






以点(.)开头的在Linux下为隐藏文件
在Linux系统中,文件名以点(.)开头通常具有特殊的含义,这种文件通常被称为“隐藏文件”。隐藏文件在Linux系统中不会在普通的文件浏览器中显示,除非用户显式地设置文件浏览器显示隐藏文件。这种设计有助于隐藏系统和配置文件,以及其他用户可能不需要直接操作的文件,从而保持文件系统的整洁性和安全性。
在Linux系统中,以点开头的文件通常具有以下一些常见特点:
-
隐藏文件:文件管理器默认不显示以点开头的文件,这些文件对于用户来说是隐藏的。
-
配置文件:许多以点开头的文件是用来存储应用程序或系统的配置信息,如
.bashrc、.gitignore等。 -
临时文件:有时以点开头的文件用于存储临时数据,例如
.tmp文件。 -
配置目录:类似于文件,以点开头的目录(如
.config)也可以用来存储配置信息。
在Windows系统中,隐藏文件与Linux系统中以点开头的隐藏文件有些不同。Windows系统中隐藏文件的隐藏属性是通过文件属性中的“隐藏”属性来控制的。隐藏文件在Windows资源管理器中默认是不可见的,用户需要在文件夹选项中启用“显示隐藏的文件、文件夹和驱动器”选项才能看到这些隐藏文件。
隐藏文件在Windows系统中可以具有以下一些常见特点:
-
系统文件:一些系统文件和文件夹被设置为隐藏,以防止用户误删除或编辑这些关键文件,例如
boot.ini。 -
临时文件:某些应用程序会生成临时文件,并将这些文件设置为隐藏,以避免用户手动修改或删除。
-
配置文件:类似于Linux系统,Windows系统中也有一些应用程序的配置文件被设置为隐藏,以防止用户意外编辑或删除这些文件。
如果您想查看在Windows系统中隐藏的文件,可以按照以下步骤操作:
-
通过资源管理器:
- 打开“文件资源管理器”。
- 点击顶部菜单中的“查看”选项。
- 在“显示/隐藏”区域中,勾选“隐藏项目”。
-
通过命令行:
- 使用
dir /a命令来显示所有文件,包括隐藏文件。 - 使用
attrib命令来查看和修改文件的属性,包括隐藏属性。
- 使用
attrib是Windows命令行中一个用于修改文件属性的命令。通过attrib命令,您可以查看和更改文件或目录的属性,包括隐藏属性、只读属性、系统属性等。
语法:
attrib [+R | -R] [+A | -A] [+S | -S] [+H | -H] [drive:][path]filename [/S [/D]]
参数:
+R:设置只读属性。-R:取消只读属性。+A:设置存档属性。-A:取消存档属性。+S:设置系统文件属性。-S:取消系统文件属性。+H:设置隐藏属性。-H:取消隐藏属性。[drive:][path]filename:指定要处理的文件或目录。/S:对指定目录中的所有文件执行操作。/D:对目录进行操作。
示例用法:
-
查看文件属性:
attrib filename -
设置文件为只读:
attrib +R filename -
取消文件只读属性:
attrib -R filename -
设置文件为隐藏:
attrib +H filename -
取消文件隐藏属性:
attrib -H filename -
将目录及其子目录下所有文件设置为只读:
attrib +R /S /D directory
通过attrib命令,您可以方便地管理文件和目录的属性,包括设置只读、存档、系统和隐藏属性等。请注意,在使用该命令时要小心谨慎,确保不会对系统文件或重要文件造成意外更改。
创建一个空文件需要占有磁盘空间
在文件系统中,创建一个空文件实际上会占据一定的磁盘空间。即使文件内容为空,文件系统也需要分配一定的存储空间来存储文件的元数据(文件名、权限等)以及文件的大小信息。这个分配的空间通常称为“簇”或“块”。
在大多数现代文件系统中,文件系统以簇为单位来分配存储空间。即使文件内容为空,文件系统也会分配至少一个簇的空间来存储这个文件。这意味着即使文件非常小,也会占用一个最小簇的空间,这个簇的大小取决于文件系统的配置。
举例来说,如果文件系统的簇大小为4KB,那么一个大小为1KB的空文件也会占用4KB的磁盘空间。这是因为文件系统以簇为单位来分配空间,而不是以文件实际大小来分配。
因此,尽管空文件不包含实际数据,但在文件系统层面上,仍然需要分配一定的磁盘空间来存储文件的元数据和分配的簇。这也是为了维护文件系统的结构和元数据信息。
文件=文件内容数据+文件属性数据(元数据)
.,..
在计算机中通常有特殊含义:
-
.:在文件系统中,.代表当前目录,表示当前所在的目录。 -
..:..代表父目录,即当前目录的上一级目录。
路径分隔符
在 Linux 和 Windows 中,路径分隔符是不同的。
-
Linux 使用正斜杠
/作为路径分隔符。例如:/home/user/Documents/file.txt -
Windows 使用反斜杠
\作为路径分隔符。例如:C:\Users\Username\Documents\file.txt
这种差异源于操作系统的设计和历史发展,而在不同操作系统上,路径分隔符的使用是为了指示文件的位置或路径。当编写代码或指定文件路径时,需要注意使用正确的路径分隔符,以确保程序在不同操作系统上的兼容性。
绝对路径与相对路径
绝对路径:绝对路径是文件或目录在文件系统中的完整位置,从根目录开始一直描述到目标文件或目录的路径。
相对路径:相对路径描述一个文件或目录相对于另一个参考位置的位置。这个参考位置可以是当前工作目录或另一个文件或目录
热点路径
"热点路径"通常指的是在一个系统或应用程序中频繁访问的路径,可以是文件系统中的文件路径或者网络中的地址路径。在性能优化和系统调优方面,关注和优化热点路径可以显著提高系统的性能和响应速度。
在软件开发或系统优化中,关注热点路径可能涉及以下方面:
-
磁盘 I/O:如果某些文件路径被频繁读取或写入,这些路径就成为热点路径。优化这些路径的访问方式、缓存机制或存储结构可以提高磁盘 I/O 性能。
-
网络请求:在网络应用程序中,某些接口或资源的访问频率较高,这些请求路径也可以被视为热点路径。对于这些路径,可以考虑使用缓存、CDN 加速或负载均衡等技术进行优化。
-
数据库查询:数据库中某些查询路径可能会被频繁执行,成为热点路径。通过索引优化、查询优化、缓存查询结果等方法可以改善数据库性能。
-
代码路径:在软件开发中,某些代码路径可能会被频繁执行,成为热点路径。通过代码优化、算法优化等方式提高这些路径的执行效率。
优化热点路径可以帮助系统更有效地利用资源,提高系统整体性能和响应速度。不同类型的系统可能有不同的热点路径,因此需要根据具体情况进行分析和优化。
ls 指令
语法: ls [选项][目录或文件]
功能:对于目录,该命令列出该目录下的所有子目录与文件。对于文件,将列出文件名以及其他信息。
常用选项:
-
-a:列出目录下的所有文件,包括以.开头的隐含文件。
例子:ls -a -
-d:将目录象文件一样显示,而不是显示其下的文件。
例子:ls -d directory_name -
-i:输出文件的i节点的索引信息。
例子:ls -ai file_name -
-k:以k字节的形式表示文件的大小。
例子:ls -alk file_name -
-l:列出文件的详细信息。
例子:ls -l -
-n:用数字的UID(用户标识)和GID(组标识)代替名称。
例子:ls -n -
-F:在每个文件名后附上一个字符以说明该文件的类型。
例子:ls -F -
-r:对目录反向排序。
例子:ls -r -
-t:以时间排序。
例子:ls -t -
-s:在文件名后输出该文件的大小。
例子:ls -s -
-R:列出所有子目录下的文件(递归)。
例子:ls -R -
-1:一行只输出一个文件。
例子:ls -1
whoami指令
whoami 是一个常用的命令,用于显示当前登录用户的用户名。在 Linux 和 Unix 系统中,whoami 命令通常用于确定当前会话的用户身份。执行 whoami 命令后,系统会返回当前登录用户的用户名。
示例:
$ whoami
执行上述命令后,系统将显示当前用户的用户名,这有助于确认当前以哪个用户身份登录系统。
pwd指令
pwd 是一个常用的命令,用于显示当前工作目录的路径。在 Linux 和 Unix 系统中,pwd 命令通常用于确定当前所处的目录位置。
示例:
$ pwd
执行上述命令后,系统将返回当前工作目录的完整路径。
cd 指令
Linux系统中,磁盘上的文件和目录被组成一棵目录树,每个节点都是目录或文件。
语法:cd 目录名
功能:改变工作目录。将当前工作目录改变到指定的目录下。
cd ~:进入用户家目
cd -:返回最近访问目录touch指令
语法:touch [选项] 文件名
功能:touch命令参数可更改文档或目录的日期时间,包括存取时间和更改时间,或者新建一个不存在的文件。
常用选项:
-a、--time=atime、--time=access、--time=use:仅更改存取时间。-c、--no-create:不创建任何文件。-d:使用指定的日期时间,而不是当前时间。-f:此选项在Linux中忽略不处理,仅解决BSD版本touch命令的兼容性问题。-m、--time=mtime、--time=modify:仅更改修改时间。-r:将指定文件或目录的日期时间设置为与参考文件或目录的日期时间相同。-t:使用指定的日期时间,而不是当前时间。
touch 是一个常用的命令,用于创建空白文件或者更新文件的访问和修改时间戳。在 Linux 和 Unix 系统中,touch 命令可以执行以下操作:
-
创建空白文件:如果指定的文件不存在,
touch命令将创建一个空白文件。示例:
$ touch example.txt -
更新文件时间戳:如果文件已经存在,
touch命令将更新文件的访问时间和修改时间为当前时间。示例:
$ touch example.txt -
指定时间戳:您还可以使用
-t选项来指定要设置的时间戳。示例:
$ touch -t 202108291200 example.txt
使用 -r 选项将 file2.txt 的日期时间设置为与 file1.txt 相同:
$ touch -r file1.txt file2.txtstat指令
stat 是一个在 Unix 和 Linux 系统中用于显示文件或文件系统状态的命令。stat 命令提供了有关文件的详细信息,包括文件的权限、类型、大小、时间戳等。
以下是 stat 命令的基本语法和一些常见用法:
-
基本语法:
stat [选项] 文件名 -
常见选项:
-c:自定义输出格式。-t:指定时间格式。-f:显示文件系统状态而非文件状态。-L:跟随符号链接。-x:显示扩展文件系统信息。
-
示例用法:
-
显示文件详细信息:
$ stat filename -
显示文件系统状态而非文件状态:
$ stat -f directoryname -
显示扩展文件系统信息:
$ stat -x filename -
自定义输出格式:
$ stat -c "File: %n Size: %s bytes"
-
- Access Time: 最后访问文件的时间戳(因为对于频繁访问会造成系统IO负担,所以现在是达到设定访问次数或时间时长才更新时间)。
- Modify Time: 最后修改文件的时间戳(操作了文件就算修改,即使没改内容)。
- Change Time: 文件状态改变的时间戳(文件属性改变就会更改)。
- Birth Time: 文件创建的时间戳(touch file不会改变,文件写了会改变)。
mkdir指令
mkdir 是一个常用的命令,用于在 Unix 和类 Unix 系统中创建目录。下面是一些关于 mkdir 命令的基本用法和示例:
基本语法:
mkdir [选项] 目录名
常见选项:
-p:递归创建目录,即如果上级目录不存在也一并创建。-m:设置新建目录的权限模式。--mode:设置新建目录的权限模式。-v:显示创建的目录信息。
示例用法:
-
创建一个名为
mydir的目录:mkdir mydir -
递归创建目录
parent/child:mkdir -p parent/child -
创建一个目录并设置权限为
rwxr-xr--:mkdir -m 754 mydir -
创建目录并显示创建信息:
mkdir -v mydir
od
在Linux中,od是一个命令行工具,用于以不同的格式查看文件的内容。od代表"octal dump",即八进制转储。这个工具可以将文件内容以各种不同的格式(如八进制、十六进制、ASCII等)进行显示,通常用于查看文件的二进制数据或非文本文件的内容。
一般用法:
od [选项] [文件名]
常用选项:
-t:指定输出格式,如-tc表示以ASCII字符形式输出。-A:指定显示的字符集,如-A n表示使用 n 类字符集。-j:跳过指定的字节数开始显示。-N:显示指定的字节数。-b:以八进制格式显示。-x:以十六进制格式显示。-c:以ASCII字符格式显示。-s:跳过指定的字节数开始显示。
示例用法:
-
显示文件内容的十六进制格式:
od -x file.txt -
显示文件内容的ASCII字符格式:
od -c file.txt -
显示文件内容的八进制格式,每行显示16个字节:
od -t o1 -w16 file.txt -
显示文件内容的八进制格式,跳过前100个字节:
od -j100 -t o1 file.txt
od命令在处理二进制文件或者需要查看文件内容的原始数据时非常有用,可以帮助用户以不同的格式查看文件的内容,从而更好地理解文件的结构和内容。
objcopy
objcopy 是 GNU Binutils 软件包中的一个命令行实用工具。它用于复制和转换目标文件。这个工具允许您创建一个目标文件的副本,可能会在过程中更改其格式或其他属性。
以下是 objcopy 的基本用法示例:
objcopy [选项] 输入文件 输出文件
objcopy 的一些常见选项包括:
-O 格式:指定输出格式(例如,binary、ihex、elf32-i386)。--strip-all:从输出文件中删除所有符号和重定位信息。--add-symbol:向输出文件添加一个符号。--rename-section oldname=newname:重命名一个节。
# 示例1: 复制二进制文件
objcopy -I binary -O binary input.bin output.bin
# 示例2: 移除调试信息
objcopy --strip-debug program_with_debug program_stripped
# 示例3: 添加新的段
objcopy --add-section .extra_data=data_file.bin executable.bin new_executable.bin
# 示例4: 删除特定段
objcopy --remove-section .debug_info program.elf program_no_debug.elf
# 示例5: 转换文件格式
objcopy -I ihex -O binary input.hex output.binobjdump
objdump是GNU Binutils工具包中的另一个实用程序,用于显示有关二进制目标文件的信息。它可以查看可执行文件、目标文件、共享库和核心转储文件的内容。objdump可以显示二进制文件的各种信息,如目标文件的符号表、段的内容、反汇编代码等。
以下是一些常见用法和示例,说明如何使用objdump命令:
示例1: 显示目标文件的符号表
objdump -t executable_file
示例2: 反汇编可执行文件
objdump -d executable_file
示例3: 显示目标文件的段内容
objdump -x executable_file
示例4: 显示核心转储文件的信息
objdump -p core_dump_file
示例5: 显示共享库的符号表
objdump -T shared_library-a或--archive-headers:显示存档头信息-f或--file-headers:显示整体文件头内容-p或--private-headers:显示特定对象格式的文件头内容-h或--[section-]headers:显示节头内容-x或--all-headers:显示所有头部内容-d或--disassemble:显示可执行部分的汇编内容-D或--disassemble-all:显示所有部分的汇编内容
objdump 命令的 -s 选项用于显示目标文件的内容,包括指定节的十六进制和ASCII表示形式。
objdump 命令的 -S 选项用于显示源代码和汇编代码的混合输出。这个选项可以帮助您查看源代码和对应的汇编代码之间的关联。
rmdir指令 && rm 指令
rmdir指令:rmdir是一个用于删除空目录的命令。如果目录中包含文件或子目录,rmdir将无法删除该目录,并会显示一个错误消息。基本语法如下:
rmdir [OPTION]... DIRECTORY...
-
一般选项:
-p:递归删除目录及其空父目录,如果在删除后目标目录为空,则删除父目录。-v:显示详细信息。--help:显示帮助信息。
-
rm指令:rm是用于删除文件或目录的命令。它可以删除单个文件、多个文件,以及非空目录。基本语法如下:
rm [OPTION]... FILE...
- 一般选项:
-r,-R:递归删除目录及其内容。-f:强制删除,不显示任何提示。-i:互动模式,删除前提示确认。-v:显示详细信息。--help:显示帮助信息。
需要特别注意的是 rm 是一个非常强大的命令,使用时要小心,避免误删重要文件。建议在使用 rm 删除文件时谨慎操作,特别是在使用通配符或 -r 选项时。
man指令
man 是一个在 Unix 和类 Unix 系统上使用的命令行工具,用于查看系统上安装的各种命令的手册页面(manual pages)。man 命令通常用于查找关于特定命令的文档、语法、选项和示例。
一般语法:
man [选项] [命令名称]
常用选项:
-f:显示与关键字匹配的所有手册页面的简短描述。-k:搜索手册页和描述,类似于apropos命令。-a:显示所有匹配的手册页面,而不仅仅是第一个匹配。-u:更新man的预格式化页面索引。-l:指定使用的手册页面的语言。-M:指定搜索手册页面的路径。-s:指定要查看的手册页面的部分。-h:显示帮助信息。
示例用法:
查看特定命令的手册页面:
man ls
这将显示 ls 命令的手册页面,包括命令的用法、选项和示例。
搜索手册页面:
man -k keyword
这将搜索包含指定关键字的所有手册页面。
显示手册页面的不同部分:
man 5 crontab
这将显示 crontab 命令的配置文件格式,因为在 crontab 命令的手册页面中,5 部分通常用于描述文件格式。
Linux的命令有很多参数,我们不可能全记住,我们可以通过查看联机手册获取帮助。访问Linux手册页的命令是 man 语法: man [选项] 命令
常用选项
-k 根据关键字搜索联机帮助
num 只在第num章节找
-a 将所有章节的都显示出来,比如 man printf 它缺省从第一章开始搜索,知道就停止,用a选项,当按
下q退出,他会继续往后面搜索,直到所有章节都搜索完毕。
解释一下,面手册分为8章
1 是普通的命令
2 是系统调用,如open,write之类的(通过这个,至少可以很方便的查到调用这个函数,需要加什么头文
件)
3 是库函数,如printf,fread4是特殊文件,也就是/dev下的各种设备文件
5 是指文件的格式,比如passwd, 就会说明这个文件中各个字段的含义
6 是给游戏留的,由各个游戏自己定义
7 是附件还有一些变量,比如向environ这种全局变量在这里就有说明
8 是系统管理用的命令,这些命令只能由root使用,如ifconfigcp指令
语法:cp [选项] 源文件或目录 目标文件或目录
功能: 复制文件或目录
说明: cp指令用于复制文件或目录,如同时指定两个以上的文件或目录,且最后的目的地是一个已经存在的目录, 则它会把前面指定的所有文件或目录复制到此目录中。若同时指定多个文件或目录,而最后的目的地并非一个已存在的目录,则会出现错误信息。
常用选项:
-f 或 --force 强行复制文件或目录, 不论目的文件或目录是否已经存在。
-i 或 --interactive 覆盖文件之前先询问用户。
-r递归处理,将指定目录下的文件与子目录一并处理。若源文件或目录的形态,不属于目录或符号链 接,则一律视为普通文件处理。
-R 或 --recursive递归处理,将指定目录下的文件及子目录一并处理。
-r, -R:递归地复制目录及其内容。-i:在覆盖目标文件之前进行提示。-u:仅在源文件比目标文件新或目标文件不存在时才复制。-v:详细显示复制的操作。-a, --archive:保持原文件的属性(包括所有者、组、权限等)。-f:强制复制,覆盖目标文件而不提示。-n:不覆盖已存在的目标文件。-b:在覆盖目标文件之前,为目标文件创建备份。
示例用法:
简单复制文件:
cp file1.txt file2.txt
这将把 file1.txt 复制到 file2.txt。
复制目录及其内容:
cp -r dir1/ dir2/
这将递归地复制 dir1 目录及其所有内容到 dir2 目录。
保持原文件属性:
cp -a source_file destination_file
这将保持 source_file 的所有属性,包括所有者、组和权限,并将其复制到 destination_file。
强制复制并覆盖目标文件:
cp -f file1.txt file2.txt
这将强制复制 file1.txt 到 file2.txt,覆盖现有的 file2.txt。
mv指令
mv命令是move的缩写,可以用来移动文件或者将文件改名(move (rename) files)。
mv 命令通常用于移动文件或目录,也可以用于重命名文件或目录。下面是 mv 命令的基本语法和一些常见用法:
语法:
mv [选项] 源文件/目录 目标文件/目录
常见选项:
-i:在覆盖目标文件前进行提示。-u:仅在源文件比目标文件新或目标文件不存在时才移动。-v:详细显示移动操作。-b:在覆盖目标文件前,为目标文件创建备份。
示例用法:
移动文件到目录:
mv file1.txt directory/
这会将 file1.txt 移动到 directory 目录中。
重命名文件:
mv old_file.txt new_file.txt
这会将名为 old_file.txt 的文件重命名为 new_file.txt。
移动目录及其内容:
mv directory1/ directory2/
这会将 directory1 及其所有内容移动到 directory2 中。
移动并覆盖目标文件:
mv -f file1.txt directory/file1.txt
这会将 file1.txt 移动到 directory 目录中,并覆盖同名的目标文件(如果存在)。
Windows 系统中常用快捷键
以下是一些在 Windows 系统中常用的文件和文件夹操作快捷键:
通用快捷键:
- Ctrl + C:复制所选内容。
- Ctrl + X:剪切所选内容。
- Ctrl + V:粘贴剪切或复制的内容。
- Ctrl + Z:撤销上一次操作。
- Ctrl + Y:重做上一次操作。
- Ctrl + A:选择所有内容。
- Ctrl + S:保存当前文件。
- Ctrl + N:打开新窗口或新文件。
- Ctrl + O:打开文件。
- Ctrl + P:打印当前文件。
Windows 资源管理器快捷键:
- F2:重命名所选文件。
- F5:刷新当前窗口。
- Ctrl + Shift + N:创建新文件夹。
- Alt + Enter:显示所选文件或文件夹的属性。
- Alt + Up Arrow:返回上一级文件夹。
- Alt + Left Arrow:返回上一浏览器页。
文本编辑器快捷键:
- Ctrl + B:粗体。
- Ctrl + I:斜体。
- Ctrl + U:下划线。
- Ctrl + F:查找。
- Ctrl + H:替换。
- Ctrl + Home:跳转至文档开头。
- Ctrl + End:跳转至文档结尾。
Web 浏览器快捷键:
- Ctrl + T:打开新标签页。
- Ctrl + W:关闭当前标签页。
- Ctrl + Tab:在标签页之间切换。
- Ctrl + F:在页面中查找。
在linux添加一个垃圾箱
# 创建一个垃圾箱目录
mkdir -p ~/.trash
# 将 rm 命令替换为 trash 命令
alias rm=trash
# 定义一个函数 undelfile 来还原被误删的文件
undelfile() {
mv -i ~/.trash/$@ ./
}
# trash 函数将文件移动到垃圾箱目录
trash() {
mv $@ ~/.trash/
}
终端中执行以下命令来取消这个别名定义:
unalias rmcat指令
语法:cat [选项][文件]
功能: 查看目标文件的内容
常用选项:
-b 对非空输出行编号
-n 对输出的所有行编号
-s 不输出多行空行
cat 命令是一个常用的命令行工具,用于连接文件并打印它们的内容。适合查看小文本和一些代码片段。
tac 指令
tac 命令是 cat 命令的反向,用于逐行显示文件内容,但是是从文件的最后一行开始逐行显示文件内容。以下是关于 tac 命令的详细解释:
基本语法
tac [选项] [文件]
常用选项
-b:在非空行上显示行号。-r:反转文本而不是行。-s:指定分隔符,默认为换行符。tac命令用于逆序显示文件内容,从最后一行开始逐行显示,对于需要从后往前查看文件内容的情况很有用。
more指令
语法:more [选项][文件]
功能:more命令,功能类似 cat
常用选项:
-n 对输出的所有行编号
q 退出more
-d:显示提示信息,每次显示一屏内容之后暂停。
常见用法
-
显示文件内容:
more file.txt -
逐页显示文件内容:
more -d file.txt -
每次显示指定行数:
more -10 file.txt -
显示进度信息:
more -p file.txt
操作方式
- 使用
Space键向下翻页。 - 使用
Enter键逐行向下滚动。 - 使用
q键退出more。
注意事项
more命令适用于逐页查看文本文件内容,特别适用于大文件的浏览。- 对于交互式操作,可能更适合使用
less命令,因为它提供了更多的功能和灵活性。
less指令
操作方式
- 使用
Space键向下翻页。 - 使用
Enter键逐行向下滚动。 - 使用
B键向上翻页。 - 使用
/进行搜索,按n查找下一个匹配项。 - 使用
q键退出less。
-i 忽略搜索时的大小写
-N 显示每行的行号
/字符串:向下搜索“字符串”的功能
?字符串:向上搜索“字符串”的功能
n:重复前一个搜索(与 / 或 ? 有关)
N:反向重复前一个搜索(与 / 或 ? 有关)
q:quit
head指令
head 是一个常用的命令行工具,用于显示文件的开头部分。head 用来显示档案的开头至标准输出中,默认head命令打印其相应文件的开头10行。
常用选项
-n NUM:显示文件的前 NUM 行内容。-c NUM:显示文件的前 NUM 个字节的内容。-q:禁止显示文件名的标题信息。-v:总是显示文件名的标题信息。-z:将多个文件的内容作为单个文件显示。
常见用法
-
显示文件开头部分:
head file.txt -
显示指定行数的文件开头:
head -n 15 file.txt -
显示文件的前 N 个字节:
head -c 100 file.txt -
显示多个文件的开头部分:
head -z file1.txt file2.txt
注意事项
head命令默认显示文件的前 10 行内容,但是您可以使用-n选项来指定显示的行数。- 通过
head命令,您可以快速查看文件的开头部分,对于需要快速预览文件内容的情况非常有用。
tail指令
tail 命令从指定点开始将文件写到标准输出.使用tail命令的-f选项可以方便的查阅正在改变的日志文件,tail - f filename会把filename里最尾部的内容显示在屏幕上,并且不但刷新,使你看到最新的文件内容.
-
显示文件末尾部分:
tail file.txt -
显示指定行数的文件末尾:
tail -n 15 file.txt -
显示文件的末尾 N 个字节:
tail -c 100 file.txt -
实时追踪文件内容变化:
tail -f log.txt
注意事项
tail命令默认显示文件的最后 10 行内容,但是您可以使用-n选项来指定显示的行数。- 使用
-f选项可以实时追踪文件的内容变化,非常适用于查看日志文件或实时监控文件内容的情况。
时间相关的指令
在 Unix/Linux 系统中,有几个常用的命令和工具可以用来处理和显示时间相关信息。以下是一些常见的时间相关指令:
1. date 命令
date 指定格式显示时间: date +%Y:%m:%d
date 用法:date [OPTION]... [+FORMAT]
1.在显示方面,使用者可以设定欲显示的格式,格式设定为一个加号后接数个标记,其中常用的标记列表如下
%H : 小时(00..23)
%M : 分钟(00..59)
%S : 秒(00..61)
%X : 相当于 %H:%M:%S
%d : 日 (01..31)
%m : 月份 (01..12)
%Y : 完整年份 (0000..9999)
%F : 相当于 %Y-%m-%d
2.在设定时间方面
date -s //设置当前时间,只有root权限才能设置,其他只能查看。
date -s 20080523 //设置成20080523,这样会把具体时间设置成空00:00:00
date -s 01:01:01 //设置具体时间,不会对日期做更改
date -s “01:01:01 2008-05-23″ //这样可以设置全部时间
date -s “01:01:01 20080523″ //这样可以设置全部时间
date -s “2008-05-23 01:01:01″ //这样可以设置全部时间
date -s “20080523 01:01:01″ //这样可以设置全部时间
3.时间戳
时间->时间戳:date +%s
时间戳->时间:date -d@1508749502
Unix时间戳(英文为Unix epoch, Unix time, POSIX time 或 Unix timestamp)是从1970年1月1日(UTC/GMT的
午夜)开始所经过的秒数,不考虑闰秒。- 功能:用于显示或设置系统时间和日期。
- 示例用法:
- 显示当前日期和时间:
date - 显示特定格式的日期和时间:
date "+%Y-%m-%d %H:%M:%S" - 设置系统时间:
sudo date MMDDhhmmYYYY
- 显示当前日期和时间:
2. cal 命令
cal命令可以用来显示公历(阳历)日历。公历是现在国际通用的历法,又称格列历,通称阳历。“阳历”又名“太阳 历”,系以地球绕行太阳一周为一年,为西方各国所通用,故又名“西历”。
命令格式: cal [参数][月份][年份]
功能: 用于查看日历等时间信息,如只有一个参数,则表示年份(1-9999),如有两个参数,则表示月份和年份
常用选项:
-3 显示系统前一个月,当前月,下一个月的月历
-j 显示在当年中的第几天(一年日期按天算,从1月1号算起,默认显示当前月在一年中的天数)
-y 显示当前年份的日历- 功能:显示日历。
- 示例用法:
- 显示当前月份的日历:
cal - 显示指定年份的日历:
cal 2024 - 显示指定月份和年份的日历:
cal 8 2024
- 显示当前月份的日历:
3. uptime 命令
- 功能:显示系统的运行时间、平均负载等信息。
- 示例用法:
uptime
4. sleep 命令
- 功能:让脚本停顿指定的时间。
- 示例用法:
sleep 5(表示停顿 5 秒)
5. timedatectl 命令
- 功能:用于控制系统时间和日期。
- 示例用法:
- 显示当前时间和日期信息:
timedatectl - 设置系统时区:
sudo timedatectl set-timezone Asia/Tokyo
- 显示当前时间和日期信息:
6. at 和 atq 命令
- 功能:
at命令用于在将来的某个时间执行命令,而atq用于列出待执行的at命令队列。 - 示例用法:
- 在未来执行命令:
echo "echo 'Hello'" | at now + 1 hour - 查看
at命令队列:atq
- 在未来执行命令:
find指令
find 命令在 Unix 和类 Unix 系统中是非常有用的。它用于在指定目录下搜索文件,并可以根据各种条件来查找文件。以下是 find 命令的基本语法和一些常见用法:
基本语法
find [搜索路径] [匹配条件] [操作]
常见用法
-
按文件名搜索:
find /path/to/directory -name "filename" -
按文件类型搜索:
find /path/to/directory -type f # 查找文件 find /path/to/directory -type d # 查找目录 -
按大小搜索:
find /path/to/directory -size +10M # 大小大于 10MB 的文件 -
按权限搜索:
find /path/to/directory -perm 644 # 权限为 644 的文件 -
按时间搜索:
find /path/to/directory -mtime -7 # 最近 7 天内修改过的文件 -
组合条件搜索:
find /path/to/directory -name "*.txt" -size +1M # 查找大于 1MB 的 .txt 文件 -
执行操作:
- 找到文件后,可以使用
-exec选项来执行操作,例如删除找到的文件:find /path/to/directory -name "file.txt" -exec rm {} \;
- 找到文件后,可以使用
-
查找并排除特定目录:
find /path/to/directory -name "file.txt" -not -path "./exclude_dir/*" -
以逻辑或搜索:
find /path/to/directory \( -name "*.txt" -o -name "*.pdf" \)
用于在文件树种查找文件,并作出相应的处理(可能访问磁盘)
which指令
which 是用于查找并显示指定命令的可执行文件的位置。which 命令可以帮助确定系统在运行特定命令时将执行的是哪个可执行文件。以下是 which 命令的基本语法和用法:
基本语法
which [command]
用法示例
-
查找命令的路径:
which ls这将显示
ls命令的完整路径,例如/bin/ls。 -
查找系统 PATH 中的命令:
which python这将显示系统中
python命令的路径,通常是/usr/bin/python。 -
查找多个命令的路径:
which gcc g++这将显示
gcc和g++命令的路径。 -
查找命令是否存在:
which non_existing_command如果命令不存在,则不会有输出。
which 命令对于确定系统中哪个可执行文件将被调用以执行特定命令非常有用。请注意,which 命令只会在 PATH 环境变量指定的目录中查找命令,如果命令不在 PATH 中,则 which 将无法找到。
alias指令
alias 是用于创建用户自定义的命令别名。通过使用 alias 命令,用户可以为常用的命令或一长串复杂命令创建简短易记的别名,从而简化命令行操作。以下是关于 alias 命令的解释和用法:
语法
alias new_command='original_command'
用法示例
-
创建别名:
alias ll='ls -l'这会将
ll设置为ls -l的别名,以便通过ll命令执行ls -l的功能。 -
显示所有别名:
alias这会列出当前系统上定义的所有别名。
-
永久保存别名(需添加到
~/.bashrc或~/.bash_profile):echo "alias ll='ls -l'" >> ~/.bashrc source ~/.bashrc这会将
ll='ls -l'添加到~/.bashrc文件中,并通过source命令使其立即生效。 -
删除别名:
unalias ll这会删除名为
ll的别名。 -
使用参数的别名:
alias grep='grep --color=auto'这会将带有参数
--color=auto的grep命令设置为别名。
通过使用 alias 命令,用户可以根据自己的需求在命令行上创建简短、易记的别名,提高命令行操作的效率和便利性。记住,别名只在当前 shell 会话中生效,若要永久保存别名,需要将其添加到适当的 shell 配置文件中(如 ~/.bashrc 或 ~/.bash_profile)。
whereis 指令
whereis 是用于查找指定命令的二进制文件、源代码文件以及帮助文件的位置。whereis 命令会搜索特定命令的可执行文件、源代码文件和帮助文件,以便用户可以找到命令所在的位置。
语法
whereis [options] command_name
用法示例
-
查找命令的位置:
whereis ls这将显示
ls命令的路径,包括可执行文件、源代码文件和帮助文件(如果存在)的位置。 -
仅显示可执行文件位置:
whereis -b ls这将仅显示
ls命令的可执行文件位置。 -
仅显示源代码文件位置:
whereis -s ls这将仅显示
ls命令的源代码文件位置。 -
仅显示帮助文件位置:
whereis -m ls这将仅显示
ls命令的帮助文件位置。 -
显示所有选项:
whereis -f ls这将显示
ls命令的所有相关文件位置。
通过使用 whereis 命令,用户可以快速找到特定命令的位置,这在需要查找命令所在路径时非常有用。请注意,whereis 命令通常用于查找系统命令,对于用户自定义的命令或脚本,可能需要使用 which 命令或查看环境变量来确定其位置。
grep指令
grep 是一个用于在文件中搜索指定模式的文本行,并将包含匹配文本的行打印出来。grep 是 Global Regular Expression Print(全局正则表达式打印)的缩写,它可以帮助用户快速过滤和查找文件中的内容。
语法
grep [options] pattern [file...]
pattern:要搜索的模式,可以是普通文本或正则表达式。file:要在其中搜索匹配模式的文件列表。如果未指定文件,则grep将从标准输入读取数据。
常见选项
-i:忽略大小写。-r:递归地搜索目录中的文件。-n:显示匹配行的行号。-v:反转匹配,只显示不匹配的行。-c:仅显示匹配行的计数。
用法示例
-
在文件中搜索指定文本:
grep "pattern" file.txt -
忽略大小写搜索:
grep -i "pattern" file.txt -
显示匹配行的行号:
grep -n "pattern" file.txt -
递归搜索目录中的文件:
grep -r "pattern" /path/to/directory -
使用正则表达式进行搜索:
grep "^[0-9]" file.txt
grep 命令非常强大且灵活,可以与管道操作符 | 结合使用,也可以通过使用正则表达式来进行高级的文本匹配。它是在命令行环境中非常实用的文本搜索工具。
wc指令
wc 命令是用于统计指定文件中的行数、单词数和字符数。wc 是 Word Count(单词计数)的缩写,它可以帮助用户快速获取文件的基本信息。
语法
wc [options] [file...]
file:要统计的文件列表。如果未指定文件,则wc将从标准输入读取数据。
常见选项
-l:仅显示行数。-w:仅显示单词数。-c:仅显示字符数。-m:仅显示字符数(考虑多字节字符)。-L:显示包含最长行的长度。
用法示例
-
统计文件中的行数、单词数和字符数:
wc file.txt -
仅显示行数:
wc -l file.txt -
仅显示单词数:
wc -w file.txt -
仅显示字符数:
wc -c file.txt -
显示包含最长行的长度:
wc -L file.txt
wc 命令可以帮助快速了解文件的基本统计信息,例如行数、单词数和字符数。它在处理文本文件时非常有用,特别是在需要快速了解文件内容特征的情况下。
sort指令
sort 命令是用于对文本文件中的行进行排序。sort 命令默认按照字母顺序对文本进行排序,但也可以根据需要使用不同的选项进行数值排序、逆序排序等操作。
语法
sort [options] [file...]
file:要排序的文件列表。如果未指定文件,则sort将从标准输入读取数据。
常见选项
-r:逆序排序。-n:按数值大小排序。-k:指定按照特定列进行排序。-u:去重,仅显示唯一行。-t:指定字段分隔符。-f:忽略大小写。-b:忽略行首的空格字符。
用法示例
-
按字母顺序排序文件中的行:
sort file.txt -
按数值大小逆序排序:
sort -nr numbers.txt -
按第二列的数值大小进行排序:
sort -nk 2 data.txt -
忽略大小写进行排序:
sort -f file.txt -
去重并排序:
sort -u file.txt
uniq指令
uniq 命令是用于从排序后的文本输入中删除重复行。uniq 命令通常与 sort 命令结合使用,以便首先对文本进行排序,然后再使用 uniq 命令去除重复的行。
语法
uniq [options] [input [output]]
input:要处理的输入文件。如果未指定输入文件,则uniq将从标准输入读取数据。output:输出文件,可选。如果指定输出文件,则结果将写入该文件。
常见选项
-c:显示每行重复出现的次数。-d:仅显示重复的行。-u:仅显示不重复的行。
用法示例
-
删除重复的行:
sort file.txt | uniq -
显示重复行及其出现次数:
sort file.txt | uniq -c -
仅显示重复行:
sort file.txt | uniq -d -
仅显示不重复的行:
sort file.txt | uniq -u
zip/unzip指令
zip 和 unzip 是用于创建和解压缩归档文件。zip 命令用于将文件或目录打包成一个压缩文件,而 unzip 命令则用于解压缩这些压缩文件。
zip 命令
语法
zip options zipfile files
options:选项,用于控制压缩的方式和行为。zipfile:指定要创建的压缩文件的名称。files:要压缩的文件或目录列表。
常见选项
-r:递归地压缩目录及其内容。-q:静默模式,不显示压缩的过程。-9:使用最高压缩级别。-u:仅更新压缩文件中已存在的文件。
用法示例
-
压缩文件:
zip compressed.zip file1.txt file2.txt -
压缩目录及其内容:
zip -r compressed.zip directory
unzip 命令
语法
unzip options zipfile
options:选项,用于控制解压缩的方式和行为。zipfile:要解压缩的压缩文件。
常见选项
-d directory:指定解压到的目标目录。-q:静默模式,不显示解压缩的过程。
用法示例
-
解压缩文件:
unzip compressed.zip -
解压缩到指定目录:
unzip compressed.zip -d destination_directory
zip默认对一个目录进行打包压缩时,只会对目录文件打包压缩,不会打包压缩目录文件里的其他内容。也就是说你打包压缩了一个空目录。
tar指令:打包/解包
tar 命令是常用的命令行实用程序,用于创建、查看和提取归档文件。tar 实用程序通常用于将一组文件打包成单个归档文件,然后可以对该归档文件执行各种操作,如压缩、解压缩等。
语法
tar [options] [archive-file] [files/directories]
options:用于指定操作的选项,例如创建、提取、压缩等。archive-file:指定归档文件的名称。files/directories:要包含在归档文件中的文件或目录列表。
常见选项
-c:创建归档文件。-x:提取归档文件。-v:显示详细信息。-f archive-file:指定归档文件的名称。-z:使用 gzip 进行压缩或解压缩。-j:使用 bzip2 进行压缩或解压缩。-r:向归档文件中追加文件。-t:显示归档文件中的内容列表。- -C : 解压到指定目录
用法示例
-
创建归档文件:
tar -cvf archive.tar file1.txt file2.txt -
提取归档文件:
tar -xvf archive.tar -
使用 gzip 进行压缩:
tar -czvf archive.tar.gz directory -
查看归档文件中的内容列表:
tar -tvf archive.tar
tar 命令是一个非常强大和灵活的工具,可以用于处理归档文件,包括创建、提取、压缩和解压缩文件。通过结合不同的选项,用户可以根据需要执行各种操作,并有效地管理文件和目录。
tar -cvf /tmp/etc.tar /etc #仅打包,不压缩!
tar -zcvf /tmp/etc.tar.gz /etc #打包后,以 gzip算法压缩
tar -jcvf /tmp/etc.tar.bz2 /etc #打包后,以 bzip2算法压缩
在参数 f 之后的文件档名是自己取的,习惯上都用 .tar 来作为辨识。
如果加 z 参数,则以 .tar.gz 或 .tgz 来代表 gzip 压缩过的 tar file
如果加 j 参数,则以 .tar.bz2 或 .tar.bz 来代表 bzip2 压缩过的 tar file
查阅上述 打包/压缩 文件内有哪些文件:
tar -tvf c_pp.tar
通过这个命令查看归档文件的内容
tar -ztvf /tmp/etc.tar.gz
使用 gzip 压缩,所以要查阅该 tar file 内的文件时,就得要加上 z 这个参数了!
tar -jtvf /tmp/etc.tar.bz2
使用 bzip2压缩,所以要查阅该 tar file 内的文件时,就得要加上 j 这个参数了!
文件解压缩:
tar -zxvf /tmp/etc.tar.gz #将文件解压缩到当前工作目录
tar -zxvf /tmp/etc.tar.gz -C /tmp #将文件解压缩到 /tmp 目录下
tar -jxvf /tmp/etc.tar.bz2 #将文件解压缩到当前工作目录
tar -jxvf /tmp/etc.tar.bz2 -C /tmp #将文件解压缩到 /tmp 目录下
在 /tmp 底下,我只想要将 /tmp/etc.tar.gz 内的 etc/passwd
tar -zxvf /tmp/etc.tar.gz etc/passwd
通过 tar -ztvf 来查阅 tar file 内的文件名称,如果只要一个文件,注意到 etc.tar.gz 内的根目录 / 是被拿掉了!
将 /etc/ 内的所有文件备份下来,并且保存其权限!
tar -zxvpf /tmp/etc.tar.gz /etc
这个 -p 的属性是很重要的,尤其是当您要保留原本文件的属性时!
在 /home 当中,比 YYYY-MM-DD 新的文件才备份
tar -N "YYYY-MM-DD" -zcvf home.tar.gz /home
备份 /home, /etc ,但不要 /home/dmtsai
tar --exclude /home/dmtsai -zcvf myfile.tar.gz /home/* /etc
将 /etc/ 打包后直接解开在 /tmp 底下,而不产生文件!
tar -cvf - /etc/ | tar -xvf - -C /tmp
这个命令的工作原理如下:
tar -cvf - /etc/:将 /etc/ 目录打包,并将输出发送到标准输出(stdout)。
|:管道符号,将前一个命令的输出作为后一个命令的输入。
tar -xvf - -C /tmp:从标准输入(stdin)中解包数据,并将文件直接解压缩到 /tmp 目录下。
这个动作有点像是 cp -r /etc /tmp
要注意的地方在输出档变成 - 而输入档也变成 - ,又有一个 | 存在~
这分别代表 standard output, standard input 与管线命令!
解压缩文件时,文件的权限可能会受到影响,具体取决于压缩文件本身的权限设置以及解压缩过程中使用的命令选项。
在大多数情况下,当您解压缩一个文件时,解压缩后的文件会继承压缩文件中的权限设置。这意味着如果压缩文件具有特定的权限(例如所有者、群组、其他用户的读写执行权限),解压缩后的文件也会反映这些权限。
如果在解压缩文件时使用了 -p(--preserve-permissions)选项,解压缩后的文件将尽可能地保留原始文件的权限设置。这对于保留文件权限和所有权信息非常有用。
另外,如果以特定用户身份执行解压缩命令(例如以 root 用户身份执行),解压缩后的文件可能会以该用户的权限创建。这可能导致文件的权限与原始文件不同。
总的来说,解压缩后文件的权限会受到一些因素的影响,包括压缩文件本身的权限设置、解压缩命令选项和执行解压缩操作的用户身份。
bc指令
bc 是一个用于执行数学运算的命令行计算器。它支持整数和小数运算,提供了一些基本的数学函数。
您可以在终端中输入 bc 命令来启动 bc 计算器。一旦进入 bc 模式,您可以输入数学表达式并按 Enter 键来执行计算。
root@iZ2vch4tdjuyi8htrm9i7hZ:~/test# echo 1+2+3+6 | bc
12uname指令
uname 命令用于显示系统信息,例如操作系统的名称、版本、发布号等。在终端中输入 uname 命令将会返回系统的基本信息。
常用的 uname 命令选项包括:
-a:显示所有系统信息。-s:显示内核名称。-n:显示网络主机名。-r:显示内核版本。-v:显示内核发布。-m:显示硬件架构。-p:显示处理器类型。-i:显示硬件平台。-o:显示操作系统名称。
x86 与 x64/x86_64区别
"x86" 和 "x64" 或 "x86_64" 是描述计算机处理器架构的术语,它们代表不同的体系结构和处理器类型。以下是它们之间的主要区别:
-
x86:
- "x86" 最初是指 Intel 公司在1980年代推出的处理器架构系列。
- 在计算机领域中,常指的是32位的x86架构,如 Intel 80386、80486 等。
- 32位的x86架构有一些限制,例如无法直接访问超过4GB的内存。
-
x64 / x86_64:
- "x64" 或 "x86_64" 是指64位的x86架构,是对32位x86架构的扩展。
- 这种架构最初由 AMD 公司提出,后来被 Intel 公司采纳并广泛应用。
- 64位的x86架构可以支持更大的内存寻址空间,更多的寄存器以及更高的性能。
主要区别:
- 寻址能力:x86架构限制了内存寻址范围为4GB,而x64/x86_64架构支持更大的内存寻址范围。
- 性能:64位架构的处理器通常可以处理更多数据和更大的指令集,因此在某些情况下可能提供更好的性能。
- 兼容性:64位处理器通常可以运行32位软件,但32位处理器无法运行64位软件。
- 软件支持:随着时间的推移,许多操作系统和应用程序已经过渐进性的更新,以支持64位架构。
重要的几个热键
这些是在 Linux 终端中常用的一些重要热键功能:
-
[Tab]按键:
- 具有『命令补全』和『档案补齐』的功能。按下Tab键可以自动补全命令或文件名,提高输入效率。
-
[Ctrl]-c按键:
- 让当前的程序『停掉』。通常用于中断当前正在运行的程序或命令。
-
[Ctrl]-d按键:
- 通常代表着:『键盘输入结束(End Of File, EOF 戒 End Of Input)』的意思。在终端中,可以表示输入结束,也可以用来取代exit命令来关闭终端。
-
[Ctrl]-r按键:
- 在终端中执行逆向搜索,允许您搜索之前输入过的命令。按下此组合键会打开一个交互式搜索功能,可快速查找并执行历史命令。
-
[Ctrl]-z按键:
- 将当前进程挂起(即进程暂停执行),并放入后台。可以使用
fg命令将其重新放回前台执行,或使用bg命令在后台继续执行。
- 将当前进程挂起(即进程暂停执行),并放入后台。可以使用
关机指令
在 Linux 系统中,您可以使用 shutdown 命令来安全地关闭系统。以下是一些常见的关机指令:
-
立即关机:
sudo shutdown -h now这个命令会立即关闭系统。
-
指定时间关机:
sudo shutdown -h +10这个命令会在 10 分钟后关闭系统。您也可以使用其他时间格式,例如
+60表示在 1 小时后关闭。 -
取消关机:
sudo shutdown -c如果您之前设置了一个延迟关机时间,您可以使用此命令来取消关机。
-
-h:在将系统的服务停掉后,立即关机。这个参数告诉系统在关闭服务后立即关机,而不是等待其他操作。 -
-r:在将系统的服务停掉后就重新启动。使用这个参数会在关闭服务后直接重启系统。 -
-t sec:-t后面跟着秒数,表示等待指定秒数后执行关机操作。这个参数允许您设置一个延迟关机的时间,比如-t 60表示在 60 秒后执行关机操作。
lscpu,lsmem指令
lscpu 和 lsmem 是用于查看系统信息的 Linux 命令,提供有关 CPU 和内存的详细信息。
-
lscpu:显示有关 CPU 架构的信息,包括逻辑 CPU 数量、CPU 类型、CPU频率、缓存大小等。 -
lsmem:提供有关系统内存的信息,包括内存总量、可用内存、NUMA 节点信息等。
您可以在终端中运行这些命令来查看系统的 CPU 和内存信息。例如:
lscpu
lsmemdf指令
df 命令是一个常用的 Linux/Unix 命令,用于显示文件系统磁盘空间利用率的信息。通过运行 df 命令,您可以查看系统中各个文件系统的磁盘空间使用情况,包括已用空间、可用空间、文件系统类型以及挂载点等信息。
以下是 df 命令的基本语法和一些常用选项:
df [OPTION]... [FILE]...
- 常用选项:
-h:以人类可读的格式显示磁盘空间大小(如 GB、MB)。-T:显示文件系统类型。-i:显示 inode 使用情况。-a:显示所有文件系统,包括系统中特殊的伪文件系统。-x:排除特定文件系统类型。--total:显示所有列的总计。--output=字段1,字段2...:指定要显示的字段。
例如,您可以运行以下命令来显示文件系统的磁盘空间使用情况:
df -h
这将以人类可读的方式显示文件系统的磁盘空间使用情况。
who,whoami指令
who 和 whoami 是两个常用的命令,在 Linux/Unix 系统中用于显示当前登录用户和当前用户的信息。
-
who:who命令用于显示当前登录到系统上的用户的信息。它会列出登录用户的用户名、终端设备、登录时间等。示例输出:
username1 tty1 2024-08-31 08:00 username2 tty2 2024-08-31 08:10 -
whoami:whoami命令用于显示当前有效用户的用户名。它会简单地返回当前用户的用户名。示例输出:
username
因此,who 用于查看当前登录到系统的用户信息,而 whoami 则用于查看当前有效用户的用户名。
安装和登录命令:
- login:登录到系统。
- shutdown:关闭系统。
- halt:立即关闭系统。
- reboot:重新启动系统。
- install:安装软件包。
- mount:挂载文件系统。
- umount:卸载文件系统。
- chsh:更改 shell。
- exit:退出当前 shell。
- last:显示最近登录的用户列表。
文件处理命令:
- file:确定文件类型。
- mkdir:创建目录。
- grep:在文件中搜索文本模式。
- dd:数据转换和复制。
- find:查找文件。
- mv:移动文件。
- ls:列出目录内容。
- diff:比较文件内容。
- cat:连接文件并打印到标准输出。
- ln:创建链接。
系统管理相关命令:
- df:显示磁盘空间使用情况。
-h:以人类可读的格式显示。-T:显示文件系统类型。
- top:显示系统资源使用情况。
-c:显示完整命令行。-u:显示特定用户的进程。
- free:显示内存使用情况。
-h:以人类可读的格式显示。
- quota:设置磁盘配额。
- at:在指定时间运行任务。
- lp:打印文件。
- adduser:添加用户。
- groupadd:添加用户组。
- kill:终止进程。
-9:强制终止进程。
- crontab:定时执行任务。
网络操作命令:
- ifconfig:配置网络接口参数。
- ip:显示和设置网络设备、路由和策略。
- ping:测试主机之间的连通性。
- netstat:显示网络连接、路由表等信息。
- telnet:远程登录。
- ftp:文件传输协议。
- route:显示和设置路由表。
- rlogin:远程登录。
- rcp:远程文件复制。
- finger:查看用户信息。
- mail:发送邮件。
- nslookup:查询 DNS。
系统安全相关命令:
- passwd:更改用户密码。
- su:切换用户。
- umask:设置默认文件权限。
- chgrp:更改文件组。
- chmod:更改文件权限。
- chown:更改文件所有者。
- chattr:更改文件属性。
- sudo:以其他用户身份执行命令。
- ps:显示进程状态。
-aux:显示所有进程。
- who:显示当前登录用户。
shell命令以及运行原理
Shell(壳)是操作系统的命令行解释器,它是用户与操作系统内核之间的接口。用户可以通过Shell来与操作系统进行交互,运行各种命令、程序和脚本。Shell会解释用户输入的命令,并将其转换为操作系统能够理解的操作。
Shell命令的运行原理大致如下:
-
用户输入命令:用户在命令行界面输入命令,比如
ls、cd等。 -
Shell解释命令:Shell解释用户输入的命令,识别命令的名称和参数。
-
查找命令:Shell会在系统的环境变量定义的路径中查找要执行的命令。
-
加载并执行命令:如果找到了要执行的命令,Shell会加载该命令的可执行文件,并在操作系统中运行该程序。
-
执行命令:操作系统会为该命令创建一个进程,并执行相应的操作。
-
输出结果:命令执行完成后,Shell会将执行结果输出到命令行界面供用户查看。
不同的操作系统有不同的Shell,比如Unix/Linux系统通常使用Bash(Bourne Again SHell),Windows系统使用的是Command Prompt或PowerShell。
Shell还支持脚本编程,用户可以编写Shell脚本来自动化一系列操作,提高工作效率。Shell脚本是一系列Shell命令按照一定逻辑组织在一起的文本文件。
在Shell脚本中,有许多常用的命令可用于执行各种操作。以下是一些常见的Shell脚本命令:
-
echo:用于在终端输出文本或变量的值。
-
read:用于从标准输入(键盘)读取用户输入,并将其保存到变量中。
-
if:用于执行条件判断,根据条件的真假执行不同的代码块。
-
for:用于循环执行一段代码,可遍历列表或序列。
-
while:用于在条件为真时循环执行一段代码块。
-
case:用于多分支条件判断,类似于 switch-case 结构。
-
function:用于定义和调用函数,可以封装一段代码以便重复利用。
-
export:用于设置环境变量,让变量在当前Shell会话及其子进程中可用。
-
grep:用于在文件中搜索指定模式的文本行。
-
sed:用于对文本进行流编辑操作,可以进行文本替换、删除、插入等操作。
-
awk:用于处理文本和生成报表,支持数据提取、转换和报表生成等功能。
-
cut:用于从文本行中提取字段。
-
sort:用于对文本文件进行排序。
-
mkdir:用于创建新的目录。
-
rm:用于删除文件或目录。
-
cp:用于复制文件或目录。
-
mv:用于移动文件或目录,也可用于重命名文件。
-
chmod:用于修改文件或目录的权限。
-
chown:用于修改文件或目录的所有者。
-
curl 或 wget:用于从网络下载文件。
Linux权限的概念
在Linux系统中,文件和目录有各种权限,这些权限规定了对文件或目录的访问方式。Linux权限系统基于用户(owner)、用户组(group)和其他用户(others)三种角色来管理文件和目录的访问权限。每个文件或目录都有一个所有者和一个所属用户组。
Linux权限包括以下几个方面:
-
读权限(Read):允许查看文件内容或目录内容,以及获取文件属性。
-
写权限(Write):允许修改文件内容或目录内容,包括创建、删除和重命名文件。
-
执行权限(Execute):对于文件,执行权限表示文件是否可执行;对于目录,执行权限表示能否进入该目录。
文件权限表示方式:
在Linux系统中,文件的权限以一个10位字符串表示,如 drwxr-xr-x。这个字符串的含义如下:
- 第一个字符表示文件类型(d 代表目录,- 代表普通文件)。
- 后面的字符分成三组,每组三个字符代表文件所有者、所属用户组和其他用户的权限。每组的三个字符分别表示读、写、执行权限,分别对应
r、w、x,如果没有权限则用-表示。
Linux下有两种用户:超级用户(root)、普通用户。
超级用户:可以再linux系统下做任何事情,不受限制
普通用户:在linux下做有限的事情。
超级用户的命令提示符是“#”,普通用户的命令提示符是“$”。
命令:su [用户名]
功能:切换用户。
例如:
-
drwxr-xr-x:这个部分表示该文件的权限和类型。d:表示这是一个目录(directory)。rwx:所有者(root)对该目录的权限。r:表示所有者(root)有读取(read)权限。w:表示所有者(root)有写入(write)权限。x:表示所有者(root)有执行(execute)权限。
r-x:所属用户组(也是root)对该目录的权限。r:表示所属用户组(root)有读取权限。-:表示所属用户组(root)没有写入权限。x:表示所属用户组(root)有执行权限。
r-x:其他用户对该目录的权限。r:表示其他用户有读取权限。-:表示其他用户没有写入权限。x:表示其他用户有执行权限。
-
2:表示与该目录相关联的文件或目录的数量(包括.和..)。 -
root root:第一个root表示该目录的所有者,第二个root表示该目录的所属用户组。 -
4096:表示该目录的大小(以字节为单位)。 -
Aug 31 17:18:表示该目录的最后修改时间。 -
c_pp/:表示该目录的名称为c_pp。
文件类型
在Linux系统中,文件系统中的每个文件都会有一个类型,用于指示该文件是普通文件、目录、链接等。文件类型通常通过文件的权限列表的第一个字符来表示。
以下是一些常见的文件类型及其含义:
-
普通文件包含文本、图像、可执行程序等内容。-:普通文件(regular file)。 -
目录用于组织和存储文件和其他目录。d:目录(directory)。 -
符号链接是指向另一个文件的指针,类似于Windows系统中的快捷方式。l:符号链接(symbolic link)。 -
字符设备文件用于与设备进行通信,例如键盘、鼠标等。c:字符设备文件(character device file)。 -
块设备文件用于与设备进行数据块级别的通信,例如硬盘、USB设备等。b:块设备文件(block device file)。 -
命名管道用于进程间通信,允许一个进程向另一个进程发送数据。p:命名管道(named pipe)。 -
套接字文件用于进程间的网络通信。s:套接字文件(socket file)。
基本权限
在Linux系统中,文件和目录的基本权限是指文件的读取(Read)、写入(Write)、执行(Execute)权限。这些权限决定了用户对文件或目录可以执行的操作。
最终权限 = 起始权限 & (~umask)
目录起始权限:777
普通文件起始权限:666
umask默认:0002
创建目录起始权限:777 & (~002)= 775
111 111 111 & (~000 000 010) ——> 111 111 111 & (111 111 101)= 111 111 101 = 0775
创建普通文件起始权限:666 & (~002)= 664
110 110 110 &(~000 000 010) ——> 110 110 110 & (111 111 101)= 110 110 100 = 0664
下面是关于基本权限的概述:
-
读取权限(Read):
- 对于文件:具有读取权限的用户可以查看文件的内容。
- 对于目录:具有读取权限的用户可以列出目录中的文件和子目录。
-
写入权限(Write):
- 对于文件:具有写入权限的用户可以修改文件的内容,包括向文件中写入新内容或覆盖现有内容。
- 对于目录:具有写入权限的用户可以在目录中创建、删除或重命名文件和子目录。
-
执行权限(Execute):
- 对于文件:具有执行权限的用户可以运行可执行文件。
- 对于目录:具有执行权限的用户可以进入该目录,即切换到该目录作为当前工作目录。
文件访问权限的设置
在Linux系统中,可以使用chmod命令来设置文件和目录的访问权限。chmod命令允许用户更改文件和目录的权限,以控制谁可以读取、写入或执行文件。
chmod命令的基本语法:
chmod [选项] 模式 文件
以下是一些常用的 chmod 命令选项和示例:
- 通过符号方式设置权限:
+:添加权限。-:移除权限。=:设置权限。
# 示例:给文件所有者添加写权限
chmod u+w file.txt
# 示例:给文件所属用户组添加执行权限
chmod g+x file.txt
# 示例:给其他用户设置只读权限
chmod o=r file.txt
- 通过数字方式设置权限:
4:读权限。2:写权限。1:执行权限。
权限数字可以相加来表示不同用户的权限。例如,7表示读取、写入和执行权限。
# 示例:设置文件所有者读取、写入和执行权限,所属用户组读取和执行权限,其他用户读取权限
chmod 750 file.txt
- 递归设置权限:可以通过
-R选项递归地设置目录及其内容的权限。
# 示例:递归设置目录及其内容为所有者具有读写权限,所属用户组和其他用户只具有读权限
chmod -R 644 directory/
- 使用符号和数字结合的方式设置权限:
# 示例:同时为所有者、所属用户组和其他用户设置不同权限
chmod u=rw,g=r,o=r file.txt
r-w-x 1 1 1 = 7
用户符号: u:拥有者 g:拥有者同组用 o:其它用户 a:所有用户
chown命令
chown命令用于修改文件的拥有者。
- 格式:
chown [参数] 用户名 文件名 - 实例:
chown user1 file.txt
chgrp命令
chgrp命令用于修改文件或目录的所属组。
- 格式:
chgrp [参数] 用户组名 文件名 - 实例:
chgrp group1 file.txt
常用选项:
-R:递归修改文件或目录的所属组
以下是一个示例,演示如何使用chown和chgrp命令:
- 修改文件的拥有者:
chown user1 file.txt
这将把file.txt的拥有者修改为user1。
将文件 testfile 的所有者更改为ptm,并将所属组更改为 test。通过使用 sudo,您确保具有足够的权限来执行这个更改操作。
sudo chown ptm:test testfile- 修改文件的所属组:
chgrp group1 file.txt
这将把file.txt的所属组修改为group1。
- 递归修改文件或目录的所属组:
chgrp -R group1 directory/
这将递归地将directory/目录及其所有内容的所属组都修改为group1。
通过chown和chgrp命令,可以更改文件和目录的拥有者和所属组,以确保正确的权限和访问控制。
file指令
功能说明:辨识文件类型。
语法:file [选项] 文件或目录... 常用选项:
-c 详细显示指令执行过程,便于排错或分析程序执行的情形。
-z 尝试去解读压缩文件的内容。
-b:只输出文件类型,不输出文件名。-i:以MIME类型的格式输出文件类型。-z:对压缩文件进行检查。-L:跟踪符号链接的类型。
目录的权限
-
可执行权限:普通用户需要有可执行权限才能进入该目录,即使用
cd命令。如果没有可执行权限,普通用户无法进入该目录。 -
可读权限:普通用户需要有可读权限来查看目录内容,如使用
ls命令列出文件和子目录。如果没有可读权限,普通用户无法查看目录中的内容。 -
可写权限:普通用户需要有可写权限才能在目录中创建、删除或重命名文件。如果没有可写权限,普通用户无法进行这些操作。
就是只要用户具有目录的写权限, 用户就可以删除目录中的文件, 而不论这个用户是否有这个文件的写权限.
目录的可执行权限是表示你可否在目录下执行命令。 如果目录没有-x权限,则无法对目录执行任何命令,甚至无法cd 进入目录, 即使目录仍然有-r 读权限(这个地方很容易犯错,认为有读权限就可以进入目录读取目录下的文件) 而如果目录具有-x权限,但没有-r权限,则用户可以执行命令,可以cd进入目录。但由于没有目录的读权限,所以在目录下,即使可以执行ls命令,但仍然没有权限读出目录下的文档。
无法使用 sudo 命令获取超级用户权限
需要将用户添加到 sudoers 文件中以允许执行特权操作。
要将用户添加到 sudoers 文件中,可以通过以下步骤:
-
打开终端,以 root 用户或具有管理员权限的用户登录。
-
运行以下命令以编辑 sudoers 文件:
visudo这个命令会使用默认文本编辑器打开 sudoers 文件进行编辑。
-
在 sudoers 文件中找到以下行:
root ALL=(ALL:ALL) ALL在这行的下方添加一行类似于以下内容,将
username替换为要添加的用户名:username ALL=(ALL:ALL) ALL例如,要将用户 ptm 添加到 sudoers 文件中,可以添加如下一行:
ptm ALL=(ALL:ALL) ALL -
保存并关闭文件。在 vim 编辑器中,按下
Esc键,然后输入:wq并按下Enter保存并退出。 -
确保语法没有错误。可以使用以下命令检查 sudoers 文件的语法:
visudo -c如果没有错误,则会显示 "sudoers file parsed OK"。
现在,用户 johndoe (或替换为你要添加的用户名)应该可以使用 sudo 命令来执行需要超级用户权限的操作了。请谨慎操作 sudoers 文件,因为错误的更改可能导致系统不稳定或不安全。
在 sudoers 文件中,username ALL=(ALL:ALL) ALL 这行的语法解释如下:
-
username: 这是你要授权的用户名,表示该规则适用于特定的用户。当这个用户登录后,可以使用sudo命令获取超级用户权限。 -
ALL: 第一个ALL表示该用户可以在任何主机上执行命令。 -
=(ALL:ALL): 这部分定义了用户可以作为哪个用户组执行命令。具体来说:- 第一个
ALL表示用户可以作为任何用户执行命令。 - 第二个
ALL表示用户可以作为任何用户组执行命令。
- 第一个
-
ALL: 最后一个ALL表示用户可以执行任何命令,不受限制。
综合起来,username ALL=(ALL:ALL) ALL 这行规则表示用户 username 可以在任何主机上以任何用户和用户组的身份执行任何命令。这是一种非常宽松的权限设置,因此在修改 sudoers 文件时应该谨慎操作,以确保系统安全。
Linux文件类型
以下是常见的文件类型标识及其解释:
-
-(普通文件):这表示文件是一个普通文件,其中包含文本、图像、二进制数据等内容。普通文件是最常见的文件类型,包含着各种数据。 -
d(目录文件):这表示文件是一个目录文件,用于存储其他文件和目录的列表。目录文件包含了文件系统中的目录结构。 -
c(字符设备文件):字符设备文件用于处理数据流,每次一个字符。这种文件通常代表计算机系统中的字符设备,如键盘、鼠标等。 -
b(块设备文件):块设备文件以块为单位处理数据,通常用于硬盘驱动器和闪存设备等。块设备文件允许以块为单位的读写操作。 -
s(套接字文件):套接字文件用于进程间的通信,特别是网络通信。网络通信中常用的套接字文件通常以这种形式存在。 -
p(管道文件):管道文件也称为FIFO文件,用于进程间的通信,允许进程进行单向通信。管道文件在Shell脚本和进程间通信方面非常有用。
mkfifo
mkfifo 是一个 Linux/Unix 命令,用于创建 FIFO 文件(First In First Out,先进先出),也称为管道文件。FIFO 是一种特殊类型的文件,在进程间通信中很有用,允许进程通过文件系统进行单向通信。
要使用 mkfifo 命令创建一个 FIFO 文件,你可以在终端中执行以下命令:
mkfifo myfifo
这将在当前目录下创建一个名为 myfifo 的 FIFO 文件。其他进程可以通过读取或写入这个 FIFO 文件来进行进程间通信。
一般来说,一个进程会向 FIFO 文件写入数据,而另一个进程则可以从 FIFO 文件读取相同的数据。这种通信方式可以用于不同进程之间的数据传输,特别是在 Shell 脚本或编程中。
linux文件类型与后缀无关,但一些工具可能对文件后缀有要求
在 Linux 中,文件类型并不是由文件名后缀来决定的,而是通过文件内容的特征来确定的。这被称为“魔法数”(magic number)或者“魔法字符串”(magic string)。这意味着即使一个文件的后缀是 .txt,它的内容仍然可以被认为是其他类型的文件,比如 C 代码文件。
当你使用 gcc 编译器编译一个文件时,gcc 会尝试根据文件内容来确定文件类型,而不是仅仅依赖于文件名后缀。如果 gcc 将一个文本文件错误地视为链接器脚本,你可以尝试告诉 gcc 明确地将该文件视为 C 代码文件。
你可以尝试使用 -x 选项来指定文件类型,即使文件名后缀不是 .c:
gcc -x c -o output_filename your_program.txt
这样告诉 gcc 将 your_program.txt 视为 C 代码文件进行编译。这种情况下,gcc 会忽略文件名后缀,而根据 -x 选项指定的文件类型来处理文件。
lsof,fuser
lsof和fuser是两个在Linux系统中用于查看打开文件和查看进程使用文件的命令。
lsof(List Open Files)
lsof命令用于列出系统中已打开的文件,包括普通文件、目录、设备文件等。它可以列出哪些进程打开了哪些文件,对系统监控和故障排除非常有用。
示例用法:
lsof /path/to/file # 列出打开指定文件的进程
lsof -u username # 列出特定用户打开的文件
lsof -i # 列出网络连接相关的文件
fuser(File User)
fuser命令用于查看哪些进程正在使用指定的文件或文件系统。它可以显示哪些进程正在访问特定文件,并可以选择性地关闭这些进程。
示例用法:
fuser /path/to/file # 列出正在使用指定文件的进程
fuser -k /path/to/file # 杀死正在使用指定文件的进程
这两个命令在管理文件和进程时非常有用,可以帮助你查看系统中哪些进程在使用文件,以及如何处理这些进程以释放文件。
查看linux用户
在Linux系统中,你可以使用不同的命令来查看系统中已存在的用户。以下是几个常用的命令:
1. 查看所有用户
使用cat /etc/passwd命令可以查看系统上所有用户的信息,每行对应一个用户的记录。
cat /etc/passwd
2. 查看当前登录用户
使用who或w命令可以查看当前登录系统的用户信息。
who
3. 查看当前登录用户及其终端
使用who命令结合-u选项可以显示详细的登录用户信息,包括登录时间和终端。
who -u
4. 查看在线用户
使用w命令可以显示当前登录用户的详细信息,包括登录时间、终端和运行的进程
w
5. 查看特定用户信息
如果你想查看特定用户的信息,可以使用id命令,后面跟上用户名。
id username
6. 查看已登录用户数量
可以使用who命令结合-q选项来查看当前系统上已登录用户的数量。
who -qLinux 用户和用户组管理
Linux系统是一个多用户多任务的分时操作系统,任何一个要使用系统资源的用户,都必须首先向系统管理员申请一个账号,然后以这个账号的身份进入系统。
用户的账号一方面可以帮助系统管理员对使用系统的用户进行跟踪,并控制他们对系统资源的访问;另一方面也可以帮助用户组织文件,并为用户提供安全性保护。
每个用户账号都拥有一个唯一的用户名和各自的口令。
用户在登录时键入正确的用户名和口令后,就能够进入系统和自己的主目录。
实现用户账号的管理,要完成的工作主要有如下几个方面:
- 用户账号的添加、删除与修改。
- 用户口令的管理。
- 用户组的管理。
添加新的用户账号使用useradd命令
useradd 选项 用户名
-
选项:
- -c comment 指定一段注释性描述。
- -d 目录 指定用户主目录,如果此目录不存在,则同时使用-m选项,可以创建主目录。
- -g 用户组 指定用户所属的用户组。
- -G 用户组,用户组 指定用户所属的附加组。
- -s Shell文件 指定用户的登录Shell。
- -u 用户号 指定用户的用户号,如果同时有-o选项,则可以重复使用其他用户的标识号。
实例1
# useradd –d /home/ptm -m ptm
此命令创建了一个用户ptm,其中-d和-m选项用来为登录名ptm产生一个主目录 /home/ptm(/home为默认的用户主目录所在的父目录)。
实例2
# useradd -s /bin/sh -g group –G adm,root gem
此命令新建了一个用户gem,该用户的登录Shell是 /bin/sh,它属于group用户组,同时又属于adm和root用户组,其中group用户组是其主组。
增加用户账号就是在/etc/passwd文件中为新用户增加一条记录,同时更新其他系统文件如/etc/shadow, /etc/group等。
删除帐号
删除用户账号就是要将/etc/passwd等系统文件中的该用户记录删除。
删除一个已有的用户账号使用userdel命令,其格式如下:
userdel 选项 用户名
常用的选项是 -r,它的作用是把用户的主目录一起删除。
例如:
# userdel -r sam
此命令删除用户sam在系统文件中(主要是/etc/passwd, /etc/shadow, /etc/group等)的记录,同时删除用户的主目录。
修改帐号
修改用户账号就是根据实际情况更改用户的有关属性,如用户号、主目录、用户组、登录Shell等。
修改已有用户的信息使用usermod命令,其格式如下:
usermod 选项 用户名
常用的选项包括-c, -d, -m, -g, -G, -s, -u以及-o等,这些选项的意义与useradd命令中的选项一样,可以为用户指定新的资源值。
另外,有些系统可以使用选项:-l 新用户名
这个选项指定一个新的账号,即将原来的用户名改为新的用户名。
例如:
# usermod -s /bin/ksh -d /home/z –g developer sam
此命令将用户sam的登录Shell修改为ksh,主目录改为/home/z,用户组改为developer。
用户口令的管理
passwd 选项 用户名
可使用的选项:
- -l 锁定口令,即禁用账号。
- -u 口令解锁。
- -d 使账号无口令。
- -f 强迫用户下次登录时修改口令。
如果默认用户名,则修改当前用户的口令。
普通用户修改自己的口令时,passwd命令会先询问原口令,验证后再要求用户输入两遍新口令,如果两次输入的口令一致,则将这个口令指定给用户;而超级用户为用户指定口令时,就不需要知道原口令。
Linux系统用户组的管理
每个用户都有一个用户组,系统可以对一个用户组中的所有用户进行集中管理。不同Linux 系统对用户组的规定有所不同,如Linux下的用户属于与它同名的用户组,这个用户组在创建用户时同时创建。
用户组的管理涉及用户组的添加、删除和修改。组的增加、删除和修改实际上就是对/etc/group文件的更新。
1、增加一个新的用户组使用groupadd命令。其格式如下:
groupadd 选项 用户组
可以使用的选项有:
- -g GID 指定新用户组的组标识号(GID)。
- -o 一般与-g选项同时使用,表示新用户组的GID可以与系统已有用户组的GID相同。
实例1:
# groupadd group1
此命令向系统中增加了一个新组group1,新组的组标识号是在当前已有的最大组标识号的基础上加1。
实例2:
# groupadd -g 101 group2
此命令向系统中增加了一个新组group2,同时指定新组的组标识号是101。
2、如果要删除一个已有的用户组,使用groupdel命令,其格式如下:
groupdel 用户组
例如:
# groupdel group1
此命令从系统中删除组group1。
3、修改用户组的属性使用groupmod命令。其语法如下:
groupmod 选项 用户组
常用的选项有:
- -g GID 为用户组指定新的组标识号。
- -o 与-g选项同时使用,用户组的新GID可以与系统已有用户组的GID相同。
- -n新用户组 将用户组的名字改为新名字
实例1:
# groupmod -g 102 group2
此命令将组group2的组标识号修改为102。
实例2:
# groupmod –g 10000 -n group3 group2
此命令将组group2的标识号改为10000,组名修改为group3。
4、如果一个用户同时属于多个用户组,那么用户可以在用户组之间切换,以便具有其他用户组的权限。
用户可以在登录后,使用命令newgrp切换到其他用户组,这个命令的参数就是目的用户组。例如:
$ newgrp root
这条命令将当前用户切换到root用户组,前提条件是root用户组确实是该用户的主组或附加组。类似于用户账号的管理,用户组的管理也可以通过集成的系统管理工具来完成。
与用户账号有关的系统文件
1、/etc/passwd文件是用户管理工作涉及的最重要的一个文件。
Linux系统中的每个用户都在/etc/passwd文件中有一个对应的记录行,它记录了这个用户的一些基本属性。
这个文件对所有用户都是可读的。它的内容类似下面的例子:
# cat /etc/passwd root:x:0:0:Superuser:/: daemon:x:1:1:System daemons:/etc: bin:x:2:2:Owner of system commands:/bin: sys:x:3:3:Owner of system files:/usr/sys: adm:x:4:4:System accounting:/usr/adm: uucp:x:5:5:UUCP administrator:/usr/lib/uucp: auth:x:7:21:Authentication administrator:/tcb/files/auth: cron:x:9:16:Cron daemon:/usr/spool/cron: listen:x:37:4:Network daemon:/usr/net/nls: lp:x:71:18:Printer administrator:/usr/spool/lp: sam:x:200:50:Sam san:/home/sam:/bin/sh
从上面的例子我们可以看到,/etc/passwd中一行记录对应着一个用户,每行记录又被冒号(:)分隔为7个字段,其格式和具体含义如下:
用户名:口令:用户标识号:组标识号:注释性描述:主目录:登录Shell
1)"用户名"是代表用户账号的字符串。
通常长度不超过8个字符,并且由大小写字母和/或数字组成。登录名中不能有冒号(:),因为冒号在这里是分隔符。
为了兼容起见,登录名中最好不要包含点字符(.),并且不使用连字符(-)和加号(+)打头。
2)“口令”一些系统中,存放着加密后的用户口令字。
虽然这个字段存放的只是用户口令的加密串,不是明文,但是由于/etc/passwd文件对所有用户都可读,所以这仍是一个安全隐患。因此,现在许多Linux 系统(如SVR4)都使用了shadow技术,把真正的加密后的用户口令字存放到/etc/shadow文件中,而在/etc/passwd文件的口令字段中只存放一个特殊的字符,例如“x”或者“*”。
3)“用户标识号”是一个整数,系统内部用它来标识用户。
一般情况下它与用户名是一一对应的。如果几个用户名对应的用户标识号是一样的,系统内部将把它们视为同一个用户,但是它们可以有不同的口令、不同的主目录以及不同的登录Shell等。
通常用户标识号的取值范围是0~65 535。0是超级用户root的标识号,1~99由系统保留,作为管理账号,普通用户的标识号从100开始。在Linux系统中,这个界限是500。
4)“组标识号”字段记录的是用户所属的用户组。
它对应着/etc/group文件中的一条记录。
5)“注释性描述”字段记录着用户的一些个人情况。
例如用户的真实姓名、电话、地址等,这个字段并没有什么实际的用途。在不同的Linux 系统中,这个字段的格式并没有统一。在许多Linux系统中,这个字段存放的是一段任意的注释性描述文字,用做finger命令的输出。
6)“主目录”,也就是用户的起始工作目录。
它是用户在登录到系统之后所处的目录。在大多数系统中,各用户的主目录都被组织在同一个特定的目录下,而用户主目录的名称就是该用户的登录名。各用户对自己的主目录有读、写、执行(搜索)权限,其他用户对此目录的访问权限则根据具体情况设置。
7)用户登录后,要启动一个进程,负责将用户的操作传给内核,这个进程是用户登录到系统后运行的命令解释器或某个特定的程序,即Shell。
Shell是用户与Linux系统之间的接口。Linux的Shell有许多种,每种都有不同的特点。常用的有sh(Bourne Shell), csh(C Shell), ksh(Korn Shell), tcsh(TENEX/TOPS-20 type C Shell), bash(Bourne Again Shell)等。
系统管理员可以根据系统情况和用户习惯为用户指定某个Shell。如果不指定Shell,那么系统使用sh为默认的登录Shell,即这个字段的值为/bin/sh。
用户的登录Shell也可以指定为某个特定的程序(此程序不是一个命令解释器)。
利用这一特点,我们可以限制用户只能运行指定的应用程序,在该应用程序运行结束后,用户就自动退出了系统。有些Linux 系统要求只有那些在系统中登记了的程序才能出现在这个字段中。
8)系统中有一类用户称为伪用户(pseudo users)。
这些用户在/etc/passwd文件中也占有一条记录,但是不能登录,因为它们的登录Shell为空。它们的存在主要是方便系统管理,满足相应的系统进程对文件属主的要求。
常见的伪用户如下所示:
伪 用 户 含 义 bin 拥有可执行的用户命令文件 sys 拥有系统文件 adm 拥有帐户文件 uucp UUCP使用 lp lp或lpd子系统使用 nobody NFS使用
拥有帐户文件
1、除了上面列出的伪用户外,还有许多标准的伪用户,例如:audit, cron, mail, usenet等,它们也都各自为相关的进程和文件所需要。
由于/etc/passwd文件是所有用户都可读的,如果用户的密码太简单或规律比较明显的话,一台普通的计算机就能够很容易地将它破解,因此对安全性要求较高的Linux系统都把加密后的口令字分离出来,单独存放在一个文件中,这个文件是/etc/shadow文件。 有超级用户才拥有该文件读权限,这就保证了用户密码的安全性。
2、/etc/shadow中的记录行与/etc/passwd中的一一对应,它由pwconv命令根据/etc/passwd中的数据自动产生
它的文件格式与/etc/passwd类似,由若干个字段组成,字段之间用":"隔开。这些字段是:
登录名:加密口令:最后一次修改时间:最小时间间隔:最大时间间隔:警告时间:不活动时间:失效时间:标志
- "登录名"是与/etc/passwd文件中的登录名相一致的用户账号
- "口令"字段存放的是加密后的用户口令字,长度为13个字符。如果为空,则对应用户没有口令,登录时不需要口令;如果含有不属于集合 { ./0-9A-Za-z }中的字符,则对应的用户不能登录。
- "最后一次修改时间"表示的是从某个时刻起,到用户最后一次修改口令时的天数。时间起点对不同的系统可能不一样。例如在SCO Linux 中,这个时间起点是1970年1月1日。
- "最小时间间隔"指的是两次修改口令之间所需的最小天数。
- "最大时间间隔"指的是口令保持有效的最大天数。
- "警告时间"字段表示的是从系统开始警告用户到用户密码正式失效之间的天数。
- "不活动时间"表示的是用户没有登录活动但账号仍能保持有效的最大天数。
- "失效时间"字段给出的是一个绝对的天数,如果使用了这个字段,那么就给出相应账号的生存期。期满后,该账号就不再是一个合法的账号,也就不能再用来登录了。
下面是/etc/shadow的一个例子:
# cat /etc/shadow root:Dnakfw28zf38w:8764:0:168:7::: daemon:*::0:0:::: bin:*::0:0:::: sys:*::0:0:::: adm:*::0:0:::: uucp:*::0:0:::: nuucp:*::0:0:::: auth:*::0:0:::: cron:*::0:0:::: listen:*::0:0:::: lp:*::0:0:::: sam:EkdiSECLWPdSa:9740:0:0::::
3、用户组的所有信息都存放在/etc/group文件中。
将用户分组是Linux 系统中对用户进行管理及控制访问权限的一种手段。
每个用户都属于某个用户组;一个组中可以有多个用户,一个用户也可以属于不同的组。
当一个用户同时是多个组中的成员时,在/etc/passwd文件中记录的是用户所属的主组,也就是登录时所属的默认组,而其他组称为附加组。
用户要访问属于附加组的文件时,必须首先使用newgrp命令使自己成为所要访问的组中的成员。
用户组的所有信息都存放在/etc/group文件中。此文件的格式也类似于/etc/passwd文件,由冒号(:)隔开若干个字段,这些字段有:
组名:口令:组标识号:组内用户列表
- "组名"是用户组的名称,由字母或数字构成。与/etc/passwd中的登录名一样,组名不应重复。
- "口令"字段存放的是用户组加密后的口令字。一般Linux 系统的用户组都没有口令,即这个字段一般为空,或者是*。
- "组标识号"与用户标识号类似,也是一个整数,被系统内部用来标识组。
- "组内用户列表"是属于这个组的所有用户的列表,不同用户之间用逗号(,)分隔。这个用户组可能是用户的主组,也可能是附加组。
/etc/group文件的一个例子如下:
root::0:root bin::2:root,bin sys::3:root,uucp adm::4:root,adm daemon::5:root,daemon lp::7:root,lp users::20:root,sam
四、添加批量用户
添加和删除用户对每位Linux系统管理员都是轻而易举的事,比
较棘手的是如果要添加几十个、上百个甚至上千个用户时,我们不太可能还使用useradd一个一个地添加,必然要找一种简便的创建大量用户的方法。Linux系统提供了创建大量用户的工具,可以让您立即创建大量用户,方法如下:
(1)先编辑一个文本用户文件。
每一列按照/etc/passwd密码文件的格式书写,要注意每个用户的用户名、UID、宿主目录都不可以相同,其中密码栏可以留做空白或输入x号。一个范例文件user.txt内容如下:
user001::600:100:user:/home/user001:/bin/bash user002::601:100:user:/home/user002:/bin/bash user003::602:100:user:/home/user003:/bin/bash user004::603:100:user:/home/user004:/bin/bash user005::604:100:user:/home/user005:/bin/bash user006::605:100:user:/home/user006:/bin/bash
(2)以root身份执行命令 /usr/sbin/newusers,从刚创建的用户文件user.txt中导入数据,创建用户:
# newusers < user.txt
然后可以执行命令 vipw 或 vi /etc/passwd 检查 /etc/passwd 文件是否已经出现这些用户的数据,并且用户的宿主目录是否已经创建。
(3)执行命令/usr/sbin/pwunconv。
将 /etc/shadow 产生的 shadow 密码解码,然后回写到 /etc/passwd 中,并将/etc/shadow的shadow密码栏删掉。这是为了方便下一步的密码转换工作,即先取消 shadow password 功能。
# pwunconv
(4)编辑每个用户的密码对照文件。
格式为:
用户名:密码
实例文件 passwd.txt 内容如下:
user001:123456 user002:123456 user003:123456 user004:123456 user005:123456 user006:123456
(5)以 root 身份执行命令 /usr/sbin/chpasswd。
创建用户密码,chpasswd 会将经过 /usr/bin/passwd 命令编码过的密码写入 /etc/passwd 的密码栏。
# chpasswd < passwd.txt
(6)确定密码经编码写入/etc/passwd的密码栏后。
执行命令 /usr/sbin/pwconv 将密码编码为 shadow password,并将结果写入 /etc/shadow。
# pwconv
这样就完成了大量用户的创建了,之后您可以到/home下检查这些用户宿主目录的权限设置是否都正确,并登录验证用户密码是否正确。
粘滞位(由一个root创建的公共目录,其他用户可以共同进行这个文件的操作)
当一个目录被设置为"粘滞位"(用chmod +t),则该目录下的文件只能由
一、超级管理员删除
二、该目录的所有者删除
三、该文件的所有者删除
粘滞位是一种特殊的权限标志,它通常应用于目录,而不是文件。当粘滞位设置在一个目录上时,它会限制对该目录中文件的删除,即使用户有对该目录的写权限。
粘滞位通常用于一些特定的系统目录,例如 /tmp 目录,以确保只有文件的所有者才能删除自己的文件,即使其他用户对该目录有写权限。
在一个目录上设置粘滞位可以通过在权限设置中使用符号“t”来表示,对应的权限位是最后一个“1”位。例如,典型的 /tmp 目录的权限设置可能如下所示:
drwxrwxrwt
粘滞位(Sticky Bit)通常用于目录,而不是文件。当粘滞位设置在目录上时,它有一个特殊的作用,即只有目录的所有者、文件的所有者或者超级用户才能删除目录中的文件,即使其他用户有写权限。
对于文件而言,设置粘滞位通常没有特定的用途。粘滞位主要用于目录,以确保在共享目录中,用户只能删除自己创建的文件。这对保护共享目录中的文件安全性和防止误删非常有用。
因此,粘滞位对于文件本身并没有直接的用途,它主要用于在目录上设置权限,控制谁有权删除目录中的文件。
这里的最后一个“t”表示粘滞位已经设置。如果没有粘滞位,相应的权限位则为“x”或“-”。
在一个root创建的权限为777的tmp目录中,其他用户可以对该目录进行任何操作。
如一个用户名为ptm1的用户创建了一个ptm1.txt文件,ptm2的用户创建了一个ptm2.txt文件,
根据文件的权限可以被不同用户访问修改。但是即使一个用户没有另一个用户文件的任何权限也可以进行该文件的删除。因为这个文件是建立在拥有权限777的目录上的。
在Linux系统中,即使一个用户没有对另一个用户文件的读、写或执行权限,仍然可以通过对文件所在目录的权限进行操作,来删除该文件。这是因为在Linux中,要删除一个文件,用户需要对该文件所在的目录具有写权限,而不是对文件本身有写权限。
具体来说,删除一个文件需要对该文件所在目录具有写权限。即使用户没有对文件的任何权限,只要对文件所在的目录有写权限,用户就可以删除该文件。这是因为删除一个文件实际上是在目录中移除对文件的引用。
目录设置了粘滞位,其他用户也不能修改文件所有者的文件了,尽管有写权限。
Linux 软件包管理器
APT (Advanced Package Tool)
APT(Advanced Package Tool)是一个用于 Debian 及其衍生发行版(如 Ubuntu)的软件包管理工具。它提供了一组用于安装、升级和删除软件包的命令,简化了软件包管理过程。以下是关于 APT 的详细信息:
-
安装软件包:
使用apt install命令可以安装软件包。例如,apt install package_name会安装名为package_name的软件包。 -
升级软件包:
使用apt upgrade命令可以升级已安装的软件包到最新版本。apt update会更新软件包列表,而apt upgrade会升级已安装的软件包。 -
搜索软件包:
使用apt search命令可以搜索软件包。例如,apt search keyword可以搜索包含关键字keyword的软件包。 -
删除软件包:
使用apt remove命令可以删除软件包,但保留相关的配置文件。要删除软件包及其相关配置文件,可以使用apt purge命令。
YUM (Yellowdog Updater Modified) / DNF (Dandified YUM)
YUM(Yellowdog Updater Modified)最初是 Red Hat Enterprise Linux(RHEL)和 CentOS 中使用的软件包管理器,后来逐渐被 DNF(Dandified YUM)取代。DNF 是 YUM 的下一代版本,提供了更多的功能和改进。以下是关于 YUM 和 DNF 的详细信息:
-
YUM 基本命令:
yum install package_name:安装软件包。yum update:更新系统中已安装的软件包。yum search keyword:搜索软件包。yum remove package_name:删除软件包。
-
DNF 特性:
- DNF 是 YUM 的新一代替代品,提供了更快的性能和改进的依赖解决方案。
- DNF 命令与 YUM 命令类似,但具有更多功能和更好的用户体验。
-
DNF 命令:
dnf install package_name:安装软件包。dnf upgrade:升级系统中已安装的软件包。dnf search keyword:搜索软件包。dnf remove package_name:删除软件包。
什么是软件包
在Linux下安装软件, 一个通常的办法是下载到程序的源代码, 并进行编译, 得到可执行程序. 但是这样太麻烦了, 于是有些人把一些常用的软件提前编译好, 做成软件包(可以理解成windows上的安 装程序)放在一个服务器上, 通过包管理器可以很方便的获取到这个编译好的软件包, 直接进行安装. 软件包和软件包管理器, 就好比 "App" 和 "应用商店" 这样的关系. yum(Yellow dog Updater, Modified)是Linux下非常常用的一种包管理器. 主要应用在Fedora, RedHat, Centos等发行版上.
apt(Advanced Package Tool)是用于 Debian 及其衍生发行版(如 Ubuntu)的软件包管理工具。
查看软件包
使用 apt 查看软件包信息:
-
查看软件包信息:
- 使用
apt show package_name命令可以查看特定软件包的详细信息。例如,要查看nginx软件包的信息,可以运行以下命令:复制
apt show nginx
- 使用
-
搜索软件包:
- 使用
apt search keyword命令可以搜索包含关键字keyword的软件包。例如,要搜索包含python关键字的软件包,可以运行以下命令:复制
apt search python
- 使用
使用 yum 查看软件包信息:
-
查看软件包信息:
- 使用
yum info package_name命令可以查看特定软件包的详细信息。例如,要查看nginx软件包的信息,可以运行以下命令:复制
yum info nginx
- 使用
-
搜索软件包:
- 使用
yum search keyword命令可以搜索包含关键字keyword的软件包。例如,要搜索包含python关键字的软件包,可以运行以下命令:复制
yum search python
- 使用
apt list
yum list
注意事项:
软件包名称: 主版本号.次版本号.源程序发行号-软件包的发行号.主机平台.cpu架构. "x86_64" 后缀表示64位系统的安装包, "i686" 后缀表示32位系统安装包. 选择包时要和系统匹配. "el7" 表示操作系统发行版的版本. "el7" 表示的是 centos7/redhat7. "el6" 表示 centos6/redhat6. 最后一列, base 表示的是 "软件源" 的名称, 类似于 "小米应用商店", "华为应用商店" 这样的概念.
安装软件
在 Debian/Ubuntu 系统上使用 apt 安装软件:
sudo apt update # 更新软件包列表
sudo apt install package_name # 安装软件包
在 Red Hat/CentOS 系统上使用 yum 安装软件:
sudo yum update # 更新软件包列表
sudo yum install package_name # 安装软件包卸载软件
在 Debian/Ubuntu 系统上使用 apt 卸载软件:
-
首先,您可以使用
apt list --installed命令列出已安装的软件包,以确定要卸载的软件包名称。 -
使用
apt remove命令卸载软件包。请注意,apt remove只会删除软件包,但不会删除相关的配置文件。
sudo apt remove package_name
如果您想删除软件包及其相关配置文件,可以使用 apt purge 命令:
sudo apt purge package_name
在 Red Hat/CentOS 系统上使用 yum 卸载软件:
-
使用
yum list installed命令列出已安装的软件包,以确定要卸载的软件包名称。 -
使用
yum remove命令卸载软件包。同样,这将仅删除软件包,而不会删除相关的配置文件。
sudo yum remove package_name
如果您想删除软件包及其相关配置文件,可以使用 yum erase 命令:
sudo yum erase package_namelrzsz文件传输工具
lrzsz 是一个软件包,其中包含了 rz 和 sz 这两个命令,用于在串行连接中进行文件的发送和接收。这些命令通常用于通过串口连接传输文件。
通过 SSH 连接的云服务器上使用 rz 和 sz 命令,您可以首先确保在服务器上安装了 lrzsz 软件包。然后,您可以在 SSH 会话中使用这些命令来进行文件传输。
SCP文件传输工具
SCP(Secure Copy Protocol)是一个用于在 Unix/Linux 系统之间安全地传输文件的命令行工具。它通过 SSH(Secure Shell)协议进行文件传输,提供了加密的方式来保护数据的安全性。以下是一些常见的用法和选项:
基本用法:
-
从本地主机复制文件到远程主机:
scp /path/to/local/file username@remote_host:/path/to/remote/directory -
从远程主机复制文件到本地主机:
scp username@remote_host:/path/to/remote/file /path/to/local/directory
选项和用法:
-
指定端口:
scp -P port /path/to/local/file username@remote_host:/path/to/remote/directory -
递归复制整个目录:
scp -r /path/to/local/directory username@remote_host:/path/to/remote/directory -
从远程主机复制整个目录:
scp -r username@remote_host:/path/to/remote/directory /path/to/local/directory -
指定密钥文件:
scp -i /path/to/private_key /path/to/local/file username@remote_host:/path/to/remote/directory -
压缩传输:
scp -C /path/to/local/file username@remote_host:/path/to/remote/directory -
限制带宽:
scp -l limit_in_kbps /path/to/local/file username@remote_host:/path/to/remote/directory
示例:
-
从本地主机复制文件到远程主机:
scp myfile.txt user@remotehost:/home/user/ -
从远程主机复制文件到本地主机:
scp user@remotehost:/home/user/remotefile.txt /local/path/
SCP 是一个强大且安全的文件传输工具,适用于在不同主机之间传输文件,尤其适用于保护数据传输安全性的应用场景。
pv 数据流进度监视工具
pv 是一个实用程序,用于监视数据流的进度。它通常用于管道操作,可以显示数据在管道中的流量、速度和进度条。pv 可以帮助您在终端中实时监控数据传输的进度。
以下是一些 pv 命令的常见用法:
-
基本用法:最简单的用法是将
pv插入到管道中,例如:cat file.txt | pv | gzip > file.txt.gz这将显示数据通过管道的传输速度和进度。
-
显示进度条:使用
-p参数可以显示进度条,例如:pv -p file.txt | gzip > file.txt.gz这会显示一个实时更新的进度条,表示数据传输的进度。
-
显示数据传输速度:使用
-r参数可以显示数据传输的速度,例如:pv -r file.txt | gzip > file.txt.gz这会显示实时更新的传输速度。
-
显示数据传输速度和进度条:您也可以同时显示传输速度和进度条,例如:
pv -per file.txt | gzip > file.txt.gz这将显示传输速度和进度条。
-
限制传输速度:使用
-L参数可以限制传输速度,例如:pv -L 1m file.txt | gzip > file.txt.gz这会限制传输速度为每秒 1MB。
通过使用 pv,可以更好地监控数据传输的进度和速度,特别是在处理大量数据或执行长时间运行的操作时。
Linux开发工具
Linux编辑器-vim的使用
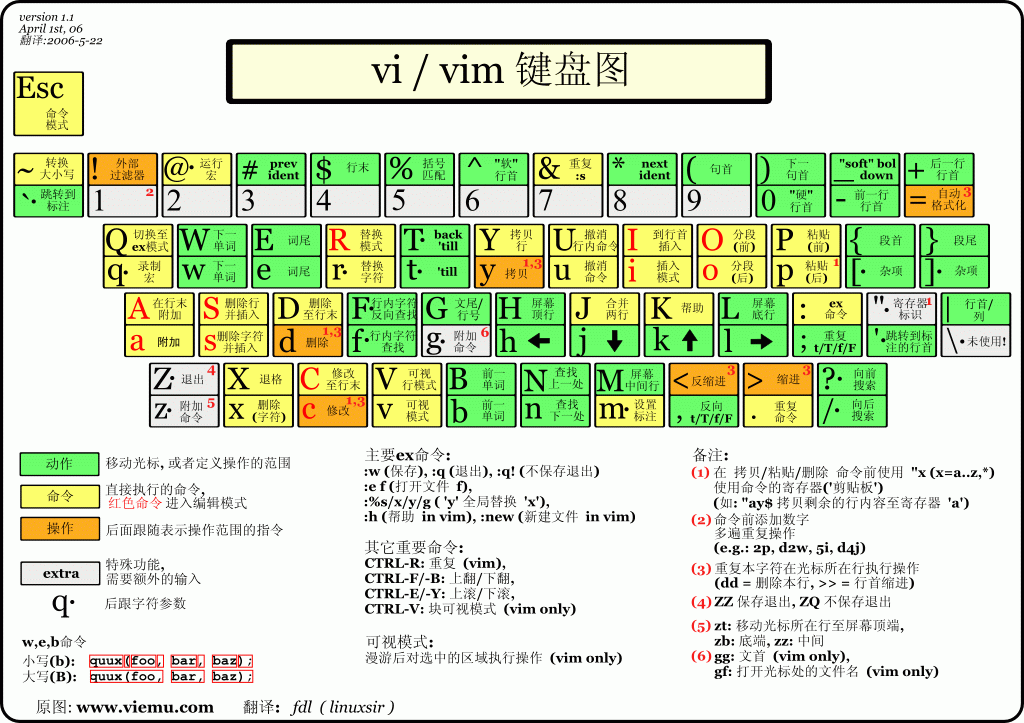
Vim 是一款功能强大的文本编辑器,广泛用于 Linux 和其他类 Unix 系统中。以下是一些基本的 Vim 使用指南:
打开/创建文件:
- 若要在 Vim 中打开文件,可以在终端中输入
vim 文件名。 - 若要创建一个新文件,可以输入
vim 新文件名。
退出 Vim:
- 要退出 Vim 并保存更改,请按
Esc键确保处于命令模式,然后输入:wq并按Enter。 - 若要强制退出 Vim 并放弃所有更改,请按
Esc键确保处于命令模式,然后输入:q!并按Enter。
移动光标:
- 使用
h、j、k、l键(左、下、上、右)或箭头键移动光标。
编辑文本:
- 在正常模式下按
i键进入插入模式,然后可以开始编辑文本。 - 在插入模式下按
Esc键返回命令模式。
保存文件:
- 在插入模式下按
:进入命令模式,然后输入w保存文件。
撤销和重做:
- 在命令模式下按
u撤销最后的操作。 - 撤销后,可以按
Ctrl + r来重做操作。
搜索文本:
- 在命令模式下,按
/进入搜索模式,输入要搜索的内容,然后按Enter。 - 若要查找下一个匹配项,可以按
n。
命令模式
用户刚刚启动 vi/vim,便进入了命令模式。
此状态下敲击键盘动作会被 Vim 识别为命令,而非输入字符,比如我们此时按下 i,并不会输入一个字符,i 被当作了一个命令。
以下是普通模式常用的几个命令:
- i -- 切换到输入模式,在光标当前位置开始输入文本。
- x -- 删除当前光标所在处的字符。
- : -- 切换到底线命令模式,以在最底一行输入命令。
- a -- 进入插入模式,在光标下一个位置开始输入文本。
- o:在当前行的下方插入一个新行,并进入插入模式。
- O -- 在当前行的上方插入一个新行,并进入插入模式。
- dd -- 剪切当前行。
- yy -- 复制当前行。
- p(小写) -- 粘贴剪贴板内容到光标下方。
- P(大写)-- 粘贴剪贴板内容到光标上方。
- u -- 撤销上一次操作。
- Ctrl + r -- 重做上一次撤销的操作。
- :w -- 保存文件。
- :q -- 退出 Vim 编辑器。
- :q! -- 强制退出Vim 编辑器,不保存修改。
若想要编辑文本,只需要启动 Vim,进入了命令模式,按下 i 切换到输入模式即可。
命令模式只有一些最基本的命令,因此仍要依靠底线命令行模式输入更多命令。
输入模式(插入模式)
在命令模式下按下 i 就进入了输入模式,使用 Esc 键可以返回到命令模式。
在输入模式中,可以使用以下按键:
- 字符按键以及Shift组合,输入字符
- ENTER,回车键,换行
- BACK SPACE,退格键,删除光标前一个字符
- DEL,删除键,删除光标后一个字符
- 方向键,在文本中移动光标
- HOME/END,移动光标到行首/行尾
- Page Up/Page Down,上/下翻页
- Insert,切换光标为输入/替换模式,光标将变成竖线/下划线
- ESC,退出输入模式,切换到命令模式
底行命令模式
在命令模式下按下 :(英文冒号)就进入了底行命令模式。
底行命令模式可以输入单个或多个字符的命令,可用的命令非常多。
在底行命令模式中,基本的命令有:
:w:保存文件。:q:退出 Vim 编辑器。:wq:保存文件并退出 Vim 编辑器。:q!:强制退出Vim编辑器,不保存修改。
按 ESC 键可随时退出底行命令模式。
vim的基本操作
以下是一些常用的 Vim 命令,涵盖了导航、编辑、保存和退出等方面的操作:
-
导航:
h或←:向左移动光标j或↓:向下移动光标k或↑:向上移动光标l或→:向右移动光标0或^:移动到当前行的开头$:移动到当前行的末尾gg:移动到文件的开头G:移动到文件的末尾:n:移动到第n行/word:向下搜索word?word:向上搜索wordn:重复上次搜索向前N:重复上次搜索向后Ctrl+f:向下翻页Ctrl+b:向上翻页
-
编辑:
i:在光标前插入a:在光标后插入o:在当前行之后插入新行x:删除光标所在处字符dd:删除当前行yy:复制当前行p:粘贴在光标后P:粘贴在光标前u:撤销上一步操作Ctrl+r:重做上一步操作:%s/old/new/g:替换old为new
-
保存和退出:
:w:保存文件:q:退出 Vim:q!:强制退出不保存:wq或:x:保存并退出
移动光标
vim可以直接用键盘上的光标来上下左右移动,但正规的vim是用小写英文字母「h」、「j」、「k」、
「l」,分别控制光标左、下、上、右移一格
按「G」:移动到文章的最后
按「 $ 」:移动到光标所在行的“行尾”
按「^」:移动到光标所在行的“行首”
按「w」:光标跳到下个字的开头
按「e」:光标跳到下个字的字尾
按「b」:光标回到上个字的开头
按「#l」:光标移到该行的第#个位置,如:5l,56l
按[gg]:进入到文本开始
按[shift+g]:进入文本末端
按「ctrl」+「b」:屏幕往“后”移动一页
按「ctrl」+「f」:屏幕往“前”移动一页
按「ctrl」+「u」:屏幕往“后”移动半页
按「ctrl」+「d」:屏幕往“前”移动半页
删除文字
「x」:每按一次,删除光标所在位置的一个字符
「#x」:例如,「6x」表示删除光标所在位置的“后面(包含自己在内)”6个字符
「X」:大写的X,每按一次,删除光标所在位置的“前面”一个字符
「#X」:例如,「20X」表示删除光标所在位置的“前面”20个字符
「dd」:删除光标所在行
「#dd」:从光标所在行开始删除#行
复制
「yw」:将光标所在之处到字尾的字符复制到缓冲区中。
「#yw」:复制#个字到缓冲区
「yy」:复制光标所在行到缓冲区。
「#yy」:例如,「6yy」表示拷贝从光标所在的该行“往下数”6行文字。
「p」:将缓冲区内的字符贴到光标所在位置。注意:所有与“y”有关的复制命令都必须与“p”配合才能完
成复制与粘贴功能。替换
「r」:替换光标所在处的字符。
「R」:替换光标所到之处的字符,直到按下「ESC」键为止。
撤销上一次操作
「u」:如果您误执行一个命令,可以马上按下「u」,回到上一个操作。按多次“u”可以执行多次回
复。
「ctrl + r」: 撤销的恢复
更改
「cw」:更改光标所在处的字到字尾处
「c#w」:例如,「c3w」表示更改3个字
跳至指定的行
「ctrl」+「g」列出光标所在行的行号。
「#G」:例如,「15G」,表示移动光标至文章的第15行行首。vim末行模式命令集
在使用末行模式之前,请记住先按「ESC」键确定您已经处于正常模式,再按「:」冒号即可进入末行模式。
列出行号
「set nu」: 输入「set nu」后,会在文件中的每一行前面列出行号。
跳到文件中的某一行
「#」:「#」号表示一个数字,在冒号后输入一个数字,再按回车键就会跳到该行了,如输入数字15,
再回车,就会跳到文章的第15行。
查找字符
「/关键字」向后查找: 先按「/」键,再输入您想寻找的字符,如果第一次找的关键字不是您想要的,可以一直按
「n」会往后寻找到您要的关键字为止。
「?关键字」向前查找:先按「?」键,再输入您想寻找的字符,如果第一次找的关键字不是您想要的,可以一直
按「n」会往前寻找到您要的关键字为止。
vim显示行号
底行模式下输入set nu
在 Vim 编辑器中,set nu 是一个命令,用于显示行号。当你输入 set nu 后,Vim 会在编辑器左侧显示每一行的行号,以便更容易地定位和引用特定行。
你可以在 Vim 中执行以下步骤来启用行号显示:
- 打开 Vim 编辑器。
- 进入命令模式,按下
Esc键确保你处于普通模式。 - 输入
:set nu并按下Enter键。
执行上述步骤后,Vim 将在左侧显示每一行的行号。如果你想禁用行号显示,可以使用 :set nonu 命令。
vim打开多个文件
底行模式下输入vs 文件名
:vs test.c #在vim中分屏幕打开另一个文本- 切换焦点:
Ctrl + w,然后按下w或方向键。- 在不同的窗口中切换焦点。
在Vim 中,您可以使用窗口分割功能来创建和管理多个窗口。以下是一些在Vim 中操作多个窗口的常用命令:
-
水平分割窗口:
:sp或:split:水平分割当前窗口,打开一个新窗口。Ctrl + w, s:通过按下Ctrl+w然后s键进行水平分割。
-
垂直分割窗口:
:vsp或:vsplit:垂直分割当前窗口,打开一个新窗口。Ctrl + w, v:通过按下Ctrl+w然后v键进行垂直分割。
-
在窗口之间切换:
Ctrl + w, w:在窗口之间切换焦点。Ctrl + w, h:切换到左侧窗口。Ctrl + w, j:切换到下方窗口。Ctrl + w, k:切换到上方窗口。Ctrl + w, l:切换到右侧窗口。
-
关闭窗口:
:q:关闭活动窗口。:qall或:qa:关闭所有窗口。
-
调整窗口大小:
Ctrl + w, +:增加当前窗口的高度。Ctrl + w, -:减小当前窗口的高度。Ctrl + w, >:增加当前窗口的宽度。Ctrl + w, <:减小当前窗口的宽度。
在Vim中,使用以下命令快速删除所有文本:
-
删除全部内容:
- 在正常模式下,您可以使用以下命令删除所有文本:
复制
gg " 将光标移动到文件的开头 dG " 删除从当前行到文件末尾的所有内容
- 在正常模式下,您可以使用以下命令删除所有文本:
-
清空当前文件:
- 如果您想保留一个空文件而不是关闭它,可以使用以下命令:
复制
:%d " 删除文件中的所有行
- 如果您想保留一个空文件而不是关闭它,可以使用以下命令:
-
删除整个文件内容:
- 如果您想彻底删除整个文件的内容,可以使用以下命令:
复制
:1,$d " 删除文件中的所有内容,包括未保存的更改
- 如果您想彻底删除整个文件的内容,可以使用以下命令:
在 Vim 中,低行模式下的 ! 符号用于执行外部命令。当您在低行模式(命令行模式)下输入 ! 后,可以在该符号后面输入要执行的外部命令,然后按下回车键来执行该命令。
在 Vim 中,可以使用 :r !{command} 的格式来将外部命令的输出插入到当前文档中。这使您可以将一个命令的输出作为文本插入到 Vim 编辑器的当前位置。
以下是一些示例:
将命令输出插入到新行:
输入 :r !{command} 并按回车键。如,要将 ls 命令的输出插入到当前光标位置,可以执行 :r !ls。
%s///g
在Vim中,:%s///g是一种用于全局替换的命令格式,其中%表示对整个文件进行操作,s表示替换操作,///用于指定查找和替换的模式,g表示全局替换(即一行中的所有匹配项都会被替换)。
具体解释如下:
::进入命令行模式。%:表示对整个文件进行操作。s:表示替换操作的开始。///:这里的两个斜杠之间是要查找的内容,第三个斜杠后面是要替换的内容。如果第一个斜杠之间留空,则表示重复上一次查找的模式。g:表示全局替换,即一行中的所有匹配项都会被替换。
在Vim中,除了:%s///g这种全局替换的命令格式外,还有一些类似的替换命令格式,可以根据需要进行特定的替换操作。以下是其中一些常用的替换命令格式:
-
仅替换当前行第一个匹配项:
:s/old/new/- 这个命令将会替换当前行中第一个匹配到的
old字符串为new字符串。
- 这个命令将会替换当前行中第一个匹配到的
-
替换当前行所有匹配项:
:s/old/new/g- 这个命令将会替换当前行中所有匹配到的
old字符串为new字符串。
- 这个命令将会替换当前行中所有匹配到的
-
替换整个文件中所有匹配项:
:%s/old/new/g- 这个命令将会替换整个文件中所有匹配到的
old字符串为new字符串。
- 这个命令将会替换整个文件中所有匹配到的
-
仅替换指定范围内的所有匹配项:
:'<,'>s/old/new/g- 这个命令将会替换选中范围内的所有匹配到的
old字符串为new字符串。
- 这个命令将会替换选中范围内的所有匹配到的
-
使用正则表达式进行替换:
:s/pattern/replacement/g- 这个命令将会使用正则表达式
pattern来匹配文本,并将匹配到的内容替换为replacement。
- 这个命令将会使用正则表达式
在Vim中,:x命令用于保存当前文件并且退出 Vim 编辑器。这个命令的作用相当于执行:wq,即保存文件并退出,如果文件没有修改,只会执行退出操作。
在Vim编辑器中,:X 命令是用于以加密方式保存当前文件的命令。当您输入 :X 并按下回车键时,Vim 会提示您输入一个密码来加密保存当前文件。
要取消 Vim 设置的密码(也称为密码保护功能),您可以按照以下步骤进行操作:
- 打开 Vim 编辑器并加载受密码保护的文件。
- 输入
:set key=命令并按下 Enter 键。这将清除密码保护设置。 - 保存文件并退出 Vim。
vim配置
Vim(Vi IMproved)是一个功能强大的文本编辑器,具有高度可定制性。Vim 的配置主要基于编辑器提供的配置文件(通常是 ~/.vimrc 文件),其中包含了用户定义的设置、键映射、插件等。
配置 Vim,您可以编辑 .vimrc 文件,这是 Vim 主要的配置文件。在 .vimrc 文件中,您可以设置各种选项、定义键映射、加载插件等。以下是一些常见的 Vim 配置示例:
-
设置行号和高亮显示:
set number " 显示行号 syntax on " 启用语法高亮 set hlsearch " 高亮显示搜索结果 -
设置缩进和自动补全:
set autoindent " 自动缩进 set tabstop=4 " 一个 Tab 等于 4 个空格 set expandtab " 将 Tab 转换为空格 -
定义键映射:
nnoremap <C-l> :nohlsearch<CR><C-l> " 清除搜索高亮 nnoremap <leader>w :w<CR> " 保存文件 -
插件管理(以 vim-plug 为例):
" 安装 vim-plug if empty(glob('~/.vim/autoload/plug.vim')) silent !curl -fLo ~/.vim/autoload/plug.vim --create-dirs \ https://raw.githubusercontent.com/junegunn/vim-plug/master/plug.vim autocmd VimEnter * PlugInstall --sync | source $MYVIMRC endif " 插件列表 call plug#begin('~/.vim/plugged') Plug 'tpope/vim-fugitive' Plug 'scrooloose/nerdtree' call plug#end() -
其他配置:
set background=dark " 设置暗色主题 colorscheme desert " 使用 desert 配色方案 set mouse=a " 允许使用鼠标 set completeopt=menu,menuone " 设置自动补全选项
Linux编译器gcc/g++
编译过程:
- 预处理:处理
#include头文件展开,去除注释,条件编译,#define宏替换等预处理指令。 - 编译:将预处理后的代码翻译成汇编语言。
- 汇编:将汇编代码转换成可重定向二进制目标文件(
.o文件)。 - 链接:将目标文件与必要的库文件链接以生成最终的可执行文件。
在编译过程中,gcc 和 g++ 编译器都会经历以下步骤:预处理、编译、汇编和链接。这些步骤将源代码转换为可执行文件。以下是每个步骤的简要说明:
1. 预处理 (Preprocessing):
- 目的:在编译之前对源代码进行预处理,包括展开头文件、宏替换等。
- 工具:
gcc和g++都使用cpp(C Preprocessor)工具执行预处理。 - 命令:
gcc -E source_file.c -o output_file.i
2. 编译 (Compiling):
- 目的:将预处理后的源代码翻译成汇编代码。
- 工具:
gcc使用cc1这个内部编译器进行编译。 - 命令:
gcc -S source_file.i -o output_file.s
3. 汇编 (Assembling):
- 目的:将汇编代码翻译成目标文件(
.o文件)。 - 工具:
as(汇编器)用于将汇编代码转换成机器指令。 - 命令:
as source_file.s -o output_file.o
4. 链接 (Linking):
- 目的:将目标文件与库文件链接为可执行文件。
- 工具:
ld(链接器)用于将目标文件链接成可执行文件。 - 命令:
gcc source_file.o -o output_file
在编译C程序时,gcc可以进行动态编译和静态编译。这两种编译方式在生成可执行文件时有所不同。
- 动态编译:在动态编译时,程序的依赖库(例如标准C库)不会被包含在可执行文件中。相反,可执行文件会在运行时动态链接到系统上已经存在的库。这使得可执行文件相对较小,但在运行时需要确保系统上已安装了所需的共享库。动态编译可以通过向
gcc添加-shared选项来实现。
gcc -o myprogram myprogram.c -shared
- 静态编译:在静态编译时,所有的依赖库会被包含在可执行文件中,使得可执行文件相对较大,但也更加独立。程序运行时不需要依赖系统上的共享库,因为所有需要的代码已经被静态链接到可执行文件中。可以通过向
gcc添加-static选项来实现静态编译。
gcc -o myprogram myprogram.c -static
选择动态编译还是静态编译取决于具体的需求和环境。动态编译能够减小可执行文件的大小,但需要确保系统上已安装了所需的共享库;而静态编译生成的可执行文件更加独立,但可能会较大。
示例:
对于 C 代码:
gcc -E source_file.c -o output_file.i # 预处理
gcc -S output_file.i -o output_file.s # 编译
gcc -c output_file.s -o output_file.o # 汇编
gcc output_file.o -o output_file # 链接
对于 C++ 代码:
g++ -E source_file.cpp -o output_file.i # 预处理
g++ -S output_file.i -o output_file.s # 编译
g++ -c output_file.s -o output_file.o # 汇编
g++ output_file.o -o output_file # 链接在编译时需要添加库文件和依赖项时,您可以使用 -l 选项指定要链接的库文件,使用 -L 选项指定库文件的搜索路径,以及使用 -I 选项指定头文件的搜索路径。以下是一些常见的用法:
添加库文件:
- 使用
-l选项来指定要链接的库文件。例如,-lm表示链接数学库。
gcc source_file.c -o output_file -lm
指定库文件搜索路径:
- 使用
-L选项来指定库文件的搜索路径。例如,假设要链接的库文件在/path/to/library目录下:
gcc source_file.c -o output_file -L/path/to/library -lmylib
指定头文件搜索路径:
- 使用
-I选项来指定头文件的搜索路径。例如,假设头文件在/path/to/include目录下:
gcc source_file.c -o output_file -I/path/to/include1. 优化级别选项:
-
-O0:表示编译器不进行任何优化,生成的代码保持易读性和调试性,但可能性能较低。 -
-O1:是默认优化级别,启用基本的优化,如删除没有用到的变量、内联函数等。 -
-O2:启用更多的优化,包括循环展开、内联函数、常量传播等,提高执行速度,但可能会增加编译时间。 -
-O3:是最高优化级别,启用所有优化选项,可能会导致生成的代码更快但也更难调试,同时编译时间可能更长。
2. 警告选项:
-
-w:表示关闭所有警告信息的输出,编译器不会产生任何警告。 -
-Wall:生成所有警告信息,包括一些潜在的代码问题,让开发者能够更好地发现潜在的错误。
ldd
ldd 命令是 Linux 系统下的一个工具,用于查看一个可执行文件或共享库的依赖关系,即它们需要哪些共享库才能正确运行。以下是关于 ldd 命令的一些详细解释:
1. 基本语法:
ldd [options] executable_file
executable_file: 要检查依赖项的可执行文件或共享库。options: 可选参数,可以对输出进行一些控制。
2. 工作原理:
ldd命令通过读取 ELF 格式的可执行文件或共享库的头部信息,找到其依赖的动态链接共享库列表,并递归地检查这些共享库的依赖。
3. 输出信息:
- 对于每个共享库,
ldd通常会显示它的路径,或者如果找不到该库,则显示 "not found"。 - 如果有共享库找不到,可能是因为它不在默认的库搜索路径中,您可以通过设置
LD_LIBRARY_PATH环境变量来指定其他搜索路径。
4. 常用选项:
-v或--verbose: 显示更详细的信息,包括版本号和调试信息。-u或--unused: 显示未使用的直接依赖。-r或--function-relocs: 显示重定位信息。
ELF
ELF(Executable and Linkable Format)是一种常见的二进制文件格式,用于可执行文件、共享库和目标文件。它是在类 Unix 系统上广泛使用的标准格式,用于存储程序的二进制代码、数据、符号表和其他相关信息。
ELF 文件结构:
ELF 文件由多个部分组成,包括:
-
文件头(File Header):包含了文件类型、目标体系结构、入口点地址等信息。
-
程序头表(Program Header Table):描述了可执行文件在内存中的布局。
-
节头表(Section Header Table):描述了各个节(Sections)的信息,每个节包含程序中的代码、数据或其他特定类型的信息。
-
节(Sections):包含了程序的代码、数据、符号表等信息。
-
符号表(Symbol Table):包含了程序中定义的符号,如变量、函数等的名称和地址信息。
-
重定位表(Relocation Table):包含了在链接时需要进行的地址重定向信息。
ELF 文件类型:
-
可执行文件(Executable File):包含可执行程序的二进制代码和数据,可以直接在操作系统中运行。
-
共享库(Shared Library):包含可在多个程序之间共享的代码和数据,可以在运行时动态加载到内存中。
-
目标文件(Object File):包含了编译后的代码、数据和符号信息,用于链接生成可执行文件或共享库。
ELF 文件操作工具:
-
readelf:查看 ELF 文件的内容和结构信息。 -
objdump:显示二进制文件的信息,包括汇编代码和其他相关信息。 -
nm:显示 ELF 文件中的符号表。 -
ldd:查看一个可执行文件或共享库的动态链接依赖关系。
ELF 文件格式为 Unix 系统提供了一种灵活且强大的二进制文件格式,使得程序可以在不同的系统架构和操作系统上运行,并提供了丰富的调试和分析工具来帮助开发人员理解和操作二进制文件。
静态库与动态库
静态库(Static Library):
- 文件类型:静态库以
.a(archive)为扩展名,例如libexample.a。 - 编译特点:在编译时将库的代码整合到可执行文件中,使得可执行文件在运行时不再需要库文件。
- 优点:编译后的可执行文件独立,不会受到库文件的影响,便于分发和部署。
- 缺点:如果多个程序使用相同的静态库,每个程序都会包含一份该库的代码,可能导致可执行文件变得较大。
- 创建和使用:使用
ar命令创建静态库,使用-l选项链接静态库到可执行文件。
动态库(Dynamic Library):
- 文件类型:动态库以
.so(shared object)为扩展名,例如libexample.so。 - 编译特点:在运行时由操作系统动态加载到内存,程序在运行时共享该库,不会将库的代码整合到可执行文件中。
- 优点:节省内存,多个程序可以共享同一份动态库,便于更新和维护。
- 缺点:程序运行时需要确保系统中存在相应的动态库,否则会导致运行错误。
- 创建和使用:使用
-shared选项编译生成动态库,使用-l选项链接动态库到可执行文件。
在 Linux 中,使用静态库和动态库取决于你的需求和项目的要求。常见的情况是,对于小型独立的程序或者需要在不同的环境中部署的程序,静态库可能更适合;而对于需要共享的库、提供插件机制或者需要动态加载的库,动态库则更为合适。
创建静态库和动态库涉及几个步骤,包括编写源代码、编译源代码生成目标文件、创建库文件以及链接库文件到项目中。下面是详细的步骤和每个步骤的指令解释:
创建静态库:
编写源文件 library.c:
echo '#include <stdio.h>' > library.c
echo 'void hello_static() { printf("Hello from static library!\n"); }' >> library.c
编译源文件生成目标文件 library.o:
gcc -c library.c -o library.o
gcc -c:表示编译但不链接,生成目标文件。
library.c:源文件。
-o library.o:指定生成的目标文件名为 library.o。
创建静态库 libhello_static.a:
ar rcs libhello_static.a library.o
ar:静态库管理工具。
rcs:分别代表创建 (r)、归档 (c)、重新构建静态库文件的索引 (s)。
libhello_static.a:指定生成的静态库文件名。
library.o:包含在静态库中的目标文件。
创建动态库:
编写源文件 library.c:
echo '#include <stdio.h>' > library.c
echo 'void hello_dynamic() { printf("Hello from dynamic library!\n"); }' >> library.c
编译源文件生成动态库 libhello_dynamic.so:
gcc -shared -fPIC library.c -o libhello_dynamic.so
-shared:生成共享库。
-fPIC:表示生成位置无关的代码。
位置无关代码:PIC 可以使生成的代码在内存中的任何位置执行,而不受加载地址的限制。这对于共享库尤其重要,因为它们在不同的进程中加载时可能会被加载到不同的地址。
library.c:源文件。
-o libhello_dynamic.so:指定生成的动态库文件名。
在决定何时使用 -fPIC 而不是 -fpic 时,主要考虑的因素包括:
目标平台的要求:不同的平台对于位置无关代码的要求可能有所不同。一般来说,-fPIC 生成的代码更灵活,但可能会有一些性能开销,而 -fpic 生成的代码则更小巧,但在某些平台上可能有限制。
共享库的大小:如果生成的共享库较小,并且不会超出 -fpic 的限制,那么可以选择使用 -fpic。
性能需求:如果性能对于应用程序至关重要,可能需要权衡代码大小和性能之间的权衡。在某些情况下,可能需要选择更高级别的 -fPIC。
目标平台的支持:某些平台可能只支持 -fPIC,因此在这种情况下,只能选择使用 -fPIC。
基本上,如果不确定应该选择哪个选项,通常可以首先尝试 -fPIC。如果遇到问题(例如生成的共享库太大),则可以考虑切换到 -fpic。在选择编译选项时,最好查阅特定平台和编译器的文档,以了解其支持的选项和限制,以便做出更明智的选择。
-fPIE 是 GCC 和其他兼容的编译器中的选项,用于生成可执行文件(Position Independent Executable,PIE)。PIE 是一种特殊类型的可执行文件,与传统的可执行文件相比,它更加安全,因为在加载和执行时会使用位置无关代码,有助于减少潜在的安全风险,如地址空间布局随机化(ASLR)。
用途和优势:
-
安全性:PIE 可以提高系统的安全性,因为它使用位置无关代码,使得随机化地址空间布局(ASLR)更加有效,降低了被攻击者利用的风险。
-
可移植性:PIE 生成的可执行文件可以在不同的地址空间加载并执行,这有助于提高可移植性,并且不容易受到地址相关问题的影响。
-
系统兼容性:许多现代操作系统和安全工具更倾向于使用 PIE 可执行文件,因此在需要与这些系统和工具良好兼容时,使用
-fPIE是一个好的选择。
使用示例:
gcc -fPIE -pie -o my_program my_program.c
-fPIE:告诉编译器生成位置无关代码。-pie:告诉链接器生成可执行文件而不是共享库。
注意事项:
- PIE 可执行文件通常比普通可执行文件稍微耗费一些性能,因为在加载时需要进行额外的重定位。
- 在对安全性要求较高的场景下,尤其是处理敏感数据或在受到攻击威胁的环境中,使用 PIE 可以提供额外的保护。
总的来说,使用 -fPIE 编译选项可以增强可执行文件的安全性,提高系统的安全性,并且有助于解决一些潜在的安全问题,特别是在受到攻击威胁的环境中。
-fPIC 和 -fPIE 都用于生成位置无关代码,但它们的主要区别在于它们的使用场景和用途:
-
-fPIC(Position Independent Code):- 用于生成位置无关代码,通常用于创建共享库(shared libraries)。
- 适用于共享库,因为共享库在加载时需要能够在内存中的任意位置执行。
- 生成的代码可以在共享库中使用,也可以在静态位置无关执行文件中使用。
-
-fPIE(Position Independent Executable):- 用于生成位置无关可执行文件,通常用于创建可执行文件或动态链接库。
- 适用于可执行文件,以提高系统的安全性,特别是在处理敏感数据或在受到攻击威胁的环境中。
- 生成的可执行文件会受益于随机化地址空间布局(ASLR)等安全功能。
虽然两者都生成位置无关代码,但它们的主要区别在于用途和目标。-fPIC 主要用于创建共享库,而 -fPIE 则用于创建可执行文件。在特定情况下,两者可能可以互换使用,但通常最好根据需求选择最适合的选项。
使用静态库和动态库的示例程序:
编写主程序 main.c:
echo '#include <stdio.h>' > main.c
echo 'void hello_static();' >> main.c
echo 'void hello_dynamic();' >> main.c
echo 'int main() { hello_static(); hello_dynamic(); return 0; }' >> main.c
链接静态库并创建可执行文件 static_example:
gcc main.c -o static_example -L. -lhello_static
-L.:告诉编译器在当前目录搜索库文件。
-lhello_static:链接名为 libhello_static.a 的静态库。
链接动态库并创建可执行文件 dynamic_example:
gcc main.c -o dynamic_example -L. -lhello_dynamic -Wl,-rpath,.
-L.:告诉编译器在当前目录搜索库文件。
-lhello_dynamic:链接名为 libhello_dynamic.so 的动态库。
-Wl,-rpath,.:在链接时指定运行时搜索动态库的路径为当前目录。
执行生成的 static_example 或 dynamic_example 可执行文件将调用相应的静态库或动态库中的函数,并输出相应的信息。
静态库命名:
- lib 前缀:静态库通常以
lib开头。 - 清晰描述:库名称应该清晰描述其功能或内容。
- 版本号:可以在库名称中包含版本号,例如
libexample_v1.a。 - 扩展名:静态库通常使用
.a扩展名。
示例: libexample.a
动态库命名:
- lib 前缀:动态库通常以
lib开头。 - 清晰描述:库名称应该清晰描述其功能或内容。
- 版本号:可以在库名称中包含版本号,例如
libexample_v1.so。 - 扩展名:动态库通常使用
.so扩展名。
示例: libexample.so
版本控制:
- 对于动态库,通常会包含版本号以便支持多个版本的库共存。
- 动态库一般会创建符号链接,比如
libexample.so->libexample.so.1,libexample.so.1->libexample.so.1.0。
其他建议:
- 简洁明了:命名应简洁明了,能够清晰表达库的功能。
- 避免特殊字符:尽量避免使用特殊字符或空格,以免造成命名上的混淆。
- 小写字母:通常建议使用小写字母,以避免在不同操作系统上的大小写问题。
ar工具
ar 是一个在 Unix 和类 Unix 系统上使用的命令行工具,用于创建、修改和提取静态库文件(archive files)。它通常用于管理目标文件集合,这些文件通常是用于生成可执行文件或共享库的编译单元。
以下是关于 ar 命令的一些常见用法和参数解释:
基本用法:
ar [options] archive-file files
archive-file:要创建或操作的静态库文件名。files:要添加到静态库中或从静态库中提取的文件列表。
常见选项:
-
-r:用于替换或添加文件到静态库中。ar -r archive.a file.o -
-c:用于创建一个新的静态库,如果该库不存在。ar -rc archive.a file1.o file2.o -
-t:列出静态库文件中的内容。ar -t archive.a -
-x:从静态库中提取文件。ar -x archive.a -
-d:从静态库中删除文件。ar -d archive.a file.o -
-s:重新构建静态库文件的索引。ar -s archive.a
其他说明:
ar命令通常用于管理静态库文件,这些文件包含了一个或多个目标文件。- 静态库文件通常用于在链接时与可执行文件一起使用,提供了一种代码复用的方式。
ar命令是 Unix/Linux 系统中标准的工具,常用于编译和构建 C/C++ 程序。
使用 ar 命令可以管理静态库文件,包括创建、更新、提取和删除文件等操作,有助于组织和管理项目中的目标文件,提高代码复用性和可维护性。
Linux调试器gdb
GDB(GNU调试器) 是一个功能强大的开源调试器,常用于调试C、C++等编程语言的程序。下面是一些基本的使用方法和常见的命令:
在 Linux 下使用 GDB:
-
编译程序时启用调试信息:
在编译时需要添加
-g选项,以便在调试时能够查看源代码。例如:gcc -g -o my_program my_program.c -
启动 GDB:
在终端中输入
gdb命令,后跟可执行文件名,如:gdb my_program -
常见 GDB 命令:
run:运行程序。break <line_number>:在指定行设置断点。next:执行下一行代码,不进入函数内部。step:执行下一行代码,如果是函数调用则进入函数内部。print <variable_name>:打印变量的值。info locals:显示当前作用域内的本地变量。backtrace或bt:显示函数调用栈。quit:退出 GDB。
-
调试过程:
- 设置断点:使用
break命令设置断点。 - 执行程序:使用
run命令运行程序。 - 逐步执行:使用
next或step命令逐步执行代码。 - 查看变量:使用
print命令查看变量的值。 - 查看堆栈:使用
backtrace命令查看函数调用栈。 - 退出调试器:使用
quit命令退出 GDB。
- 设置断点:使用
-
其他功能:
- 条件断点:使用
break命令并指定条件,如break 12 if x == 0。 - 监视点:使用
watch命令监视变量值的变化。 - 核心转储文件:使用
core命令加载核心转储文件进行调试。
- 条件断点:使用
程序的发布方式有两种,debug模式和release模式
Linux gcc/g++出来的二进制程序,默认是release模式
要使用gdb调试,必须在源代码生成二进制程序的时候, 加上 -g 选项gdb binFile 退出: ctrl + d 或 quit 调试命令:
list/l 行号:显示binFile源代码,接着上次的位置往下列,每次列10行。
list/l 函数名:列出某个函数的源代码。
r或run:运行程序。
n 或 next:单条执行。
s或step:进入函数调用
break(b) 行号:在某一行设置断点
break 函数名:在某个函数开头设置断点
info break :查看断点信息。
finish:执行到当前函数返回,然后挺下来等待命令
print(p):打印表达式的值,通过表达式可以修改变量的值或者调用函数
p 变量:打印变量值。
set var:修改变量的值
continue(或c):从当前位置开始连续而非单步执行程序
run(或r):从开始连续而非单步执行程序
delete breakpoints:删除所有断点
delete breakpoints n:删除序号为n的断点
disable breakpoints:禁用断点
enable breakpoints:启用断点
info(或i) breakpoints:参看当前设置了哪些断点
display 变量名:跟踪查看一个变量,每次停下来都显示它的值
undisplay:取消对先前设置的那些变量的跟踪
until X行号:跳至X行
breaktrace(或bt):查看各级函数调用及参数
info(i) locals:查看当前栈帧局部变量的值
quit:退出gdb
gdb列出源码
(gdb) list
在GDB调试器中,当您输入 list 命令时,它会显示当前位置周围的源代码。这可以帮助查看正在执行的代码的上下文,有助于理解程序的执行流程和可能的问题。
(gdb) l
在GDB中,l 是 list 命令的缩写。
(gdb) l 0
从源代码的开头部分显示。
gdb中设置断点
使用 break 或 b 命令设置在 Print 函数内的断点。可以通过行号或函数名来设置断点。
(gdb) b 20
(gdb) break Print
如果有多个同名函数,您可以在函数名后面加上文件名以指定具体的函数。
(gdb) break your_file.c:Print
运行程序: 继续执行程序。当程序执行到 Print 函数时,执行会在断点处暂停。
(gdb) continue
查看当前设置的断点列表,您可以使用 info breakpoints/break/b命令
(gdb) info b
使用 delete 或 clear 命令来删除断点。以下是删除断点的方法:
删除单个断点:
使用 delete 命令并指定要删除的断点编号来删除单个断点。
(gdb) delete 1
如果知道要删除的断点在源代码的特定行上,使用 clear 命令,并指定文件名和行号来删除该位置上的断点。
(gdb) clear your_file.c:10
删除所有断点:
如果想要删除所有断点,可以使用 delete 命令后跟 breakpoints 来删除所有断点。
(gdb) delete breakpoints
(gdb) del break
(gdb) d break
(gdb) d br
禁用断点:
如果想要保留断点信息但暂时禁用它们,可以使用 disable 命令。
(gdb) disable 1
启用断点:
要重新启用已禁用的断点,可以使用 enable 命令。
(gdb) enable 1
在程序运行时查看变量的值
使用 print 命令,后跟要查看的变量名或表达式,可以查看该变量的当前值。
(gdb) print variable_name
例如,要查看变量 sum 的值,可以执行以下命令:
(gdb) print sum
(gdb) p sum
使用 display 命令:
使用 display 命令可以持续显示一个表达式的值,每次程序停止时都会显示该值。
(gdb) display expression
这对于跟踪变量值的变化很有用。
在断点处查看变量:
当程序在断点处停止时,可以使用 print 命令来查看变量的值。
在程序运行时动态查看变量:
在程序运行时,您以随时使用 print 命令来查看变量的值。程序在遇到断点或手动停止时,会显示变量的当前值。
调试: 程序执行到断点处后,您可以使用 step 命令逐行执行代码,next 命令执行当前行并跳到下一行,print 命令打印变量的值等来进行调试。
step 命令:逐行执行代码,如果遇到函数调用会进入函数内部。
next 命令:执行当前行并跳到下一行,不会进入函数内部。
print 命令:打印变量的值。
continue 命令:继续执行程序直到下一个断点或程序结束。
运行程序:使用 run 命令来运行程序。
(gdb) r
(gdb) run
在 GDB 中,n 命令和 s 命令是两个常用的单步执行命令,它们之间有一些关键区别:
n 命令 (next):
n 命令用于执行当前行的代码,然后移到下一行。
如果当前行是一个函数调用,n 命令将执行整个函数并将控制权传回到调用者。
n 命令适用于快速地执行当前行并转到下一行,而不会进入函数内部。
s 命令 (step):
s 命令用于单步执行程序,一次执行一行代码。
如果当前行是一个函数调用,s 命令将进入该函数并逐步执行其中的代码。
s 命令适用于逐步跟踪程序的执行过程,包括进入函数并逐行执行其中的语句。
(gdb) n
(gdb) next
(gdb) s
(gdb) step
c 命令通常用于继续执行程序,直到遇到下一个断点或程序结束。
(gdb) c
(gdb) continue
bt 命令的作用是打印当前线程的调用堆栈(backtrace)
(gdb) bt
finish 命令用于执行当前函数的剩余部分,并停在函数返回的地方。这个命令在您想要跳出当前函数并返回到调用者处时非常有用。
(gdb) finish
undisplay 命令用于取消先前设置的显示表达式
(gdb) undisplay display_number
until 命令用于使程序执行直到达到指定的行号,然后停止。这个命令通常用于跳过循环或重复执行的代码,直到达到感兴趣的代码行。
(gdb) until line_number
set var 命令用于设置一个变量的值。这个命令可以帮助您在调试过程中手动更改程序中的变量的值。
(gdb) set var count = 10
info locals 是 GDB 中一个用于显示当前函数中局部变量信息的命令。
(gdb) info locals
Linux项目自动化构建工具make/Makefile
Makefile 是一种文本文件,用于定义项目的构建规则和依赖关系,以便通过构建工具 make 自动化构建整个项目。在 Linux 和类 Unix 系统中,make 是一个常用的构建工具,通过读取 Makefile 文件来执行编译、链接和其他构建任务。
Makefile 结构详解
-
规则(Rules):Makefile 包含一系列规则,每个规则指定了一个或多个目标文件如何生成,以及生成目标所需的依赖关系和命令。
-
变量(Variables):Makefile 中可以定义变量,用于存储编译器、编译选项等信息。在 Makefile 中,通过
=或:=运算符来定义变量,例如CXX = g++。 -
注释:可以使用
#符号开头的行来添加注释。 -
目标(Targets):目标是 Makefile 中的一个关键概念,表示一个构建的目标(如可执行文件、目标文件等)。
-
依赖关系(Dependencies):每个目标可以有零个或多个依赖项,表示生成目标所需的其他文件或目标。
-
命令(Commands):在每个规则中,可以定义用于生成目标的命令。这些命令必须以一个制表符(
\t)开头。 -
通配符(Wildcards):Makefile 支持通配符,例如
*.cpp可以匹配所有以.cpp结尾的文件。
示例
# 定义变量
CXX = g++
CXXFLAGS = -std=c++11 -Wall
# 默认目标
all: myprogram
# 规则:生成可执行文件
myprogram: main.o
$(CXX) $(CXXFLAGS) -o myprogram main.o
# 规则:生成目标文件
main.o: main.cpp
$(CXX) $(CXXFLAGS) -c main.cpp
# 清理规则
clean:
rm -f *.o myprogram
- 在这个示例中,
CXX和CXXFLAGS是变量,分别定义了编译器和编译选项。 all是默认目标,指定了要构建的可执行文件的名称。myprogram和main.o是规则,定义了如何生成可执行文件和目标文件。clean是用于清理项目的规则。
使用 Makefile
- 在终端中,可以通过运行
make命令来执行 Makefile 中定义的规则。 - 可以使用
make clean命令来清理项目。
.PHONY
在 Makefile 中,.PHONY 是一个特殊的目标,用于声明那些不是实际文件名的伪目标。声明一个目标为 .PHONY 可以确保这个目标不会和实际文件名冲突,并且每次执行时都会运行相应的命令,而不管是否存在以其名字命名的文件。使用 .PHONY 的示例:
.PHONY: clean
clean:
rm -f *.o
在上面的示例中,.PHONY: clean 声明了 clean 是一个伪目标。当你运行 make clean 时,无论是否存在名为 clean 的文件,rm -f *.o 命令都会被执行。
为什么使用 .PHONY:
避免与文件名冲突:如果存在一个叫做 clean 的文件,而你声明了 clean 为伪目标,那么 Make 会忽略文件 clean,执行你在 .PHONY 目标下定义的命令。
强制执行命令:声明为伪目标的目标会在每次执行时强制运行其下定义的命令,而不仅仅是在目标文件不存在时运行。
建议:
常见的伪目标:clean、all、install 等常见的操作可以声明为伪目标,以确保其命令被每次执行。
清理规则:通常用于清理生成的文件或对象文件。
结语:
.PHONY 是在 Makefile 中声明伪目标的一种方式,用于确保指定目标总是被执行,而不管是否存在同名文件。这有助于避免一些潜在的问题并确保 Make 的正确行为。
规则
Makefile由若干条规则(Rule)构成,每一条规则指出一个目标文件(Target),若干依赖文件(prerequisites),以及生成目标文件的命令。
目标文件: 依赖文件1 依赖文件2 ...
例如:
# 目标文件: 依赖文件1 依赖文件2
e.txt: c.txt d.txt
cat c.txt d.txt > e.txt
c.txt: a.txt b.txt
cat a.txt b.txt > c.txt
#上面的cat命令以Tab开头以Tab开头的是命令,用来生成目标文件。
注意:Makefile的规则中,命令必须以Tab开头,不能是空格。
root@iZ2vch4tdjuyi8htrm9i7hZ:~/Test# make
cat a.txt b.txt > c.txt
cat c.txt d.txt > e.txt
make默认执行第一条规则
make默认执行第一条规则,也就是创建e.txt,但是由于e.txt依赖的文件c.txt不存在(另一个依赖d.txt已存在),故需要先执行规则c.txt创建出c.txt文件,再执行规则e.txt。执行完成后,当前目录下生成了两个文件c.txt和e.txt。
可见,Makefile定义了一系列规则,每个规则在满足依赖文件的前提下执行命令,就能创建出一个目标文件,这就是英文Make file的意思。
把默认执行的规则放第一条,其他规则的顺序是无关紧要的,因为make执行时自动判断依赖。
此外,make会打印出执行的每一条命令,便于我们观察执行顺序以便调试。
root@iZ2vch4tdjuyi8htrm9i7hZ:~/Test# cat Makefile
test:test.o
gcc test.o -o test
test.i:test.c
gcc -E test.c -o test.i
test.o:test.s
gcc -c test.s -o test.o //顺序与下面的调换了
test.s:test.i
gcc -S test.i -o test.s
.PHONY:clean
clean:
rm -f *.o *.s *.i test
root@iZ2vch4tdjuyi8htrm9i7hZ:~/Test# make -f Makefile
gcc -E test.c -o test.i
gcc -S test.i -o test.s //正确执行命令
gcc -c test.s -o test.o
gcc test.o -o test
root@iZ2vch4tdjuyi8htrm9i7hZ:~/Test#
若再次运行make,输出如下:
root@iZ2vch4tdjuyi8htrm9i7hZ:~/Test# make -f Makefile
make: 'test' is up to date.
make检测到test已经是最新版本,不会再次执行,因为test的创建时间晚于它依赖文件的最后修改时间。
make使用文件的创建和修改时间来判断是否应该更新一个目标文件。
修改依赖文件后,运行make,会触发依赖文件的更新:
root@iZ2vch4tdjuyi8htrm9i7hZ:~/Test# make
cat a.txt b.txt > c.txt
cat c.txt d.txt > e.txt
root@iZ2vch4tdjuyi8htrm9i7hZ:~/Test# vim c.txt
root@iZ2vch4tdjuyi8htrm9i7hZ:~/Test# make
cat c.txt d.txt > e.txt
root@iZ2vch4tdjuyi8htrm9i7hZ:~/Test# vim d.txt
root@iZ2vch4tdjuyi8htrm9i7hZ:~/Test# make
cat c.txt d.txt > e.txt
root@iZ2vch4tdjuyi8htrm9i7hZ:~/Test#
但并不会触发c.txt的更新,原因是c.txt的依赖a.txt与b.txt并未更新,所以,make只会根据Makefile去执行那些必要的规则,并不会把所有规则都无脑执行一遍。
在编译大型程序时,全量编译往往需要几十分钟甚至几个小时。全量编译完成后,如果仅修改了几个文件,再全部重新编译完全没有必要,用Makefile实现增量编译就十分节省时间。
伪目标
在 Makefile 中,伪目标(phony targets)是指那些不对应真实文件名的目标,而是代表一种动作或操作。这些目标通常用于执行特定的任务,比如清理生成的文件、安装软件、运行测试等,而不是生成文件。
在 Makefile 中,声明一个目标为伪目标可以确保 make 工具不会误解它为要构建的文件,而是执行相应的任务。常见的做法是将这些伪目标放在 .PHONY 特殊目标下。
示例:
.PHONY: clean
clean:
rm -f test.i test.s test.o test
在这个示例中,clean 是一个伪目标,用于清理生成的目标文件(.o 文件)。通过声明为伪目标,即使存在名为 clean 的文件,make 也不会将其误解为要构建的文件,而会执行 rm -f *.o 命令。
为什么使用伪目标:
-
避免冲突:防止真实文件和目标名冲突,确保
make在执行时可以正确识别任务而不是文件生成。 -
强制执行:伪目标总是会执行其下定义的命令,无论是否存在同名文件。
常见的伪目标:
clean:清理生成的文件。all:构建整个项目。install:安装软件或文件。test:运行测试。
通过使用伪目标,你可以更好地组织 Makefile,并确保 make 在执行时按照你的意图执行任务。
因为test.i test.s test.o test都是自动生成的文件,所以,可以安全地删除。
然而,在执行clean时,我们并没有创建一个名为clean的文件,所以,因为目标文件clean不存在,每次运行make clean,都会执行这个规则的命令。
如果我们手动创建一个clean的文件,这个clean规则就不会执行了!
如果我们希望make把clean不要视为文件,可以添加一个标识:
.PHONY: clean
clean:
rm -f test.i test.s test.o test 此时,clean就不被视为一个文件,而是伪目标(Phony Target)。
大型项目通常会提供clean、install这些约定俗成的伪目标名称,方便用户快速执行特定任务。
一般来说,并不需要用.PHONY标识clean等约定俗成的伪目标名称,除非创建名字叫clean的文件。
执行多条命令
一个规则可以有多条命令,例如:
cd:
pwd
cd ..
pwd
执行cd规则:
root@iZ2vch4tdjuyi8htrm9i7hZ:~/Test# make cd
pwd
/root/Test
cd ..
pwd
/root/Test
观察输出,发现cd ..命令执行后,并未改变当前目录,两次输出的pwd是一样的,这是因为make针对每条命令,都会创建一个独立的Shell环境,类似cd ..这样的命令,并不会影响当前目录。
解决办法是把多条命令以;分隔,写到一行:
cd:
pwd; cd ..; pwd;
再执行cd目标就得到了预期结果:
root@iZ2vch4tdjuyi8htrm9i7hZ:~/Test# make cd
pwd;cd ..;touch hhu;mv ./hhu ./Test/;pwd;
/root/Test
/root
可以使用\把一行语句拆成多行,便于浏览:
cd:
pwd; \
cd ..; \
pwd
root@iZ2vch4tdjuyi8htrm9i7hZ:~/Test# make cd
pwd;\
cd ..;\
pwd;
/root/Test
/root
另一种执行多条命令的语法是用&&,它的好处是当某条命令失败时,后续命令不会继续执行:
&& 连接符用于在前一个命令成功(返回值为 0)时执行后续的命令。
cd:
pwd && cd .. && pwdroot@iZ2vch4tdjuyi8htrm9i7hZ:~/Test# make cd
pwd && cd .. && pwd
/root/Test
/root
使用||用于在前一个命令失败(返回值非零)时执行后续的命令。
root@iZ2vch4tdjuyi8htrm9i7hZ:~/Test# make cd
pwd || cd .. || pwd
/root/Test
root@iZ2vch4tdjuyi8htrm9i7hZ:~/Test#
如果 pwd 命令成功执行(返回值为0),则不会执行后续的命令,因为 || 连接符的左侧命令成功执行时不会执行右侧命令。
控制打印
默认情况下,make会打印出它执行的每一条命令。如果我们不想打印某一条命令,可以在命令前加上@,表示不打印命令(但是仍然会执行):
no:
@pwd
pwd
ls
root@iZ2vch4tdjuyi8htrm9i7hZ:~/Test# make no
/root/Test
pwd
/root/Test
ls
Makefile a.out a.txt b.txt c.txt d.txt e.txt hello.py hello.sh makefile test.c test.cpp
控制错误
make在执行命令时,会检查每一条命令的返回值,如果返回错误(非0值),就会中断执行。
erro:
rm hh
echo 'yes'
root@iZ2vch4tdjuyi8htrm9i7hZ:~/Test# make erro
rm hh
rm: cannot remove 'hh': No such file or directory
make: *** [makefile:18: erro] Error 1
有些时候,我们想忽略错误,继续执行后续命令,可以在需要忽略错误的命令前加上-:
17 erro:
-rm hh
echo 'yes'
root@iZ2vch4tdjuyi8htrm9i7hZ:~/Test# make erro
rm hh
rm: cannot remove 'hh': No such file or directory
make: [makefile:18: erro] Error 1 (ignored)
echo 'yes'
yes
make检测到rm zzz.txt报错,并打印错误,但显示(ignored),然后继续执行后续命令。
对于执行可能出错,但不影响逻辑的命令,可以用-忽略。
编译C程序
程序的编译通常分两步:
- 将每个
.c文件编译为.o文件; - 将所有
.o文件链接为最终的可执行文件。
假设一个C项目,包含hello.c、hello.h和main.c。
hello.c内容如下:
#include <stdio.h>
void hello()
{
printf("hello, world!\n");
}
hello.h内容如下:
void hello();
main.c内容如下:
#include <stdio.h>
#include "hello.h"
int main()
{
printf("start...\n");
hello();
printf("exit.\n");
return 0;
}注意到main.c引用了头文件hello.h。我们很容易梳理出需要生成的文件,逻辑如下:
┌───────┐ ┌───────┐ ┌───────┐
│hello.c│ │main.c │ │hello.h│
└───────┘ └───────┘ └───────┘
│ │ │
│ └────┬────┘
│ │
▼ ▼
┌───────┐ ┌───────┐
│hello.o│ │main.o │
└───────┘ └───────┘
│ │
└───────┬──────┘
│
▼
┌─────────┐
│ a.out │
└─────────┘
假定最终生成的可执行文件是a.out,中间步骤还需要生成hello.o和main.o两个文件。根据上述依赖关系,我们可以很容易地写出Makefile如下:
# 生成可执行文件:
a.out: hello.o main.o
cc -o a.out hello.o main.o
# 编译 hello.c:
hello.o: hello.c
cc -c hello.c
# 编译 main.c:
main.o: main.c hello.h
cc -c main.c
clean:
rm -f *.o a.out
执行make,输出如下:
root@iZ2vch4tdjuyi8htrm9i7hZ:~/Test# make
cc -c hello.c
cc -c main.c
cc -o a.out hello.o main.o
在当前目录下可以看到hello.o、main.o以及最终的可执行程序a.out。执行a.out:
root@iZ2vch4tdjuyi8htrm9i7hZ:~/Test# ./a.out
start
hello world!
end
与我们预期相符。
修改hello.c,把输出改为"hello c\n",再执行make,观察输出:
root@iZ2vch4tdjuyi8htrm9i7hZ:~/Test# make
cc -c hello.c
cc -o a.out hello.o main.o
仅重新编译了hello.c,并未编译main.c。由于hello.o已更新,所以,仍然要重新生成a.out。执行a.out:
root@iZ2vch4tdjuyi8htrm9i7hZ:~/Test# ./a.out
start
hello c
end
与我们预期相符。
修改hello.h:
int hello();
以及hello.c,再次执行make:
root@iZ2vch4tdjuyi8htrm9i7hZ:~/Test# make
cc -c hello.c
cc -c main.c
cc -o a.out hello.o main.o
会触发main.c的编译,因为main.c依赖hello.h。
执行make clean会删除所有的.o文件,以及可执行文件a.out,再次执行make就会强制全量编译:
root@iZ2vch4tdjuyi8htrm9i7hZ:~/Test# make clean && make
rm -f *.o a.out
cc -c hello.c
cc -c main.c
cc -o a.out hello.o main.o
这个简单的Makefile使我们能自动化编译C程序,十分方便。
使用隐式规则
即使我们把.o的规则删掉,也能正常编译:
# 只保留生成 a.out 的规则:
a.out: hello.o main.o
cc -o a.out hello.o main.o
clean:
rm -f *.o a.out
执行make,输出如下:
root@iZ2vch4tdjuyi8htrm9i7hZ:~/Test# make
cc -c -o hello.o hello.c
cc -c -o main.o main.c
cc -o a.out hello.o main.o
我们没有定义hello.o和main.o的规则,为什么make也能正常创建这两个文件?
因为make最初就是为了编译C程序而设计的,为了免去重复创建编译.o文件的规则,make内置了隐式规则(Implicit Rule),即遇到一个xyz.o时,如果没有找到对应的规则,就自动应用一个隐式规则:
xyz.o: xyz.c
cc -c -o xyz.o xyz.c
make针对C、C++、ASM、Fortran等程序内置了一系列隐式规则,可以参考官方手册查看。
对于C程序来说,使用隐式规则有一个潜在问题,那就是无法跟踪.h文件的修改。如果我们修改了hello.h的定义,由于隐式规则main.o: main.c并不会跟踪hello.h的修改,导致main.c不会被重新编译。
使用变量
当我们在Makefile中重复写很多文件名时,一来容易写错,二来如果要改名,要全部替换,费时费力。
编程语言使用变量(Variable)来解决反复引用的问题,类似的,在Makefile中,也可以使用变量来解决重复问题。
如:
a.out: hello.o main.o
cc -o a.out hello.o main.o
clean:
rm -f *.o a.out
编译的最终文件a.out重复出现了3次,因此,完全可以定义一个变量来替换它:
TARGET = a.out
$(TARGET): hello.o main.o
cc -o $(TARGET) hello.o main.o
clean:
rm -f *.o $(TARGET)
变量定义用变量名 = 值或者变量名 := 值,通常变量名全大写。引用变量用$(变量名),非常简单。
注意到hello.o main.o这个“列表”也重复了,我们也可以用变量来替换:
OBJS = hello.o main.o
TARGET = a.out
$(TARGET): $(OBJS)
cc -o $(TARGET) $(OBJS)
clean:
rm -f *.o $(TARGET)
如果有一种方式能让make自动生成hello.o main.o这个“列表”,就更好了。注意到每个.o文件是由对应的.c文件编译产生的,因此,可以让make先获取.c文件列表,再替换,得到.o文件列表:
# $(wildcard *.c) 列出当前目录下的所有 .c 文件: hello.c main.c
# 用函数 patsubst 进行模式替换得到: hello.o main.o
OBJS = $(patsubst %.c,%.o,$(wildcard *.c))
TARGET = a.out
$(TARGET): $(OBJS)
cc -o $(TARGET) $(OBJS)
clean:
rm -f *.o $(TARGET)
wildcard *.c会匹配当前目录下的所有以.c结尾的文件,并将它们作为一个文件列表返回。patsubst %.c, %.o, ...会将这个文件列表中所有以.c结尾的文件名替换为对应的.o文件名。
这样,我们每添加一个.c文件,不需要修改Makefile,变量OBJS会自动更新。
内置变量
我们还可以用变量$(CC)替换命令cc:
$(TARGET): $(OBJS)
$(CC) -o $(TARGET) $(OBJS)
没有定义变量CC也可以引用它,因为它是make的内置变量(Builtin Variables),表示C编译器的名字,默认值是cc,我们也可以修改它,例如使用交叉编译时,指定编译器:
CC = riscv64-linux-gnu-gcc
...
自动变量
在Makefile中,经常可以看到$@、$<这样的变量,这种变量称为自动变量(Automatic Variable),它们在一个规则中自动指向某个值。
例如,$@表示目标文件,$^表示所有依赖文件,因此,我们可以这么写:
a.out: hello.o main.o
cc -o $@ $^
在没有歧义时可以写$@,也可以写$(@),有歧义时必须用括号,例如$(@D)。
为了更好地调试,我们还可以把变量打印出来:
a.out: hello.o main.o
@echo '$$@ = $@' # 变量 $@ 表示target
@echo '$$< = $<' # 变量 $< 表示第一个依赖项
@echo '$$^ = $^' # 变量 $^ 表示所有依赖项
cc -o $@ $^
执行结果输出如下:
$@ = a.out
$< = hello.o
$^ = hello.o main.o
cc -o a.out hello.o main.o$^:代表规则中所有的依赖文件列表,用空格分隔。$<:代表规则中的第一个依赖文件(源文件)。$@:代表规则中的目标文件名。$*:代表目标文件名中的通配符部分。比如,如果目标文件是program.o,那么$*就代表program。$?:代表比目标文件更新的所有依赖文件列表,用空格分隔。$(@D):代表目标文件的目录部分。$(@F):代表目标文件的文件名部分。$(<D):代表依赖文件的目录部分。$(<F):代表依赖文件的文件名部分。
使用模式规则
使用隐式规则可以让make在必要时自动创建.o文件的规则,但make的隐式规则的命令是固定的,对于xyz.o: xyz.c,它实际上是:
$(CC) $(CFLAGS) -c -o $@ $<
能修改的只有变量$(CC)和$(CFLAGS)。如果要执行多条命令,使用隐式规则就不行了。
这时,我们可以自定义模式规则(Pattern Rules),它允许make匹配模式规则,如果匹配上了,就自动创建一条模式规则。
如:
OBJS = $(patsubst %.c,%.o,$(wildcard *.c))
TARGET = a.out
$(TARGET): $(OBJS)
cc -o $(TARGET) $(OBJS)
# 模式匹配规则:当make需要目标 xyz.o 时,自动生成一条 xyz.o: xyz.c 规则:
%.o: %.c
@echo 'compiling $<...'
cc -c -o $@ $<
clean:
rm -f *.o $(TARGET)
当make执行a.out: hello.o main.o时,发现没有hello.o文件,于是需要查找以hello.o为目标的规则,结果匹配到模式规则%.o: %.c,于是make自动根据模式规则为我们动态创建了如下规则:
hello.o: hello.c
@echo 'compiling $<...'
cc -c -o $@ $<
查找main.o也是类似的匹配过程,于是我们执行make,就可以用模式规则完成编译:
$ make
compiling hello.c...
cc -c -o hello.o hello.c
compiling main.c...
cc -c -o main.o main.c
cc -o a.out hello.o main.o
模式规则的命令完全由我们自己定义,因此,它比隐式规则更灵活。
自动生成依赖
隐式规则和模式规则,这两种规则都可以解决自动把.c文件编译成.o文件,但都无法解决.c文件依赖.h文件的问题。
因为一个.c文件依赖哪个.h文件必须要分析文件内容才能确定,没有一个简单的文件名映射规则。
但是,要识别出.c文件的头文件依赖,可以用GCC提供的-MM参数:
$ cc -MM main.c
main.o: main.c hello.h
上述输出告诉我们,编译main.o依赖main.c和hello.h两个文件。
因此,我们可以利用GCC的这个功能,对每个.c文件都生成一个依赖项,通常我们把它保存到.d文件中,再用include引入到Makefile,就相当于自动化完成了每个.c文件的精准依赖。
我们改写Makefile如下:
# 列出所有 .c 文件:
SRCS = $(wildcard *.c)
# 根据SRCS生成 .o 文件列表:
OBJS = $(SRCS:.c=.o)
# 根据SRCS生成 .d 文件列表:
DEPS = $(SRCS:.c=.d)
TARGET = a.out
# 默认目标:
$(TARGET): $(OBJS)
$(CC) -o $@ $^
# xyz.d 的规则由 xyz.c 生成:
%.d: %.c
rm -f $@; \
$(CC) -MM $< >$@.tmp; \
sed 's,\($*\)\.o[ :]*,\1.o $@ : ,g' < $@.tmp > $@; \
rm -f $@.tmp
# 模式规则:
%.o: %.c
$(CC) -c -o $@ $<
clean:
rm -rf *.o *.d $(TARGET)
# 引入所有 .d 文件:
include $(DEPS)
变量$(SRCS)通过扫描目录可以确定为hello.c main.c,因此,变量$(OBJS)赋值为hello.o main.o,变量$(DEPS)赋值为hello.d main.d。
通过include $(DEPS)我们引入hello.d和main.d文件,但是这两个文件一开始并不存在,不过,make通过模式规则匹配到%.d: %.c,这就给了我们一个机会,在这个模式规则内部,用cc -MM命令外加sed把.d文件创建出来。
运行make,首次输出如下:
$ make
Makefile:31: hello.d: No such file or directory
Makefile:31: main.d: No such file or directory
rm -f main.d; \
cc -MM main.c >main.d.tmp; \
sed 's,\(main\)\.o[ :]*,\1.o main.d : ,g' < main.d.tmp > main.d; \
rm -f main.d.tmp
rm -f hello.d; \
cc -MM hello.c >hello.d.tmp; \
sed 's,\(hello\)\.o[ :]*,\1.o hello.d : ,g' < hello.d.tmp > hello.d; \
rm -f hello.d.tmp
cc -c -o hello.o hello.c
cc -c -o main.o main.c
cc -o a.out hello.o main.o
make会提示找不到hello.d和main.d,不过随后自动创建出hello.d和main.d。hello.d内容如下:
hello.o hello.d : hello.c
上述规则有两个目标文件,实际上相当于如下两条规则:
hello.o : hello.c
hello.d : hello.c
main.d内容如下:
main.o main.d : main.c hello.h
因此,main.o依赖于main.c和hello.h,这个依赖关系就和我们手动指定的一致。
改动hello.h,再次运行make,可以触发main.c的编译:
$ make
rm -f main.d; \
cc -MM main.c >main.d.tmp; \
sed 's,\(main\)\.o[ :]*,\1.o main.d : ,g' < main.d.tmp > main.d; \
rm -f main.d.tmp
cc -c -o main.o main.c
cc -o a.out hello.o main.o
在实际项目中,对每个.c文件都可以生成一个对应的.d文件表示依赖关系,再通过include引入到Makefile,同时又能让make自动更新.d文件
完善Makefile
对项目目录进行整理,把所有源码放入src目录,所有编译生成的文件放入build目录:
<project>
├── Makefile
├── build
└── src
├── hello.c
├── hello.h
└── main.c
整理Makefile,内容如下:
SRC_DIR = ./src
BUILD_DIR = ./build
TARGET = $(BUILD_DIR)/a.out
CC = cc
CFLAGS = -Wall
# ./src/*.c
SRCS = $(shell find $(SRC_DIR) -name '*.c')
# ./src/*.c => ./build/*.o
OBJS = $(patsubst $(SRC_DIR)/%.c,$(BUILD_DIR)/%.o,$(SRCS))
# ./src/*.c => ./build/*.d
DEPS = $(patsubst $(SRC_DIR)/%.c,$(BUILD_DIR)/%.d,$(SRCS))
# 默认目标:
all: $(TARGET)
# build/xyz.d 的规则由 src/xyz.c 生成:
$(BUILD_DIR)/%.d: $(SRC_DIR)/%.c
@mkdir -p $(dir $@); \
rm -f $@; \
$(CC) -MM $< >$@.tmp; \
sed 's,\($*\)\.o[ :]*,$(BUILD_DIR)/\1.o $@ : ,g' < $@.tmp > $@; \
rm -f $@.tmp
# build/xyz.o 的规则由 src/xyz.c 生成:
$(BUILD_DIR)/%.o: $(SRC_DIR)/%.c
@mkdir -p $(dir $@)
$(CC) $(CFLAGS) -c -o $@ $<
# 链接:
$(TARGET): $(OBJS)
@echo "buiding $@..."
@mkdir -p $(dir $@)
$(CC) -o $(TARGET) $(OBJS)
# 清理 build 目录:
clean:
@echo "clean..."
rm -rf $(BUILD_DIR)
# 引入所有 .d 文件:
-include $(DEPS)
这个Makefile定义了源码目录SRC_DIR、生成目录BUILD_DIR,以及其他变量,同时用-include消除了.d文件不存在的错误。执行make,输出如下:
$ make
cc -Wall -c -o build/hello.o src/hello.c
cc -Wall -c -o build/main.o src/main.c
buiding build/a.out...
cc -o ./build/a.out ./build/hello.o ./build/main.o输出不同颜色字符
在终端中输出彩色字符通常是通过使用 ANSI 转义码来实现的。ANSI 转义码是一种特殊的控制字符序列,用于控制文本终端的输出格式,包括文本颜色、背景颜色、样式等。在这里,我将详细解释输出颜色字符的原理及过程:
原理:
ANSI 转义码:ANSI 转义码是以 \x1b[ 开头的特殊字符序列,用于告诉终端应该如何显示后续的文本。
颜色设置:通过发送适当的 ANSI 转义码序列,可以控制终端显示的前景色和背景色。比如,\x1b[31m 可以设置文本颜色为红色。
文本样式:除了颜色外,还可以通过 ANSI 转义码设置文本样式,如粗体、斜体、下划线等。
过程:
选择颜色:
开发者在输出文本之前插入特定的 ANSI 转义码序列来选择所需的颜色或样式。例如,\x1b[31m 选择红色作为文本颜色。
输出文本:
开发者在 ANSI 转义码后直接输出希望显示的文本内容。这些文本将会以之前设置的颜色和样式显示。
重置样式:
在需要改变颜色或样式的地方,或者在文本输出结束后,通常会发送重置样式的 ANSI 转义码 \x1b[0m,以确保后续文本不受之前样式的影响。
显示效果:
文本及其样式会根据设置的 ANSI 转义码在终端上显示相应的颜色和样式效果
当在终端中使用 ANSI 转义码来设置文本颜色时,可以使用不同的 ANSI 色彩代码来表示不同的颜色。以下是一些常用的 ANSI 色彩代码及其对应的颜色:
前景色:
\x1b[30m: 黑色
\x1b[31m: 红色
\x1b[32m: 绿色
\x1b[33m: 黄色
\x1b[34m: 蓝色
\x1b[35m: 紫色
\x1b[36m: 青色
\x1b[37m: 白色
背景色:
\x1b[40m: 黑色
\x1b[41m: 红色
\x1b[42m: 绿色
\x1b[43m: 黄色
\x1b[44m: 蓝色
\x1b[45m: 紫色
\x1b[46m: 青色
\x1b[47m: 白色
这些 ANSI 色彩代码可以与其他 ANSI 转义码结合使用,如重置样式 \x1b[0m,以创建丰富的文本效果。在终端中使用这些 ANSI 色彩代码,可以让您的文本在不同的颜色中进行展示,提高可读性或突出显示特定内容。
闪烁:
\x1b[5m: 开启闪烁效果
\x1b[25m: 关闭闪烁效果
加粗:
\x1b[1m: 开启加粗文本
\x1b[22m: 关闭加粗文本
斜体:
\x1b[3m: 开启斜体文本
\x1b[23m: 关闭斜体文本
下划线:
\x1b[4m: 开启下划线
\x1b[24m: 关闭下划线
反转(文本背景色与前景色对调):
\x1b[7m: 开启反转
\x1b[27m: 关闭反转
隐藏(隐藏文本):
\x1b[8m: 开启隐藏
\x1b[28m: 关闭隐藏
#include <stdio.h>
#include <string.h>
#include <windows.h> // 包含 Windows.h 头文件以使用 Sleep 函数
// 进度条函数
void ProcessOn()
{
int cnt = 0; // 进度计数
char bar[101]; // 进度条数组
char buf[] = { '|', '\\', '-', '/' }; // 旋转动画符号数组
memset(bar, '\0', sizeof(bar)); // 初始化进度条数组
while (cnt < 101)
{
// 输出带有 ANSI 转义码的进度条
printf("\x1b[31m [%-100s]\x1b[32m[%d%%]\x1b[33m[%c]\r", bar, cnt, buf[cnt % 4]);
bar[cnt++] = '#'; // 更新进度条
Sleep(20); // 等待一段时间,模拟进度更新
fflush(stdout); // 清空输出缓冲区,立即显示更新
}
printf("\n"); // 输出换行符,结束进度条显示
}
int main()
{
ProcessOn(); // 调用进度条函数
return 0;
}使用 git 命令行
-
克隆仓库:
git clone <repository_url>从远程仓库克隆代码到本地。
-
添加文件到暂存区:
git add <file_name>将文件添加到 Git 的暂存区,准备提交。
-
提交更改:
git commit -m "Commit message"将暂存区的更改提交到本地仓库。
-
推送到远程仓库:
git push origin <branch_name>将本地分支的更改推送到远程仓库。
-
拉取远程仓库更改:
git pull从远程仓库拉取最新更改并合并到本地分支。
-
查看文件状态:
git status查看工作目录和暂存区的文件状态。
-
查看提交历史:
git log查看提交历史记录。
-
创建分支:
git branch <branch_name>创建一个新的分支。
-
切换分支:
git checkout <branch_name>切换到指定分支。
-
合并分支:
git merge <branch_name>将指定分支合并到当前分支。
Git是一个分布式版本控制系统,它被设计用于高效地处理从小型到非常大型项目的所有内容。
root@iZ2vch4tdjuyi8htrm9i7hZ:/home/r7ftf/giteedir/dir# cd ../../../ test
-bash: cd: too many arguments
root@iZ2vch4tdjuyi8htrm9i7hZ:/home/r7ftf/giteedir/dir# cd ../../../test
在Linux系统中,涉及多级目录时不要加空格。问题出现在输入命令时的空格位置。
如上正确的命令应该是:
cd ../../../test
进程
进程(Process)是计算机中正在运行的程序的实例。在操作系统中,进程是程序在执行过程中分配和管理资源的基本单位。每个进程都有自己的内存空间、代码、数据和系统资源。
/proc 是一个特殊的虚拟文件系统,它在 Linux 系统中扮演着关键的角色。下面是关于 /proc 文件系统的一些重要信息:
作用:
/proc 文件系统提供了一个动态的视图,用于查看系统内核和运行中进程的信息。它不包含实际的文件,而是提供了一个接口,通过读取这些文件可以获取系统状态和进程信息。
内容:
/proc 文件系统中包含了大量以数字命名的目录和文件,其中每个目录和文件对应一个进程或系统信息。例如,/proc/cpuinfo 包含有关 CPU 的信息,/proc/meminfo 包含有关内存的信息。
常见用途:
在 /proc 文件系统中,可以查看系统的各种信息,如进程列表、系统负载、内存使用情况、CPU 信息等。
还可以通过读取特定文件来获取有关运行中进程的详细信息,如进程 ID、进程状态、进程命令行等。
示例:
例如,可以使用 cat /proc/cpuinfo 命令来查看 CPU 的详细信息,或者使用 ps aux 命令结合 /proc 目录中的信息来查看系统中的进程信息。
另外,可以通过浏览 /proc/<PID> 目录中的文件来查看特定进程的详细信息,其中 <PID> 是进程的 ID。
注意事项:
/proc 文件系统中的信息是动态生成的,并且在访问时会实时更新。因此,可以在运行时查看系统和进程的最新信息。
大多数 /proc 中的文件都是只读的,用于提供系统信息,尝试修改这些文件可能会导致系统不稳定。
以下是关于进程的一些重要概念:
进程特点:
独立性:每个进程都是独立的实体,拥有自己的内存空间和资源。
并发性:多个进程可以同时运行,通过操作系统的调度算法控制进程之间的执行顺序。
动态性:进程的创建、执行和销毁是动态发生的,可以根据系统需求进行调度管理。
资源分配:进程可以请求和释放系统资源,如内存、CPU 时间、文件等。
进程状态:
运行态(Running):进程正在执行。
就绪态(Ready):进程已经准备好执行,等待被调度。
阻塞态(Blocked):进程暂时停止执行,等待某个事件的发生。
创建态(New):进程正在被创建。
终止态(Terminated):进程执行完毕或被终止。
进程控制块(PCB):
进程控制块是操作系统中用于管理进程的数据结构,存储了进程的各种信息,包括进程状态、程序计数器、内存分配、打开文件等。进程信息被放在一个叫做进程控制块的数据结构中,可以理解为进程属性的集合。
task_struct-PCB的一种
在Linux中描述进程的结构体叫做task_struct。
task_struct是Linux内核的一种数据结构,它会被装载到RAM(内存)里并且包含着进程的信息。
task_ struct内容分类
标示符: 描述本进程的唯一标示符,用来区别其他进程。
状态: 任务状态,退出代码,退出信号等。
优先级: 相对于其他进程的优先级。
程序计数器: 程序中即将被执行的下一条指令的地址。
内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针
上下文数据: 进程执行时处理器的寄存器中的数据。
I/O状态信息: 包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表。
记账信息: 可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。
其他信息组织进程 可以在内核源代码里找到它。所有运行在系统里的进程都以task_struct链表的形式存在内核里。
进程间通信:
进程间通信(Inter-Process Communication,IPC)是进程之间交换数据和信息的机制,包括共享内存、消息队列、信号量、管道等。
多线程与进程:
线程是在同一进程内并发执行的流程,共享相同的地址空间和资源,而进程是操作系统为了实现并发执行而提供的独立执行环境。
进程的信息可以通过 /proc 系统文件夹查看
ps指令
ps 是一个常用的 Unix/Linux 命令,用于显示当前系统中运行的进程信息。ps 命令的输出可以提供关于进程的各种详细信息,比如进程 ID、CPU 使用情况、内存占用情况等。这里是一些常用的 ps 命令选项及其含义:
ps 命令选项:
ps:显示当前终端下的活动进程。
ps -e:显示系统中所有进程的信息。
ps -ef:显示所有进程的详细信息,包括命令行参数。
ps aux:显示所有进程的详细信息,包括用户、CPU 使用情况等。
ps -u username:显示特定用户的进程信息。
ps -p PID:显示特定进程 ID 对应的进程信息。
ps -l:以长格式显示进程信息,包括更多的字段。
ps -F:显示完整格式的进程信息。
ps -H:显示进程的层次结构。
ps 输出中常见的列含义:
PID:进程 ID。
TTY:所属终端。
TIME:CPU 占用时间。
CMD:命令名称。
ps ajx
ps ajx 是一个常见的命令组合,用于显示系统中所有进程的详细信息,并以进程树的形式展示进程之间的层次关系。以下是关于 ps ajx 命令的解释:
ps:用于报告当前系统的进程状态。a:显示所有用户的进程,而不仅仅是当前用户的进程。j:以 BSD 风格的格式显示作业信息,包括进程 ID(PID)、进程组 ID(PGID)、作业 ID(SID)、终端 ID(TTY)、进程状态(STAT)、占用 CPU 时间(TIME)等。x:显示没有控制终端的进程。
PID:进程 ID,唯一标识每个进程。
PPID:父进程的进程 ID。
PGID:进程组 ID。
SID:会话 ID。
TTY:终端设备。
STAT:进程状态,如 R(运行)、S(睡眠)、Z(僵尸)等。
TIME:进程累计 CPU 时间。
COMMAND:启动进程时使用的命令。
ps aux
ps aux:
ps aux:是一个常见的 Unix/Linux 命令,用于显示当前系统中所有用户的进程信息。
a:显示所有用户的进程,而不仅仅是当前用户的进程。
u:以用户为中心的输出格式,提供了更详细的进程信息,如用户、CPU 占用、内存占用等。
x:显示没有控制终端的进程,通常用于显示守护进程等后台进程。
在Linux系统中,STAT 字段用于表示进程的状态,常见的状态包括:
R(运行):进程正在执行或在运行队列中等待执行。
S(睡眠):进程处于睡眠状态,通常是在等待某些事件的发生,比如等待I/O完成。
Z(僵尸):僵尸进程,即进程已经终止,但其父进程尚未调用wait()或waitpid()来获取其终止状态,因此进程描述符仍然存在,但进程已经不再执行任何代码。
T(停止):进程被暂停,通常是由于接收到一个停止信号,比如通过键盘输入Ctrl+Z发送SIGTSTP信号。
D(不可中断的睡眠):进程处于不可中断的休眠状态,通常是因为在等待硬件设备的响应,无法被中断。
W(进入内存交换):进程被迁移到交换空间,即内存中的页面被交换到磁盘上。
X(死亡):进程已经死亡,但仍保留在进程表中。
<(高优先级):进程具有较高的优先级。
N(低优先级):进程具有较低的优先级。
在Linux系统中,Ctrl+Z 和 Ctrl+C 是两个常用的键盘快捷键,用于控制正在运行的进程。它们的作用如下:
Ctrl+Z:
当您按下 Ctrl+Z 键时,会发送 SIGTSTP 信号给当前正在前台运行的进程,将其暂停(挂起)并放到后台运行,同时会显示进程挂起的编号。该进程的状态将变为 Stopped(已停止)。
暂停的进程可以通过 fg 命令恢复到前台运行,或通过 bg 命令在后台继续运行。
Ctrl+C:
当您按下 Ctrl+C 键时,会发送 SIGINT 信号给当前正在前台运行的进程,通知进程终止。这通常会导致进程被终止并返回到 shell 提示符。
Ctrl+C 通常用于中断正在运行的程序,例如如果一个程序陷入无限循环或者需要提前结束程序的执行。
在计算机操作系统中,"后台运行"(background running)是指在不占用当前终端(或 shell)的情况下运行进程或命令。当一个进程在后台运行时,它不会阻塞当前终端的输入和输出,允许用户在终端上继续执行其他操作或命令。
在 Linux 或 Unix 系统中,可以通过以下方式将进程在后台运行:
使用 & 符号:
在执行一个命令时,可以在命令的结尾添加 & 符号,这样命令将在后台运行,例如:
command &
使用 Ctrl+Z 和 bg 命令:
暂停一个前台进程并将其放到后台可以使用 Ctrl+Z 键。
使用 bg 命令可以将最近暂停的进程放到后台继续运行,例如:
bg
使用 nohup 命令:
使用 nohup 命令可以让一个命令在后台运行,并且不会受到终端关闭的影响,例如:
nohup command &
通过系统调用获取进程标示符
进程id(PID)
父进程id(PPID)
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
printf("pid: %d\n", getpid());
printf("ppid: %d\n", getppid());
return 0;
}
通过系统调用创建进程fork()
使用fork()系统调用来创建一个新的进程。fork()系统调用会创建当前进程的一个副本,这个副本会继承父进程的数据。父子进程代码共享,数据各自开辟空间,私有一份(采用写时拷贝)
调用fork()会返回两次。在父进程中,fork()返回子进程的进程ID,而在子进程中,fork()返回0。通过检查返回值,我们可以在父进程和子进程中执行不同的代码。
请注意,fork()系统调用是Unix和类Unix系统中可用的。
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
int ret = fork();
if (ret < 0) {
perror("fork");
return 1;
}
else if (ret == 0) { //child
printf("I am child : %d!, ret: %d\n", getpid(), ret);
}
else { //father
printf("I am father : %d!, ret: %d\n", getpid(), ret);
}
sleep(1);
return 0;
}进程+号代表前台运行
在 Linux 中,进程状态中的符号和字母表示不同的进程状态。以下是常见的一些进程状态符号和字母及其含义:
R:运行状态(Running)- 进程当前正在执行或等待 CPU 时间片。
S:睡眠状态(Sleeping)- 进程当前处于休眠状态,正在等待某些事件的发生。
D:不可中断的休眠状态(Uninterruptible Sleep)- 进程正在执行一个不可中断的系统调用。
T:停止状态(Stopped)- 进程已经停止,等待信号继续或终止。
Z:僵尸状态(Zombie)- 进程已经终止,但其父进程尚未对其进行善后处理。
X:死掉的进程(Dead)- 进程已经终止,但仍然存在于系统中。
<:高优先级进程(High-priority)- 进程具有较高的优先级。
N:低优先级进程(Low-priority)- 进程具有较低的优先级。
L:内存上锁(Memory locked)- 进程锁定了一部分内存以防止被交换出去。
+:前台进程组(Foreground)- 进程是前台进程组的一部分。
t: 暂停状态(tracing stop) - 表示该进程正在被追踪。(如:调试程序)
僵死进程会以终止状态保持在进程表中,并且会一直在等待父进程读取退出状态代码。 所以,只要子进程退出,父进程还在运行,但父进程没有读取子进程状态,子进程进入Z状态。
僵尸进程危害
进程的退出状态必须被维持下去,因为他要告诉关心它的进程(父进程),你交给我的任务,我办的怎
么样了。可父进程如果一直不读取,那子进程就一直处于Z状态?是的!
维护退出状态本身就是要用数据维护,也属于进程基本信息,所以保存在task_struct(PCB)中,换句话
说,Z状态一直不退出,PCB一直都要维护?是的!
那一个父进程创建了很多子进程,就是不回收,是不是就会造成内存资源的浪费?是的!因为数据结构
对象本身就要占用内存,想想C中定义一个结构体变量(对象),是要在内存的某个位置进行开辟空
间!
内存泄漏?是的!僵尸进程本身实际上已经处于终止状态,因此无法像正常的运行进程一样被直接杀死。
通常情况下,解决僵尸进程的方法是由父进程调用 wait() 或 waitpid() 等系统调用,以回收子进程的资源。父进程在调用这些函数之后,操作系统会将僵尸进程从进程表中移除,释放相关资源。
如果父进程无法或者未能处理僵尸进程,可以间接地通过杀死父进程来清除僵尸进程。
孤儿进程
孤儿进程(Orphan Process)是指其父进程先于它结束或者没有正常地等待它的终止状态,而使得孤儿进程成为由 init 进程(PID为1)接管的子进程。init 进程会负责处理这些孤儿进程,以确保它们能够正确地被回收,避免它们成为僵尸进程。
当一个进程创建了子进程,但在子进程执行期间父进程先结束,或者父进程没有等待子进程的终止状态,这样的子进程就会变成孤儿进程。孤儿进程的特点包括:
父进程先于孤儿进程结束,孤儿进程的父进程变为 init 进程。
孤儿进程的父进程 ID 被设置为 1。
孤儿进程在其终止后,其资源会被 init 进程回收。
处理孤儿进程的责任通常落在 init 进程身上。当孤儿进程终止后,init 进程会接管并负责回收该进程的资源,确保系统资源得到正确释放,避免产生僵尸进程。
因此,孤儿进程并不会像僵尸进程那样产生问题,因为它们会被系统正确处理。这种机制确保了即使父进程意外终止或者没有等待子进程,系统仍能正确处理子进程的终止状态,保证系统的稳定性。
如果前台进程创建的子进程,变成孤儿进程了,会自动变成后台进程。
进程优先级
基本概念
进程优先级是操作系统中用来决定进程调度顺序的重要概念之一。在多任务操作系统中,有许多进程同时运行,操作系统需要根据一些规则来确定哪个进程应该在某个时间点被执行。进程优先级就是用来帮助操作系统做出这些决定的一个重要因素。
以下是关于进程优先级的一些基本概念:
-
优先级范围:
- 进程优先级通常是一个整数值,通常范围在一个特定的范围内,比如 Linux 系统中,进程优先级范围一般是 -20 到 19(也可能会有些许变化)。
-
高优先级和低优先级:
- 数值越小的进程优先级越高,数值越大的进程优先级越低。在某些系统中,负数优先级代表高优先级,正数优先级代表低优先级。
-
进程调度:
- 操作系统根据进程的优先级来安排进程执行的顺序。通常情况下,优先级高的进程会被更频繁地执行,而低优先级的进程则可能会被推迟执行,以确保系统资源的合理分配。
-
动态优先级:
- 有些操作系统会根据进程的行为动态地改变进程的优先级。例如,当一个进程长时间运行并占用大量 CPU 资源时,操作系统可能会降低其优先级,以便给其他进程更多的执行机会。
-
nice 值:
- 在类 Unix 系统中,进程的优先级可以通过
nice命令或系统调用来调整。nice命令允许用户在启动进程时设置其优先级,这个值称为 nice 值。
- 在类 Unix 系统中,进程的优先级可以通过
-
实时优先级:
- 一些系统支持实时进程调度,这些进程有固定的优先级,不受动态调整的影响。实时进程通常用于时间敏感的应用,如音频处理或控制系统。
进程优先级在操作系统中起着重要作用,它有助于确保系统资源的有效分配和进程的合理调度,从而提高系统的性能和响应能力。
cpu资源分配的先后顺序,就是指进程的优先权(priority)。
优先权高的进程有优先执行权利。配置进程优先权对多任务环境的linux很有用,可以改善系统性能。
还可以把进程运行到指定的CPU上,这样一来,把不重要的进程安排到某个CPU,可以大大改善系统整体性能。
查看系统进程
在linux或者unix系统中,用ps –al命令则会类似输出以下几个内容:
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
0 R 1000 1234 5678 0 80 0 - 9893 - pts/0 00:00:00 psUID : 代表执行者的身份
PID : 代表这个进程的代号
PPID :代表这个进程是由哪个进程发展衍生而来的,亦即父进程的代号
PRI :代表这个进程可被执行的优先级,其值越小越早被执行
NI :代表这个进程的nice值PRI and NI
PRI也还是比较好理解的,即进程的优先级,或者通俗点说就是程序被CPU执行的先后顺序,此值越小
进程的优先级别越高
那NI呢?就是我们所要说的nice值了,其表示进程可被执行的优先级的修正数值
PRI值越小越快被执行,那么加入nice值后,将会使得PRI变为:PRI(new)=PRI(old)+nice
这样,当nice值为负值的时候,那么该程序将会优先级值将变小,即其优先级会变高,则其越快被执行
所以,调整进程优先级,在Linux下,就是调整进程nice值
nice其取值范围是-20至19,一共40个级别。PRI vs NI
需要强调一点的是,进程的nice值不是进程的优先级,他们不是一个概念,但是进程nice值会影响到进 程的优先级变化。 可以理解nice值是进程优先级的修正修正数据 。
用top命令更改已存在进程的nice:
top 进入top后按“r”–>输入进程PID–>输入nice值
竞争性: 系统进程数目众多,而CPU资源只有少量,甚至1个,所以进程之间是具有竞争属性的。为了高
效完成任务,更合理竞争相关资源,便具有了优先级
独立性: 多进程运行,需要独享各种资源,多进程运行期间互不干扰
并行: 多个进程在多个CPU下分别,同时进行运行,这称之为并行
并发: 多个进程在一个CPU下采用进程切换的方式,在一段时间之内,让多个进程都得以推进,称之为
并发进程切换
进程切换是操作系统中一个关键的机制,它允许多个进程共享CPU时间,实现并发执行。
进程切换详解:
-
当前进程的状态保存:
当操作系统决定切换到另一个进程时,当前正在执行的进程的上下文状态需要被保存下来,以便稍后能够恢复到该进程并继续执行。这包括保存以下内容:- 堆栈:保存了函数调用的参数、局部变量等。
- 内存页表:保存了进程的内存映射信息。
- 进程控制块(PCB):包含了进程的所有信息,如进程ID、状态、程序计数器、寄存器值、内存分配等。
- 寄存器状态:包括通用寄存器、程序计数器(PC)、堆栈指针(SP)等。
-
选择下一个要执行的进程:
操作系统通过调度算法从就绪队列中选择下一个要执行的进程。选择可能基于进程的优先级、轮转调度等。 -
新进程的状态加载:
操作系统执行以下操作来加载新进程的状态以准备执行:- 切换堆栈:切换到新进程的堆栈,以确保正确的函数调用和返回。
- 更新内存管理单元(MMU):确保新进程的内存空间正确映射到物理内存。
- 加载新进程的上下文:将新进程的上下文从进程控制块(PCB)或内存中加载到CPU寄存器中。
-
执行新进程:
CPU开始执行新进程的代码,从其上次中断的位置继续执行。 -
上下文切换开销:
上下文切换是一个开销较大的操作,因为它涉及到保存和恢复大量的状态信息。频繁的进程切换可能会导致系统性能下降。 -
进程切换的重要性:
进程切换是操作系统实现并发的关键机制,允许多个进程共享CPU,从而提高系统的效率和响应能力。
环境变量
环境变量(environment variables)一般是指在操作系统中用来指定操作系统运行环境的一些参数环境变量是操作系统中存储有关操作系统或用户环境的动态信息的值。它们在许多操作系统中都被广泛使用,包括Unix/Linux、Windows等。环境变量通常用于配置系统行为、影响程序的运行方式以及提供有关系统状态的信息。
以下是一些关于环境变量的重要概念:
系统环境变量:
系统环境变量是由操作系统设置的全局变量,对所有用户和进程都是可见的。这些变量通常包括操作系统的默认配置信息以及全局路径等。
用户环境变量:
用户环境变量是特定用户设置的变量,仅对该用户及其启动的进程可见。用户可以根据自己的需求设置这些变量,用于自定义工作环境。
常见环境变量:
PATH:包含可执行文件的搜索路径,系统在执行命令时会在这些路径中查找可执行文件。
HOME:指向当前用户的主目录。
SHELL : 当前Shell,它的值通常是/bin/bash。
USER:当前登录用户的用户名。
LANG:指定系统默认的语言环境。
PWD:当前工作目录的路径。
环境变量的设置:
在Unix/Linux系统中,可以使用export命令来设置环境变量,如
export PATH=/usr/local/bin:$PATH。在环境变量后添加
export PATH=$PATH:/usr/local/bin。在环境变量前添加
在Windows系统中,可以使用set命令来设置环境变量,如 set PATH=C:\Program Files\Example;%PATH%。
查看环境变量
使用 echo 命令:
可以使用 echo $VARIABLE_NAME 来查看特定环境变量的值。例如,echo $PATH 可以查看 PATH 环境变量的值。
使用 printenv 命令:
可以使用 printenv 命令来列出所有环境变量及其值。
在Unix或Linux系统中,通常使用美元符号 $ 来引用环境变量。在Windows系统中,% 百分号通常用于引用环境变量。因此,在Unix或Linux系统中,正确的语法是使用 $ 符号来引用环境变量,例如 $PATH 表示引用环境变量 PATH 的值。
以下是几个常用的与环境变量相关的命令:
printenv:用于打印当前系统中所有的环境变量及其对应的值。
printenv
env:类似于printenv,用于显示当前环境中所有的环境变量及其值。
env
export:用于设置一个新的环境变量,或者修改已存在环境变量的值。
export MY_VAR="some_value"
unset:用于移除一个环境变量。
unset MY_VAR
echo:用于打印特定环境变量的值。
echo $PATH
source:用于在当前shell环境中执行指定的文件,通常用于重新加载配置文件以使环境变量的更改生效。
source ~/.bashrc
set:显示当前shell中所有变量,包括环境变量和shell变量。
set
export -p:显示当前所有的导出的环境变量。
export -p分时操作系统(Time-sharing Operating System)和实时操作系统(Real-time Operating System)是两种不同类型的操作系统,它们在设计目标和应用领域上有着显著的区别。
分时操作系统(Time-sharing Operating System)
特点:
允许多个用户通过时间片轮转的方式共享计算机系统资源。
系统会为每个用户分配一小段时间来执行任务,通过快速的切换使得多个用户感觉同时在使用计算机。
目的是提高系统的利用率,减少用户等待时间,增加用户交互性。
应用:
适用于大型计算机系统,如服务器和主机系统。
用于支持多用户并发访问和任务调度。
例子:
UNIX、Linux、Windows等桌面操作系统都采用了分时操作系统的思想。
实时操作系统(Real-time Operating System)
特点:
保证任务在特定时间内得到处理,避免任务因延迟而失效。
分为硬实时(Hard Real-time)和软实时(Soft Real-time)两种类型。
硬实时要求任务在严格的时间限制内完成,缺一秒都不允许。
软实时对时间限制更为宽松,任务可以在时间限制内完成的概率很高。
应用:
用于需要快速响应和精确控制的系统,如航空航天、汽车控制系统、医疗设备、工业自动化等。
在需要对任务的执行时间做严格控制的场景下被广泛应用。
例子:
VxWorks、QNX等是一些常见的实时操作系统。
总的来说,分时操作系统注重多用户共享系统资源和提高系统利用率,而实时操作系统则注重任务的及时响应和执行,适用于对时间要求严格的应用场景。
指令集架构:
复杂指令集计算机(CISC):指令集复杂,一条指令可以执行多个操作。
精简指令集计算机(RISC):指令简单,每条指令只执行一个基本操作。
通过代码如何获取环境变量
命令行第三个参数
#include <stdio.h>
int main(int argc, char *argv[], char *env[])
{
int i = 0;
for(; env[i]; i++){
printf("%s\n", env[i]);
}
return 0;
}通过第三方变量environ获取
#include <stdio.h>
int main()
{
extern char **environ;
int i = 0;
for(; environ[i]; i++){
printf("%s\n", environ[i]);
}
return 0;
}libc中定义的全局变量environ指向环境变量表,environ没有包含在任何头文件中,所以在使用时 要用extern声明。
通过系统调用获取或设置环境变量
#include <stdio.h>
#include <stdlib.h>
int main()
{
printf("%s\n", getenv("PATH"));
return 0;
}常用getenv和putenv函数来访问特定的环境变量。
getenv 和 putenv 是 C 语言中用于处理环境变量的函数。
下面是它们的基本用法:
getenv
getenv 函数用于获取指定环境变量的值。
原型:
char *getenv(const char *name);参数:
name: 环境变量的名称(以字符串形式)。
返回值:
如果环境变量存在,返回指向环境变量值的指针;如果不存在,返回 NULL。
示例:
#include <stdio.h>
#include <stdlib.h>
int main() {
const char *value = getenv("HOME");
if (value != NULL) {
printf("HOME: %s\n", value);
} else {
printf("HOME not found.\n");
}
return 0;
}putenv
putenv 函数用于设置或修改环境变量。将指定环境变量导入到系统environ环境变量表中。
原型:
int putenv(char *string);参数:
string: 一个字符串,格式为 "NAME=VALUE"。
返回值:
成功时返回 0,失败时返回 -1。
示例:
#include <stdio.h>
#include <stdlib.h>
int main() {
if (putenv("MYVAR=HelloWorld") == 0) {
printf("MYVAR set to: %s\n", getenv("MYVAR"));
} else {
perror("putenv failed");
}
return 0;
}注意事项
使用 putenv 修改环境变量后,这些修改会影响当前进程及其子进程。
环境变量的名称通常是大写字母,遵循一定的命名约定。
putenv 的参数是一个指向字符串的指针,因此在修改该字符串之后,环境变量的值可能会被改变。
环境变量通常是具有全局属性的
环境变量通常具有全局属性,可以被子进程继承下去。
在 C 语言中,int main(int argc, char *argv[], char *env[]) 它允许程序接收命令行参数和环境变量。
由系统维护一张命令行参数所对应的指针数组表,和一张环境变量所对应的指针数组表,以NULL结尾。
程序地址空间
程序地址空间是指操作系统为每个进程分配的内存范围。这一内存空间通常包括以下几个部分:
代码段(Text Segment):
存储可执行程序的代码。
通常是只读的,以防止程序无意中修改自身代码。
数据段(Data Segment):
包含已初始化的全局变量和静态变量。
在程序开始时,这些变量被分配并初始化。
BSS段(Block Started by Symbol):
存储未初始化的全局变量和静态变量。
在程序启动时,这些变量初始化为零。
堆(Heap):
用于动态分配内存。
通常从低地址向高地址增长。
使用诸如 malloc 和 free 的函数进行内存管理。
栈(Stack):
用于存储函数的局部变量和调用信息。
从高地址向低地址增长。
自动管理内存分配和释放。
内核空间:
操作系统内核保留的内存区域,用户进程无法直接访问。
提供系统调用接口,允许用户程序请求操作系统服务。
地址空间布局示例
+--------------------+ 高地址
| 栈 (Stack) |
|--------------------|
| 动态链接库区 |
|--------------------|
| 堆 (Heap) |
|--------------------|
| BSS段 |
|--------------------|
| 数据段 |
|--------------------|
| 代码段 |
+--------------------+ 低地址
注意事项
虚拟内存:现代操作系统使用虚拟内存技术,使每个进程拥有独立的地址空间。物理内存和虚拟地址之间通过页表映射。
地址空间隔离:确保进程间的内存访问隔离,提高系统安全性和稳定性。
#include <stdio.h>
#include <unistd.h>
int main()
{
int g_lab = 100;
int cnt = 0;
pid_t id = fork();
if(id<0)
{
printf("erro\n");
return 1;
}
else if(id==0)
{
while(1)
{
if(cnt==10)
{
g_lab = 300;
printf("子进程修改了全局变量------------------------\n");
}
printf("我是子进程,pid: %d,ppid: %d, g_lab: %d, &g_lab: %p | \n",getpid(),getppid(),g_lab,&g_lab);
sleep(1);
cnt++;
}
}
else
{
while(1)
{
printf("我是父进程,pid:%d,ppid:%d, g_lab: %d, &g_lab: %p | \n",getpid(),getppid(),g_lab,&g_lab);
sleep(2);
}
}
return 0;
}我们发现,父子进程,输出地址是一致的,但是子进程修改变量后父子内容不一样!
变量内容不一样,所以父子进程输出的变量绝对不是同一个变量。
但地址值是一样的,说明,该地址绝对不是物理地址!
在Linux地址下,这种地址叫做虚拟地址。
我们在用C/C++语言所看到的地址,全部都是虚拟地址!物理地址,用户一概看不到,由OS统一管理 OS必须负责将 虚拟地址 转化成 物理地址。
进程地址空间
之前说的程序的地址空间是不准确的,准确的应该说成 进程地址空间。
进程的地址空间可以形象地看作是操作系统为每个进程“画的大饼”。这个“大饼”代表了进程在内存中可以使用的所有地址和资源。以下是对这一概念的进一步解释:
进程地址空间的组成
分段:
进程的地址空间通常被分为几个段,如代码段、数据段、堆和栈。每个段都有不同的用途和特性。
逻辑与物理分离:
操作系统为每个进程提供一个逻辑地址空间,进程在其中运行时只感知逻辑地址,而不需要关心物理内存的实际布局。操作系统通过内存管理单元(MMU)将逻辑地址映射到物理地址。
隔离性:
每个进程都有独立的地址空间,这样可以避免进程间的干扰和数据泄露,提高系统的安全性和稳定性。
地址空间的本质:是内核的一种数据结构 mm_struct (先描述再组织)
同一个变量,地址相同,其实是虚拟地址相同,内容不同其实是被映射到了不同的物理地址!
页表
页表是操作系统中用于管理虚拟内存的关键数据结构。它记录了虚拟地址和物理地址之间的映射关系,允许系统有效地使用内存并实现虚拟内存的概念。以下是关于页表的详细解释。
1. 什么是页表?
定义: 页表是一个数据结构,存储了虚拟地址到物理地址的映射。每个进程都有自己的页表,用于管理该进程的虚拟内存。
功能: 它使得程序可以使用比实际物理内存更大的内存空间,通过映射机制实现虚拟内存。
2. 页表的工作原理
虚拟地址空间: 程序使用虚拟地址进行内存访问。每个虚拟地址由两部分组成:
页号: 指定虚拟页面的编号。
页内偏移: 指定在页面内的具体位置。
物理地址空间: 实际物理内存地址。
映射过程:
当程序访问虚拟地址时,CPU 将该地址分解为页号和页内偏移。
CPU 查询页表,找到对应的物理页号。
将物理页号与页内偏移组合,得到实际的物理地址。
3. 页表的结构
基本页表: 一个简单的页表通常是一个数组,其中每个条目对应一个虚拟页,包含该页对应的物理页框号(frame number)。
多级页表: 为了节省内存,现代操作系统常使用多级页表。它将页表分成多个层级,减少了页表的内存占用:
第一级页表: 存储指向第二级页表的指针。
第二级页表: 存储具体的物理页框号。
4. 页表的类型
传统页表: 每个进程都有一个完整的页表,简单但消耗内存。
反向页表: 主要用于跟踪物理内存的使用情况,映射物理页到虚拟页,适用于某些特定的系统。
层次页表: 使用多级结构来减少内存使用,适合大型地址空间的系统。
5. 页表条目
每个页表条目通常包含以下信息:
物理页框号: 映射的物理页框。
有效位: 指示该条目是否有效。
访问权限: 读/写/执行权限。
修改位: 指示该页是否被修改过。
引用位: 指示该页是否被访问过,用于页面置换算法。
6. 页面置换
当物理内存不足时,操作系统需要决定哪些页可以被替换。常见的页面置换算法包括:
最少使用(LRU): 替换最久未被使用的页面。
先进先出(FIFO): 替换最早加载的页面。
最不常用(LFU): 替换使用次数最少的页面。
总结
页表是现代操作系统中实现虚拟内存管理的核心数据结构。它通过映射虚拟地址和物理地址,允许程序使用的内存大于实际物理内存,并提供内存保护和管理的功能。这使得操作系统能够有效地利用内存资源,提高系统性能和稳定性。
内核进程调度队列
内核进程调度队列是操作系统中用于管理和调度进程的关键数据结构。它们确保系统能够有效地分配CPU时间给各个进程。以下是关于内核进程调度队列的主要概念和机制:
主要调度队列
就绪队列:
存放所有当前可以运行,但尚未分配CPU时间的进程。
当进程从阻塞状态变为就绪状态时,它会被加入到就绪队列。
阻塞队列:
存放当前等待某个事件(如I/O操作完成)的进程。
当事件发生时,这些进程会被移到就绪队列中,等待CPU调度。
终止队列:
存放已经完成执行的进程,待操作系统回收其资源。
调度算法
内核使用不同的调度算法来管理这些队列,常见的调度算法包括:
先来先服务(FCFS):
按照进程到达的顺序进行调度,简单但可能导致“饥饿”现象。
短作业优先(SJF):
优先调度预计执行时间短的进程,能够减少平均等待时间。
时间片轮转(Round Robin):
每个进程分配一个固定时间片,时间片结束后,进程被移到队尾,适合时间共享系统。
优先级调度:
根据进程的优先级进行调度,高优先级的进程优先执行。
多级反馈队列:
结合多种调度算法,允许进程根据其行为在不同优先级队列之间移动。
调度过程
进程状态变更:
进程可以在不同队列之间移动,例如从阻塞队列到就绪队列。
调度决策:
内核根据当前调度算法,从就绪队列中选择一个进程来执行。
上下文切换:
当调度器决定切换进程时,内核会保存当前进程的状态,并加载新进程的状态,完成上下文切换。
进程创建
进程创建是操作系统中一个重要的概念,涉及从现有进程生成新进程的过程。这一过程通常包括以下几个步骤和关键概念:
1. 进程创建的方式
系统调用:
进程通常通过系统调用创建,如 fork()(在类Unix系统中)或 CreateProcess()(在Windows中)。
复制现有进程:
使用 fork() 时,操作系统会创建一个新进程(子进程),该进程是调用进程(父进程)的副本。新进程会获得一个新的进程标识符(PID)。
2. 进程创建的步骤
分配进程控制块(PCB):
操作系统为新进程分配一个 PCB,用于存储进程的状态信息,如进程ID、程序计数器、寄存器状态、内存管理信息等。
分配资源:
分配必要的资源,如内存、文件描述符等。子进程通常继承父进程的资源,但也可以选择性地复制或共享。
设置进程状态:
将新进程的状态设置为“就绪”,并将其添加到就绪队列中,以便调度器可以对其进行调度。
加载程序:
如果新进程需要执行不同的程序,操作系统会加载相应的程序到内存中,通常使用 exec() 系列函数。
3. 进程的创建方式
单纯复制:
使用 fork() 创建一个与父进程几乎完全相同的子进程。
替换进程映像:
使用 exec() 系列函数,在子进程中加载新程序,替换其当前映像。
4. 进程间关系
父子进程关系:
子进程从父进程创建,父进程可以通过 wait() 系列函数等待子进程结束并获取其退出状态。
进程终止:
子进程完成后会发送信号给父进程,父进程可以选择回收子进程的资源,防止“僵尸进程”出现。
5. 注意事项
资源限制:
操作系统通常会对进程创建数量和资源使用进行限制,以避免资源耗尽。
同步与通信:
进程创建后,父子进程之间可能需要通过进程间通信(IPC)机制进行数据交换和同步。
在进程创建时,操作系统需要在资源共享和复制之间做出选择,以优化性能和资源使用。以下是关于进程创建时如何处理资源共享和复制的详细说明:
1. 资源复制
使用 fork() 创建子进程:
当调用 fork() 时,操作系统会创建一个新的进程(子进程),并复制父进程的所有资源,包括:
进程控制块(PCB):子进程会有自己的PCB,但大部分信息(如程序计数器、寄存器)会从父进程复制。
内存空间:在大多数现代操作系统中,子进程最初会复制父进程的内存空间,但使用了一种称为“写时复制”(Copy-On-Write, COW)的技术。
写时复制(Copy-On-Write, COW)
机制:
在子进程创建时,父进程的内存页不会立即复制,而是两个进程共享同一块物理内存。只有当其中一个进程尝试修改共享的内存时,操作系统才会进行实际的复制。
优点:
这种方式显著降低了内存使用和创建新进程的开销,因为只有在需要修改时才进行复制。
2. 资源共享
共享内存:
进程可以选择使用共享内存区域,这样多个进程可以同时访问相同的数据,而无需进行复制。例如,可以使用 shmget() 和 shmat() 等系统调用创建和附加共享内存。
文件描述符:
在使用 fork() 时,子进程会继承父进程的打开文件描述符。这意味着父子进程可以共享文件的状态(如偏移量),但它们的文件描述符表是独立的。
3. 选择共享或复制
根据需求选择:
在某些情况下,进程可能需要独立的资源(如独立的内存空间),而在其他情况下,进程可能希望共享某些资源以提高效率。操作系统提供了灵活的方法来实现这一点。
使用 exec():
如果子进程需要执行不同的程序,可以在 fork() 后立即调用 exec() 系列函数。exec() 会替换进程的内存映像,但共享的文件描述符会保持不变。fork函数
fork() 是 Unix 和类 Unix 系统中的一个系统调用,用于创建新进程。调用 fork() 时,当前进程(称为父进程)会创建一个新的进程(称为子进程)。
以下是关于 fork() 的详细信息:
1. 基本概念
返回值:
fork() 的返回值在父进程中是新创建的子进程的进程ID(PID),而在子进程中返回 0。如果调用失败,则返回 -1,并且没有创建新进程。
进程状态:
子进程是父进程的副本,包含几乎所有的进程属性(如内存、文件描述符等),但它们的进程ID是不同的。
2. 写时复制(Copy-On-Write)
内存管理:
在许多操作系统中(如 Linux),fork() 使用写时复制(COW)机制。初始时,父进程和子进程共享相同的物理内存页面,只有在其中一个进程修改页面时,操作系统才会复制该页面。
3. 使用场景
多进程编程:
fork() 常用于实现并发执行的程序。父进程可以在创建子进程后继续执行,而子进程可以独立执行任务。
服务器模型:
在服务器应用中,使用 fork() 可以为每个客户端请求创建一个新的子进程,从而实现并发处理。
函数原型
#include <unistd.h>
pid_t fork(void);语法说明
头文件:fork() 函数定义在 <unistd.h> 头文件中。
返回类型:返回值类型为 pid_t,表示进程ID(PID)。
无参数:fork() 函数不接受任何参数。
返回值
成功:
在父进程中,返回值为新创建的子进程的PID。
在子进程中,返回值为 0。
失败:
返回 -1,表示创建进程失败,通常可以通过 errno 获取错误信息。
进程调用fork,当控制转移到内核中的fork代码后,内核做:
分配新的内存块和内核数据结构给子进程
将父进程部分数据结构内容拷贝至子进程
添加子进程到系统进程列表当中 hash表 哈希表(Hash Table)是一种用于快速数据查找的数据结构,利用哈希函数将键映射到数组索引
fork返回,开始调度器调度fork之前父进程独立执行,fork之后,父子两个执行流分别执行。注意,fork之后,谁先执行完全由调度器决定。
#include <stdio.h>
#include <unistd.h>
int main() {
pid_t pid = fork(); // 创建子进程
if (pid < 0) {
// fork失败
perror("fork failed");
return 1;
} else if (pid == 0) {
// 子进程执行
printf("Child process (PID: %d) return pid:%d\n", getpid(),pid);
} else {
// 父进程执行
printf("Parent process (PID: %d) return pid:%d\n", getpid(),pid);
}
return 0;
}fork函数返回值 :子进程返回0, 父进程返回的是子进程的pid。
写时拷贝 : 通常,父子代码共享,父子进程在不写入时,数据也是共享的,当任意一方试图写入,便以写时拷贝的方式各自一份副本。
fork常规用法
一个父进程希望复制自己,使父子进程同时执行不同的代码段。例如,父进程等待客户端请求,生成子 进程来处理请求。
一个进程要执行一个不同的程序。例如子进程从fork返回后,调用exec函数。
fork调用失败的原因
1. 资源不足
系统资源不足,无法创建新的进程。例如,达到进程数的限制或系统内存不足。
系统没有足够的内存来创建新进程。
2. 进程限制
达到用户或系统允许的最大进程数(通常是 ulimit 设置的限制)。
3. 权限问题
调用进程没有足够的权限来创建进程,通常发生在尝试创建非同用户进程时。
4. 内核限制
系统的进程表已满,无法分配新的进程 ID。
5. 系统调用错误
其他系统调用错误可能会导致 fork 失败,例如文件系统错误等。
进程终止
进程终止是操作系统中一个重要的概念,涉及到进程的结束和资源的回收。
以下是关于进程终止的几个关键点:
1. 进程终止的原因
正常终止:
通过调用 exit 函数(或返回 main 函数)正常结束。
异常终止:
由于未处理的信号(如 SIGKILL、SIGSEGV 等)导致进程异常退出。
用户请求:
用户通过命令(如 kill 命令)发送信号终止进程。
父进程终止:
如果父进程结束,子进程可能会被转移到 init 进程(PID 1)中。
2. 进程终止的状态
退出状态:
进程终止时会返回一个退出状态码,父进程可以通过 wait 或 waitpid 获取该状态。
僵尸进程:
子进程结束后,其进程控制块仍然存在,以便父进程读取状态。此时子进程处于僵尸状态,直到父进程调用 wait。
3. 进程终止的函数
exit(int status):
用于正常终止进程并返回退出状态。
_exit(int status):
系统调用,立即终止进程,不做缓冲区清理,通常用于子进程中。
wait(int *status):
父进程调用此函数等待子进程结束,并获取其退出状态。
waitpid(pid_t pid, int *status, int options):
更灵活的等待特定子进程结束。
可以通过 echo $? 查看进程退出码
_exit函数
_exit 函数是一个系统调用,用于立即终止当前进程。它与标准库函数 exit 有一些重要的区别。以下是对 _exit 函数的详细说明:
1. 函数原型
#include <unistd.h>
void _exit(int status);参数:status 定义了进程的终止状态,父进程通过wait来获取该值
说明:虽然status是int,但是仅有低8位可以被父进程所用。所以_exit(-1)时,在终端执行$?发现返回值是255。
2. 用法
_exit 函数用于在进程中直接终止并返回一个状态码。它通常在子进程中使用,以避免对父进程的影响。
3. 特点
立即终止进程:
_exit 立即终止进程,不会执行任何清理操作(如缓冲区刷新)。
不调用 atexit 注册的函数:
与 exit 不同,_exit 不会调用在 atexit 中注册的退出处理函数。
不关闭文件描述符:
_exit 不会关闭由标准 I/O 库打开的文件描述符,可能会导致数据丢失或文件损坏。
4. 何时使用 _exit
在子进程中:
当使用 fork 创建子进程时,通常在子进程中使用 _exit 来确保它不会影响父进程的状态。
避免缓冲区问题:
在处理信号或异常情况时,如果需要立即退出,使用 _exit 可以避免潜在的数据一致性问题。
exit函数
exit 函数是 C 标准库中用于终止程序的函数。它能够完成必要的清理工作,并将退出状态返回给操作系统。以下是对 exit 函数的详细说明:
1. 函数原型
#include <stdlib.h>
void exit(int status);2. 用法
exit 函数用于正常终止程序,并允许开发者指定一个状态码。状态码通常用于表示程序的退出状态。
3. 特点
清理资源:
exit 会执行以下操作:
关闭所有打开的文件描述符。
刷新和关闭标准 I/O 缓冲区,将未写入的数据写入文件。
调用所有通过 atexit 注册的退出处理函数。
返回状态:
status 参数用于指示程序的退出状态,通常:
0 表示成功。
非零值表示错误或异常情况。
4. 何时使用 exit
正常结束:
当程序完成任务并希望正常退出时,可以调用 exit。
错误处理:
在出现错误的情况下,可以使用非零状态码调用 exit 来指示错误。
return退出
在 C 语言中,使用 return 语句可以从一个函数返回,并且在 main 函数中,它也可以用来退出程序。以下是对 return 退出机制的详细说明:
1. 在 main 函数中的用法
当 return 在 main 函数中使用时,它会导致程序的终止,并返回一个退出状态给操作系统。其基本用法如下:
#include <stdio.h>
int main() {
printf("Program is running...\n");
// 正常退出
return 0; // 返回 0 表示成功
}
2. 退出状态
return 0:- 通常表示程序成功完成。
- 非零返回值:
- 表示程序发生了错误或异常。例如,
return 1;表示一般错误。
- 表示程序发生了错误或异常。例如,
3. 在其他函数中的用法
在其他函数中,return 语句用于返回到调用该函数的位置,并返回一个值(如果该函数有返回值类型)。
#include <stdio.h>
int add(int a, int b) {
return a + b; // 返回两个数的和
}
int main() {
int result = add(3, 5);
printf("Result: %d\n", result);
return 0; // 正常退出
}
4. 与 exit 和 _exit 的区别
-
return:- 结束当前函数,返回控制权给调用者。在
main函数中,return也会结束程序。
- 结束当前函数,返回控制权给调用者。在
-
exit:- 立即终止程序,调用
atexit注册的清理函数,关闭打开的文件描述符,刷新缓冲区等。
- 立即终止程序,调用
-
_exit:- 直接终止进程,不执行任何清理操作,通常在子进程中使用。
5. 示例代码
以下是一个示例,展示如何在 main 函数中使用 return 语句:
#include <stdio.h>
int main() {
printf("Hello, World!\n");
if (/* some error condition */) {
printf("An error occurred!\n");
return 1; // 返回非零表示错误
}
return 0; // 正常退出
}return是一种更常见的退出进程方法。执行return n等同于执行exit(n),因为调用main函数会将main的返回值当做exit的参数。
进程等待
进程等待(Process Waiting)是指一个进程在执行时,可能会因为某些条件未满足而暂停执行,直到这些条件满足后再继续运行。这种机制在多进程或多线程环境中非常重要,通常用于协调不同进程之间的执行。
等待的常见场景
资源等待:
当一个进程请求某些资源(如文件、网络连接、CPU 等)时,如果这些资源当前不可用,进程会被挂起,直到资源可用。
子进程等待:
父进程在调用系统调用(如 fork)创建子进程后,通常会使用 wait 或 waitpid 等函数等待子进程结束,以获取其退出状态。
条件变量:
在多线程编程中,条件变量用于让线程等待特定条件的变化,从而避免忙等待。
在 Unix/Linux 中的子进程等待
使用 wait 和 waitpid 函数来等待子进程的结束。
示例代码
#include <iostream>
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
int main() {
pid_t pid = fork(); // 创建子进程
if (pid < 0) {
std::cerr << "Fork failed!" << std::endl;
return 1;
} else if (pid == 0) {
// 子进程执行的代码
std::cout << "Child process is running." << std::endl;
sleep(2); // 模拟长时间运行的任务
return 42; // 返回状态
} else {
// 父进程等待子进程结束
int status;
waitpid(pid, &status, 0); // 等待子进程
if (WIFEXITED(status)) {
std::cout << "Child exited with status: " << WEXITSTATUS(status) << std::endl;
}
}
return 0;
}
关键点
fork():创建新进程,返回值在父进程中是子进程的 PID,在子进程中返回 0。waitpid():父进程调用此函数等待指定的子进程结束。WIFEXITED(status)和WEXITSTATUS(status):- 这两个宏用于检查子进程是否正常退出并获取其退出状态。
多线程中的等待
在多线程编程中,可以使用条件变量和互斥锁来实现线程的等待和通知机制。
示例代码
#include <iostream>
#include <thread>
#include <mutex>
#include <condition_variable>
std::mutex mtx;
std::condition_variable cv;
bool ready = false;
void worker() {
std::unique_lock<std::mutex> lock(mtx);
cv.wait(lock, [] { return ready; }); // 等待条件变量
std::cout << "Worker thread is running." << std::endl;
}
int main() {
std::thread t(worker);
// 进行一些准备工作
std::this_thread::sleep_for(std::chrono::seconds(1));
{
std::lock_guard<std::mutex> lock(mtx);
ready = true; // 设置条件
}
cv.notify_one(); // 通知等待的线程
t.join(); // 等待线程结束
return 0;
}进程等待必要性
僵尸进程的产生
-
子进程退出:
当子进程执行完毕后,它的状态会变为“僵尸”,这意味着它仍然在系统中占有一个进程标识符(PID),但已经不再执行任何代码。 -
父进程未处理:
如果父进程没有调用wait()或waitpid()等函数来回收子进程的状态信息和资源,子进程就会保持僵尸状态。
僵尸进程的影响
-
内存泄漏:
- 虽然僵尸进程不占用 CPU 资源,但它们仍然占用系统表项和一些内存资源,可能导致系统资源耗尽。
-
无法被杀死:
- 僵尸进程无法被
kill -9等命令终止,因为它们已经完成了执行,只是没有被父进程清理。
- 僵尸进程无法被
父进程的责任
-
回收资源:
父进程需要通过进程等待机制(如wait())来回收子进程的资源,以避免僵尸进程的出现。 -
获取退出状态:
父进程可以通过等待机制获取子进程的退出状态,判断子进程是否正常退出以及执行结果,这对于父进程后续的逻辑处理非常重要。
解决方案
-
使用
wait():- 父进程可以在子进程结束后调用
wait()或waitpid(),以清理僵尸进程。
- 父进程可以在子进程结束后调用
-
设置信号处理:
- 通过设置信号处理函数(如
SIGCHLD),父进程可以在子进程终止时自动处理其状态,避免僵尸进程的产生。
- 通过设置信号处理函数(如
进程等待的方法
1. wait()
- 用途:父进程调用该函数以等待其子进程的结束。
- 返回值:返回子进程的PID,并可以通过参数获取子进程的退出状态。
示例:
#include<sys/types.h>
#include<sys/wait.h>
pid_t wait(int*status);
返回值:
成功返回被等待进程pid,失败返回-1。
参数:
输出型参数,获取子进程退出状态,不关心则可以设置成为NULL2. waitpid()
- 用途:更灵活的等待子进程,可以指定等待的特定子进程。
- 参数:可以控制是否阻塞等待、是否返回已结束的子进程等。
示例:
pid_ t waitpid(pid_t pid, int *status, int options);
返回值:
当正常返回的时候waitpid返回收集到的子进程的进程ID;
如果设置了选项WNOHANG,而调用中waitpid发现没有已退出的子进程可收集,则返回0;
如果调用中出错,则返回-1,这时errno会被设置成相应的值以指示错误所在;
参数:
pid:
Pid=-1,等待任一个子进程。与wait等效。
Pid>0.等待其进程ID与pid相等的子进程。
status:
WIFEXITED(status): 若为正常终止子进程返回的状态,则为真。(查看进程是否是正常退出)
WEXITSTATUS(status): 若WIFEXITED非零,提取子进程退出码。(查看进程的退出码)
options:
WNOHANG: 若pid指定的子进程没有结束,则waitpid()函数返回0,不予以等待。若正常结束,则返回该子进
程的ID。如果子进程已经退出,调用wait/waitpid时,wait/waitpid会立即返回,并且释放资源,获得子进程退
出信息。
如果在任意时刻调用wait/waitpid,子进程存在且正常运行,则进程可能阻塞。
如果不存在该子进程,则立即出错返回。获取子进程status
wait和waitpid,都有一个status参数,该参数是一个输出型参数,由操作系统填充。
如果传递NULL,表示不关心子进程的退出状态信息。
否则,操作系统会根据该参数,将子进程的退出信息反馈给父进程。
status不能简单的当作整形来看待,可以当作位图来看待,只研究status低16比特位:
int status = 0;
pid_t ret = waitpid(id,&status,0);
if(id > 0)
{
printf("wait sucess:%d,sig num:%d,child:%d,ret:%d\n",ret,(status&0x7F),((status>>8)&0xFF),status);
}
-
状态信息提取:
(status & 0x7F):这部分提取了低7位,通常表示子进程的信号编号或退出状态。如果子进程是因信号而终止,这个值就是信号编号。((status >> 8) & 0xFF):这部分提取了高8位的信息。根据具体实现,这可能存储了额外的状态信息或调试信息。status:整个状态值,包含所有信息。
输出示例
假设你有一个子进程,它的状态值为 0x00000042,那么输出将会是:
ret:返回的子进程 ID。sig num:status & 0x7F结果。如果子进程正常退出,其值为0。child:((status >> 8) & 0xFF)结果,这可能是子进程的退出状态(如42)。status:完整的状态值。
非阻塞的轮询等待
非阻塞的轮询等待通常通过使用 waitpid() 函数与 WNOHANG 选项来实现。这种方法允许父进程检查子进程的状态而不阻塞。如果没有子进程结束,调用将立即返回。
以下是一个使用 waitpid() 进行非阻塞轮询等待的示例:
示例代码
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <signal.h>
#include <time.h>
#include <iostream>
int main() {
pid_t pid = fork();
if (pid < 0) {
// fork 失败
perror("Fork failed");
return 1;
}
if (pid == 0) {
// 子进程
std::cout << "Child process (PID: " << getpid() << ") is sleeping for 5 seconds...\n";
sleep(5); // 模拟长时间运行的任务
std::cout << "Child process finished.\n";
exit(0); // 结束子进程
} else {
// 父进程
int status;
while (true) {
pid_t result = waitpid(pid, &status, WNOHANG); // 非阻塞等待
if (result == 0) {
// 子进程仍在运行
std::cout << "Child is still running...\n";
sleep(1); // 暂停一段时间后再检查
} else if (result == pid) {
// 子进程已结束
if (WIFEXITED(status)) {
std::cout << "Child exited with status: " << WEXITSTATUS(status) << std::endl;
} else {
std::cout << "Child terminated abnormally.\n";
}
break; // 退出循环
} else {
// 错误
perror("waitpid failed");
break;
}
}
}
return 0;
}
代码解释
- 创建子进程:使用
fork()创建一个新进程。 - 子进程:
- 模拟一个长时间运行的任务(例如,通过
sleep(5))。 - 结束时调用
exit(0)。
- 模拟一个长时间运行的任务(例如,通过
- 父进程:
- 进入一个无限循环,通过
waitpid()检查子进程的状态。 - 使用
WNOHANG选项使waitpid()非阻塞。 - 如果返回值为
0,表示子进程仍在运行,父进程输出相应信息并继续。 - 如果返回值为子进程的 PID,表示子进程已结束,父进程处理退出状态并退出循环。
- 如果发生错误,输出错误信息并退出循环。
- 进入一个无限循环,通过
进程程序替换
在 Unix/Linux 系统中,进程替换(Process Replacement)是指使用 exec 系列函数替换当前进程的映像。这个过程将当前进程的地址空间替换为新程序的地址空间,而不创建新进程。
将指定的程序加载到内存中,让指定进程执行该程序就是进程程序替换。
exec 系列函数
exec 系列函数通常包括以下几种:
execl():使用参数列表。execv():使用参数数组。execle():使用参数列表,带环境变量。execve():使用参数数组,带环境变量。execvp():使用路径查找的参数数组(可执行文件)。
使用示例
以下是一个简单的示例,展示如何使用 fork() 创建子进程并用 execl() 进行进程替换。
#include <unistd.h>
#include <iostream>
#include <sys/types.h>
#include <sys/wait.h>
int main() {
pid_t pid = fork(); // 创建子进程
if (pid < 0) {
// fork 失败
perror("Fork failed");
return 1;
}
if (pid == 0) {
// 子进程
std::cout << "Child process: replacing with 'ls' command.\n";
execl("/bin/ls", "ls", "-l", NULL); // 进程替换
// 如果 exec 成功,以下代码不会执行
perror("execl failed");
exit(1);
} else {
// 父进程
int status;
waitpid(pid, &status, 0); // 等待子进程结束
if (WIFEXITED(status)) {
std::cout << "Child exited with status: " << WEXITSTATUS(status) << std::endl;
}
}
return 0;
}
代码解释
fork():创建一个新进程。如果创建成功,返回子进程的 PID;在子进程中返回 0。- 子进程:
- 调用
execl()替换当前进程的映像。 - 如果
execl()成功,子进程的代码将被替换,之后的代码不会执行。 - 如果替换失败,输出错误信息并退出。
- 调用
- 父进程:
- 使用
waitpid()等待子进程结束,并处理其退出状态。
- 使用
其他 exec 函数的用法
execv()示例:
#include <unistd.h>
#include <iostream>
int main() {
pid_t pid = fork();
if (pid == 0) {
char *argv[] = {"ls", "-l", NULL}; // 参数数组
execv("/bin/ls", argv);
perror("execv failed");
exit(1);
}
wait(NULL); // 等待子进程结束
return 0;
}
execvp()示例(使用环境变量查找可执行文件):
#include <unistd.h>
#include <iostream>
int main() {
pid_t pid = fork();
if (pid == 0) {
char *argv[] = {"ls", "-l", NULL}; // 参数数组
execvp("ls", argv); // 不需要完整路径
perror("execvp failed");
exit(1);
}
wait(NULL);
return 0;
} 在 Unix/Linux 系统中,使用 fork() 创建子进程后,子进程会复制父进程的内存空间,包括代码、数据和堆栈。尽管父进程和子进程在创建时拥有相同的程序状态,但它们可以根据需要执行不同的代码分支。
exec 函数的作用
当子进程调用 exec 函数系列时,它将当前进程的用户空间代码和数据完全替换为新程序的代码和数据。这个过程是关键的,以下是一些关于 exec 函数的重要点:
- 替换当前进程:
exec函数不会创建新的进程,而是用新程序替换当前进程的映像。这意味着子进程将不再执行原来的程序代码,而是执行新程序的代码。 - 进程 ID 不变:调用
exec之后,进程的 ID(PID)仍然保持不变。子进程的 PID 和父进程的 PID 仍然是相同的。 - 执行新程序:
exec函数的调用会从新程序的入口点开始执行,所有之前的状态(如堆栈、全局变量等)都被新程序的状态所替代。 - 退出状态:如果
exec成功,之后的代码不会执行。如果exec失败,控制会返回到调用进程,并且可以检查错误。
替换函数
下面是对 exec 系列函数的详细介绍,包括它们的函数原型、参数和使用示例。
1. execl()
- 原型:
int execl(const char *path, const char *arg, ...); - 描述:使用可变参数列表来指定程序的命令行参数。
- 参数:
path:要执行的程序的完整路径。arg:程序的第一个参数,通常是程序的名称,后续参数以可变参数形式传入,最后以NULL结束。
- 示例:
execl("/bin/ls", "ls", "-l", NULL);
2. execlp()
- 原型:
int execlp(const char *file, const char *arg, ...); - 描述:与
execl()类似,但会在PATH环境变量中查找可执行文件。 - 参数:
file:程序的名称。arg:程序的第一个参数,后续参数以可变参数形式传入,最后以NULL结束。
- 示例:
execlp("ls", "ls", "-l", NULL);
3. execle()
- 原型:
int execle(const char *path, const char *arg, ..., char *const envp[]); - 描述:与
execl()类似,但允许传递环境变量。 - 参数:
path:要执行的程序的完整路径。arg:程序的第一个参数,后续参数以可变参数形式传入,最后以NULL结束。envp:环境变量数组,以NULL结束。
- 示例:
char *envp[] = {"VAR=value", NULL}; execle("/bin/ls", "ls", "-l", NULL, envp);
4. execv()
- 原型:
int execv(const char *path, char *const argv[]); - 描述:使用参数数组来指定程序的命令行参数。
- 参数:
path:要执行的程序的完整路径。argv:参数数组,最后一个元素必须是NULL。
- 示例:
char *argv[] = {"ls", "-l", NULL}; execv("/bin/ls", argv);
5. execvp()
- 原型:
int execvp(const char *file, char *const argv[]); - 描述:与
execv()类似,但会在PATH环境变量中查找可执行文件。 - 参数:
file:程序的名称。argv:参数数组,最后一个元素必须是NULL。
- 示例:
char *argv[] = {"ls", "-l", NULL}; execvp("ls", argv);
6. execve()
- 原型:
int execve(const char *path, char *const argv[], char *const envp[]); - 描述:最底层的
exec函数,允许传递参数和环境变量。 - 参数:
path:要执行的程序的完整路径。argv:参数数组,最后一个元素必须是NULL。envp:环境变量数组,以NULL结束。
- 示例:
char *argv[] = {"ls", "-l", NULL}; char *envp[] = {"VAR=value", NULL}; execve("/bin/ls", argv, envp);
execvpe()
- 原型:
int execvpe(const char *file, char *const argv[], char *const envp[]); - 描述:与
execvp()类似,但允许传递自定义环境变量。 - 参数:
file:要执行的程序的名称。argv:参数数组,最后一个元素必须是NULL。envp:环境变量数组,以NULL结束。
- 示例:
char *argv[] = {"ls", "-l", NULL}; char *envp[] = {"VAR=value", NULL}; execvpe("ls", argv, envp);
完整的 exec 函数系列包括:
execl()execlp()execle()execv()execvp()execve()execvpe()
这些函数如果调用成功则加载新的程序从启动代码开始执行,不再返回。 如果调用出错则返回-1 ,所以exec函数只有出错的返回值而没有成功的返回值。
命名理解
在 exec 系列函数中,函数名称的命名具有一定的含义,有助于理解它们的功能和用法。以下是对每个函数名称的解释:
1. execl()
- 命名含义:
exec:表示执行(execute)。l:表示使用“列表”(list)作为参数,即可变参数列表。
2. execlp()
- 命名含义:
exec:表示执行(execute)。l:使用“列表”(list)作为参数。p:表示“在路径中查找”(path)。这个函数会在系统的PATH环境变量中查找可执行文件。
3. execle()
- 命名含义:
exec:表示执行(execute)。l:使用“列表”(list)作为参数。e:表示可以传递环境变量(environment variables)。
4. execv()
- 命名含义:
exec:表示执行(execute)。v:表示使用“向量”(vector)作为参数,即参数数组。
5. execvp()
- 命名含义:
exec:表示执行(execute)。v:使用“向量”(vector)作为参数。p:表示“在路径中查找”(path)。会在系统的PATH环境变量中查找可执行文件。
6. execve()最底层的系统调用 exec 函数,允许传递参数和环境变量。
- 命名含义:
exec:表示执行(execute)。v:使用“向量”(vector)作为参数。e:表示可以传递环境变量(environment variables)。
7. execvpe()
- 命名含义:
exec:表示执行(execute)。v:使用“向量”(vector)作为参数。p:表示“在路径中查找”(path)。e:表示可以传递环境变量(environment variables)。
只有execve是真正的系统调用,其它五个函数最终都调用 execve,所以execve在man手册第2节,其它函数在 man手册第3节。
chdir
chdir 是一个用于改变当前工作目录的系统调用,通常在 Unix/Linux 系统中使用。
它的函数原型如下:
原型
#include <unistd.h>
int chdir(const char *path);
参数
path:要更改到的目录的路径,可以是绝对路径或相对路径。
返回值
- 成功时返回
0,失败时返回-1,并设置errno以指示错误类型。
系统文件I/O
在 Linux 和 Unix 系统中,文件 I/O(输入/输出)是与文件进行交互的基本方式。系统文件 I/O 提供了读取、写入、打开、关闭和管理文件的功能。下面是关于系统文件 I/O 的详细介绍,包括常用的函数和示例。
1. 文件操作的基本概念
- 打开文件:使用
open函数打开文件,获取文件描述符。 - 读写文件:使用
read和write函数进行数据的读取和写入。 - 关闭文件:使用
close函数关闭文件描述符。
2. 常用函数
1. open
#include <fcntl.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
int open(const char *pathname, int flags, mode_t mode);参数
pathname:要打开的文件的路径。flags:打开文件的模式,可以是以下选项的组合:O_RDONLY:只读模式。O_WRONLY:只写模式。O_RDWR:读写模式。O_CREAT:如果文件不存在,则创建该文件。O_TRUNC:如果文件已存在并以写入模式打开,则将文件截断为长度为 0,清空数据。O_APPEND:在写入时将文件指针移动到文件末尾,追加内容。O_RDONLY: 只读打开 O_WRONLY: 只写打开 O_RDWR : 读,写打开 这三个常量,必须指定一个且只能指定一个 O_CREAT : 若文件不存在,则创建它。需要使用mode选项,来指明新文件的访问权限 O_APPEND: 追加写
mode:当使用O_CREAT创建新文件时,指定文件的权限(如0666)。此参数在不使用O_CREAT时可以忽略。
open 函数具体使用哪个,和具体应用场景相关,如目标文件不存在,需要open创建,则第三个参数表示创建文件的默认权限,否则,使用两个参数的open。
返回值
- 成功时,返回文件描述符(一个非负整数)。
- 失败时,返回 -1,并设置
errno以指示错误类型。
常见错误
EACCES:权限被拒绝。ENOENT:指定的文件不存在。EEXIST:使用O_CREAT时,文件已存在且O_EXCL也被设置。ENOSPC:设备上没有足够的空间。
2. read
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);参数
fd:要读取的文件描述符,通常由open函数返回。buf:指向存储读取数据的缓冲区的指针。count:要读取的字节数。
返回值
- 返回实际读取的字节数。如果返回值小于
count,可能是因为到达文件末尾(EOF)或发生错误。 - 如果返回值为 -1,表示发生错误,
errno将被设置以指示错误类型。
常见错误
EBADF:无效的文件描述符。EFAULT:buf指向的内存地址无效。EINTR:在读取过程中被信号中断。EIO:输入/输出错误。
3. write
#include <unistd.h>
ssize_t write(int fd, const void *buf, size_t count);参数
fd:要写入的文件描述符,通常由open函数返回。buf:指向包含要写入数据的缓冲区的指针。count:要写入的字节数。
返回值
- 返回实际写入的字节数,可能小于
count,特别是在非阻塞模式下。 - 如果返回值为 -1,表示发生错误,
errno将被设置以指示错误类型。
常见错误
EBADF:无效的文件描述符。EFAULT:buf指向的内存地址无效。EINTR:在写入过程中被信号中断。ENOSPC:设备上没有足够的空间来写入数据。EIO:输入/输出错误。
4. close
#include <unistd.h>
int close(int fd);参数
fd:要关闭的文件描述符,通常由open函数返回。
返回值
- 成功时返回
0。 - 失败时返回
-1,并设置errno以指示错误类型。
常见错误
EBADF:无效的文件描述符,可能是因为它已经被关闭。EIO:发生输入/输出错误。
3. 示例代码
以下是一个简单的示例,展示如何使用系统文件 I/O 函数:
#include <fcntl.h>
#include <unistd.h>
#include <stdio.h>
#include <sys/types.h> // 可选,通常用于定义 mode_t
#include <sys/stat.h> // 可选,通常用于文件权限常量
int main() {
const char *filename = "example.txt";
const char *text = "Hello, World!";
char buffer[50];
// 打开文件以进行写入
int fd = open(filename, O_WRONLY | O_CREAT | O_TRUNC, 0666);
if (fd == -1) {
perror("Failed to open file");
return 1;
}
// 写入数据
ssize_t bytes_written = write(fd, text, 13);
if (bytes_written == -1) {
perror("Failed to write to file");
close(fd);
return 1;
}
// 关闭文件
close(fd);
// 打开文件以进行读取
fd = open(filename, O_RDONLY);
if (fd == -1) {
perror("Failed to open file for reading");
return 1;
}
// 读取数据
ssize_t bytes_read = read(fd, buffer, sizeof(buffer) - 1);
if (bytes_read == -1) {
perror("Failed to read from file");
close(fd);
return 1;
}
buffer[bytes_read] = '\0'; // 确保以 null 结尾
printf("Read from file: %s\n", buffer);
// 关闭文件
close(fd);
return 0;
}fopen、fclose、fread 和 fwrite 是 C 标准库中的库函数(libc),而 open、close、read、write 和 lseek 是操作系统提供的系统调用接口。
文件描述符fd
文件描述符(file descriptor,简称 fd)是一个非负整数,用于标识进程打开的文件或其他输入/输出资源(如管道、套接字等)。它在 Unix/Linux 操作系统中非常重要,以下是关于文件描述符的详细说明。
文件描述符的基本概念
-
定义:
文件描述符是一个整数,代表一个打开的文件或其他 I/O 资源。操作系统使用它来跟踪进程所打开的文件。 -
标准文件描述符:
在 Unix/Linux 系统中,进程启动时会自动打开三个标准文件描述符:- 2:标准错误(stderr)
- 1:标准输出(stdout)
- 0:标准输入(stdin)
-
用户自定义文件描述符:
当进程使用open系统调用打开一个文件时,操作系统会为该文件分配一个新的文件描述符。这个描述符通常是当前最大的文件描述符加一。
文件描述符的特性
- 非负整数:文件描述符是一个非负整数,通常从 0 开始。
- 唯一性:在同一进程中,每个文件描述符都是唯一的,指向特定的文件或 I/O 资源。
- 资源管理:操作系统会跟踪每个文件描述符的状态,确保在使用后正确释放资源。
Linux进程默认情况下会有3个缺省打开的文件描述符,分别是标准输入0, 标准输出1, 标准错误2. 0,1,2对应的物理设备一般是:键盘,显示器,显示器。
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <string.h>
#include <unistd.h> // 需要包含这个头文件以使用 read 和 write
int main() {
char buf[1024]; // 创建一个字符数组,用于存储输入的数据
ssize_t s = read(0, buf, sizeof(buf)); // 从标准输入(文件描述符 0)读取数据
if (s > 0) { // 如果读取成功
buf[s] = 0; // 将读取的字节数作为字符串的结束标志
write(1, buf, strlen(buf)); // 将数据写入标准输出(文件描述符 1)
write(2, buf, strlen(buf)); // 将数据写入标准错误(文件描述符 2)
}
return 0; // 返回 0 表示程序成功结束
}上面代码用于从标准输入读取数据,并将读取的数据同时写入标准输出和标准错误。
文件描述符就是从0开始的小整数。当打开文件时,操作系统在内存中要创建相应的数据结构来描述目标文件。于是就有了file结构体。表示一个已经打开的文件对象。而进程执要行open系统调用,必须让进程和文件关联起来。每个进程都有一个指针*files, 指向一张表files_struct,该表最重要的部分就是包涵一个指针数组,每个元素都是一个指向打开文件的指针!所以,本质上,文件描述符就是该数组的下标。所以,只要拿着文件描述符,就可以找到对应的文件。
文件描述符的分配规则
1. 从0开始分配
- 文件描述符通常从0开始分配,依次递增。标准输入、标准输出和标准错误分别对应于文件描述符0、1和2。
2. 空闲描述符的选择
- 当进程请求打开一个新文件时,操作系统会寻找当前进程的
files_struct中第一个未被占用的文件描述符。也就是说,系统会选择当前最小的未使用的文件描述符进行分配。
3. 关闭文件描述符
- 当文件描述符被关闭后(通过
close系统调用),该描述符就会被标记为可用,未来的打开操作可以重新使用这个描述符。 - 当你调用
close(fd)关闭文件描述符时:
内核会减少该文件表项的引用计数。
如果引用计数降到零,内核会释放该文件的资源(包括关闭文件和释放内存)。
4. 进程间共享
- 文件描述符是进程特有的,但可以通过
fork或exec等系统调用在子进程中共享。当父进程打开文件时,子进程会继承父进程的文件描述符表。
5. 限制
- 系统会限制每个进程可以打开的文件描述符的数量,通常由系统参数(如
ulimit)控制。超出这个限制,后续的open调用将失败。
6. 线程安全
- 在多线程环境中,每个线程也会有自己的文件描述符表,确保对文件描述符的操作是线程安全的。
7. 特殊文件描述符
- 一些特殊的文件描述符(如管道、套接字)也遵循相同的分配规则,允许进行网络通信或进程间通信。
文件描述符的分配规则:在files_struct数组当中,找到当前没有被使用的 最小的一个下标,作为新的文件描述符。
重定向是操作系统中将输入和输出流重新定向到不同的文件或设备的过程。它通常用于命令行环境中,允许用户控制程序的输入和输出。以下是重定向的基本概念和用法:
重定向
1. 输出重定向
-
定义:将标准输出(stdout)重定向到一个文件。
-
用法:使用
>符号。command > output.txt这会将
command的输出写入output.txt文件。如果文件已存在,则会被覆盖。 -
追加输出:使用
>>符号。command >> output.txt这会将
command的输出追加到output.txt文件末尾。
2. 输入重定向
-
定义:将标准输入(stdin)从文件读取,而不是从键盘。
-
用法:使用
<符号。command < input.txt这会使
command从input.txt中读取输入。
3. 错误重定向
-
定义:将标准错误(stderr)重定向到文件。
-
用法:使用
2>符号。command 2> error.txt这会将
command的错误信息写入error.txt文件。 -
追加错误:使用
2>>符号。command 2>> error.txt这会将错误信息追加到
error.txt文件末尾。
4. 同时重定向输出和错误
-
定义:将标准输出和标准错误同时重定向到同一个文件。
-
用法:
command > output.txt 2>&1这将把正常输出和错误输出都写入
output.txt文件。
5. 管道
-
定义:通过管道将一个命令的输出直接作为另一个命令的输入。
-
用法:使用
|符号。command1 | command2这会将
command1的输出传递给command2作为输入。
重定向的本质是改变输入/输出流的默认目标,以便将数据从一个地方引导到另一个地方。
dup2 系统调用
dup2 是一个系统调用,用于复制文件描述符并将其重定向到另一个文件描述符。它常用于实现输入输出重定向。
功能
dup2可以将一个打开的文件描述符(源描述符)复制到另一个文件描述符(目标描述符)。如果目标描述符已经打开,则会被关闭。
函数原型
#include <unistd.h>
int dup2(int oldfd, int newfd);
参数
- oldfd:要复制的文件描述符。
- newfd:目标文件描述符,
oldfd将被复制到此描述符。如果newfd已经打开,它将被关闭。
返回值
- 成功时返回
newfd,失败时返回-1,并设置errno。
使用场景
-
重定向标准输出或输入
- 可以将标准输出(文件描述符 1)重定向到文件,以便后续的输出会写入该文件。
-
实现管道
- 在多个进程间传递数据时,可以使用
dup2将文件描述符重定向到管道的读写端。
- 在多个进程间传递数据时,可以使用
FILE
缓冲机制
-
缓冲类型:
- 全缓冲:当输出的数据存储在一个缓冲区中,只有当缓冲区满或者手动刷新时(如调用
fflush),数据才会被写入目标文件。 - 行缓冲:对于标准输出(通常是终端),输出是行缓冲的,即每次输出一行时(遇到换行符),会刷新缓冲区。
- 全缓冲:当输出的数据存储在一个缓冲区中,只有当缓冲区满或者手动刷新时(如调用
-
库函数 vs 系统调用:
printf和fwrite是 C 标准库的函数,它们使用用户级的缓冲区来优化性能。write是一个系统调用,不使用用户级缓冲区,直接将数据写入内核。
fork 的影响
- 当调用
fork时,父进程的用户级缓冲区会被复制到子进程。这意味着,在父进程和子进程中,两个进程都有同样的缓冲区状态。 - 如果父进程在 fork 之后调用
printf或fwrite,并且这些函数的数据尚未被刷新到文件中,父进程的刷新会导致子进程也输出相同的数据,从而导致输出重复。
为什么 write 不会重复
write直接与内核交互,不涉及用户级的缓冲区。因此,它不会受到fork的影响,每次调用都会立即将数据写入目标。- 由于没有缓冲机制,
write的操作是原子的,不会出现上述的重复输出问题。
总结
- C 标准库的缓冲:
printf和fwrite使用了用户级缓冲区,能够提高性能,但在多进程环境中可能导致重复输出。 - 系统调用的直接性:
write直接与内核交互,避免了缓冲带来的潜在问题,确保数据的原子性和一致性。 - 进程间的影响:在使用
fork后,父子进程共享用户级缓冲区的内容,这会导致在父进程刷新的时候,子进程也能看到相同的数据。
#include <stdio.h>
#include <unistd.h>
#include <string.h>
int main()
{
const char* msg0 = "hello printf\n";
const char* msg1 = "hello fwrite\n";
const char* msg2 = "hello write\n";
printf("%s", msg0);
fwrite(msg1, strlen(msg0), 1, stdout);
write(1, msg2, strlen(msg2));
fork();
return 0;
}
对进程实现输出重定向
./a.out > txt
root@iZ2vch4tdjuyi8htrm9i7hZ:~# cat txt
hello write
hello printf
hello fwrite
hello printf
hello fwrite
发现 printf 和 fwrite (库函数)都输出了2次,而 write 只输出了一次(系统调用)。
为什么呢?
输出重复的原因
- 当父进程调用
printf和fwrite时,这些内容被放入缓冲区。 - 在
fork之后,父进程的缓冲区内容被复制到子进程。 - 当父进程退出时,缓冲区的内容会被刷新到文件,子进程也会看到已复制的缓冲区内容,因此两个进程都输出了相同的数据。
- 父子进程共享缓冲区,这会导致缓冲区内容在进程退出时被重复输出。
缓冲区
缓冲区(Buffer)是计算机科学中一个重要的概念,通常用于临时存储数据,以便高效地进行数据传输或处理。缓冲区可以用在多种场景中,包括输入/输出(I/O)、网络通信、图像处理等。以下是一些关于缓冲区的基本概念和应用。
缓冲区的基本概念
-
定义:
缓冲区是一个内存区域,通常分配在 RAM 中,用于临时存储数据,以便后续处理。 -
目的:
提高数据处理的效率,减少 I/O 操作的频率,平衡生产者和消费者之间的速度差异。 -
类型:
- 输入缓冲区:用于存储从外部设备(如键盘、网络)读取的数据。
- 输出缓冲区:用于存储将要写入外部设备(如屏幕、文件)的数据。
缓冲区的应用
-
文件 I/O:
在文件读取和写入操作中,使用缓冲区可以减少对磁盘的直接访问次数,提高性能。例如,C++ 中的std::ifstream和std::ofstream默认使用缓冲区。 -
网络通信:
在网络编程中,网络套接字通常会使用缓冲区来存储发送和接收的数据,以应对网络延迟和数据包的顺序问题。 -
图形处理:
在图形渲染中,缓冲区用于存储像素数据,以便在屏幕上快速绘制和更新图像。 -
音频处理:
在音频流处理时,音频数据会被存储在缓冲区中,以保证连续播放,避免产生音频中断。
文件系统
文件系统是操作系统中用于管理和存储文件的结构和方法。它负责文件的创建、读取、写入、删除以及目录的管理等操作。以下是文件系统的主要组成部分和概念。
1. 文件系统的基本概念
-
文件:文件是数据的集合,可以是文本、图像、音频等。每个文件都有一个名称和相关属性(如大小、权限、创建时间等)。
-
目录(文件夹):用于组织文件的结构,目录可以包含文件和其他目录,形成层次结构。
-
路径:表示文件或目录在文件系统中的位置。路径可以是绝对路径(从根目录开始)或相对路径(相对于当前工作目录)。
2. 文件系统的类型
不同的文件系统适用于不同的操作系统和应用场景。常见的文件系统包括:
-
FAT(File Allocation Table):一种早期的文件系统,广泛用于小型存储设备,如 USB 驱动器。
-
NTFS(New Technology File System):Windows 操作系统使用的文件系统,支持文件权限、加密和压缩等特性。
-
ext3/ext4:Linux 系统常用的文件系统,ext4 是 ext3 的升级版本,具有更好的性能和更大的文件支持。
-
HFS+:苹果 macOS 使用的文件系统,适用于苹果设备。
-
APFS(Apple File System):苹果最新的文件系统,优化了闪存存储的性能和安全性。
3. 文件系统的组成部分
-
超级块(Superblock):包含文件系统的元数据,如大小、状态和类型。
-
索引节点(inode):每个文件或目录都有一个 inode,存储文件的元数据(如权限、大小、时间戳等),但不包含文件名。
-
数据块:实际存储文件内容的地方。
-
目录项:将文件名与 inode 关联的记录。
4. 文件操作
文件系统提供多种操作来管理文件:
-
创建文件:在文件系统中生成新的文件。
-
打开文件:将文件加载到内存中,以进行读取或写入操作。
-
读取文件:从文件中获取数据。
-
写入文件:将数据保存到文件中。
-
删除文件:从文件系统中移除文件。
-
重命名文件:改变文件的名称。
5. 文件权限
文件系统管理文件的访问权限,确保只有授权用户能够访问文件。常见的权限有:
- 读(r):允许读取文件内容。
- 写(w):允许修改文件内容。
- 执行(x):允许执行文件(对程序文件)。
6. 文件系统的挂载
在多存储设备的环境中,文件系统需要被挂载到操作系统的目录结构中。挂载点是特定的目录,文件系统的根目录将与这个目录关联。
7. 文件系统的性能
文件系统性能受多种因素影响,包括:
- 访问时间:读取和写入数据的速度。
- 碎片化:文件被分散存储可能导致访问延迟。
- 缓存机制:操作系统使用缓存来提高文件访问速度。
inode
inode(索引节点)是文件系统中用于存储文件元数据的一种数据结构。每个文件和目录都有一个唯一的 inode,用于管理文件的属性和位置。下面是对 inode 的详细解析。
1. inode 的基本概念
-
定义:inode 是文件系统中存储文件的元数据的结构,包含文件的所有信息,但不包含文件名和实际数据内容。
-
唯一性:每个文件和目录都有一个唯一的 inode 号,文件名与 inode 号通过目录项关联。
2. inode 的组成部分
一个 inode 通常包含以下信息:
-
文件类型:指示文件的类型(普通文件、目录、符号链接等)。
-
权限信息:包括文件的读、写和执行权限,通常以三组(用户、组、其他)来表示。
-
所有者和组:文件的拥有者和所属组的用户 ID。
-
文件大小:以字节为单位的文件大小。
-
时间戳:
- 创建时间(ctime):文件的inode最后修改时间。
- 最后访问时间(atime):文件最后一次被访问的时间。
- 最后修改时间(mtime):文件内容最后一次被修改的时间。
-
链接计数:指向该 inode 的硬链接数量。
-
数据块指针:指向文件数据在磁盘上的存储位置,通常是数据块的地址。
3. inode 的工作原理
-
创建文件时:
当一个新文件被创建时,文件系统会分配一个 inode,并为其分配一个唯一的 inode 号。文件名会被存储在目录项中,与该 inode 号关联。 -
访问文件时:
当访问文件时,系统通过目录项查找文件名对应的 inode 号,然后读取 inode 中的元数据,找到文件数据在磁盘上的位置。 -
修改文件:
当文件内容发生变化时,inode 可能会更新时间戳和文件大小。
4. 硬链接与 inode
- 硬链接:多个文件名可以指向同一个 inode 号,这意味着它们共享相同的文件数据。删除其中一个硬链接不会影响其他链接,只有当所有链接都被删除时,文件的实际数据才会被释放。
5. inode 的限制
-
数量限制:每个文件系统在创建时会定义可用的 inode 数量,达到上限后无法创建新文件,即使磁盘空间尚未用尽。
-
性能:频繁的 inode 操作可能会影响性能,尤其是在大量小文件的情况下。
6. 查看 inode 信息
在 Unix/Linux 系统中,可以使用以下命令查看 inode 信息:
-
查看 inode 号:
ls -i filename -
查找文件:
find . -inum inode_number
7. inode 的优缺点
优点:
- 高效的文件管理:inode 可以快速访问文件的元数据,而不需要扫描整个目录。
- 支持硬链接:允许多个名称指向同一文件内容。
缺点:
- inode 数量限制:文件系统的 inode 数量是固定的,可能导致无法创建新文件。
- 过多的小文件:在存储大量小文件时,可能会耗尽 inode,导致无法创建新文件。
总结
inode 是文件系统中管理文件的重要组成部分,存储了文件的元数据和指向数据块的指针。
磁盘与块设备
磁盘是典型的块设备,通常被划分为多个块(block)。每个块的大小在格式化时确定,常见的块大小为 1024、2048 或 4096 字节。这种分块结构带来了对存储的高效管理。
1. 块的定义
- 块(Block):磁盘上的基本存储单位。所有的读写操作都是在块级别进行的。
- 块大小:在格式化时确定,无法更改。例如,使用
mke2fs命令可以指定块大小。
2. stat 命令输出解析
使用 stat 命令可以查看文件的详细信息。以下是一个示例输出及其解析:
# stat test.c
File: "test.c"
Size: 654 Blocks: 8 IO Block: 4096 普通文件
Device: 802h/2050d Inode: 263715 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2017-09-13 14:56:57.059012947 +0800
Modify: 2017-09-13 14:56:40.067012944 +0800
Change: 2017-09-13 14:56:40.069012948 +0800
- Size: 文件的字节大小(654 字节)。
- Blocks: 占用的块数(8 块)。
- IO Block: 每个块的大小(4096 字节)。
- Inode: 文件的 inode 号码(263715)。
- Links: 硬链接数量(1)。
- Access: 文件权限和类型。
- Uid/Gid: 文件拥有者和用户组。
- Access/Modify/Change: 文件的访问、修改和状态更改时间。
3. 块组(Block Group)
在 ext2 文件系统中,整个磁盘分区被划分为多个块组(Block Group),每个块组都有相同的结构,包含以下组成部分:
-
超级块(Super Block):
- 存储文件系统的结构信息。
- 包含总块数、总 inode 数、未使用的块和 inode 数、块和 inode 的大小、最近一次挂载时间、最近一次写入时间和检查时间等。
- 如果超级块损坏,整个文件系统将无法正常工作。
-
块组描述符表(GDT, Group Descriptor Table):
- 描述块组的属性信息,包括每个块组的起始位置和状态。
-
块位图(Block Bitmap):
- 记录每个数据块的使用状态(已占用或未占用)。
-
inode 位图(inode Bitmap):
- 每个位表示一个 inode 是否可用。
-
inode 表:
- 存储文件属性,如文件大小、所有者、最近修改时间等。
-
数据区:
- 存储文件的实际内容。
ls -s
ls -s 是一个用于在 Unix/Linux 系统中列出文件和目录的命令,用于显示每个文件或目录所占用的块数(block size)。
软/硬链接
硬链接和软链接(符号链接)是 Unix/Linux 文件系统中两种不同类型的链接方式。它们各自有不同的特性和用途。
硬链接(Hard Link)
1. 定义
硬链接是指向文件系统中同一 inode 的多个目录项。创建硬链接时,新的目录项指向原始文件的 inode。
2. 特点
- 相同的 inode:硬链接和原始文件共享相同的 inode,因此它们的内容完全相同。
- 文件名独立:硬链接可以有不同的文件名和路径,但它们指向相同的数据。
- 无法跨文件系统:硬链接只能在同一文件系统内创建,不能跨越不同的文件系统。
- 不能链接目录:出于防止循环引用和维护文件系统完整性的原因,硬链接不能用于目录。
- 链接计数:内核维护一个链接计数,表示有多少个文件名指向同一个 inode。
3. 使用示例
# 创建一个硬链接
ln original_file.txt hard_link.txt
4. 删除文件
- 删除原始文件或任何硬链接时,只有当所有链接都被删除后(引用计数为0),文件内容才会被实际释放。
- 从目录中删除记录:在目录表中移除对应的文件名。
- 减少链接计数:硬链接的计数减少 1。如果链接计数变为 0,表示没有文件名指向该 inode,系统会释放相关的磁盘空间。
- 释放 inode:当硬链接数为 0 时,内核会标记 inode 为可用,并释放其占用的数据块。
- 数据保留:在有多个硬链接的情况下,文件内容会保留,直到所有的链接都被删除。
软链接(Symbolic Link, Symlink)
1. 定义
软链接是一个指向另一个文件路径的文件。它存储的是目标文件的路径,而不是文件的 inode。
2. 特点
- 不同的 inode:软链接有自己独立的 inode,指向目标文件的路径。
- 可以跨文件系统:软链接可以指向不同文件系统的文件。
- 可以链接目录:软链接可以指向目录,便于创建快捷方式。
- 断链问题:如果目标文件被删除或移动,软链接将失效,成为“悬挂链接”或“死链接”。
3. 使用示例
# 创建一个软链接
ln -s original_file.txt symbolic_link.txt
4. 删除文件
- 删除原始文件时,软链接仍然存在,但指向的路径将无效。
5. 硬链接与软链接的对比
| 特点 | 硬链接 | 软链接 |
|---|---|---|
| inode | 共享相同的 inode | 独立的 inode |
| 文件路径 | 文件的真实数据 | 指向目标文件的路径 |
| 跨文件系统 | 不支持 | 支持 |
| 链接目录 | 不支持 | 支持 |
| 断链问题 | 不会出现 | 可能出现(悬挂链接) |
6. 应用场景
-
硬链接:
- 用于共享文件内容,而不需要额外的数据占用。
- 在需要保护重要文件时,可以创建硬链接,以便在删除原始文件时仍然保留数据。
-
软链接:
- 用于创建快捷方式或别名,便于用户访问。
- 在系统中指向配置文件、库文件等,便于管理和维护。
在 Linux 系统中,可以使用 ls 命令和 stat 命令查看文件的 inode 信息。以下是两种常用的方法:
1. 使用 ls 命令
可以使用 -i 选项来查看文件的 inode 号。
ls -i filename
示例
root@iZ2vch4tdjuyi8htrm9i7hZ:~# ls -i txt
397065 txt
在这个示例中,397065 是 txt 的 inode 号。
2. 使用 stat 命令
stat 命令提供更详细的文件信息,包括 inode 号、文件大小、权限、时间戳等。
stat filename
示例
root@iZ2vch4tdjuyi8htrm9i7hZ:~# stat txt
File: txt
Size: 90 Blocks: 8 IO Block: 4096 regular file
Device: fc03h/64515d Inode: 397065 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2024-09-23 10:26:30.830601208 +0800
Modify: 2024-09-23 10:26:27.814487447 +0800
Change: 2024-09-23 10:26:27.814487447 +0800
Birth: 2024-09-23 10:22:36.569762921 +0800
在这个示例中,Inode: 397065 表示文件的 inode 号。
Access: 2024-09-23 10:26:30.830601208 +0800
Modify: 2024-09-24 16:30:52.419415271 +0800
Change: 2024-09-24 16:30:52.419415271 +0800
- Access: 最近一次访问文件的时间,格式为
YYYY-MM-DD HH:MM:SS.NNNNNNNNN ±ZZZZ。 - Modify: 最近一次修改文件内容的时间。
- Change: 最近一次更改文件属性(如权限、所有者、文件大小等)的时间。
Birth: 2024-09-23 10:22:36.569762921 +0800
- Birth: 文件的创建时间,并非所有文件系统都支持此信息。
动态库和静态库
1. 静态库
定义
静态库是将多个目标文件(.o 或 .obj 文件)打包成一个单一的库文件(通常是 .a 或 .lib 格式)。在编译时,这些库的代码会被复制到最终生成的可执行文件中。
特点
- 链接时刻:静态库在编译时链接到应用程序中。
- 文件扩展名:在 Unix/Linux 系统中通常是
.a,在 Windows 中通常是.lib。 - 无运行时依赖:可执行文件不依赖于静态库的存在,所有代码都包含在可执行文件中。
优点
- 性能:因为代码在编译时就链接在一起,运行时无需额外的查找和加载,启动速度较快。
- 简化部署:只需分发可执行文件,不需要担心库文件缺失。
- 版本控制:不同版本的库不会影响已编译的可执行文件。
缺点
- 文件大小:包含库的所有代码,使得最终生成的可执行文件较大。
- 更新困难:如果库的代码需要更新,必须重新编译所有依赖该库的可执行文件。
- 内存使用:多个程序使用同一静态库时,每个程序都加载一份库代码,造成内存浪费。
使用场景
- 用于对性能要求较高的应用程序。
- 当库的更新频率较低,且不希望频繁重新编译应用程序时。
2. 动态库
定义
动态库是在运行时加载的库,也称为共享库。它们的代码在运行时被加载到内存中,多个程序可以共享相同的库代码。
特点
- 链接时刻:动态库在运行时链接,通常通过动态链接器进行处理。
- 文件扩展名:在 Unix/Linux 系统中通常是
.so(shared object),在 Windows 中通常是.dll(dynamic link library)。 - 运行时依赖:可执行文件在运行时需要找到并加载动态库。
- 运行时链接:动态库的链接发生在程序运行时。可执行文件仅包含对动态库中函数的入口地址的引用,而不是完整代码。
- 共享机制:多个程序可以共享同一份动态库代码,从而减少内存和磁盘空间的使用。
- 动态链接(Dynamic Linking):是指在程序启动时,操作系统负责加载所需的动态库,并将其代码映射到进程的虚拟内存空间中。
- 当程序调用动态库中的函数时,操作系统会根据入口地址找到对应的函数并执行。
优点
- 小的可执行文件:可执行文件不包含库的代码,文件体积较小。
- 内存节省:多个程序可以共享同一份动态库代码,减少内存占用。
- 方便更新:只需更新动态库文件,不需要重新编译依赖该库的应用程序。
缺点
- 启动延迟:启动应用程序时需要加载动态库,可能导致启动速度变慢。
- 运行时错误:如果动态库缺失或版本不兼容,可能导致运行时错误。
- 版本管理:管理动态库版本可能会变得复杂,尤其是在多个程序依赖不同版本时。
使用场景
- 用于需要频繁更新的库,或当多个程序需要共享同一库时。
- 在大型应用程序中,减少内存占用和可执行文件大小。
3. 关键区别总结
| 特性 | 静态库 | 动态库 |
|---|---|---|
| 链接时机 | 编译时链接 | 运行时链接 |
| 文件扩展名 | .a (Unix/Linux), .lib (Windows) | .so (Unix/Linux), .dll (Windows) |
| 可执行文件大小 | 较大 | 较小 |
| 内存占用 | 每个程序独立加载 | 共享同一份库代码 |
| 更新复杂性 | 需要重新编译应用程序 | 只需更新库文件 |
| 性能 | 启动速度快 | 启动速度可能较慢 |
| 依赖性 | 无运行时依赖 | 运行时依赖 |
创建静态库
使用 ar 命令将目标文件打包成静态库:
ar rcs libmathlib.a mathlib.o
r:插入文件。c:创建库。s:生成索引。
这将创建一个名为 libmathlib.a 的静态库文件。
ar是gnu归档工具,rc表示(replace and create)
查看静态库中的目录列表
可以使用 ar t 命令来列出静态库中的文件:
ar t libmathlib.a
-
如果你想要查看更详细的信息,可以结合
v选项使用:ar tv libmymath.a tv:t选项显示文件列表,v选项表示详细模式。-
这会列出库中的所有文件,并显示文件的大小和时间戳。
-
提取文件:
如果需要从静态库中提取某个目标文件,可以使用:ar x libmathlib.a mathlib.o
路径搜索
gcc -o mytest main.c -I ./mylib/include -L ./mylib/lib -l mymath1. 命令结构
gcc
- GNU Compiler Collection:GNU 编译器集合的简称,是编译 C、C++ 和其他语言的工具。
-o mytest
- 输出文件:
-o选项指定生成的可执行文件名。在这个例子中,生成的可执行文件名为mytest。
main.c
- 源文件:这是要编译的源代码文件。在这个例子中,
main.c是包含main函数的 C 源文件。
-I ./mylib/include
- 包含目录:
-I选项用于指定头文件的搜索路径。./mylib/include是一个相对路径,告诉编译器在这个目录中查找头文件。 - 例如,如果
main.c中有#include "mymath.h",编译器会在./mylib/include目录中寻找mymath.h文件。
-L ./mylib/lib
- 库目录:
-L选项用于指定库文件的搜索路径。./mylib/lib是一个相对路径,告诉链接器在这个目录中查找库文件。 - 这通常用于链接静态库或动态库。
-l mymath
- 链接库:
-l选项用于链接一个库。在这个例子中,-l mymath表示链接名为libmymath.a(静态库)或libmymath.so(动态库)的库文件。 - 链接器会自动添加库文件的前缀
lib和后缀.a或.so,根据库的类型进行选择。
2. 整个命令的作用
综合上述各部分,这条命令的作用是:
- 编译
main.c文件。 - 在编译过程中,查找头文件时会在
./mylib/include目录中查找。 - 在链接时,会在
./mylib/lib目录中查找名为libmymath.a或libmymath.so的库文件。 - 最终生成名为
mytest的可执行文件。
1. -I
- 含义:指定头文件的搜索路径(Include)。
- 记忆方法:可以联想到 "Include" 的首字母
I。当你在代码中需要包含文件时,GCC 需要知道去哪里找这些文件。
2. -L
- 含义:指定库文件的搜索路径(Library)。
- 记忆方法:可以联想到 "Library" 的首字母
L。这个选项告诉编译器去哪里寻找你要链接的库文件。
3. -l
- 含义:链接指定的库(link)。
- 记忆方法:可以联想到 "link" 的首字母
l,或者可以想象成 "library" 的简写形式。使用这个选项时,你在告诉编译器要链接的库的名称。
总结
-I= Include 头文件-L= Library 路径-l= link 库
生成动态库
shared: 表示生成共享库格式
fPIC:产生位置无关码(position independent code)
动态库名规则:libxxx.so
编译源文件为动态库
使用 gcc 编译源文件并生成动态库。可以使用 -fPIC 选项和 -shared 选项来生成共享库。
编译命令
gcc -fPIC -c mathlib.c -o mathlib.o
-fPIC:生成位置无关代码(Position Independent Code),这是创建共享库的必要条件。-c:表示只编译源文件,不进行链接。
创建动态库
接下来,使用 gcc 将目标文件打包成共享库:
gcc -shared -o libmathlib.so mathlib.o
-shared:指示编译器创建一个共享库。-o libmathlib.so:指定生成的库文件名。
设置库路径
1、拷贝.so文件到系统共享库路径下, 一般指/usr/lib
2、更改 LD_LIBRARY_PATH
3、ldconfig 配置/etc/ld.so.conf.d/,ldconfig更新
设置动态库路径的几种方法可以帮助系统找到共享库文件。
方法 1:拷贝 .so 文件到系统共享库路径
-
拷贝共享库文件:
将.so文件拷贝到系统的共享库目录,通常是/usr/lib或/usr/local/lib。使用cp命令:sudo cp libmathlib.so /usr/lib/或者对于某些系统:
sudo cp libmathlib.so /usr/local/lib/
方法 2:更改 LD_LIBRARY_PATH
LD_LIBRARY_PATH 是一个环境变量,用于指定动态链接器查找库文件的目录。
-
设置环境变量:
可以在终端中临时设置LD_LIBRARY_PATH:export LD_LIBRARY_PATH=/path/to/your/library:$LD_LIBRARY_PATH将
/path/to/your/library替换为包含.so文件的实际路径。 -
持久化设置:
如果希望在每次登录时自动设置,可以将上述命令添加到用户的~/.bashrc或~/.bash_profile文件中:echo "export LD_LIBRARY_PATH=/path/to/your/library:\$LD_LIBRARY_PATH" >> ~/.bashrc然后使用以下命令使更改生效:
source ~/.bashrc
方法 3:使用 ldconfig 和配置文件
-
创建配置文件:
在/etc/ld.so.conf.d/目录下创建一个新的配置文件,命名为mylib.conf(可以自定义名称):echo "/path/to/your/library" | sudo tee /etc/ld.so.conf.d/mylib.conf将
/path/to/your/library替换为包含.so文件的实际路径。 -
更新库缓存:
运行ldconfig更新库缓存:sudo ldconfig
总结
这三种方法都可以使系统找到所需的动态库。
- 拷贝到系统库目录:适合全局使用的库。
- 更改
LD_LIBRARY_PATH:适合临时或用户特定的库。 - 使用
ldconfig和配置文件:适合长期管理库路径的情况。 - 库文件名称和引入库的名称 如:libc.so -> c库,去掉前缀lib,去掉后缀.so或.a
tee
tee 是一个在 Unix/Linux 系统中非常有用的命令行工具。它的主要功能是从标准输入读取数据,并同时将数据写入标准输出和一个或多个文件中。这样,你可以在终端查看输出的同时,也将其保存到文件中。
基本用法
1. 语法
tee [OPTION]... [FILE]...
2. 常见选项
-a:以附加模式打开文件(追加到文件末尾,而不是覆盖)。-i:忽略中断信号。
3. 示例
3.1. 基本示例
将命令的输出写入文件并显示在终端:
echo "Hello, World!" | tee output.txt
这将会在终端显示 "Hello, World!",同时将其写入 output.txt 文件。
3.2. 追加到文件
如果你希望将输出追加到文件中而不是覆盖,可以使用 -a 选项:
echo "Another line" | tee -a output.txt
这会将 "Another line" 追加到 output.txt 文件的末尾。
3.3. 多个文件
tee 也可以同时写入多个文件:
echo "Test" | tee file1.txt file2.txt
这将把 "Test" 写入 file1.txt 和 file2.txt。
进程间通信
进程间通信(Inter-Process Communication,IPC)是指在不同进程之间交换数据和信息的机制。由于进程之间的内存空间是独立的,因此需要特定的技术和方法来实现通信。
以下是一些常见的进程间通信机制及其详细说明:
1. 管道(Pipes)
描述:管道是一种单向的通信机制,允许一个进程将数据发送到另一个进程。
- 匿名管道:通常用于父子进程之间的通信。
- 命名管道(FIFO):可以在任意两个进程之间通信,通过文件系统中的特殊文件实现。
示例(C语言):
#include <stdio.h>
#include <unistd.h>
int main() {
int fd[2];
pipe(fd); // 创建管道
if (fork() == 0) { // 子进程
close(fd[1]); // 关闭写端
char buffer[100];
read(fd[0], buffer, sizeof(buffer)); // 读数据
printf("Received: %s\n", buffer);
close(fd[0]);
} else { // 父进程
close(fd[0]); // 关闭读端
write(fd[1], "Hello, IPC!", 12); // 写数据
close(fd[1]);
}
return 0;
}
2. 消息队列(Message Queues)
描述:消息队列允许不同进程通过消息的方式进行通信,消息可以被存储在队列中,允许异步处理。
- 优点:可以按优先级发送消息,且消息可以在发送和接收之间存储。
示例(C语言,使用 System V 消息队列):
#include <stdio.h>
#include <sys/ipc.h>
#include <sys/msg.h>
#include <string.h>
struct msgbuf {
long mtype;
char mtext[100];
};
int main() {
int msgid = msgget(IPC_PRIVATE, 0666 | IPC_CREAT); // 创建消息队列
struct msgbuf message;
if (fork() == 0) { // 子进程
message.mtype = 1;
strcpy(message.mtext, "Hello, IPC!");
msgsnd(msgid, &message, sizeof(message.mtext), 0); // 发送消息
} else { // 父进程
msgrcv(msgid, &message, sizeof(message.mtext), 1, 0); // 接收消息
printf("Received: %s\n", message.mtext);
msgctl(msgid, IPC_RMID, NULL); // 删除消息队列
}
return 0;
}
3. 共享内存(Shared Memory)
描述:共享内存允许多个进程访问同一块内存区域,提供了高效的数据交换方式。
- 优点:速度快,适合大量数据的交换。
示例(C语言):
#include <stdio.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <string.h>
#include <unistd.h>
int main() {
int shmid = shmget(IPC_PRIVATE, 1024, 0666 | IPC_CREAT); // 创建共享内存
char *str = (char*) shmat(shmid, NULL, 0); // 连接共享内存
if (fork() == 0) { // 子进程
strcpy(str, "Hello, IPC!");
shmdt(str); // 断开连接
} else { // 父进程
sleep(1); // 等待子进程写入
printf("Received: %s\n", str);
shmdt(str); // 断开连接
shmctl(shmid, IPC_RMID, NULL); // 删除共享内存
}
return 0;
}
4. 套接字(Sockets)
描述:套接字是一种网络通信机制,可以在本地和远程进程之间进行通信。支持 TCP 和 UDP 协议。
- 优点:灵活性高,支持网络通信。
示例(C语言,TCP 套接字)(省略了错误处理):
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <unistd.h>
#include <arpa/inet.h>
#define PORT 8080
int main() {
int sockfd;
struct sockaddr_in server_addr;
char *message = "Hello, IPC!";
sockfd = socket(AF_INET, SOCK_STREAM, 0); // 创建套接字
server_addr.sin_family = AF_INET;
server_addr.sin_addr.s_addr = INADDR_ANY;
server_addr.sin_port = htons(PORT);
bind(sockfd, (struct sockaddr*)&server_addr, sizeof(server_addr));
listen(sockfd, 5); // 监听连接
int new_sock = accept(sockfd, NULL, NULL); // 接受连接
send(new_sock, message, strlen(message), 0); // 发送消息
char buffer[1024] = {0};
read(new_sock, buffer, sizeof(buffer)); // 接收消息
printf("Received: %s\n", buffer);
close(new_sock);
close(sockfd);
return 0;
}
5. 信号(Signals)
描述:信号是一种异步通信机制,用于通知进程发生了某种事件。
- 优点:轻量级,适用于简单的事件通知。
示例(C语言):
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <signal.h>
void handler(int signum) {
printf("Received signal %d\n", signum);
}
int main() {
signal(SIGUSR1, handler); // 注册信号处理函数
if (fork() == 0) { // 子进程
sleep(1); // 等待父进程
kill(getppid(), SIGUSR1); // 发送信号
} else { // 父进程
pause(); // 等待信号
}
return 0;
}
总结
进程间通信(IPC)提供了多种机制,包括管道、消息队列、共享内存、套接字和信号等。
进程间通信目的
进程间通信(IPC)的目的主要包括以下几个方面:
1. 数据传输
- 描述:一个进程需要将数据发送给另一个进程。这种数据可以是计算结果、输入数据或任何其他信息。
- 应用:例如,在客户端-服务器模型中,客户端将请求数据发送给服务器,服务器处理后返回结果。
2. 资源共享
- 描述:多个进程之间共享同样的资源,如内存、文件或设备。
- 应用:在多进程应用中,多个进程可以访问共享内存区域,以提高数据访问效率,避免重复数据存储。
3. 通知事件
- 描述:一个进程需要向另一个或一组进程发送消息,通知它们某种事件的发生,如进程的终止、状态变化或任务完成。
- 应用:例如,子进程结束时可能需要通知父进程,以便父进程可以进行相应的处理(如资源清理或状态更新)。
4. 进程控制
- 描述:某些进程希望完全控制另一个进程的执行,例如调试进程。这些控制进程需要能够拦截信号、异常和陷入,并及时了解被控进程的状态变化。
- 应用:调试工具可以使用这种机制监控其他进程的执行,捕获异常信息,分析程序的运行状态。
总结
进程间通信的目的在于实现进程之间的有效协作,通过数据传输、资源共享、事件通知和进程控制等方式,提升系统的整体性能和灵活性。这些机制使得复杂的应用程序能够在多进程环境中高效运行。
进程间通信发展
管道
System V进程间通信
POSIX进程间通信
进程间通信分类
管道
匿名管道pipe
命名管道
System V IPC
System V 消息队列
System V 共享内存
System V 信号量
POSIX IPC
消息队列
共享内存
信号量
互斥量
条件变量
读写锁管道(Pipes)
描述
管道是最早的进程间通信机制之一,允许一个进程将数据传输到另一个进程。管道可以是匿名的或命名的。管道是一个用于在进程间传输数据的缓冲区,通常是无名的(即不在文件系统中有实体)。
特点
- 匿名管道:通常用于父子进程之间的通信。数据单向流动,父进程写入数据,子进程读取。
- 命名管道(FIFO):可以在任意两个进程之间通信。通过文件系统创建,具有持久性。
管道是Unix中最古老的进程间通信的形式。 我们把从一个进程连接到另一个进程的一个数据流称为一个“管道”。
匿名管道
pipe 函数
功能
pipe 函数用于创建一条无名管道,提供一个单向的数据通道。通过管道,进程可以通过写端发送数据,并通过读端接收数据。
原型
int pipe(int fd[2]);
参数
fd:文件描述符数组,长度为 2。fd[0]:表示管道的读端。通过该文件描述符,进程可以从管道中读取数据。fd[1]:表示管道的写端。通过该文件描述符,进程可以向管道写入数据。
返回值
- 成功:返回 0。
- 失败:返回 -1,并设置
errno,表示错误类型。errno可以用来判断错误的具体原因,例如:EMFILE:进程打开的文件描述符数量达到上限。ENFILE:系统打开的文件描述符数量达到上限。ENOMEM:内存不足,无法分配所需的资源。
使用示例
下面是一个简单的示例,展示如何使用 pipe 创建一个无名管道,并在父子进程之间进行通信:
#include <iostream>
#include <cstdio>
#include <unistd.h>
#include <sys/wait.h>
#include <sys/types.h>
#include <cstring>
using std::cout;
using std::endl;
int main()
{
int fds[2];
int n = pipe(fds); // 创建管道
if (n < 0)
return -1;
pid_t id = fork(); // 创建子进程
if (id < 0)
return -1;
if (id == 0) // 子进程
{
close(fds[0]); // 关闭子进程读端
const char *s = "我是子进程,正在给父进程发消息";
int cnt = 0;
while (true)
{
cnt++;
char buf[1024];
snprintf(buf, sizeof buf, "child->parent say: %s[%d][%d]", s, cnt, getpid());
write(fds[1], buf, strlen(buf)); // 向管道写入数据
sleep(1); // 每秒发送一次
}
close(fds[1]); // 关闭子进程写端
exit(0);
}
// 父进程
close(fds[1]); // 关闭父进程写端
while (true)
{
char buf[1024];
ssize_t s = read(fds[0], buf, sizeof(buf) - 1); // 从管道读取数据
if (s > 0)
buf[s] = 0; // 添加字符串结束符
cout << "Get Message# " << buf << "| my pid :" << getpid() << endl; // 打印收到的消息
}
n = waitpid(id, nullptr, 0); // 等待子进程结束
if (n != id)
return -1;
cout << "fds[0]: " << fds[0] << endl; // 打印管道的文件描述符
cout << "fds[1]: " << fds[1] << endl;
close(fds[0]); // 关闭父进程读端
return 0;
}- 文件描述符(FD):是一个非负整数,用于标识打开的文件或 I/O 资源。每个进程都有自己的文件描述符表。
- 管道的文件描述符:
- 读端
fd[0]:用于读取数据。当没有数据可读时,读取操作会阻塞,直到有数据可用或管道关闭。 - 写端
fd[1]:用于写入数据。当没有足够的缓冲区空间时,写入操作会阻塞,直到有空间可用或管道关闭。
- 读端
管道的读写操作是阻塞的:
- 读操作:如果没有数据可读,读操作会阻塞,直到有数据可用或管道的写端被关闭。
- 写操作:如果管道的缓冲区已满,写操作会阻塞,直到有空间可用或管道的读端被关闭。
- 管道的生命周期与创建它的进程相关。管道的读端和写端的文件描述符在进程退出时会被自动关闭。
- 如果写端被关闭,且读端仍然打开,读操作会读取到 EOF(文件结束标志),这表示没有更多的数据可读。
- 如果读端被关闭,且写端仍然打开,操作系统会给写进程发送
SIGPIPE信号,这通常会导致写进程终止,除非它处理了这个信号。 - 处理
SIGPIPE:如果写进程忽略这个信号或捕获它,它可以继续运行,但写入操作通常会失败,并返回一个错误(如EPIPE),指示管道破裂。
在使用管道的多进程程序中,每个进程都会有自己的文件描述符表:
- 当通过
fork()创建子进程时,子进程会继承父进程的文件描述符,包括管道的读端和写端。 - 这意味着子进程可以直接使用父进程创建的管道进行通信。
在复杂的应用中,多个进程可能会同时写入一个管道或同时从一个管道读取数据:
- 竞争条件:如果多个进程同时写入同一个管道,数据的顺序可能会混乱。
- 解决方案:可以使用互斥锁或信号量来管理对管道的并发访问。
- 容量限制:管道的缓冲区通常有大小限制(如 4KB 或 8KB),这意味着在高频率数据传输时,可能会导致阻塞。
- 无名管道:无名管道在进程间传输数据时无法跨网络或不同的会话。
管道特点
只能用于具有共同祖先的进程(具有亲缘关系的进程)之间进行通信;通常,一个管道由一个进程创
建,然后该进程调用fork,此后父、子进程之间就可应用该管道。
管道提供流式服务
一般而言,进程退出,管道释放,所以管道的生命周期随进程
一般而言,内核会对管道操作进行同步与互斥
管道是半双工的,数据只能向一个方向流动;需要双方通信时,需要建立起两个管道
命名管道
命名管道(Named Pipe),在 UNIX 和 Linux 系统中通常称为 FIFO(First In, First Out),是一种特殊的文件类型,用于进程间通信。与匿名管道不同,命名管道在创建时会有一个名称,并且可以在任意两个进程之间进行通信。
管道应用的一个限制就是只能在具有共同祖先(具有亲缘关系)的进程间通信。 如果我们想在不相关的进程之间交换数据,可以使用FIFO文件来做这项工作,它经常被称为命名管道。 命名管道是一种特殊类型的文件。
以下是命名管道的主要特点和使用方法:
命名管道中的数据不会被写入磁盘,而是存储在内存中。
创建命名管道的方法可以通过命令行或程序中使用 mkfifo 函数。
1. 使用命令行创建命名管道
在命令行中,你可以使用 mkfifo 命令来创建一个命名管道。命令的基本格式如下:
mkfifo filename
例如,要创建一个名为 myfifo 的命名管道,可以执行:
mkfifo myfifo
2. 使用程序创建命名管道
在 C 或 C++ 程序中,可以使用 mkfifo 函数来创建命名管道。以下是一个简单示例:
#include <iostream>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h> // for mode_t
int main(int argc, char *argv[]) {
const char *fifoName = "myfifo"; // 命名管道的名称
mode_t mode = 0644; // 权限设置,0644 表示所有者可读写,其他用户可读
// 创建命名管道
if (mkfifo(fifoName, mode) < 0) {
perror("mkfifo"); // 错误处理
return 1;
}
std::cout << "命名管道 " << fifoName << " 创建成功。" << std::endl;
return 0;
}
3. 使用命名管道的注意事项
-
权限:
mode_t参数用于设置命名管道的权限。常见的权限设置包括:0644:所有者可读写,组用户和其他用户可读。0666:所有用户可读写。
-
错误处理:在创建命名管道时,最好检查
mkfifo的返回值,以便处理可能出现的错误(如文件已存在,权限不足等)。 -
删除管道:使用
unlink命令或remove函数可以删除命名管道。
匿名管道与命名管道的区别
匿名管道由pipe函数创建并打开。
命名管道由mkfifo函数创建,打开用open
FIFO(命名管道)与pipe(匿名管道)之间唯一的区别在它们创建与打开的方式不同,一但这些工作完成之后,它们具有相同的语义。
#include "comm.hpp"
int main()
{
std::cout << "Server is running, waiting for client..." << std::endl;
int wfd = open(NAMED_PIPE, O_WRONLY);
std::cout << "Server is ready!" << std::endl;
if (wfd < 0)
exit(1);
char buffer[1024];
while (true)
{
std::cout << "Please Say# ";
fgets(buffer, sizeof(buffer) - 1, stdin);
if (strlen(buffer) > 0)
buffer[strlen(buffer) - 1] = 0; // Remove newline
ssize_t n = write(wfd, buffer, strlen(buffer));
(void)n; // Discard the result
}
close(wfd);
return 0;
}#include "comm.hpp"
int main()
{
bool r = createFifo(NAMED_PIPE);
(void)r; // Discard the result
std::cout << "Server started, waiting for client..." << std::endl;
int rfd = open(NAMED_PIPE, O_RDONLY);
std::cout << "Connected!" << std::endl;
if (rfd < 0)
exit(1);
char buffer[1024];
while (true)
{
ssize_t s = read(rfd, buffer, sizeof(buffer) - 1);
if (s > 0)
{
buffer[s] = 0;
std::cout << "Client->" << buffer << std::endl;
}
else if (s == 0)
{
std::cout << "Client quit , me too!" << std::endl;
break;
}
else
{
std::cerr << "Read error: " << errno << " err string: " << strerror(errno) << std::endl;
break;
}
}
close(rfd);
removeFifo(NAMED_PIPE);
return 0;
}#pragma once
#include <iostream>
#include <string>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <fcntl.h>
#include <cerrno>
#include <cstring>
#define NAMED_PIPE "/tmp/named_pipe"
bool createFifo(const std::string &path)
{
umask(0);
int n = mkfifo(path.c_str(), 0600);
if (n == 0)
return true;
else
{
std::cerr << "Create FIFO error: " << errno << " err string: " << strerror(errno) << std::endl;
return false;
}
}
void removeFifo(const std::string &path)
{
int n = unlink(path.c_str());
(void)n;
}system V共享内存
System V 共享内存是系统中提供的一种进程间通信(IPC)机制,允许多个进程共享同一块内存区域,从而实现高效的数据交换。
共享内存区是最快的IPC形式。一旦这样的内存映射到共享它的进程的地址空间,这些进程间数据传递不再涉及到内核,换句话说是进程不再通过执行进入内核的系统调用来传递彼此的数据。
- 效率:由于共享内存直接在内存中进行读写,速度较其他 IPC 机制(如管道、消息队列等)更快。
创建和访问共享内存
shmget:创建一个新的共享内存段或访问现有的共享内存段。shmat:将共享内存段附加到进程的地址空间。shmdt:从进程的地址空间分离共享内存段。shmctl:控制共享内存段的属性(如删除、获取状态等)。
共享内存的特点
-
直接内存访问:
一旦共享内存段被映射到各进程的地址空间,进程可以直接访问这块内存,而无需通过内核进行数据传输。这样可以显著减少上下文切换的开销。 -
高效的数据交换:
由于数据在用户空间进行传递,避免了传统 IPC 机制(如管道、消息队列等)中频繁的系统调用,从而实现更高效的数据交换。 -
适用于大量数据传输:
共享内存非常适合需要传递大量数据的场景,比如图像处理、大型计算等。
使用共享内存的优势
-
性能:
由于不需要频繁进入内核,进程间的数据传输速度非常快,适合实时应用和高性能计算。 -
低延迟:
共享内存几乎没有延迟,因为数据传输不涉及内核的调度和上下文切换。 -
灵活性:
共享内存的大小和内容可以动态调整,适应不同的应用需求。
需要注意的事项
-
同步问题:
当多个进程同时访问共享内存时,必须使用同步机制(如信号量、互斥锁等)来避免数据竞争和不一致性。 -
资源管理:
共享内存的创建和销毁需要仔细管理,避免内存泄漏和资源浪费。 -
复杂性:
虽然共享内存本身很高效,但实现起来可能比其他 IPC 机制更复杂,尤其是在多进程同步和数据一致性方面。
ipcs
ipcs 是一个用于显示当前系统中的进程间通信(IPC)资源的命令行工具。它通常用于查看共享内存段、消息队列和信号量的状态和信息。
1. 基本用法
在终端中输入 ipcs 命令,可以查看系统中的 IPC 资源。基本命令如下:
ipcs
2. 常用选项
-m:显示共享内存段的信息。-q:显示消息队列的信息。-s:显示信号量的信息。-a:显示所有类型的 IPC 资源。-l:显示系统限制信息。-p:显示进程信息,包括创建者和最后操作的进程 ID。
3. 示例
查看共享内存段
ipcs -m
查看消息队列
ipcs -q
查看信号量
ipcs -s
查看所有 IPC 资源
ipcs -a
查看系统限制
ipcs -l
4. 输出解释
ipcs 命令的输出通常包含以下字段:
- key:IPC 资源的键值。
- shmid(对于共享内存):共享内存段的 ID。
- msgid(对于消息队列):消息队列的 ID。
- semid(对于信号量):信号量的 ID。
- owner:资源的拥有者。
- permissions:资源的访问权限。
- size:资源的大小。
- nattch:附加到共享内存段的进程数量(仅适用于共享内存)。
- ctime:资源的创建时间。
ipcrm
ipcrm 是一个命令行工具,用于删除系统中的进程间通信(IPC)资源,包括共享内存段、消息队列和信号量。这在清理不再需要的 IPC 资源时非常有用。
1. 基本用法
删除 IPC 资源的基本语法
ipcrm [options] <id>
选项
-m <shmid>:删除指定的共享内存段。-q <msgid>:删除指定的消息队列。-s <semid>:删除指定的信号量。
2. 示例
2.1 删除共享内存段
如果您已经使用 ipcs -m 命令查看到共享内存段的 ID(如 shmid),可以使用以下命令删除它:
ipcrm -m <shmid>
例如,如果 shmid 为 12345:
ipcrm -m 12345
2.2 删除消息队列
同样,使用 ipcs -q 查看消息队列的 ID,并使用以下命令删除它:
ipcrm -q <msgid>
例如,如果 msgid 为 67890:
ipcrm -q 67890
2.3 删除信号量
使用 ipcs -s 查看信号量的 ID,并使用以下命令删除它:
ipcrm -s <semid>
例如,如果 semid 为 54321:
ipcrm -s 54321
3. 确认清理结果
在使用 ipcrm 命令删除 IPC 资源后,可以再次使用 ipcs 命令确认资源是否已被成功清理。
ipcs -m # 查看共享内存段
ipcs -q # 查看消息队列
ipcs -s # 查看信号量
共享内存函数
共享内存是进程间通信(IPC)的一种高效方式。在 Linux 系统中,使用共享内存的主要函数包括 shmget、shmat、shmdt 和 shmctl。
注意:共享内存没有进行同步与互斥!
1. shmget 函数
功能:创建一个共享内存段或获取一个已存在的共享内存段的标识符。
原型:
int shmget(key_t key, size_t size, int shmflg);
参数:
key:共享内存段的唯一标识符,通常通过ftok函数生成。size:共享内存段的大小(以字节为单位)。shmflg:权限标志,由九个权限标志构成,它们的用法和创建文件时使用的mode模式标志是相似的 。
shmflg 可以包含以下标志:
1. 基本权限标志
IPC_CREAT:如果共享内存段不存在,则创建它。IPC_EXCL:与IPC_CREAT一起使用,如果共享内存段已存在,调用将失败并返回错误。
2. 权限模式
这部分与文件权限相似,可以使用以下模式标志:
0666:表示所有用户都可以读写。0664:表示所有用户可以读,只有拥有者和组用户可以写。0644:表示只有拥有者可以读写,组用户和其他用户只能读。
3. 示例组合
shmflg 可以同时使用多个标志,例如:
0666 | IPC_CREAT:创建一个共享内存段,并设置读写权限。0660 | IPC_CREAT | IPC_EXCL:创建一个共享内存段,仅限拥有者和组用户写入,且如果已存在则失败。
返回值:
- 成功返回一个非负整数,即该共享内存段的标识符(
shmid)。 - 失败返回
-1。
2. shmat 函数
功能:将共享内存段连接到进程的地址空间。
原型:
void *shmat(int shmid, const void *shmaddr, int shmflg);
参数:
shmid:共享内存段的标识符。shmaddr:指定连接的地址,如果为NULL,内核会自动选择一个地址。shmflg:可以是SHM_RDONLY(只读)和SHM_RND(随机地址)等标志。
返回值:
- 成功返回指向共享内存段的指针。
- 失败返回
-1。
3. shmdt 函数
功能:将共享内存段从当前进程的地址空间中分离。
原型:
int shmdt(const void *shmaddr);
参数:
shmaddr:由shmat返回的指针,指向要分离的共享内存段。
返回值:
- 成功返回
0。 - 失败返回
-1。
4. shmctl 函数
功能:控制共享内存段的操作,例如获取状态信息或删除共享内存段。
原型:
int shmctl(int shmid, int cmd, struct shmid_ds *buf);
参数:
shmid:共享内存段的标识符。cmd:要执行的操作,可以是以下几种:IPC_STAT:获取共享内存段的信息。IPC_RMID:删除共享内存段。IPC_SET:设置共享内存段的权限。
buf:指向shmid_ds结构体的指针,用于保存共享内存的状态和权限信息。
返回值:
- 成功返回
0。 - 失败返回
-1。
5. struct shmid_ds
struct shmid_ds {
struct ipc_perm shm_perm; /* 操作权限 */
int shm_segsz; /* 共享内存段大小(字节) */
__kernel_time_t shm_atime; /* 最后附加时间 */
__kernel_time_t shm_dtime; /* 最后分离时间 */
__kernel_time_t shm_ctime; /* 最后修改时间 */
__kernel_ipc_pid_t shm_cpid; /* 创建进程 PID */
__kernel_ipc_pid_t shm_lpid; /* 最后操作进程 PID */
unsigned short shm_nattch; /* 当前附加进程数量 */
unsigned short shm_unused; /* 兼容性 */
void *shm_unused2; /* 兼容性 - DIPC 使用 */
void *shm_unused3; /* 未使用 */
};
6. 实例代码
下面是一个简单的示例,演示如何使用上述函数创建和使用共享内存。
#include <stdio.h>
#include <stdlib.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <string.h>
#include <unistd.h>
#define SHM_SIZE 1024 // 共享内存大小
int main() {
key_t key = ftok("shmfile", 65); // 生成唯一键
int shmid = shmget(key, SHM_SIZE, 0666 | IPC_CREAT); // 创建共享内存
if (shmid == -1) {
perror("shmget");
exit(EXIT_FAILURE);
}
// 连接共享内存
char *str = (char *)shmat(shmid, (void *)0, 0);
if (str == (char *)(-1)) {
perror("shmat");
exit(EXIT_FAILURE);
}
// 写入数据
strcpy(str, "Hello, Shared Memory!");
printf("Data written to shared memory: %s\n", str);
// 等待输入以查看数据
printf("Press Enter to detach and delete shared memory...\n");
getchar();
// 分离共享内存
if (shmdt(str) == -1) {
perror("shmdt");
exit(EXIT_FAILURE);
}
// 删除共享内存
if (shmctl(shmid, IPC_RMID, NULL) == -1) {
perror("shmctl");
exit(EXIT_FAILURE);
}
return 0;
}
共享内存的大小是系统页面的倍数
建议使用系统页面大小的整数倍来优化性能。这是因为操作系统通常以页面为单位来管理内存。
1. 页面大小
在大多数 Linux 系统中,默认的页面大小通常是 4KB,但在某些系统中可能会有所不同。可以通过以下命令查看当前系统的页面大小:
getconf PAGE_SIZE
2. 为什么使用页面大小的整数倍?
- 性能优化:操作系统以页面为单位管理内存,使用页面大小的倍数可以减少内存碎片,提高内存分配效率。
- 避免分配失败:如果请求的共享内存大小不是页面大小的整数倍,可能会导致内存分配时出现问题,尤其在某些特定配置的系统中。
3. 实际应用
尽管没有硬性规定必须使用页面大小的倍数,但为了兼容性和性能,建议在设计共享内存大小时考虑这一点。例如,如果页面大小为 4KB,可以选择 4KB、8KB、16KB 等大小。
示例
在创建共享内存段时,可以自由选择大小,但最好还是遵循这一原则:
#define SHM_SIZE (4 * 1024) // 4KB
或者:
#define SHM_SIZE (8 * 1024) // 8KB
在 Linux 系统中,当您请求共享内存或其他类型的内存时,如果申请的大小不是系统页面大小的整数倍,内核通常会进行向上取整,以确保分配满足对齐要求。这意味着如果您申请 4097 字节,内核可能会将其向上调整到下一个页面大小的整数倍。
1. 页面大小
在大多数 Linux 系统上,默认的页面大小通常是 4KB(4096 字节)。因此,在请求共享内存时:
- 如果您申请 4097 字节,内核会将其向上取整到 8kB(8192 字节)(两个页面)。
2. 向上取整的影响
- 内存浪费:如果经常申请不满足页面大小整数倍的内存,可能会导致内存浪费,因为每次申请的内存都要向上取整。
- 性能:内存管理的效率可能会受到影响,尤其是在频繁进行内存申请和释放的场景中。
getconf
getconf 是一个用于查询系统配置参数的命令行工具。在 Linux 和 Unix 系统中,getconf 可以用来获取各种系统和环境的配置信息,例如页面大小、最大文件名称长度、系统的最大用户数量等。
基本用法
getconf [option] [configuration_variable]
常用选项和参
-
getconf PAGE_SIZE或
getconf PAGESIZE -
获取系统最大路径长度
getconf PATH_MAX / -
获取最大文件名称长度
getconf NAME_MAX / -
获取系统最大用户数量
getconf _SC_CHILD_MAX -
获取系统的最大进程数
getconf _SC_NPROCESSORS_CONF
System V 消息队列
System V 消息队列是 Unix 和类 Unix 系统中用于进程间通信(IPC)的一种机制。它允许一个进程将消息发送到一个队列中,另一个进程可以从这个队列中读取消息。消息队列支持优先级和消息的非阻塞读取,适合需要异步通信的场景。
主要功能
- 消息发送:进程可以将消息发送到消息队列中。
- 消息接收:进程可以从消息队列中接收消息。
- 消息优先级:支持不同优先级的消息,可以根据优先级来决定接收顺序。
- 非阻塞操作:可以选择非阻塞地发送和接收消息。
相关函数
以下是 System V 消息队列的常用函数:
-
创建或获取消息队列
msgget(key_t key, int msgflg):创建一个新的消息队列或获取现有的消息队列。key:消息队列的唯一标识符。msgflg:控制标志,通常使用IPC_CREAT创建新队列。
-
发送消息
msgsnd(int msqid, const void *msgp, size_t msgsz, int msgflg):将消息发送到消息队列。msqid:消息队列标识符。msgp:指向消息内容的指针。msgsz:消息的大小。msgflg:控制标志。
-
接收消息
msgrcv(int msqid, void *msgp, size_t msgsz, long msgtyp, int msgflg):从消息队列接收消息。msqid:消息队列标识符。msgp:指向接收消息的缓冲区。msgsz:缓冲区的大小。msgtyp:消息类型,0 表示接收任何类型的消息。msgflg:控制标志。
-
删除消息队列
msgctl(int msqid, int cmd, struct msqid_ds *buf):控制消息队列的操作。msqid:消息队列标识符。cmd:控制命令,使用IPC_RMID删除消息队列。buf:指向消息队列状态信息的结构体。
示例代码
下面是一个简单的示例,演示如何创建、发送和接收消息:
消息发送程序(sender.c)
#include <stdio.h>
#include <stdlib.h>
#include <sys/ipc.h>
#include <sys/msg.h>
#include <string.h>
#include <unistd.h>
#define MSG_SIZE 100
struct msgbuf {
long mtype; // 消息类型
char mtext[MSG_SIZE]; // 消息内容
};
int main() {
key_t key = ftok("msgfile", 65); // 生成唯一键
int msgid = msgget(key, 0666 | IPC_CREAT); // 创建消息队列
struct msgbuf message;
message.mtype = 1; // 设置消息类型
strcpy(message.mtext, "Hello, World!"); // 设置消息内容
msgsnd(msgid, &message, sizeof(message.mtext), 0); // 发送消息
printf("Message sent: %s\n", message.mtext);
return 0;
}
消息接收程序(receiver.c)
#include <stdio.h>
#include <stdlib.h>
#include <sys/ipc.h>
#include <sys/msg.h>
#include <string.h>
#define MSG_SIZE 100
struct msgbuf {
long mtype; // 消息类型
char mtext[MSG_SIZE]; // 消息内容
};
int main() {
key_t key = ftok("msgfile", 65); // 生成唯一键
int msgid = msgget(key, 0666 | IPC_CREAT); // 获取消息队列
struct msgbuf message;
msgrcv(msgid, &message, sizeof(message.mtext), 1, 0); // 接收消息
printf("Received message: %s\n", message.mtext);
msgctl(msgid, IPC_RMID, NULL); // 删除消息队列
return 0;
}
system V信号量
System V 信号量是一种用于进程间同步和互斥的机制,广泛用于 Unix 和类 Unix 系统中。信号量可以控制对共享资源的访问,确保在一个时刻只有一个进程可以访问该资源,从而避免数据冲突和不一致的问题。
信号量的类型
- 计数信号量:可以取任意非负值,适用于控制多个资源的访问。
- 二进制信号量:只取 0 或 1,类似于互斥锁,用于保护临界区。
相关函数
以下是操作 System V 信号量的常用函数:
-
创建或获取信号量集
semget(key_t key, int nsems, int semflg):创建或获取一个信号量集。semflg:控制标志。nsems:信号量的数量。key:信号量的唯一标识符。
-
初始化信号量
semctl(int semid, int semnum, int cmd, ...):控制信号量的操作。cmd:控制命令,通常使用SETVAL初始化信号量的值。semnum:信号量的索引。semid:信号量集的标识符。
-
执行 P 操作
semop(int semid, struct sembuf *sops, size_t nsops):执行对信号量的操作。nsops:操作数组的大小。sops:指向操作数组的指针。semid:信号量集的标识符。
-
删除信号量
semctl(int semid, int semnum, int cmd):可以使用IPC_RMID命令删除信号量集。
示例代码
以下是一个简单的示例,演示如何使用 System V 信号量进行进程间同步。
信号量的创建与使用
信号量示例(semaphore_example.c):
#include <stdio.h>
#include <stdlib.h>
#include <sys/ipc.h>
#include <sys/sem.h>
#include <sys/types.h>
#include <unistd.h>
#include <string.h>
void P(int semid) {
struct sembuf sb = {0, -1, 0}; // P 操作
semop(semid, &sb, 1);
}
void V(int semid) {
struct sembuf sb = {0, 1, 0}; // V 操作
semop(semid, &sb, 1);
}
int main() {
key_t key = ftok("semfile", 65); // 生成唯一键
int semid = semget(key, 1, 0666 | IPC_CREAT); // 创建信号量集
semctl(semid, 0, SETVAL, 1); // 初始化信号量为1
if (fork() == 0) { // 子进程
for (int i = 0; i < 5; i++) {
P(semid); // 进入临界区
printf("Child process is in critical section.\n");
sleep(1); // 模拟进行某些操作
V(semid); // 退出临界区
}
} else { // 父进程
for (int i = 0; i < 5; i++) {
P(semid); // 进入临界区
printf("Parent process is in critical section.\n");
sleep(1); // 模拟进行某些操作
V(semid); // 退出临界区
}
}
// 等待子进程结束
wait(NULL);
semctl(semid, 0, IPC_RMID); // 删除信号量集
return 0;
}System V 信号量是一种有效的进程间同步机制,可以防止多个进程同时访问共享资源。通过使用 P 和 V 操作,可以实现临界区的安全访问,确保数据的一致性和完整性。在实际应用中,信号量常用于实现生产者-消费者模型、读写锁等场景。
system V IPC资源的生命周期随内核。
System V IPC 资源的生命周期
-
持久性:
IPC 资源在创建后会一直存在,直到显式删除或者系统重启。它们不会随着创建它们的进程的结束而自动消失。 -
资源管理:
开发者必须负责管理这些资源。未清理的 IPC 资源会占用系统内存,可能导致资源枯竭。 -
重启时清理:
当系统重启时,所有未删除的 IPC 资源会被内核清除。这意味着在系统重启后,IPC 资源会重新变得可用。
资源删除的重要性
- 避免错误:如果不删除资源,后续尝试创建相同类型的 IPC 资源时可能会遇到“文件已存在”的错误。例如,运行
shmget时,如果共享内存段已经存在,将返回错误。 - 内存泄漏:长期不清理的 IPC 资源会导致内存泄漏,最终影响系统的性能和稳定性。
信号量是一种用于进程间同步和互斥的机制,其本质是一种计数器,用于控制对共享资源的访问。信号量的设计旨在解决多个进程或线程在并发执行时可能遇到的资源竞争问题。
信号量的本质
-
计数器:
信号量可以看作是一个计数器,表示可用资源的数量。它可以取任意非负整数,通常用于表示某种共享资源的数量(如可用的锁、可用的缓冲区等)。 -
同步与互斥:
信号量用于实现进程间的同步,确保共享资源在某一时刻只能被一个进程访问。通过这种方式,信号量可以防止数据竞争和不一致的情况。 -
原子操作:
对信号量的操作(如 P 操作和 V 操作)是原子的。这意味着这些操作不可被中断,可以保证在多进程环境中信号量的状态变化是安全的。
信号
信号是 Unix 和类 Unix 系统中用于进程间通信的一种机制。它是一种异步通知方式,允许一个进程向另一个进程发送特定的事件或状态信息。信号通常用于处理事件、错误和中断。
信号的基本概念
-
异步通知:
信号是一种异步机制,允许进程在运行时接收通知,而不需要主动查询。 -
预定义信号:
系统定义了一组标准信号(如SIGINT、SIGTERM、SIGKILL等),每个信号都有特定的含义和默认处理方式。 -
用户定义信号:
用户可以定义自己的信号(如SIGUSR1和SIGUSR2)来进行自定义处理。
信号的发送
信号发送的本质是操作系统修改进程的信号位图
-
由内核发送:
- 某些信号由内核自动发送,例如:
SIGTERM:请求程序终止。SIGKILL:强制终止程序。SIGSEGV:内存访问错误。
- 某些信号由内核自动发送,例如:
-
由进程发送:
- 进程可以使用
kill函数或命令手动发送信号。例如:kill(pid, SIGTERM); // 向进程 pid 发送 SIGTERM 信号
- 进程可以使用
信号的处理
-
默认处理:
每个信号都有默认的处理方式,例如:SIGKILL默认强制终止进程,无法被捕获或忽略。SIGINT(通常由 Ctrl+C 触发)默认终止进程。
-
自定义处理:
进程可以使用signal或sigaction函数注册信号处理程序,以自定义对特定信号的响应。例如:void handle_sigint(int sig) { printf("Caught SIGINT! Exiting...\n"); exit(0); } int main() { signal(SIGINT, handle_sigint); // 注册 SIGINT 的处理函数 while (1) { // 主循环 } return 0; }
信号的特点
- 异步性:信号处理可以在进程的任何时刻发生。
- 非阻塞性:信号处理程序在执行时可能会中断进程的正常执行流。
- 有限性:信号数量有限(通常有 31 个标准信号),并且某些信号(如
SIGKILL和SIGSTOP)无法被捕获或忽略。
信号的应用
- 进程控制:如终止、暂停和恢复进程。
- 事件通知:如处理定时器到期、处理用户输入等。
- 错误处理:如处理非法操作、内存错误等。
总结
信号是一种轻量级的进程间通信机制,用于异步通知和事件处理。通过信号,进程可以响应系统事件、用户操作或其他进程的请求,增强了程序的灵活性和交互性。在编写多进程或需要响应外部事件的程序时,信号是一个重要的工具。
31 个标准信号
-
描述:挂起信号,通常用于通知进程终止或重新加载配置。SIGHUP(1): -
描述:中断信号,通常由 Ctrl+C 触发,用于中断进程。SIGINT(2): -
描述:退出信号,通常由 Ctrl+\ 触发,终止进程并生成核心转储。SIGQUIT(3): -
描述:非法指令信号,表示程序执行了无效的机器指令。SIGILL(4): -
描述:陷入信号,通常用于调试目的。SIGTRAP(5): -
描述:主动中止信号,由调用SIGABRT(6):abort()函数触发。 -
描述:总线错误信号,表示程序试图访问无效地址。SIGBUS(7): -
描述:浮点异常信号,表示非法的算术运算(如除以零)。SIGFPE(8): -
描述:强制终止信号,无法被捕获或忽略。SIGKILL(9): -
描述:用户定义信号 1,供用户自定义用途。SIGUSR1(10): -
描述:段错误信号,表示程序试图访问无效内存地址。SIGSEGV(11): -
描述:用户定义信号 2,供用户自定义用途。SIGUSR2(12): -
描述:管道破裂信号,表示写入一个没有读者的管道。SIGPIPE(13): -
描述:定时器信号,通常由SIGALRM(14):alarm()函数触发。 -
描述:终止信号,请求程序正常终止。SIGTERM(15): -
描述:栈浮点异常信号,特定于某些架构。SIGSTKFLT(16): -
描述:子进程状态变化信号,通常在子进程结束时发送。SIGCHLD(17): -
描述:继续信号,恢复被停止的进程。SIGCONT(18): -
描述:停止信号,无法被捕获或忽略,用于暂停进程。SIGSTOP(19): -
描述:终止前台进程的信号,通常由 Ctrl+Z 触发。SIGTSTP(20): -
描述:后台进程尝试读取终端信号。SIGTTIN(21): -
描述:后台进程尝试写入终端信号。SIGTTOU(22): -
描述:紧急数据到达信号。SIGURG(23): -
描述:超出 CPU 时间限制信号。SIGXCPU(24): -
描述:文件大小限制超出信号。SIGXFSZ(25): -
描述:虚拟时间定时器信号。SIGVTALRM(26): -
描述:专业时间定时器信号。SIGPROF(27): -
描述:窗口大小变化信号。SIGWINCH(28): -
描述:异步 I/O 信号。SIGIO(29): -
描述:电源故障信号。SIGPWR(30): -
描述:无效系统调用信号。SIGSYS(31):
信号是进程之间事件异步通知的一种方式,属于软中断。
Ctrl-C 和信号
-
前台进程:
- 当用户在终端中运行一个前台进程时,按下
Ctrl-C会产生一个SIGINT信号,默认情况下该信号会终止前台进程。 - 前台进程是与终端交互的进程,能够接收来自终端的控制信号(如
Ctrl-C和Ctrl-Z)。
- 当用户在终端中运行一个前台进程时,按下
-
后台进程:
- 在命令后添加
&会将进程放到后台运行。这样,Shell 不必等待该进程结束,可以接受新的命令和启动新的进程。 - 后台进程无法接收来自终端的控制信号(如
Ctrl-C),因为它们不与终端直接交互。
- 在命令后添加
每个信号都有一个编号和一个宏定义名称,这些宏定义可以在signal.h中找到。
例如其中有定义 #define SIGINT 2
编号34以上的是实时信号
这些信号各自在什么条件下 产生,默认的处理动作是什么,在signal(7)中都有详细说明: man 7 signal
信号处理方式
1. 忽略此信号。
2. 执行该信号的默认处理动作。
3. 提供一个信号处理函数,要求内核在处理该信号时切换到用户态执行这个处理函数,这种方式称为捕捉 (Catch)一个信号。
调用系统函数向进程发信号
kill 函数和 raise 函数都是用于发送信号的,但它们的功能和应用场景有所不同。
1. kill 函数
-
定义:
kill函数用于向指定的进程发送信号。尽管函数名为kill,它不仅仅用于终止进程,还可以发送多种信号。 -
语法:
int kill(pid_t pid, int sig);pid: 目标进程的进程 ID。如果pid为 0,信号将发送给当前进程组中的所有进程;如果pid为 -1,将发送信号给所有进程(需要特权);如果pid为正数,信号将发送给指定进程。sig: 要发送的信号类型(如SIGTERM,SIGINT,SIGUSR1等)。
-
返回值: 成功时返回 0,失败时返回 -1,并设置 errno。
2. raise 函数
-
定义:
raise函数用于向当前进程发送信号。它可以用来发送信号给自己。 -
语法:
int raise(int sig);sig: 要发送的信号类型。
-
返回值: 成功时返回 0,失败时返回非零值(通常是 -1)。
示例代码
以下是一个示例,展示如何使用 kill 和 raise 函数发送信号:
#include <iostream>
#include <csignal>
#include <unistd.h>
using namespace std;
// 信号处理函数
void signalHandler(int signal) {
cout << "Received signal: " << signal << endl;
}
int main() {
// 注册信号处理函数
signal(SIGUSR1, signalHandler);
pid_t pid = fork(); // 创建子进程
if (pid < 0) {
cerr << "Fork failed" << endl;
return 1;
} else if (pid == 0) {
// 子进程
cout << "Child process (PID: " << getpid() << ") sending signal to parent..." << endl;
kill(getppid(), SIGUSR1); // 向父进程发送 SIGUSR1 信号
_exit(0); // 退出子进程
} else {
// 父进程
cout << "Parent process (PID: " << getpid() << ") waiting for signal..." << endl;
// 等待一段时间以确保子进程能发送信号
sleep(1);
raise(SIGUSR1); // 当前进程给自己发送 SIGUSR1 信号
wait(NULL); // 等待子进程结束
cout << "Child process has terminated." << endl;
}
return 0;
}
输出结果
运行该程序时,输出可能类似于:
Parent process (PID: 12345) waiting for signal...
Child process (PID: 12346) sending signal to parent...
Received signal: 10
Received signal: 10
Child process has terminated.
总结
kill函数: 用于向指定进程发送信号,适合进程间的信号传递。raise函数: 用于向当前进程发送信号,适合进程内部的信号处理。
abort 函数简介
-
定义:
abort是一个标准库函数,声明在<cstdlib>头文件中。它会引发程序的非正常终止,并生成核心转储(core dump),以便后续调试。 -
语法:
void abort(); -
返回值: abort函数使当前进程接收到信号而异常终止。就像exit函数一样,abort函数总是会成功的,所以没有返回值。
2. 功能
- 当调用
abort函数时,程序会立即终止,并向操作系统发送SIGABRT信号。 - 如果没有捕获该信号,默认行为是终止进程,并在终端显示错误消息。
- 在终止之前,
abort会执行所有已注册的信号处理程序,特别是SIGABRT的处理程序(如果有的话)。
注意事项
- 调试: 使用
abort时会生成核心转储,这对于调试非常有用,可以帮助你了解程序在崩溃时的状态。 - 信号处理: 可以自定义信号处理程序,捕获
SIGABRT信号,并执行特定操作(如清理资源)。 - 不建议在生产代码中使用: 一般来说,
abort适合用于开发和调试阶段。在生产代码中,应该使用其他方式处理错误,例如抛出异常。
产生信号的方式
硬件异常产生信号
硬件异常被硬件以某种方式被硬件检测到并通知内核,然后内核向当前进程发送适当的信号。例如当前进程执行了除 以0的指令,CPU的运算单元会产生异常,内核将这个异常解释 为SIGFPE信号发送给进程。再比如当前进程访问了非 法内存地址,,MMU会产生异常,内核将这个异常解释为SIGSEGV信号发送给进程。
1. 硬件异常的类型
常见的硬件异常包括:
- 除零异常 (
SIGFPE): 当程序尝试执行除以零的操作时,会产生此信号。 - 无效操作异常 (
SIGILL): 当程序执行无效的机器指令时,例如执行未定义的指令时,会产生此信号。 - 段错误 (
SIGSEGV): 当程序访问无效的内存地址时,例如访问未分配或已释放的内存时,会产生此信号。 - 总线错误 (
SIGBUS): 当程序尝试访问对齐不当或不存在的内存地址时,会产生此信号。
2. 信号处理
当硬件异常导致信号产生时,操作系统将该信号发送到产生异常的进程。进程可以选择注册信号处理程序,以便在信号发生时执行特定操作。
3. 示例代码
#include <iostream>
#include <csignal>
#include <cstdlib>
#include <unistd.h>
using namespace std;
// 信号处理函数
void signalHandler(int signal) {
switch (signal) {
case SIGFPE:
cout << "Caught a floating-point exception (SIGFPE)." << endl;
break;
case SIGILL:
cout << "Caught an illegal instruction (SIGILL)." << endl;
break;
case SIGSEGV:
cout << "Caught a segmentation fault (SIGSEGV)." << endl;
break;
case SIGBUS:
cout << "Caught a bus error (SIGBUS)." << endl;
break;
default:
cout << "Caught signal: " << signal << endl;
break;
}
exit(signal); // 退出程序并返回信号编号
}
int main() {
// 注册信号处理函数
signal(SIGFPE, signalHandler);
signal(SIGILL, signalHandler);
signal(SIGSEGV, signalHandler);
signal(SIGBUS, signalHandler);
// 触发 SIGFPE(浮点异常)
int a = 1, b = 0;
cout << "Triggering SIGFPE (division by zero)..." << endl;
int c = a / b; // 除以零
// 触发 SIGILL(非法指令)
// asm("ud2"); // 触发非法指令
// 触发 SIGSEGV(段错误)
// int* p = nullptr;
// cout << "Triggering SIGSEGV (segmentation fault)..." << endl;
// cout << *p << endl; // 访问空指针
return 0;
}我们在C/C++当中除零,内存越界等异常,在系统层面上,是被当成信号处理的。
软件条件产生信号
SIGPIPE 是一种由软件条件产生的信号,通常在向无读者的管道或套接字写入数据时触发。与此相关的 alarm 函数和 SIGALRM 信号是用于定时任务的重要工具。
1. alarm 函数
alarm 函数用于设置一个定时器,使得在指定的秒数后,系统会向调用进程发送 SIGALRM 信号。
调用alarm函数可以设定一个闹钟,也就是告诉内核在seconds秒之后给当前进程发SIGALRM信号, 该信号的默认处理动作是终止当前进程。
函数原型
#include <unistd.h>
unsigned int alarm(unsigned int seconds);
参数
seconds: 定时器的时间长度(以秒为单位)。如果该参数为 0,则会取消当前的定时器。
返回值
- 返回值是未到期的定时器剩余时间(以秒为单位)。如果没有已设置的定时器,返回值为 0。
2. SIGALRM 信号
SIGALRM 信号是由系统在定时器到期时发送的信号。程序可以通过注册信号处理程序来捕获和处理此信号。
3. 示例代码
以下示例展示了如何使用 alarm 函数设置定时器,并处理 SIGALRM 信号:
#include <iostream>
#include <csignal>
#include <unistd.h>
using namespace std;
// 信号处理函数
void signalHandler(int signal) {
cout << "Received SIGALRM signal: Timer expired!" << endl;
}
int main() {
// 注册信号处理函数
signal(SIGALRM, signalHandler);
cout << "Setting alarm for 5 seconds..." << endl;
alarm(5); // 设置定时器,5秒后发送 SIGALRM 信号
// 模拟一些工作
while (true) {
cout << "Working..." << endl;
sleep(1); // 每秒输出一次
}
return 0;
}信号总结
1. OS 是信号的管理者
操作系统(OS)是计算机系统的核心部分,负责管理硬件和软件资源。信号是操作系统用于进程间通信和异步事件通知的一种机制。
- 管理功能: OS 负责创建和终止进程、调度进程、分配资源等。信号作为一种重要的通信机制,必须由 OS 管理,以确保其正确性和可靠性。
2. 信号的处理时机
信号的处理并不是立即发生的,而是在合适的时机进行处理。具体而言:
- 信号捕获: 当信号到达一个进程时,如果该进程正在执行某个代码段并且没有设置为忽略该信号,操作系统会在合适的时机(通常是在进程的上下文切换时)调用相应的信号处理程序。
- 上下文切换: 进程在执行期间,操作系统会定期进行上下文切换,以便响应其他进程的需求。在这个过程中,信号处理程序会被调用。
3. 信号的存储与记录
如果信号在进程执行期间到达,但该进程正在执行一个不允许处理信号的代码段(例如,系统调用或信号处理程序),该信号会被暂时记录下来。
- 信号队列: 操作系统通常会为每个进程维护一个信号队列,用于存储未处理的信号。
- 记录位置: 信号可以在进程的 PCB(进程控制块)中记录,PCB 中包含有关进程状态的信息,包括信号的待处理状态。
4. 进程对信号的预期处理
一个进程在没有收到信号时,无法主动知道自己应该如何处理合法信号。信号处理的逻辑通常在程序中显式定义。例如,程序开发者可以使用 signal 或 sigaction 函数注册处理程序,预先定义在接收到特定信号时的行为。
5. OS 向进程发送信号的过程
OS 向进程发送信号的完整过程如下:
-
信号生成: 当某个事件发生(例如,用户输入、定时器到期、进程间通信等),操作系统会生成一个信号。
-
信号发送: OS 通过内部机制将信号发送到目标进程。这可以是通过
kill、raise或其他系统调用。 -
信号接收:
- 如果目标进程正在运行,操作系统会检查该进程的信号处理设置。
- 如果该信号被阻塞,系统将其记录在进程的信号队列中。
-
信号处理:
- 当进程在合适的时机(即上下文切换或系统调用返回时)检查信号时,如果有待处理的信号,操作系统将调用相应的信号处理程序。
- 如果信号处理程序返回,进程将继续执行。
-
信号恢复: 完成信号处理后,操作系统会将进程的控制权恢复到原来的执行状态。
总结
信号是一种由操作系统管理的异步事件通知机制。尽管信号的产生和处理不是立即的,操作系统通过维护信号队列和上下文切换机制,确保信号能够在合适的时机被处理。进程不能主动知道自己应该如何处理信号,但可以通过注册信号处理程序来定义行为。整个信号发送和处理的过程是由操作系统精确管理的,以确保系统的稳定性和可靠性。
Core dump(核心转储)
Core dump(核心转储)是操作系统在程序崩溃或异常终止时生成的一种文件,包含了进程在崩溃时的内存状态和相关信息。它通常用于调试和分析程序错误。以下是关于 core dump 的详细介绍。
1. 什么是 Core Dump
- 定义: Core dump 是一个包含程序在崩溃时内存内容的文件,包括堆栈、寄存器、堆和数据段等信息。
- 目的: 通过分析 core dump 文件,开发者可以了解程序崩溃时的状态,有助于定位和修复错误。
2. 生成 Core Dump
- 条件: Core dump 通常在以下情况下生成:
- 程序遇到未处理的信号(如
SIGSEGV、SIGABRT等)。 - 程序运行时发生致命错误。
- 程序遇到未处理的信号(如
- 位置: 操作系统会将 core dump 文件生成在当前工作目录或指定目录,文件名通常为
core或以进程 ID 命名(如core.1234)。
3. 如何启用和禁用 Core Dump
-
启用 Core Dump: 在 Linux 系统中,可以使用
ulimit命令启用 core dump:ulimit -c unlimited # 允许生成无限大小的 core dump 文件 -
禁用 Core Dump: 如果希望禁用 core dump,可以设置为 0:
ulimit -c 0 # 禁止生成 core dump 文件
4. 分析 Core Dump
-
调试工具: 分析 core dump 文件通常使用
gdb(GNU Debugger)等调试工具。gdb <executable> core.1234 -
常见操作:
bt: 打印堆栈回溯,查看函数调用链。info registers: 查看寄存器状态。list: 查看崩溃时的源代码。
5. Core Dump 的内容
Core dump 文件通常包括以下信息:
- 进程的内存映像: 包含所有加载的库、变量、数据结构等。
- 寄存器状态: 包括程序计数器、栈指针和其他 CPU 寄存器的值。
- 信号信息: 导致崩溃的信号类型和状态。
6. Core Dump 的优缺点
-
优点:
- 有助于程序调试和错误定位。
- 可以记录程序崩溃时的详细状态。
-
缺点:
- 生成的文件可能会很大,导致存储空间不足。
- 可能泄露敏感数据(如密码、密钥等)。
7. 总结
Core dump 是一个强大的调试工具,能够提供程序崩溃时的详细信息。通过分析 core dump 文件,开发者可以快速定位问题并做出相应的修复。虽然有一定的缺点,但在调试复杂程序时,core dump 是非常有价值的资源。
阻塞信号
信号其他相关常见概念
实际执行信号的处理动作称为信号递达(Delivery)
信号从产生到递达之间的状态,称为信号未决(Pending)
进程可以选择阻塞 (Block )某个信号。
被阻塞的信号产生时将保持在未决状态,直到进程解除对此信号的阻塞,才执行递达的动作.。
注意阻塞和忽略是不同的,只要信号被阻塞就不会递达,而忽略是在递达之后可选的一种处理动作。
信号在内核中的表示
1. 信号的标志位
每个信号在内核中通常有两个主要的标志位:
- 阻塞标志 (Blocked):
- 表示信号是否被阻塞。若信号被阻塞,进程在信号到达时不会立即处理该信号。
- 未决标志 (Pending):
- 表示信号是否已经产生但尚未处理。只有当信号未被阻塞时,未决标志才会被清除。
2. 信号处理函数指针
每个信号还关联一个函数指针,指向处理该信号的处理程序。进程可以通过 signal 或 sigaction 系统调用来注册自己的信号处理程序。
3. 信号的产生和递达
当信号产生时,内核会执行以下操作:
-
设置未决标志:
- 内核在进程的 PCB 中设置相应信号的未决标志,表明该信号已产生。
-
未决信号的递达:
- 当信号到达时,内核检查信号的阻塞状态。
- 如果信号未被阻塞,内核会清除未决标志并调用相应的信号处理程序。
- 如果信号被阻塞,未决标志保持设置状态,信号不会递达。
4. 信号的处理
- SIGHUP:
- 若未被阻塞且未产生过,信号到达时会执行默认处理动作。
- SIGINT:
- 若信号产生但被阻塞,未决标志保持设置状态。在阻塞解除之前,信号不会递达,进程有机会改变处理动作。
- SIGQUIT:
- 如果信号未产生且被阻塞,一旦产生,信号的未决标志会被设置,并且处理动作为用户自定义函数(
sighandler)。
- 如果信号未产生且被阻塞,一旦产生,信号的未决标志会被设置,并且处理动作为用户自定义函数(
5. 多次产生信号的处理
对于信号产生的次数,POSIX.1 规定了以下行为:
-
常规信号:
- 在信号递达之前产生多次只计为一次。这意味着即使同一信号被多次产生,内核只会在解除阻塞后递达一次。
-
实时信号:
- 在信号递达之前产生多次,可以依次放在一个队列中。这个机制允许实时信号的处理更加灵活,并确保所有信号都能被处理。
sigset_t
每个信号只有一个bit的未决标志,非0即1,不记录该信号产生了多少次,阻塞标志也是这样表示的。 因此,未决和阻塞标志可以用相同的数据类型sigset_t来存储,sigset_t称为信号集,这个类型可以表示每个信号 的“有效”或“无效”状态,在阻塞信号集中“有效”和“无效”的含义是该信号是否被阻塞,而在未决信号集中“有 效”和“无效”的含义是该信号是否处于未决状态。 阻塞信号集也叫做当前进程的信号屏蔽字(Signal Mask),这里的“屏蔽”应该理解为阻塞而不是忽略。
信号集操作函数
sigset_t类型对于每种信号用一个bit表示“有效”或“无效”状态,至于这个类型内部如何存储这些bit则依赖于系统实现,从使用者的角度是不必关心的,使用者只能调用以下函数来操作sigset_ t变量,而不应该对它的内部数据做任何解释,比如用printf直接打印sigset_t变量是没有意义的
在 Unix 和 Linux 系统中,信号集操作函数用于管理和操作 sigset_t 类型的信号集合。
1. 初始化信号集
sigemptyset
-
原型:
int sigemptyset(sigset_t *set); -
功能: 将信号集
set初始化为空集合,即不包含任何信号。 -
返回值: 成功返回 0,失败返回 -1。
sigfillset
-
原型:
int sigfillset(sigset_t *set); -
功能: 将信号集
set初始化为全集合,即包含所有可用信号。 -
返回值: 成功返回 0,失败返回 -1。
2. 添加和删除信号
sigaddset
-
原型:
int sigaddset(sigset_t *set, int signum); -
功能: 将信号
signum添加到信号集set中。 -
返回值: 成功返回 0,失败返回 -1。
sigdelset
-
原型:
int sigdelset(sigset_t *set, int signum); -
功能: 从信号集
set中删除信号signum。 -
返回值: 成功返回 0,失败返回 -1。
3. 检查信号
sigismember
-
原型:
int sigismember(const sigset_t *set, int signum); -
功能: 检查信号
signum是否在信号集set中。 -
返回值: 如果信号在集合中,返回 1;如果不在,返回 0;出错时返回 -1。
4. 信号集的操作
sigprocmask
-
原型:
int sigprocmask(int how, const sigset_t *set, sigset_t *oldset); -
功能: 修改当前进程的信号屏蔽字(即阻塞信号的集合)。
how参数可以为:SIG_BLOCK: 将set中的信号添加到当前阻塞信号集中。SIG_UNBLOCK: 从当前阻塞信号集中移除set中的信号。SIG_SETMASK: 将当前阻塞信号集替换为set中的信号集合。
-
返回值: 成功返回 0,失败返回 -1。
sigpending
-
原型:
int sigpending(sigset_t *set); -
功能: 获取当前进程未决的信号,并将其存储在
set中。 -
返回值: 成功返回 0,失败返回 -1。
5. 示例代码
以下是一个简单的示例,展示了如何使用信号集操作函数
#include <stdio.h>
#include <signal.h>
#include <unistd.h>
void handler(int sig) {
printf("Caught signal: %d\n", sig);
}
int main() {
sigset_t set, oldset;
// 注册信号处理程序
signal(SIGINT, handler);
// 初始化信号集合
sigemptyset(&set);
sigaddset(&set, SIGINT);
// 阻塞 SIGINT
sigprocmask(SIG_BLOCK, &set, &oldset);
printf("SIGINT is blocked. Press Ctrl+C...\n");
sleep(5); // 等待 5 秒
// 解除阻塞
sigprocmask(SIG_UNBLOCK, &set, NULL);
printf("SIGINT is unblocked.\n");
// 等待信号
while (1) {
pause(); // 等待信号到达
}
return 0;
}
函数sigemptyset初始化set所指向的信号集,使其中所有信号的对应bit清零,表示该信号集不包含任何有效信号。
函数sigfillset初始化set所指向的信号集,使其中所有信号的对应bit置位,表示该信号集的有效信号包括系统支持的所有信号。
注意在使用sigset_ t类型的变量之前,一定要调用sigemptyset或sigfillset做初始化,使信号集处于确定的状态。初始化sigset_t变量之后就可以在调用sigaddset和sigdelset在该信号集中添加或删除某种有效信号。
这四个函数都是成功返回0,出错返回-1。sigismember是一个布尔函数,用于判断一个信号集的有效信号中是否包含某种信号,若包含则返回1,不包含则返回0,出错返回-1。
信号捕捉的实现机制
-
信号的基本概念:
- 信号是一种异步通知机制,用于通知进程发生了某种事件,例如用户按下 Ctrl+C、定时器到期、外部事件等。
- 每个信号都有其特定的编号和默认处理方式。
-
注册信号处理函数:
- 用户程序可以通过系统调用(如
signal()或sigaction())注册自定义的信号处理函数。这个函数将在信号到达时被调用。 - 例如:
void sighandler(int signo) { // 处理信号的代码 } signal(SIGQUIT, sighandler);
- 用户程序可以通过系统调用(如
-
信号递达:
- 当信号递达时,内核会记录这个信号,并在适当的时候通知目标进程。
- 如果进程当前处于用户空间执行(例如在
main()函数中),而此时发生中断或异常,内核会切换到内核态处理相应的中断。
-
上下文切换:
- 在中断处理完成后,内核需要决定如何返回用户态。
- 如果在返回之前检测到有信号(如
SIGQUIT),内核将不恢复原来的上下文,而是切换到用户注册的信号处理函数sighandler。
-
执行信号处理函数:
sighandler函数与main函数在不同的堆栈空间中执行,这意味着它们之间没有直接的调用关系。- 内核会保存当前上下文(如程序计数器、寄存器等),然后加载
sighandler的上下文。
-
返回流程:
sighandler函数执行完毕后,需要通过特殊的系统调用sigreturn返回。sigreturn会将之前保存的上下文恢复到main函数中,然后继续执行。
示例流程
假设我们有如下代码:
#include <stdio.h>
#include <stdlib.h>
#include <signal.h>
#include <unistd.h>
void sighandler(int signo) {
printf("Caught SIGQUIT!\n");
}
int main() {
signal(SIGQUIT, sighandler);
while (1) {
printf("Running...\n");
sleep(1);
}
return 0;
}
流程详细说明
-
初始化:
- 用户程序运行时,
signal(SIGQUIT, sighandler);注册了sighandler作为SIGQUIT信号的处理函数。
- 用户程序运行时,
-
运行中:
- 程序在
main()函数中循环打印 "Running..."。
- 程序在
-
信号到达:
- 用户按下 Ctrl+\(发送
SIGQUIT信号)时,内核捕捉到信号并记录下来。 - 当执行到下一个中断点(如系统调用或其他中断),内核会检查是否有待处理的信号。
- 用户按下 Ctrl+\(发送
-
处理信号:
- 如果检测到
SIGQUIT,内核不会继续执行main(),而是切换到sighandler。 sighandler在其自己的堆栈上执行,打印 "Caught SIGQUIT!"。
- 如果检测到
-
返回到用户态:
sighandler执行完后,返回时调用sigreturn,内核恢复保存的上下文。- 随后,控制权返回到
main()函数,程序继续运行。
注意事项
- 信号的异步性:信号处理是异步的,这意味着信号可能在任何时间到达。
- 重入性:信号处理函数应该是重入的,即在处理信号期间不应再发生同样的信号,可能会导致不一致状态。
- 信号安全:信号处理函数应只调用异步信号安全的函数,以避免潜在问题。
用户态到内核态的切换,以及内核态到用户态的切换是操作系统实现多任务和信号处理的核心机制。以下是这两种切换的具体时间、方式和实现过程:
用户态到内核态的切换
何时发生:
- 系统调用:程序请求操作系统提供服务(如文件操作、内存分配等)。
- 中断:外部硬件或定时器产生中断,通知CPU处理某些事件。
- 异常:程序执行过程中出现错误(如除零错误、缺页异常等)。
如何实现:
- 触发条件:当上述事件发生时,CPU检测到需要切换到内核态。
- 保存上下文:CPU保存当前进程的上下文(如寄存器、程序计数器等)。
- 切换到内核栈:CPU切换到内核态的栈。
- 执行内核代码:根据事件类型,调用相应的内核处理程序(如系统调用处理函数或中断处理程序)。
内核态到用户态的切换
何时发生:
- 系统调用返回:内核完成了系统调用的处理,准备将控制权返回给用户程序。
- 信号处理完成:内核处理完信号后,准备将控制权返回到用户态。
- 调度:进程调度时,内核选择一个新的用户进程执行。
如何实现:
- 恢复上下文:内核恢复先前保存的用户进程上下文(寄存器、程序计数器等)。
- 切换到用户栈:CPU切换回用户态的栈。
- 返回用户态:使用特定指令(如
iret或syscall)将控制权转移回用户程序,继续执行。
具体实现细节
用户态到内核态的实现
-
系统调用:
- 用户程序通过特定的指令(如
syscall或int 0x80)触发系统调用。 - CPU切换到内核态,进入内核空间执行相关的内核函数。
- 用户程序通过特定的指令(如
-
中断处理:
- 硬件产生中断信号(如I/O完成、定时器中断),CPU自动保存当前状态,切换到中断处理程序。
-
异常处理:
- CPU在执行指令时遇到异常,自动切换到内核态,执行异常处理程序。
内核态到用户态的实现
-
系统调用返回:
- 内核完成系统调用后,使用
syscall返回用户空间,恢复用户上下文。
- 内核完成系统调用后,使用
-
信号处理返回:
- 信号处理函数执行完毕后,通过
sigreturn系统调用恢复上下文,返回到原先的用户程序。
- 信号处理函数执行完毕后,通过
-
进程调度:
- 内核选择新的进程进行调度,保存当前进程的状态并恢复新进程的状态,切换到新进程的用户态。
小结
用户态与内核态之间的切换是操作系统实现多任务、信号处理和系统调用的关键。系统通过中断、异常和系统调用等机制实现这些切换,保证程序的高效运行和响应性。
信号捕捉的实现机制
-
信号的基本概念:
- 信号是一种异步通知机制,用于通知进程发生了某种事件,例如用户按下 Ctrl+C、定时器到期、外部事件等。
- 每个信号都有其特定的编号和默认处理方式。
-
注册信号处理函数:
- 用户程序可以通过系统调用(如
signal()或sigaction())注册自定义的信号处理函数。这个函数将在信号到达时被调用。 - 例如:
void sighandler(int signo) { // 处理信号的代码 } signal(SIGQUIT, sighandler);
- 用户程序可以通过系统调用(如
-
信号递达:
- 当信号递达时,内核会记录这个信号,并在适当的时候通知目标进程。
- 如果进程当前处于用户空间执行(例如在
main()函数中),而此时发生中断或异常,内核会切换到内核态处理相应的中断。
-
上下文切换:
- 在中断处理完成后,内核需要决定如何返回用户态。
- 如果在返回之前检测到有信号(如
SIGQUIT),内核将不恢复原来的上下文,而是切换到用户注册的信号处理函数sighandler。
-
执行信号处理函数:
sighandler函数与main函数在不同的堆栈空间中执行,这意味着它们之间没有直接的调用关系。- 内核会保存当前上下文(如程序计数器、寄存器等),然后加载
sighandler的上下文。
-
返回流程:
sighandler函数执行完毕后,需要通过特殊的系统调用sigreturn返回。sigreturn会将之前保存的上下文恢复到main函数中,然后继续执行。
示例流程
假设我们有如下代码:
#include <stdio.h>
#include <stdlib.h>
#include <signal.h>
#include <unistd.h>
void sighandler(int signo) {
printf("Caught SIGQUIT!\n");
}
int main() {
signal(SIGQUIT, sighandler);
while (1) {
printf("Running...\n");
sleep(1);
}
return 0;
}
流程详细说明
-
初始化:
- 用户程序运行时,
signal(SIGQUIT, sighandler);注册了sighandler作为SIGQUIT信号的处理函数。
- 用户程序运行时,
-
运行中:
- 程序在
main()函数中循环打印 "Running..."。
- 程序在
-
信号到达:
- 用户按下 Ctrl+\(发送
SIGQUIT信号)时,内核捕捉到信号并记录下来。 - 当执行到下一个中断点(如系统调用或其他中断),内核会检查是否有待处理的信号。
- 用户按下 Ctrl+\(发送
-
处理信号:
- 如果检测到
SIGQUIT,内核不会继续执行main(),而是切换到sighandler。 sighandler在其自己的堆栈上执行,打印 "Caught SIGQUIT!"。
- 如果检测到
-
返回到用户态:
sighandler执行完后,返回时调用sigreturn,内核恢复保存的上下文。- 随后,控制权返回到
main()函数,程序继续运行。
注意事项
- 信号的异步性:信号处理是异步的,这意味着信号可能在任何时间到达。
- 重入性:信号处理函数应该是重入的,即在处理信号期间不应再发生同样的信号,可能会导致不一致状态。
- 信号安全:信号处理函数应只调用异步信号安全的函数,以避免潜在问题。
信号捕捉的实现涉及用户态与内核态之间的切换。以下是用户态到内核态以及内核态到用户态的主要步骤和过程:
用户态到内核态的过程
-
信号的发送:
- 当信号发生(例如用户按下 Ctrl+C 或发送特定信号),内核会捕捉到这个信号。
-
上下文切换:
- 内核需要进行上下文切换,保存当前进程的状态(如程序计数器、寄存器、堆栈指针等)。
-
信号处理判断:
- 内核检查当前进程是否有注册的信号处理函数。
- 如果有,内核准备执行该信号处理函数;如果没有,可能采取默认处理(如终止进程)。
-
切换到信号处理函数:
- 内核设置新的堆栈指针,以便执行信号处理函数。
- 内核将控制权转移到用户定义的信号处理函数。
内核态到用户态的过程
-
执行信号处理函数:
- 用户定义的信号处理函数在用户态堆栈中执行。
-
函数返回:
- 当信号处理函数执行完毕后,通常会返回到内核态,通过调用特殊的系统调用
sigreturn。
- 当信号处理函数执行完毕后,通常会返回到内核态,通过调用特殊的系统调用
-
恢复上下文:
- 内核通过
sigreturn恢复之前保存的进程上下文(如程序计数器、寄存器等)。 - 这包括了进程的原始堆栈指针,以便返回到调用
signal或sigaction的位置。
- 内核通过
-
返回用户态:
- 最后,内核将控制权返回到用户进程,继续执行被中断的代码(如
main函数)。
- 最后,内核将控制权返回到用户进程,继续执行被中断的代码(如
总结
这两个过程确保了信号能够被及时捕捉和处理,同时又能在处理完信号后无缝返回到用户态的正常执行状态。这样的机制使得系统能够有效处理异步事件,保持程序的响应性。
用户态到内核态的切换,以及内核态到用户态的切换是操作系统实现多任务和信号处理的核心机制。以下是这两种切换的具体时间、方式和实现过程:
用户态到内核态的切换
何时发生:
- 系统调用:程序请求操作系统提供服务(如文件操作、内存分配等)。
- 中断:外部硬件或定时器产生中断,通知CPU处理某些事件。
- 异常:程序执行过程中出现错误(如除零错误、缺页异常等)。
如何实现:
- 触发条件:当上述事件发生时,CPU检测到需要切换到内核态。
- 保存上下文:CPU保存当前进程的上下文(如寄存器、程序计数器等)。
- 切换到内核栈:CPU切换到内核态的栈。
- 执行内核代码:根据事件类型,调用相应的内核处理程序(如系统调用处理函数或中断处理程序)。
内核态到用户态的切换
何时发生:
- 系统调用返回:内核完成了系统调用的处理,准备将控制权返回给用户程序。
- 信号处理完成:内核处理完信号后,准备将控制权返回到用户态。
- 调度:进程调度时,内核选择一个新的用户进程执行。
如何实现:
- 恢复上下文:内核恢复先前保存的用户进程上下文(寄存器、程序计数器等)。
- 切换到用户栈:CPU切换回用户态的栈。
- 返回用户态:使用特定指令(如
iret或syscall)将控制权转移回用户程序,继续执行。
具体实现细节
用户态到内核态的实现
-
系统调用:
- 用户程序通过特定的指令(如
syscall或int 0x80)触发系统调用。 - CPU切换到内核态,进入内核空间执行相关的内核函数。
- 用户程序通过特定的指令(如
-
中断处理:
- 硬件产生中断信号(如I/O完成、定时器中断),CPU自动保存当前状态,切换到中断处理程序。
-
异常处理:
- CPU在执行指令时遇到异常,自动切换到内核态,执行异常处理程序。
内核态到用户态的实现
-
系统调用返回:
- 内核完成系统调用后,使用
syscall返回用户空间,恢复用户上下文。
- 内核完成系统调用后,使用
-
信号处理返回:
- 信号处理函数执行完毕后,通过
sigreturn系统调用恢复上下文,返回到原先的用户程序。
- 信号处理函数执行完毕后,通过
-
进程调度:
- 内核选择新的进程进行调度,保存当前进程的状态并恢复新进程的状态,切换到新进程的用户态。
小结
用户态与内核态之间的切换是操作系统实现多任务、信号处理和系统调用的关键。系统通过中断、异常和系统调用等机制实现这些切换,保证程序的高效运行和响应性。
sigaction 函数
sigaction 函数是用于设置和获取信号处理动作的重要接口,允许程序控制如何响应特定信号。以下是对 sigaction 函数的详细解释,包括其使用方法、结构体、信号屏蔽字以及相关参数的说明。
sigaction 函数概述
函数原型
#include <signal.h>
int sigaction(int signo, const struct sigaction *act, struct sigaction *oact);
参数说明
signo:要处理的信号的编号(如SIGINT、SIGTERM等)。act:指向sigaction结构体的指针,用于指定新的信号处理动作。如果为NULL,则不修改信号处理动作。oact:指向sigaction结构体的指针,用于保存原来的信号处理动作。如果为NULL,则不保存原来的动作。
返回值
- 成功时返回
0,失败时返回-1,并设置errno以指示错误类型。
sigaction 结构体
sigaction 结构体定义如下:
struct sigaction {
void (*sa_handler)(int); // 信号处理函数指针
void (*sa_sigaction)(int, siginfo_t *, void *); // 实时信号处理函数指针
sigset_t sa_mask; // 在信号处理期间需要屏蔽的信号集合
int sa_flags; // 一些选项标志
// 可能还有其他实现相关的字段
};
信号处理
-
sa_handler:可以设置为:SIG_IGN:忽略该信号。SIG_DFL:执行系统默认动作。- 指向自定义处理函数的指针:用于捕捉信号的处理函数。
-
sa_sigaction:用于处理实时信号的函数,允许传递更多信息,如信号编号和其他上下文。 -
sa_mask:指定在信号处理函数执行期间需要被屏蔽的信号。可以通过sigemptyset和sigaddset等函数来操作信号集合。 -
sa_flags:设置处理选项,例如:SA_RESTART:保证在信号处理后恢复被信号中断的系统调用。SA_SIGINFO:使用sa_sigaction处理函数而非sa_handler。
信号屏蔽字
- 在信号处理函数被调用时,内核会自动将当前信号添加到进程的信号屏蔽字中,以防止该信号的再次发生影响当前的处理。
- 在处理函数返回时,原来的信号屏蔽字会自动恢复。
- 如果希望在处理某个信号时屏蔽其他信号,可以在
sa_mask中指定这些信号。
示例代码
下面是一个简单的示例,演示如何使用 sigaction 注册信号处理函数:
#include <stdio.h>
#include <stdlib.h>
#include <signal.h>
#include <unistd.h>
void handler(int signo) {
printf("Caught signal %d\n", signo);
}
int main() {
struct sigaction act, oact;
// 设置新的信号处理动作
act.sa_handler = handler; // 指定处理函数
sigemptyset(&act.sa_mask); // 初始化 sa_mask,默认不屏蔽信号
act.sa_flags = 0; // 设置标志为0
// 注册SIGINT信号的处理函数
if (sigaction(SIGINT, &act, &oact) == -1) {
perror("sigaction");
exit(EXIT_FAILURE);
}
// 主循环
while (1) {
printf("Waiting for signal...\n");
sleep(1);
}
return 0;
}
总结
sigaction 函数提供了一种灵活的方式来控制信号处理。通过配置 sigaction 结构体中的字段,用户可以选择如何响应特定信号、屏蔽其他信号,以及使用自定义的信号处理函数。这种机制使得程序能够更好地处理异步事件并保持稳定性。
可重入函数
可重入函数是指在多线程或中断环境中,可以被安全地多次调用的函数。也就是说,这种函数在被中断或被其他线程调用时,不会导致数据损坏或不一致的状态。
可重入函数的特征
-
无状态性:
可重入函数不依赖于静态或全局变量的状态。所有需要的信息应通过参数传递,并在函数内部处理。 -
不使用锁:
可重入函数通常不需要使用锁或其他同步机制来保护共享数据,避免了死锁和竞争条件。 -
无副作用:
函数在调用期间不会对外部环境产生副作用,也不会修改调用者的上下文。
可重入函数的实现
-
参数传递:
- 通过参数传递所有必要的数据,而不是依赖于全局或静态变量。
int add(int a, int b) { return a + b; // 使用参数而非全局变量 } -
局部变量:
- 使用局部变量而非全局变量,确保每次调用都有独立的状态。
int increment(int *value) { int temp = *value; // 读取参数 return temp + 1; // 不修改 *value } -
避免动态内存分配:
- 在可重入函数中避免使用
malloc或free,因为它们可能在多线程环境中导致不一致的状态。
- 在可重入函数中避免使用
示例
以下是一个简单的可重入函数示例:
#include <stdio.h>
int safe_add(int a, int b) {
return a + b; // 无全局状态,安全可重入
}
int main() {
int x = 5, y = 10;
printf("Sum: %d\n", safe_add(x, y)); // 输出: Sum: 15
return 0;
}
不可重入函数的示例
相对地,以下是一个不可重入函数的示例:
#include <stdio.h>
static int global_counter = 0;
int increment() {
return ++global_counter; // 使用全局变量,非线程安全
}
int main() {
printf("Counter: %d\n", increment()); // 输出: Counter: 1
printf("Counter: %d\n", increment()); // 输出: Counter: 2
return 0;
}
总结
可重入函数在多线程编程和信号处理等环境中非常重要。它们确保在并发执行时不会出现数据不一致或破坏的情况,通常通过局部状态和参数传递来实现这一点。设计可重入函数是编写高效和安全的并发程序的重要一步。
volatile
在 C 和 C++ 中,volatile 是一个类型修饰符,用于指示编译器某个变量的值可能会被程序以外的因素改变。这种因素可以包括硬件设备、信号处理程序或多线程环境中的其他线程。
使用场景
-
硬件寄存器:
- 当与硬件设备交互时,设备寄存器的值可能会在程序的控制之外改变。例如,读取传感器的值。
-
信号处理:
- 在信号处理程序中,可能会修改某个变量。如果该变量在主程序中使用,应该将其声明为
volatile,以确保编译器不对其进行优化。
- 在信号处理程序中,可能会修改某个变量。如果该变量在主程序中使用,应该将其声明为
-
多线程编程:
- 在线程间共享的变量如果可能被不同的线程修改,也应声明为
volatile。虽然volatile本身并不能替代互斥锁,但它可以防止编译器缓存该变量的值。
- 在线程间共享的变量如果可能被不同的线程修改,也应声明为
volatile 的效果
- 防止优化:当编译器遇到
volatile变量时,它会禁止对该变量的某些优化,例如:- 不会将其值存储在寄存器中,而是每次访问都从内存中读取。
- 不会对该变量进行重排序,因为它可能会被外部因素改变。
volatile 作用:保持内存的可见性,告知编译器,被该关键字修饰的变量,不允许被优化,对该变量 的任何操作,都必须在真实的内存中进行操作。
#include <stdio.h>
#include <signal.h>
#include <unistd.h>
volatile sig_atomic_t flag = 0; // 使用 volatile 确保在信号处理时的可见性 不会被编译器优化到寄存器
void handler(int sig) {
flag = 1; // 设置标志,表示信号已被处理
}
int main() {
struct sigaction sa;
sa.sa_handler = handler; // 设置处理函数
sigemptyset(&sa.sa_mask); // 初始化信号屏蔽字
sa.sa_flags = 0; // 没有特殊标志
sigaction(SIGINT, &sa, NULL); // 注册信号处理程序
while (!flag); // 持续循环,直到 flag 变为 1
write(STDOUT_FILENO, "process quit normal\n", 21); // 使用 write 输出
return 0;
}SIGCHLD信号
SIGCHLD 信号是 UNIX 和类 UNIX 系统中用于通知进程其子进程状态变化的信号。具体来说,当一个子进程终止或停止时,其父进程会收到 SIGCHLD 信号。
SIGCHLD 的作用
-
子进程终止:
当一个子进程正常退出(通过调用exit())或被信号终止时,父进程会收到SIGCHLD信号。这使得父进程可以知道其子进程的状态变化。 -
子进程停止:
当子进程被停止(例如通过SIGSTOP或SIGTSTP信号),父进程也会收到SIGCHLD。
处理 SIGCHLD 信号
父进程可以通过注册信号处理程序来处理 SIGCHLD 信号,以便在子进程状态变化时执行特定操作,如收集子进程的退出状态。
示例代码
以下是一个简单的示例,演示如何使用 SIGCHLD 信号:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <signal.h>
#include <sys/types.h>
#include <sys/wait.h>
void handler(int sig) {
// 处理子进程状态变化
while (1) {
pid_t pid = waitpid(-1, NULL, WNOHANG); // 非阻塞方式收集子进程状态
if (pid <= 0) {
break; // 没有更多的子进程,退出循环
}
printf("Child process %d terminated.\n", pid);
}
}
int main() {
struct sigaction sa;
sa.sa_handler = handler; // 设置信号处理函数
sigemptyset(&sa.sa_mask); // 初始化信号屏蔽字
sa.sa_flags = 0; // 设置标志为0
sigaction(SIGCHLD, &sa, NULL); // 注册 SIGCHLD 处理程序
// 创建子进程
for (int i = 0; i < 3; i++) {
if (fork() == 0) {
sleep(1); // 子进程执行某些操作
exit(0); // 子进程正常退出
}
}
// 主进程循环
while (1) {
printf("Parent process running...\n");
sleep(2);
}
return 0;
}
重要概念
-
非阻塞状态收集:
在处理SIGCHLD信号时,通常使用waitpid()函数来收集子进程的退出状态。使用WNOHANG标志可以确保waitpid是非阻塞的,不会导致父进程阻塞。 -
多次信号处理:
可能会收到多个SIGCHLD信号,因此在信号处理程序中应使用循环来处理所有子进程的状态变化。 -
避免僵尸进程:
通过及时调用wait()或waitpid(),可以避免僵尸进程的产生。僵尸进程是已经终止但仍占用系统资源的进程。
总结
SIGCHLD 信号提供了一种机制,使父进程能够响应子进程的状态变化。通过适当处理 SIGCHLD 信号,父进程可以有效地管理其子进程,避免僵尸进程的产生,并确保系统资源的有效利用。
用wait和waitpid函数清理僵尸进程,父进程可以阻塞等待子进程结束,也可以非阻塞地查询是否有子进 程结束等待清理(也就是轮询的方式)。采用第一种方式,父进程阻塞了就不 能处理自己的工作了;采用第二种方式,父进程在处理自己的工作的同时还要记得时不时地轮询一 下,程序实现复杂。
其实,子进程在终止时会给父进程发SIGCHLD信号,该信号的默认处理动作是忽略,父进程可以自 定义SIGCHLD信号 的处理函数,这样父进程只需专心处理自己的工作,不必关心子进程了,子进程 终止时会通知父进程,父进程在信号处理函数中调用wait清理子进程即可。
事实上,由于UNIX 的历史原因,要想不产生僵尸进程还有另外一种办法:父进程调用sigaction将SIGCHLD的处理动作置为SIG_IGN,这样fork出来的子进程在终止时会自动清理掉,不会产生僵尸进程,也不会通知父进程。系统默认的忽略动作和用户用sigaction函数自定义的忽略通常是没有区别的,但这是一个特例。此方法对于Linux可用,但不保证在其它UNIX系统上都可用。
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
#include <signal.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
void handler(int sig) {
pid_t id;
// 非阻塞方式收集子进程状态
while ((id = waitpid(-1, NULL, WNOHANG)) > 0) {
printf("wait child success: %d\n", id);
}
printf("child is quit! %d\n", getpid());
}
int main() {
signal(SIGCHLD, handler); // 注册 SIGCHLD 信号处理函数
pid_t cid;
if ((cid = fork()) == 0) { // 创建子进程
printf("child : %d\n", getpid());
sleep(3); // 模拟子进程工作
exit(1); // 子进程正常退出
}
while (1) { // 父进程循环
printf("father proc is doing some thing!\n");
sleep(1);
}
return 0;
}地址空间划分
将32位地址划分为10位、10位和12位的方式可以用作以下几种寻址方式:
- 页表寻址:
- 10位的第一部分可以用作页目录。
- 10位的第二部分可以用作页表索引。
- 12位的最后一部分用作页内偏移。
示例
假设有一个32位的地址 0x12345678,将其转换为二进制:
0001 0010 0011 0100 0101 0110 0111 1000
将其划分为三部分:
- 第一部分(10位):
0001001000(十进制为 72) - 第二部分(10位):
1101000101(十进制为 837) - 第三部分(12位):
011001110000(十进制为 1792)
计算示例
假设我们有这样的配置:
- 页大小:4096 字节(即 4KB),这意味着每一页可以容纳 4096 字节的数据。
- 页表大小:我们有 1024 个页表项,每个页表项指向一个页。
寻址过程
- 获取页目录:通过前 10 位(72),可以找到页目录中的第 72 项。
- 获取页表:通过中间 10 位(837),可以找到对应页目录项所指向的页表中的第 837 项。
- 获取偏移:最后 12 位(1792)则用来在该页内访问具体的字节。
线程
线程是操作系统中进程的一个重要组成部分,它是程序执行的基本单位。下面是关于线程的详细解释,包括其定义、特性、优缺点、以及应用场景。
1. 线程的定义
- 线程(Thread)是进程内部的一个执行流。一个进程可以包含一个或多个线程,这些线程共享进程的资源(如内存、文件句柄等)。
2. 线程的特性
- 轻量级:线程比进程更轻量,创建和销毁的开销较小。
- 共享资源:同一进程中的线程共享进程的地址空间和资源,这使得线程间的通信比进程间通信更高效。
- 上下文切换:线程间的上下文切换比进程间的切换更快,因为线程共享同一进程的资源。
3. 线程的优点
- 并发执行:多个线程可以并发执行,提高程序的响应性和性能。
- 资源共享:线程之间共享资源,减少了内存开销。
- 提高应用性能:在多核处理器上,多个线程可以真正并行执行,提高计算效率。
4. 线程的缺点
- 复杂性:多线程编程会增加程序的复杂性,容易出现竞争条件、死锁等问题。
- 调试困难:由于线程的非确定性,调试多线程程序相对困难。
- 资源竞争:多个线程同时访问共享资源可能导致数据不一致。
5. 线程的应用场景
- 用户界面:在图形用户界面(GUI)应用中,使用线程可以保持界面的响应性,同时进行后台处理。
- 网络服务器:Web 服务器通常使用多线程来处理多个客户请求,实现并发处理。
- 科学计算:在需要大量计算的应用中,利用多线程可以加速计算过程。
6. 线程的实现
在操作系统中,线程通常由操作系统的调度器进行管理。不同的编程语言和库提供了不同的线程实现方式,例如:
- POSIX 线程(pthreads):在 Unix/Linux 系统中广泛使用的线程库。
- Java 线程:Java 提供了内置的线程支持,通过
Thread类和Runnable接口来实现。 - C# 线程:C# 提供了
Thread类和Task类来处理多线程编程。
7. 示例代码
以下是一个简单的 C++ 线程示例,使用 std::thread 创建和运行线程:
#include <iostream>
#include <thread>
#include <windows.h>
void threadFunction()
{
while (true)
{
std::cout << "Hello from thread!" << std::endl;
Sleep(1000);
}
}
int main()
{
std::thread t(threadFunction); // 创建并启动线程
while (true)
{
std::cout << "Hello from main!" << std::endl;
Sleep(1000);
}
return 0;
}
ps -L
ps -L 是 Linux 和 Unix 系统中用于查看进程状态的命令之一。具体来说,ps 命令用于显示当前运行的进程,而 -L 选项则用于显示线程信息。以下是对该命令的详细解释。
ps -L 命令详解
ps:表示“process status”,用于显示当前系统的进程信息。-L:选项用于显示每个进程的线程信息。
使用示例
ps -L
输出说明
执行 ps -L 后,输出的列通常包括:
- PID:进程的ID。
- LWP:轻量级进程(即线程)的ID。
- NLWP:该进程中的线程数量。
- S:线程的状态(如运行、睡眠等)。
- TIME:线程使用的CPU时间。
- CMD:执行该线程的命令。
常见用途
- 查看线程信息:通过
ps -L,你可以查看某个进程内的所有线程。 - 性能分析:在进行性能监控时,查看线程的状态和使用的 CPU 时间有助于识别瓶颈。
- 调试:在调试多线程应用时,了解每个线程的状态可以帮助排查问题。
结合其他选项
ps -L 可以与其他选项结合使用,例如:
ps -eL:显示所有进程及其线程。ps -p <PID> -L:显示指定进程的线程信息。
示例
ps -eL
这将列出系统中所有进程的线程信息,输出可能如下所示:
PID LWP NLWP S TIME CMD
1234 1234 5 S 00:00:01 my_process
1234 1235 5 S 00:00:00 my_process
1234 1236 5 S 00:00:00 my_process
什么是线程
在一个程序里的一个执行路线就叫做线程(thread)。更准确的定义是:线程是“一个进程内部的控制序
列”
一切进程至少都有一个执行线程
线程在进程内部运行,本质是在进程地址空间内运行
在Linux系统中,在CPU眼中,看到的PCB都要比传统的进程更加轻量化
透过进程虚拟地址空间,可以看到进程的大部分资源,将进程资源合理分配给每个执行流,就形成了线程
执行流
线程的优点
创建一个新线程的代价要比创建一个新进程小得多
与进程之间的切换相比,线程之间的切换需要操作系统做的工作要少很多
线程占用的资源要比进程少很多
能充分利用多处理器的可并行数量
在等待慢速I/O操作结束的同时,程序可执行其他的计算任务
计算密集型应用,为了能在多处理器系统上运行,将计算分解到多个线程中实现
I/O密集型应用,为了提高性能,将I/O操作重叠。线程可以同时等待不同的I/O操作。
线程的缺点
性能损失
一个很少被外部事件阻塞的计算密集型线程往往无法与共它线程共享同一个处理器。如果计算密集型
线程的数量比可用的处理器多,那么可能会有较大的性能损失,这里的性能损失指的是增加了额外的
同步和调度开销,而可用的资源不变。
健壮性降低
编写多线程需要更全面更深入的考虑,在一个多线程程序里,因时间分配上的细微偏差或者因共享了
不该共享的变量而造成不良影响的可能性是很大的,换句话说线程之间是缺乏保护的。
缺乏访问控制
进程是访问控制的基本粒度,在一个线程中调用某些OS函数会对整个进程造成影响。
编程难度提高
编写与调试一个多线程程序比单线程程序困难得多
线程异常
单个线程如果出现除零,野指针问题导致线程崩溃,进程也会随着崩溃
线程是进程的执行分支,线程出异常,就类似进程出异常,进而触发信号机制,终止进程,进程终止,该
进程内的所有线程也就随即退出
线程用途
合理的使用多线程,能提高CPU密集型程序的执行效率
合理的使用多线程,能提高IO密集型程序的用户体验(如生活中我们一边写代码一边下载开发工具,就是
多线程运行的一种表现)
Linux进程VS线程
进程和线程
进程是资源分配的基本单位
线程是调度的基本单位
线程共享进程数据,但也拥有自己的一部分数据:
线程ID
一组寄存器
栈
errno
信号屏蔽字
调度优先级
进程的多个线程共享同一地址空间,因此Text Segment、Data Segment都是共享的,如果定义一个函数,在各线程中都可以调用,如果定义一个全局变量,在各线程中都可以访问到,除此之外,各线程还共享以下进程资源和环境:
文件描述符表
每种信号的处理方式(SIG_ IGN、SIG_ DFL或者自定义的信号处理函数)
当前工作目录
用户id和组id
Linux线程控制
POSIX线程库
与线程有关的函数构成了一个完整的系列,绝大多数函数的名字都是以“pthread_”打头的,要使用这些函数库,要通过引入头文<pthread.h>,链接这些线程函数库时要使用编译器命令的“-lpthread”选项。
创建线程
功能:创建一个新的线程
原型
int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *
(*start_routine)(void*), void *arg);
参数
thread:返回线程ID
attr:设置线程的属性,attr为NULL表示使用默认属性
start_routine:是个函数地址,线程启动后要执行的函数
arg:传给线程启动函数的参数
返回值:成功返回0;失败返回错误码
错误检查:
传统的一些函数是,成功返回0,失败返回-1,并且对全局变量errno赋值以指示错误。
pthreads函数出错时不会设置全局变量errno(而大部分其他POSIX函数会这样做)。而是将错误代码通
过返回值返回
pthreads同样也提供了线程内的errno变量,以支持其它使用errno的代码。对于pthreads函数的错误,
建议通过返回值业判定,因为读取返回值要比读取线程内的errno变量的开销更小#include <iostream>
#include <pthread.h>
#include <cassert>
#include <unistd.h>
using namespace std;
void *thread_routine(void *args)
{
const char *s = (const char *)args;
while (true)
{
cout << "我是新线程:" << s << endl;
sleep(1);
}
}
int main()
{
pthread_t tid;
int n = pthread_create(&tid, nullptr, thread_routine, (void *)"thread one");
assert(0 == n);
(void)n;
while (true)
{
cout << "我是主线程" << endl;
sleep(1);
}
return 0;
}
#pragma once
//.hpp 文件 header only 开源代码
#include <iostream>
#include <string>
#include <cstring>
#include <functional>
#include <pthread.h>
#include <cassert>
class Thread; // 声明类
// 上下文
class Context
{
public:
Thread *_this;
void *_args;
public:
Context() : _this(nullptr), _args(nullptr)
{
}
~Context() {}
};
class Thread
{
public:
// using func_t = std::function<void *(void *)>;
typedef std::function<void *(void *)> func_t;
const int NUM = 1024;
public:
Thread(func_t func, void *args, int number) : _func(func), _args(args)
{
// _name = "thread-";
// _name += std::to_string(number);
char buffer[NUM];
snprintf(buffer, sizeof buffer, "thread%d", number);
_name = buffer;
}
// 在类内创建函数,不要缺省参数this指针需要设置static因为static没有this指针
static void *start_routine(void *args) // 类内成员 有缺省参数this指针
{
// 静态方法不能调用成员方法或成员变量只能调用静态成员方法/变量
Context *ctx = static_cast<Context *>(args);
void *ret = ctx->_this->run(ctx->_args);
delete ctx;
return ret;
}
void start()
{
Context *ctx = new Context();
ctx->_this = this;
ctx->_args = _args;
int n = pthread_create(&_tid, nullptr, start_routine, ctx);
assert(0 == n);
(void)n;
}
void join()
{
int n = pthread_join(_tid, nullptr);
assert(0 == n);
(void)n;
}
void *run(void *args)
{
return _func(args);
}
~Thread()
{
}
private:
std::string _name;
func_t _func;
void *_args;
pthread_t _tid;
};
#include "Thread.hpp"
#include <unistd.h>
#include <memory>
void *thread_run(void *args)
{
std::string work_type = static_cast<const char *>(args);
while (true)
{
std::cout << "I am a new thread I am doing : " << work_type << std::endl;
sleep(1);
}
}
int main()
{
std::unique_ptr<Thread> thread(new Thread(thread_run, (void *)"hello_thread0", 0));
std::unique_ptr<Thread> thread1(new Thread(thread_run, (void *)"hello_thread1", 1));
std::unique_ptr<Thread> thread2(new Thread(thread_run, (void *)"hello_thread2", 2));
thread->start();
thread1->start();
thread2->start();
thread->join();
thread1->join();
thread2->join();
return 0;
}clone()
clone() 是 Linux 特有的系统调用,用于创建新线程或进程。与 fork() 不同,clone() 提供了更大的灵活性,允许你控制新进程或线程如何共享资源,如内存和文件描述符。
函数原型
#include <sched.h>
int clone(int flags, void *stack, int *ptid, int *ctid, unsigned long newtls);
参数详解
-
flags:- 控制新线程/进程如何共享资源的标志。常用的标志包括:
CLONE_VM:父进程和子进程共享同一内存空间。CLONE_FS:共享文件系统信息(如当前工作目录、文件系统信息)。CLONE_SIGHAND:共享信号处理程序。CLONE_THREAD:将新线程与父线程标识为同一线程组。CLONE_PARENT_SETTID:设置新线程的父线程 ID。CLONE_CHILD_CLEARTID:在新线程结束时清除子线程的 TID。CLONE_NEWNS:创建新的名字空间(用于容器化)。
- 控制新线程/进程如何共享资源的标志。常用的标志包括:
-
stack:- 指向新线程栈的指针。线程的栈通常需要在调用
clone()之前分配。栈指针应指向栈的顶部。
- 指向新线程栈的指针。线程的栈通常需要在调用
-
ptid:- 指向父线程 ID 的指针,通常用于存储父线程的 TID。可以设置为
NULL。
- 指向父线程 ID 的指针,通常用于存储父线程的 TID。可以设置为
-
ctid:- 指向子线程 ID 的指针,用于存储子线程的 TID。可以设置为
NULL。
- 指向子线程 ID 的指针,用于存储子线程的 TID。可以设置为
-
newtls:- 用于设置新线程的 TLS(线程局部存储),通常设置为
0。
- 用于设置新线程的 TLS(线程局部存储),通常设置为
返回值
- 成功时,返回新线程的 PID。
- 失败时,返回
-1,并设置errno以指示错误原因。
#include <iostream>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <sched.h>
#include <cstring>
#define STACK_SIZE (1024 * 1024) // 定义栈大小
// 线程函数
int thread_function(void* arg) {
for (int i = 0; i < 5; ++i) {
std::cout << "线程: " << static_cast<char*>(arg) << " 正在运行\n";
sleep(1); // 模拟一些工作
}
return 0; // 线程结束
}
int main() {
char* stack = new char[STACK_SIZE]; // 为线程分配栈
if (!stack) {
perror("无法分配栈");
return 1;
}
// 创建新线程
pid_t pid = clone(thread_function, stack + STACK_SIZE, SIGCHLD, (void*)"线程A");
if (pid == -1) {
perror("线程创建失败");
delete[] stack; // 清理分配的内存
return 1;
}
// 主线程也执行一些工作
for (int i = 0; i < 5; ++i) {
std::cout << "主线程正在运行\n";
sleep(1);
}
// 等待子线程结束
waitpid(pid, nullptr, 0);
std::cout << "主线程结束\n";
delete[] stack; // 清理分配的内存
return 0;
}vfork()
vfork() 是一个在 Unix/Linux 中用于创建新进程的系统调用。它与 fork() 类似,但在某些方面进行了优化,尤其是在内存使用和性能方面。以下是对 vfork() 的详细讲解。
函数原型
#include <unistd.h>
pid_t vfork(void);
主要特点
-
性能优化:
vfork()旨在提高性能,特别是在创建大量子进程时。它避免了在创建子进程时复制父进程的整个地址空间。 -
共享地址空间:
在vfork()之后,子进程与父进程共享相同的地址空间。这意味着子进程对内存的任何修改都会影响父进程。因此,子进程必须在执行exec()或exit()之前,不修改任何父进程的数据。 -
阻塞父进程:
当调用vfork()时,父进程会被阻塞,直到子进程调用exec()或exit()。这确保了在子进程完成其初始化之前,父进程不会继续执行,从而避免了潜在的竞争条件。
返回值
- 成功:返回新创建子进程的 PID。
- 失败:返回
-1,并设置errno以指示错误原因。
vfork() 和 fork() 是 Unix/Linux 系统中用于创建新进程的两个系统调用。虽然它们的功能相似,但在实现细节和行为上有一些重要区别。以下是它们的主要区别:
1. 地址空间共享
-
fork():- 创建一个新进程,并复制父进程的整个地址空间。父进程和子进程各自拥有独立的内存映像。
- 这意味着对子进程内存的任何修改不会影响父进程。
-
vfork():- 创建一个新进程,但不复制父进程的地址空间。子进程与父进程共享相同的内存空间。
- 子进程对内存的修改会直接影响父进程,因此子进程在执行期间不能修改父进程的变量。
2. 阻塞父进程
fork():- 父进程和子进程是独立的,父进程在调用
fork()后会继续执行,不会被阻塞。
- 父进程和子进程是独立的,父进程在调用
vfork():- 父进程会被阻塞,直到子进程调用
exec()或exit()。这确保了在子进程完成其初始化之前,父进程不会继续执行。
- 父进程会被阻塞,直到子进程调用
线程ID及进程地址空间布局
线程 ID
-
线程 ID (TID):
- 每个线程在创建时会被分配一个唯一的线程 ID(TID),这个 ID 通常是一个整数,用于区分同一进程中的不同线程。
- 在 POSIX 线程(pthread)库中,可以使用
pthread_t类型来表示线程 ID。 - 线程 ID 是在进程内部唯一的,但同一系统中不同进程的线程 ID 可以重复。
-
获取线程 ID:
- 在 POSIX 系统中,可以使用
pthread_self()函数获取当前线程的 ID。 - 示例:
pthread_t tid = pthread_self();
- 在 POSIX 系统中,可以使用
进程地址空间布局
进程地址空间通常分为几个主要部分:
-
代码段 (Text Segment):
存放程序的机器代码,是只读的。 -
数据段 (Data Segment):
存放已初始化的全局变量和静态变量。 -
BSS段 (Block Started by Symbol):
存放未初始化的全局变量和静态变量,通常在程序启动时被清零。 -
堆 (Heap):
动态分配内存的区域,通过malloc、new等函数进行管理。堆的大小可以在运行时动态变化。 -
栈 (Stack):
存放函数的局部变量、返回地址等信息。每个线程都有自己的栈空间,用于存储其局部变量和函数调用信息。 -
内核空间:
进程和线程的内核结构及其相关信息(如调度、状态等)存储在内核空间,但用户程序无法直接访问。
进程与线程的关系
-
进程:
- 进程是操作系统分配资源的基本单位,它拥有自己的地址空间、全局变量、堆、栈等。
- 进程间的通信通常需要借助 IPC(进程间通信)机制,如管道、消息队列、共享内存等。
-
线程:
- 线程是进程内的执行单位,多个线程共享同一个进程的地址空间,意味着它们可以直接访问进程中的全局变量和堆内存。
- 线程间的通信相对简单,因为它们共享同一块内存,但需要注意同步和互斥,以防止数据竞争。
示例:线程 ID 和地址空间
以下是一个简单的 C++ 示例,展示如何获取线程 ID 和理解地址空间:
#include <iostream>
#include <pthread.h>
#include <unistd.h>
void *thread_function(void *arg) {
pthread_t tid = pthread_self(); // 获取线程 ID
std::cout << "线程 ID: " << tid << " | 地址空间: " << &arg << std::endl;
return nullptr;
}
int main() {
pthread_t tid;
// 创建线程
pthread_create(&tid, nullptr, thread_function, nullptr);
// 等待线程结束
pthread_join(tid, nullptr);
std::cout << "主线程 ID: " << pthread_self() << std::endl;
return 0;
}
总结
- 线程 ID 是唯一标识一个线程的标识符,可以在同一进程中区分不同的线程。
- 进程地址空间 是由不同段组成的,每个线程在同一进程内共享这些地址空间的部分(如堆和全局变量),但每个线程有自己的栈空间。
pthread_t 到底是什么类型呢?取决于实现。对于Linux目前实现的NPTL实现而言,pthread_t类型的线程ID,本质就是一个进程地址空间上的一个地址。
pthread_t 是 POSIX 线程库中用于表示线程 ID 的数据类型。它的具体实现取决于操作系统和线程库。在 Linux 系统中,特别是使用 NPTL(Native POSIX Threads Library)实现的情况下,pthread_t 可以看作是一个与线程相关的标识符。
线程终止
如果需要只终止某个线程而不终止整个进程,可以有三种方法:
1. 从线程函数return。这种方法对主线程不适用,从main函数return相当于调用exit。
2. 线程可以调用pthread_ exit终止自己。
3. 一个线程可以调用pthread_ cancel终止同一进程中的另一个线程。
pthread_exit函数
函数原型
void pthread_exit(void *retval);
参数
retval:这是线程返回的值,可以是一个指向任意类型的指针。主线程或其他线程可以通过pthread_join函数获取这个值。
功能
pthread_exit会终止调用它的线程的执行,并可以返回一个值给等待该线程结束的其他线程。- 调用
pthread_exit后,线程会进入“终止”状态,但其占用的资源(如线程 ID 和堆栈)仍然保留,直到其他线程通过pthread_join收集其返回值并确认线程已结束。
使用场景
- 在线程函数中提前退出:当某个条件满足时,线程可以通过
pthread_exit提前退出,而不是直接返回。 - 在非主线程中返回值:通过
pthread_exit返回值,可以让主线程或其他线程获取到该值。
注意事项
-
避免资源泄漏:
在调用pthread_exit后,确保其他线程调用pthread_join,以回收资源。否则,线程将处于“类僵尸”状态,直到进程终止。 -
与
在线程函数中,可以使用return的关系:return语句直接返回,效果与调用pthread_exit相同。使用return时,返回值通常是通过pthread_join获取。 -
主线程的行为:
如果主线程调用pthread_exit,则整个进程会等待所有线程结束。因此,通常在主线程中使用pthread_exit可以确保其他线程有时间完成。 -
安全性:
在使用pthread_exit时,确保没有未处理的资源(如动态分配的内存)被泄漏。
需要注意,pthread_exit或者return返回的指针所指向的内存单元必须是全局的或者是用malloc分配的,不能在线程函数的栈上分配,因为当其它线程得到这个返回指针时线程函数已经退出了。
pthread_cancel函数
函数原型
int pthread_cancel(pthread_t thread);
参数
thread:要取消的目标线程的线程 ID,类型为pthread_t。
返回值
- 成功时,返回
0。 - 失败时,返回错误码,常见的错误码包括:
ESRCH:没有找到指定的线程。EINVAL:线程 ID 无效。
功能
pthread_cancel向指定的线程发送一个取消请求。被请求取消的线程会在下一个取消点检查是否收到了取消请求。- 如果线程在取消点处接收到取消请求,它会进行清理操作并终止执行。
取消点
- 线程只有在取消点处才会响应取消请求。可以在以下位置设置取消点:
- 调用
pthread_testcancel()函数。 - 调用某些线程库函数(如
pthread_join()、pthread_cond_wait()等)。
- 调用
线程等待 为什么需要线程等待?
已经退出的线程,其空间没有被释放,仍然在进程的地址空间内。
创建新的线程不会复用刚才退出线程的地址空间。
功能:等待线程结束
原型
int pthread_join(pthread_t thread, void **value_ptr);
参数
thread:线程ID
value_ptr:它指向一个指针,后者指向线程的返回值
返回值:成功返回0;失败返回错误码调用该函数的线程将挂起等待,直到id为thread的线程终止。thread线程以不同的方法终止,通过pthread_join得到的终止状态是不同的,总结如下:
1. 如果thread线程通过return返回,value_ ptr所指向的单元里存放的是thread线程函数的返回值。
2. 如果thread线程被别的线程调用pthread_ cancel异常终掉,value_ ptr所指向的单元里存放的是常数PTHREAD_ CANCELED。
3. 如果thread线程是自己调用pthread_exit终止的,value_ptr所指向的单元存放的是传给pthread_exit的参数。
4. 如果对thread线程的终止状态不感兴趣,可以传NULL给value_ ptr参数。
#include <iostream>
#include <pthread.h>
#include <unistd.h>
void* thread_function(void* arg) {
int thread_id = *(int*)arg;
std::cout << "线程 " << thread_id << " 正在运行..." << std::endl;
// 模拟工作
for (int i = 0; i < 5; ++i) {
std::cout << "线程 " << thread_id << " 工作中..." << std::endl;
sleep(1); // 模拟工作延迟
}
std::cout << "线程 " << thread_id << " 完成工作,正常退出。" << std::endl;
return nullptr; // 正常退出
}
void* cancelable_thread_function(void* arg) {
int thread_id = *(int*)arg;
std::cout << "可取消线程 " << thread_id << " 正在运行..." << std::endl;
// 循环工作,并在每次迭代中检查取消请求
while (true) {
std::cout << "可取消线程 " << thread_id << " 工作中..." << std::endl;
sleep(1);
// 检查是否有取消请求
pthread_testcancel(); // 这是一个取消点
}
return nullptr; // 不会到达这里
}
int main() {
pthread_t threads[3];
int thread_ids[3] = {1, 2, 3};
// 创建普通线程
for (int i = 0; i < 3; ++i) {
pthread_create(&threads[i], nullptr, thread_function, &thread_ids[i]);
}
// 创建可取消的线程
pthread_t cancelable_thread;
int cancelable_id = 4;
pthread_create(&cancelable_thread, nullptr, cancelable_thread_function, &cancelable_id);
// 等待普通线程完成
for (int i = 0; i < 3; ++i) {
pthread_join(threads[i], nullptr);
}
// 等待一段时间后取消可取消的线程
sleep(3);
std::cout << "请求取消可取消线程..." << std::endl;
pthread_cancel(cancelable_thread);
// 等待可取消线程结束
pthread_join(cancelable_thread, nullptr);
std::cout << "可取消线程已结束,主线程结束。" << std::endl;
return 0;
}线程分离
默认情况下,新创建的线程是joinable的,线程退出后,需要对其进行pthread_join操作,否则无法释放资源,从而造成系统泄漏。
如果不关心线程的返回值,join是一种负担,这个时候,我们可以告诉系统,当线程退出时,自动释放线程资源。
pthread_detach 是 POSIX 线程库中的一个函数,用于将一个线程设置为分离状态。在分离状态下,线程结束后占用的资源会自动释放,而不需要其他线程调用 pthread_join 来回收这些资源。
函数原型
int pthread_detach(pthread_t thread);
参数
thread:要设置为分离状态的线程的线程 ID,类型为pthread_t。
返回值
- 成功时返回
0。 - 失败时返回错误码,常见的错误码包括:
ESRCH:没有找到指定的线程。EINVAL:线程 ID 无效,或者该线程已经被分离。
使用场景
- 自动资源管理:适用于不需要等待线程结束的情况,避免手动管理线程的生命周期。
- 后台任务:适合用于执行一些后台任务的线程,这些任务完成后不需要通知主线程。
注意事项
- 不能重复分离:同一个线程只能分离一次,重复调用
pthread_detach会导致未定义行为。 - 无法获取返回值:分离线程结束后,无法通过
pthread_join获取其返回值,因为它不再需要被其他线程显式地等待。
可以是线程组内其他线程对目标线程进行分离,也可以是线程自己分离:
pthread_detach(pthread_self());joinable和分离是冲突的,一个线程不能既是joinable又是分离的。
线程局部存储
__thread 是 C 和 C++ 中用于声明线程局部存储(Thread Local Storage, TLS)的关键字。它允许每个线程都有自己独立的变量副本,这样一个线程对变量的修改不会影响其他线程中的该变量。
1. 使用 __thread
- 定义:在变量前加上
__thread关键字,可以使该变量成为线程局部存储。 - 作用:每个线程对这个变量的访问都是自己的副本,互不干扰。
2. 示例代码
以下是一个使用 __thread 的示例,展示了如何为每个线程创建独立的变量副本:
#include <iostream>
#include <pthread.h>
#include <unistd.h>
__thread int thread_local_var = 0; // 线程局部变量
void* thread_function(void* arg) {
int thread_id = *(int*)arg;
thread_local_var = thread_id; // 设置线程局部变量
std::cout << "线程 " << thread_id << " 的线程局部变量值: " << thread_local_var << std::endl;
sleep(1); // 模拟工作
std::cout << "线程 " << thread_id << " 结束,线程局部变量值: " << thread_local_var << std::endl;
return nullptr;
}
int main() {
pthread_t threads[3];
int thread_ids[3] = {1, 2, 3};
// 创建多个线程
for (int i = 0; i < 3; ++i) {
pthread_create(&threads[i], nullptr, thread_function, &thread_ids[i]);
}
// 等待线程结束
for (int i = 0; i < 3; ++i) {
pthread_join(threads[i], nullptr);
}
return 0;
}
3. 代码解释
- 定义线程局部变量:使用
__thread int thread_local_var = 0;定义一个线程局部变量。 - 线程函数:每个线程在执行时会设置自己的
thread_local_var值,并打印出来。 - 主线程:创建多个线程并等待它们完成。
4. 注意事项
- 编译器支持:
__thread关键字是 GCC 和一些其他编译器的扩展,确保你的编译器支持它。 - C++11 的替代方案:在 C++11 及更高版本中,使用
thread_local关键字来定义线程局部存储,更加标准化。
5. C++11 示例
在 C++11 中,你可以使用 thread_local 进行相同的操作:
#include <iostream>
#include <thread>
thread_local int thread_local_var = 0; // 线程局部变量
void thread_function(int id) {
thread_local_var = id; // 设置线程局部变量
std::cout << "线程 " << id << " 的线程局部变量值: " << thread_local_var << std::endl;
}
int main() {
std::thread threads[3];
// 创建多个线程
for (int i = 0; i < 3; ++i) {
threads[i] = std::thread(thread_function, i + 1);
}
// 等待线程结束
for (auto& t : threads) {
t.join();
}
return 0;
}
总结
__thread和thread_local关键字用于创建线程局部存储,确保每个线程都有独立的变量副本。- 适用于需要在多线程环境中维护线程特定数据的场景。
Linux线程互斥
在 Linux 中,线程互斥是通过使用互斥锁(mutex)来实现的。这种机制可以防止多个线程同时访问共享资源,从而避免数据竞争和不一致性。
1. 互斥锁的基本概念
- 互斥锁(Mutex):互斥锁是一种同步原语,确保在同一时刻只有一个线程可以访问特定资源。
- 锁定和解锁:线程在访问共享资源之前必须先锁定互斥锁,访问完成后必须解锁。
2. 使用互斥锁的步骤
- 初始化互斥锁:使用
pthread_mutex_init初始化互斥锁。 - 锁定互斥锁:在访问共享资源之前调用
pthread_mutex_lock。 - 解锁互斥锁:在完成对共享资源的访问后调用
pthread_mutex_unlock。 - 销毁互斥锁(可选):在不再需要时调用
pthread_mutex_destroy。
4. 关键点
- 锁定和解锁:在访问共享资源前后分别调用
pthread_mutex_lock和pthread_mutex_unlock。 - 避免死锁:在复杂的多线程程序中,确保以相同的顺序锁定多个互斥锁,以避免死锁。
- 性能考虑:互斥锁会引入一定的性能开销,尽量减少锁的持有时间。
适当使用读写锁(pthread_rwlock_t)可以允许多个线程进行读取操作,提高性能。 -
锁的粒度:锁的粒度(即锁定的资源范围)对性能有重要影响。粒度越小,线程并发性越高,但锁的管理可能更复杂。
5. 其他同步机制
除了互斥锁,Linux 还提供了其他同步机制,例如:
- 读写锁(Read-Write Locks):允许多个线程同时读取,但写入时需独占锁。
- 条件变量(Condition Variables):用于线程之间的通知和等待机制。
- 信号量(Semaphores):用于控制对共享资源的访问。
进程线程间的互斥相关背景概念
临界资源:多线程执行流共享的资源就叫做临界资源
临界区:每个线程内部,访问临界资源的代码,就叫做临界区
互斥:任何时刻,互斥保证有且只有一个执行流进入临界区,访问临界资源,通常对临界资源起保护作用
原子性:不会被任何调度机制打断的操作,该操作只有两态,要么完成,要么未完成互斥锁的使用
2.1 初始化互斥锁
使用 pthread_mutex_init 函数初始化互斥锁:
pthread_mutex_t mutex;
pthread_mutex_init(&mutex, nullptr); // 或者使用 PTHREAD_MUTEX_INITIALIZER
2.2 锁定和解锁
在访问共享资源时,使用 pthread_mutex_lock 和 pthread_mutex_unlock:
pthread_mutex_lock(&mutex); // 锁定
// 访问共享资源
pthread_mutex_unlock(&mutex); // 解锁
2.3 销毁互斥锁
当不再需要互斥锁时,使用 pthread_mutex_destroy 进行销毁:
pthread_mutex_destroy(&mutex);
互斥量mutex
大部分情况,线程使用的数据都是局部变量,变量的地址空间在线程栈空间内,这种情况,变量归属单个
线程,其他线程无法直接获得这种变量。
但有时候,很多变量都需要在线程间共享,这样的变量称为共享变量,可以通过数据的共享,完成线程之
间的交互。
多个线程并发的操作共享变量,会带来一些问题。多线程中的数据竞争
1. 争取结果的原因
1.1 数据竞争
在多线程环境中,如果多个线程同时访问共享变量而没有适当的同步机制,就会发生数据竞争。这种情况下,结果可能不可预测,因为多个线程可能会同时读取和写入共享变量。
1.2 非原子操作
例如,ticket-- 操作不是一个原子操作。它实际上由三条汇编指令组成:
- 加载(load):将
ticket的值从内存加载到寄存器。 - 更新(update):在寄存器中执行减 1 操作。
- 存储(store):将更新后的值写回到
ticket的内存地址。
由于这三条指令不是原子执行的,如果在执行过程中上下文切换到其他线程,可能导致多个线程读取和更新 ticket,从而导致最终结果不准确。
1.3 代码切换
在判断条件为真后,代码可以并发的切换到其他线程,导致在此期间其他线程也进入临界区并操作共享变量。
2. 解决方案
为了确保线程安全和正确的结果,需要实现互斥行为,具体要求如下:
2.1 互斥行为
当代码进入临界区执行时,不允许其他线程进入该临界区。可以通过使用互斥量来实现这一点。
2.2 线程访问控制
如果多个线程同时请求执行临界区的代码,而该临界区没有其他线程在执行,那么只能允许一个线程进入。互斥量的锁定和解锁机制可以保证这一点。
2.3 非临界区线程的自由
如果线程不在临界区中执行,那么该线程不能阻止其他线程进入临界区。互斥量的使用可以确保只有持有锁的线程才能访问临界区。
要做到这三点,本质上就是需要一把锁。Linux上提供的这把锁叫互斥量。
互斥量的初始化方法
2.1 静态分配
使用静态分配方法时,可以在声明互斥量的同时进行初始化。示例代码如下:
#include <pthread.h>
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER; // 静态初始化
这种方法简单且直接,适用于全局或静态范围的互斥量。
2.2 动态分配
动态分配方法使用 pthread_mutex_init 函数进行初始化。其函数原型如下:
int pthread_mutex_init(pthread_mutex_t *restrict mutex, const pthread_mutexattr_t *restrict attr);
参数说明
- mutex:指向要初始化的互斥量的指针。
- attr:互斥量的属性指针,通常为
NULL,表示使用默认属性。
返回值
- 返回 0:表示成功。
- 返回非零值:表示错误,通常可以通过
errno获取错误类型。
互斥量的销毁
1. 函数原型
销毁互斥量使用的函数是:
int pthread_mutex_destroy(pthread_mutex_t *mutex);
参数
- mutex:指向要销毁的互斥量的指针。
返回值
- 返回 0:表示成功。
- 返回非零值:表示错误,通常可以通过
errno获取错误类型。
2. 注意事项
在销毁互斥量时,需要遵循以下注意事项:
2.1 初始化方式
-
静态初始化:使用
PTHREAD_MUTEX_INITIALIZER初始化的互斥量不需要销毁。这是因为它在程序的生命周期内存在,系统会自动处理其生命周期。pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER; // 不需要销毁 -
动态初始化:使用
pthread_mutex_init动态初始化的互斥量需要调用pthread_mutex_destroy来销毁。
2.2 锁定状态
- 未解锁的互斥量:在销毁之前,确保该互斥量没有被任何线程锁定。如果尝试销毁一个已经加锁的互斥量,可能会导致未定义的行为或程序崩溃。
2.3 避免重复销毁
- 确保在销毁互斥量后,不会有其他线程尝试再次加锁或解锁该互斥量。对已销毁的互斥量进行操作也会导致未定义行为。
互斥量的加锁和解锁
1.1 加锁
加锁使用的函数是:
int pthread_mutex_lock(pthread_mutex_t *mutex);
返回值
- 成功时返回 0。
- 失败时返回错误号,常见的错误包括:
EDEADLK:尝试对同一线程加锁(死锁)。EINVAL:传入的互斥量无效。
行为
- 如果互斥量处于未锁状态,
pthread_mutex_lock会将其锁定,并返回成功。 - 如果互斥量已被其他线程锁定,当前线程将被阻塞,直到互斥量解锁为止。
1.2 解锁
解锁使用的函数是:
int pthread_mutex_unlock(pthread_mutex_t *mutex);
返回值
- 成功时返回 0。
- 失败时返回错误号,常见的错误包括:
EPERM:当前线程未持有该互斥量。
行为
- 当前持有锁的线程调用
pthread_mutex_unlock将解锁互斥量,使其他等待该互斥量的线程得以继续执行。
2. 注意事项
2.1 锁定状态
- 在调用
pthread_mutex_unlock之前,确保当前线程已经成功加锁该互斥量。 - 不要对未加锁的互斥量进行解锁,这将导致未定义行为。
2.2 死锁
- 如果同一线程尝试多次加锁同一互斥量,而没有解锁,将导致死锁。使用
pthread_mutex_trylock可避免此问题,但它不会阻塞线程。
2.3 互斥量的性质
- 互斥量通常是非递归的,即同一线程只能加锁一次。如果需要递归锁,可以使用
pthread_mutexattr_settype设置互斥量属性为递归类型。
原子性与数据一致性
1.1 非原子操作的问题
在多线程环境中,简单的自增操作(如 i++ 或 ++i)并不是原子的。这意味着在这些操作的执行过程中,可能会发生线程切换,从而导致数据一致性问题。例如,两个线程同时读取和更新同一变量 i,可能导致最终的值不正确。
1.2 原子操作的定义
原子操作是指在多个线程并发执行时,某个操作要么完全执行,要么完全不执行,无法被中断。这保证了在操作执行期间,其他线程无法访问或修改相关的数据。
2. 使用 swap 或 exchange 指令
2.1 硬件支持
许多现代处理器架构提供了 swap 或 exchange 指令。这些指令的作用是将寄存器的值与内存单元的数据交换,保证了该操作的原子性。即使在多处理器平台上,这些指令也能确保在执行期间,其他处理器的相关操作会被阻塞。
可重入与线程安全
线程安全
线程安全是指在多个线程并发执行同一段代码时,不会产生不同的结果。这通常涉及对共享资源(如全局变量或静态变量)的访问。在没有适当的同步机制(如锁)的情况下,多个线程同时访问共享变量可能导致数据不一致。
可重入
可重入是指同一个函数在不同执行流中被调用时,当前调用尚未完成时,另一个执行流可以再次进入该函数,而不会产生任何不一致的结果。可重入函数在被重入的情况下,结果是可预测的;否则,该函数被视为不可重入。
常见的线程不安全的情况
- 不保护共享变量的函数:直接操作全局变量或静态变量而未使用锁。
- 状态变化的函数:函数内部状态依赖于调用次数或条件,可能因并发执行而产生不一致。
- 返回指向静态变量的指针:静态变量在多个调用中共享,导致数据不一致。
- 调用线程不安全函数的函数:在安全函数中调用不安全的外部函数。
常见的线程安全的情况
- 只读权限:多个线程仅对全局变量或静态变量进行读取,不进行写入。
- 原子操作:类或接口的操作是原子的。
- 确定性结果:多个线程切换不会导致接口执行结果的二义性。
常见的不可重入的情况
- 使用
malloc/free函数:因为malloc使用全局链表管理堆,可能导致状态不一致。 - 调用标准 I/O 函数:许多标准 I/O 函数使用全局数据结构,导致不可重入。
- 使用静态数据结构:可重入函数体内使用静态数据结构会导致状态共享。
常见的可重入的情况
- 不使用全局或静态变量:避免共享状态。
- 不使用动态内存:不调用
malloc或new。 - 不调用不可重入函数:避免引入不可重入的外部依赖。
- 不返回静态或全局数据:所有数据由调用者提供。
- 使用本地数据:确保数据局部化,或通过制作全局数据的本地拷贝来保护全局数据。
可重入与线程安全的联系
- 可重入函数是线程安全的:如果一个函数是可重入的,意味着它可以安全地被多个线程并发调用。
- 不可重入函数不适合多线程使用:如果一个函数不可重入,它在多线程环境中可能引发线程安全问题。
- 全局变量的影响:如果一个函数依赖全局变量,它既不是线程安全的,也不是可重入的。
可重入与线程安全的区别
- 可重入函数是线程安全函数的一种:但是并不是所有线程安全的函数都是可重入的。
- 线程安全不等于可重入:线程安全的函数通过适当的锁机制保护资源,但如果函数在持有锁的情况下被重入,可能导致死锁,使其不可重入。
死锁
死锁是指在一组进程中的各个进程均占有不会释放的资源,但因互相申请被其他进程所站用不会释放的资 源而处于的一种永久等待状态。
死锁四个必要条件
互斥条件:一个资源每次只能被一个执行流使用
请求与保持条件:一个执行流因请求资源而阻塞时,对已获得的资源保持不放
不剥夺条件:一个执行流已获得的资源,在末使用完之前,不能强行剥夺
循环等待条件:若干执行流之间形成一种头尾相接的循环等待资源的关系
避免死锁
破坏死锁的四个必要条件
加锁顺序一致
避免锁未释放的场景
资源一次性分配
Linux线程同步
条件变量
条件变量是一种重要的线程同步机制,允许线程在某些条件未满足时进入等待状态,从而有效地协调多个线程之间的操作。
在多线程编程中,线程可能会在访问共享资源时发现某些条件不满足,比如一个线程在访问一个共享队列时,如果发现队列为空,它就无法继续处理。这时,条件变量可以帮助线程进行协调,让它在条件满足时被唤醒。
关键点
- 互斥访问:条件变量通常与互斥锁结合使用,以确保访问共享资源的线程之间是互斥的。
- 等待与唤醒:线程可以在条件变量上等待,直到另一个线程发出信号(唤醒)表示条件已改变。
同步:在保证数据安全的前提下,让线程能够按照某种特定的顺序访问临界资源,从而有效避免饥饿问题,叫做同步
竞态条件:由于多线程的执行顺序不确定,导致程序的结果依赖于执行的时序,从而可能引发异常或不一致的状态。
条件变量的基本操作
2.1 初始化
在使用条件变量之前,首先需要初始化它:
pthread_cond_t cond;
pthread_cond_init(&cond, NULL);
2.2 等待条件
当线程需要等待某个条件时,它会调用 pthread_cond_wait() 函数:
pthread_cond_wait(&cond, &mutex);
- 参数:
cond:条件变量。mutex:与条件变量关联的互斥量。调用此函数时,互斥量必须是锁定状态。
调用 pthread_cond_wait() 时,线程会自动释放互斥锁并进入等待状态,直到被其他线程唤醒。
2.3 唤醒等待的线程
当条件改变时,其他线程可以调用 pthread_cond_signal() 或 pthread_cond_broadcast() 来唤醒等待的线程:
pthread_cond_signal(&cond); // 唤醒一个等待的线程
pthread_cond_broadcast(&cond); // 唤醒所有等待的线程
2.4 销毁条件变量
在不再需要条件变量时,应该销毁它:
pthread_cond_destroy(&cond);
pthread_cond_wait 的工作原理
当线程调用 pthread_cond_wait(&cond, &mutex) 时,操作流程如下:
- 锁定互斥量:调用线程必须首先锁定互斥量,以确保对共享资源的安全访问。
- 检查条件:线程检查条件是否满足。如果条件不满足,线程会进入等待状态。
- 释放互斥量:在进入等待状态之前,
pthread_cond_wait会自动释放互斥量。这允许其他线程在此时访问共享资源。 - 被唤醒:当其他线程通过
pthread_cond_signal或pthread_cond_broadcast唤醒等待的线程时,线程会再次获取互斥量,然后继续执行。
条件变量使用规范
1. 等待条件的代码
pthread_mutex_lock(&mutex);
while (条件为假) {
pthread_cond_wait(&cond, &mutex); // 线程等待条件
}
// 继续处理条件为真的逻辑
pthread_mutex_unlock(&mutex);
- 锁定互斥量:在检查条件之前,首先锁定互斥量以确保对共享资源的安全访问。
- 检查条件:使用
while循环检查条件是否为真。使用while而非if是为了防止虚假唤醒(即,不相关的唤醒导致线程继续执行)。 - 进入等待状态:如果条件为假,调用
pthread_cond_wait,该函数会自动释放互斥量并使线程进入等待状态。 - 条件满足后继续:当条件满足后,线程再次获取互斥量,然后继续执行。
2. 修改条件并发送信号的代码
pthread_mutex_lock(&mutex);
// 设置条件为真
条件 = true; // 修改共享条件
pthread_cond_signal(&cond); // 唤醒一个等待的线程
pthread_mutex_unlock(&mutex);
- 锁定互斥量:同样,首先要锁定互斥量,以确保在修改条件时不会有其他线程干扰。
- 修改条件:设置条件为真,表示条件已改变。
- 发送信号:调用
pthread_cond_signal唤醒一个等待该条件的线程(如果有的话)。 - 解锁互斥量:完成后解锁互斥量,以允许其他线程访问共享资源。
生产者消费者模型
生产者-消费者模型是一个经典的多线程设计模式,适用于处理多线程之间的任务协调问题。该模型的基本思想是将生产者和消费者分离,允许它们在不同的步调下运行,并使用缓冲区来存储数据。
1. 模型概述
1.1 角色
- 生产者:负责生成数据、任务或产品,并将其放入缓冲区。
- 消费者:从缓冲区中取出数据、任务或产品进行处理。
- 缓冲区:共享存储区域,用于存放生产者生成的产品和消费者处理的产品。
1.2 问题
- 缓冲区满:如果生产者试图在缓冲区已满时放入新产品,则需要等待。
- 缓冲区空:如果消费者试图从缓冲区中取出产品时发现缓冲区为空,则需要等待。
为何要使用生产者消费者模型
生产者消费者模式就是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。这个阻塞队列就是用来给生产者和消费者解耦的。
生产者消费者模型优点:解耦 ,支持并发, 支持忙闲不均
基于BlockingQueue的生产者消费者模型
BlockingQueue 在多线程编程中阻塞队列(Blocking Queue)是一种常用于实现生产者和消费者模型的数据结构。其与普通的队列区别在于,当队列为空时,从队列获取元素的操作将会被阻塞,直到队列中被放入了元素;当队列满时,往队列里存放元素的操作也会被阻塞,直到有元素被从队列中取出(以上的操作都是基于不同的线程来说的,线程在对阻塞队列进程操作时会被阻塞)
#include <iostream>
#include <queue>
#include <cstdlib>
#include <pthread.h>
#include <ctime>
#include <unistd.h> // for sleep
#define NUM 8 // 缓冲区的最大容量
// 定义一个线程安全的阻塞队列类
class BlockQueue
{
private:
std::queue<int> q; // 存储数据的队列
int cap; // 队列的最大容量
pthread_mutex_t lock; // 互斥锁,保护对队列的访问
pthread_cond_t full; // 条件变量,用于表示队列满
pthread_cond_t empty; // 条件变量,用于表示队列空
public:
// 构造函数,初始化队列和条件变量
BlockQueue(int _cap = NUM) : cap(_cap)
{
pthread_mutex_init(&lock, NULL); // 初始化互斥锁
pthread_cond_init(&full, NULL); // 初始化条件变量:队列满
pthread_cond_init(&empty, NULL); // 初始化条件变量:队列空
}
// 向队列中插入数据
void PushData(const int& data)
{
pthread_mutex_lock(&lock); // 锁定队列以保证线程安全
while (q.size() == cap)
{ // 如果队列已满
pthread_cond_signal(&empty); // 通知消费者
pthread_cond_wait(&full, &lock); // 等待直到队列有空间
}
q.push(data); // 将数据插入队列
pthread_cond_signal(&empty); // 通知消费者有新数据可用
pthread_mutex_unlock(&lock); // 解锁队列
}
// 从队列中取出数据
void PopData(int& data)
{
pthread_mutex_lock(&lock); // 锁定队列以保证线程安全
while (q.empty())
{ // 如果队列为空
pthread_cond_signal(&full); // 通知生产者
pthread_cond_wait(&empty, &lock); // 等待直到队列有数据
}
data = q.front(); // 获取队列头部的数据
q.pop(); // 移除头部数据
pthread_cond_signal(&full); // 通知生产者队列有空间可用
pthread_mutex_unlock(&lock); // 解锁队列
}
// 析构函数,清理资源
~BlockQueue()
{
pthread_mutex_destroy(&lock); // 销毁互斥锁
pthread_cond_destroy(&full); // 销毁条件变量:队列满
pthread_cond_destroy(&empty); // 销毁条件变量:队列空
}
};
// 消费者线程函数
void* consumer(void* arg)
{
BlockQueue* bqp = (BlockQueue*)arg; // 将参数转换为 BlockQueue 指针
int data;
while (true)
{ // 无限循环,持续消费数据
bqp->PopData(data); // 从队列中取出数据
std::cout << "Consumed: " << data << std::endl; // 输出消费的数据
sleep(1); // 模拟处理时间
}
}
// 生产者线程函数
void* producer(void* arg)
{
BlockQueue* bqp = (BlockQueue*)arg; // 将参数转换为 BlockQueue 指针
srand((unsigned long)time(NULL)); // 初始化随机数生成器
while (true)
{ // 无限循环,持续生产数据
int data = rand() % 1024; // 生成随机数据
bqp->PushData(data); // 将数据推送到队列
std::cout << "Produced: " << data << std::endl; // 输出生产的数据
sleep(1); // 模拟生产时间
}
}
int main()
{
BlockQueue bq; // 创建 BlockingQueue 实例
pthread_t c, p; // 声明消费者和生产者线程变量
pthread_create(&c, NULL, consumer, (void*)&bq); // 创建消费者线程
pthread_create(&p, NULL, producer, (void*)&bq); // 创建生产者线程
pthread_join(c, NULL); // 等待消费者线程结束
pthread_join(p, NULL); // 等待生产者线程结束
return 0; // 程序结束
}POSIX信号量
POSIX 信号量是一种用于多线程或多进程之间同步和互斥的机制。它们可以有效地控制对共享资源的访问,防止竞争条件。信号量可以是计数信号量或者二进制信号量。
1. 信号量的基本概念
- 计数信号量:可以取任意非负整数值,表示可用资源的数量。它允许多个线程同时访问共享资源。
- 二进制信号量:类似于互斥锁,只能取 0 或 1 值,通常用于实现互斥访问。
2. 信号量的主要操作
-
初始化:
sem_init():初始化信号量。sem_destroy():销毁信号量。
-
等待操作:
sem_wait():对信号量进行等待,当信号量的值大于 0 时,递减其值并继续执行;否则,阻塞当前线程。
-
释放操作:
sem_post():对信号量进行释放,增加其值并唤醒等待的线程。
POSIX信号量和SystemV信号量作用相同,都是用于同步操作,达到无冲突的访问共享资源目的。 但POSIX可以用于线程间同步。
POSIX 信号量操作
<semaphore.h>:包含 POSIX 信号量的相关函数和数据结构。<pthread.h>:包含 POSIX 线程的相关函数和数据结构。
-
初始化信号量
#include <semaphore.h>// POSIX 信号量的定义和操作 int sem_init(sem_t *sem, int pshared, unsigned int value);-
参数:
sem: 指向信号量的指针。pshared:0表示信号量在线程间共享(适用于多线程)。- 非零值表示信号量在进程间共享(适用于多进程)。
value: 信号量的初始值,通常是可用资源的数量。
-
返回值:成功返回
0,失败返回-1。
-
-
销毁信号量
int sem_destroy(sem_t *sem);- 参数:
sem: 指向要销毁的信号量的指针。
- 返回值:成功返回
0,失败返回-1。在销毁信号量之前,确保没有线程在等待该信号量。
- 参数:
-
等待信号量
int sem_wait(sem_t *sem); // P()-
功能:等待信号量。若信号量值大于0,则将其减1并继续执行;若信号量值为0,则阻塞当前线程,直到信号量值大于0。
-
返回值:成功返回
0,失败返回-1。
-
-
发布信号量
int sem_post(sem_t *sem); // V()-
功能:发布信号量,表示资源已使用完毕,可以归还资源。信号量值加1,若有线程在等待该信号量,则唤醒其中一个线程。
-
返回值:成功返回
0,失败返回-1。
-
基于环形队列的生产消费模型
基于环形队列的生产者-消费者模型是一种高效的方式,用于管理生产者和消费者之间的同步和互斥。环形队列(Circular Queue)能够有效利用内存,并且在队列满或空时可以阻塞生产者或消费者。
环形队列采用数组模拟,用模运算来模拟环状特性。
环形结构起始状态和结束状态都是一样的,不好判断为空或者为满,所以可以通过加计数器或者标记位来判断满或者空。另外也可以预留一个空的位置,作为满的状态。
#include <iostream>
#include <vector>
#include <cstdlib>
#include <semaphore.h>
#include <pthread.h>
#include <ctime>
#include <unistd.h> // for sleep
#define NUM 16 // 环形队列的大小
class RingQueue
{
private:
std::vector<int> q; // 存储数据的动态数组
int cap; // 队列容量
sem_t data_sem; // 表示数据的信号量
sem_t space_sem; // 表示空位的信号量
int consume_step; // 消费者索引
int product_step; // 生产者索引
public:
// 构造函数
RingQueue(int _cap = NUM) : q(_cap), cap(_cap), consume_step(0), product_step(0)
{
sem_init(&data_sem, 0, 0); // 初始化数据信号量
sem_init(&space_sem, 0, cap); // 初始化空位信号量
}
// 入队
void PutData(const int &data)
{
sem_wait(&space_sem); // 等待空位
q[consume_step] = data; // 放入数据
consume_step++;
consume_step %= cap; // 更新消费者指针
sem_post(&data_sem); // 增加数据信号量
}
// 出队
void GetData(int &data)
{
sem_wait(&data_sem); // 等待数据
data = q[product_step]; // 获取数据
product_step++;
product_step %= cap; // 更新生产者指针
sem_post(&space_sem); // 增加空位信号量
}
// 析构函数
~RingQueue()
{
sem_destroy(&data_sem); // 销毁数据信号量
sem_destroy(&space_sem); // 销毁空位信号量
}
};
// 消费者线程函数
void *consumer(void *arg)
{
RingQueue *rqp = (RingQueue *)arg; // 将参数转换为 RingQueue 指针
int data;
while (true)
{
rqp->GetData(data); // 从队列中获取数据
std::cout << "Consume data done: " << data << std::endl;
sleep(1); // 模拟处理时间
}
}
// 生产者线程函数
void *producer(void *arg)
{
RingQueue *rqp = (RingQueue *)arg; // 将参数转换为 RingQueue 指针
srand((unsigned long)time(NULL)); // 初始化随机种子
while (true)
{
int data = rand() % 1024; // 生成随机数据
rqp->PutData(data); // 将数据放入队列
std::cout << "Produce data done: " << data << std::endl;
// sleep(1); // 可以取消注释以控制生产速度
}
}
int main()
{
RingQueue rq; // 创建环形队列实例
pthread_t c, p; // 声明消费者和生产者线程变量
// 创建消费者线程
pthread_create(&c, NULL, consumer, (void *)&rq);
// 创建生产者线程
pthread_create(&p, NULL, producer, (void *)&rq);
// 等待线程结束
pthread_join(c, NULL);
pthread_join(p, NULL);
return 0; // 程序结束
}线程池
线程池是一种用于管理和复用线程的设计模式,旨在提高程序的性能和资源利用率。通过预先创建一定数量的线程,线程池可以减少频繁创建和销毁线程带来的开销。以下是线程池的基本概念、实现步骤以及示例代码。
线程池的基本概念
- 线程复用:线程池中的线程可以被多个任务复用,而不需要为每个任务创建新的线程。
- 任务队列:线程池通常使用一个任务队列来管理待处理的任务。任务被放入队列中,线程从队列中获取任务并执行。
- 控制线程数量:线程池可以限制并发线程的数量,从而避免系统资源的过度消耗。
线程池的实现步骤
- 定义任务类型:可以使用函数指针、
std::function或者其他可调用对象来表示任务。 - 创建线程类:实现一个线程类,用于封装线程的创建、启动和管理。
- 实现线程池类:
- 包括线程管理、任务队列和同步机制(如互斥锁和条件变量)。
- 提供添加任务和启动线程的方法。
- 优雅停止:提供机制来安全地停止线程池,确保所有任务完成后再退出。
线程池: 一种线程使用模式。线程过多会带来调度开销,进而影响缓存局部性和整体性能。而线程池维护着多个线程,等待着监督管理者分配可并发执行的任务。这避免了在处理短时间任务时创建与销毁线程的代价。线程池不仅能够保证内核的充分利用,还能防止过分调度。可用线程数量应该取决于可用的并发处理器、处理器内核、内存、网络sockets等的数量。
线程池的应用场景:
1. 需要大量的线程来完成任务,且完成任务的时间比较短。 WEB服务器完成网页请求这样的任务,使用线程池技术是非常合适的。因为单个任务小,而任务数量巨大,你可以想象一个热门网站的点击次数。 但对于长时间的任务,比如一个Telnet连接请求,线程池的优点就不明显了。因为Telnet会话时间比线程的创建时间大多了。 2. 对性能要求苛刻的应用,比如要求服务器迅速响应客户请求。
3. 接受突发性的大量请求,但不至于使服务器宕机,因此产生大量线程的应用。突发性大量客户请求,在没有线程池情况下,将产生大量线程,虽然理论上大部分操作系统线程数目最大值不是问题,但短时间内产生大量线程可能使内存到达极限,从而出现错误。
线程池的种类:
固定大小线程池:
线程数量在创建时就固定,适用于任务负载相对稳定的场景。
优点:资源利用率高,避免频繁的线程创建与销毁开销。
示例:Web 服务器处理请求时,使用固定数量的线程来处理并发请求。
动态大小线程池:
根据当前的任务负载动态调整线程数量。
优点:能够应对突发的高负载情况,自动增加线程数以处理更多任务。
示例:在线购物网站在促销期间增加处理订单的线程数。
缓存线程池:
允许创建新线程来处理任务,空闲线程会被销毁。
优点:适合短时间内大量任务的场景,能快速响应任务需求。
示例:后台任务处理系统,任务量波动较大。
单线程池:
只有一个线程,适合任务执行顺序要求严格的场景。
优点:简单,避免并发问题。
示例:日志记录系统,确保日志记录顺序一致。
定时任务线程池:
支持定时执行任务,通常用于调度任务。
示例:定期执行数据库备份或清理任务。
线程池示例:
1. 创建固定数量线程池,循环从任务队列中获取任务对象,
2. 获取到任务对象后,执行任务对象中的任务接口
线程池的示例代码
#pragma once
#include <iostream>
#include <vector>
#include <queue>
#include <pthread.h>
#include <functional>
#include <unistd.h>
template <class T>
class ThreadPool
{
private:
std::vector<pthread_t> _threads; // 线程数组
std::queue<T> _task_queue; // 任务队列
pthread_mutex_t _mutex; // 互斥锁
pthread_cond_t _cond; // 条件变量
bool _stop; // 停止标志
int _num; // 线程数量
// 线程处理函数
static void* handlerTask(void* args)
{
ThreadPool* pool = static_cast<ThreadPool*>(args);
while (true)
{
T task;
{
pthread_mutex_lock(&pool->_mutex); // 加锁
while (pool->_task_queue.empty() && !pool->_stop)
{
pthread_cond_wait(&pool->_cond, &pool->_mutex); // 等待任务
}
if (pool->_stop)
{
pthread_mutex_unlock(&pool->_mutex);
return nullptr; // 停止线程
}
task = pool->_task_queue.front();
pool->_task_queue.pop();
pthread_mutex_unlock(&pool->_mutex); // 解锁
}
// 执行任务
task();
}
return nullptr;
}
public:
ThreadPool(int num = 5) : _num(num), _stop(false)
{
pthread_mutex_init(&_mutex, nullptr);
pthread_cond_init(&_cond, nullptr);
_threads.resize(_num);
for (int i = 0; i < _num; i++)
{
pthread_create(&_threads[i], nullptr, handlerTask, this); // 创建线程
}
}
void addTask(const T& task)
{
{
pthread_mutex_lock(&_mutex);
_task_queue.push(task); // 添加任务
}
pthread_cond_signal(&_cond); // 通知一个线程有新任务
}
void stop()
{
{
pthread_mutex_lock(&_mutex);
_stop = true; // 设置停止标志
}
pthread_cond_broadcast(&_cond); // 唤醒所有线程
}
~ThreadPool()
{
stop(); // 停止线程池
for (auto& thread : _threads)
{
pthread_join(thread, nullptr); // 等待线程结束
}
pthread_mutex_destroy(&_mutex);
pthread_cond_destroy(&_cond);
}
};代码说明
-
线程池类
ThreadPool:- 维护一个线程数组和一个任务队列。
- 使用互斥锁和条件变量来确保线程安全。
- 线程通过
handlerTask方法处理任务。
-
任务添加:
使用addTask方法将任务添加到队列,并通知空闲线程执行任务。 -
线程停止:
stop方法设置停止标志并唤醒所有线程,确保它们可以安全退出。
线程安全的单例模式
什么是单例模式
单例模式(Singleton Pattern)是一种设计模式,确保一个类只有一个实例,并提供一个全局访问点。
单例模式的特点
- 唯一性:整个应用程序中只有一个实例存在。
- 全局访问:提供一个静态方法,可以在任何地方访问该实例。
- 延迟初始化:实例在第一次被请求时创建,避免不必要的资源消耗。
适用场景
- 全局配置:如应用程序的配置设置。
- 共享资源:如线程池、数据库连接池等。
- 日志记录:用于写日志的单一入口。
单例模式的实现方式
- 懒汉式:在第一次使用时创建实例,通常需要处理线程安全。
- 饿汉式:在类加载时就创建实例,线程安全,但可能浪费资源。
- 线程安全的懒汉式:使用锁机制确保线程安全。
- 局部静态变量:利用 C++11 的特性,局部静态变量会在第一次调用时初始化,线程安全。
饿汉实现方式和懒汉实现方式
1. 饿汉式(Eager Initialization)
特点:
- 在类加载时就创建实例,确保在调用之前已经初始化。
- 线程安全,因为实例在类加载时就创建。
优点:
- 实现简单,线程安全。
- 不需要加锁,性能较高。
缺点:
- 可能会浪费资源:即使在程序中没有使用单例实例,也会在启动时创建。
代码示例:
#include <iostream>
class Singleton {
private:
static Singleton* instance;
// 私有构造函数
Singleton() {
std::cout << "Singleton created." << std::endl;
}
public:
// 获取实例的静态方法
static Singleton* getInstance() {
return instance; // 直接返回已初始化的实例
}
// 禁止拷贝构造和赋值
Singleton(const Singleton&) = delete;
Singleton& operator=(const Singleton&) = delete;
};
// 初始化静态成员
Singleton* Singleton::instance = new Singleton();
int main() {
Singleton* s1 = Singleton::getInstance();
Singleton* s2 = Singleton::getInstance();
std::cout << "Addresses: " << s1 << ", " << s2 << std::endl; // 应该相同
return 0;
}
2. 懒汉式(Lazy Initialization)
特点:
- 只有在第一次使用时才创建实例,延迟了实例的创建。
优点:
- 节省资源:只有在需要时才创建实例。
缺点:
- 需要处理线程安全问题,如果在多线程环境中不加锁,可能会创建多个实例。
代码示例(不安全版本):
#include <iostream>
class Singleton {
private:
static Singleton* instance;
// 私有构造函数
Singleton() {
std::cout << "Singleton created." << std::endl;
}
public:
// 获取实例的静态方法
static Singleton* getInstance() {
if (instance == nullptr) {
instance = new Singleton(); // 创建实例
}
return instance;
}
// 禁止拷贝构造和赋值
Singleton(const Singleton&) = delete;
Singleton& operator=(const Singleton&) = delete;
};
// 初始化静态成员
Singleton* Singleton::instance = nullptr;
int main() {
Singleton* s1 = Singleton::getInstance();
Singleton* s2 = Singleton::getInstance();
std::cout << "Addresses: " << s1 << ", " << s2 << std::endl; // 应该相同
return 0;
}
代码示例(线程安全版本):
#include <iostream>
#include <mutex>
class Singleton {
private:
static Singleton* instance;
static std::mutex mtx; // 互斥锁
// 私有构造函数
Singleton() {
std::cout << "Singleton created." << std::endl;
}
public:
// 获取实例的静态方法
static Singleton* getInstance() {
if (instance == nullptr) {
std::lock_guard<std::mutex> lock(mtx); // 加锁
if (instance == nullptr) {
instance = new Singleton(); // 创建实例
}
}
return instance;
}
// 禁止拷贝构造和赋值
Singleton(const Singleton&) = delete;
Singleton& operator=(const Singleton&) = delete;
};
// 初始化静态成员
Singleton* Singleton::instance = nullptr;
std::mutex Singleton::mtx;
int main() {
Singleton* s1 = Singleton::getInstance();
Singleton* s2 = Singleton::getInstance();
std::cout << "Addresses: " << s1 << ", " << s2 << std::endl; // 应该相同
return 0;
}
线程安全的懒汉式单例模式,使用了双重检查锁定和 volatile 关键字。
#include <iostream>
#include <mutex>
template <typename T>
class Singleton {
private:
volatile static T* inst; // 需要设置 volatile 关键字,防止编译器优化
static std::mutex lock; // 互斥锁
public:
static T* GetInstance() {
if (inst == nullptr) { // 第一次检查
lock.lock(); // 加锁
if (inst == nullptr) { // 第二次检查
inst = new T(); // 创建实例
}
lock.unlock(); // 解锁
}
return inst; // 返回实例
}
};
// 静态成员初始化
template <typename T>
T* Singleton<T>::inst = nullptr;
template <typename T>
std::mutex Singleton<T>::lock;
// 测试代码
class MyClass {
public:
MyClass() {
std::cout << "MyClass created." << std::endl;
}
};
int main() {
MyClass* obj1 = Singleton<MyClass>::GetInstance();
MyClass* obj2 = Singleton<MyClass>::GetInstance();
std::cout << "Addresses: " << obj1 << ", " << obj2 << std::endl; // 应该相同
return 0;
}
关键点说明
-
volatile关键字:volatile关键字用于告诉编译器不要对这个变量进行优化。这样可以确保每次访问inst时,都会从内存中读取最新的值,而不是使用缓存的值。这在多线程环境中特别重要,避免了某些情况下的错误。 -
互斥锁:
std::mutex用于确保在多线程情况下对inst的安全访问。加锁和解锁保证了在创建实例时不会有其他线程同时执行。 -
双重检查锁定:
- 第一次检查
inst是否为nullptr是在加锁之前,这样可以避免在inst已经被初始化的情况下每次调用GetInstance()都进行加锁,从而提高性能。 - 第二次检查是在加锁之后,确保在锁定状态下再次确认
inst是否为nullptr,以避免多个线程同时创建实例。
- 第一次检查
-
注意事项:
在使用lock.unlock()之前,可以考虑使用std::lock_guard来自动管理锁的释放,避免因异常或提前退出导致死锁。
总结
- 饿汉式适合于实例创建相对简单且在程序启动时就需要使用的情况。
- 懒汉式适合于需要延迟加载的情况,但要注意线程安全的问题,可以通过加锁来解决。选择哪种实现方式取决于具体的应用场景和需求。
STL,智能指针和线程安全
STL 容器的线程安全性
-
线程安全性:
STL 容器 不是线程安全的。多个线程同时访问同一个容器可能导致数据竞争和未定义行为。 -
原因:
- STL 的设计目标是性能优化。为了实现高效的操作,STL 容器在设计时没有内置线程安全机制,因为加锁会显著降低性能。
- 不同容器的加锁机制也可能不同,例如哈希表可能需要对整个表加锁,而某些实现可能只对桶加锁。
-
调用者的责任:
在多线程环境中使用 STL 容器时,开发者需要自行实现线程安全机制,通常通过互斥锁(如std::mutex)来保护对容器的访问。
智能指针的线程安全性
-
std::unique_ptr:std::unique_ptr是线程安全的,因为它的设计确保了每个unique_ptr只能有一个所有者,无法被复制或共享。因此,不涉及共享资源的问题。 -
std::shared_ptr:std::shared_ptr支持多个指针共享同一个对象,引用计数用于管理对象的生命周期。在多线程环境中,引用计数的增减操作是线程安全的。STL 的实现通常使用原子操作(如 CAS,Compare and Swap)来确保引用计数的操作是原子的,从而避免数据竞争。
总结
- STL 容器:默认情况下不支持线程安全,开发者需自行保证线程安全。
- 智能指针:
std::unique_ptr是线程安全的,适用于独占所有权的情况。std::shared_ptr具有线程安全的引用计数机制,但在访问共享对象时仍需额外的同步措施。
其他常见的各种锁
悲观锁
- 定义:悲观锁是一种假设数据会被其他线程修改的锁机制。在访问数据之前,线程总是首先加锁。
- 特点:
- 阻塞:当一个线程持有锁时,其他线程必须等待。
- 适用场景:适用于高冲突的多线程环境,确保数据一致性。
- 类型:
- 读锁:允许多个线程同时读取,但不允许写入。
- 写锁:独占访问,其他线程无法读取或写入。
乐观锁
- 定义:乐观锁是一种假设数据不会被其他线程修改的锁机制。线程在更新数据之前不会加锁,而是在更新时进行检查。
- 特点:
- 非阻塞:线程在读取数据时不加锁,通常不会导致阻塞。
- 适用场景:适合读多写少的场景,增加并发性。
- 主要机制:
- 版本号机制:每次修改数据时更新版本号,更新时检查版本号是否匹配。
- CAS(Compare and Swap)操作:
- 通过原子操作检查当前值与之前值是否相等。
- 如果相等,则更新为新值;如果不等,则更新失败,通常会重试。
CAS(Compare and Swap)操作
- 定义:一种原子操作,用于实现乐观锁。
- 工作原理:
- 读取当前内存值和之前的值。
- 如果当前值与之前的值相等,则更新为新值。
- 如果不相等,则更新失败,通常需要重试。
- 优点:避免了使用传统锁的开销,提高了并发性能。
自旋锁
- 定义:自旋锁是一种轻量级的锁机制,线程在获取锁时会忙等待(自旋),而不是被挂起。
- 特点:
- 高效:适用于加锁时间非常短的场景,避免了上下文切换的开销。
- 缺点:如果锁持有时间较长,可能导致 CPU 时间浪费。
在 POSIX 线程库中,pthread_spinlock_t 提供了自旋锁的实现。以下是有关 pthread_spin_lock 的基本信息和使用示例。
1. 自旋锁的定义
自旋锁的类型通常定义为:
#include <pthread.h>
pthread_spinlock_t spinlock;
2. 初始化自旋锁
在使用自旋锁之前,需要进行初始化:
int pthread_spin_init(pthread_spinlock_t *lock, int pshared);
lock:指向要初始化的自旋锁。pshared:如果设置为0,则锁只能在同一进程的线程之间共享;如果设置为非零值,则可以在不同进程之间共享(需要使用共享内存)。
3. 加锁和解锁
-
加锁:
int pthread_spin_lock(pthread_spinlock_t *lock);- 线程尝试获取自旋锁,如果锁已被占用,线程会自旋等待。
-
解锁:
int pthread_spin_unlock(pthread_spinlock_t *lock);- 释放自旋锁。
4. 销毁自旋锁
在不再使用自旋锁时,需要销毁它:
int pthread_spin_destroy(pthread_spinlock_t *lock);
使用示例
公平锁与非公平锁
-
公平锁:
- 定义:公平锁确保按照请求锁的顺序来分配锁。
- 特点:
- 防止饥饿:所有线程都有机会获取锁,按照请求顺序。
- 可能导致性能下降,因为需要维护队列。
-
非公平锁:
- 定义:非公平锁不保证线程请求锁的顺序,可能导致某些线程长时间得不到锁。
- 特点:
- 提高了性能,减少了管理锁请求的开销。
- 可能导致某些线程饥饿,但在高冲突情况下往往表现更好。
总结
- 悲观锁适用于高冲突场景,确保数据一致性,但可能导致性能下降。
- 乐观锁适用于读多写少的场景,通过版本检查和 CAS 操作提高并发性。
- 自旋锁适合短时间锁定的场景,避免了线程挂起的开销。
- 公平锁和非公平锁提供了不同的锁争用策略,选择取决于应用场景的需求。
读者写者问题
读写锁
读写锁是一种特殊的同步机制,用于解决读者写者问题。它允许多个线程同时读取共享数据,但在写入时必须独占访问。这样可以提高系统的并发性能,特别是在读取操作远多于写入操作的场景中。
读写锁的基本概念
- 读锁(Shared Lock):允许多个线程同时获得读锁,从而并发读取同一资源。
- 写锁(Exclusive Lock):只允许一个线程获得写锁,其他线程(无论是读线程还是写线程)在写锁持有时都无法访问资源。
读写锁的优势
- 提高并发性:允许多个读者同时访问共享资源,减少了因独占锁而造成的性能瓶颈。
- 高效处理读多写少的场景:在大多数情况下,读操作比写操作频繁,读写锁能够有效提高性能。
读写锁的工作原理
-
读锁(Shared Lock):
- 允许多个线程同时获取读锁,读取共享数据。
- 当至少有一个线程持有读锁时,写锁将被阻塞。
-
写锁(Exclusive Lock):
- 允许只有一个线程获取写锁,进行写操作。
- 当一个线程持有写锁时,其他任何线程(无论是读还是写)都不能访问共享数据。
使用场景
- 高读低写:当你的应用程序中读操作的频率远高于写操作时,读写锁能够显著提高性能。
- 长时间读取:如果读取操作耗时较长,使用读锁可以避免在读取期间阻塞其他读者。
注意:写独占,读共享,读锁优先级高
读写锁接口
1. 设置读写优先级
int pthread_rwlockattr_setkind_np(pthread_rwlockattr_t *attr, int pref);
- 参数:
attr:指向读写锁属性对象的指针。pref:优先级设置,可以取以下值:PTHREAD_RWLOCK_PREFER_READER_NP:默认设置,读者优先,可能导致写者饥饿。PTHREAD_RWLOCK_PREFER_WRITER_NP:写者优先,但目前存在 bug,表现行为与读者优先一致。PTHREAD_RWLOCK_PREFER_WRITER_NONRECURSIVE_NP:写者优先,但写者不能递归加锁。
2. 初始化读写锁
int pthread_rwlock_init(pthread_rwlock_t *restrict rwlock, const pthread_rwlockattr_t *restrict attr);
- 参数:
rwlock:指向要初始化的读写锁的指针。attr:指向读写锁属性的指针,通常可以为NULL。
3. 销毁读写锁
int pthread_rwlock_destroy(pthread_rwlock_t *rwlock);
- 参数:
rwlock:指向要销毁的读写锁的指针。
4. 加锁
- 获取读锁:
int pthread_rwlock_rdlock(pthread_rwlock_t *rwlock);
- 获取写锁:
int pthread_rwlock_wrlock(pthread_rwlock_t *rwlock);
- 参数:
rwlock:指向读写锁的指针。
5. 解锁
int pthread_rwlock_unlock(pthread_rwlock_t *rwlock);
- 参数:
rwlock:指向读写锁的指针。
网络
计算机网络是由多个计算机及其他设备通过通信媒介相互连接而成的系统,允许它们共享资源和信息。
协议
计算机网络中的协议是指用于不同计算机或网络设备之间进行通信的规则和标准。协议定义了数据传输的格式、顺序、错误处理和数据压缩等方面,确保信息能够可靠、有效地从一个设备传输到另一个设备。
1. 协议的分类
协议可以根据不同的标准进行分类,主要包括:
1.1 按照层次
-
应用层协议:直接与用户应用程序交互,处理具体的应用数据。
- 例:HTTP(超文本传输协议)、FTP(文件传输协议)、SMTP(简单邮件传输协议)
-
传输层协议:负责数据的传输和完整性,提供端到端的通信。
- 例:TCP(传输控制协议)、UDP(用户数据报协议)
-
网络层协议:负责路由选择和数据包的传输。
- 例:IP(互联网协议)、ICMP(互联网控制消息协议)
-
数据链路层协议:负责在物理网络上发送数据帧。
- 例:Ethernet(以太网)、PPP(点对点协议)
1.2 按照功能
-
连接导向协议:在数据传输前建立连接,确保可靠性。
- 例:TCP
-
无连接协议:不建立连接,数据包独立发送,速度快但不保证可靠性。
- 例:UDP
2. 常见的网络协议
以下是一些常见的网络协议及其功能:
2.1 传输层协议
-
TCP(传输控制协议):
- 面向连接,提供可靠的数据传输。
- 通过序列号、确认应答和重传机制确保数据完整性。
-
UDP(用户数据报协议):
- 无连接协议,提供简单、快速的数据传输。
- 不保证数据完整性,适用于对速度要求高的应用,如视频流和在线游戏。
2.2 网络层协议
-
IP(互联网协议):
- 负责数据包的寻址和路由。
- IPv4和IPv6是两个主要版本,IPv6提供更大的地址空间。
-
ICMP(互联网控制消息协议):
- 用于发送错误消息和网络诊断信息,如ping命令。
2.3 应用层协议
-
HTTP/HTTPS(超文本传输协议):
- 用于网页数据的传输,HTTPS是加密的HTTP,确保数据安全。
-
FTP(文件传输协议):
- 用于在网络上进行文件传输,支持上传和下载。
-
SMTP(简单邮件传输协议):
- 用于发送电子邮件,通常与IMAP或POP3结合使用。
-
DNS(域名系统):
- 将域名解析为IP地址,使用户能够通过易记的名称访问网站。
3. 协议栈
计算机网络中的协议通常以层次结构的形式组织,称为协议栈。常见的模型有:
-
OSI模型:包含七个层次,从上到下分别为应用层、表示层、会话层、传输层、网络层、数据链路层和物理层。
-
TCP/IP模型:包含四个层次,从上到下分别为应用层、传输层、网络层和链路层。
4. 协议的重要性
- 互操作性:不同设备和系统之间能够有效地通信。
- 数据完整性:确保数据在传输过程中不被损坏。
- 安全性:通过协议的设计确保数据的机密性和完整性。
TCP/IP五层模型
五层模型通常包括以下层次:
1.1 物理层(Physical Layer)
- 功能:负责传输原始数据比特流,通过各种传输媒介将数据传输到物理介质上。
- 设备:集线器(Hub)、网络接口卡(NIC)、电缆(如双绞线、同轴电缆、光纤)、无线电波等。
- 特点:
- 决定最大传输速率、传输距离及抗干扰性。
- 包括信号的电气特性、传输模式(如全双工、半双工)等。
1.2 数据链路层(Data Link Layer)
- 功能:负责设备之间的数据帧的传送和识别,包括帧的封装、地址识别和差错检测。
- 协议:以太网、Wi-Fi、令牌环等。
- 设备:交换机(Switch)、网卡(NIC)。
- 特点:
- 提供物理地址(MAC地址)来唯一标识网络设备。
- 处理冲突检测和帧同步。
1.3 网络层(Network Layer)
- 功能:负责数据包的路由选择和转发,管理网络间的通信。
- 协议:IP(互联网协议)、ICMP(互联网控制消息协议)。
- 设备:路由器(Router)。
- 特点:
- 通过IP地址标识主机。
- 使用路由表确定数据包的最佳传输路径。
1.4 传输层(Transport Layer)
- 功能:负责两台主机之间的数据传输,确保数据的可靠性和完整性。
- 协议:
- TCP(传输控制协议):面向连接,提供可靠的数据传输。
- UDP(用户数据报协议):无连接,提供快速但不保证可靠性的传输。
- 特点:
- 提供端到端的通信。
- 处理流量控制和错误检测。
1.5 应用层(Application Layer)
- 功能:负责应用程序之间的通信,提供网络服务。
- 协议:
- HTTP/HTTPS(超文本传输协议)
- FTP(文件传输协议)
- SMTP(简单邮件传输协议)
- Telnet(远程访问协议)
- 特点:
- 直接与用户的应用程序交互,支持各种网络应用。
2. TCP/IP四层模型
在一些简化的模型中,TCP/IP也可以被描述为四层模型:
- 网络接口层(Network Interface Layer):包括物理层和数据链路层的功能。
- 网络层(Network Layer):负责数据包的路由和传输。
- 传输层(Transport Layer):负责数据的可靠传输。
- 应用层(Application Layer):负责应用程序间的通信。
总结
TCP/IP模型提供了一种分层结构,使不同的网络协议能够互相协作。每一层都有其特定的功能和责任,从物理信号的传输到应用程序的交互。理解这一模型有助于网络设计、故障排查和协议开发。
网络传输基本流程
网络传输的基本流程涉及数据从源设备到目标设备的传输过程。以下是一个典型的网络传输流程,从数据生成到接收的各个步骤。
1. 数据生成
- 应用程序:用户在应用程序中生成数据(例如,发送电子邮件、浏览网页等)。
- 数据封装:应用层将数据封装成特定格式(例如,HTTP请求、SMTP邮件等)。
2. 分层封装
数据在传输过程中经过不同的层进行封装,每一层为数据添加协议头。
-
应用层:
- 数据被封装成应用层数据单元(如HTTP报文)。
-
传输层:
- 数据被分割成段(TCP)或数据报(UDP)。
- 添加传输层头部(如TCP头部包含源端口、目标端口、序列号等)。
-
网络层:
- 段被封装成数据包,添加网络层头部(如IP头部包含源IP地址、目标IP地址等)。
-
数据链路层:
- 数据包被封装成帧,添加数据链路层头部和尾部(如MAC地址、帧校验序列等)。
3. 物理传输
- 信号发送:
- 数据帧通过物理介质(如电缆、光纤或无线信号)在网络中传输。
- 传输介质:
- 使用不同的传输介质(如双绞线、同轴电缆、光纤、Wi-Fi等),信号以电流、光脉冲或电磁波的形式传输。
4. 路由和交换
- 路由器和交换机:
- 数据帧到达数据链路层设备(如交换机)后,交换机会根据目标MAC地址转发帧。
- 如果数据包需要跨越不同网络,路由器会根据目标IP地址选择最佳路径,将数据包转发到下一个网络。
5. 目标设备接收
-
数据链路层解封装:
- 目标设备的网络接口接收到数据帧,检查帧的完整性(如CRC校验),并提取数据包。
-
网络层解封装:
- 提取传输层数据段,检查传输层头部,确保数据的完整性(如TCP的确认应答)。
-
传输层解封装:
- 将接收到的数据段重新组合(如TCP重组),并传递给应用层。
-
应用层处理:
- 应用层根据协议处理数据(如显示网页、读取邮件等)。
6. 确认和反馈
- 确认机制:
- 在使用TCP协议时,接收方会发送确认(ACK)给发送方,确认数据已成功接收。
- 如果未收到确认,发送方会重传数据。
数据包的封装和分用
1. 数据封装
在数据传输过程中,每一层协议会对数据进行封装。封装过程包括添加协议头(header),形成不同的数据单元。
1.1 各层数据单元的称谓
- 应用层:数据通常被称为消息(Message)。
- 传输层:数据被称为段(Segment)或数据报(Datagram),具体取决于使用的协议:
- TCP协议:将数据称为段(Segment)。
- UDP协议:将数据称为数据报(Datagram)。
- 网络层:数据被称为数据包(Packet)或数据报(Datagram),通常指的是IP数据包。
- 数据链路层:数据被称为帧(Frame)。
1.2 封装过程
-
应用层:
- 应用层生成数据(如HTTP请求),并将其封装为消息。
-
传输层:
- 将应用层的消息封装为段(TCP)或数据报(UDP),并添加传输层头部。
- 头部内容:包括源端口、目标端口、序列号、校验和等信息。
-
网络层:
- 将传输层的段或数据报封装为数据包,添加网络层头部。
- 头部内容:包括源IP地址、目标IP地址、协议类型等信息。
-
数据链路层:
- 将网络层的数据包封装为帧,添加数据链路层头部和尾部。
- 头部内容:包括源MAC地址、目标MAC地址、帧类型等信息,尾部通常包含错误检测信息(如CRC)。
2. 数据分用
数据分用是接收方在接收数据时的解封装过程,每层协议逐层剥离头部,以获取原始数据。
2.1 分用过程
-
物理层:
- 接收信号并将其转换为比特流。
-
数据链路层:
- 接收比特流并识别帧,检查帧的完整性(如CRC校验)。
- 提取数据包,剥离数据链路层头部和尾部。
-
网络层:
- 提取数据包,检查网络层头部(如IP地址)。
- 根据目标IP地址决定是否继续处理,将剥离的数据传递给传输层。
-
传输层:
- 提取段或数据报,检查传输层头部(如校验和)。
- 将剥离的数据传递给应用层。
-
应用层:
- 根据协议类型(在传输层头部中指定的上层协议字段)处理数据(如解析HTTP请求)。
3. 封装和分用的重要性
- 结构化:通过分层封装和剥离,网络协议能够有效地组织和管理数据。
- 互操作性:不同协议可以在同一网络中协同工作,简化了网络通信的复杂性。
- 可靠性:通过各层的校验机制,提高了数据传输的可靠性。
4. 示例
以发送一个HTTP请求为例,展示封装和分用的过程:
封装示例
- 应用层:生成HTTP请求消息。
- 传输层:将消息封装为TCP段,增加TCP头部。
- 网络层:将TCP段封装为IP数据包,增加IP头部。
- 数据链路层:将IP数据包封装为帧,增加MAC头部和尾部。
分用示例
- 接收方物理层:接收信号并转换为比特流。
- 数据链路层:提取帧,剥离MAC头部和尾部。
- 网络层:提取数据包,剥离IP头部。
- 传输层:提取TCP段,剥离TCP头部。
- 应用层:处理HTTP请求,执行相应操作(如加载网页)。
总结
数据包的封装和分用是网络通信中的核心过程。通过在每一层添加和剥离协议头,网络能够有效地管理数据的传输,确保可靠性和完整性。这种分层结构不仅提高了通信的效率,还增强了网络的灵活性和扩展性。
网络中的地址管理
网络中的地址管理是确保设备能够在网络中相互通信的关键。有效的地址管理可以提高网络的效率、可扩展性和安全性。以下是关于网络地址管理的详细概述。
1. 网络地址的类型
在计算机网络中,主要有两种类型的地址:
1.1 IP地址
- 定义:IP地址是分配给网络中每个设备的唯一标识符,用于在互联网上进行通信。
- 格式:
- IPv4:使用32位地址,通常以十进制形式表示,如
192.168.1.1。 - IPv6:使用128位地址,通常以十六进制表示,如
2001:0db8:85a3:0000:0000:8a2e:0370:7334。
- IPv4:使用32位地址,通常以十进制形式表示,如
1.2 MAC地址
- 定义:每个网络接口卡(NIC)都有一个唯一的物理地址,称为MAC地址,用于局域网内部的设备识别。
- 格式:通常为48位,表示为6组十六进制数,如
00:1A:2B:3C:4D:5E。
2. 地址分配与管理
2.1 静态地址分配
- 定义:手动为每个设备分配IP地址,通常用于需要固定地址的设备,如服务器和打印机。
- 优点:
- 地址不变,易于管理。
- 适合特定应用需要。
- 缺点:
- 管理繁琐,特别是在大型网络中。
- 容易出现地址冲突。
2.2 动态地址分配
-
定义:通过动态主机配置协议(DHCP)自动为设备分配IP地址。
-
工作流程:
- DHCP Discover:客户端广播请求。
- DHCP Offer:DHCP服务器响应,提供可用的IP地址。
- DHCP Request:客户端请求分配该地址。
- DHCP Acknowledgment:服务器确认并分配地址。
-
优点:
- 简化管理,特别是在设备频繁变动的环境中。
- 减少地址冲突的可能性。
-
缺点:
- 地址可能会改变,可能影响某些服务。
- 依赖DHCP服务器的正常运行。
3. 子网划分
-
定义:通过子网掩码将大的IP地址块划分为多个小块,以提高管理效率和安全性。
-
优点:
- 降低广播域的大小,减少网络拥塞。
- 提高安全性,通过划分不同的子网限制访问。
-
示例:
- 一个
192.168.1.0/24的网络可以划分为多个子网,如192.168.1.0/26、192.168.1.64/26等。
- 一个
4. 地址解析协议
- ARP(地址解析协议):
- 用于将IP地址解析为MAC地址,使得数据在局域网中能够正确路由。
- 当设备知道目标IP地址但不知道目标MAC地址时,会广播ARP请求,目标设备回复其MAC地址。
5. 地址管理工具和技术
-
IP地址管理(IPAM):
- 用于规划、跟踪和管理IP地址的工具,提供可视化和报告功能,简化地址管理。
-
DHCP和DNS的结合:
- 动态DNS(DDNS)允许动态分配的IP地址实时更新DNS记录,确保网络中的设备能够通过名称访问。
6. 安全性考虑
- 地址过滤:通过配置防火墙和路由器,仅允许特定IP地址或MAC地址的设备访问网络。
- ARP欺骗防护:使用静态ARP表和ARP监控工具来防止ARP欺骗攻击。
网络编程
源IP地址(Source IP Address)
- 定义:源IP地址是发送数据包的设备在网络中的唯一标识符。它表示数据包的发送方。
- 功能:
- 标识发送方:源IP地址帮助接收方知道数据包的来源。
- 路由与返回:网络设备(如路由器)使用源IP地址来确定数据包的返回路径,确保响应能够正确返回给发送方。
目的IP地址(Destination IP Address)
- 定义:目的IP地址是接收数据包的设备在网络中的唯一标识符。它表示数据包的接收方。
- 功能:
- 指明目标:目的IP地址告诉网络设备数据包应该发送到哪个目标设备。
- 路由:网络设备使用目的IP地址来决定如何转发数据包,确保它最终到达正确的接收方。
数据包的结构
在网络传输中,每个数据包通常包含源IP地址和目的IP地址。具体结构如下:
- IP头部:
- 源IP地址:发送方的IP地址。
- 目的IP地址:接收方的IP地址。
- 其他字段:协议类型、TTL(生存时间)、版本等。
认识端口号
端口号是计算机网络中用于标识特定进程或服务的关键要素,主要在传输层协议中使用。
IP地址 + 端口号能够标识网络上的某一台主机的某一个进程; 一个端口号只能被一个进程占用。
1. 端口号的基本概念
- 定义:端口号是一个16位的整数(范围从0到65535),用于标识主机上的特定进程或服务。
- 作用:它告诉操作系统当前的数据应该交给哪个进程进行处理。IP地址加上端口号共同构成了一个唯一的地址,指向网络上的某一台主机的某一个进程。
2. 端口号的分类
- 知名端口(Well-Known Ports):范围从0到1023,通常由系统和常见服务使用(如HTTP使用端口80,HTTPS使用端口443)。
- 注册端口(Registered Ports):范围从1024到49151,供用户进程和应用程序使用。
- 动态或私有端口(Dynamic/Private Ports):范围从49152到65535,通常由客户端应用程序临时使用。
3. 端口号与进程ID的关系
3.1 进程ID(PID)
- 定义:进程ID是操作系统分配给每个进程的唯一标识符,用于管理和调度进程。
- 作用:通过PID,操作系统可以追踪和控制进程的状态和资源。
3.2 端口号与PID的关系
- 唯一性:每个端口号在同一时间只能被一个进程占用,这样可以避免数据混淆。
- 标识:虽然端口号和进程ID都是用来标识进程的,但它们的作用不同:
- 端口号用于网络通信,指示数据流向哪个进程。
- 进程ID用于操作系统内部管理,追踪进程的状态和资源。
- 示例:一个进程可能绑定到多个端口号(如一个Web服务器可能同时监听HTTP和HTTPS),但每个端口号只能由一个进程绑定。
端口号的使用场景
- Web服务器:通常监听80(HTTP)或443(HTTPS)端口。
- 数据库服务:例如,MySQL使用3306端口,PostgreSQL使用5432端口。
- FTP服务:使用21端口进行控制连接。
源端口号(Source Port Number)
- 定义:源端口号是发送数据包的应用程序使用的端口,标识数据的来源。
- 功能:
- 标识发送方:源端口号帮助接收方确定数据包来自哪个应用程序。
- 建立连接:在TCP连接中,源端口号与源IP地址一起用于建立和维护连接。
目的端口号(Destination Port Number)
- 定义:目的端口号是接收数据包的应用程序使用的端口,标识数据的目的地。
- 功能:
- 指明目标应用程序:目的端口号告诉接收方的数据应该交给哪个应用程序进行处理。
- 路由决策:网络设备使用目的端口号来决定如何将数据包转发到正确的接收方应用程序。
数据包结构
在网络通信中,数据包的结构通常包含以下信息:
-
IP头部:
- 源IP地址
- 目的IP地址
-
传输层头部:
- 源端口号:标识发送方的端口。
- 目的端口号:标识接收方的端口。
- 其他字段:如序列号、确认号、校验和等。
TCP(传输控制协议)
1. TCP的基本特性
1.1 面向连接
- 定义:在数据传输之前,TCP建立一个连接,这意味着数据的发送和接收双方都需准备好进行通信。
- 三次握手:在建立连接时,使用三次握手过程来确认双方的通信能力。
1.2 可靠性
- 数据完整性:TCP通过序列号和确认机制确保数据包的可靠传输,任何丢失或损坏的数据包都会被重新发送。
- 流量控制:使用滑动窗口机制来控制数据流,避免发送方过快地发送数据,以至于接收方来不及处理。
1.3 有序性
- 数据顺序:TCP保证数据包按照发送顺序到达接收方,即使数据包在网络中以不同的顺序到达,TCP也会重新排序。
1.4 全双工通信
- 双向通信:TCP支持在同一连接中同时进行双向数据传输,允许数据在两个方向上独立流动。
2. TCP的工作流程
2.1 连接建立(三次握手)
- SYN:客户端发送一个SYN(同步)报文段,请求建立连接。
- SYN-ACK:服务器响应一个SYN-ACK报文段,确认接收到客户端的请求。
- ACK:客户端发送一个ACK(确认)报文段,确认建立连接。
2.2 数据传输
- 在连接建立后,双方可以开始数据传输。每个数据段都有序列号和确认号,以确保数据的完整性和顺序。
2.3 连接终止(四次挥手)
- FIN:一方发送FIN报文段,表示希望终止连接。
- ACK:接收方确认接收到FIN,发送ACK报文段。
- FIN:接收方也发送FIN报文段,表示要关闭连接。
- ACK:发送方确认接收到FIN,发送ACK报文段,连接正式关闭。
3. TCP头部结构
TCP数据包的头部包含多个字段,主要包括:
- 源端口号:发送方的端口号。
- 目的端口号:接收方的端口号。
- 序列号:用于数据排序和完整性检查。
- 确认号:下一个期望接收的数据序列号。
- 数据偏移:TCP头部的长度。
- 标志位:如SYN、ACK、FIN等,用于控制连接状态。
- 窗口大小:流量控制的单位,表示接收方的缓冲区大小。
- 校验和:用于错误检测。
- 紧急指针:指示紧急数据的位置(如果有)。
4. TCP的应用场景
- Web浏览:HTTP和HTTPS协议基于TCP,保证网页内容的可靠传输。
- 文件传输:FTP(文件传输协议)使用TCP来确保文件完整性。
- 电子邮件:SMTP、POP3和IMAP等邮件协议均使用TCP进行数据传输。
5. TCP的优缺点
5.1 优点
- 可靠性高:确保数据的完整性和顺序。
- 流量控制:避免网络拥堵。
- 面向连接:适合需要稳定连接的应用。
5.2 缺点
- 延迟:由于建立连接和确认机制,TCP的延迟相对较高。
- 开销大:TCP头部较大,增加了网络负担。
- 不适合实时应用:对于要求实时性的应用(如语音和视频通信),TCP的可靠性和顺序保证可能成为负担。
UDP(用户数据报协议)
1. UDP的基本特性
1.1 无连接
- 定义:UDP是无连接的协议,发送数据之前无需建立连接,这使得数据传输过程更简单、速度更快。
1.2 不可靠性
- 数据不保证送达:UDP不提供数据传输的可靠性保障。如果数据包在传输过程中丢失或损坏,UDP不会进行重传。
- 无序传输:UDP不保证数据包的顺序,接收方可能会以与发送方不同的顺序收到数据。
1.3 轻量级
- 头部开销小:UDP头部仅8个字节,相比TCP的20字节头部,UDP的开销更小,适合对延迟敏感的应用。
1.4 面向报文
- 完整报文传输:UDP以报文为单位进行数据传输,每个UDP数据报是一个完整的消息,不会拆分。
2. UDP的工作流程
UDP的工作流程相对简单,主要包括:
- 数据打包:应用程序将数据打包成UDP数据报。
- 发送数据报:UDP通过网络将数据报发送到目标IP地址和端口号。
- 接收数据报:目标主机的UDP协议接收数据报,传递给目标应用程序。
3. UDP头部结构
UDP数据包的头部包含以下字段:
- 源端口号:发送方的端口号(可选)。
- 目的端口号:接收方的端口号。
- 长度:UDP头部和数据部分的总长度。
- 校验和:用于错误检测(可选)。
4. UDP的应用场景
UDP适用于对速度和实时性要求较高的应用,常见的应用场景包括:
- 视频流:如直播、视频会议等实时视频传输。
- 音频流:如VoIP(语音传输)和网络电话。
- 在线游戏:需要快速响应的多人在线游戏。
- DNS(域名系统):用于域名解析的请求和响应。
5. UDP的优缺点
5.1 优点
- 速度快:由于无连接和小的头部开销,UDP在传输速度上具有优势。
- 简单性:协议简单,易于实现,适合高效的数据传输。
5.2 缺点
- 不可靠:无法保证数据的完整性和顺序,适合对可靠性要求不高的场景。
- 无流量控制:UDP不提供流量控制,可能导致网络拥塞。
网络字节序
1. 字节序(Endianness)概念
字节序是指多字节数据在内存中存储的顺序,主要有两种类型:
1.1 大端字节序(Big-Endian)
- 定义:在大端字节序中,数据的高位字节存储在低地址,低位字节存储在高地址。
1.2 小端字节序(Litle-Endian)
- 定义:在小端字节序中,数据的低位字节存储在低地址,高位字节存储在高地址。
网络字节序采用大端字节序。这意味着在网络上传输的数据总是以大端格式表示,无论发送方和接收方的主机使用何种字节序。
采用统一的字节序有助于提供跨平台的兼容性,确保不同系统之间的数据能够正确解释。
在网络传输中,数据包的发送和接收过程遵循一定的字节顺序和地址定义:
- 数据发送顺序:发送主机通常将发送缓冲区中的数据按内存地址从低到高的顺序发送。这意味着,先发送的数据位于较低的地址,而后发送的数据位于较高的地址。
- 数据接收顺序:接收主机将网络上接收到的字节按照同样的顺序存储在接收缓冲区中,即也是按内存地址从低到高保存。
C语言中的字节序转换函数
为了使网络程序具有可移植性,许多编程语言提供了字节序转换的库函数。在C语言中,常用的转换函数包括:
- htons(Host to Network Short):将主机字节序的16位整数转换为网络字节序(大端)。
- htonl(Host to Network Long):将主机字节序的32位整数转换为网络字节序(大端)。
- ntohs(Network to Host Short):将网络字节序的16位整数转换为主机字节序。
- ntohl(Network to Host Long):将网络字节序的32位整数转换为主机字节序。
示例代码
以下是一个示例代码,演示如何在C语言中进行字节序转换:
#include <stdio.h>
#include <arpa/inet.h>
int main()
{
uint16_t host_short = 0x1234; // 示例16位整数
uint32_t host_long = 0x12345678; // 示例32位整数
// 转换为网络字节序
uint16_t net_short = htons(host_short);
uint32_t net_long = htonl(host_long);
// 打印结果
printf("Host short: 0x%X, Network short: 0x%X\n", host_short, net_short);
printf("Host long: 0x%X, Network long: 0x%X\n", host_long, net_long);
return 0;
}
socket编程
Socket编程的基本步骤
1 创建Socket
使用socket()函数创建一个Socket。
2 绑定Socket
对于服务器,使用bind()函数将Socket绑定到特定的IP地址和端口号。
3 监听(仅TCP)
服务器使用listen()函数监听连接请求。
4 接受连接(仅TCP)
服务器使用accept()函数接受客户端的连接请求。
5 发送和接收数据
使用send()和recv()(TCP)或sendto()和recvfrom()(UDP)函数进行数据传输。
6 关闭Socket
使用close()函数关闭Socket,释放资源。
socket接口
1. 创建Socket
int socket(int domain, int type, int protocol)
- 功能:创建一个新的Socket。
- 参数:
domain:地址族,常用的有AF_INET(IPv4)和AF_INET6(IPv6)。type:Socket类型,常用的有:SOCK_STREAM:TCP协议(面向连接)。SOCK_DGRAM:UDP协议(无连接)。
protocol:通常设为0,表示使用默认协议。
- 返回值:成功返回Socket描述符,失败返回-1。
2. 绑定Socket
int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen)
- 功能:将Socket绑定到特定的IP地址和端口号。
- 参数:
sockfd:Socket描述符。addr:指向sockaddr结构体的指针,包含IP地址和端口号。addrlen:地址结构的长度。
- 返回值:成功返回0,失败返回-1。
建立连接
int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
- 功能:建立与服务器的连接(用于TCP客户端)。
- 参数:
sockfd:Socket描述符。addr:指向sockaddr结构的指针,包含服务器的IP地址和端口号。addrlen:地址结构的长度。
- 返回值:成功返回0,失败返回-1。
3. 监听连接(仅TCP)
int listen(int sockfd, int backlog)
- 功能:将Socket设置为监听状态,等待客户端连接。
- 参数:
sockfd:Socket描述符。backlog:等待连接的最大数量。
- 返回值:成功返回0,失败返回-1。
4. 接受连接(仅TCP)
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen)
- 功能:接受客户端的连接请求。
- 参数:
sockfd:Socket描述符。addr:指向sockaddr结构体的指针,用于存储客户端的地址信息。addrlen:指向地址长度的指针,初始值为addr的长度,返回时更新为实际客户端地址的长度。
- 返回值:成功返回新的Socket描述符,失败返回-1。
5. 发送和接收数据
ssize_t send(int sockfd, const void *buf, size_t len, int flags)
- 功能:通过Socket发送数据。
- 参数:
sockfd:Socket描述符。buf:指向要发送数据的缓冲区。len:要发送的数据字节数。flags:通常设置为0。
- 返回值:成功返回发送的字节数,失败返回-1。
ssize_t recv(int sockfd, void *buf, size_t len, int flags)
- 功能:从Socket接收数据。
- 参数:
sockfd:Socket描述符。buf:指向接收数据的缓冲区。len:缓冲区大小。flags:通常设置为0。
- 返回值:成功返回接收的字节数,失败返回-1。
6. 发送和接收数据(UDP)
ssize_t sendto(int sockfd, const void *buf, size_t len, int flags, const struct sockaddr *dest_addr, socklen_t addrlen)
- 功能:通过UDP Socket发送数据到指定地址。
- 参数:
sockfd:Socket描述符。buf:指向要发送数据的缓冲区。len:要发送的数据字节数。flags:通常设置为0。dest_addr:目标地址的指针。addrlen:目标地址长度。
- 返回值:成功返回发送的字节数,失败返回-1。
ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags, struct sockaddr *src_addr, socklen_t *addrlen)
- 功能:从UDP Socket接收数据。
- 参数:
sockfd:Socket描述符。buf:指向接收数据的缓冲区。len:缓冲区大小。flags:通常设置为0。src_addr:指向源地址的指针(可选)。addrlen:源地址长度的指针。
- 返回值:成功返回接收的字节数,失败返回-1。
7. 关闭Socket
int close(int sockfd)
- 功能:关闭Socket,释放资源。
- 参数:
sockfd:Socket描述符。
- 返回值:成功返回0,失败返回-1。
sockaddr结构
sockaddr 是一个通用的地址结构,通常定义如下:
struct sockaddr {
unsigned short sa_family; // 地址族
char sa_data[14]; // 地址信息
};
- sa_family: 表示地址的类型(如
AF_INET表示 IPv4,AF_INET6表示 IPv6)。 - sa_data: 存储具体的地址信息(如 IP 地址和端口号)。
IPv4 地址结构
对于 IPv4,使用 sockaddr_in 结构:
#include <netinet/in.h>
struct sockaddr_in {
short sin_family; // 地址族,通常为 AF_INET
unsigned short sin_port; // 端口号(网络字节序)
struct in_addr sin_addr; // IP 地址
char sin_zero[8]; // 填充,通常为0
};
- sin_family: 地址族,通常为
AF_INET。 - sin_port: 端口号,使用
htons()函数转换为网络字节序。 - sin_addr: 32位的 IPv4 地址,通常使用
inet_pton()或inet_addr()进行转换。 - sin_zero: 填充字段,确保结构体的大小与其他地址结构一致。
IPv6 地址结构
对于 IPv6,使用 sockaddr_in6 结构:
#include <netinet/in.h>
struct sockaddr_in6 {
short sin6_family; // 地址族,通常为 AF_INET6
unsigned short sin6_port; // 端口号(网络字节序)
uint32_t sin6_flowinfo; // 流量信息
struct in6_addr sin6_addr; // IPv6 地址
uint32_t sin6_scope_id; // 作用域 ID
};
- sin6_family: 地址族,通常为
AF_INET6。 - sin6_port: 端口号,使用
htons()函数转换为网络字节序。 - sin6_flowinfo: 流量控制信息,通常设置为0。
- sin6_addr: IPv6 地址,使用
inet_pton()进行转换。 - sin6_scope_id: 作用域 ID,通常用于多播和链接本地地址。
netstat
netstat 是一个网络统计工具,用于显示网络连接、路由表、接口统计、伪连接和网络协议等信息。
1. 基本用法
在终端中输入 netstat 命令:
netstat
2. 常见选项
-a:显示所有连接和监听的端口。-t:显示 TCP 连接。-u:显示 UDP 连接。-l:仅显示正在监听的端口。-p:显示使用每个连接的程序的 PID 和名称。-n:以数字形式显示地址和端口号,避免 DNS 解析。-r:显示路由表。-i:显示网络接口信息。-s:显示网络统计信息,例如协议统计。
netstat -tulnp
这个命令将显示所有 TCP 和 UDP 连接、监听的端口,以及对应的程序信息。
5. 注意事项
- 在某些系统中,
netstat可能需要超级用户权限才能显示所有信息。 - 在现代 Linux 发行版中,
netstat被ss命令所取代,ss提供了更快和更丰富的功能。
ss
在终端中输入 ss 命令:
ss
常见选项
-a:显示所有连接,包括监听和非监听的套接字。-t:显示 TCP 套接字。-u:显示 UDP 套接字。-l:仅显示监听的套接字。-p:显示使用每个套接字的程序的 PID 和名称。-n:以数字形式显示地址和端口号,避免 DNS 解析。-r:显示路由信息。-s:显示统计信息。-i:显示网络接口信息。
可以将多个选项结合使用,例如:
ss -tunlp
这个命令将显示所有 TCP 和 UDP 套接字,包括监听的套接字和对应的程序信息。
地址转换函数
在网络编程中,IP 地址的转换非常重要,尤其是在处理不同的地址表示形式时。以下是对地址转换函数的详细解释,主要集中在 inet_pton 和 inet_ntop 函数,这些函数用于在字符串格式的 IP 地址与其二进制格式(如 struct in_addr 和 struct in6_addr)之间进行转换。
1. inet_pton
功能
将点分十进制字符串(如 "192.168.1.1" 或 IPv6 地址)转换为网络字节序的二进制格式。
语法
int inet_pton(int af, const char *src, void *dst);
参数
af: 地址族,通常为AF_INET(表示 IPv4)或AF_INET6(表示 IPv6)。src: 输入的字符串格式的 IP 地址。dst: 指向接收转换结果的结构体指针(如struct in_addr或struct in6_addr)。
返回值
- 成功时返回
1。 - 如果输入字符串无效返回
0。 - 出错时返回
-1,并设置errno以指示错误类型。
示例
#include <arpa/inet.h>
#include <iostream>
bool stringToInAddr(const std::string &ipStr, struct in_addr *addr) {
if (inet_pton(AF_INET, ipStr.c_str(), addr) != 1) {
std::cerr << "Invalid IP address: " << ipStr << std::endl;
return false; // 转换失败
}
return true; // 转换成功
}
2. inet_ntop
功能
将网络字节序的二进制格式(如 struct in_addr 或 struct in6_addr)转换为点分十进制字符串。
语法
const char *inet_ntop(int af, const void *src, char *dst, socklen_t size);
参数
af: 地址族,通常为AF_INET(IPv4)或AF_INET6(IPv6)。src: 指向要转换的网络地址结构的指针。dst: 指向接收转换结果的字符数组。size:dst数组的大小。
返回值
- 成功时返回
dst指针。 - 出错时返回
nullptr,并设置errno以指示错误类型。
示例
#include <arpa/inet.h>
#include <iostream>
std::string inAddrToString(const struct in_addr &addr) {
char buffer[INET_ADDRSTRLEN]; // IPv4 地址的最大字符串长度
if (inet_ntop(AF_INET, &addr, buffer, sizeof(buffer)) == nullptr) {
std::cerr << "Error converting in_addr to string" << std::endl;
return ""; // 转换失败
}
return std::string(buffer); // 返回转换后的字符串
}
bind() 函数的作用
-
服务器端:
- 显式绑定:服务器通常会调用
bind()来将套接字与特定的 IP 地址和端口号绑定。这样可以确保服务器在启动时使用一个固定的端口,客户端在连接时可以知道这个端口。 - 隐式绑定:如果服务器不调用
bind(),内核会自动为服务器分配一个可用的端口。虽然这在某些情况下是可行的,但会导致每次启动服务器时端口号不同,给客户端带来连接困难。
- 显式绑定:服务器通常会调用
-
客户端:
- 不调用
bind():客户端在创建套接字后,一般不需要调用bind()来指定一个端口。系统会自动为客户端分配一个可用的端口号,这是常见的做法。 - 调用
bind()的情况:在某些特定情况下,客户端可能会调用bind(),例如:- 当需要确保使用特定的源端口号进行通信时。
- 当需要同时运行多个客户端实例并确保它们使用不同的端口。
- 不调用
端口冲突
-
多个客户端实例:如果在同一台机器上启动多个客户端实例,并且每个实例都调用
bind()来指定相同的端口,将导致端口冲突,只有第一个实例会成功,后续的实例将无法绑定到同一端口。 -
解决方案:
- 客户端通常不需要调用
bind(),让系统自动分配端口。 - 如果确实需要指定源端口,可以选择使用不同的端口号,以避免冲突。
- 客户端通常不需要调用
实际应用中的考虑
-
动态分配端口:客户端可以不调用
bind(),让系统自动为其分配端口,这样可以避免端口冲突,并简化客户端的实现。 -
固定服务器端口:服务器通常应该调用
bind()来使用一个固定的端口号,这样客户端可以很容易地连接到服务器。
TCP 连接的建立和断开的过程进行了详细说明。以下是对您所描述的内容的总结和补充信息,以便更好地理解 TCP 协议和相关的 socket API。
服务器初始化过程
-
创建套接字:
- 调用
socket()创建一个文件描述符,用于后续的网络通信。 - 例如:
int sockfd = socket(AF_INET, SOCK_STREAM, 0);
- 调用
-
绑定地址:
- 使用
bind()将套接字与特定的 IP 地址和端口号绑定。 - 如果绑定的端口已被其他进程占用,
bind()将失败并返回错误。 - 例如:
bind(sockfd, (struct sockaddr *)&server_addr, sizeof(server_addr));
- 使用
-
监听连接:
- 调用
listen()将套接字标记为监听状态,准备接受客户端的连接请求。 - 例如:
listen(sockfd, SOMAXCONN);
- 调用
-
接受连接:
- 使用
accept()阻塞等待客户端的连接请求,成功后返回一个新的套接字描述符用于与该客户端通信。 - 例如:
int client_sockfd = accept(sockfd, (struct sockaddr *)&client_addr, &addr_len);
- 使用
建立连接的过程(三次握手)
-
客户端请求连接:
- 客户端调用
socket()创建套接字,并调用connect()向服务器发起连接请求。 connect()会发送一个 SYN 段,并阻塞等待服务器的响应。
- 客户端调用
-
服务器响应:
- 服务器收到客户端的 SYN 段后,回复一个 SYN-ACK 段,表示同意建立连接。
-
客户端确认:
- 客户端收到 SYN-ACK 段后,会再发送一个 ACK 段,完成连接建立。
数据传输过程
- 建立连接后,TCP 协议提供全双工通信,允许双方同时发送和接收数据。
- 服务器在调用
accept()后,可以通过read()从套接字读取数据。该调用会阻塞,直到有数据到达。 - 客户端使用
write()发送请求,服务器在处理请求后使用write()将结果发送回客户端。 - 客户端通过
read()接收服务器的响应。此过程可以循环进行,直到通信结束。
断开连接的过程(四次挥手)
-
客户端关闭连接:
- 客户端调用
close(),发送 FIN 段表示不再发送数据。
- 客户端调用
-
服务器确认:
- 服务器收到 FIN 段后,发送 ACK 段,表示已收到关闭请求,
read()返回 0,表明连接已关闭。
- 服务器收到 FIN 段后,发送 ACK 段,表示已收到关闭请求,
-
服务器关闭连接:
- 服务器随后调用
close(),发送 FIN 段给客户端,表明也停止发送数据。
- 服务器随后调用
-
客户端确认关闭:
- 客户端收到服务器的 FIN 段后,发送 ACK 段,确认连接已关闭。
应用程序与 TCP 协议的交互
- 应用程序通过 socket API 调用来发送和接收数据,TCP 协议负责将这些请求转换为相应的网络操作。
- 例如,调用
connect()会触发 TCP 协议发送 SYN 段,状态变化(如连接建立)会通过阻塞的 socket 函数返回。 read()返回 0 表示接收到 FIN 段,连接已关闭。

















 16万+
16万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









