






今天我们来写一个boost搜索引擎!
(后续如果有更新,这个博客也会更新)
gitee连接:boost搜索引擎: boost搜索引擎
首先我们要介绍一下我们这个项目,我们项目的目的是通过我们的搜索引擎能够通过关键字查找到对应的网页,并且可以点击跳转到指定网页,相当于一个搜索框!
首先我们可以去boost官网去下载boost库的网页文件!
然后我们主要需要的是其中的网页文件,所以我们将下载好的压缩包解压以后,将其放在我们的项目文件中!(boost_1_84_0/doc/html)

然后我们可以看一下我们的网页文件,会发现里面除了网页的标题,内容,url之外其他的我们并不需要,并且这些东西会干扰对网页内容的提取,所以我们必须要去掉这些无用的标签!


所以我们要编写一个模块,先将这些原始文件处理干净!
于是我们就可以开始写我们的parser模块了!
首先我们看我们的主框架,整个程序的思路是,首先我们要提取出整个文件的内容,然后将所有文件的内容写入一个文件,然后用分隔符进行分割,然后再对文件主要信息进行提取

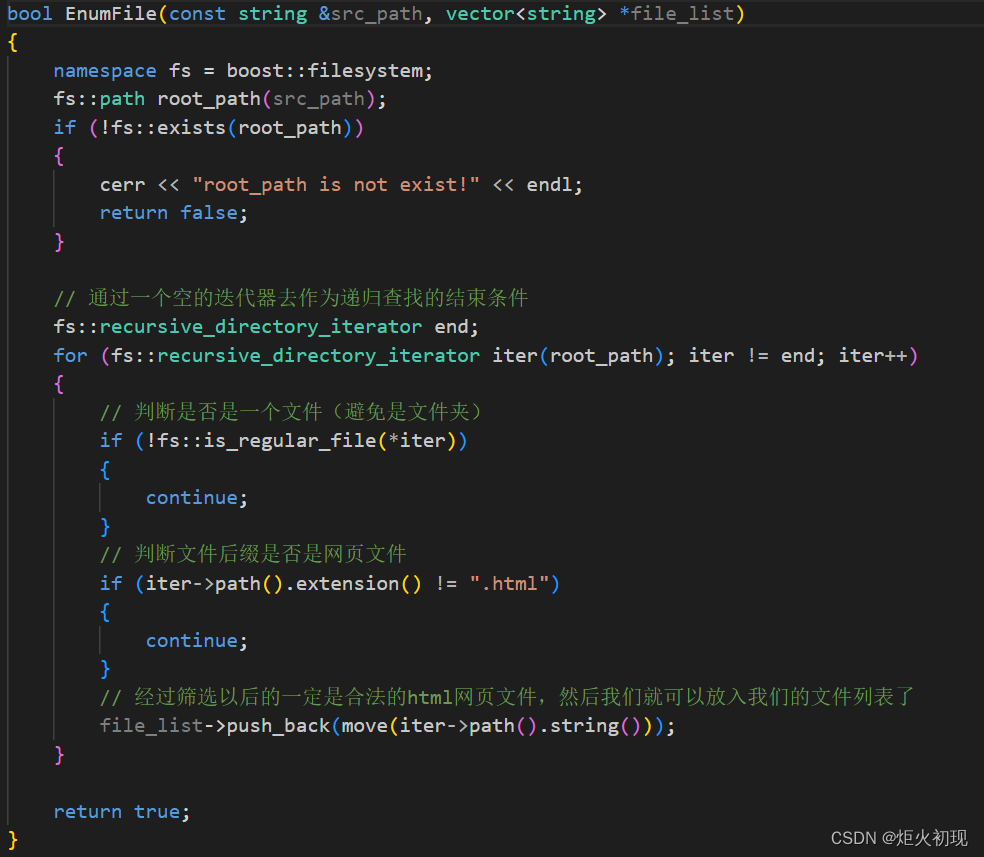
然后是获取所有合法的html文件的路径
然后就可以开始读取文件内容并且进行解析,主要就是获取每个网页的标题,内容,url
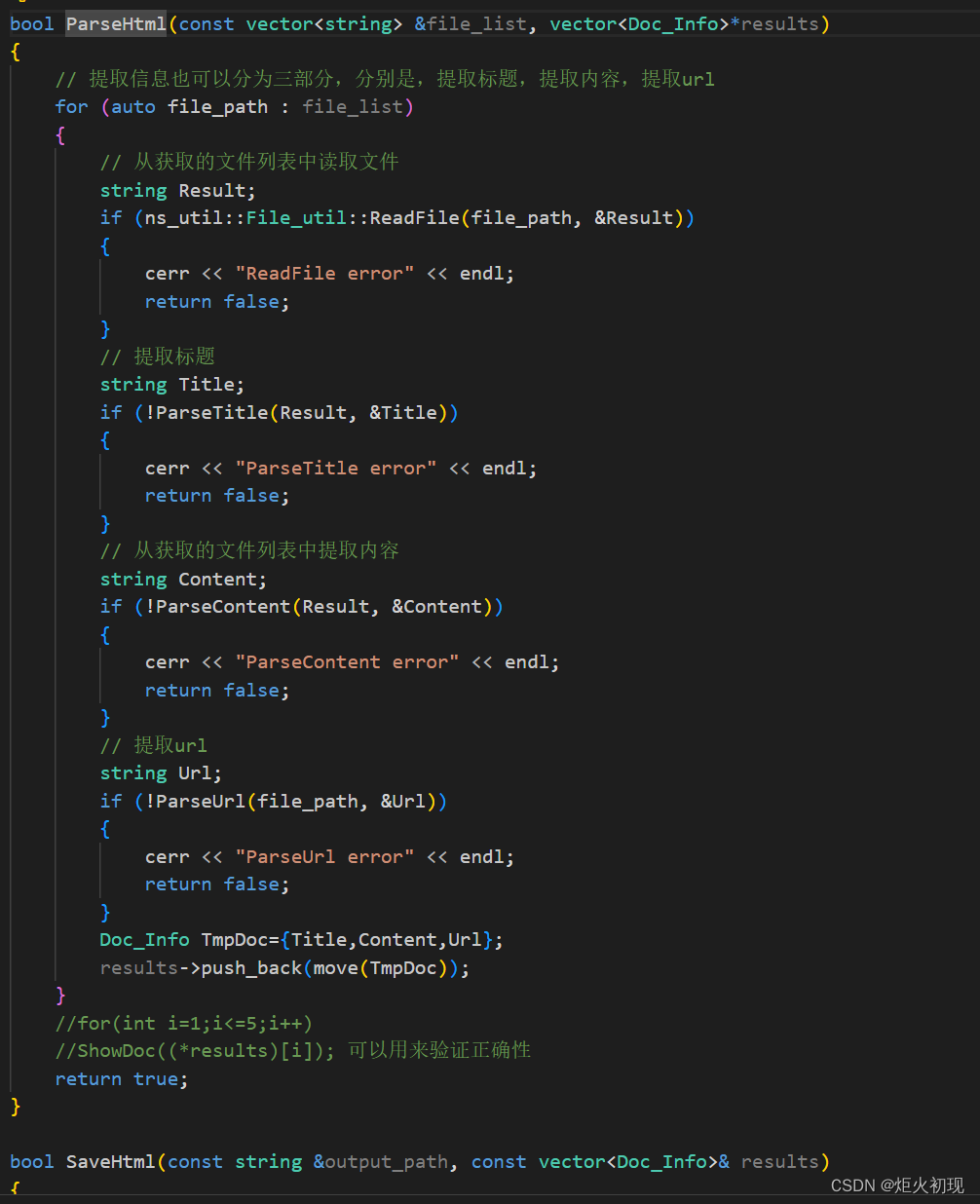
此处的ReadFile是我们封装进util头文件中的函数


然后就是将解析好的内容进行保存!存入一个大的文本之中!
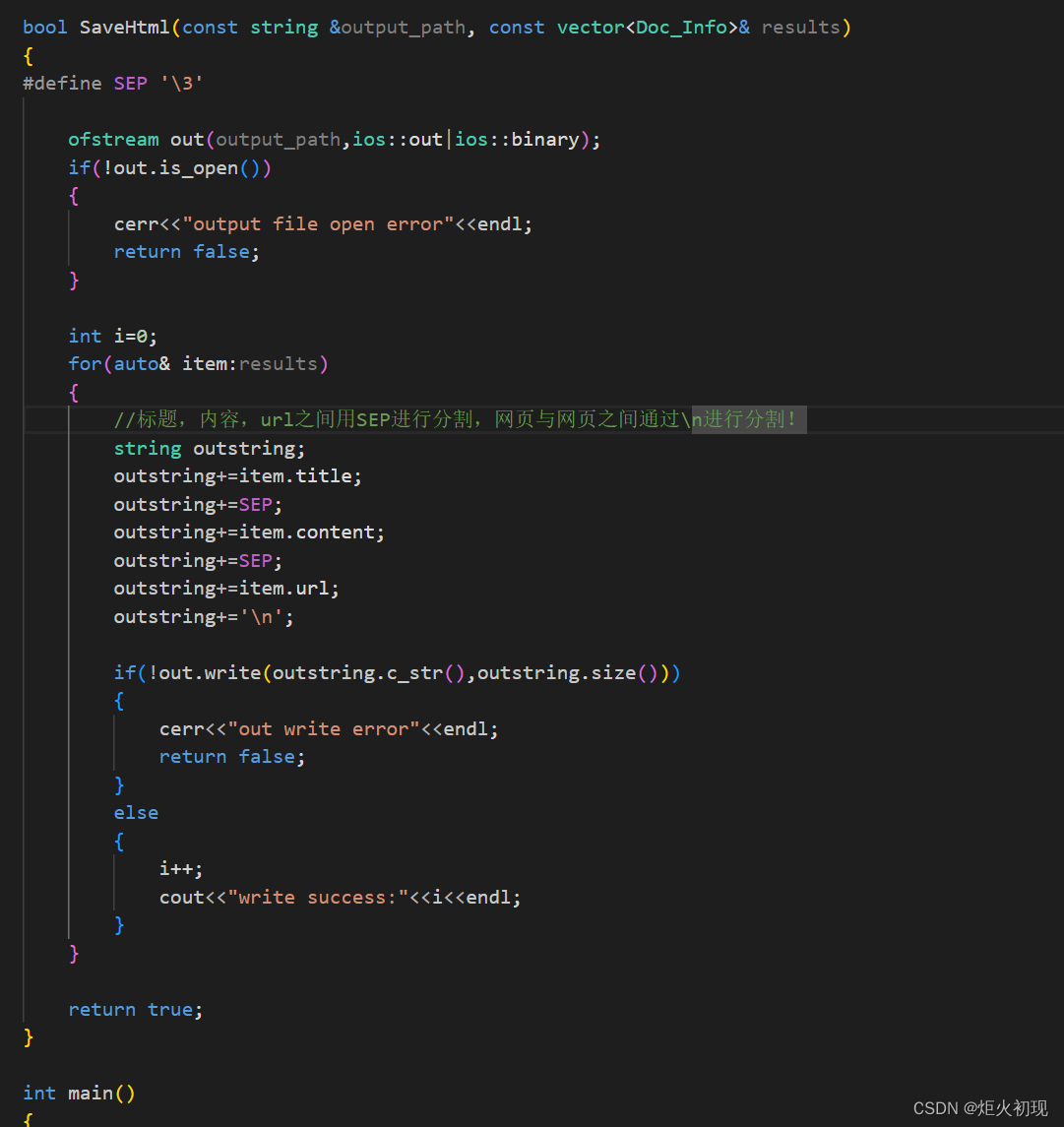
至此parse就基本上完成了!
然后我们就要建立正排索引和倒排索引了。
首先解释一下正排索引和倒排索引是什么意思。
正排索引就比如我们翻书一样,我们先确定翻到那一面,然后翻页到指定页面进行观看。
倒排索引就是我们根据内容反向搜索页数,就像我们字典的目录一样。
然后我们来看具体实现
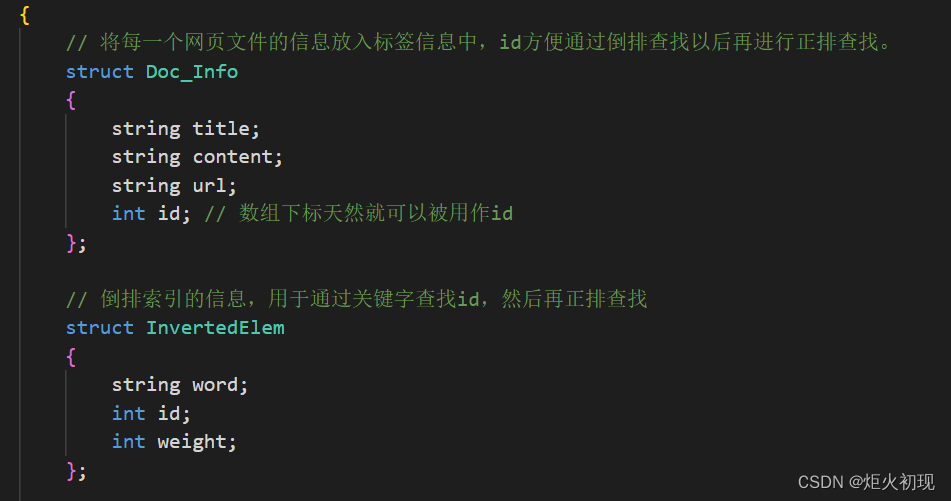
首先我们要构建每个页面的基本信息结构,一个页面我们关注的主要就是title,content,url。除此之外就不是我们需要关心的信息了。并且数据已经在parser阶段清理,我们现在的任务就是把文档里面的数据读取到我们的数据结构中。
再就是InvertedElem,即一个关键字对应的文章id和权重。
然后我们开始编写创建标签的函数,主要就是创建正排拉链和倒排拉链。

创建正排拉链和倒排拉链的实现如下!

主要就是把保存好的网页数据提取出来,再通过分隔符将数据解析出来,形成一个Doc_Info,然后再保存到我们的正排拉链(其实就是一个vector中)即可,这样下标和id会有一一对应的关系。也方便了我们的倒排索引查到id以后再进行查找!


倒排索引也不复杂,主要就是获取内容(主要工作就是屏蔽大小写和词频统计)
这个地方的词频统计采取非常简单的方法,即标题里面出现权重为10,内容出现权重为1,然后求和即可。(真正的浏览器远远不是如此简单的,不过小项目只需要能展现出排序的原理和功能接可)
然后我们创建每个合法的InvertedElem之后就可以将其放入我们的map(inverted_list)中去了.这样关键字就会和网页信息产生对应效果了。
然后就是为了我们的效率,我们的目录也只需要才去单例模式,也即目录只用创建一次即可,避免重复创建!(注意多线程的问题,要加锁)
然后留出我们的正排索引和倒排索引的调用接口即可,实现如下。
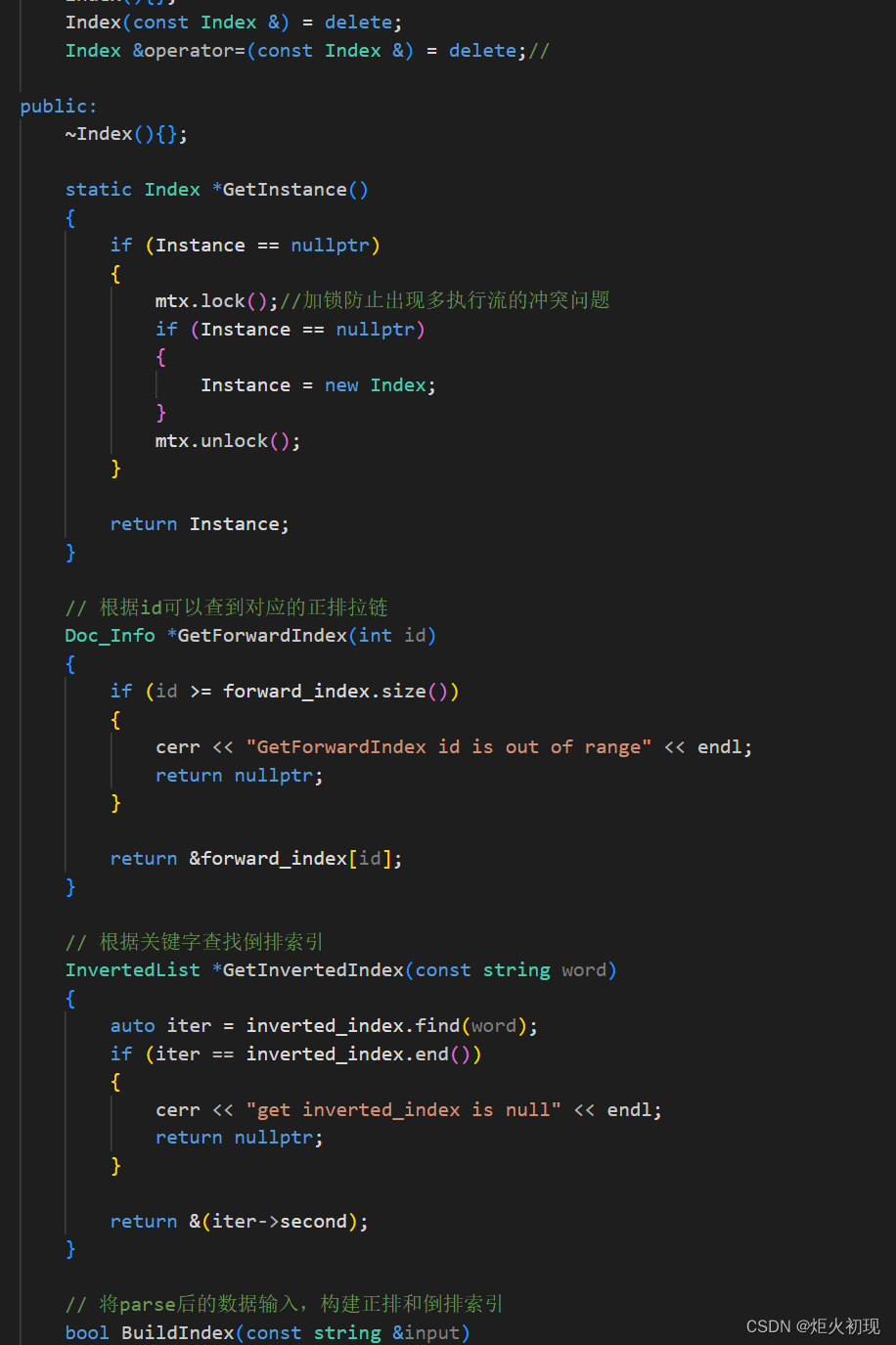
至此,我们的创建索引的工作也基本完成,接下来就实现我们的查找模块!

首先就是初始化搜索也即建立索引即可。
然后我们的网页中一般形成的都是摘要,而非直接展现内容,所以我们还要实现一个获取摘要的函数。
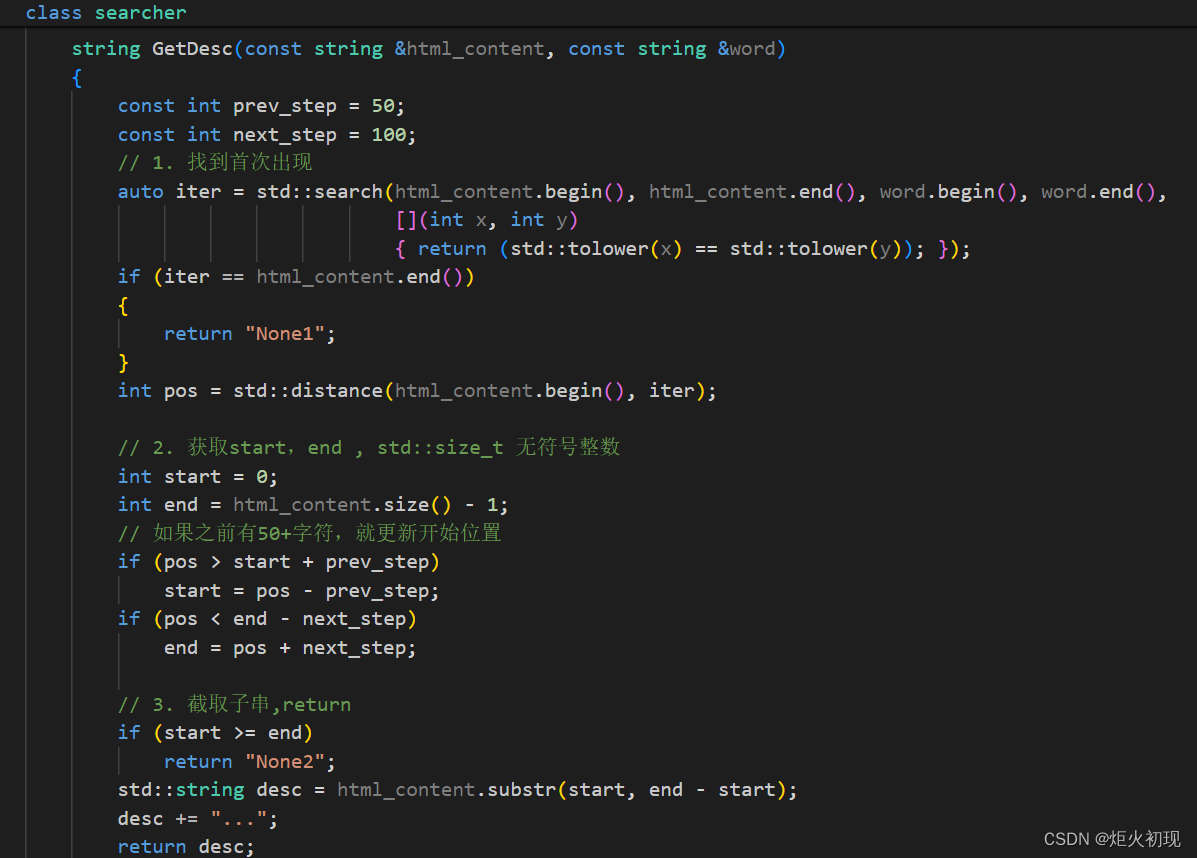
主要就是呈现出关键字附近的文字即可!
最后我们就要实现最为关键的功能,也即搜索功能。
输入查询,然后我们返回json串(对数据进行序列化)
主要就是先对我们的搜索内容进行分词(调boost库的分词功能,CutString对库进行了封装,写在util.hpp中,我们后面再看)。
然后就是根据分词的内容,进行查找!这个地方我们要注意一个问题,由于分词,所以一个搜索会被分为多个关键字,每个关键字都会查找到一些文章,而这些文章的内容很有可能是重复的,所以我们必须进行去重工作!
实现也不难,我们可以准备一个map然后针对同一个id我们对其权值进行累加,然后就对网页实现了去重的操作!
去重以后再把这些内容放入我们的倒排拉链之中!
然后进行第三步,根据权重进行降序排序,使用sort对权值排序即可,比较简单。
最后我们再调用jsoncpp库,把我们的倒排拉链进行序列化即可进行返回即可!


至此我们的查找功能也基本实现完毕!
最后就是我们的http服务器的搭建。
只要调用cpp-httplib库对报文进行响应即可!具体用法大家可以去查文档!
(注意:一定要先升级g++编译器到高版本再进行编译,否则将会出现问题!)

最后我们再编写前端的网页文件即可(然后把根目录给httplib服务器,会自动进行使用前端文件)
(通常默认的网页都叫index.html)
下面是该文件的实现(由于前端文件不是我写的,这个地方就不过多讲解了,大家看一下就好)
















 1568
1568











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









