







本论文提出了一个无监督的持续学习组件STAM(Self-Taught Associative Memory)
如下图:

上图中,
C
i
C_i
Ci为所有聚类簇的集合。当一个图片
X
i
X_i
Xi输入到这个结构中时,会被打碎成若干个重叠的可接受域(Receptive Fields,RFs)。需要注意的是,每一个STAM结构处理一个可接受域。这些可接受域经过函数
c
(
x
i
,
m
)
=
arg min
j
=
1...
∣
C
i
∣
∣
∣
x
i
,
m
−
w
i
,
j
∣
∣
c(x_{i,m})=\argmin_{j=1...|C_i|} ||x_{i,m}-w_{i,j}||
c(xi,m)=j=1...∣Ci∣argmin∣∣xi,m−wi,j∣∣的处理会将各个可接受域转为相应的聚类簇。上图中
c
i
(
x
i
,
.
m
)
c_i(x_{i,.m})
ci(xi,.m)意为第
i
i
i层的聚类簇中,与
x
i
,
.
m
x_{i,.m}
xi,.m距离最近的聚类簇(欧氏距离),而
x
i
,
m
x_{i,m}
xi,m意为第
i
i
i层,第
m
m
m个可接受域的输入数据。然后将通过函数
c
(
⋅
)
c(·)
c(⋅)处理的的可接受域重组输出为处理后的图片输出为
Y
i
Y_i
Yi,
Y
i
Y_i
Yi虽然与
X
i
X_i
Xi具有相同的特征维度,但是因为
X
i
X_i
Xi的每一个可接受域做了分类处理,所以
Y
i
Y_i
Yi的实际特征维度可能小于
X
i
X_i
Xi。此外,聚类簇的集合可能会更新。没当我们队
x
i
,
m
x_{i,m}
xi,m进行分类时,若
x
i
,
m
x_{i,m}
xi,m分类至第
i
i
i层,第
j
j
j个聚类簇
w
i
,
j
w_{i,j}
wi,j,则聚类簇向量
w
i
,
j
w_{i,j}
wi,j需要进行更新,公式为:
w
i
,
j
=
α
x
i
,
m
+
(
1
−
α
)
w
i
,
j
w
h
e
n
c
(
x
i
,
m
)
=
j
w_{i,j}=\alpha x_{i,m}+(1-\alpha)w_{i,j} when c(x_{i,m})=j
wi,j=αxi,m+(1−α)wi,jwhenc(xi,m)=j
此外,由于持续学习的不确定性,难免乎有新的聚类簇也会动态的生成,它会分成两个步骤判断是都要生成新的聚类簇。更新第
j
j
j的聚类簇对应的平均值和标准差。
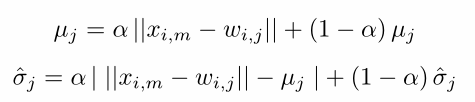
对于输入的可接受域 x i , m x_{i,m} xi,m,如果其与离它最近的聚类簇 j j j,存在以下关系,则可以判定 x i , m x_{i,m} xi,m是一个新的类,以该可接受域初始化产生新的聚类簇,判别准则如下:
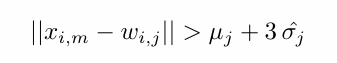
但是为了区分极端值与真正的新的类簇,我们可以再做一个判定。若 y i + 1 , m y_{i+1,m} yi+1,m是输出 Y i + 1 Y_{i+1} Yi+1的一部分,将其按第 i i i层RF的划分方式划分,则 y i + 1 , m y_{i+1,m} yi+1,m对应的是第 i i i层,第 m m m个STAM的输入,计算 c i ( y i + 1 , m ) c_i(y_{i+1,m}) ci(yi+1,m),并根据上面的判别准则判定 y i + 1 , m y_{i+1,m} yi+1,m是否属于新的类簇,如果 y i + 1 , m y_{i+1,m} yi+1,m与 x i , m x_{i,m} xi,m都是新的类簇,则生成新的聚类簇。如果 x i , m x_{i,m} xi,m是新类簇而 y i + 1 , m 不 是 y_{i+1,m}不是 yi+1,m不是,则不生产新的类簇。
当我们对输入的数据 x x x进行最终分类时,遵循以下步骤:
- 首先,计算每个代表及的向量 x n x_n xn与类簇 w j w_j wj的忠诚度,忠诚度的定义见下图(6)式。即与 x n x_n xn类簇 w j w_j wj的关系值除以与 x n x_n xn关系最近的类簇KaTeX parse error: Expected group after '^' at position 4: w_j^̲'
- 类簇 w j w_j wj与类 m m m的忠诚度定义为,任意属于 m m m的向量 x n x_n xn的与类簇 w j w_j wj的忠诚度的平均值
- 判定输入向量
x
x
x属于哪个类
m
m
m,则根据式(8),
x
x
x所属的类
k
k
k,使得(8)式值最大
()















 1001
1001











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









