







原文链接: 强化学习 qlearning 双网络 CartPole-v0
上一篇: 强化学习 qlearning 自制小游戏
下一篇: chrome 下载
由于双网络需要每隔一段时间更新参数,所以训练步数比单网络多
玄学炼丹,有时候效果很好
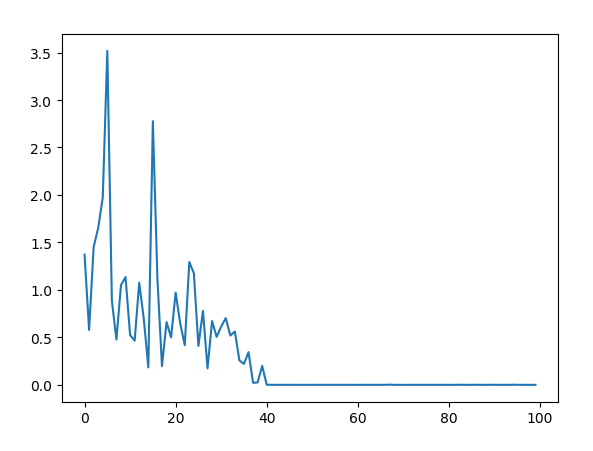
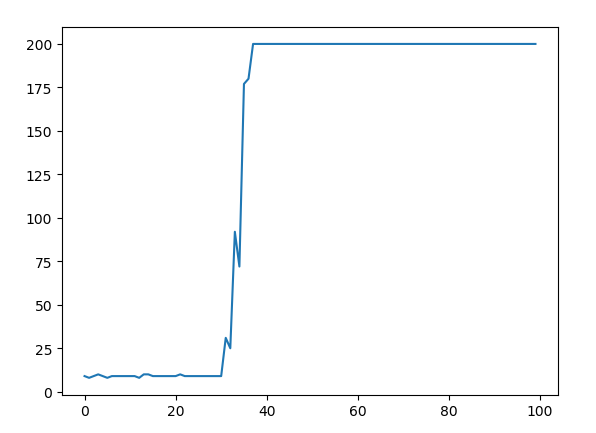
有时候收敛很慢
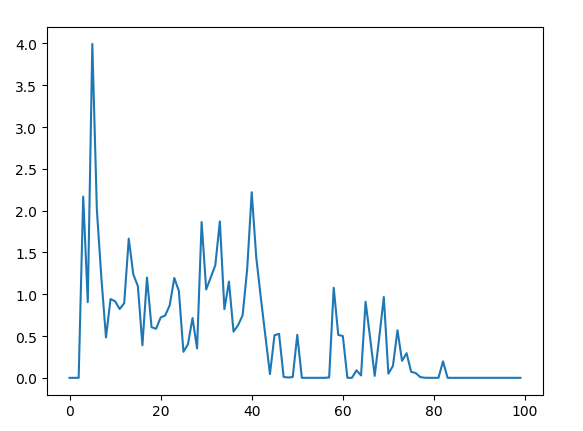
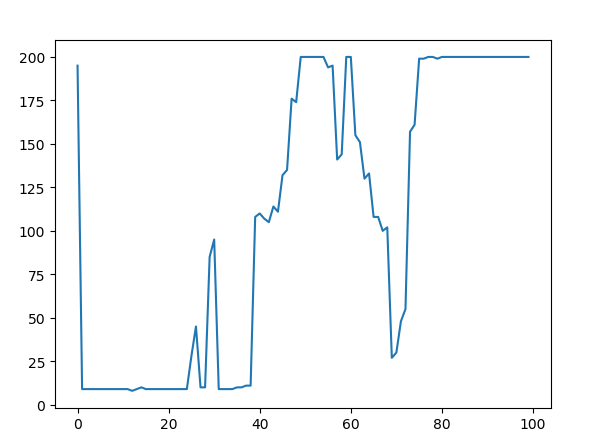
不好的情况,网络会有震荡问题
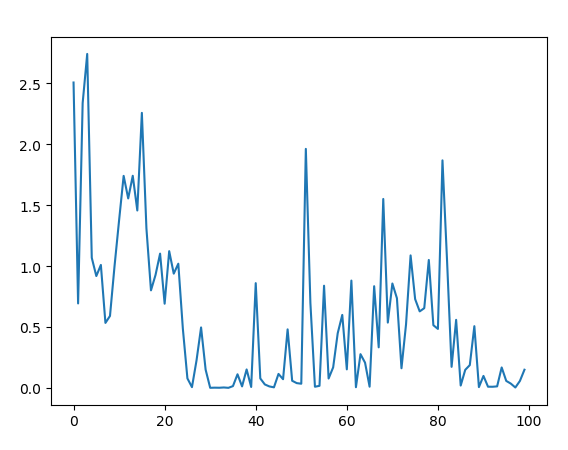
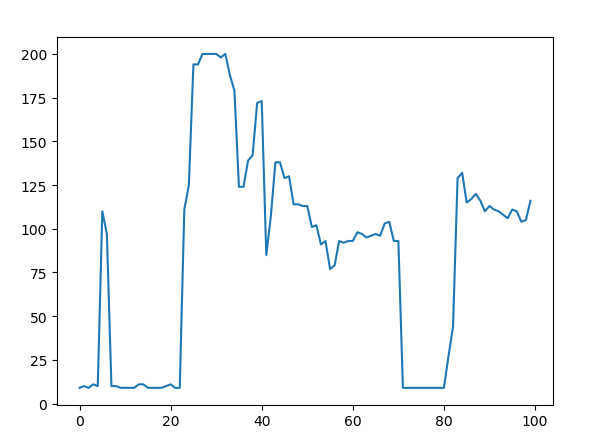
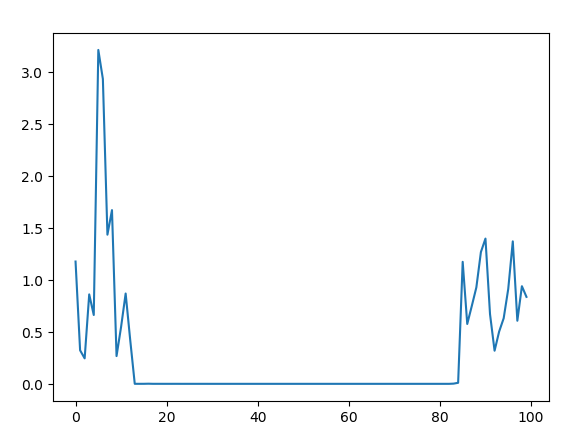
有时候还会出现稳定后又开始退化的情况
 本文介绍了使用强化学习的Q学习算法,结合双网络解决CartPole-v0问题的过程。训练中遇到的问题包括网络参数更新导致的训练步数增加、效果的不稳定性以及网络震荡和退化现象。文章提供了最终的代码实现。
本文介绍了使用强化学习的Q学习算法,结合双网络解决CartPole-v0问题的过程。训练中遇到的问题包括网络参数更新导致的训练步数增加、效果的不稳定性以及网络震荡和退化现象。文章提供了最终的代码实现。
原文链接: 强化学习 qlearning 双网络 CartPole-v0
上一篇: 强化学习 qlearning 自制小游戏
下一篇: chrome 下载
由于双网络需要每隔一段时间更新参数,所以训练步数比单网络多
玄学炼丹,有时候效果很好
有时候收敛很慢
不好的情况,网络会有震荡问题
有时候还会出现稳定后又开始退化的情况
 1150
1150

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章





















