






Task 04- 机器翻译-注意力机制-Seq2seq-Transformer
1 机器翻译(Machine Translation)
1.0 数据集形式

1.1 序列预处理
- 序列padding(保持序列的长度一致)–> valid length:序列未padding之前的长度
def pad(line, max_len, padding_token):
if len(line) > max_len:
return line[:max_len]
return line + [padding_token] * (max_len - len(line))
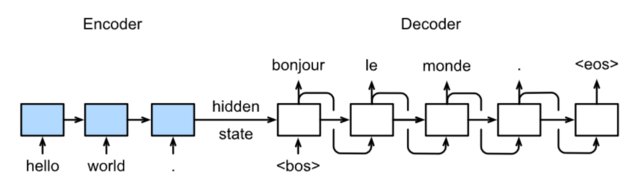
1.2 Seq2Seq模型(Encoder-Decoder框架)
- Encoder:输入序列编码到语义编码(context vector c \bold{c} c)
- Decoder:将语义编码解码到输出

- S e q 2 S e q Seq2Seq Seq2Seq模型架构

- 训练:

- 测试:多次前向传播,进行自回归预测
1.3 模型测试序列生成策略
- 贪心搜索(greedy search):逐步选取概率最大的词

-
穷举搜索(exhaustive search):穷举所有可能输出序列,但开销过大
-
集束搜索(beam search):维特比算法,带有超参数束宽(beam size) k k k,在第一个时间步选取 k k k个概率最大的词,在其后的时间步各选取一个概率最大的词

2 注意力机制
2.0 为什么?
- Enc-Dec框架里,Decoder将语义编码映射至输出;
- S e q 2 S e q Seq2Seq Seq2Seq模型因为使用RNN进行编/解码,容易出现长程梯度消失的问题,故语义编码难以保存完整语义信息;
- 各个输出词对各个输入词的依赖程度不同,这种依赖程度通过权重表达即 a t t e n t i o n w e i g h t s attention\ weights attention weights
2.1 组成

- Query( q \bold{q} q):理解为由输出端向输入端发出一个查询请求,通过 a t t e n t i o n w e i g h t s attention\ weights attention weights进行编码
- Key( k i \bold{k}_i ki)-Value( v i \bold{v}_i vi):键-值对
q i ∈ R d k , v i ∈ R d v , q ∈ R d q . a i = α ( q , k i ) . b 1 , … , b n = softmax ( a 1 , … , a n ) . o = ∑ i = 1 n b i v i . \bold{q}_i∈ℝ^{d_k}, \bold{v}_i∈ℝ^{d_v}, \bold{q}∈ℝ^{d_q}. \\ a_i = \alpha(\mathbf q, \mathbf k_i). \\ b_1, \ldots, b_n = \textrm{softmax}(a_1, \ldots, a_n). \\ \mathbf o = \sum_{i=1}^n b_i \mathbf v_i. qi∈Rdk,vi∈Rdv,q∈Rdq.ai=α(q,ki).b1,…,bn=softmax(a1,…,an).o=i=1∑nbivi.

2.2 分类
2.2.1 点积注意力
∀ i , q , k i ∈ R d α ( q , k ) = ⟨ q , k ⟩ / d α ( Q , K ) = Q K T / d ( Q ∈ R m d , K ∈ R n d ) \forall i, \bold{q},\bold{k}_i ∈ ℝ_d \\ \alpha(\bold{q},\bold{k})=⟨\bold{q},\bold{k}⟩/ \sqrt{d} \\ \alpha(\bold{Q},\bold{K})=\bold{Q}\bold{K}^T/\sqrt{d}\ (\bold{Q}∈ℝ^{md},\bold{K}∈ℝ^{nd}) ∀i,q,ki∈Rdα(q,k)=⟨q,k⟩/dα(Q,K)=QKT/d (Q∈Rmd,K∈Rnd)
2.2.2 MLP注意力
W k ∈ R h d k , W q ∈ R h × d q , v ∈ R h α ( q , k ) = v T t a n h ( W k k + W q q ) \bold{W}_k∈ℝ^{hd_{k}},\bold{W}_q∈ℝ^{h×d_{q}},\bold{v}∈ℝ^h \\ \alpha(\bold{q},\bold{k})=\bold{v}^Ttanh(\bold{W}_k\bold{k}+\bold{W}_q\bold{q}) Wk∈Rhdk,Wq∈Rh×dq,v∈Rhα(q,k)=vTtanh(Wkk+Wqq)
2.3 Enc-Dec上的注意力机制

3 Transformer

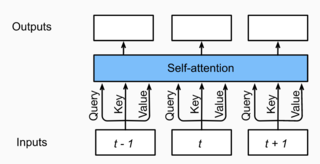
3.0 Self-Attention
- Q , K , V Q,K,V Q,K,V均为当前时间步的值,第一次softmax后,与前后时间步再进行一次attention计算
class DotProductAttention(nn.Module):
def __init__(self, dropout, **kwargs):
super(DotProductAttention, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
# query: (batch_size, #queries, d)
# key: (batch_size, #kv_pairs, d)
# value: (batch_size, #kv_pairs, dim_v)
# valid_length: either (batch_size, ) or (batch_size, xx)
def forward(self, query, key, value, valid_length=None):
d = query.shape[-1]
# set transpose_b=True to swap the last two dimensions of key
scores = torch.bmm(query, key.transpose(1,2)) / math.sqrt(d)
attention_weights = self.dropout(masked_softmax(scores, valid_length))
return torch.bmm(attention_weights, value)
3.1 Multi-head Attention
- 多头注意力:将query、key和value用三个现行层进行映射,这h个注意力头的输出将会被拼接之后输入最后一个线性层进行整合

def transpose_qkv(X, num_heads):
# Original X shape: (batch_size, seq_len, hidden_size * num_heads),
# -1 means inferring its value, after first reshape, X shape:
# (batch_size, seq_len, num_heads, hidden_size)
X = X.view(X.shape[0], X.shape[1], num_heads, -1)
# After transpose, X shape: (batch_size, num_heads, seq_len, hidden_size)
X = X.transpose(2, 1).contiguous()
# Merge the first two dimensions. Use reverse=True to infer shape from
# right to left.
# output shape: (batch_size * num_heads, seq_len, hidden_size)
output = X.view(-1, X.shape[2], X.shape[3])
return output
# Saved in the d2l package for later use
def transpose_output(X, num_heads):
# A reversed version of transpose_qkv
X = X.view(-1, num_heads, X.shape[1], X.shape[2])
X = X.transpose(2, 1).contiguous()
return X.view(X.shape[0], X.shape[1], -1)
class MultiHeadAttention(nn.Module):
def __init__(self, input_size, hidden_size, num_heads, dropout, **kwargs):
super(MultiHeadAttention, self).__init__(**kwargs)
self.num_heads = num_heads
self.attention = DotProductAttention(dropout)
self.W_q = nn.Linear(input_size, hidden_size, bias=False)
self.W_k = nn.Linear(input_size, hidden_size, bias=False)
self.W_v = nn.Linear(input_size, hidden_size, bias=False)
self.W_o = nn.Linear(hidden_size, hidden_size, bias=False)
def forward(self, query, key, value, valid_length):
# query, key, and value shape: (batch_size, seq_len, dim),
# where seq_len is the length of input sequence
# valid_length shape is either (batch_size, )
# or (batch_size, seq_len).
# Project and transpose query, key, and value from
# (batch_size, seq_len, hidden_size * num_heads) to
# (batch_size * num_heads, seq_len, hidden_size).
query = transpose_qkv(self.W_q(query), self.num_heads)
key = transpose_qkv(self.W_k(key), self.num_heads)
value = transpose_qkv(self.W_v(value), self.num_heads)
if valid_length is not None:
# Copy valid_length by num_heads times
device = valid_length.device
valid_length = valid_length.cpu().numpy() if valid_length.is_cuda else valid_length.numpy()
if valid_length.ndim == 1:
valid_length = torch.FloatTensor(np.tile(valid_length, self.num_heads))
else:
valid_length = torch.FloatTensor(np.tile(valid_length, (self.num_heads,1)))
valid_length = valid_length.to(device)
output = self.attention(query, key, value, valid_length)
output_concat = transpose_output(output, self.num_heads)
return self.W_o(output_concat)
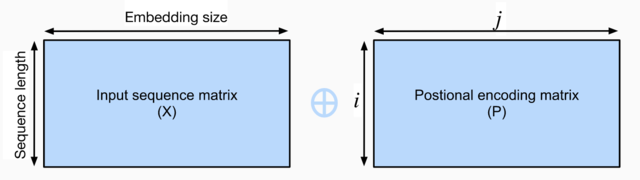
3.2 Positional Encoding
- 用波函数来对序列位置进行编码
P i , 2 j = s i n ( i / 1000 0 2 j / d ) P i , 2 j + 1 = c o s ( i / 1000 0 2 j / d ) f o r i = 0 , … , l − 1 a n d j = 0 , … , ⌊ ( d − 1 ) / 2 ⌋ P_{i,2j} = sin(i/10000^{2j/d}) \\ P_{i,2j+1} = cos(i/10000^{2j/d}) \\ for\ i=0,\ldots, l-1\ and\ j=0,\ldots,\lfloor (d-1)/2 \rfloor Pi,2j=sin(i/100002j/d)Pi,2j+1=cos(i/100002j/d)for i=0,…,l−1 and j=0,…,⌊(d−1)/2⌋
3.3 Position-wise FeedForward Network (FFN)
- 仅对输入的最后一维进行编码,即每个词的embedding进行编码
class PositionWiseFFN(nn.Module):
def __init__(self, input_size, ffn_hidden_size, hidden_size_out, **kwargs):
super(PositionWiseFFN, self).__init__(**kwargs)
self.ffn_1 = nn.Linear(input_size, ffn_hidden_size)
self.ffn_2 = nn.Linear(ffn_hidden_size, hidden_size_out)
def forward(self, X):
return self.ffn_2(F.relu(self.ffn_1(X)))
3.4 Transformer code
class EncoderBlock(nn.Module):
def __init__(self, embedding_size, ffn_hidden_size, num_heads,
dropout, **kwargs):
super(EncoderBlock, self).__init__(**kwargs)
self.attention = MultiHeadAttention(embedding_size, embedding_size, num_heads, dropout)
self.addnorm_1 = AddNorm(embedding_size, dropout)
self.ffn = PositionWiseFFN(embedding_size, ffn_hidden_size, embedding_size)
self.addnorm_2 = AddNorm(embedding_size, dropout)
def forward(self, X, valid_length):
Y = self.addnorm_1(X, self.attention(X, X, X, valid_length))
return self.addnorm_2(Y, self.ffn(Y))
class TransformerEncoder(d2l.Encoder):
def __init__(self, vocab_size, embedding_size, ffn_hidden_size,
num_heads, num_layers, dropout, **kwargs):
super(TransformerEncoder, self).__init__(**kwargs)
self.embedding_size = embedding_size
self.embed = nn.Embedding(vocab_size, embedding_size)
self.pos_encoding = PositionalEncoding(embedding_size, dropout)
self.blks = nn.ModuleList()
for i in range(num_layers):
self.blks.append(
EncoderBlock(embedding_size, ffn_hidden_size,
num_heads, dropout))
def forward(self, X, valid_length, *args):
X = self.pos_encoding(self.embed(X) * math.sqrt(self.embedding_size))
for blk in self.blks:
X = blk(X, valid_length)
return X
class DecoderBlock(nn.Module):
def __init__(self, embedding_size, ffn_hidden_size, num_heads,dropout,i,**kwargs):
super(DecoderBlock, self).__init__(**kwargs)
self.i = i
self.attention_1 = MultiHeadAttention(embedding_size, embedding_size, num_heads, dropout)
self.addnorm_1 = AddNorm(embedding_size, dropout)
self.attention_2 = MultiHeadAttention(embedding_size, embedding_size, num_heads, dropout)
self.addnorm_2 = AddNorm(embedding_size, dropout)
self.ffn = PositionWiseFFN(embedding_size, ffn_hidden_size, embedding_size)
self.addnorm_3 = AddNorm(embedding_size, dropout)
def forward(self, X, state):
enc_outputs, enc_valid_length = state[0], state[1]
# state[2][self.i] stores all the previous t-1 query state of layer-i
# len(state[2]) = num_layers
if state[2][self.i] is None:
key_values = X
else:
# shape of key_values = (batch_size, t, hidden_size)
key_values = torch.cat((state[2][self.i], X), dim=1)
state[2][self.i] = key_values
if self.training:
batch_size, seq_len, _ = X.shape
# Shape: (batch_size, seq_len), the values in the j-th column are j+1
valid_length = torch.FloatTensor(np.tile(np.arange(1, seq_len+1), (batch_size, 1)))
valid_length = valid_length.to(X.device)
else:
valid_length = None
X2 = self.attention_1(X, key_values, key_values, valid_length)
Y = self.addnorm_1(X, X2)
Y2 = self.attention_2(Y, enc_outputs, enc_outputs, enc_valid_length)
Z = self.addnorm_2(Y, Y2)
return self.addnorm_3(Z, self.ffn(Z)), state
class TransformerDecoder(d2l.Decoder):
def __init__(self, vocab_size, embedding_size, ffn_hidden_size,
num_heads, num_layers, dropout, **kwargs):
super(TransformerDecoder, self).__init__(**kwargs)
self.embedding_size = embedding_size
self.num_layers = num_layers
self.embed = nn.Embedding(vocab_size, embedding_size)
self.pos_encoding = PositionalEncoding(embedding_size, dropout)
self.blks = nn.ModuleList()
for i in range(num_layers):
self.blks.append(
DecoderBlock(embedding_size, ffn_hidden_size, num_heads,
dropout, i))
self.dense = nn.Linear(embedding_size, vocab_size)
def init_state(self, enc_outputs, enc_valid_length, *args):
return [enc_outputs, enc_valid_length, [None]*self.num_layers]
def forward(self, X, state):
X = self.pos_encoding(self.embed(X) * math.sqrt(self.embedding_size))
for blk in self.blks:
X, state = blk(X, state)
return self.dense(X), state















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









