









 本文探讨了如何在跨筒仓联合学习和隐私保护的背景下扩展公平性增强方法,提出FedFair方法,通过不侵犯隐私的联合估计,提升模型在分布式环境中的公平训练性能。DEGO公平度量被有效整合,解决新问题并展示了与现有方法如LCO和AgnosticFair的对比。
本文探讨了如何在跨筒仓联合学习和隐私保护的背景下扩展公平性增强方法,提出FedFair方法,通过不侵犯隐私的联合估计,提升模型在分布式环境中的公平训练性能。DEGO公平度量被有效整合,解决新问题并展示了与现有方法如LCO和AgnosticFair的对比。

cross device 跨设备 / cross silo 跨数据井
介绍
①我们能否轻松地扩展现有的加强公平的方法,以适应协作和隐私保护的需要?
NO:现有的公平性增强方法主要是在一个统一的可用训练数据集的假设下设计的,因此不能容易地解决分布式协作的需求,如跨筒仓联合学习,以及参与方的隐私保护。
②我们能否轻松扩展现有的联合学习,突出的协作和隐私保护框架,以加强模型构建的公平性?
NO:现有的联邦学习方法根本没有考虑机器学习模型的公平性。此外,为了获得模型作为对各方训练数据的中间结果的公平性,简单的设计可能会侵犯各方的隐私,如泄露各方数据的分布信息。正如在第II-B节中所讨论的,即使AgnostiFair[3],唯一声称结合联邦学习和公平的现有方法,也是相当原始的,并不能保证隐私保护的要求。
本文的工作:
1)提出了一种联合估计方法,在不侵犯任何一方数据隐私的情况下,准确估计模型的公平性。
2)证明了联合估计方法比局部估计模型对单个参与者的公平性更准确,这导致在跨竖井联合学习中具有更好的公平模型训练性能。
3)构建了新的FedFair问题;开发了一个有效的联合学习框架来解决这个问题,而不侵犯任何一方的数据隐私。
4)充分的的实验
相关工作
Fairness Enhancing Methods
现有的方法可分为①pre-processing methods②post-processing methods③In-processing methods
而:我们的方法还定制了学习过程,直接训练公平模型。然而,它与In-processing methods有很大的不同,因为我们的方法允许多方合作训练公平的模型,而不侵犯他们的数据隐私。
Fair Models and Federated Learning
- 经典的联合学习方法[5],[26]-[29]大多是为了保护隐私而设计的,而不是训练公平模型。
- AgnosticFair方法[3]试图通过在损失函数和公平性约束中为每个训练数据实例分配重估值,来训练能够很好地适应未知测试数据的公平模型。但是,它不能完全保护数据隐私,因为学习重估值需要对数据分布有很强的先验知识,还需要泄露每个参与方数据分布的敏感信息。
- 通过最小化受保护类上产生的最大训练损失,为机器学习模型引入了一个弱公平概念作为副产品。但这只能减轻训练过程的偏差,不能保证训练模型[30]的良好公平性。
- 协作公平方法[30]-[36]侧重于根据参与各方对联合学习过程的贡献来平衡支付给他们的报酬。(贡献评估)
公平度量
现有的公平度量方法
分为两类:
1)individual fairness:个体公平性[37],[38]通过评估一对相似实例从模型获得相似预测的可能性来衡量模型的公平性。
2)group fairness:群体公平性[9],[15],[25],[39],[40]通过评估一个模型的预测在预定义的一对保护组(例如,“女性”与“男性”)上的平衡程度来衡量模型公平性。
【众所周知,个体公平测量比群体公平测量[1],[41]更不稳定。因此,在本文中,我们关注群体公平度量。】
现有的工作
group fairness存在的问题:
许多群体公平度量指标,如异类影响[9]、人口均等[37]、[39]、[40]、平等几率和平等机会[15],都是基于模型的预测精度制定的。然而,由于模型的预测精度是一个非光滑和不可微的函数,要将这种公平性度量作为嵌入联邦模型训练算法中的公平性约束,即使不是完全不可能,也是非常困难的。
相关工作:
- 一些方法[3],[42]将基于预测精度的测量转换为平滑的代理约束。但是经过训练的模型的公平性性能受制于代理约束与原始公平性测量值[25]之间的近似误差。
- Xu等[41]和Cotter等[43]提出了一系列可以顺利集成到培训过程中的公平度量。但是,这些方法仍然不适用于我们的任务,因为它们需要知道每个保护组中包含的实例的一定比例,从而暴露参与者的隐私数据在保护组中的分布,从而侵犯了参与者的数据隐私。
- Hashimoto等[44]和Baharlouei等[45]开发了几种不考虑模型基本预测精度的测量方法,因此它们不能始终确保公平性,并可能潜在地破坏训练过程[15]、[37]的优化目标。
我们的工作——DEGO
我们提出了一个联合公平模型训练的新问题。我们的模型采用了名为DGEO[25]的通用公平度量,并成功地适应了DGEO,在不侵犯任何客户数据隐私的情况下实现了出色的联邦公平模型训练性能。
问题建模
DEGO
Model:f(θ) 关于 受保护类c 的DEGO:
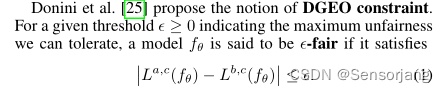
DEGO越小,说明对于c中的实例越公平
DEGO越大,说明对于c中的实例越不公平
FL公平模型训练

在满足公平性约束(2b)的前提下最小化FedratedLoss(Li(θ))
FadFair问题解决
问题分析
使用 Li(θ)ˆ 来近似代替 Li(θ)
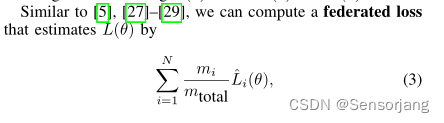
Li(θ)ˆ,其实就是全局Model f(θ) 在所有Client的所有样本实例上的Loss的平均值
Li(θ)ˆ 的计算不侵犯隐私,因为:①每个经验损失的口令Li(θ)都是由相应的客户端Ui私下计算的,所有的经验损失都被发送到云服务器上计算联邦损失。②对于每个客户机,云服务器只知道客户机的经验损失和私有数据集中的实例数量。换句话说,客户端不公开任何实例或任何数据分布信息。
真正的挑战是准确估算La,c(θ) - Lb,c(θ)。
局部估计方法——LCO问题

LCO问题的解θ是(ε+r)-公平,且概率不小于下限(1−σ2min)/r2。
不幸的是,这个下限在实际应用中可能很小,
因为σ21,…σ2N 当客户端私有数据实例数量不够多时可以较大。因此,解决LCO问题可能只有很小的概率获得良好的模型公平性性能。
而且,当大量的客户端引入大量的局部DGEO约束时,LCO问题甚至可能是不可行的,这些约束所引起的可行区域的交点由于σ21,…σ2N 的较大方差很有可能为空。
联邦估计方法——FedFair问题
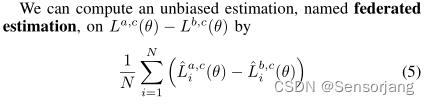

LCO与FedFair问题的求解
- 将FedFair问题转化为非凸-凹最小极大问题。然后,我们应用交替梯度投影(AGP)算法[4]来解决最小-最大问题,而不侵犯任何客户的数据隐私。
- 我们还将AGP扩展到以类似的隐私保护方式处理LCO问题。
使用AGP解决FedFair



【Algorithm 1 是否保护了每个客户端拥有的私有数据的隐私?】
YES:它以类似[5],[29],[46]的方式保护客户端的数据隐私。因为,在每一次迭代中,客户端之间不存在通信,客户端发送到云服务器的信息只包含了
ˆDi(θk), ∇ ˆDi(θk) and ∇ˆLi(θk), 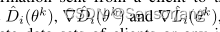
,这些信息不暴露客户端的私有数据集,也不暴露私有数据集的分布情况。
使用AGP解决LCO

实验
基线:
FedFair
LCO
AgnosticFair
ST(separate training)
FedAvg
EO(equalized odds)+FedAvg
CEO(calibrated equalized odds)+FedAvg
数据集:
ADULT、COMPAS、DRUG
指标:
FR:fairness = 1 − DEO(fθ),其中DEO(fθ)[25]从平等机会的概念[15]扩展来衡量模型fθ的不公平性。(Donini et al[25]认为,越小的DGEO通常表示越小的DEO(fθ),这意味着较好的公平性。公平的范围在0到1之间。公平值越大,说明模型fθ越公平。)
AC:accuracy
HM:harmonic mean,通过fθ的公平性和准确性的谐波平均值来评价它的整体性能
对于分别为N个客户生产N个不同模型的ST、EO和CEO,我们在测试数据集上报告N个模型的平均AC、平均FR 和 平均HM。
1、Fairness and Accuracy of Trained Models
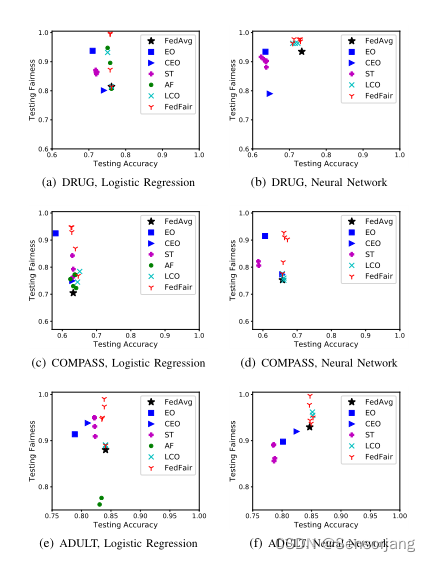
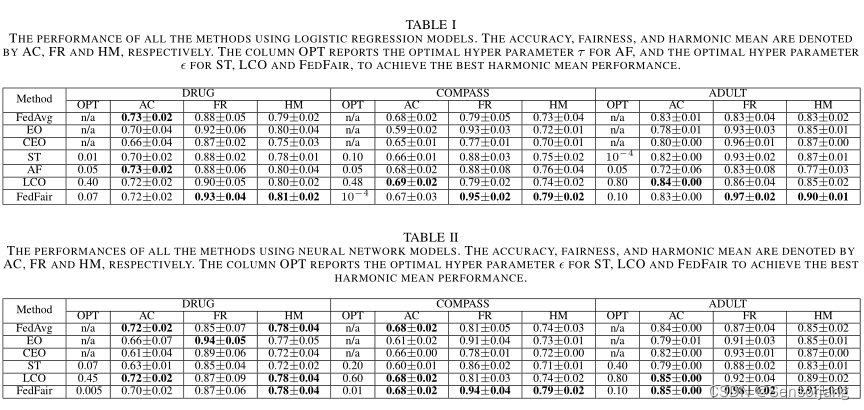
结果:
如图1所示,ST训练的模型在公平性和准确性上都表现不佳,因为在训练过程中客户之间缺乏协作。FedAvg训练的模型由于在训练过程中对公平性的忽略,无法获得良好的公平性。EO和CEO后处理的模型不能同时获得良好的公平性和良好的准确性,因为其公平性的提高通常是以牺牲精度[1]为代价的。
处理中的方法,如LCO、AF和FedFair,可以获得更好的结果,因为它们可以显式地在目标函数中施加准确性和公平性之间所需的权衡,以便在训练[19]期间找到良好的平衡。
LCO、AF和FedFair训练的模型精度基本相当,但FedFair的公平性性能最好。这证明了FedFair在训练准确率高的集市模型方面的出色表现。
分析:
①图1(a)中逻辑回归模型的准确性略优于图1(b)中相应神经网络模型的准确性,这是因为神经网络模型容易对DRUG的小训练数据进行过拟合。
②从图1中我们还可以得出结论,在大多数数据集上,LCO训练的模型的公平性要弱于FedFair,因为当?变得很小,这使得LCO训练的模型的公平性无法提高。相反,FedFair问题在ε值很小的情况下仍然是可行的,因此它能够训练出比LCO公平得多的模型,而在精度上只有很小的开销
2、Effect of Parameter ε
AFE:联邦估计的绝对值(the absolute value of the federated estimation )
DGEO:(前面提到的。DEGO越小越公平。)
fairness
accuracy
逻辑回归Model:
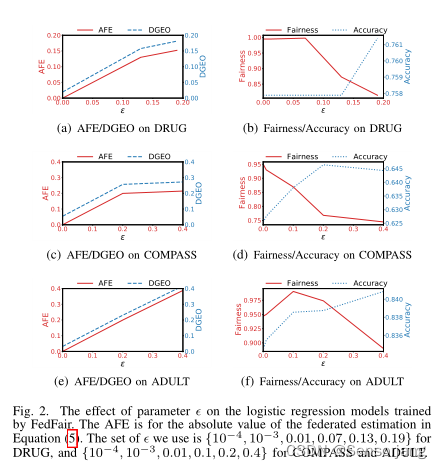
神经网络Model:

2(b) 2(d) 2(f) 与3(b) 3(d) 3(f) 差异大的原因:
这主要是由于神经网络模型的高模型复杂性和高非线性,其中一个更小的ε可作为正则化项,提高神经网络模型的测试精度。
**我们还可以从图3中观察到,神经网络下,更小的DGEO并不总是为神经网络模型带来更大的公平性。**这是因为当我们用交叉熵损失来训练神经网络模型[25]时,用于发展公平性的DEO(fθ)的概念并不等同于DGEO。然而,这并不会对FedFair的实际性能造成太大影响。
3、The influence of dropping clients on FedFair and LCO
我们在FedFair和LCO的每次迭代训练过程中随机掉线一定比例的客户端,并评估掉线客户端对训练模型HM的影响。
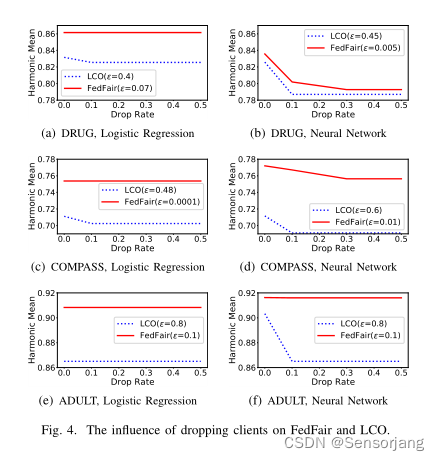
在大多数情况下,当下降率从0.0增加到0.1时,LCO训练的模型的谐波均值会下降。由于丢弃一个客户端将丢弃LCO问题对应的局部DGEO约束,如果在训练过程中丢弃一些占主导地位的活动局部DGEO约束,将降低LCO训练模型的公平性。
与LCO相比,FedFair对客户端丢失的鲁棒性要好得多。如图4(a), 4©和4(e)所示,FedFair训练的逻辑回归模型的调和均值在所有下降率下都保持在非常高的值不变。FedFair对删除客户端的这种出色的鲁棒性继承自联邦估计的鲁棒性,因为联邦估计是本地估计的平均值,这对删除的客户端非常鲁棒。
在训练神经网络模型时,FedFair对丢弃客户端的鲁棒性与训练线性模型略有不同。在图4(b)和4(d)中,在DRUG和COMPASS的小数据集上,FedFair训练的神经网络模型的谐波均值随着丢弃率的增加而减小。因为训练神经网络模型需要大量的数据,但是丢弃客户端会减少可用的私有数据集的数量,从而限制了客户之间的协作效率。然而,FedFair仍然非常健壮,可以在大型ADULT数据集上删除客户。如图4(f)所示,丢弃客户端并不影响FedFair训练的神经网络模型的HM。
总结
略
文章可能出现的错误或疑问请在评论区回复我。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









