






TomatoSCI分析日记——层次聚类
今天介绍的是一种常见的聚类方法——层次聚类。层次聚类会将数据集划分成嵌套的簇,形成一个层次结构(树状图),经常用于探究样本的相似性。用大白话来说,就是:我有一大堆样品,每个样品都有n个特征,我们通过层次聚类利用这些特征可以把这些样品划分为不同的类群。
1.层次聚类的两种方式
层次聚类通常分为“向下分裂”和“向上合并”两类。
向下分裂:从一个整体开始,每一步将最不相似的点或子簇分开,直到每个样本成为单独的簇。
向上合并:每一步合并两个最相似的簇,直到只剩一个簇或达到设定的聚类数。
两种方法各有千秋,向下分裂不容易受异常值影响,向上合并策略更灵活。在实际中,更多的是选择“向上合并”。
2.如何确定分多少类(簇数)?
在讲解实例之前,我们还要确定一件事,就是要分多少类(簇数)。我们最好是通过一个有说服力的指标去确定簇数,而不是分几簇有利于我的实际情况就去分几簇,随意分簇导致的后果就是当我们的分析结果遭到质疑的时候我们往往很难有足够证据去反驳。
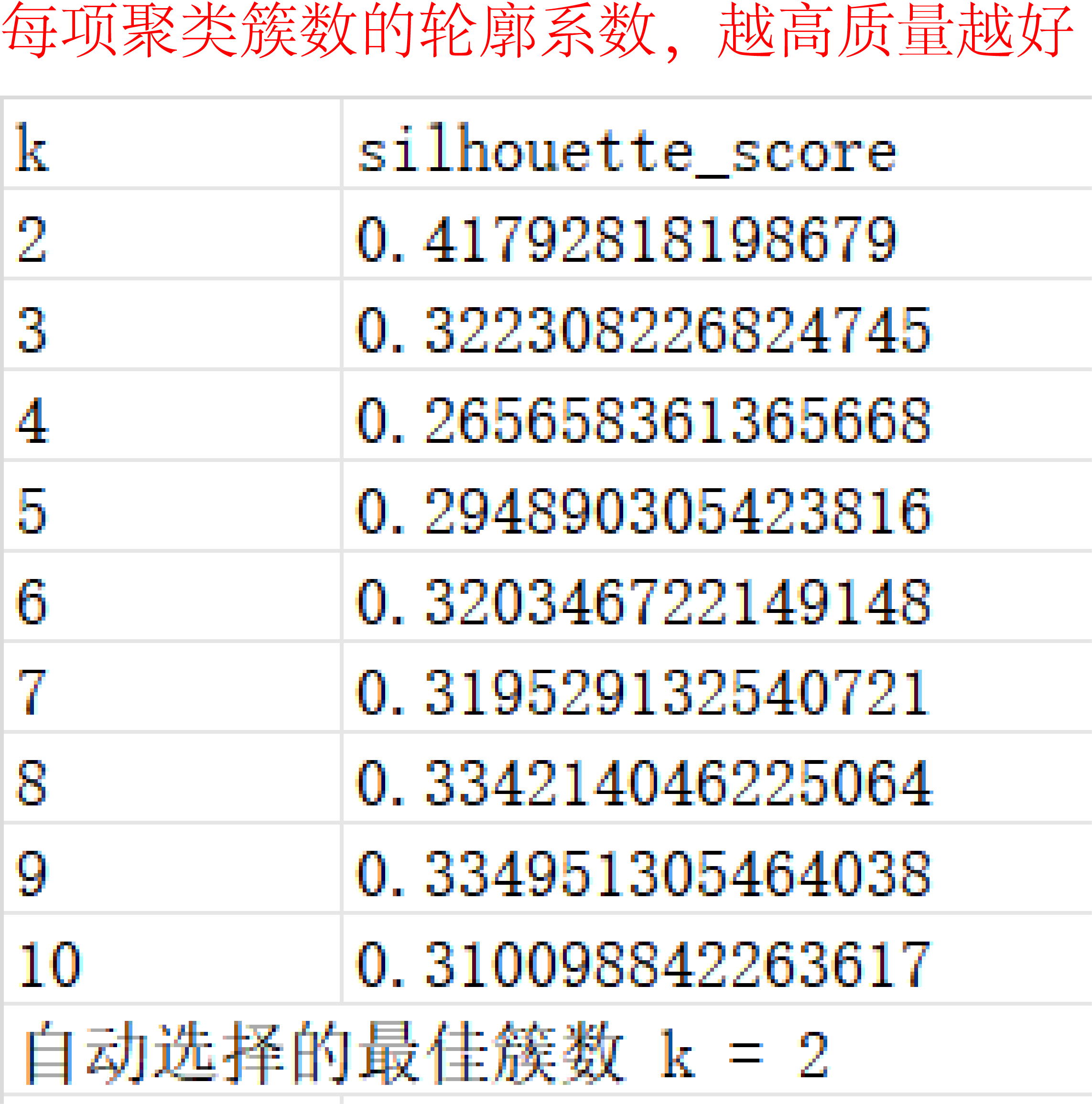
这里就需要引入“轮廓系数”。轮廓系数是衡量聚类效果好坏的一个经典指标,它能够同时反映数据点与自身簇的紧密度以及与最近邻簇的分离度,用来评价聚类的合理性。通常使用所有样本的轮廓系数的平均值对聚类整体质量进行评价,数值越大效果越好。在聚类时,可以比较不同k下的平均轮廓系数,选择轮廓系数最大时的k。这样我们的聚类就有了有力的依据。
3.示例
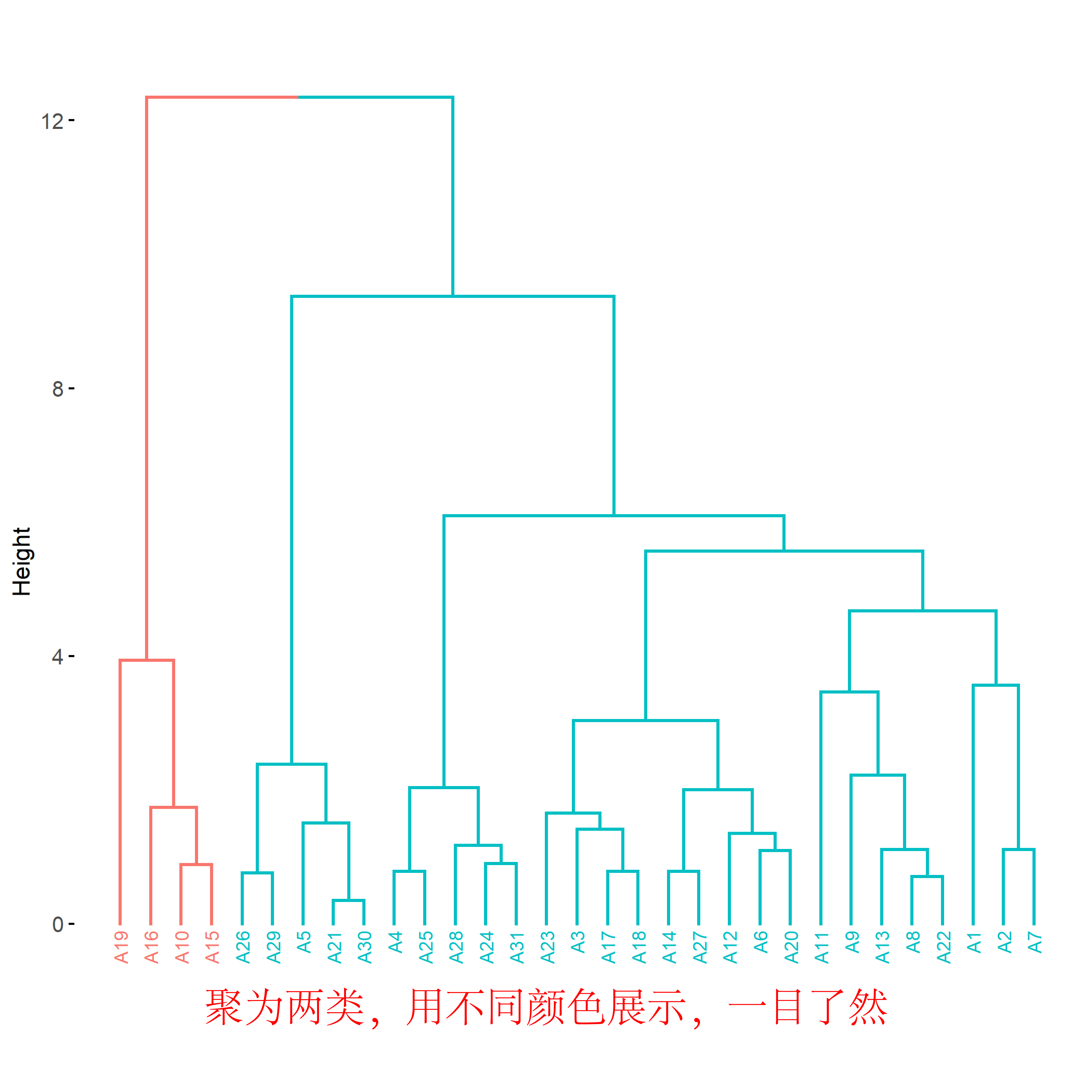
图1是示例数据,每行为一个样本,每列为一个特征,量纲如果不同则需要标准化。图2是聚2-10簇时的轮廓系数,我们可以看到当簇数为2时轮廓系数最大,因此我们选择聚2类。图3的树状图是层次聚类的经典可视化方式,使用了不同颜色区分不同簇,结果一目了然。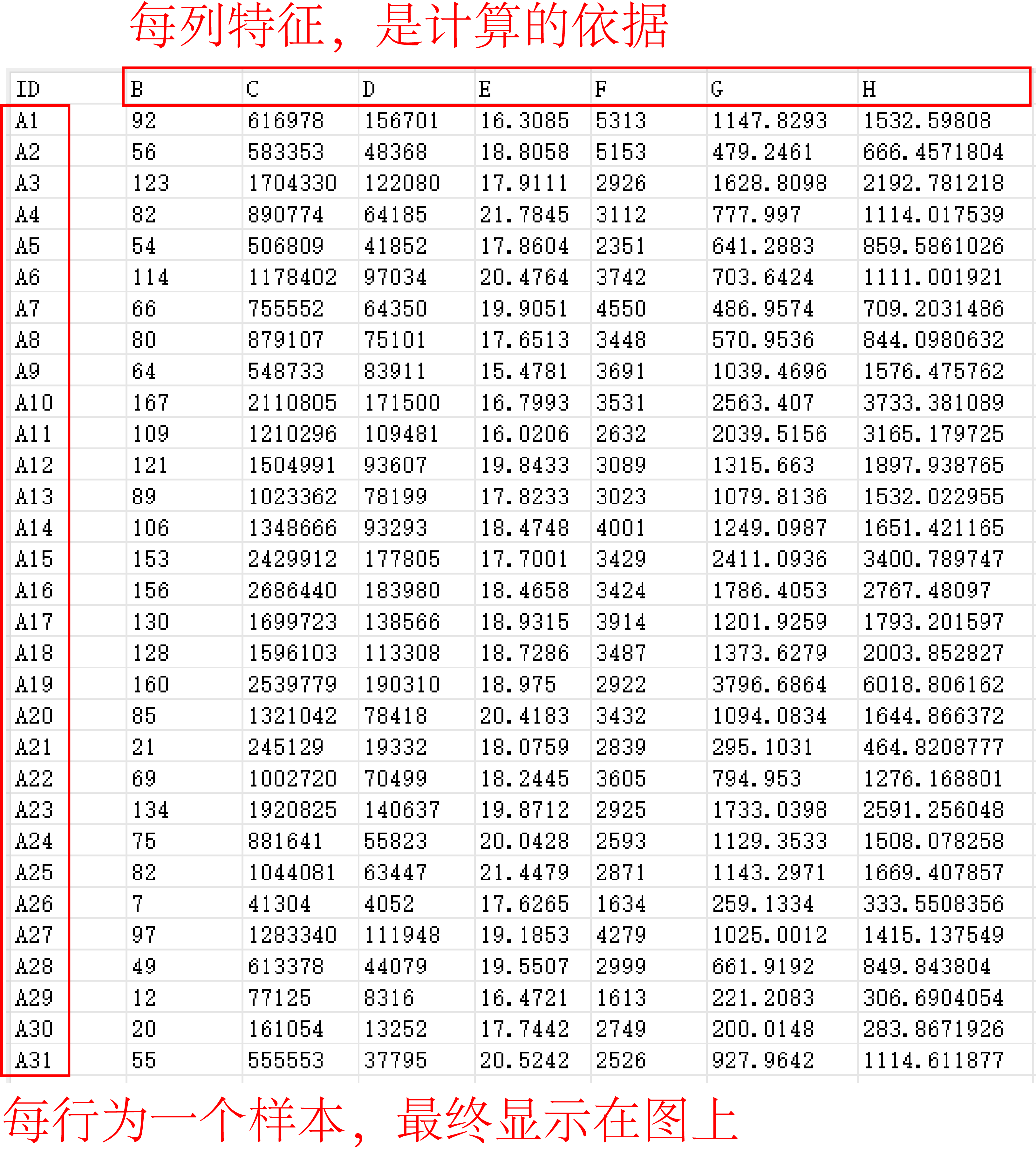
4.结语
欢迎来访TomatoSCI。等你就位!


















 749
749

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









