










目录
在对离线任务进行优化时,一般来说有两种思路。一是参数优化,尽量提高CPU、内存利用率,或者减少spill率;二是SQL优化,减少性能较低的操作。
在比较json_tuple和get_json_object两个算子时,get_json_obeject的优点在于可以处理的 path更为丰富,能够支持正则、支持嵌套、取多层,缺点在于一次只能取一个值;json_tuple的优点在于可以一次取多个值,缺点在于只能处理同一级path。
因为一次可以取多个值而get_json_object需要取多次,所以json_tuple的性能就更高吗?这正是本文所将探讨的内容。
一、执行过程
如下是get_json_object的查询sql:
explain select
get_json_object(report_message, '$.msgBody.param') as param,
get_json_object(param, '$.role') as role,
get_json_object(param, '$.cpu_time') as cpu_time,
get_json_object(param, '$.session_id') as session_id,
get_json_object(param, '$.simulcast_id') as simulcast_id,
get_json_object(param, '$.server_addr') as server_ip
from
test_table
where
p_date = '20221012'得到结果如下所示:
Explain
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: test_table
filterExpr: (p_date = '20221012') (type: boolean)
Statistics: Num rows: 282587784 Data size: 36093178201 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: get_json_object(report_message, '$.msgBody.param') (type: string), get_json_object(param, '$.role') (type: string), get_json_object(param, '$.cpu_time') (type: string), get_json_object(param, '$.session_id') (type: string), get_json_object(param, '$.simulcast_id') (type: string), get_json_object(param, '$.server_addr') (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5
Statistics: Num rows: 282587784 Data size: 36093178201 Basic stats: COMPLETE Column stats: NONE
Limit
Number of rows: 100000
Statistics: Num rows: 100000 Data size: 12700000 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 100000 Data size: 12700000 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.TextInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: 100000
Processor Tree:
ListSink执行过程而言比较简单,get_json_object在select Operator算子中进行调用,输入数据量2亿+。
接下来看json_tuple,它的使用方式有两种,一种是直接select,另一种是配合lateral view 使用。
//1.直接select
explain select
json_tuple(get_json_object(report_message, '$.msgBody.param') ,'role','cpu_time','session_id','simulcast_id','server_addr') as (`role`,cpu_time,session_id,simulcast_id,server_addr)
from
test_table
where
p_date = '20221012'
//2.与lateral view一起使用
select
get_json_object(report_message, '$.msgBody.param') as param,
from
test_table
lateral view outer json_tuple(param,'role','cpu_time','session_id','simulcast_id','server_addr') tmp
as role,cpu_time,session_id,simulcast_id,server_addr
where
p_date = '20221012'看看他们分别的执行计划,先看直接select的:
Explain
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: test_table
filterExpr: (p_date = '20221012') (type: boolean)
Statistics: Num rows: 282587784 Data size: 36093178201 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: get_json_object(report_message, '$.msgBody.param') (type: string), 'role' (type: string), 'cpu_time' (type: string), 'session_id' (type: string), 'simulcast_id' (type: string), 'server_addr' (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5
Statistics: Num rows: 282587784 Data size: 36093178201 Basic stats: COMPLETE Column stats: NONE
UDTF Operator
Statistics: Num rows: 282587784 Data size: 36093178201 Basic stats: COMPLETE Column stats: NONE
function name: json_tuple
Limit
Number of rows: 100000
Statistics: Num rows: 100000 Data size: 12700000 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 100000 Data size: 12700000 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.TextInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: 100000
Processor Tree:
ListSink
json_tuple在UDTF Operator中执行,相比于get_json_object多了一个operator的操作。再来看看与lateral view一起使用的情况。
Explain
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: test_table
filterExpr: (p_date = '20221012') (type: boolean)
Statistics: Num rows: 282587784 Data size: 36093178201 Basic stats: COMPLETE Column stats: NONE
Lateral View Forward
Statistics: Num rows: 282587784 Data size: 36093178201 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: param (type: string)
outputColumnNames: param
Statistics: Num rows: 282587784 Data size: 36093178201 Basic stats: COMPLETE Column stats: NONE
Lateral View Join Operator
outputColumnNames: _col14, _col24, _col25, _col26, _col27, _col28
Statistics: Num rows: 565175568 Data size: 72186356402 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col14 (type: string), _col24 (type: string), _col25 (type: string), _col26 (type: string), _col27 (type: string), _col28 (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5
Statistics: Num rows: 565175568 Data size: 72186356402 Basic stats: COMPLETE Column stats: NONE
Limit
Number of rows: 100000
Statistics: Num rows: 100000 Data size: 12700000 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 100000 Data size: 12700000 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.TextInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Select Operator
expressions: get_json_object(report_message, '$.msgBody.param') (type: string), 'role' (type: string), 'cpu_time' (type: string), 'session_id' (type: string), 'simulcast_id' (type: string), 'server_addr' (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5
Statistics: Num rows: 282587784 Data size: 36093178201 Basic stats: COMPLETE Column stats: NONE
UDTF Operator
Statistics: Num rows: 282587784 Data size: 36093178201 Basic stats: COMPLETE Column stats: NONE
function name: json_tuple
outer lateral view: true
Lateral View Join Operator
outputColumnNames: _col14, _col24, _col25, _col26, _col27, _col28
Statistics: Num rows: 565175568 Data size: 72186356402 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col14 (type: string), _col24 (type: string), _col25 (type: string), _col26 (type: string), _col27 (type: string), _col28 (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5
Statistics: Num rows: 565175568 Data size: 72186356402 Basic stats: COMPLETE Column stats: NONE
Limit
Number of rows: 100000
Statistics: Num rows: 100000 Data size: 12700000 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 100000 Data size: 12700000 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.TextInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: 100000
Processor Tree:
ListSink
这个稍微复杂一点,可以画个图对比一下3种方式。
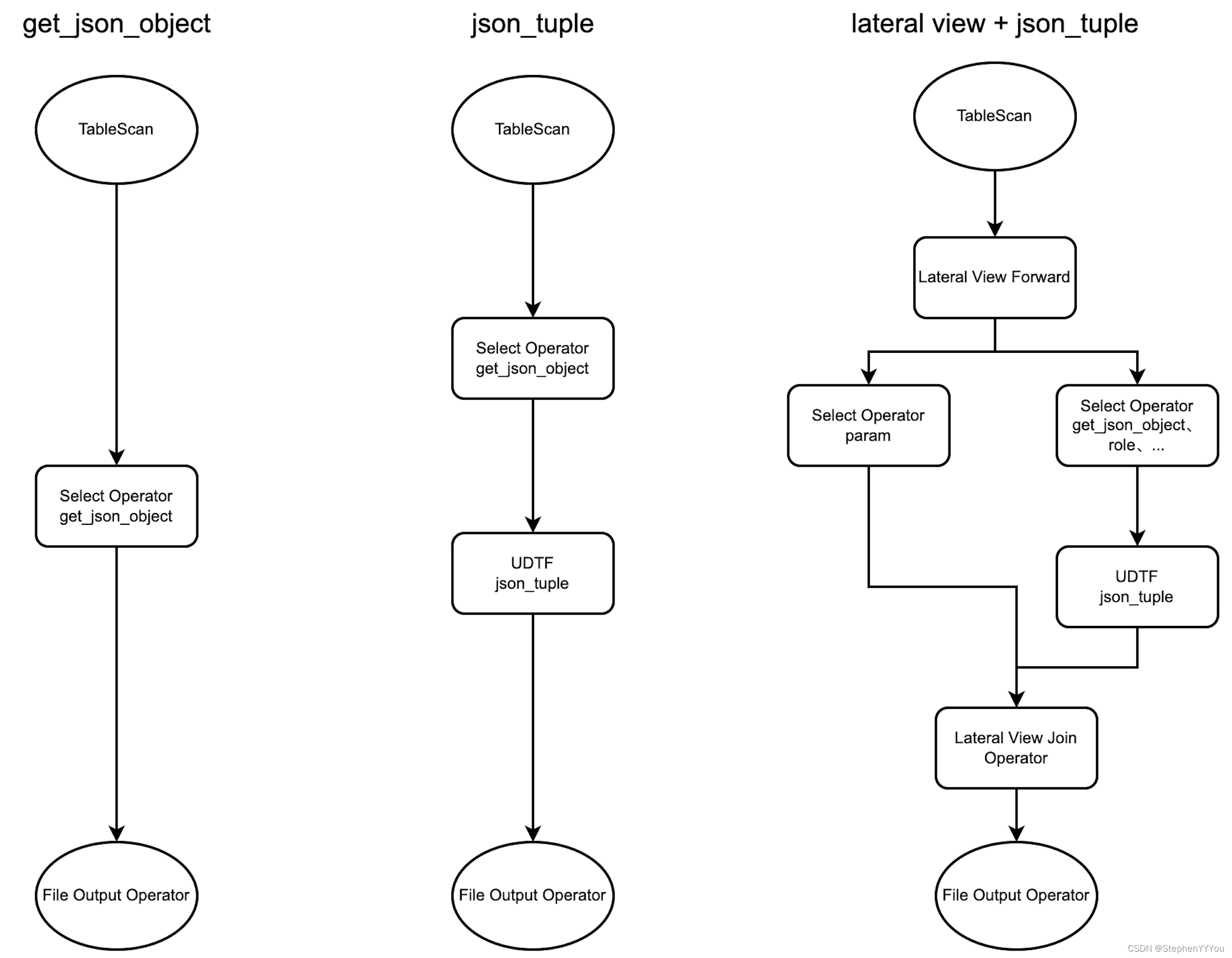 可以看到json_tuple相较于get_json_object更多了一个udtf Operator过程,而加上lateral view之后又更复杂了一点,多了Lateral view join的过程,但需要注意的是,虽然是名叫join,但是因为reduce过程并且join之前没有file output过程,所以Lateral view join只是数据的连接而没有shuffle过程。
可以看到json_tuple相较于get_json_object更多了一个udtf Operator过程,而加上lateral view之后又更复杂了一点,多了Lateral view join的过程,但需要注意的是,虽然是名叫join,但是因为reduce过程并且join之前没有file output过程,所以Lateral view join只是数据的连接而没有shuffle过程。
所以从执行过程,看不出json_tuple的性能优势。
二、源码比较
看看get_json_object的代码:
public Text evaluate(String jsonString, String pathString) {
...
...
// Cache extractObject
Object extractObject = extractObjectCache.get(jsonString);
if (extractObject == null) {
if (unknownType) {
try {
// 解析jsonString->jsonArray
extractObject = objectMapper.readValue(jsonString, LIST_TYPE);
} catch (Exception e) {
// Ignore exception
}
if (extractObject == null) {
try {
// 解析jsonString->jsonObject
extractObject = objectMapper.readValue(jsonString, MAP_TYPE);
} catch (Exception e) {
return null;
}
}
} else {
JavaType javaType = isRootArray ? LIST_TYPE : MAP_TYPE;
try {
extractObject = objectMapper.readValue(jsonString, javaType);
} catch (Exception e) {
return null;
}
}
//缓存解析出来的jsonNode
extractObjectCache.put(jsonString, extractObject);
}
//
for (int i = pathExprStart; i < pathExpr.length; i++) {
if (extractObject == null) {
return null;
}
//解析到最后一层,同时缓存匹配的field object
extractObject = extract(extractObject, pathExpr[i], i == pathExprStart && isRootArray);
}
Text result = new Text();
if (extractObject instanceof Map || extractObject instanceof List) {
try {
//结果
result.set(objectMapper.writeValueAsString(extractObject));
} catch (Exception e) {
return null;
}
} else if (extractObject != null) {
result.set(extractObject.toString());
} else {
return null;
}
return result;
}可以看到 JsonString实际上只会被解析一次,然后就会被缓存起来,更新策略是LRU,所以理论上来说,即使使用get_json_object取多个值,也不会造成太大的性能损耗。
接下来看看json_tuple的源码:
//1.初始化,会解析传入的参数,做正确性校验
public StructObjectInspector initialize(ObjectInspector[] args)
throws UDFArgumentException {
...
...
// construct output object inspector
ArrayList<String> fieldNames = new ArrayList<String>(numCols);
ArrayList<ObjectInspector> fieldOIs = new ArrayList<ObjectInspector>(numCols);
for (int i = 0; i < numCols; ++i) {
// column name can be anything since it will be named by UDTF as clause
fieldNames.add("c" + i);
// all returned type will be Text
fieldOIs.add(PrimitiveObjectInspectorFactory.writableStringObjectInspector);
}
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs);
}
//2.在process函数中进行具体操作
public void process(Object[] o) throws HiveException {
...
...
//与get_json_object一样,jsonString->jsonObject之后会缓存起来
String jsonStr = ((StringObjectInspector) inputOIs[0]).getPrimitiveJavaObject(o[0]);
if (jsonStr == null) {
forward(nullCols);
return;
}
try {
Object jsonObj = jsonObjectCache.get(jsonStr);
if (jsonObj == null) {
try {
jsonObj = MAPPER.readValue(jsonStr, MAP_TYPE);
} catch (Exception e) {
reportInvalidJson(jsonStr);
forward(nullCols);
return;
}
jsonObjectCache.put(jsonStr, jsonObj);
}
...
...
for (int i = 0; i < numCols; ++i) {
if (retCols[i] == null) {
retCols[i] = cols[i]; // use the object pool rather than creating a new object
}
Object extractObject = ((Map<String, Object>)jsonObj).get(paths[i]);
if (extractObject instanceof Map || extractObject instanceof List) {
retCols[i].set(MAPPER.writeValueAsString(extractObject));
} else if (extractObject != null) {
retCols[i].set(extractObject.toString());
} else {
retCols[i] = null;
}
}
//收集结果
forward(retCols);
return;
} catch (Throwable e) {
LOG.error("JSON parsing/evaluation exception" + e);
forward(nullCols);
}
}与get_json_object一样,json_tuple也会将解析生成的jsonObject缓存起来,保证一个json只被解析一次。
从源码上来看,似乎get_json_object和json_tuple之间也没有明显的性能差异。
三、实验论证
实验证实一下。运行一下第一部分中的sql,看一下具体的执行效果。
| get_json_object | json_tuple | lateral view + json_tuple | |
| mapCpuVcores | 1 | 1 | 1 |
| mapMemMb | 2560 | 2560 | 2560 |
| reduceCpuVcores | 1 | 1 | 1 |
| reduceMemMb | 3072 | 3072 | 3072 |
| 作业GC时间 | 18.14 s | 18.80 s | 20.96 s |
| 作业CPU消耗时间 | 565.72 s | 539.41 s | 604.52 s |
| 作业执行时间 | 42.29 s | 59.20 s | 109.59 s |
| 作业内存使用率 | 74.14% | 73.88 % | 73.94 % |
| 作业CPU使用率 | 44.74% | 45.07 % | 32.05 % |
可以看到,实际上get_json_object和json_tuple性能上没有太大差异,反倒是使用了lateral view + json_tuple时,性能损耗明显变大。
四、总结
get_json_object与json_tuple的性能基本没有差别,差别在于二者的功能不一样。lateral view适用于一行->多行的场景,lateral view + json_tuple对开发者友好,但是性能损耗较大,除非有嵌套多字段解析和炸裂操作,否则不建议使用。
文章分享就到这里,有误的地方欢迎指出,也欢迎大家关注我的公众号 咸鱼说数据 一起讨论数据开发的相关内容。感谢大家。















 1361
1361











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









