







 本文提出HOICLIP框架,将视觉语言模型知识迁移到HOI检测任务。该框架从空间、动词、语言特征三方面检索CLIP先验知识,构建新交互解码器、动词分类器及增强方法。实验表明,其在多种设置下性能优于现有技术,提高了数据效率和泛化能力。
本文提出HOICLIP框架,将视觉语言模型知识迁移到HOI检测任务。该框架从空间、动词、语言特征三方面检索CLIP先验知识,构建新交互解码器、动词分类器及增强方法。实验表明,其在多种设置下性能优于现有技术,提高了数据效率和泛化能力。
CVPR 2023 CLIP
摘要
- 概念:人-物交互(HOI)检测的目的是定位人-物对并识别它们的交互
- 引出现有方法并提出不足之处:
- 现有方法:对比度图像预训练(CLIP)
- 不足之处:依赖于大规模的训练数据,并且在few/zero-shot下性能较差
- 引出自己的方法:本文提出了一种新的HOI检测框架,该框架能够有效地从CLIP中提取先验知识,并获得更好的泛化能力
- 具体介绍:
- 新的交互解码器:通过交叉注意机制从CLIP的视觉特征图中提取信息区域,然后通过知识集成块将其与检测骨干融合,以实现更准确的人体对象对检测
- 构建新的动词分类器:利用CLIP文本编码器中的先验知识,通过嵌入HOI描述来生成分类器。为了区分细粒度的交互,我们通过视觉语义算法和轻量级动词表示适配器从训练数据中构建
- 新的增强方法:我们提出了一种无需训练的增强方法来利用CLIP的全局HOI预测
- 展示实验数据:大量的实验表明,我们的方法在各种设置上都大大优于现有技术,例如, +4.04 mAP在HICO-Det上
介绍
- 解释人物交互概念:人与物体交互(HOI)检测旨在定位人与物体对并识别他们的交互,是全面理解视觉场景的核心任务
- 引出相关领域:近年来,它因其在广泛应用中的关键作用而引起了越来越多的兴趣,例如辅助机器人、视觉监控和视频分析
- 当前的领域研究发展:由于端到端对象检测器的发展,最近的研究在交互中定位人对象实例方面取得了显着进展
- 引出现在所面临的挑战:识别人与物体对之间的交互类别的问题仍然特别具有挑战性。
- 传统方法及其局限性:传统策略只是学习多标签分类器,通常需要大规模带注释的数据进行训练。因此,它们经常遭受长尾类别分布的困扰,并且缺乏对看不见的交互的泛化能力。
- 现有方法及应用情况:对比视觉语言预训练被探索来解决开放词汇和零样本学习问题,因为其学习的视觉和语言表示在各种下游任务中表现出强大的迁移能力。
- 详细介绍现有方法的一些研究进展:最近关于开放词汇检测的工作利用知识蒸馏将 CLIP 的对象表示转移到对象检测器,这种策略已经在 HOI 检测工作中采用,包括 GEN-VLKT 和 EoID ,它们利用 CLIP 的知识来解决 HOI 任务中的长尾和零样本学习。
- 但是仍然有些问题没有解决:
- 问题:如何有效地将 CLIP 知识转移到 HOI 识别任务中
- 主要原因:它涉及由视觉对象和交互组成的组合概念。
- 详细原因:
- 普遍采用的师生蒸馏目标与提高学生模型的泛化能力不一致。
- 学习HOI(例如GEN-VLKT)中的知识蒸馏通常需要大量的训练数据,这表明其数据效率较低。
- 知识蒸馏通常会在零样本泛化中遇到性能下降的问题,因为它缺乏对看不见的类的训练信号,而这对于从教师模型继承知识至关重要。
- 为了解决这些问题作者提出了新方法:
- 主要方法:提出了 HOICLIP ,用于将 CLIP 知识转移到本工作中的 HOI 检测任务中。它直接从 CLIP 中检索学到的知识,并通过利用 HOI 识别的组合性质从多个方面挖掘先验知识。
- 次要方法:为了应对低数据条件下动词识别中的长尾和零样本学习,我们开发了一种基于视觉语义算法的动词类表示,它不需要像基于知识蒸馏的方法那样需要大量的训练数据。
- 优势:该使我们能够提高 HOI 表示学习中的数据效率,并实现更好的泛化和鲁棒性。
- 具体方法介绍:
具体来说,我们的 HOICLIP 框架从三个方面学习从 CLIP 模型中检索先验知识:- 空间特征:由于特征位置是检测任务的关键,因此我们充分利用 CLIP 中的视觉表示并仅从信息丰富的图像区域中提取特征。为此,我们利用 CLIP 的空间维度特征图,开发了一种基于 Transformer 的交互解码器,该解码器可以学习具有跨模态注意力的局部交互特征。
- 动词特征:为了解决长尾动词类问题,我们开发了一个动词分类器,专注于学习更好的动词表示。我们的动词分类器由动词特征适配器和一组通过视觉语义算术计算的类权重组成。我们通过融合动词分类器和公共交互分类器的输出来增强 HOI 预测。
- 语言特征:为了应对 HOI 预测中非常罕见和看不见的类别,我们采用了基于提示的 HOI 语言表示,并为 HOI 分类构建了一个零样本分类器 。该分类器分支不需要训练,我们在模型推理期间将其输出与 HOI 分类器集成
- 该方法在数据集上的效果:
- 数据集:HICO-DET 和 V-COCO
- 条件:完全监督设置、零样本设置和数据高效设置
- 结果:HOICLIP 在所有三种设置上都实现了有竞争力的性能,在零样本设置上比之前最先进的方法高出 4.04 mAP,并显着提高了数据效率。
- 总结作者的主要贡献:
- HOICLIP 是第一个利用基于查询的知识检索来实现从预训练 CLIP 模型到 HOI 检测任务的高效知识迁移的工作。(利用查询的知识检索来实现高效的知识迁移)
- 我们开发了一种细粒度的迁移策略,通过交叉注意力利用 HOI 的区域视觉特征,并通过视觉语义算术利用动词表示,以实现更具表现力的 HOI 表示。(引入交叉注意力使得结果更具表现力)
- 我们通过利用零样本 CLIP 知识进一步提高 HOICLIP 的性能,无需额外培训。(引入先验知识而不用额外训练)
相关工作
1、HOI检测
- HOI检测任务:主要涉及物体检测、人体物体配对和交互识别。
- 以前的方法:
- 两阶段方法使用独立的检测器来获取对象的位置和类别,然后是专门设计的用于人与对象关联和交互识别的模块。典型的策略是使用基于图的方法来提取关系信息以支持交互理解。
- 一阶段方法直接检测具有交互的人-物体对,而不需要分阶段处理。
- 基于 Transformer的方法 :
- GEN-VLKT进一步设计了一个两分支管道来提供并行的转发过程,并使用针对人和物体的分离查询而不是CDN中使用的统一查询
- RLIP提出了一种基于图像标题的 HOI 检测预训练策略
- 作者的方法:建立在基于 Transformer 的 HOI 检测策略之上,专注于改进交互识别
2、利用视觉语言模型
- 视觉语言模型 (VLM):最新突破证明了向下游任务的有前途的迁移能力。从自然语言监督中学习到的视觉表示为零样本和开放词汇任务铺平了道路。
- 新的方法:通过知识蒸馏将 VLM 转移到开放词汇对象检测
- 研究:先前将VLM转移到检测任务的努力可以概括为两个方面
- 通过文本整合先验知识,利用CLIP中标签的文本嵌入来初始化分类器
- 特征(或logtis)级知识蒸馏,指导学习到的特征(或logit预测)与CLIP嵌入的图像特征(或零样本CLIP预测的logtis)对齐
- 作者的方法:提出了一种将 VLM 知识转移到 HOI 检测任务的新策略。与上述方法不同,我们直接从CLIP中检索相关信息,从而获得更优越的性能和更高的数据效率
3、零样本HOI检测
- 零样本 HOI 检测:目标是检测和识别训练数据中缺少的 HOI 类别。
- 重要性:由于HOI的组合性,所有可能的HOI组合的注释是不切实际的。因此,零样本HOI检测设置对于实际场景中的应用非常重要。
- 以前的方法:之前的工作以组合的方式解决了这样的挑战,在训练过程中解开了对动作和对象的推理。这使得在推理过程中识别看不见的⟨人、物体、动词⟩组合成为可能。由于VLM的突破,最近的研究侧重于从VLM转移知识以识别未见过的HOI概念,并在零样本设置上实现有希望的性能增益。
- 作者的方法:我们的工作旨在探索一种更有效的多方面策略,用于零样本HOI中VLM的知识转移
方法
介绍HOICLIP框架
- 3.1 节中描述了模型的整体架构,然后是我们的传输方法的三个关键方面
- 3.2节中,我们介绍了基于查询的知识检索策略,以实现高效的视觉知识迁移
- 3.3 节中,我们介绍了用于动词知识迁移的动词表示适配器和动词分类器提取
- 3.4 节中,我们开发了一种无需培训的视觉语言知识迁移增强方法
- 3.5 节中,我们描述了我们的训练和推理pipeline
1、整体架构
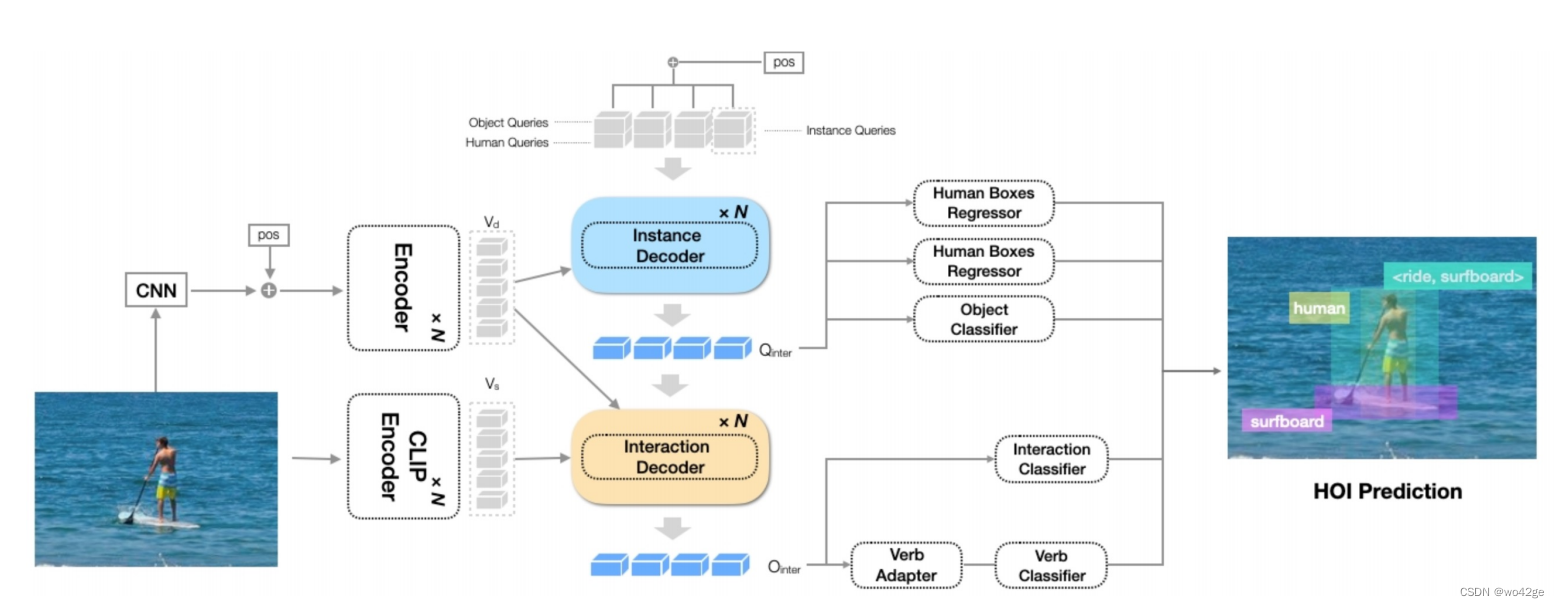
-
我们首先采用基于 Transformer 的端到端对象检测器来定位人和对象:
- 具体来说,给定输入图像 I,我们使用变换器编码器获得空间图像特征图 Vd,然后使用实例解码器和交互解码器分别完成实例检测和交互识别。
- 受GEN-VLKT的启发,实例解码器将两组查询分别作为人和对象的输入,即人类查询Qh和对象查询Qo。
- 最后一个解码器层中的输出对象查询 Oo ∈ RNq×Ce 和人类查询 Oh ∈ RNq×Ce 用于预测人类边界框 Bh ∈ RNq×4 、对象边界框 Bo ∈ RNq×4 和对象类 Co ∈ RNq× Ko ,其中 Ko 是对象类的数量。
-
给定人和物体特征,然后我们引入一种新颖的交互解码器来执行交互识别:
- 其中我们利用先前提取的特征图 Vd 和 CLIP 生成的空间特征图 Vs 中的信息,并通过交叉注意力模块。
- 动词适配器提取动作信息以增强交互表示和识别
- 线性分类器采用交互解码器的输出来预测 HOI 类别,并通过使用 CLIP 语言特征的免训练分类器进一步增强
2、基于查询的知识检索
- zero-shot CLIP:
-
CLIP 通过视觉编码器和文本编码器提取双模态特征。
-
视觉编码器由主干 VisEnc(·) 和投影层 Proj(·) 组成。
-
视觉主干提取视觉空间特征 Vs ∈ RHs×Ws×Cs ,将其馈送到投影层以获得全局视觉特征 Vg ∈ RD。
-
文本编码器 TextEnc(·) 为每个类别提取全局文本表示 Tg ∈ RD×K,其中 K 是类别数。
-
分类 S ∈ RK 计算如下:
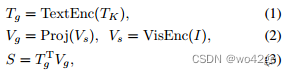
-
其中Tg和Vg是L2归一化特征,TK是描述K类别的句子。矩阵乘法计算余弦相似度。
-
- 具有知识集成的交互解码器:
-
为了预测一对人类和物体查询的 HOI 类别,我们通过将人类和物体特征 Oh 和 Oo 馈送到投影层来生成一组交互查询 Qinter ∈ RNq×Cs。
-
为了充分利用 CLIP 知识,我们建议从 CLIP 中检索交互特征,以更好地与分类器权重中的先验知识保持一致。
-
具体来说,我们保留 CLIP 空间特征 Vs 并将检测视觉特征 Vd 投影到与 Vs 相同的维度:

-
其中 Wi , bi , Wp, bp 为投影参数,V ′ d ∈ RHs×Ws×Cs,Pool 取平均值。
-
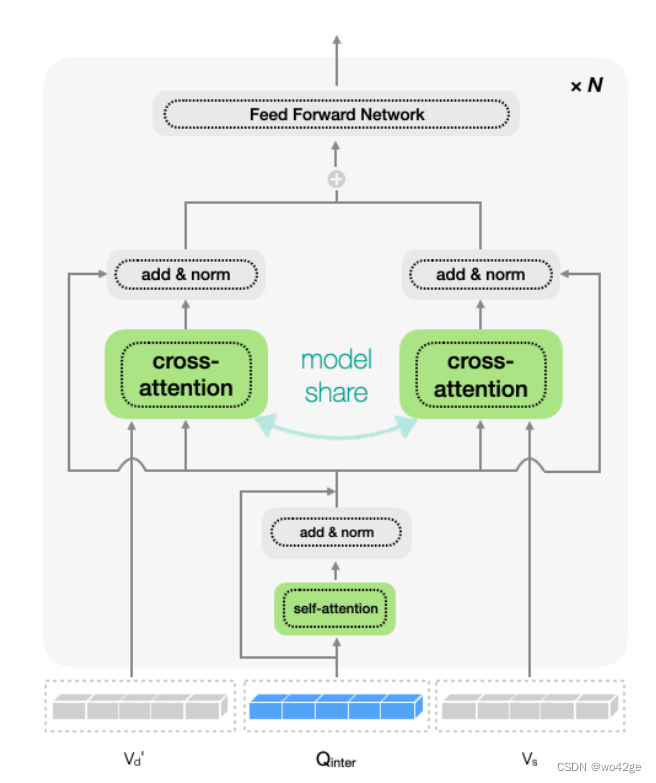
为了引导交互查询 Qinter ∈ RNq×Cs 探索 Vs 和 Vd 中的信息区域,我们设计了一个用于知识集成的交叉注意力模块,其架构如图 3 所示。Qinter 首先通过自注意力进行更新,然后馈送分别进入带有Vs和V’d的交叉注意力模块并获得两个输出特征。最后,我们总结输出并将其输入前馈网络。正式地,
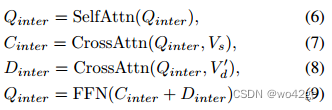
-
其中Vs、V′d分别是键和值,Qinter是共享交叉注意力中的查询。为了提取最终的交互表示 Ointer ∈ RNq×D,我们采用与 CLIP 相同的投影操作,将交叉注意力的输出转换到 CLIP 特征空间,如下所示,
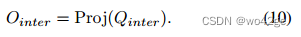
-
该表示将用于基于第 3.4 节中介绍的零样本分类器的交互分类
-
通过这种方式,我们利用实例解码器中的对象和人类信息从 CLIP 的空间特征图中检索交互表示,并从检测器中检索视觉特征。这种基于查询的知识检索设计使我们能够实现高效的表示学习和强大的泛化能力。
-
3、动词类表示
在本小节中,我们介绍了一种新颖的管道来提取全局动词类表示,以及根据 CLIP 特征构建的动词分类器来应对标签不平衡问题。
- 视觉语义算法
为了更好地从自然不平衡的HOI注释中捕获细粒度的动词关系,我们通过视觉语义算法构建了一个动词分类器,它代表了训练数据集的全局动词分布。这里我们假设动词类表示可以从 HOI 的全局视觉特征与其对象的全局视觉特征的差异中得出。该概念如图 4 所示。
具体来说,我们使用覆盖对象和人体边界框的最小区域来表示 HOI 三元组。然后我们将 OBJj 定义为包含对象类 j 的所有实例的集合。此外,我们使用元组(i,j)来表示 HOI 类别,其中 i 和 j 分别代表动词和宾语的类别。类似地,我们将 HOI(i,j) 定义为包含 HOI 类别 (i, j) 的所有实例的集合。对于 HOI 和对象区域,我们使用 CLIP 图像编码器来获取它们的视觉特征,然后采用投影仪将特征映射到全局特征空间。形式上,给定一个区域 R,我们计算其特征如下:
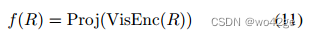
动词类 k 的表示是通过平均 HOI 和对象区域特征的差异来计算的:
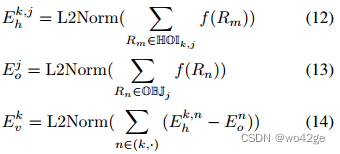
其中 L2Norm 代表 L2 标准化操作,E k,j h , Ej o 是计算出的 HOI 和对象表示。提取的动词类表示是来自 CLIP 的动词概念的先验知识,并用作下面的动词分类器,表示为 Ev ∈ RKv ×D 其中 Kv 是动词类别的编号。
2. 动词适配器
为了使用动词类别表示进行分类,我们设计了一个轻量级适配器模块来基于交互特征Ointer提取动词特征Overb ∈ RNq×D。具体来说,我们使用 MLP 将交互特征映射为动词特征 Overb ∈ RNq×D,并计算动词类别分数如下:

其中动词 logits Sv 计算为动词特征 Overb 和动词类别表示 Ev 之间的余弦相似度。通过这种方式,我们利用 CLIP 视觉编码器中的先验知识从训练数据中提取动词分类器,并设计动词适配器以更好地表示动词。该设计生成细粒度的动词信息,有利于 HOI 预测。
4、零样本HOI增强
作者在这里引入了由CLIP文本编码器的先验知识生成的HOI分类器,它为HOI分类提供了一种无需训练的增强方法
-
具体来说,我们利用 CLIP 学习到的视觉语言对齐构建了一个零样本 HOI 分类器,其中 CLIP 文本编码器 TextEnc 嵌入的标签描述用作分类器权重。我们将每个 HOI 类别转换为带有手工制作模板的句子,“一个人的照片 [Verb-ing] a [Object]”。将模板输入 CLIP 文本编码器 TextEnc 以获得 HOI 分类器 Einter ∈ RKh×D,其中 Kh 是 HOI 类别的数量。
-
为了利用零样本 CLIP 知识,我们根据图像 Vg 的全局视觉特征和 HOI 分类器 Einter 计算一组附加的 HOI logits。为了过滤掉低置信度预测,我们只保留最高的 K ∈ [0, Kh] 分数。
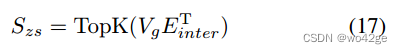
-
其中 Topk 是选择具有最高 K 分数的 HOI logits 的操作,S i zs 表示第 i 个 HOI 类别的分数。
-
更新后的 Szs 是一种高置信度的免训练 HOI 预测,它利用零样本 CLIP 知识有利于尾类预测。
-
给定零样本 HOI 分类器 Einter,我们还使用它根据 3.2 节中计算的交互表示 Ointer 生成交互预测分数
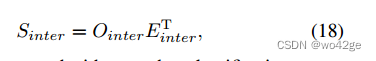
-
它将与其他两个分类分数相结合
5、推理与训练
在本小节中,我们将介绍我们框架的训练和推理管道的详细信息。
1.训练
-
在训练过程中,我们通过结合 HOI 预测 Sinter 和动词预测 Sv 获得训练 HOI logits St
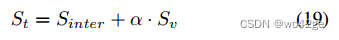
-
其中 α ∈ R 是权重参数。对于二分匹配过程,我们遵循之前基于DETR 框架的 HOI 检测器,并使用匈牙利算法将真实值分配给预测。
-
匹配成本包括人和物体边界框回归损失、物体分类损失、交互联合损失和 HOI 分类损失。辅助损失用于解码器层的中间输出。
2.推理
-
零样本 HOI 预测 Szs 用于推理时间。最终 HOI logits Si 的获得方式为:
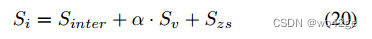
-
按照之前的方法,我们使用来自实例解码器的对象分数 Co 来计算 HOI 三元组分数,可以写为
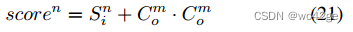
其中n是HOI类别索引,m是与第n个HOI类别对应的对象类别索引。最后,根据置信度得分,将三元组 NMS 应用于 top-K HOI 三元组。
实验
在本节中,我们介绍了一系列实验分析和综合消融研究,以证明我们方法的有效性。
1. 实验设置
数据集
- HICO-DET和 V-COCO上进行实验。
- HICO-Det 包含 47,776 张图像(38,118 张用于训练,9,658 张用于测试)。
- HICO-Det 的注释总结了 600 个 HOI 三元组类别,由 80 个对象类别和 117 个动作类别组成。
- 在600个HOI类别中,有138个类别的训练实例数少于10个,定义为Rare,其他462个类别定义为Non-Rare。
评估指标
- 使用平均精度(mAP)作为评估指标。
- 如果满足以下标准,我们将 HOI 三元组预测定义为真阳性示例:
- 1)人类边界框和物体边界框的 IoU 大于 0.5 w.r.t(GT 边界框);
- 2)预测的交互类别准确。
零次设置
我们以四种方式构建零样本设置实验:
- 稀有第一未见组合(RF-UC)
- 非稀有第一未见组合(NF-UC)
- 未见动词( UV)
- 看不见的物体(UO)
- 看不见的组合(UC)
具体来说,UC 表示训练期间包含所有动作类别和对象类别,但有些HOI 三元组(即组合)丢失。
- 在RFUC设置下,尾部HOI类别被选择为不可见类,而NF-UC则使用头部HOI类别作为不可见类。
- UV设置和UO设置分别表示训练集中未得出某些动作类别和对象类别。
- 对于 RF-UC 和 NFUC,我们选择 120 个 HOI 类别作为未见过的类别。
- 对于 UV,HOI 类别涉及 80 个对象类别中随机选择的 12 个对象,被定义为不可见类。
- 对于UV,HOI类别涉及20个随机选择的动词类别,在训练期间没有给出。
- 对于 UC,我们遵循中未见过的组合设置。
实验细节
- 为了与以前的方法进行公平比较,我们使用 ResNet-50 作为主干特征提取器和 ViT-32/B CLIP 变体。
- Transformer 编码器和 Transformer 解码器的层数设置为 3。查询数量设置为 64。
- 我们使用优化器 AdamW 训练 HOICLIP,批量大小为 16,权重衰减为 10−4 。
- 训练 epoch 的总数设置为 90。对于前 60 个 epoch,我们将初始学习率设置为 10−4,并在最后 30 个 epoch 中使用学习率下降。
- 参数使用 MS-COCO 训练的 DETR 进行初始化。
- CLIP 模型和分类器在训练期间是固定的。
- 我们在 2 个 NVIDIA A40 GPU 上以批量大小 8 进行实验。
2.部分数据实验
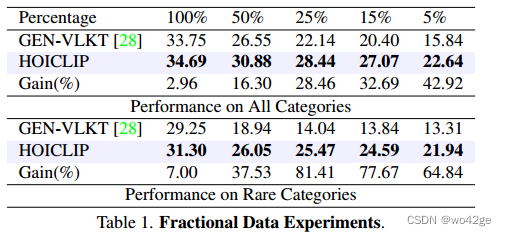
- 为了验证 HOICLIP 的数据效率,我们将训练数据分别减少到 50%、25%、15% 和 5%,并将我们的性能与使用这些部分数据设置训练的最先进方法进行比较。
- 我们分别在表 1 中展示了所有 HOI 类别和稀有 HOI 类别的性能,其中对整个数据集执行了视觉语义算法。
- 我们在补充材料中提供了部分数据视觉语义算法的结果。
- 在每个部分训练数据场景中,HOICLIP 都显着优于对手,尤其是在罕见的 HOI 类别上。
- 随着可用数据百分比的下降,HOICLIP 保持了令人满意且稳定的性能,而其他方法则由于训练数据不足而遭受了急剧下降。
- 我们观察到 HOICLIP 在 25% 分数数据场景下的稀有类别上实现了超过 81.41% 的显着性能提升。
- 该性能证明了我们的知识转移方法的效率和稳健性。
3. 常规设置下的分析
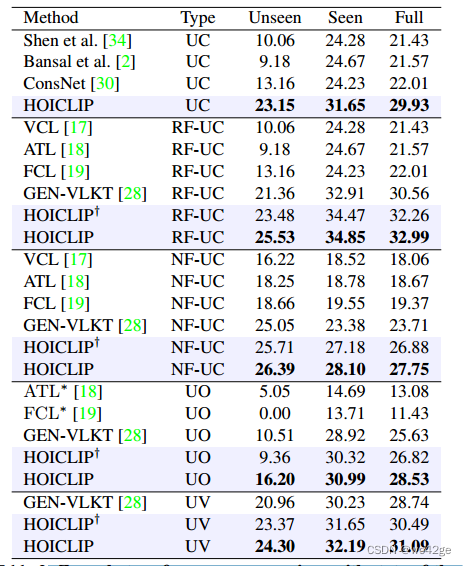
为了充分了解 HOICLIP 的特性,我们对各种零样本设置、RF-UC、NF-UC、UV 和 UO 进行了实验。我们将 HOICLIP 与几种最先进的方法进行比较。结果如表2所示,证明了HOICLIP的优越性能。
与 GEN-VLKT相比,我们在 NF-UC 设置下对所有类别实现了令人印象深刻的 +4.04 mAP 增益,在 UO 设置下对稀有类别实现了 +5.69 mAP 改进。
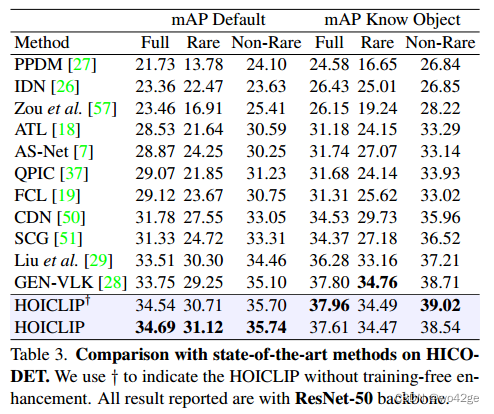
此外,为了进一步证明 HOICLIP 的有效性,我们将 HOICLIP 的性能与默认 HOI 检测设置上的现有技术进行了比较。我们在表 3 显示了数据集 HICO-DET 上的性能。
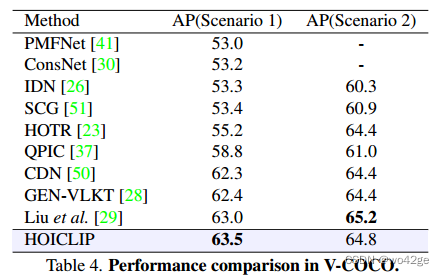
与 GEN-VLKT 相比,HOICLIP 取得了有竞争力的性能,特别是在稀有类别中 mAP 提高了 +1.87。对于数据集 V-COCO,结果如表 4 所示。我们在场景 1 中超越了之前的方法,达到了 63.5 AP 的最新性能。鉴于 V-COCO 的规模相对较小,该改进不如 HICO-DET 显着。
4. 消融研究
网络架构设计

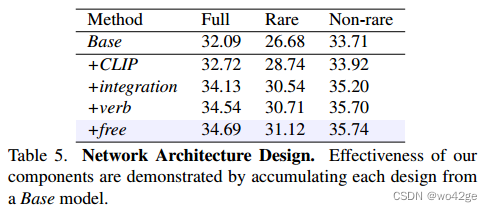
为了展示我们模型设计的特点,我们首先遵循 GEN-VLKT 的设计引入一个基线模型,但删除了知识蒸馏部分,在表 5 中表示为 Base。第一个修改是更改交互解码器的图像输入特征从检测视觉特征Vd到来自CLIP图像编码器的视觉特征Vs,表示为+CLIP。我们观察到稀有类别的 mAP 提高了 2.06。接下来,我们用知识集成交叉注意层替换交互解码器中的传统交叉注意层,并将输入更改为Vd和Vs,表示为+integration。结果显示,+integration 优于所有现有的 HOI 探测器,与 +CLIP 相比,增益增加了 +1.41 mAP。为了实现更深入的交互理解的目标,我们添加了来自视觉语义算术的动词适配器和动词分类器,表示为+verb。所有类别的性能进一步提升至 34.54 mAP。最后,我们引入了+verb的免训练增强,记为+free。无需额外培训即可获得 +0.15 mAP 的增益。我们还在补充材料中提供了部分数据设置下的消融研究。
动词分类器提取
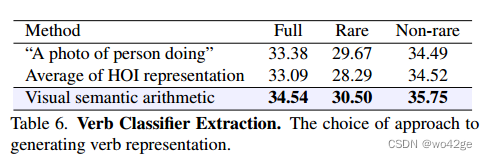
我们在以下实验中探索不同的方法来提取动词表示。一个简单的替代方案是使用类似于 CLIP 中使用的方式的句子来描述人类行为。例如,我们可以用一句话来描述骑行动作:“一个人骑行的照片”。使用 CLIP 生成每个 HOI 类别的表示后,我们还可以通过取涉及动词的所有 HOI 表示的平均值来获得动词的表示。对于所有三种方法,我们使用所有动词的表示来初始化动词适配器的权重。我们的实验结果如表 6 所示。
我们看到,在全类设置中,与句子描述方法相比,我们的视觉语义算术策略获得了 1.16 mAP 的性能增益,与 HOI 平均方法相比,获得了 1.45 mAP 的性能增益。
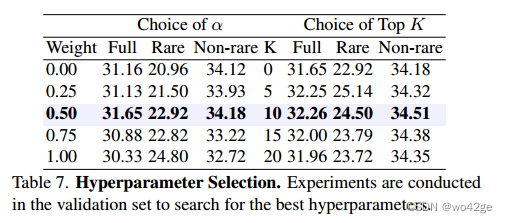
在这一部分中,我们讨论每个模块的超参数的选择。与之前的工作不同,我们使用单独的验证集,其详细信息在补充材料中提供。
我们用不同的 Sv 权重训练我们的模型,发现权重 0.5 达到了最佳性能。我们取消了 Sv 权重 α 的选择,结果如表 7 所示。我们还以相同的方式选择用于免训练增强的 k 值。我们发现 k = 10 可以获得最佳性能。所有结果如表7所示。
模型效率分析
我们在单个 NVIDIA A100 GPU 上评估 HOICLIP 和现有技术 GEN-VLKT。
HOICLIP 的推理时间(55.52 ms/img)与 GEN-VLKT(52.80 ms/img)相当,小差距是从额外的前向通过 CLIP 编码器开始的。
考虑到性能的提高,这样的权衡似乎是值得的。 HOICLIP 中的附加参数只会导致推理成本略有增加。此外,对于模型训练,由于其 CLIP 模块经过微调,GEN-VLKT 在常规设置下的可训练参数数量为 129.8M,而我们的 HOICLIP 由于固定的 CLIP 视觉编码器而具有 66.1M 可训练参数。
可视化

我们将预测结果和注意力图可视化,以展示图 7 中我们方法的特征。
注意力图来自交互解码器中用于知识集成的交叉注意力模块。我们观察到 CLIP 视觉特征的注意力图集中在更广泛的交互相关区域,而注意力图检测主干仅强调对象区域。
结论
我们提出了 HOICLIP,一种将视觉语言模型知识转移到 HOI 检测的新颖框架。 HOICLIP 以基于查询的方式检索 CLIP 知识,并利用空间视觉特征进行高效、鲁棒的交互表示学习。我们还通过视觉语义算术从 CLIP 的先验知识中提取动词分类器,并引入动词适配器以实现更深入的交互理解。为了进一步提高模型的泛化能力,我们通过 CLIP 的文本特征对 HOI 分类进行免训练增强。大量的实验证明了在完全监督和零样本场景中的卓越性能和高数据效率。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









