







1. 学习缓慢问题
二次代价函数,定义如下
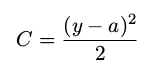
其中 a 是神经元的输出,训练输入为 x = 1,y = 0 则是目标输出。显式地使用权重和偏置来表达这个,我们有 a = σ(z),其中 z = wx + b。使用链式法则来求权重和偏置的偏导数就有:
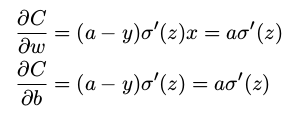
σ 函数图像:
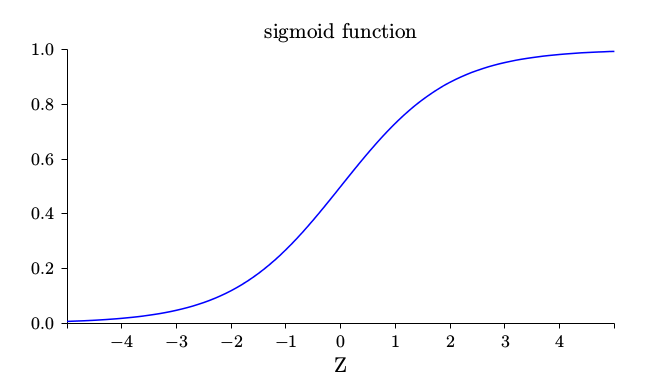
我们可以从这幅图看出,当神经元的输出接近 1 的时候,曲线变得相当平,所以 σ ′ (z) 就很小了。∂C/∂w 和 ∂C/∂b 会非常小,这其实就是学习缓慢的原因所在
2. 引入交叉熵代价函数
定义交叉熵代价函数:
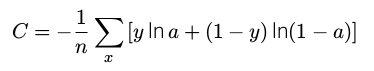
其中 n 是训练数据的总数,求和是在所有的训练输入 x 上进行的,y 是对应的目标输出。
将交叉熵看做是代价函数有两点原因,交叉熵是非负的,在神经元达到很好的正确率的时候会接近 0。
计算交叉熵函数关于权重的偏导数。将 a = σ(z) 代入到 上式 中应用两次链式法则,得到:
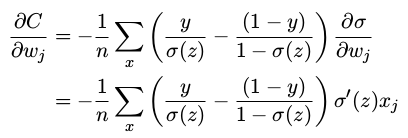
将结果合并一下,简化成:

根据 σ(z) = 1/(1 + e −z ) 的定义,和一些运算,我们可以得到 σ ′ (z) = σ(z)(1 − σ(z)),上下两项约去:
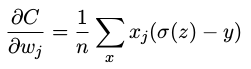
这个公式告诉我们权重学习的速度受到 σ(z) − y,也就是输出中的误差的控制。更大的误差,更快的学习速度。
另一种解决学习缓慢的问题的方法
3. 基于柔性最大值(softmax)神经元层
柔性最大值的想法其实就是为神经网络定义一种新式的输出层。首先计算带权输入
zLj=∑kwLjkaL−1k+bLj
。在
zLj
上应用softmax函数,第 j 个神经元的激活值
aLj
就是:
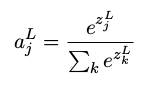
其中,分母中的求和是在所有的输出神经元上进行的。
学习缓慢问题:
先定义一个对数似然(log-likelihood)代价函数,使用 x 表示网络的训练输入,y 表示对应的目标输出:
学习缓慢的关键就是量 ∂C/∂wLjk 和 ∂C/∂bLj 的变化情况
????????????????????????????
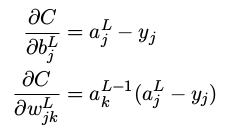
???????????????????????????
把一个具有对数似然代价的柔性最大值输出层,看作与一个具有交叉熵代价的 S 型输出层非常相似















 903
903











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









