






原文链接: fast style transfer 快速风格转换 tfjs
上一篇: dqn dueling 算法 CartPole-v0 三网络实现
下一篇: tfjs 配合opencvjs 读取网页图像并显示
由于tfjs并不支持pad操作,所以需要在模型中除去
如果不进行pad操作,则也就不需要输入宽和高,网络输入只需要一张图片即可
效果 浏览器运算能力还是很有限太大的图片可以计算,但是很难绘制出来
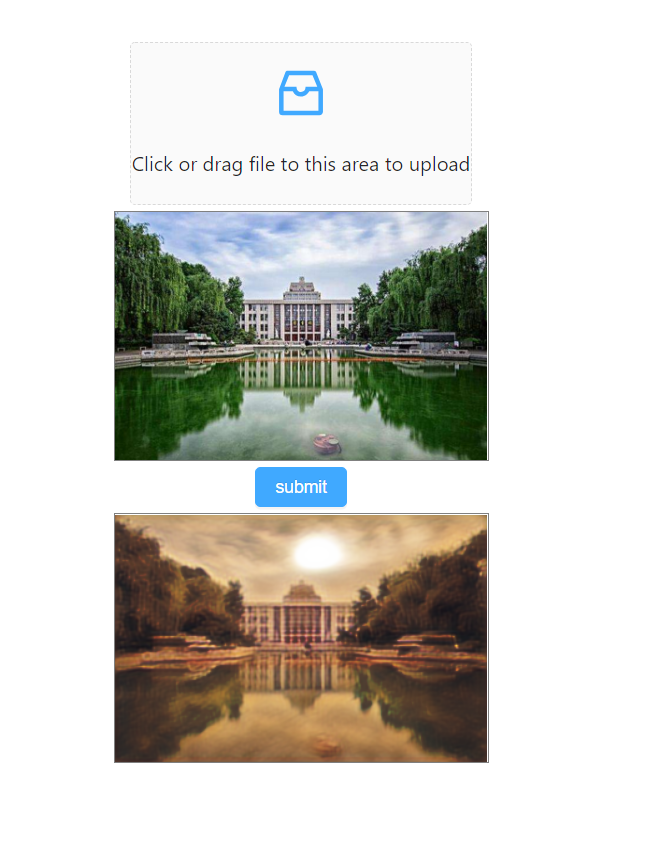
安装 tensorflowjs, 将保存的pb文件转换为tfjs能用的格式
pip install tensorflowjsimport tensorflowjs as tfjs
tfjs.converters.tf_saved_model_conversion_pb.convert_tf_frozen_model(
'./pb/mnls_no_pad.pb',
'generator/output',
'./tfjs'
)
使用vue和antd做可视化
安装
npm install @tensorflow/tfjsantd
https://ant-design-vue.gitee.io/docs/vue/getting-started-cn/
<template>
<div class="main">
<a-upload-dragger name="file" :showUploadList="false" :beforeUpload="beforeUpload"
>
<p class="ant-upload-drag-icon">
<a-icon type="inbox"/>
</p>
<p class="ant-upload-text">Click or drag file to this area to upload</p>
</a-upload-dragger>
<img src="/static/default.jpg" alt="" class="img" id="img">
<a-button type="primary" @click="submit">submit</a-button>
<canvas src="/static/default.jpg" class="img" id="mix"></canvas>
</div>
</template>
<script>
import * as tf from '@tensorflow/tfjs';
import {loadGraphModel} from '@tensorflow/tfjs-converter';
export default {
methods: {
beforeUpload(file) {
console.log(file);
let img = document.getElementById('img')
let url = window.URL.createObjectURL(file);
img.src = url
// 返回false表示文件不提交到服务器
return false
},
async submit() {
// let model = await tf.loadLayersModel('./static/style_model/mnls/model.json')
// let model = await tf.loadLayersModel('./static/style_model/style1/model.json')
let MODEL_URL = './static/style_model/mnls/tensorflowjs_model.pb'
let WEIGHTS_URL = './static/style_model/mnls/weights_manifest.json'
// 加载模型
const model = await loadGraphModel(MODEL_URL, WEIGHTS_URL);
console.log(model)
let img = document.getElementById('img')
let canvas = document.getElementById("mix");
let tensor = tf.browser.fromPixels(img).toFloat()
console.log(tensor.shape)
tensor = tensor.expandDims(0)
console.log(tensor)
let ret = await model.execute({
"in_x": tensor,
})
ret = ret.squeeze(0)
console.log('ret', ret)
ret = ret.clipByValue(0, 255).toInt()
console.log('ret', ret)
await tf.browser.toPixels(ret, canvas)
// var new_img = new Image();
// console.log(tensor.dataSync())
// img.src = window.URL.createObjectURL(tensor.dataSync())
}
},
}
</script>
<style>
.main {
display: flex;
flex-direction: column;
/*justify-content: center;*/
align-items: center;
}
.img {
/*width: 256px;*/
/*height: 256px;*/
min-width: 200px;
min-height: 200px;
max-width: 300px;
max-height: 300px;
border: 1px solid gray;
margin: 5px;
}
</style>
model
import tensorflow as tf
import tensorflow.contrib.slim as slim
from tensorflow.contrib.slim import instance_norm
from config import *
import tensorflow.contrib.eager as tfe
import tensorflow.contrib.slim.nets as nets
def residual(x, filter_num, name):
with tf.variable_scope(name):
with slim.arg_scope([slim.conv2d],
activation_fn=tf.nn.leaky_relu,
):
net1 = slim.conv2d(x, filter_num, 1)
net3 = slim.conv2d(x, filter_num, 3)
net5 = slim.conv2d(x, filter_num, 5)
net7 = slim.conv2d(x, filter_num, 7)
net9 = slim.conv2d(x, filter_num, 9)
net = tf.concat([net3, net5, net7, net9], axis=3)
net = slim.conv2d(net, filter_num, 1)
return net + net1
# image 是(-1,1)的图像,并且需要输入的宽和高,输出(0,255)相同大小的image
def generator(image):
# image = tf.pad(image, [[0, 0], [IMAGE_PAD, IMAGE_PAD], [IMAGE_PAD, IMAGE_PAD], [0, 0]], mode='REFLECT')
print(image.shape)
with tf.variable_scope(GENERATOR_SCOPE, reuse=tf.AUTO_REUSE):
with slim.arg_scope([slim.conv2d_transpose, slim.conv2d],
activation_fn=tf.nn.leaky_relu,
):
conv1 = instance_norm(slim.conv2d(image, 64, 9, 1, scope='conv1'))
conv2 = instance_norm(slim.conv2d(conv1, 64, 9, 1, scope='conv2'))
# conv3 = instance_norm(slim.conv2d_transpose(conv2, 32, 3, 2, scope='conv3'))
conv3 = instance_norm(slim.conv2d(conv2, 64, 9, 1, scope='conv3'))
res1 = instance_norm(residual(conv3, 64, 'res1'))
res2 = instance_norm(residual(res1, 64, 'res2'))
res3 = instance_norm(residual(res2, 64, 'res3'))
res4 = instance_norm(residual(res3, 64, 'res4'))
res5 = instance_norm(residual(res4, 64, 'res5'))
deconv1 = instance_norm(slim.conv2d(res5, 64, 9, 1, scope='deconv1'))
deconv2 = instance_norm(slim.conv2d(deconv1, 64, 9, 1, scope='deconv2'))
deconv3 = instance_norm(slim.conv2d(deconv2, 3, 9, 1, scope='deconv3'))
y = tf.nn.tanh(deconv3)
# re-vlaue to [0, 255]
y = (y + 1.0) * 127.5
# y = tf.image.crop_to_bounding_box(y, IMAGE_PAD, IMAGE_PAD, height, width)
# y = tf.slice(y, [0, IMAGE_PAD, IMAGE_PAD, 0], [-1, height, width, -1], name='output')
y = tf.identity(y, 'output')
print(y)
return y
def build_model(in_x):
with tf.variable_scope('', reuse=tf.AUTO_REUSE):
_, endpoints = nets.vgg.vgg_19(in_x, spatial_squeeze=False)
need_layer = STYLE_LAYERS + CONTENT_LAYERS
net = {
k: endpoints[k]
for k in endpoints
if k in need_layer
}
net['input'] = in_x
return net
def content_layer_loss(p, x):
_, h, w, N = p.get_shape()
M = h.value * w.value
N = N.value
# K = 1. / (2. * N ** 0.5 * M ** 0.5)
K = 1. / (N * M)
# K = 1. / 2.
loss = K * tf.reduce_sum((x - p) ** 2)
return loss
def style_layer_loss(a, x):
_, h, w, N = a.get_shape()
M = h.value * w.value
N = N.value
# print('style_layer_loss ', a.shape, x.shape)
A = gram_matrix(a, M, N)
G = gram_matrix(x, M, N)
loss = (1. / (4 * N ** 2 * M ** 2)) * tf.reduce_sum((G - A) ** 2)
return loss
def gram_matrix(x, area, depth):
F = tf.reshape(x, (area, depth))
G = tf.matmul(tf.transpose(F), F)
# print('gram_matrix ', G.shape)
return G
# styled_net 输出图片风格网络
# style_nets 目标图片风格网络
# batch_size 只在训练中有效,所以可以固化
# 不然gram 矩阵会reshape失败
def sum_style_losses(styled_net, style_nets):
with tf.variable_scope('sum_style'):
total_style_loss = 0.
for net, img_weight in zip(style_nets, STYLE_WEIGHTS):
style_loss = 0.
for layer, weight in zip(STYLE_LAYERS, STYLE_LAYER_WEIGHTS):
a = net[layer]
# x = styled_net[layer]
for x in tf.split(styled_net[layer], BATCH_SIZE):
# print('sum_style_losses ', a.shape, x.shape)
ls = tfe.py_func(func=style_layer_loss, inp=[a, x], Tout=tf.float32)
style_loss += ls * weight
style_loss /= float(len(STYLE_LAYERS))
total_style_loss += (style_loss * img_weight)
total_style_loss /= float(len(style_nets))
total_style_loss /= BATCH_SIZE
return total_style_loss
def sum_content_losses(styled_net, content_net):
with tf.variable_scope('sum_content'):
content_loss = 0.
for layer, weight in zip(CONTENT_LAYERS, CONTENT_LAYER_WEIGHTS):
p = content_net[layer]
x = styled_net[layer]
# print('sum_content_losses ', p.shape, x.shape)
ls = tfe.py_func(func=content_layer_loss, inp=[p, x], Tout=tf.float32)
content_loss += ls * weight
content_loss /= float(len(CONTENT_LAYERS))
return content_loss
train
import matplotlib.pyplot as plt
from model_tfjs import *
# from model import *
import data
from tensorflow.python.framework import graph_util
from config import *
import scipy.misc as sm
def main():
iterator = data.get_iterator()
image_batch = iterator.get_next()
style_images = [
sm.imread(path, mode='RGB')
for path in STYLE_IMAGE_PATHS
]
test_images = [
sm.imresize(sm.imread(path, mode='RGB'), (MAX_IMAGE_SIZE, MAX_IMAGE_SIZE))
for path in TEST_IMAGE_PATHS
]
test_images = np.stack(test_images).astype(np.float32)
in_x = tf.placeholder(tf.float32, (None, None, None, 3), name='in_x')
# 如果有多张,输入的风格图片应该与内容图片有相同的size
in_y = tf.placeholder(tf.float32, (None, None, None, 3), name='in_y')
style_nets = [
build_model(img - MEAN_PIXEL)
for img in tf.split(in_y, len(STYLE_IMAGE_PATHS))
]
styled_image = generator(in_x / 127.5 - 1)
print(styled_image.name, styled_image.shape)
styled_net = build_model(styled_image - MEAN_PIXEL)
content_net = build_model(in_x - MEAN_PIXEL)
# style loss
L_style = sum_style_losses(styled_net, style_nets)
# content loss
L_content = sum_content_losses(styled_net, content_net)
# denoising loss
L_tv = tf.reduce_mean(tf.image.total_variation(styled_net['input']))
# total loss
L_total = tf.reduce_sum(
[CONTENT_WEIGHT * L_content, STYLE_WEIGHT * L_style, TV_WEIGHT * L_tv]
# [CONTENT_WEIGHT * L_content, STYLE_WEIGHT * L_style]
)
var_list = slim.get_variables('generator')
train_op = tf.train.AdamOptimizer(LEARNING_RATE).minimize(L_total, var_list=var_list)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
sess.run(iterator.initializer)
# tf.summary.FileWriter('./log', sess.graph)
variables_to_restore = slim.get_variables_to_restore(include=['vgg_19'])
restorer = tf.train.Saver(variables_to_restore)
restorer.restore(sess, VGG19_CKPT_PATH)
for i in range(1, 1 + TRAIN_STEP):
image_val = sess.run(image_batch)
_, h, w, _ = image_val.shape
in_style_images = [
sm.imresize(img, (h, w))
for img in style_images
]
in_style_images = np.stack(in_style_images).astype(np.float32)
_, lt, ls, lc, lv = sess.run(
[train_op, L_total, L_style, L_content, L_tv], {
in_x: image_val,
in_y: in_style_images,
})
if not i % SHOW_STEP:
print(i, lt, ls, lc, lv)
# print(image_val.shape, in_style_images.shape)
out_image = sess.run(
styled_image, {
in_x: test_images,
}
)
out_image = np.clip(out_image, 0, 255).astype(np.uint8)
out_image = np.concatenate(out_image, axis=1)
plt.imshow(out_image)
plt.show()
if not i % SAVE_STEP:
# 将网络保存到pb文件
constant_graph = graph_util.convert_variables_to_constants(sess, sess.graph_def, ['generator/output'])
with tf.gfile.FastGFile(PB_PATH, mode='wb') as f:
f.write(constant_graph.SerializeToString())
print(f"{i} save")
if __name__ == '__main__':
main()















 145
145











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









