









 本文介绍了如何使用Python进行标准正态同质性检验(SNHT)进行突变点检测,以NDVI时间序列为例。SNHT通过标准化处理检测时间序列数据的均值突变,适用于气候、环境科学等领域。文中提供了读取CSV数据的示例,并强调了知识产权的重要性。
本文介绍了如何使用Python进行标准正态同质性检验(SNHT)进行突变点检测,以NDVI时间序列为例。SNHT通过标准化处理检测时间序列数据的均值突变,适用于气候、环境科学等领域。文中提供了读取CSV数据的示例,并强调了知识产权的重要性。
作者:CSDN @ _养乐多_
本文将介绍标准正态同质性检验(Standard Normal Homogeneity Test,SNHT) 突变点检测代码。以 NDVI 时间序列为例。输入数据可以是csv,一列NDVI值,一列时间。代码可以扩展到遥感时间序列突变检测(突变年份、突变幅度等)中。
结果如下图所示,
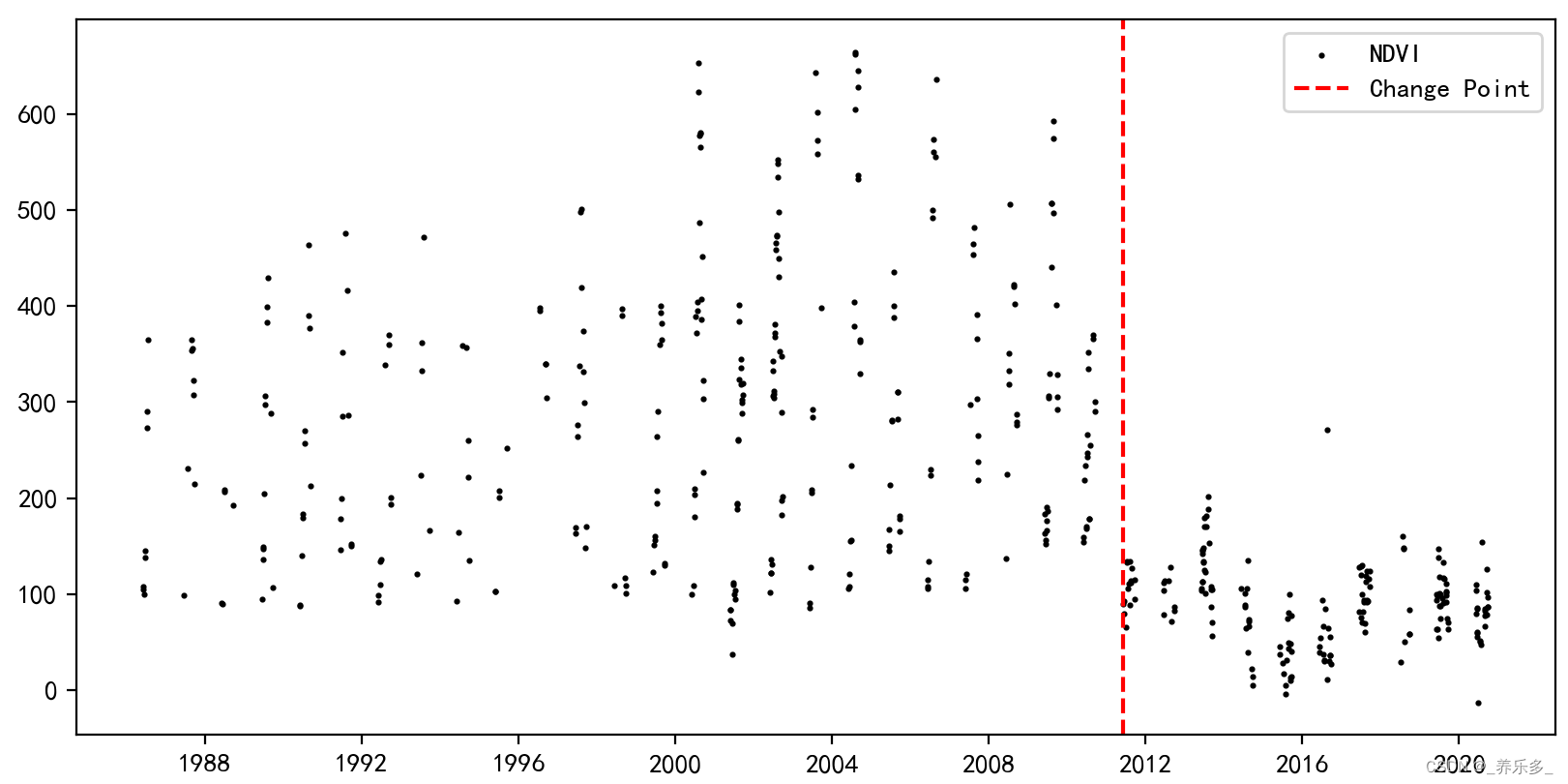
一、准备数据
测试数据(0积分下载):https://download.csdn.net/download/qq_35591253/88895803
该数据是GEE上提取的,参考博客《GEE:基于Landsat5/7/8/9数据提取一个点的NDVI时间序列(1986-2024)》
二、SNHT介绍和代码
Standard Normal Homogeneity Test (SNHT) 是一种用于检测时间序列数据同质性的统计检验方法。
2.1 原理和步骤
SNHT的核心原理是通过标准化处理来检验时间序列数据的均值是否存在突变点。 这种检验方法在气候学、环境科学和地球物理学等领域中被广泛应用,用以检测气温、降水、风速等数据的同质性。具体步骤如下:
- 计算时间序列的均值和标准差:首先需要计算出整个时间序列数据的均值和标准差。
- 标准化处理:将时间序列数据转换为标准正态分布,即对每个数据点减去均值后除以标准差,得到标准化的时间序列。
- 分割时间序列:在潜在的变点处将时间序列分割成两部分,并分别计算前后两段的均值。
- 构建统计量:对于每一个可能的变点,构建一个统计量,该统计量反映了在该点分割前后两段数据的均值差异。
- 显著性检验:通过比较统计量与某个临界值的大小关系来判断变点是否显著。通常,会选择一个置信水平(如95%),并找到对应的临界值。如果统计量大于临界值,则认为在该点存在显著的均值变化,即存在突变点。
- 确定变点:对所有可能的变点进行检验,找到统计量最大的点作为最终的变点。
2.2 核心函数
def SNHT_change_point_detection(inputdata):
inputdata = np.array(inputdata)
mean_value = np.mean(inputdata)
length = inputdata.shape[0]
k_range = range(1, length)
standard_deviation = np.sqrt(np.sum((inputdata-np.mean(inputdata))*2)/(length-1))
Tk_values = [x*(np.sum((inputdata[0:x]-mean_value)/standard_deviation)/x)**2 + (length-x)*(np.sum((inputdata[x:length]-mean_value)/standard_deviation)/(length-x))**2 for x in k_range]
max_Tk = np.max(Tk_values)
change_point = list(Tk_values).index(max_Tk) + 1
return change_point
三、读取csv格式时序数据的示例
示例代码以csv格式数据为例子,当然可以扩展到遥感时间序列中,遥感时序数据的分析代码框架参考博客《python:处理遥感时间序列(代码框架),并保存结果》
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 从CSV文件中读取数据
df = pd.read_csv('测试数据\\ee-chart.csv')
df = pd.DataFrame(df).dropna()
df["system:time_start"] = pd.to_datetime(df["system:time_start"], format='mixed')
df['time'] = df['system:time_start']
seasonal_ts = df
nSTS = len(seasonal_ts)
# 取序列的前80%
percentile_start = 0 # 74
percentile_end = 100 # 86
percentile_index_start = int(nSTS * percentile_start / 100)
percentile_index_end = int(nSTS * percentile_end / 100)
seasonal_ts1 = seasonal_ts[percentile_index_start : percentile_index_end]
seasonal_ts = seasonal_ts1['NDVI'].values
time = seasonal_ts1['time'].values
def SNHT_change_point_detection(inputdata):
inputdata = np.array(inputdata)
mean_value = np.mean(inputdata)
length = inputdata.shape[0]
k_range = range(1, length)
standard_deviation = np.sqrt(np.sum((inputdata-np.mean(inputdata))*2)/(length-1))
Tk_values = [x*(np.sum((inputdata[0:x]-mean_value)/standard_deviation)/x)**2 + (length-x)*(np.sum((inputdata[x:length]-mean_value)/standard_deviation)/(length-x))**2 for x in k_range]
max_Tk = np.max(Tk_values)
change_point = list(Tk_values).index(max_Tk) + 1
return change_point
# 检测变点
change_point = SNHT_change_point_detection(seasonal_ts)
# 绘制图形
plt.figure()
plt.scatter(time, seasonal_ts, color='black', label='NDVI', s=1.5)
plt.axvline(x = seasonal_ts1['time'].values[change_point], color='r', linestyle='--', label='Change Point')
plt.legend()
plt.show()
声明:
本人作为一名作者,非常重视自己的作品和知识产权。在此声明,本人的所有原创文章均受版权法保护,未经本人授权,任何人不得擅自公开发布。
本人的文章已经在一些知名平台进行了付费发布,希望各位读者能够尊重知识产权,不要进行侵权行为。任何未经本人授权而将付费文章免费或者付费(包含商用)发布在互联网上的行为,都将视为侵犯本人的版权,本人保留追究法律责任的权利。
谢谢各位读者对本人文章的关注和支持!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











