







 本文介绍了在天池比赛中如何运用Apriori算法进行商品关联分析,详细阐述了关联分析的基本概念,包括频繁项集、关联规则、支持度和置信度,并展示了实际操作步骤,包括数据处理、寻找频繁项集和挖掘关联规则。
本文介绍了在天池比赛中如何运用Apriori算法进行商品关联分析,详细阐述了关联分析的基本概念,包括频繁项集、关联规则、支持度和置信度,并展示了实际操作步骤,包括数据处理、寻找频繁项集和挖掘关联规则。
这篇文章是对天池比赛里面的商品关联分析案例的介绍,采用 Apriori 算法发现频繁项集,确定关联关系。
1、基本概念
1.1 关联分析相关概念
频繁项集和关联规则是关联分析中的两个基本概念:频繁项集(frequent item sets)是经常出现在一块的物品的集合,关联规则(association rules)暗示两种物品之间可能存在很强的关系。
关联分析中采用 支持度 去筛选出频繁项集:一个项集的支持度(support)被定义为数据集中包含该项集的记录所占的比例。从下边 图1 中可以得到,{豆奶}的支持度为4/5。而在5条交易记录中有3条包含{豆奶,尿布},因此{豆奶,尿布}的支持度为3/5。支持度是针对项集来说的,因此可以定义一个最小支持度,而只保留满足最小支持度的项集。
关联分析中采用 可信度/置信度 去找出关联规则,可信度/置信度(confidence)是针对一条诸如{尿布} ➞ {葡萄酒}的关联规则来定义的。这条规则的可信度被定义为“支持度({尿布,葡萄酒})/支持度({尿布})”。从下边 图1 中可以看到,由于{尿布,葡萄酒}的支持度为3/5,尿布的支持度为4/5,所以“尿布 ➞ 葡萄酒”的可信度为3/4=0.75。这意味着对于包含“尿布”的所有记录,我们的规则对其中75%的记录都适用。

1.2 Apriori 算法简介
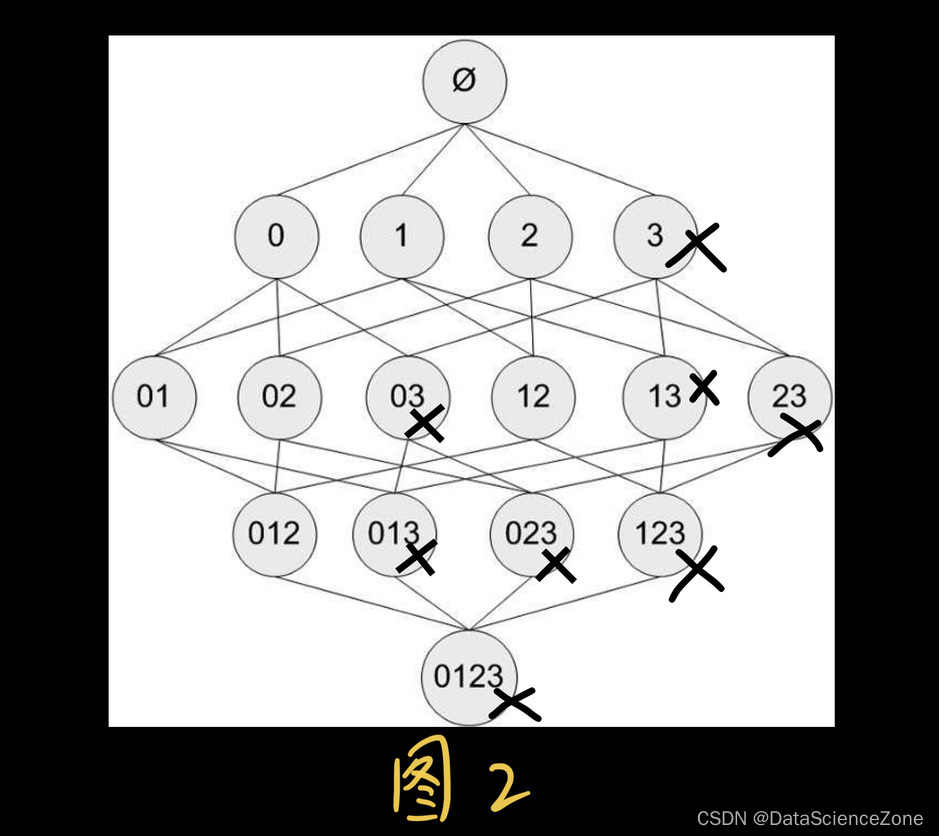
Apriori 原理是说如果某个项集是频繁的,那么它的所有子集也是频繁的。对于下边 图2 给出的例子,这意味着如果{0,1}是频繁的,那么{0}、{1}也一定是频繁的。这个原理直观上并没有什么帮助,但是如果反过来看就有用了,也就是说 如果一个项集是非频繁集,那么它的所有超集也是非频繁的。如下边的 图2 ,其中 3 是非频繁的,那么 3 的超集 0 3,1 3,2 3, 0 1 3,0 2 3,1 2 3, 0 1 2 3 也是非频繁的。
2、赛题
这个比赛的题目来自于天池的教学赛(https://tianchi.aliyun.com/competition/entrance/531891/information),赛题以购物篮分析为背景,要求选手对品牌的历史订单数据,挖掘频繁项集与关联规则。通过这道赛题,鼓励学习者利用订单数据,为企业提供销售策略,产品关联组合,为企业提升销量的同时,也为消费者提供更适合的商品推荐。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









