






目录
0.观前提醒:
(1)本文所有代码资源都已经上传至Gitee码云,强烈建议源码与Xmind思维导图食用此文。
(2)本文是保姆级项目展示,耐心看一定能看懂,且你对搜索引擎技术的理解将比别人高一个层次。
1.项目背景介绍
(1) 在如今的信息时代下,检索信息成为几乎人人的"必需品",在此大背景下,出现了诸如百度,360,搜狗等大型的搜索引擎,我们可以通过做一个微型的搜索引擎达到"管中窥豹"的效果,明晰搜索引擎的运行原理。
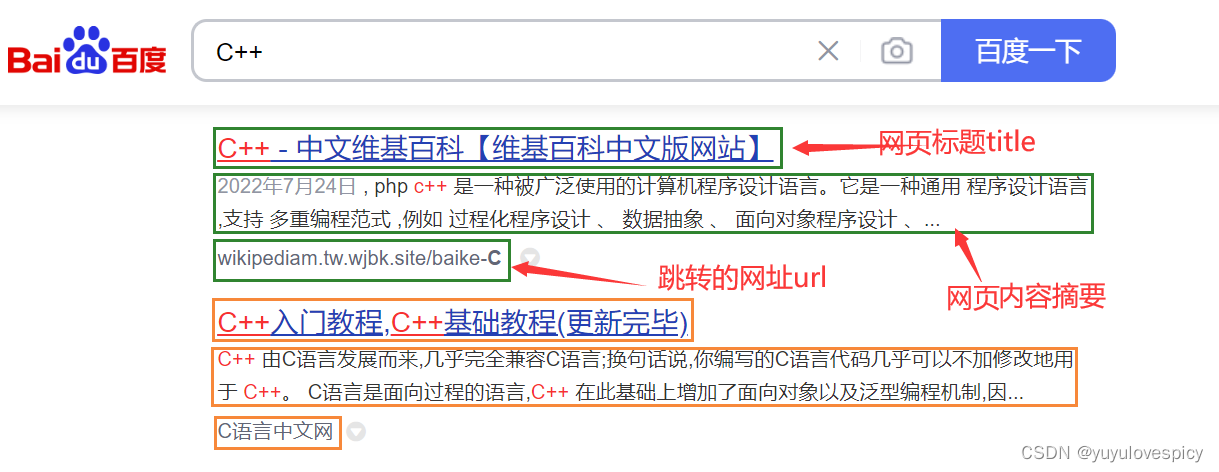
图片1 搜索引擎网页的基本构成
(2) boost作为C++的准标准库,在C++代码编写中使用频率很高,但是在官方的网站中,却没有站内搜索,并不便于用户的快速查找。
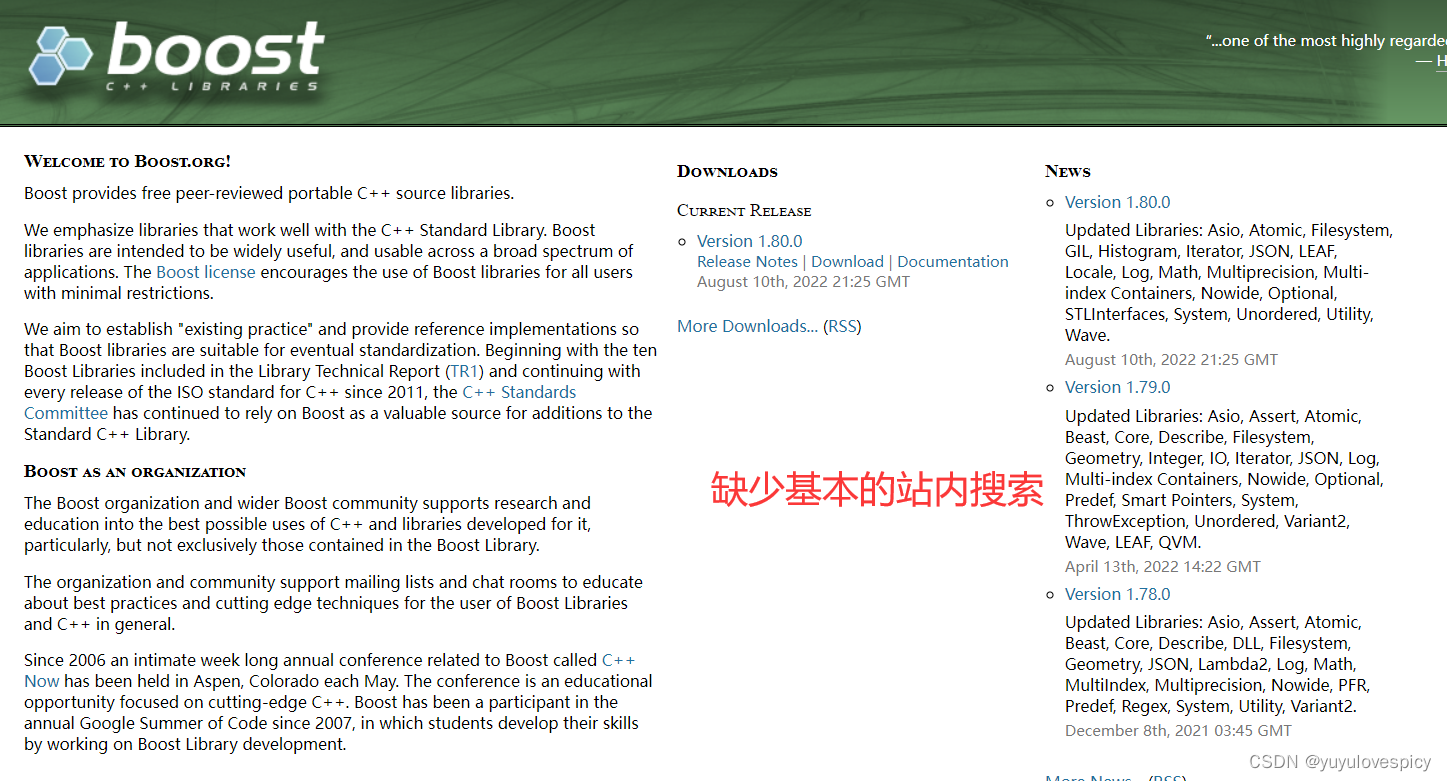
所以我们的项目boost搜索引擎,就是用来提供对boost官方库中资源的搜索服务的。
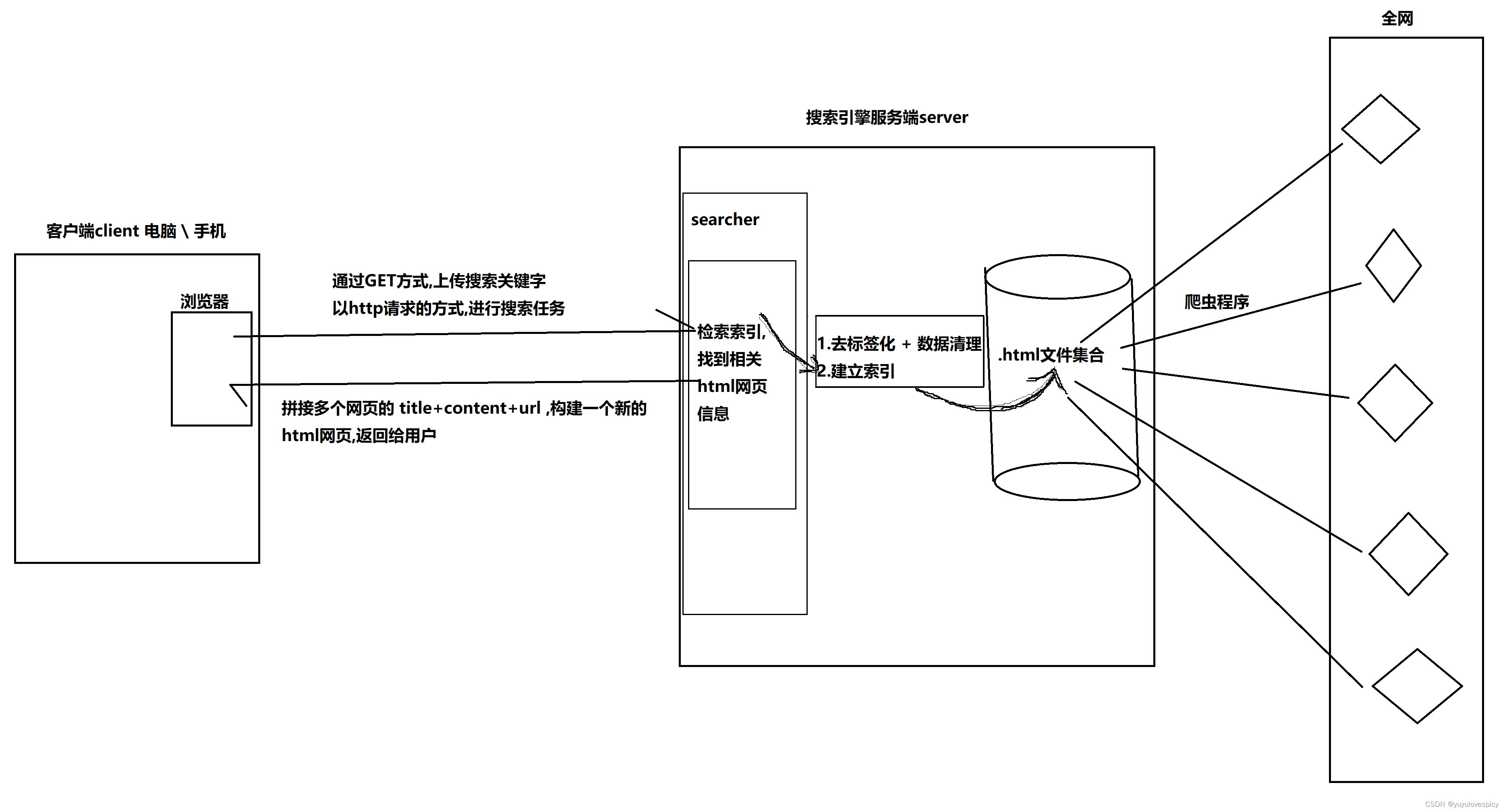
2.搜索引擎宏观原理
(1)通过爬虫程序在全网中抓取相关的html网页信息,存至server服务器端的磁盘当中。
(2)对这些html文件,进行去标签化与数据清理,即只保留网页文件中的主要信息(title,content,url)。
(3)对去标签化清理后的数据,建立索引,方便我们进行后续的检索查找。
(4)客户端在浏览器中发起http请求,服务端在索引中检索到相关的html网页主要信息。
(5)拼接多个网页的(title+content+url)信息,构建出一个新html网页,返回给用户。
PS:爬虫程序,涉及法律,技术等因素限制,所以我们暂时只爬取一个boost库官方网站,且通过正规
渠道下载boost库的相关文件。
3.搜索引擎技术栈与项目环境
技术栈:
后端:C/C++,C++11,STL,boost准标准库,Jsoncpp,cppjieba,cpp-httplib
前端:HTML5,CSS,JS,jQuery,Ajax
项目环境:
Centos7云服务器,vim/gcc(g++)/Makefile,VS2022/Vscode
4.正排索引 && 倒排索引 - 搜索引擎基本原理
文档一: 郑成功打败了荷兰殖民者。
文档二: 郑成功收复了台湾。
4.1正排索引
正排索引:就是从文档ID中找到文档内容(或文档内的关键字)
| 文档ID | 文档内容 |
| 1 | 郑成功打败了荷兰殖民者。 |
| 2 | 郑成功收复了台湾。 |
4.2文档分词
对目标文档进行分词(目的: 方便建立倒排索引与查找)
文档1: [郑成功打败了荷兰殖民者。] : 郑成功/打败/荷兰/殖民者/荷兰殖民者
文档2: [郑成功从荷兰手中收复了台湾。] : 郑成功/荷兰/台湾/收复台湾
PS:停止词如 "了" , "从" , "吗" , "the" , "a" 等,在我们分词的时候不纳入考虑范围。
4.3倒排索引
倒排索引:根据文档内容进行分词 , 整理不重复的各个关键字 , 对应联系到文档ID的方案
| 关键字(具有唯一性) | 文档ID,weight(权重) |
| 郑成功 | 文档1,文档2 |
| 打败 | 文档1 |
| 荷兰 | 文档1,文档2 |
| 殖民者 | 文档1 |
| 荷兰殖民者 | 文档1 |
| 收复 | 文档2 |
| 台湾 | 文档2 |
| 收复台湾 | 文档2 |
总之,大致过程就是先使用倒排索引,通过关键字找到文档ID。
再使用正排索引,通过文档ID找到文档内容。
用户输入 : 郑成功 -> 倒排索引中查找 -> 提取出文档ID{1,2} -> 根据正排索引
-> 找到文档内容 -> title+content+url 文档结果进行摘要 -> 构建响应结果
PS:后续我们倒排索引找到文档ID后, 在网页中,需要按照权重对不同文档进行先后的排序显示,所以我们在倒排索引这里需要增加权重weight信息项。
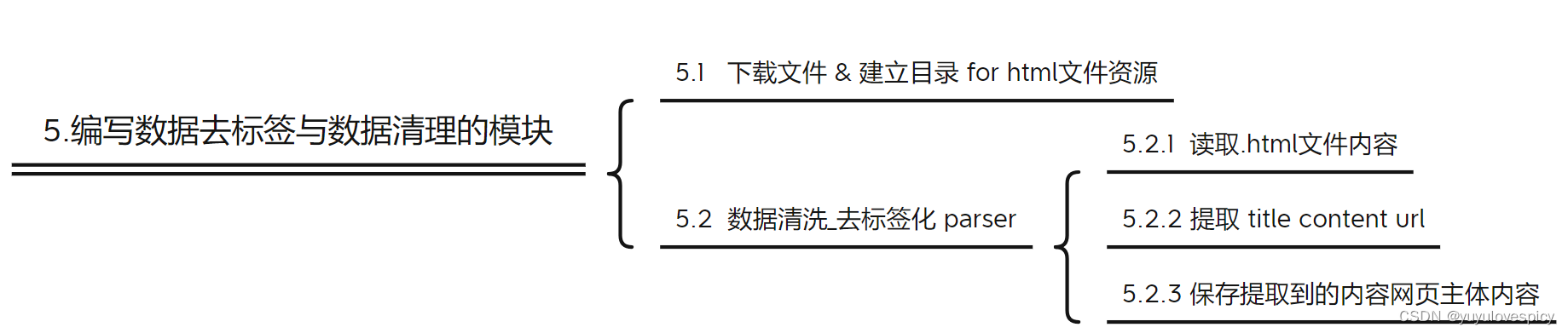
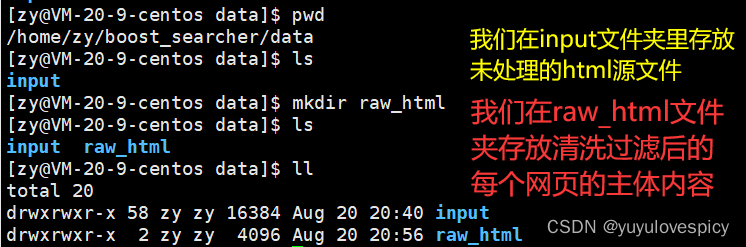
5.编写数据去标签与数据清理的模块 Parser
5.1获取相关boost资源
(1)进入官网 https://www.boost.org 进行相应资源下载(我们以boost1.8为例)
(2)下载后载入云服务器中
PS:这里需要使用lrzsz进行云服务的文件上传 , 如果没有安装可以执行 sudo yum install lrzsz 指令进行安装。

PS:我们获取的基本资源是boost_1_80_0/doc/html/* 这个文件夹里面的内容
主要是因为云服务器配置并不允许我拷贝来那么多资源,配置好的小伙伴可以
cp boost_1_80_0/doc/*
整站搜索NO... 部分站资源搜索YES!
5.2去标签化思路构建
我们随便打开一个.html原生文件,观察其内容
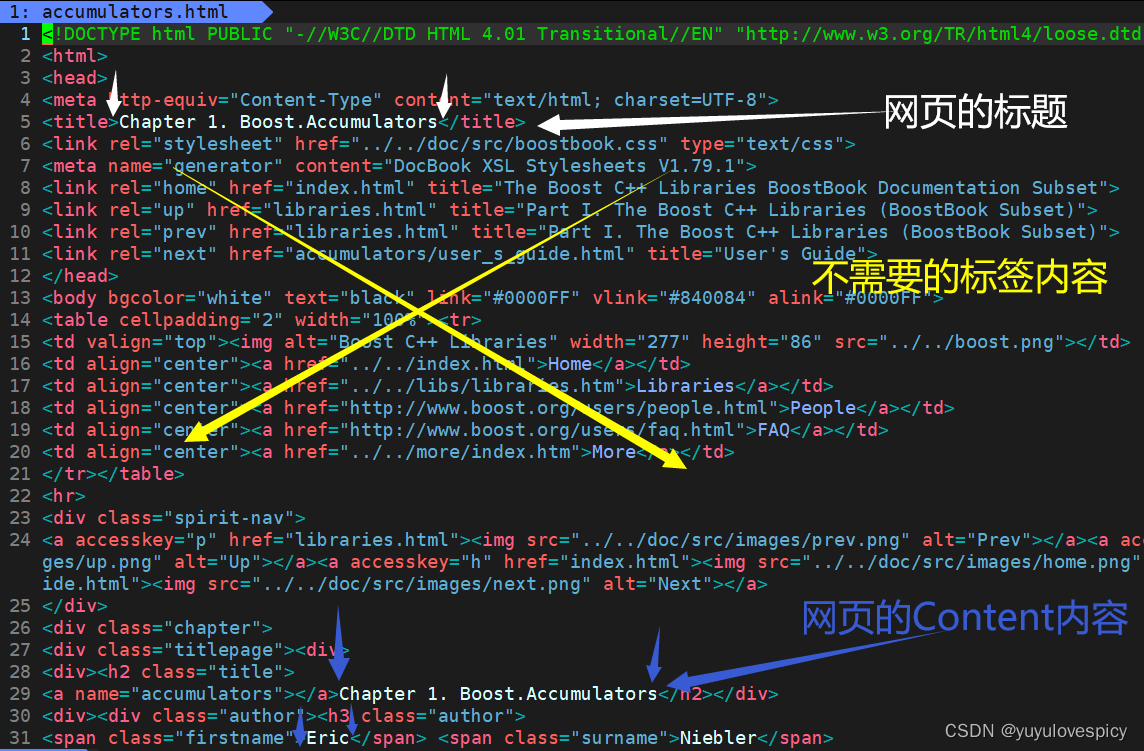
我们的目的是提取出一个网页文件的 title + content + url, 得到每一个网页的去标签化内容 ,。
所以就需要过滤掉<...>等并不需要的标签内容 ,
最终将每个网页文件的主体三件套 title + content + url 进行保存。
总思路:
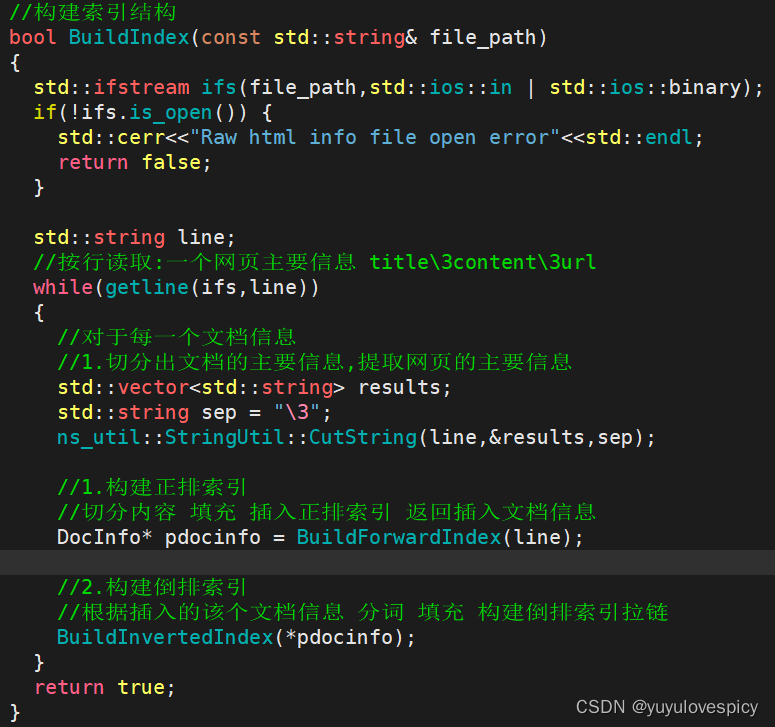
就是把每个文档内容都进行解析去标签化后,写入raw_html文件夹中的同一个文件当中。
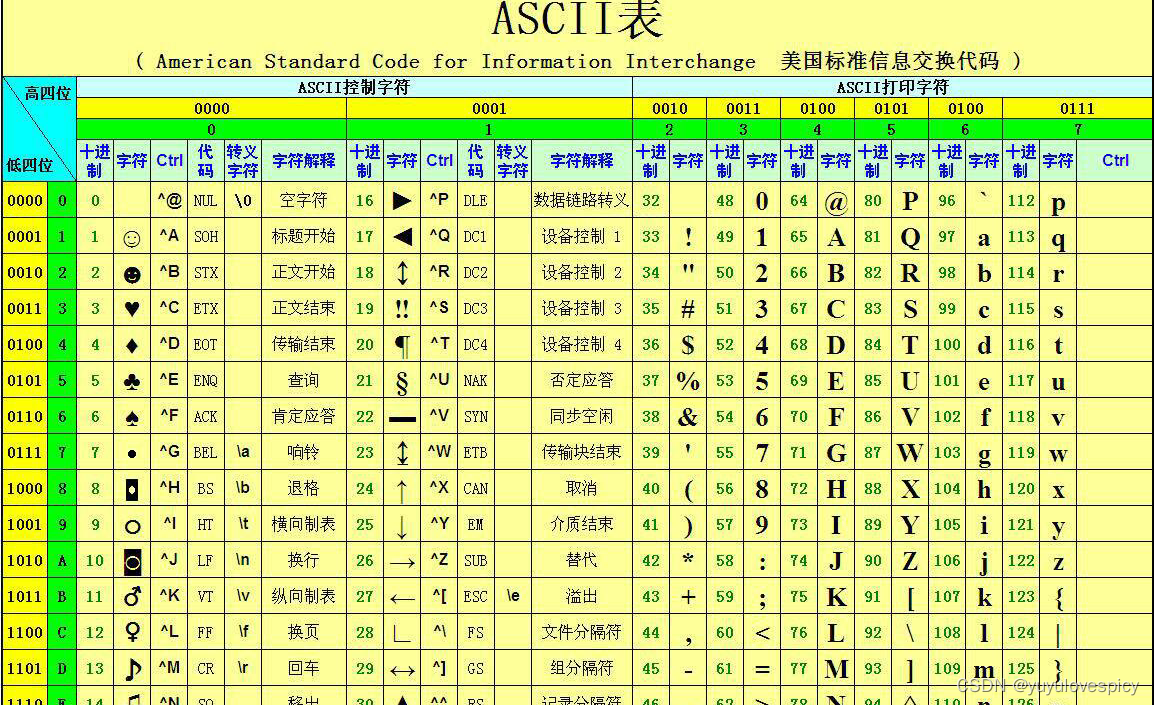
PS: 在保存网页数据的时候,我们使用 '\3'作为分隔符
这是因为在ASCII表中 , 控制字符是不可显示字符 , 即无法打印。
在我们获取的文档内容(即data/input中的html网页文件)中,里面基本上都是可打印字符,基本上不会有不可显示的控制字符。
如此以来也就不会污染我们的文档内容啦。
5.3去标签化代码实现
我们创建parser.cc文件进行去标签化工作
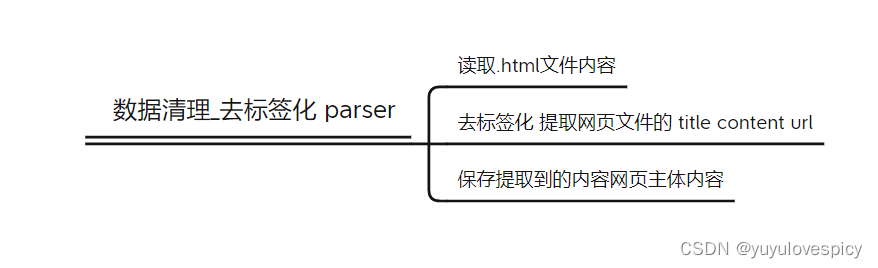
5.3.1网页文件去标签化代码的基本框架:
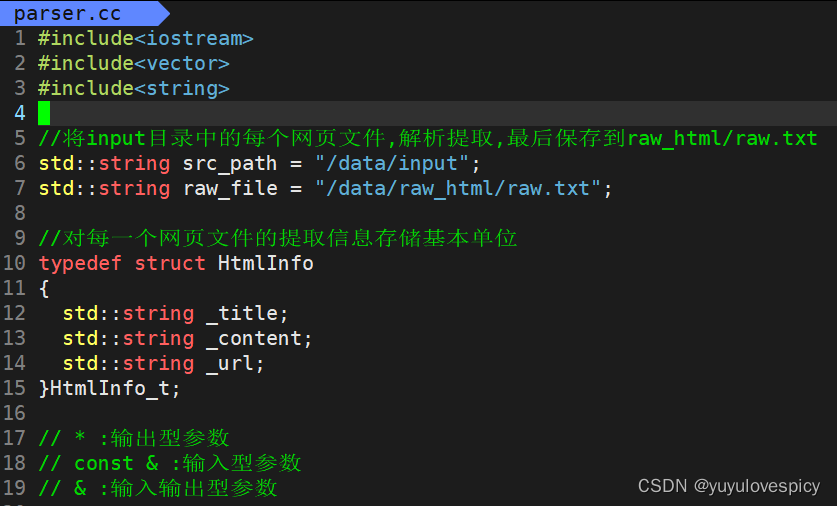

5.3.2网页文件解析接口的分别实现
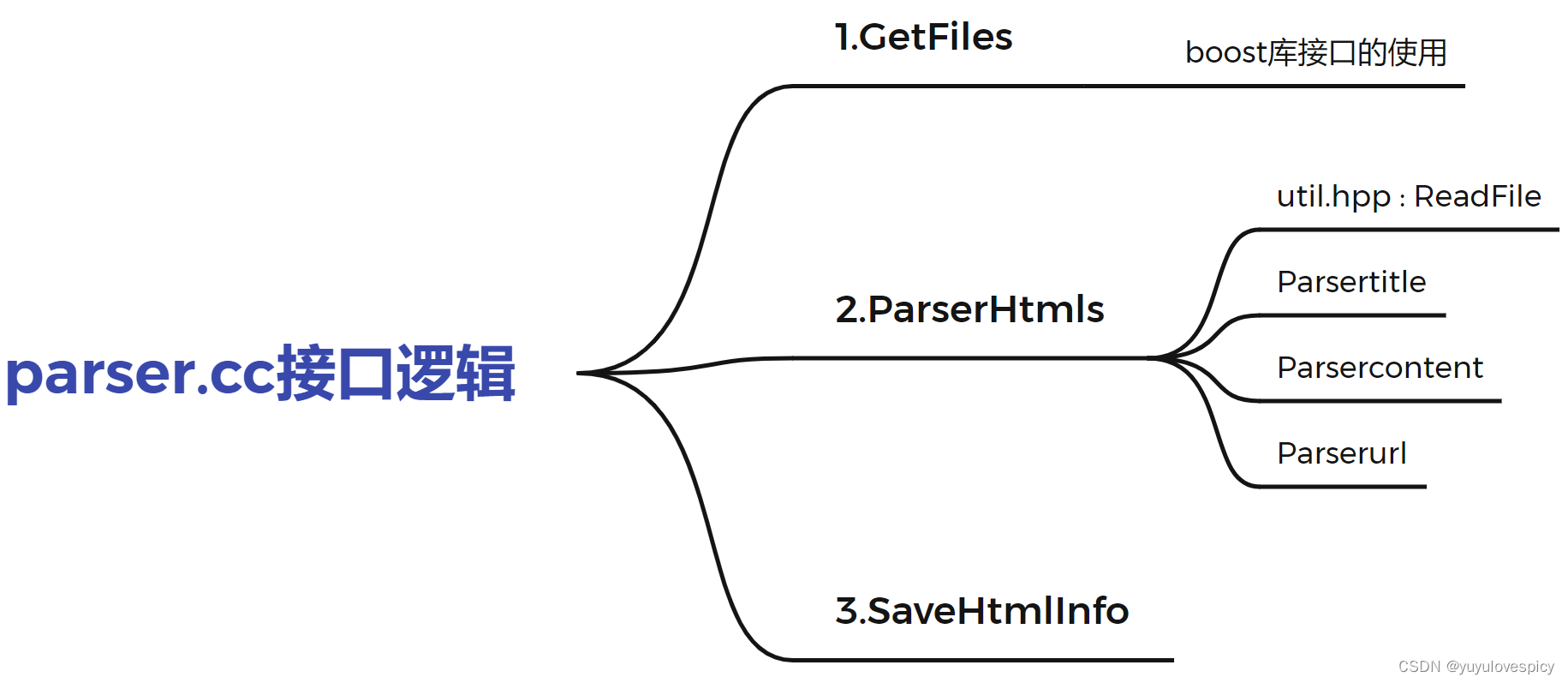 #1.GetFiles接口的实现:
#1.GetFiles接口的实现:
要实现GetFIles接口,就是要在/data/input/文件夹下 , 提取每个html网页文件的路径名称。
这时候就需要借助boost库中的接口来完成这一任务。
#1.1 认识使用boost库接口
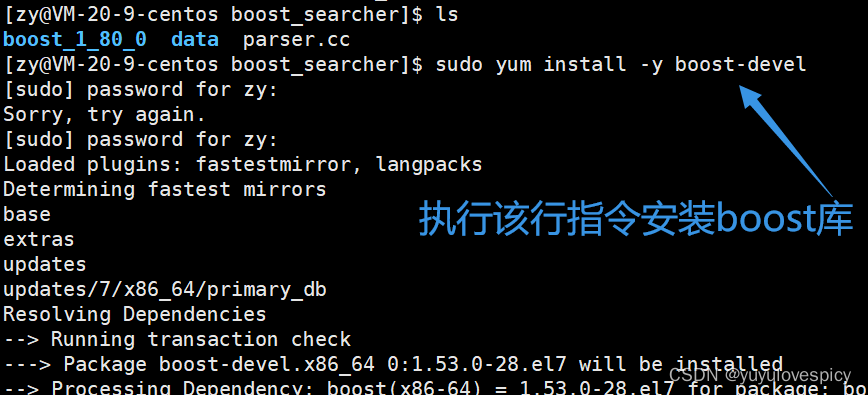
这里做一个区分,我们做站内搜索的版本是1.80 , 我们写代码要使用的boost库是1.53版本。

在云服务器中对boost库进行安装: (sudo yum install -y boost-devel)
在boost官方中可以找到相应接口的使用手册: (如下是进入方法)

#1.2 编写GetFiles接口
下面开始我们的编写GetFiles接口的代码部分: (不要忘记#include<boost/filesystem.hpp>哦)
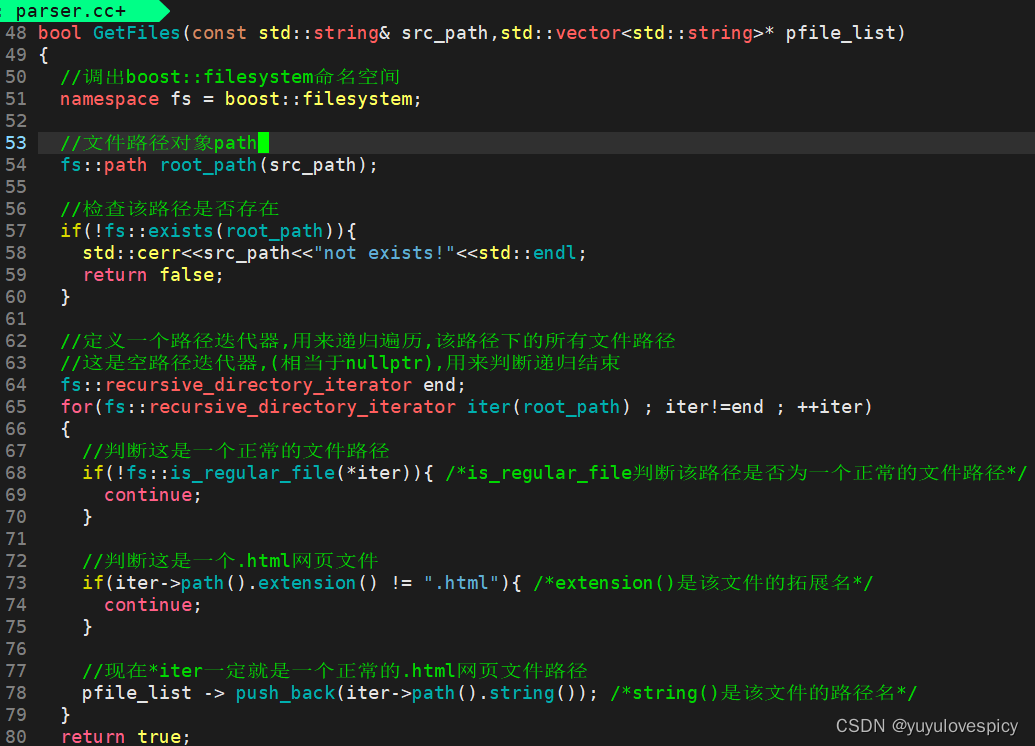
现在我们Getfiles已经把data/input/目录下的所有.html文件名路径,读取到了file_list中,
下一步就是根据所有的文件名路径,打开每一个.html文件,读取+解析文件(数据清洗,去标签化)
只提取出每个文件的title content url,再将一个个提取内容保存到result中。
#2.ParserHtmls接口的实现:
任务就是实现这四个函数,从而实现对每一个.html文件的读取解析提取。
ParserHtmls函数基本结构:
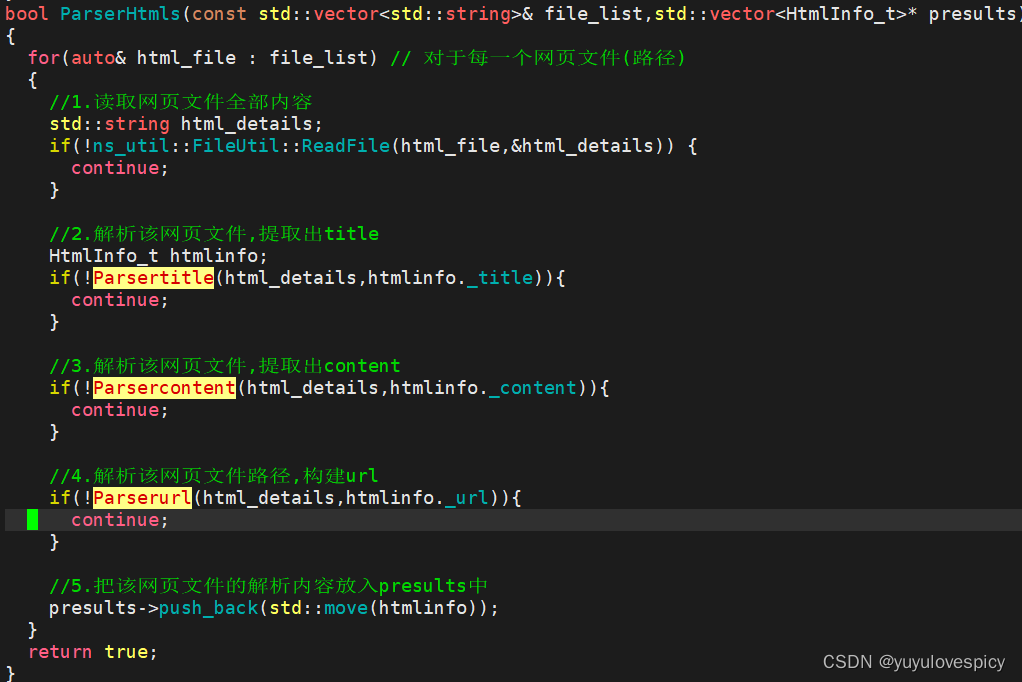
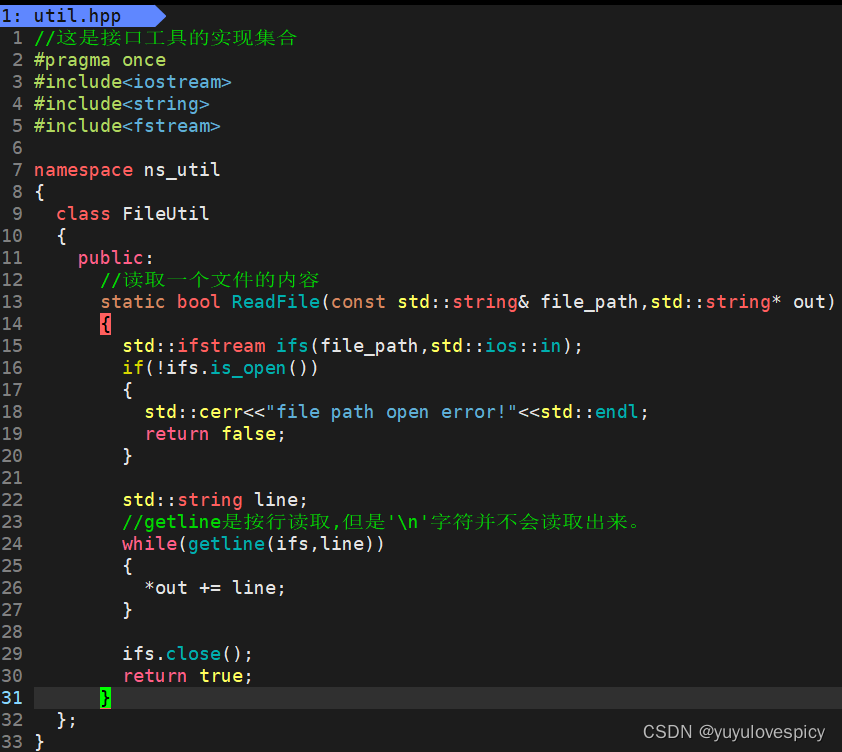
#2.1ReadFile接口:
#2.2Parsertitle接口:
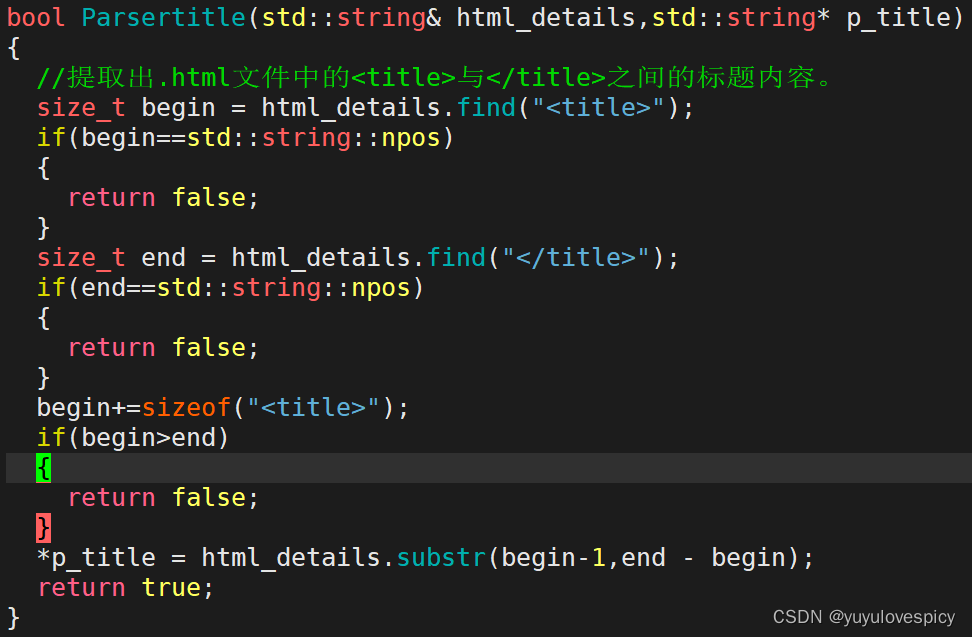
#2.3Parsercontent接口:
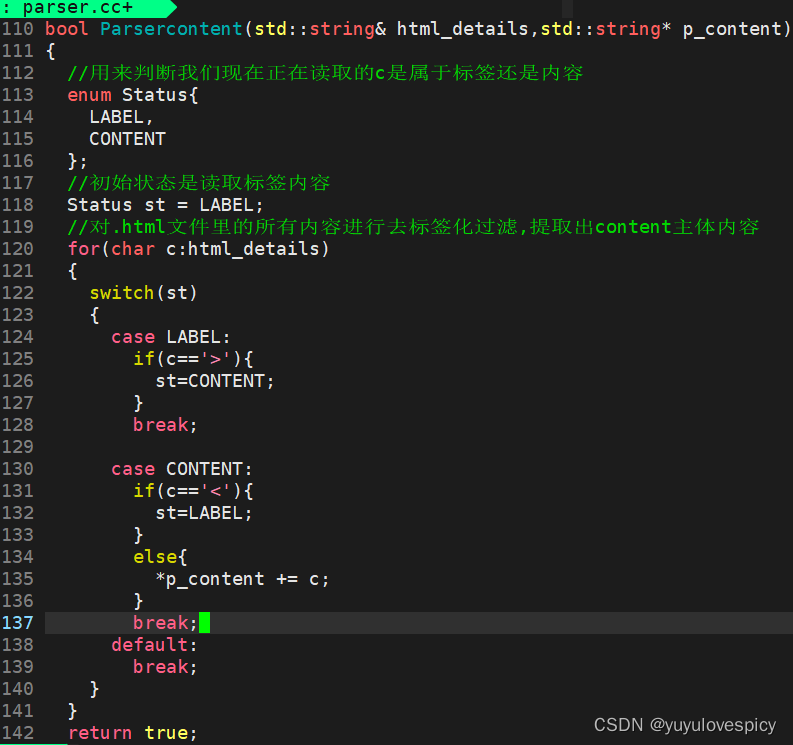
#2.4Parserurl接口:
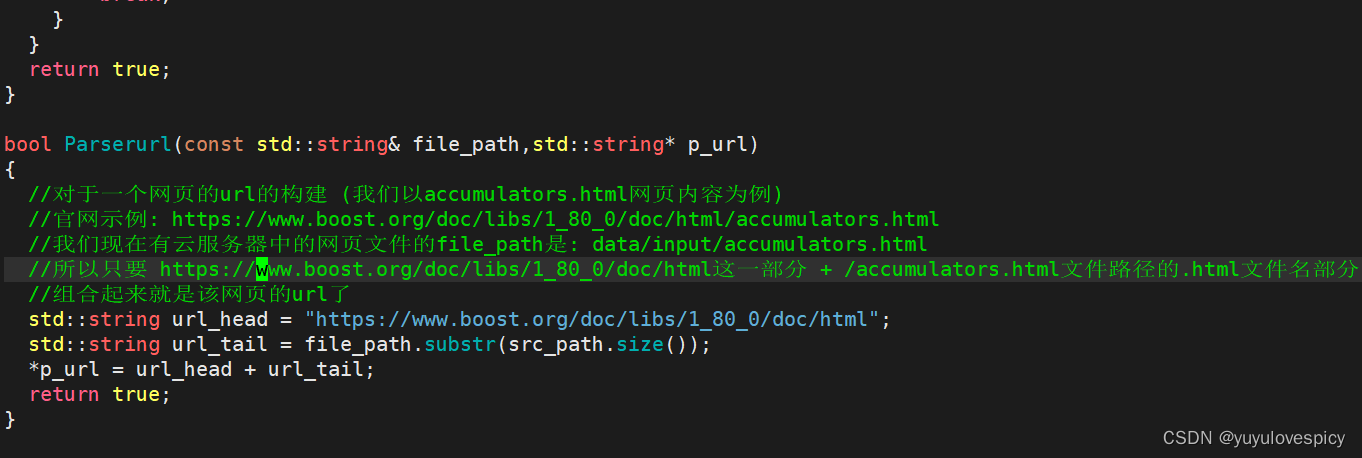
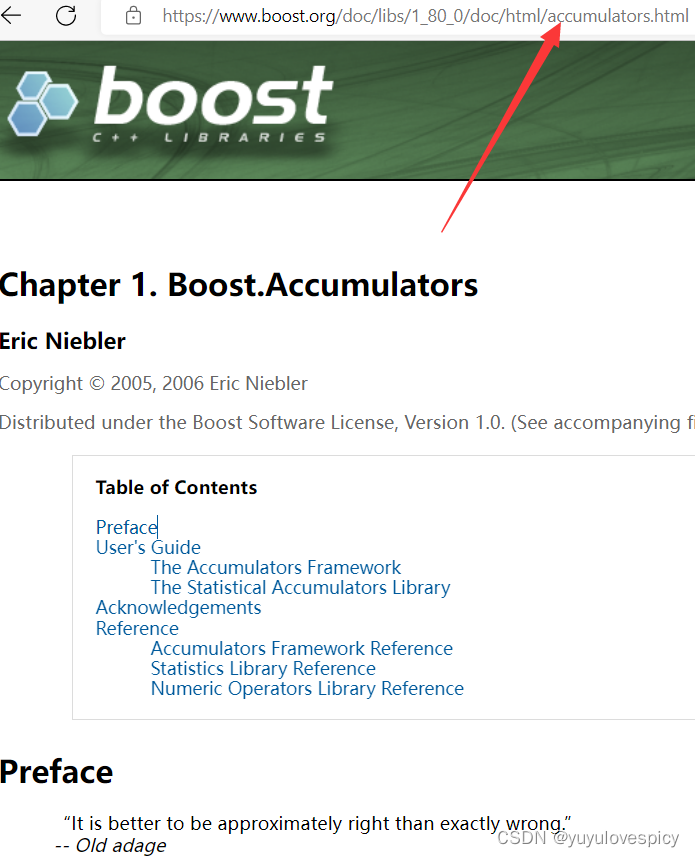
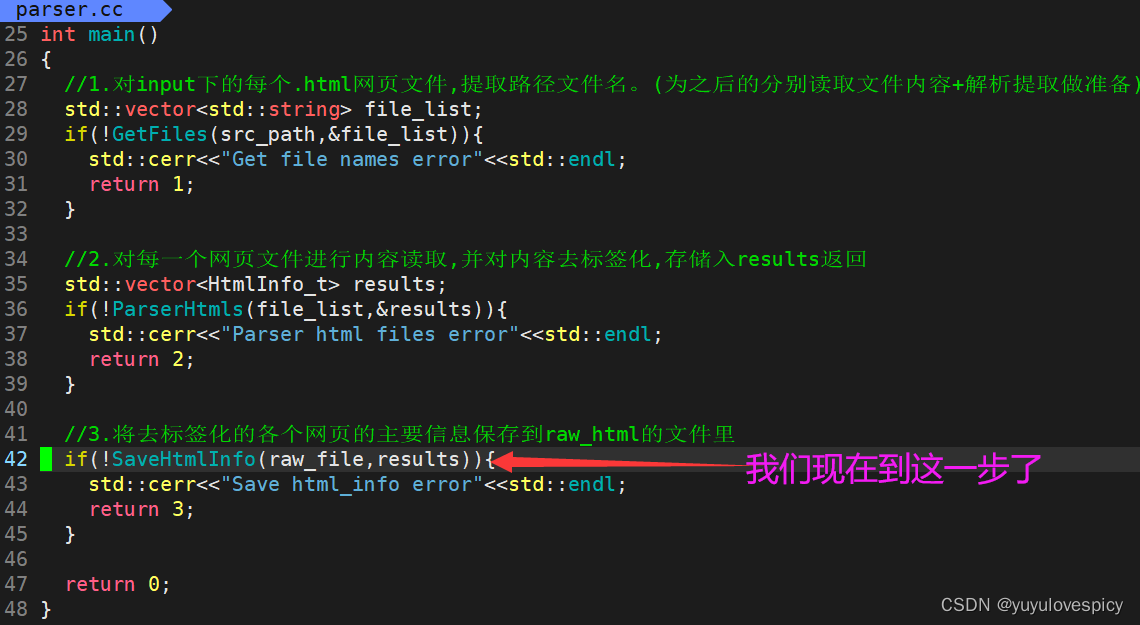 #3.SaveHtmlInfo接口的实现:
#3.SaveHtmlInfo接口的实现:
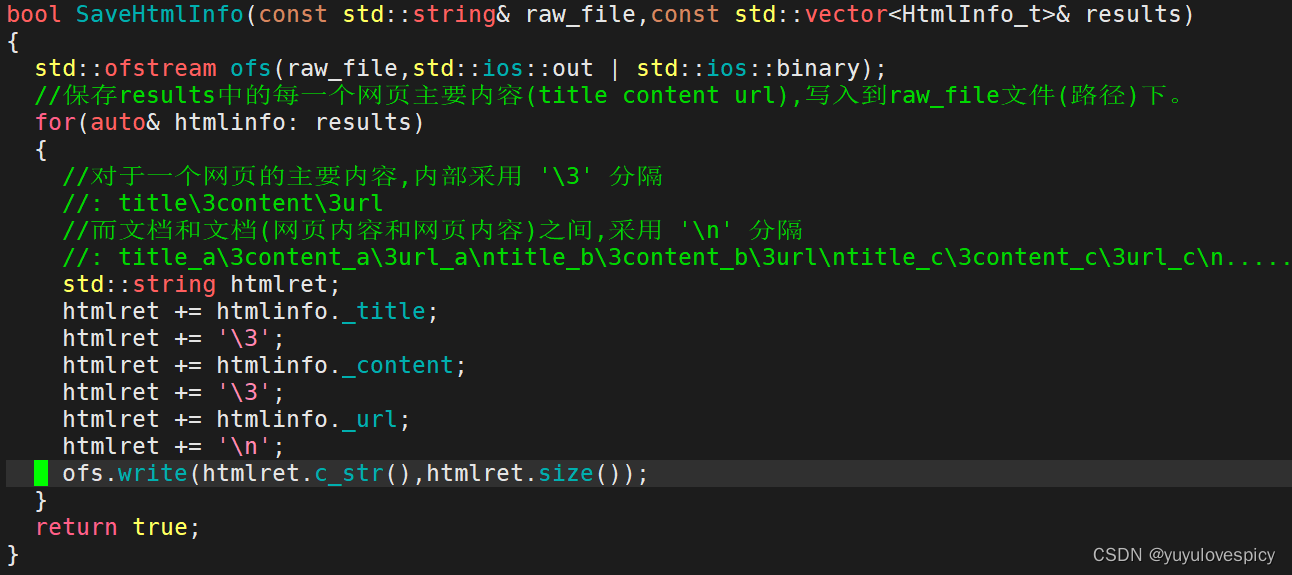
PS:
('\3'作为控制字符,不可显示性质的内容,用其分隔可不污染原文档主体内容)
一个文档,即一个html的三件套(title+content+url),内部采用\3分隔。 <不采用\n分隔>
文档与文档之间采用\n分隔。 <不再采用\3分隔>
主要是因为 后续我们对/data/raw_html/raw.txt的读取时,
使用getline一次读取文件一行\n , 读取单个文档的效率就提高了!
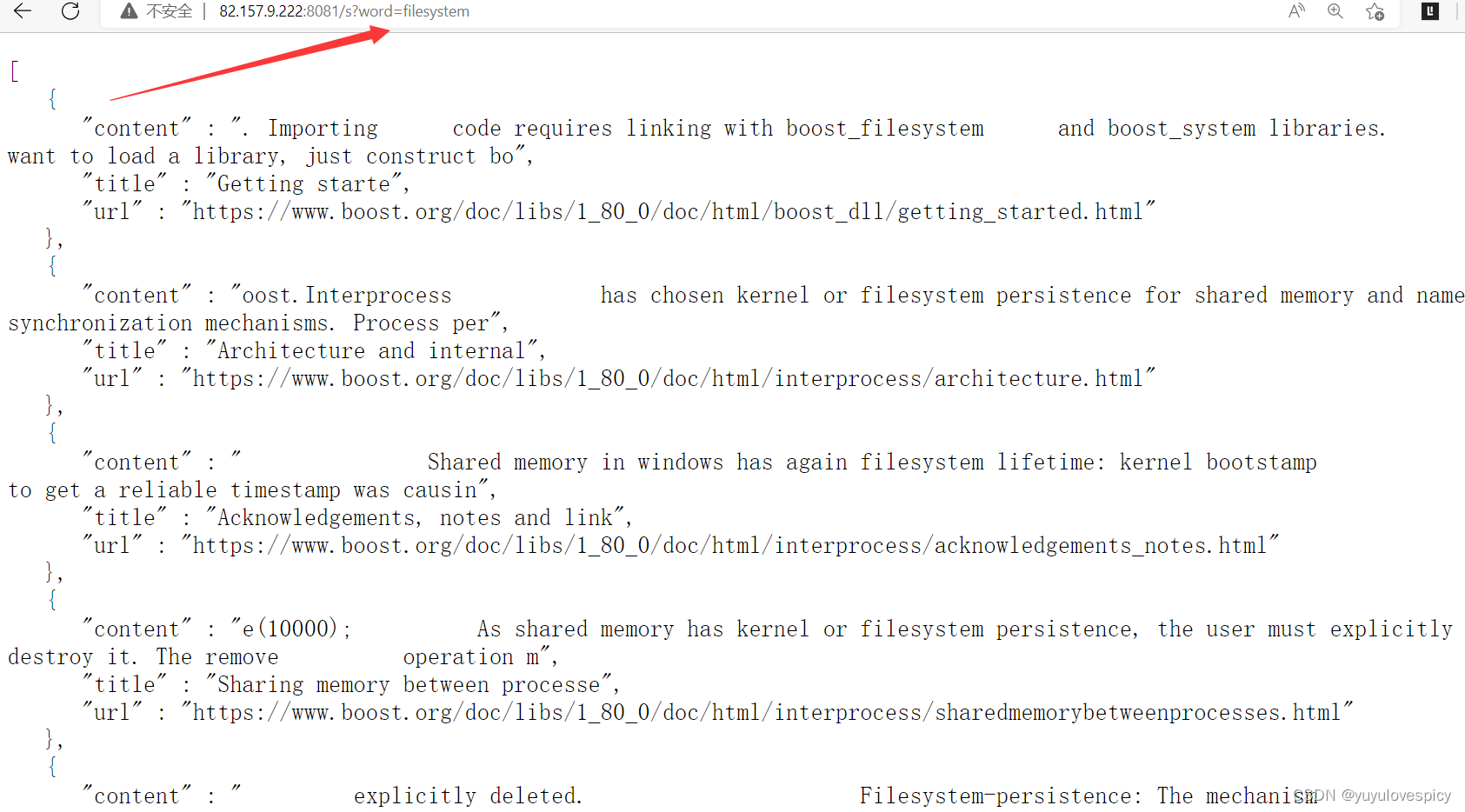
综上,我们就有了去标签化的各个网页文件的主体内容(title+content+url)了(如下图)。
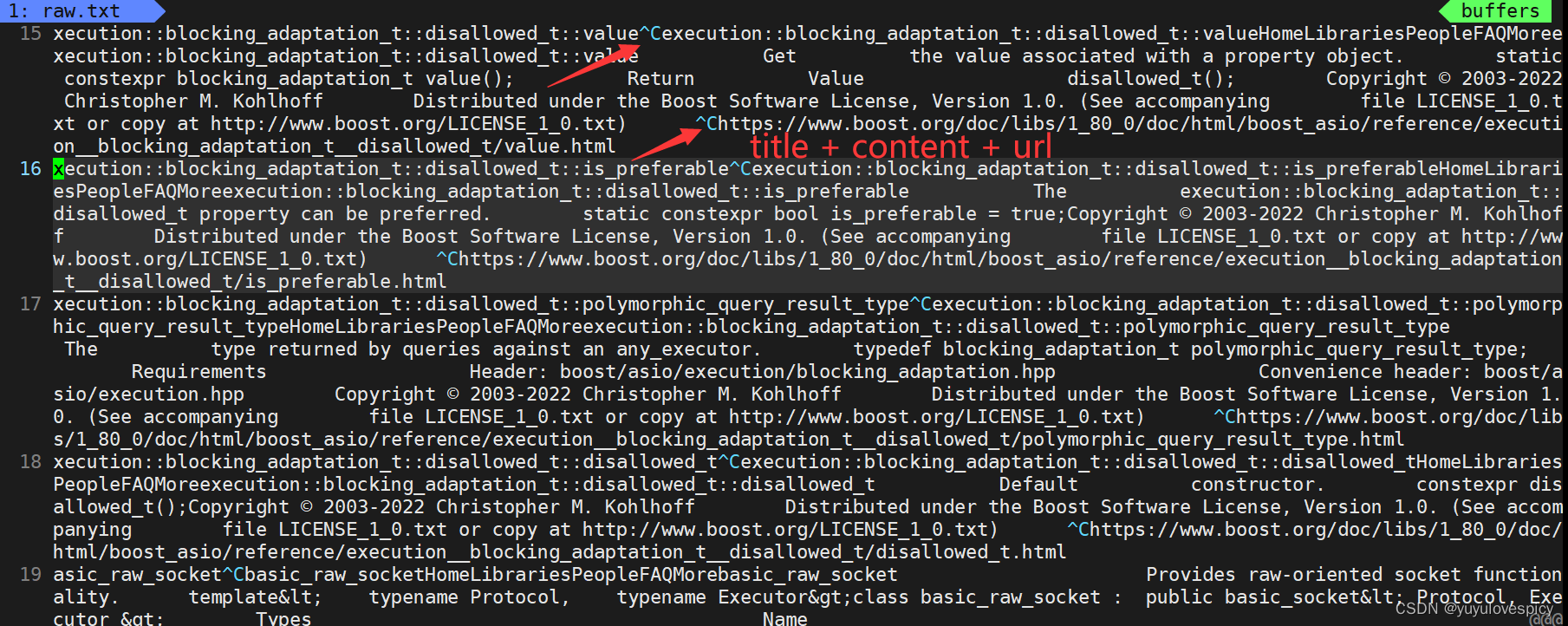
完成以上的解析去标签化工作,就可以给建立索引提供基本的数据源了。
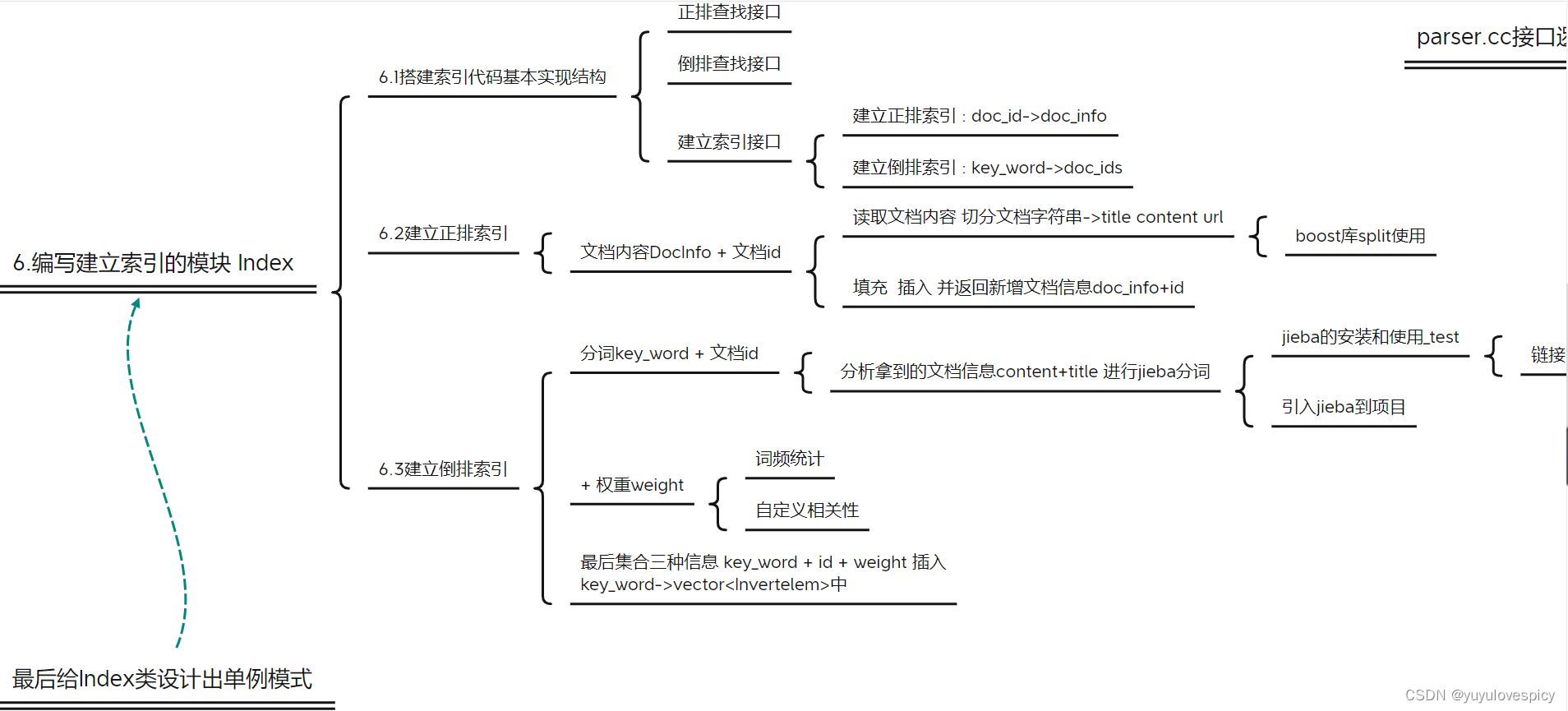
6.编写建立索引的模块 Index
我们构建索引,实际上就是构建存储+搜索的数据结构,来加快我们对于关键字->文档ID->文档内容的搜索过程。根据第四部分所述"正排索引 && 倒排索引 - 搜索引擎基本原理",我们需要构建正排索引以及倒排索引。
6.1建立索引的基本代码框架
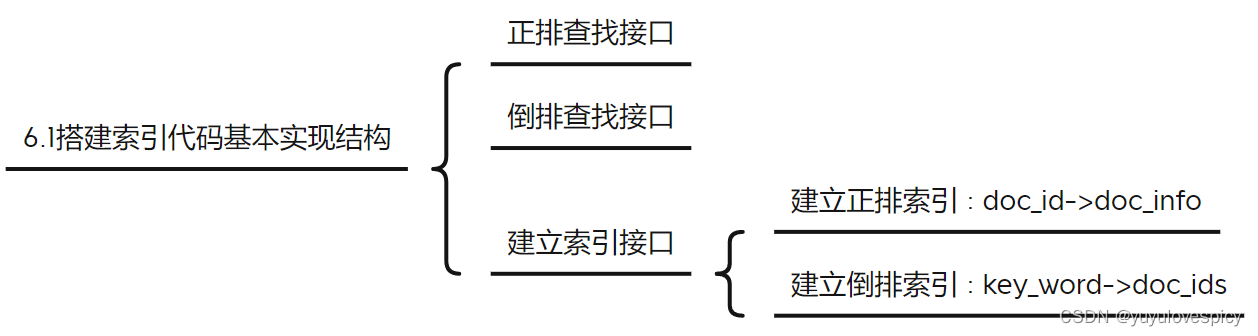
存储倒排索引与正排索引的基本信息单位

使用vector作为构建正排索引的容器 : 则vector的下标就是天然的文档ID
使用unordered_map作为构建倒排索引的容器 : 通过关键字key_word , 从而快速查找到倒排文档信息拉链。
对索引Index对象,我们有三个核心接口,分别是在正派索引的查找,在倒排索引的查找,构建索引(包括构建正排和倒排索引结构)。
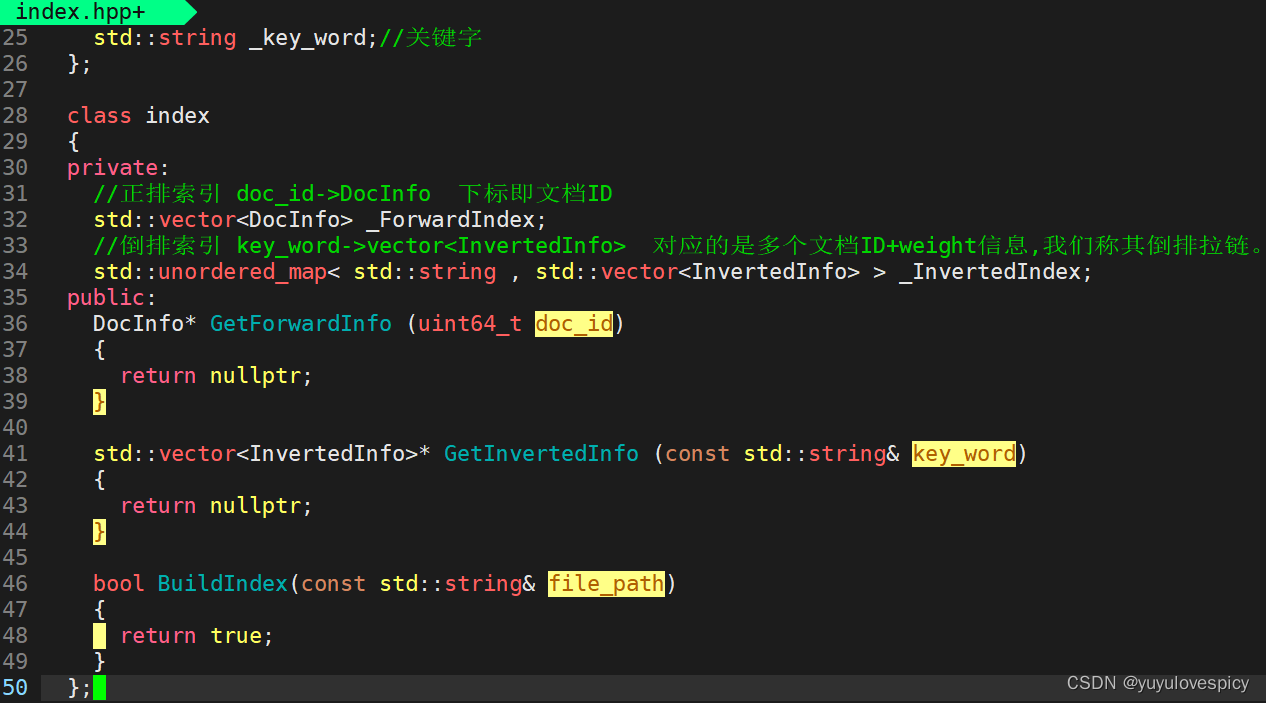
对于索引查找接口的实现:
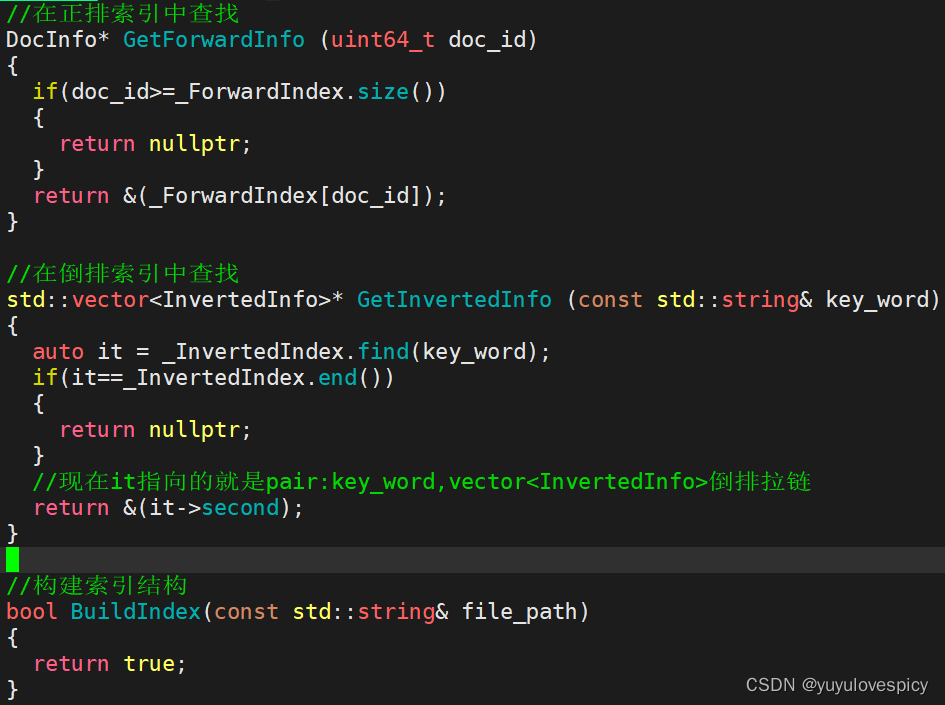
对于构建索引代码结构的实现:
则接下来的重点就是如何对每一个文档的基本信息,分别构建正排索引以及倒排索引了。
先建立正排索引。
6.2建立正排索引

6.2.1正排索引代码基本结构
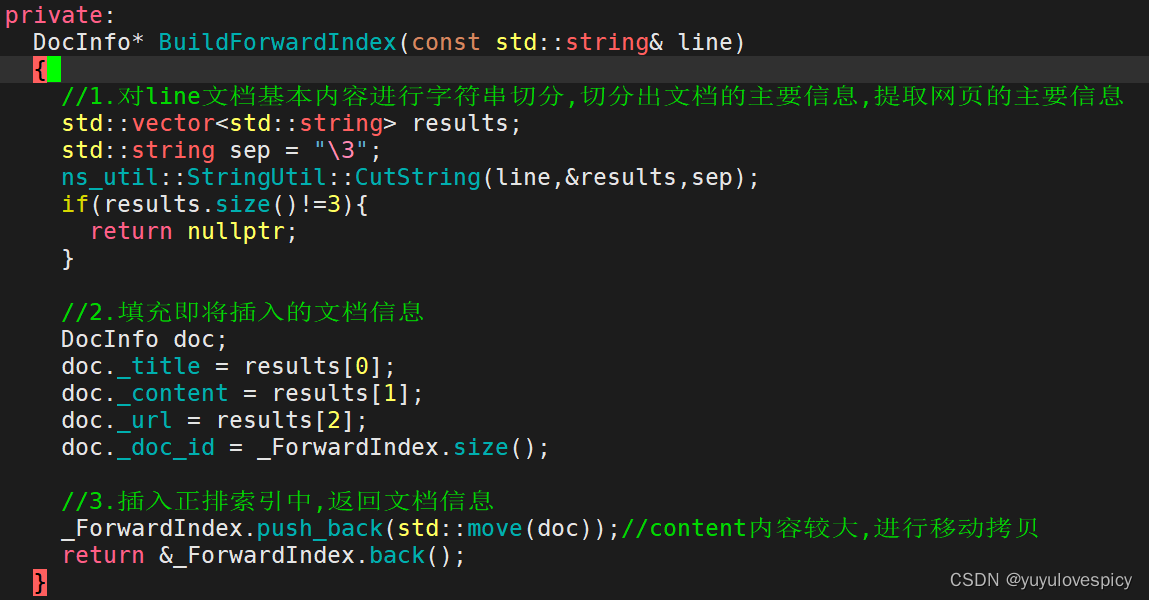
6.2.2切分字符串-boost库split函数使用
在util.hpp中,我们首先需要引头文件#include<boost//algorithm/boost.hpp>
举例使用 : 一个例子带你了解boost::split分词使用
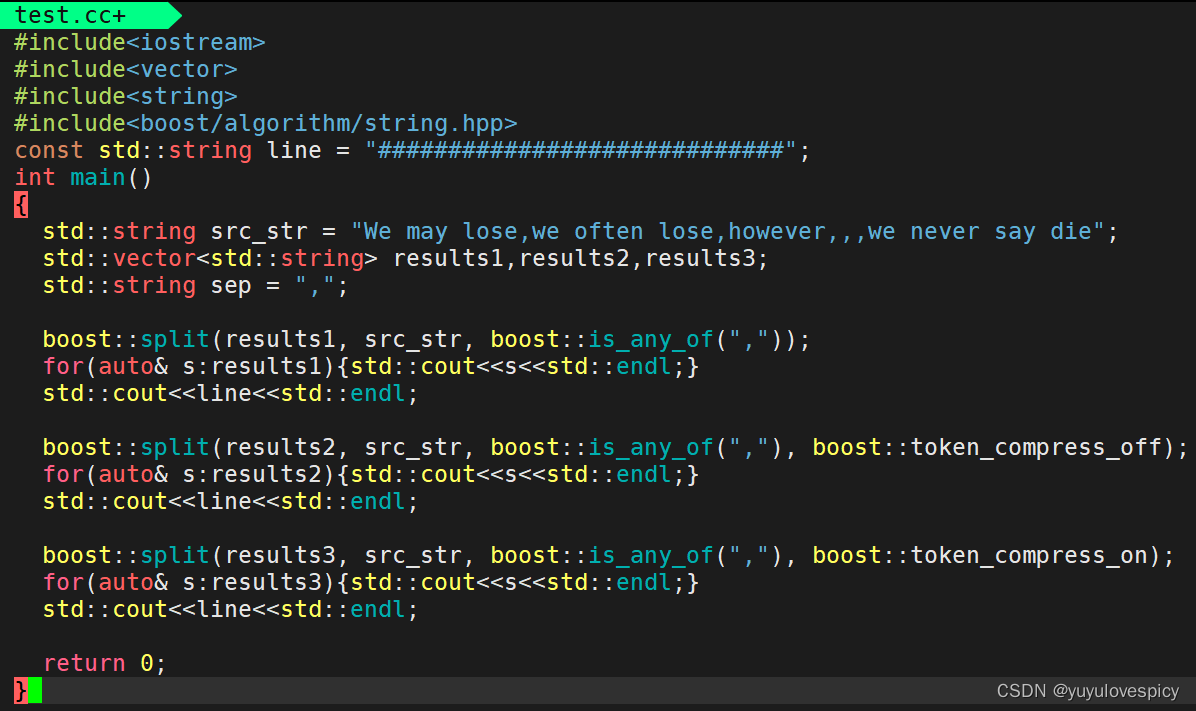
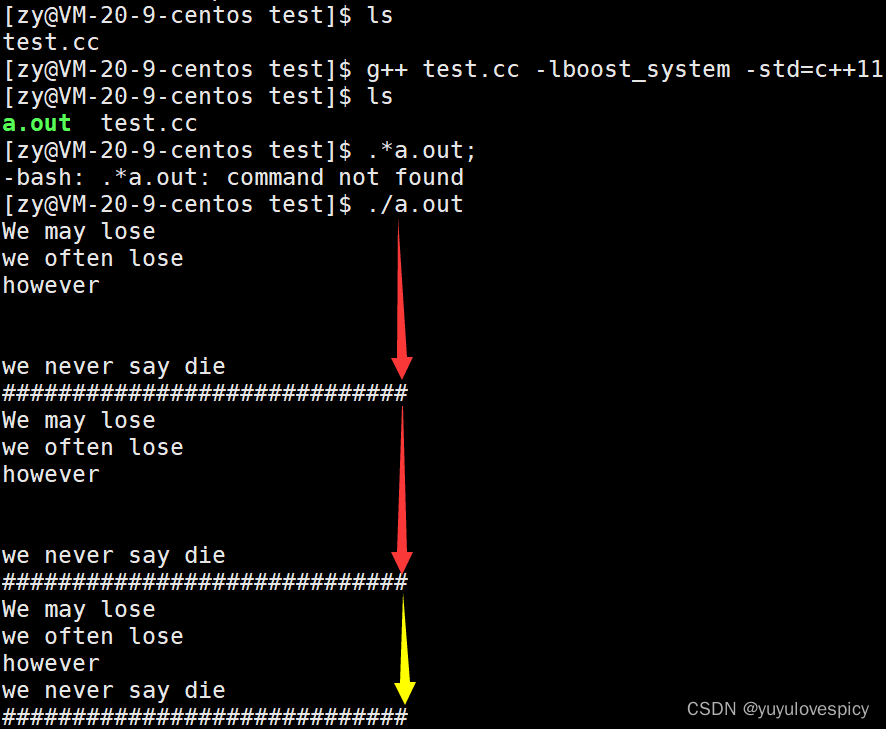
编写util.hpp的切分字符串函数

6.3建立倒排索引

6.3.1倒排索引的思路结构
我们对于每一个获取到的文档信息title+content+url,建立倒排索引。
#1.首先我们对一个文档的title+content进行分词(借助于jieba分词工具,这点我们最后谈)
#2.我们对分词后得到的多个词段,进行词频统计,得到每一个词段的在标题/内容的出现次数
#3.就可以根据<词key_word,频次word_cnt>map表,填充单个倒排词段信息,插入到倒排索引
PS:一个文档中的一个key_word关键词的权重weight信息的计算:
就是根据这个文档中该关键词在标题title 内容content中出现的次数,
再自定义相关性计算出该关键词key_word的分量weight,再填充词段信息weight。
一个简单例子理清上述思路:
#1.分词
title: 计算机专业
content: 计算机专业是硬件与软件的结合
title: 计算机 / 专业 / 计算机专业
content: 计算机 / 专业 / 计算机专业 / 硬件 / 软件 / 结合
存储在vector<string> title_word , content_word
#2.词频统计
struct word_cnt{
title_cnt;
content_cnt;
}//对于一个词段的在标题和内容中出现频数统计
unordered_map<string , word_cnt> wordcnt_map;
for word : title_word{
word_cnt[word].title_cnt++;
//计算机(1) / 专业(1) / 计算机专业(1)
}
for word : content_word{
word_cnt[word].content_cnt++;
//计算机(1) / 专业(1) / 计算机专业(1) / 硬件(1) / 软件(1) / 结合(1)
}
则可以知道每一个出现的词段,以及其在标题/内容中出现的次数。
#3.自定义相关性_填充字段_插入倒排索引
for word : wordcnt_map{
// key_word->vector<InvertedInfo> 一个关键字对应多个文档的信息
InvertedInfo word_info;
word_info._key_word = word.first;
word_info._doc_id = Doc._doc_id
word_info._weight = 10*word.second.title_cnt + 1*word.second.content_cnt
//根据word_cnt频数自定义
_InvertedIndex[word.first].push_back(word_info);
}
6.3.2倒排索引的代码编写
由于对cppjieba工具的说明使用部分较长,我们放在倒排索引代码编写部分之后进行说明。
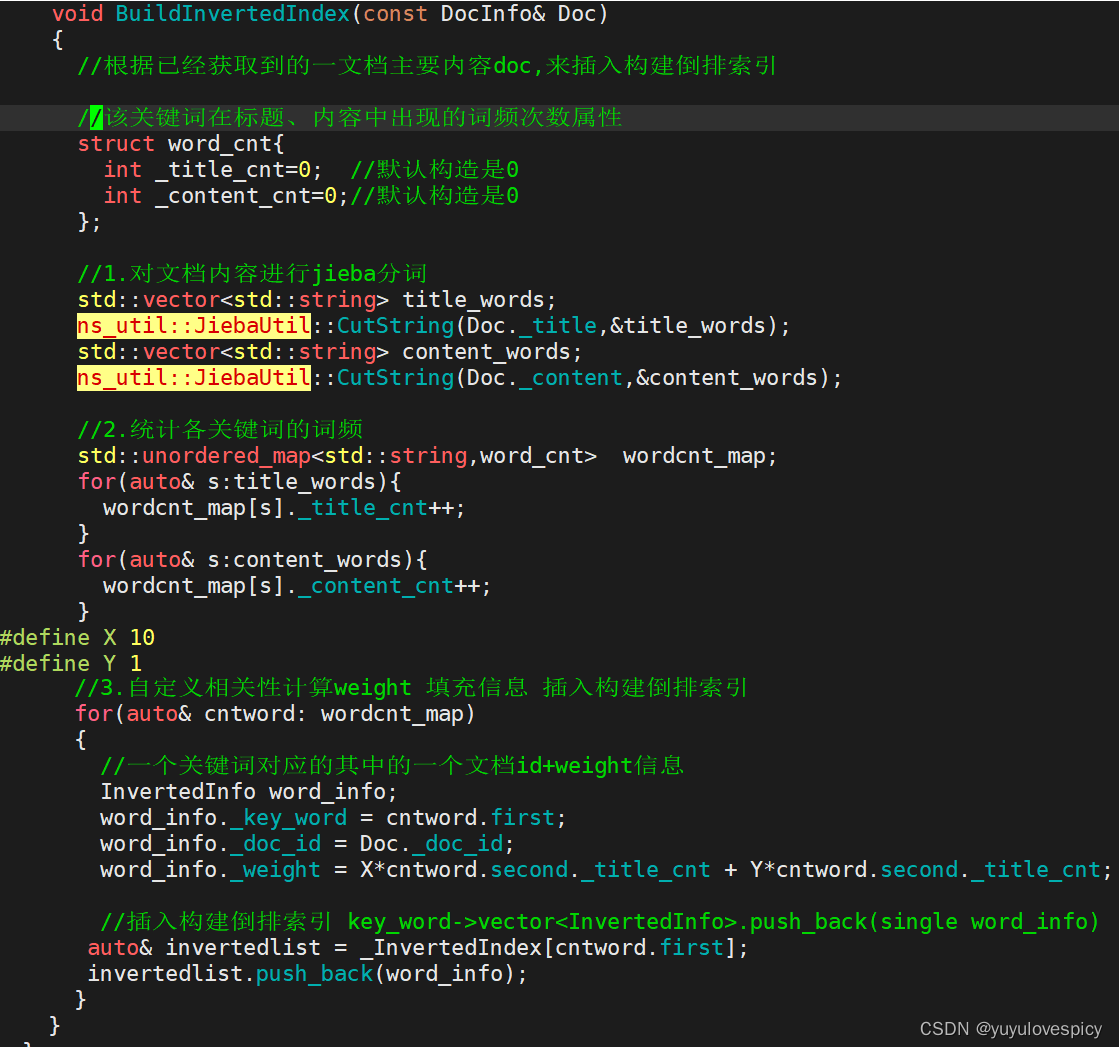
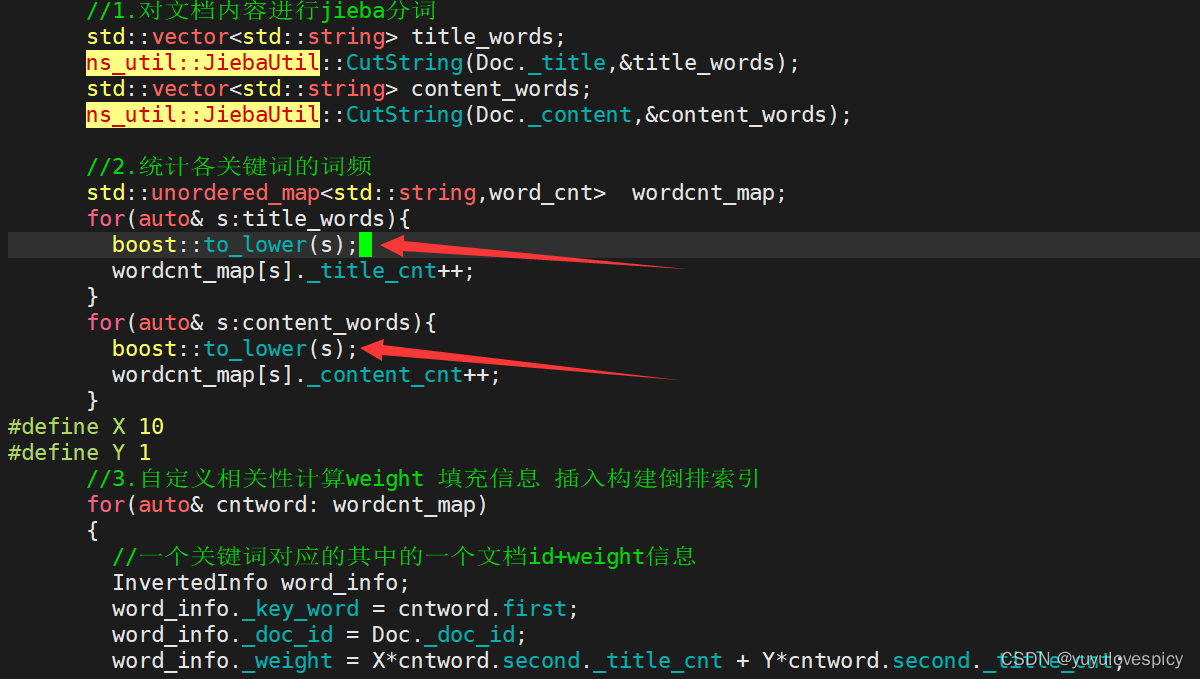
PS细节说明: 我们在搜索的时候实际上是不需要区分大小写的,所以需要我们在进行关键词统计的时候,我们统一将获取的分词进行小写化,即把我们倒排索引中查找的关键词(即倒排表的左侧改为全小写),我们随后在索引中搜索时再统一将输入的搜索词按小写检索。
所以我们对代码做如下改动。
6.3.3分词工具cppjieba
#1.Jieba库的安装和使用
我们进入GitHub来获取cppjieba分词工具资源(链接如下)
GitHub - yanyiwu/cppjieba: "结巴"中文分词的C++版本
我们看一下cppjieba工具包的具体构造
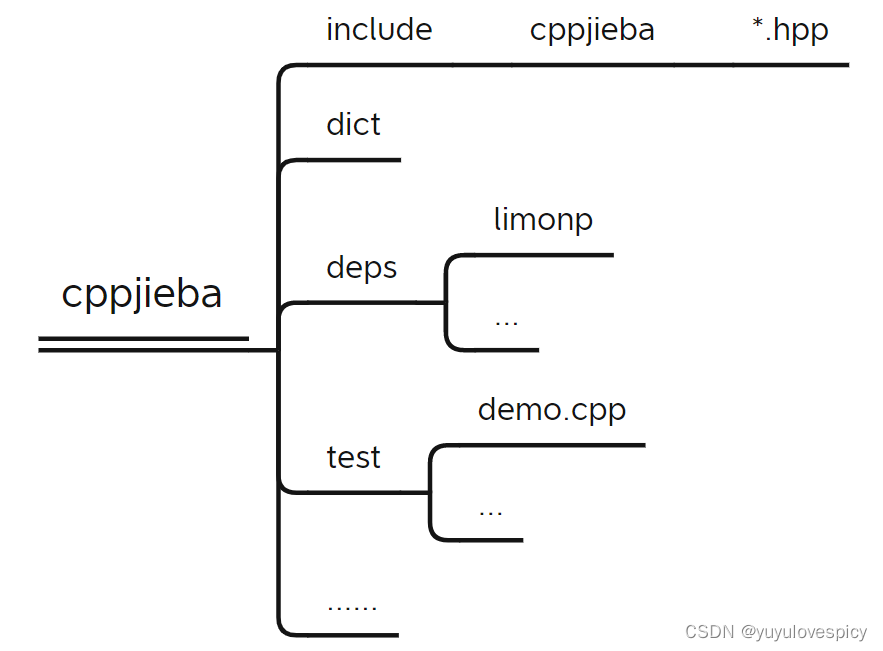
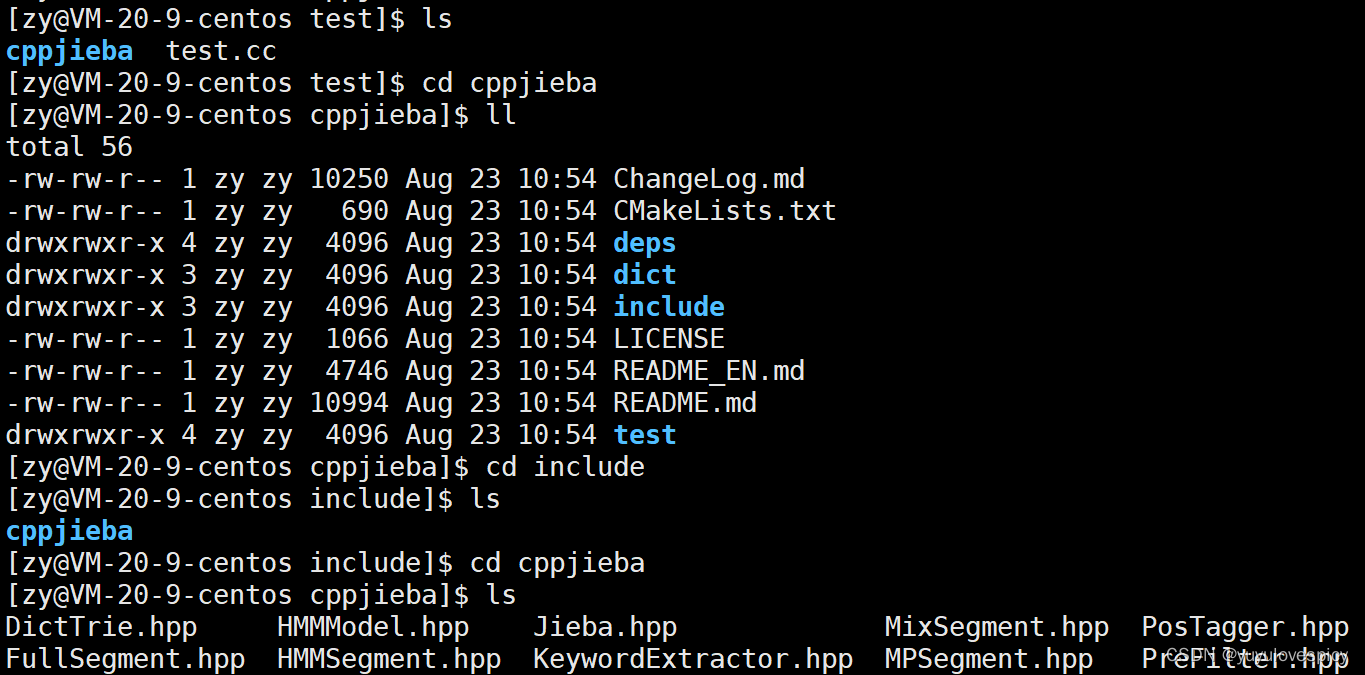
解决jiaba库的链接使用问题
其中我们需要连接使用的是如下三个:
cppjieba/include (需要建立对/include目录下文件的链接)
cppjiba/dict (需要建立对/dict目录下文件的链接,从而获取jieba分词时的字典根据)
cppjibea/deps/limonp (这是cppjiaba库的坑,需要将此目录拷贝到cppjieba/include/cppjieba)
下面我们举例测试使用cppjieba工具,可以带我们了解cppjiba库的基本使用
PS:我们使用jieba库中的demo.cpp进行测试,当然我们也要首先解决jiba库的链接问题。
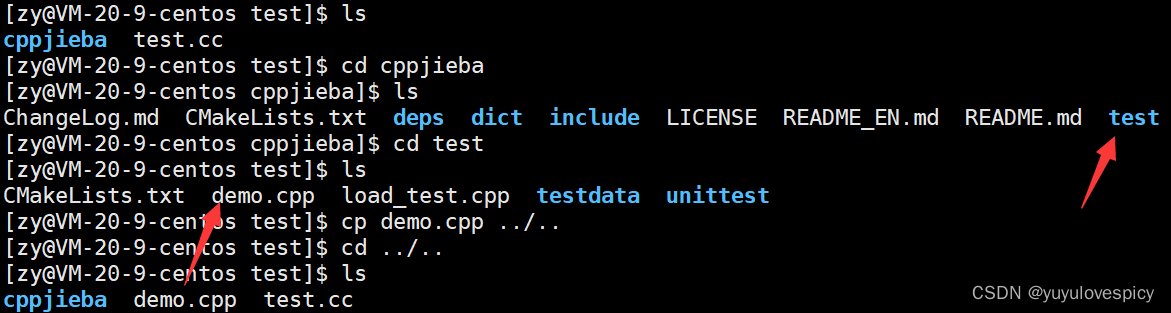
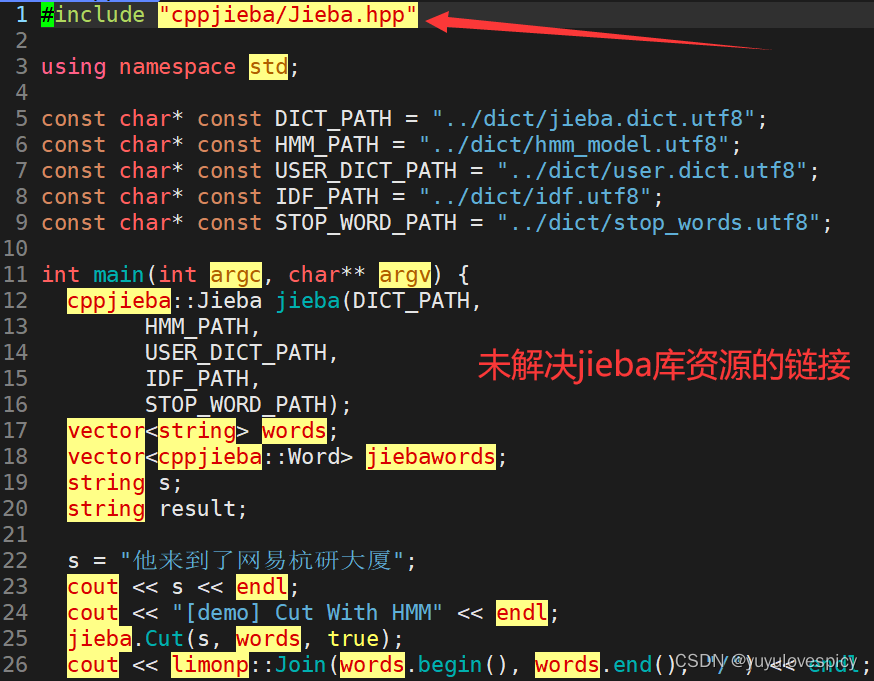
解决jieba库的链接问题
(链接问题实际上是要解决在一个.cpp源文件中要找到库的链接路径)
(我们软连接ln -s 库路径 , 实际上就是在为源文件.cpp寻找到库路径提供便利)
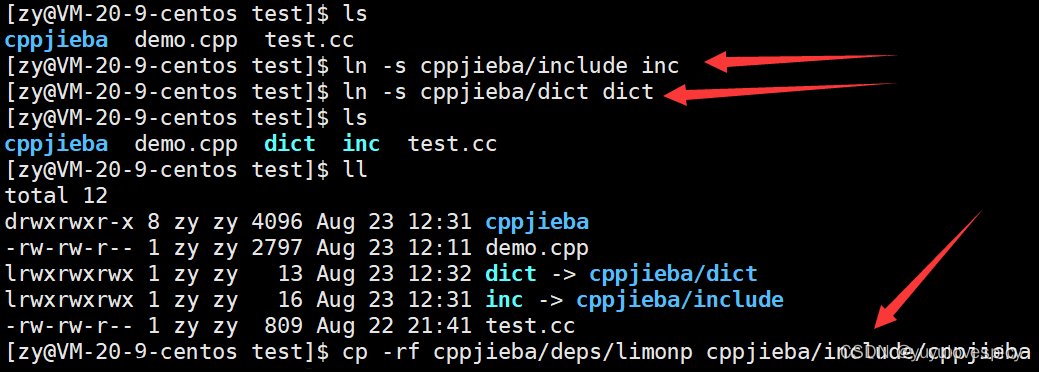
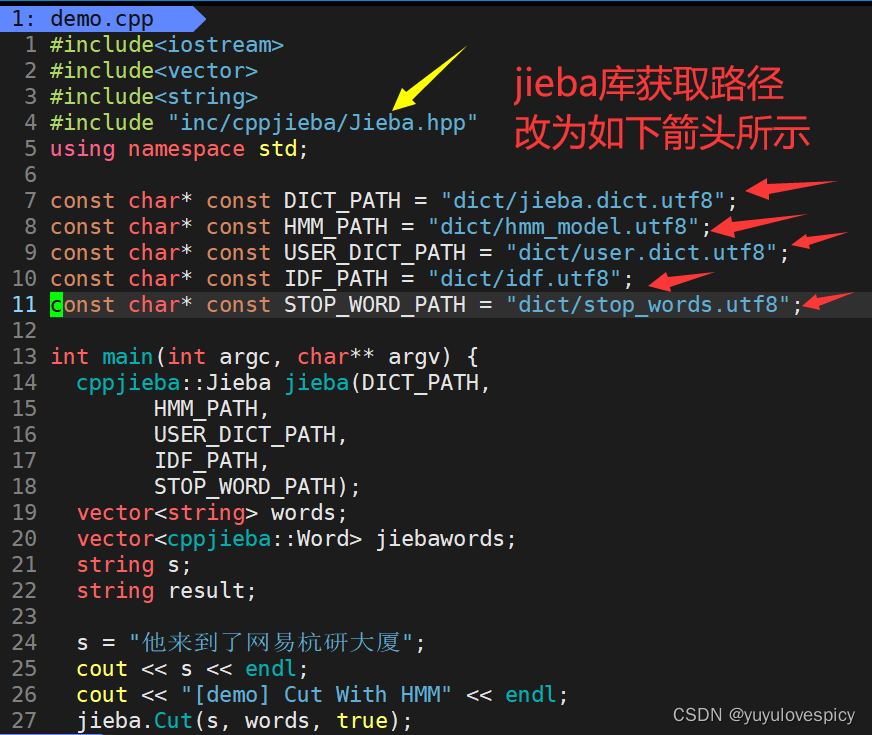
下面我们对修改源文件demo.cpp的对库的链接获取路径
这里我们发现了一个问题 : 我们直接下载的cppjieba/deps/limonp实际上是空文件夹,
(不信自己下载完去看 真的哭了) 这就需要我们重新专门下载limonp文件夹。

git clone https://github.com/yanyiwu/limonp.git
得到limonp文件夹 按照如下操作就可以了
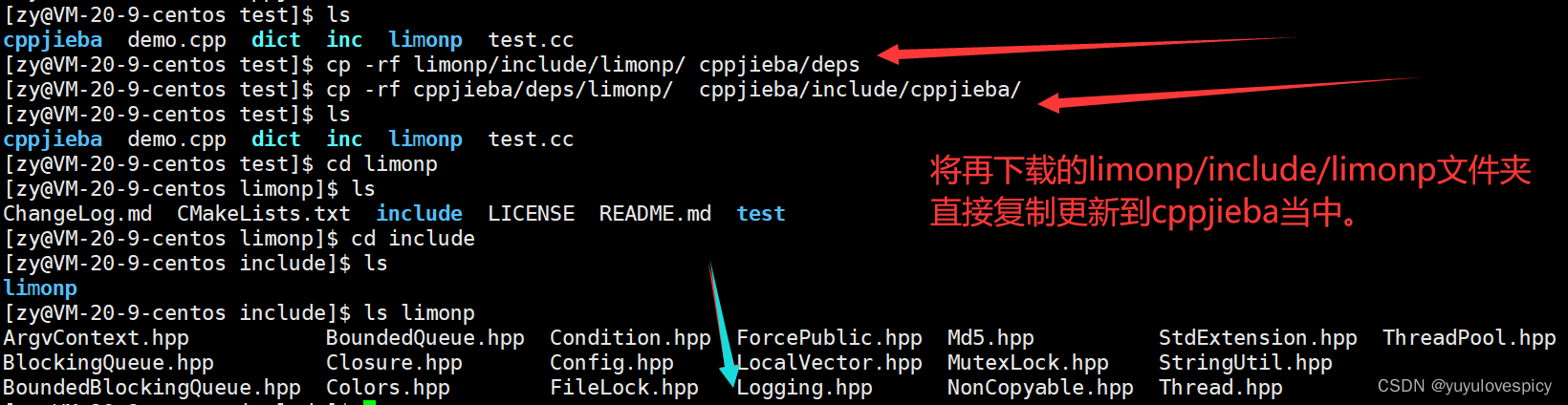
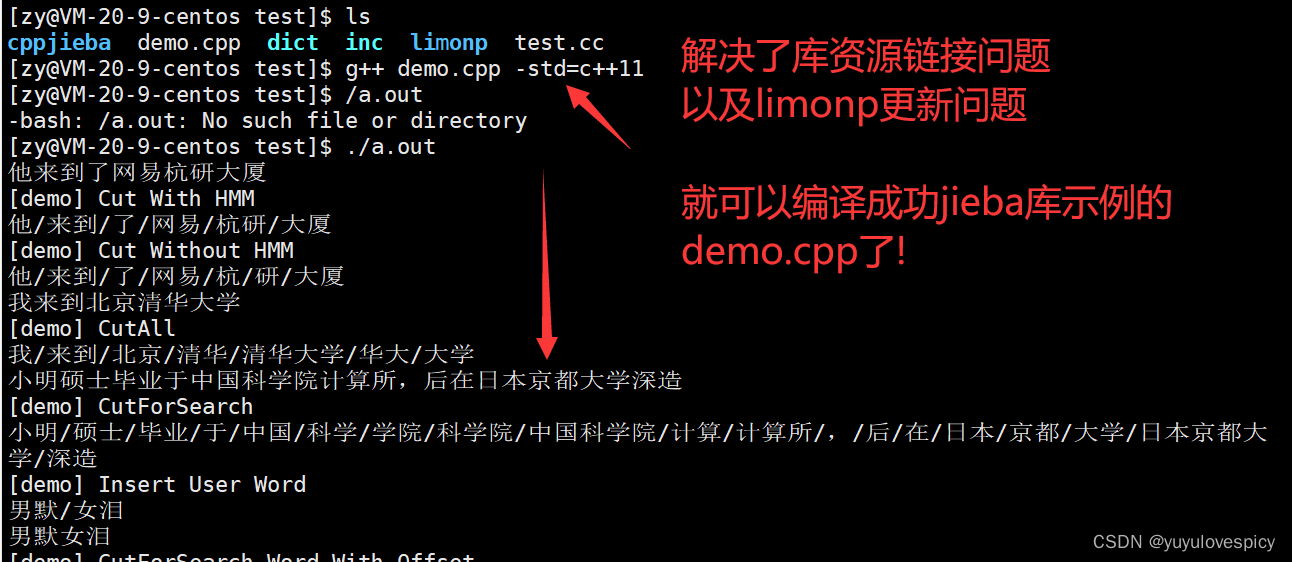
#2.引入Jieba库到项目
我们先将完整的,更新limonp的jieba库 , 拷贝到专门的资源仓库文件夹中。

建立对jieba库的软连接

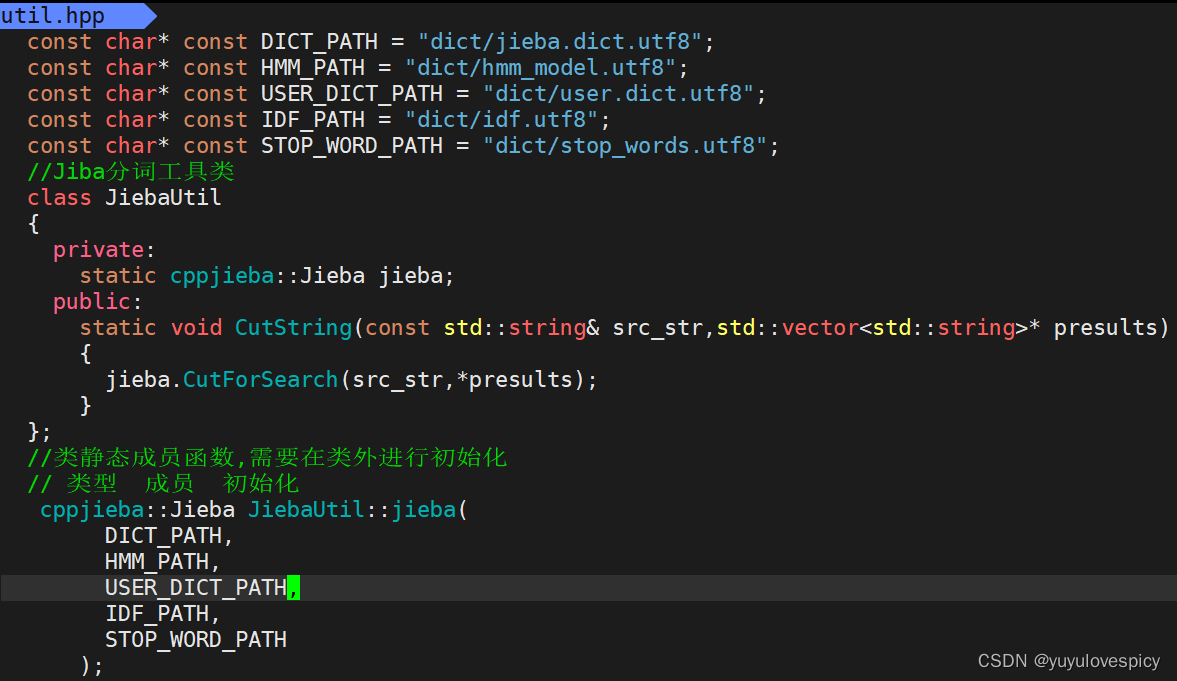
根据demo.cpp的对字符串的分词示例,设计util.hpp中Jieba分词接口
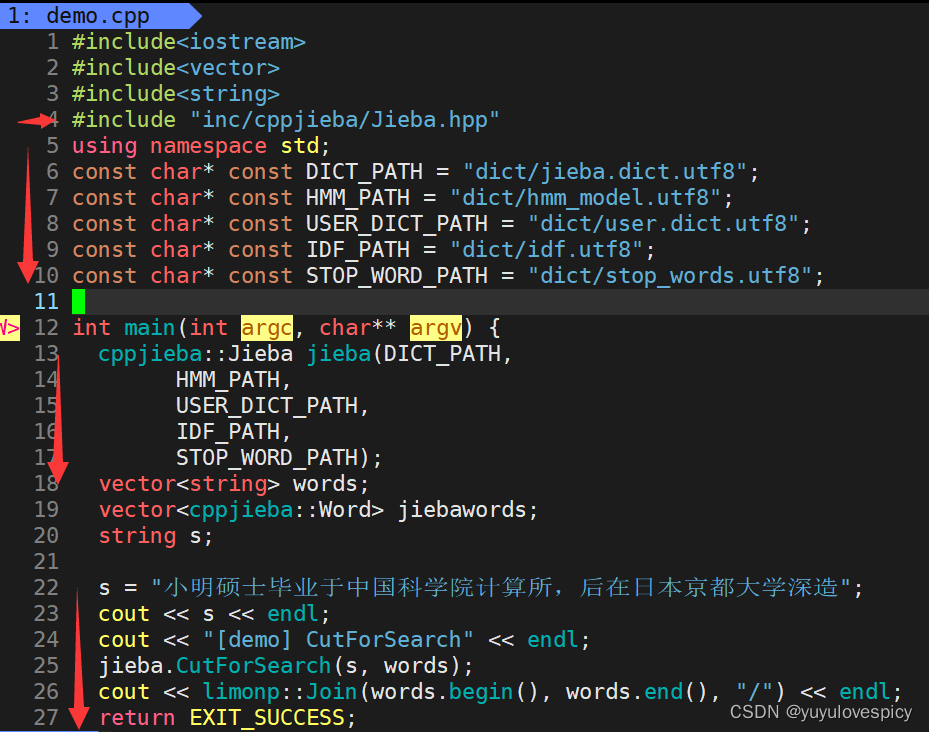

#3.工具集util.hpp中对于Jieba分词接口的实现
友情提示:不要忘记在util.hpp中#include"cppjieba/Jieba.hpp"
到此我们建立索引的部分就结束了
索引就是一个存储+查找的数据结构(这里其实就是填充两张表嘛)
然而,我们再思考一下索引类,我们需要建立多个索引对象吗?
一来,我们其实在boost搜索引擎项目当中,事实上不需要建立多个Index索引对象,只需要建立一个索引对象就可以完成查找工作了(即我们不需要建立多对正排倒排表,只要有一对能检索查找即可)。
二来,我们建立一个索引对象的成本事实上是极高的,因为我们需要将所有的网页信息分词,统计,填充,插入,效率上会受极大损失。
因此我们将其设计为单例模式。
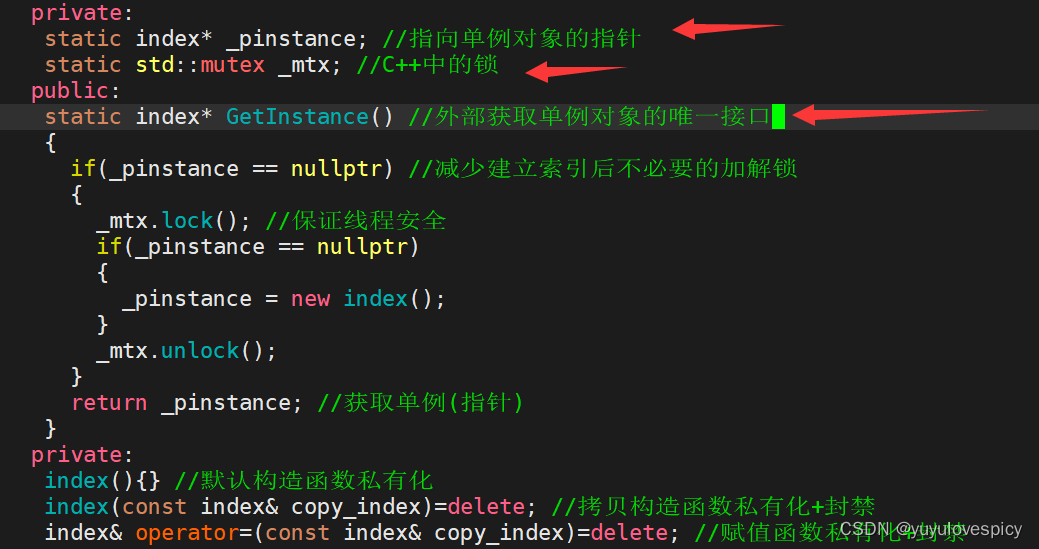
6.4将索引类设计成为单例模式
6.4.1 限制构造
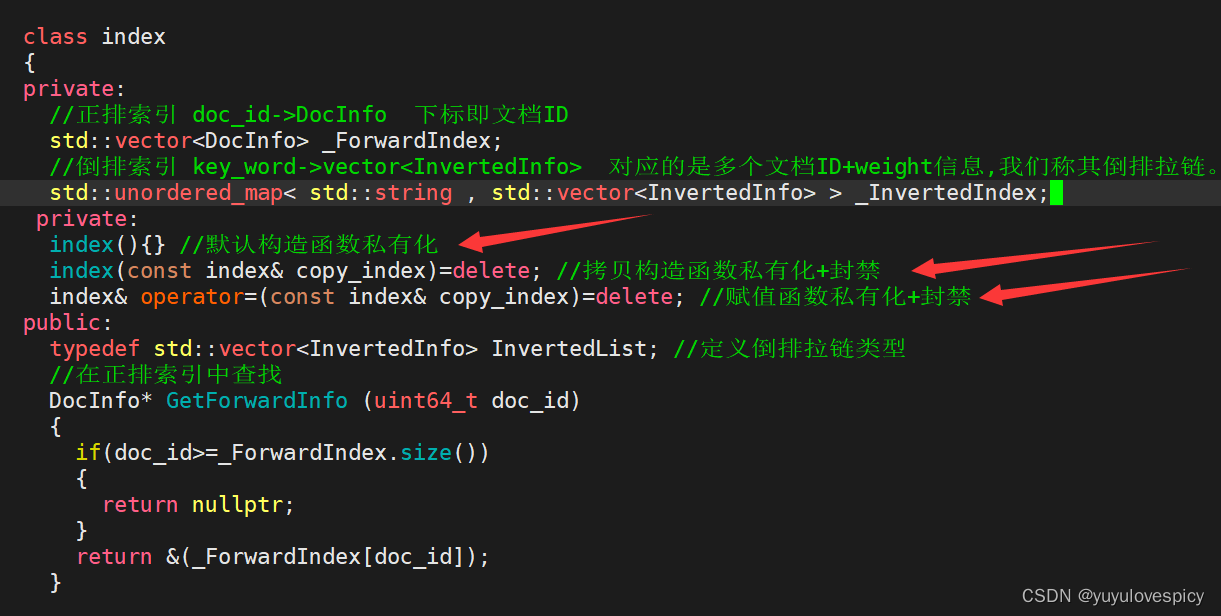
6.4.2 单例接口
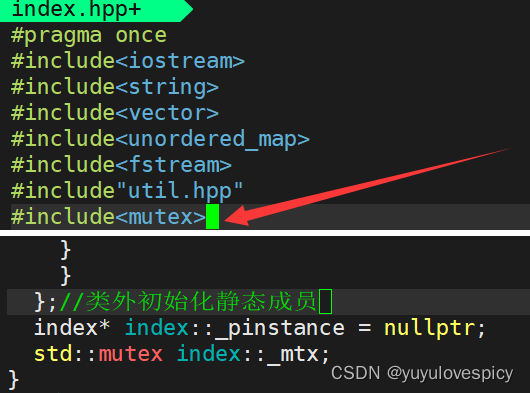
友情提示:记得#include<mutex> 和 类外初始化静态成员
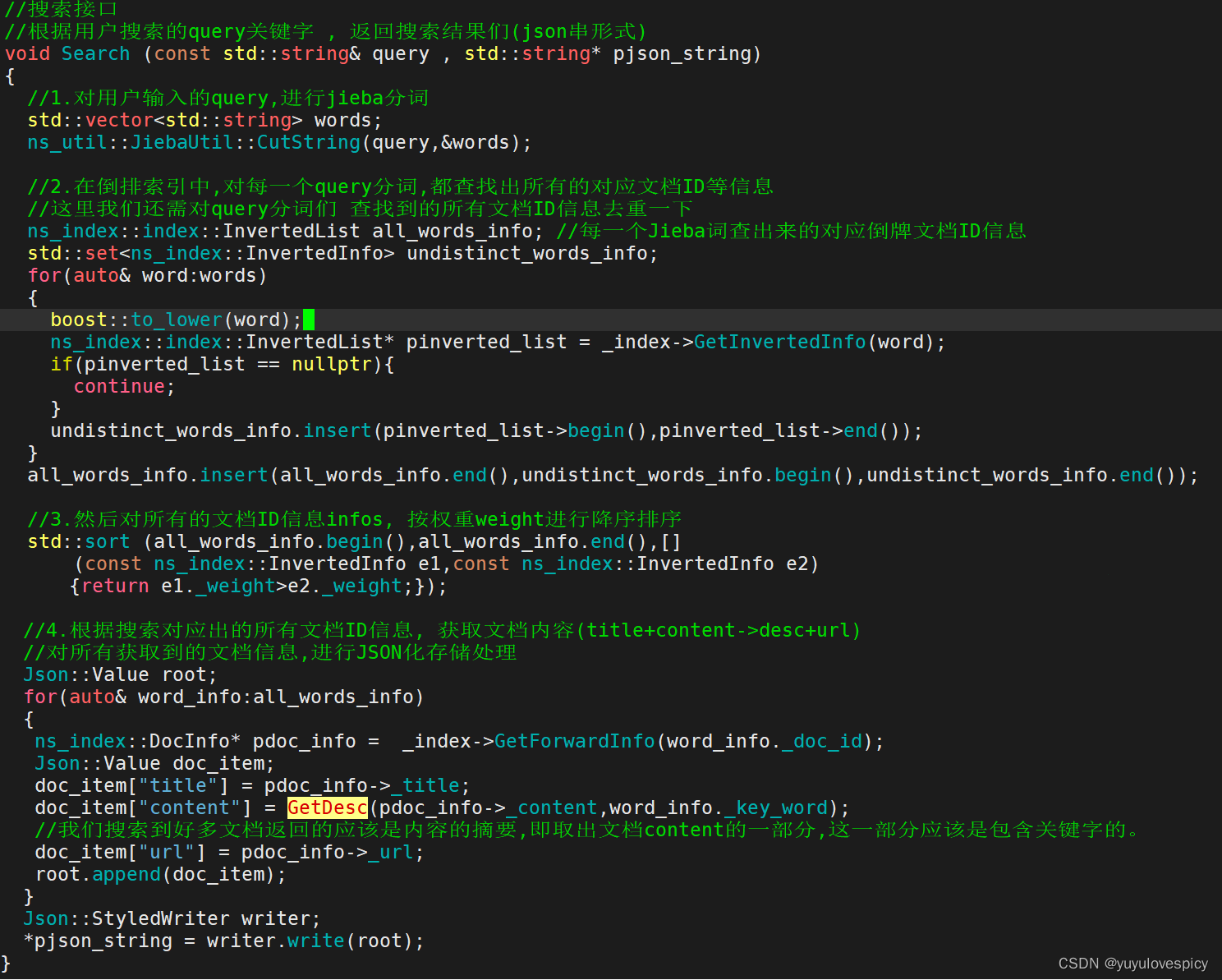
7.编写搜索引擎模块Searcher
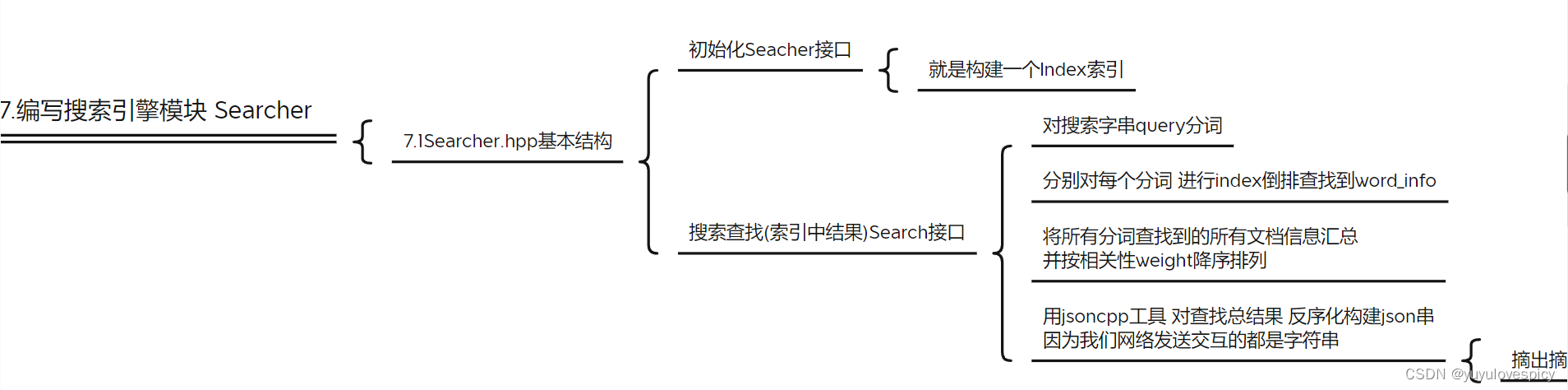
编写Seacher搜索引擎,实际上就是对index索引类的一个再封装的过程,进而在接下来对搜索服务端时更加方便的使用检索查找接口。
7.1搜索引擎Searcher.hpp基本结构
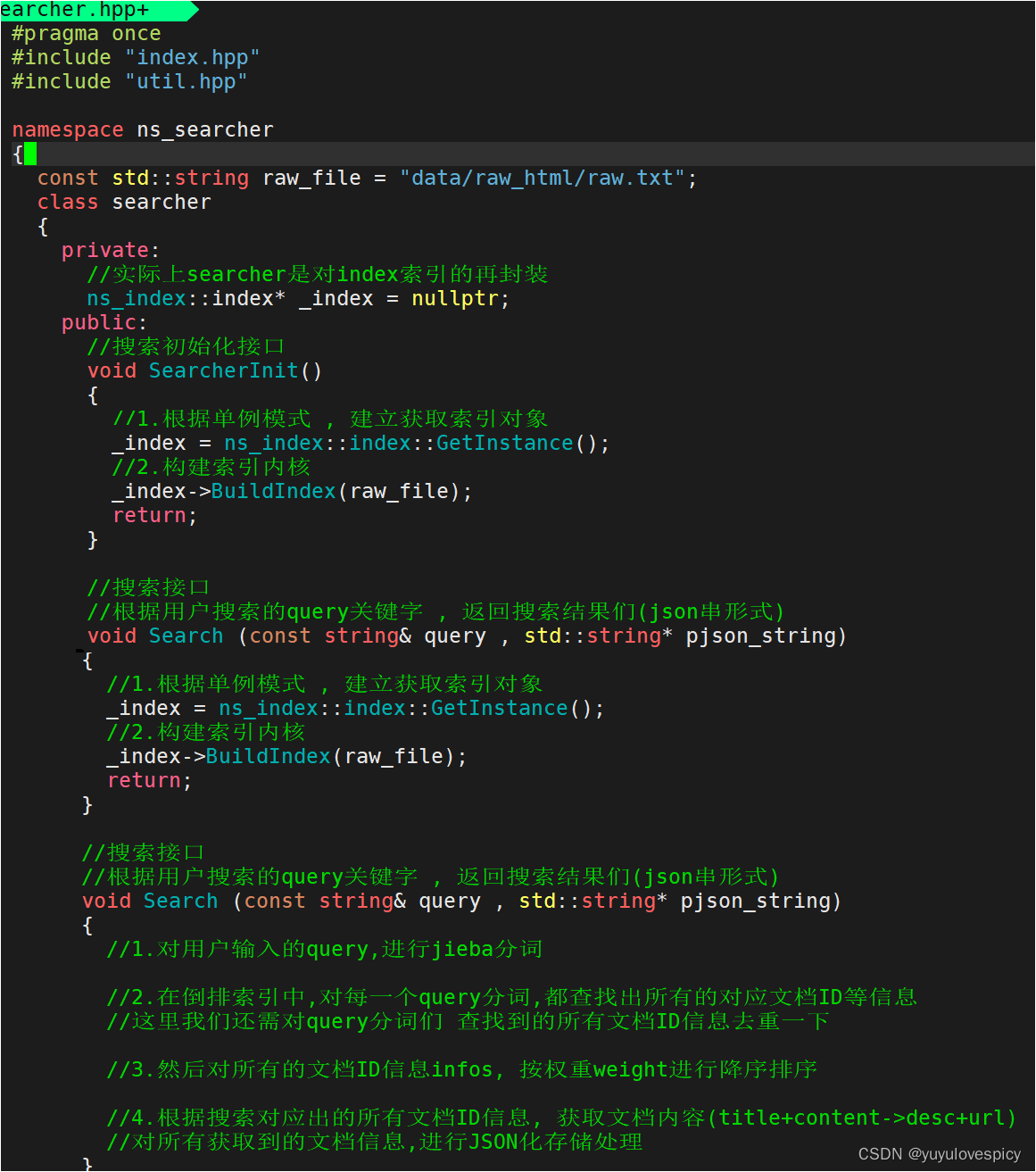
7.2对Search接口的实现
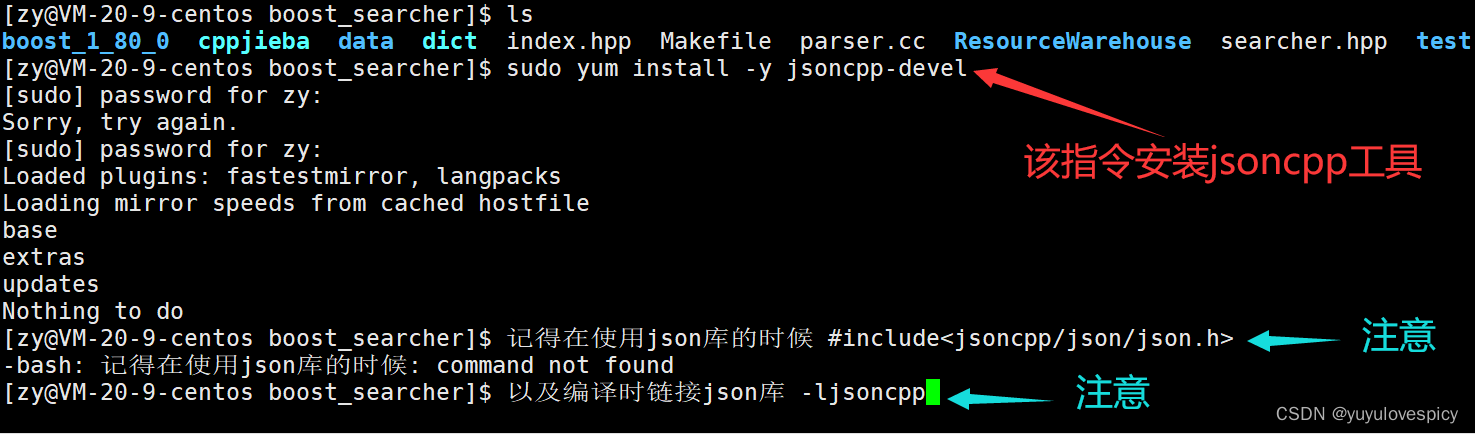
友情提示: 下载json库后, #include<jsoncpp/json/json.h>
7.3对jsoncpp库的引入与使用
jsoncpp库的引入 sudo yum install -y jsoncpp-devel
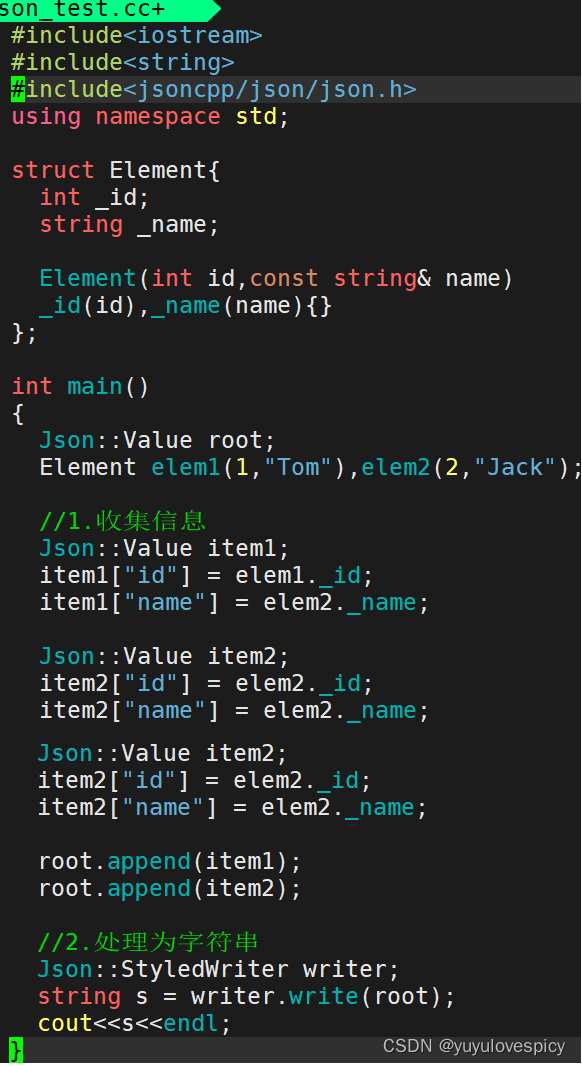
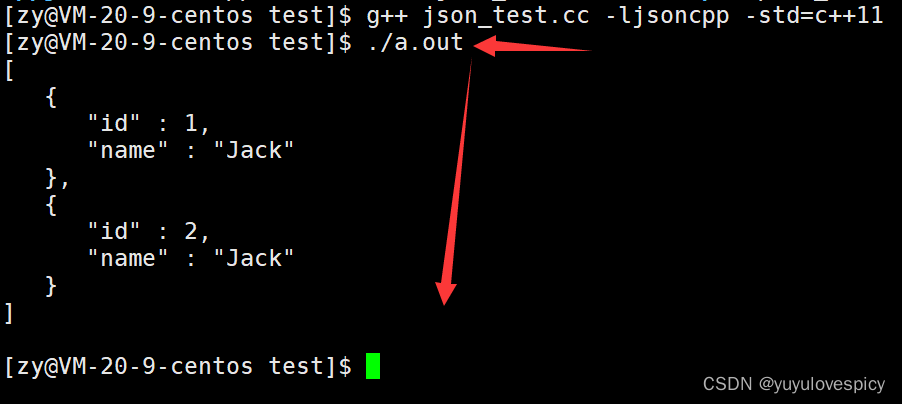
对jsoncpp库的使用测试
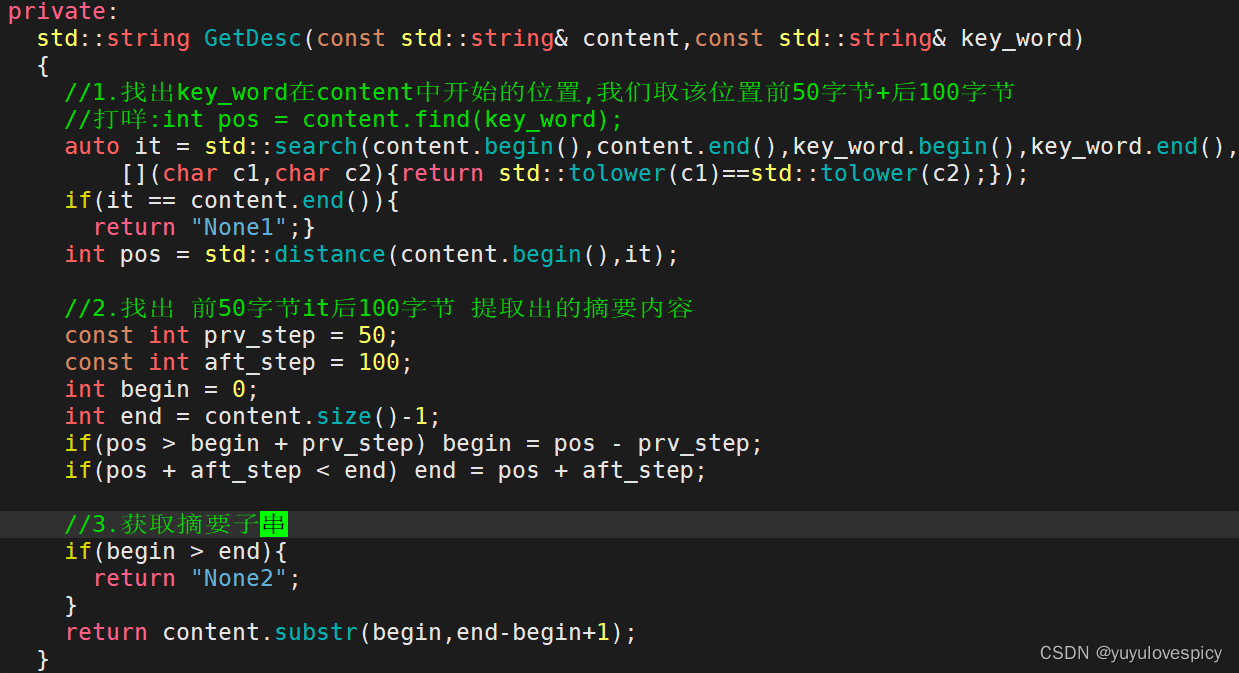
7.4实现获取内容摘要接口
前情提要:我们根据搜索内容query分词,到倒排查找到的文档内容进行返回,然而我们返回的,即用户搜索完出来的信息,应该是文档内容的摘要部分,所以我们只需要找到包含搜索关键字的内容摘要即可。 content ---> Desc(content,key_word)
$获取内容摘要接口注意点:
(1)我们的建立的索引Index,其中的倒排表实际上是统一按照小写词段进行查找的,也就是说,我们倒排索引表的左侧是小写的词。
我们搜索到的倒排拉链里面的文档ID信息里面存储的也是小写化的搜索关键词_key_word。
(2)而索引Index.其中的正排表中,文档id对应的文档内容,doc_info里面的_content内容,却是不区分大小写的。
->所以我们不能直接用小写化的_key_word在_content中find搜索,大小写不匹配,这是不可能找到包含该关键词的语句的。
我们应该在content中寻找key_word时,在检查对比时,统一小写化对比。
这里我们使用C++ <algorithm>中的search接口解决。

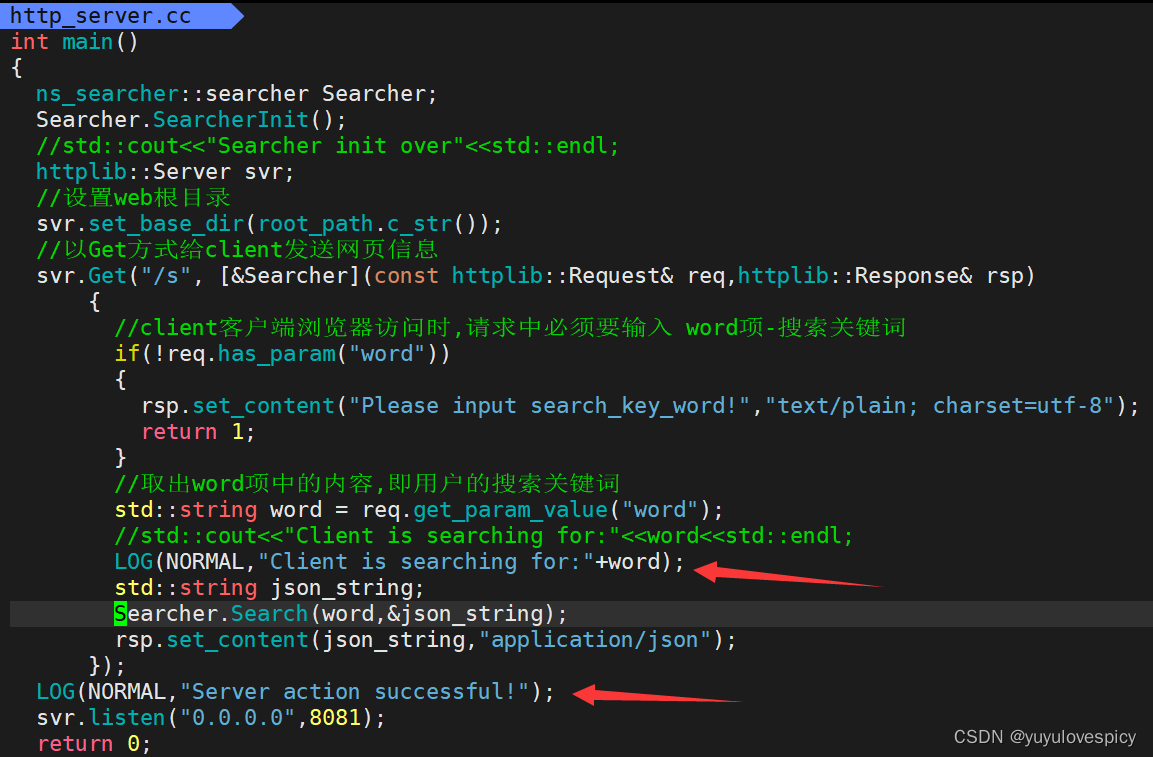
8.编写搜索服务端http_server.cc
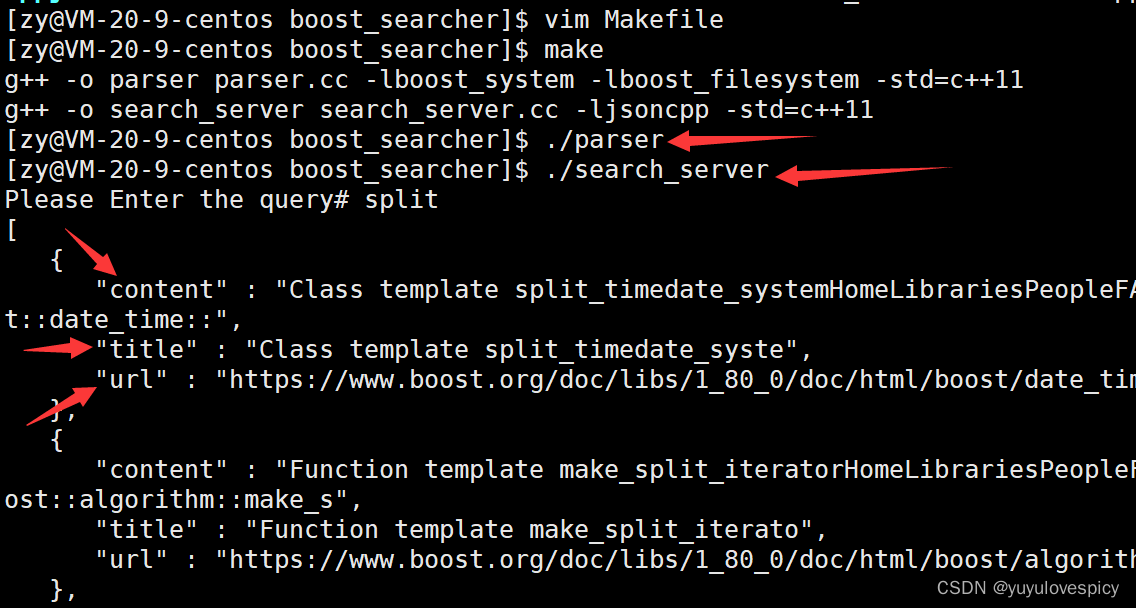
8.1测试版search_server.cc
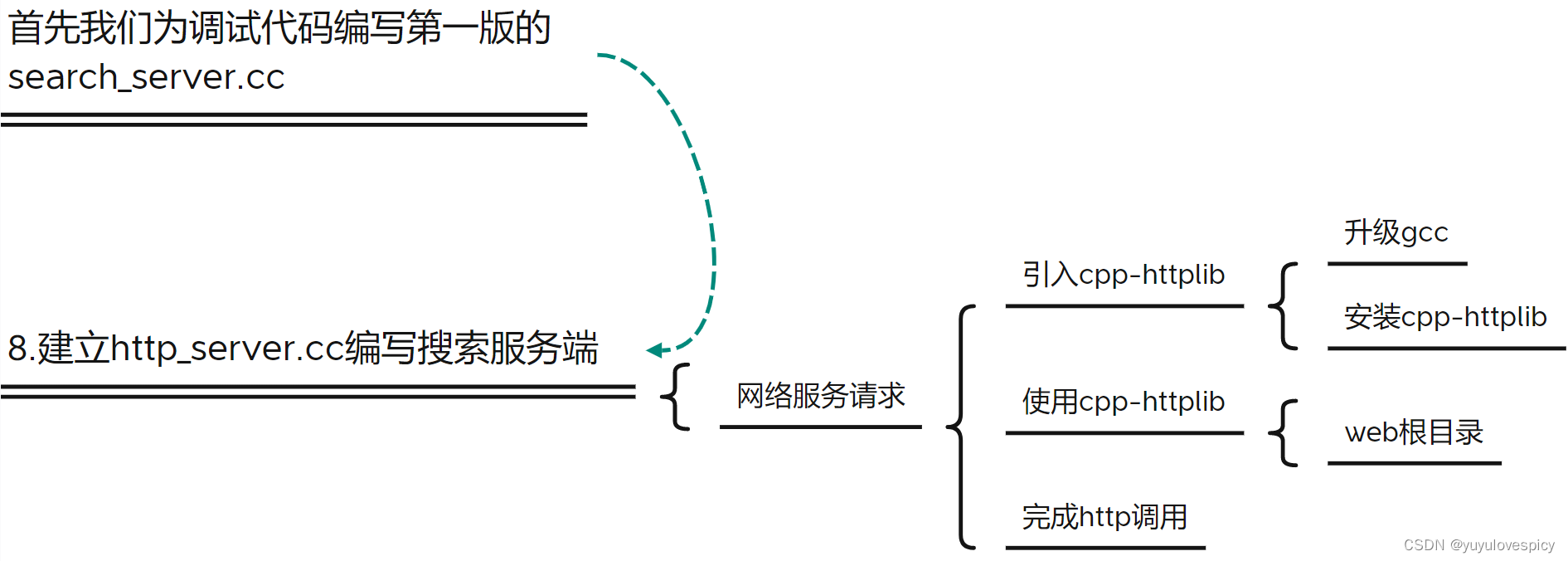
编写测试版http_server.cc
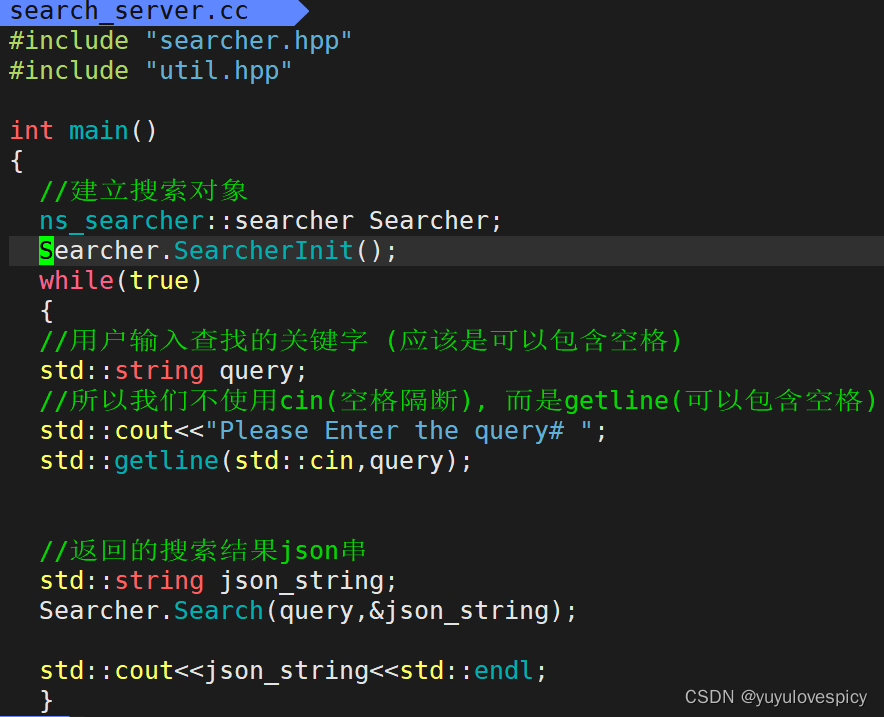
改写编译规则Makefile
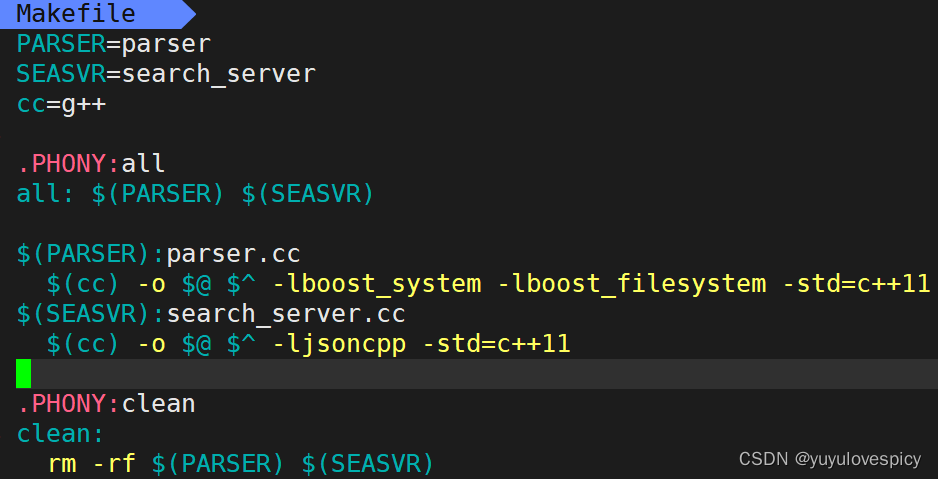
测试运行,我们发现了如下报错
可以看出是对于ns_index::InvertedInfo类的比较出现比较问题。
我们STL中的set底层是一棵红黑树,在插入的时候需要来回比较结点,而我们InvertedInfo类作为自定义类无法比较,所以需要我们添加比较规则,即给set传入比较仿函数类。

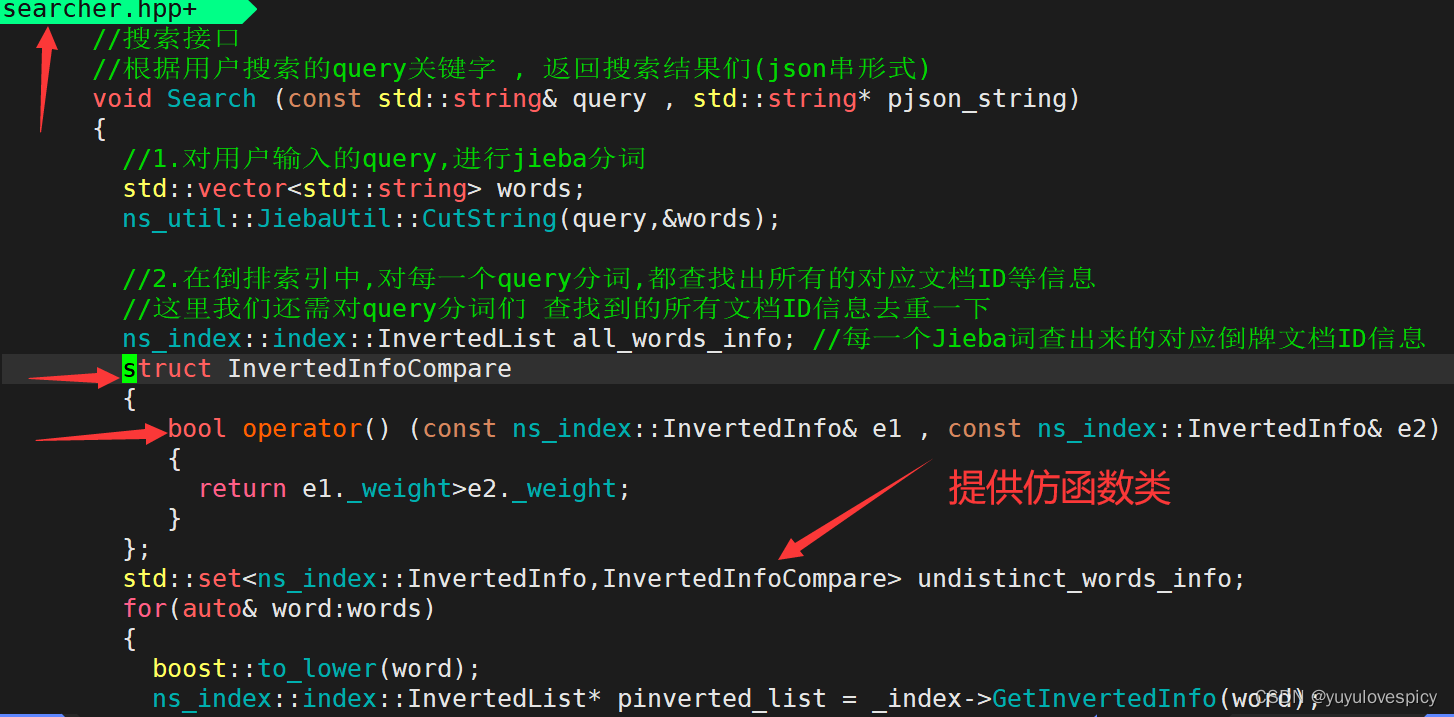
给set添加比较仿函数之后,我们再次运行测试,可以发现运行成功!
8.2网络版http_server.cc
我们要编写网络版本的boost搜索引擎服务端,就要使用网络传输的原始接口,不过在C++中,
可以直接引入cpp-httplib库,减少我们编写网络传输部分代码的成本。
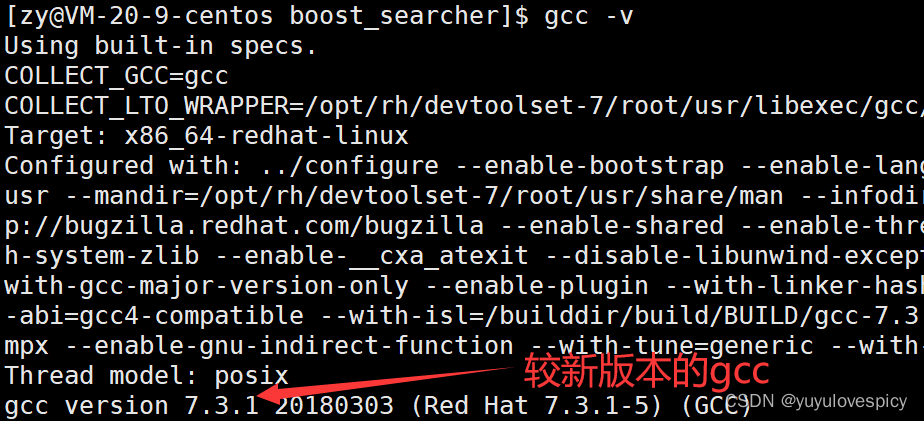
然而,要链接,编译,使用cpp-httplib库,我们需要使用更新版本的gcc。
我们云服务器中自带的gcc版本较低,是不能编译通过cpp-httplib库的。
所以在引入cpp-httplib库之前我们需要先升级gcc。
8.2.1升级gcc
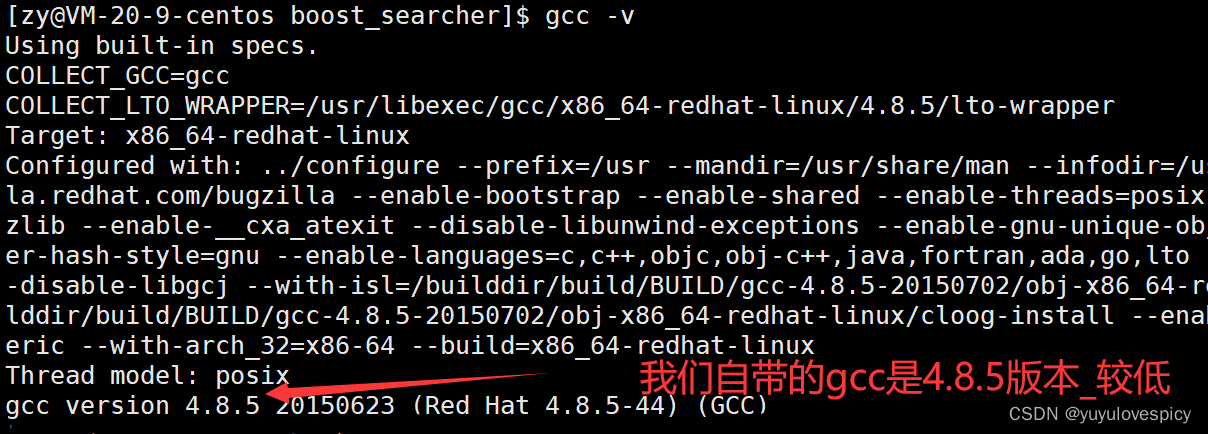
我们更新gcc需要用到三条指令 + 一个配置 (需要用scl来启动gcc 后续的配置是方便使用)
$1.安装scl
sudo yum install -y centos-release-scl
$2.安装新版本gcc
sudo yum install -y devtoolset-7
$3.启动scl更新gcc
scl enable devtoolset-7 bash
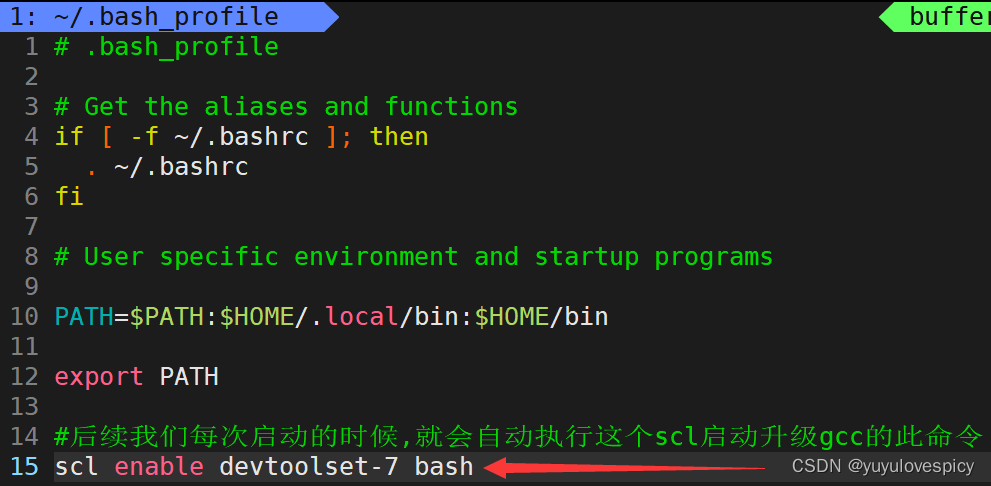
#4.(选做)配置自启动更新gcc
vim ~/.bash_profile
>在该文件的末尾放上语句scl enable devtoolset-7 bash即可
我们启动scl更新gcc,实际上只有当前次会话有效而已,即下一次重新启动之后仍然需要启动scl更新gcc。所以才有了我们的第四步配置bash_profile ,可以使每次启动的时候,都会自动执行更新gcc的指令:enable devtoolset-7 bash 。 就不用劳烦大家每次都启动更新一下gcc啦~
执行$1 $2 $3 三步之后,就可以使用gcc的升级版本了
执行#4 配置自启动更新gcc
8.2.2引入cpp-httplib库
我们在gitee网站上搜索该资源
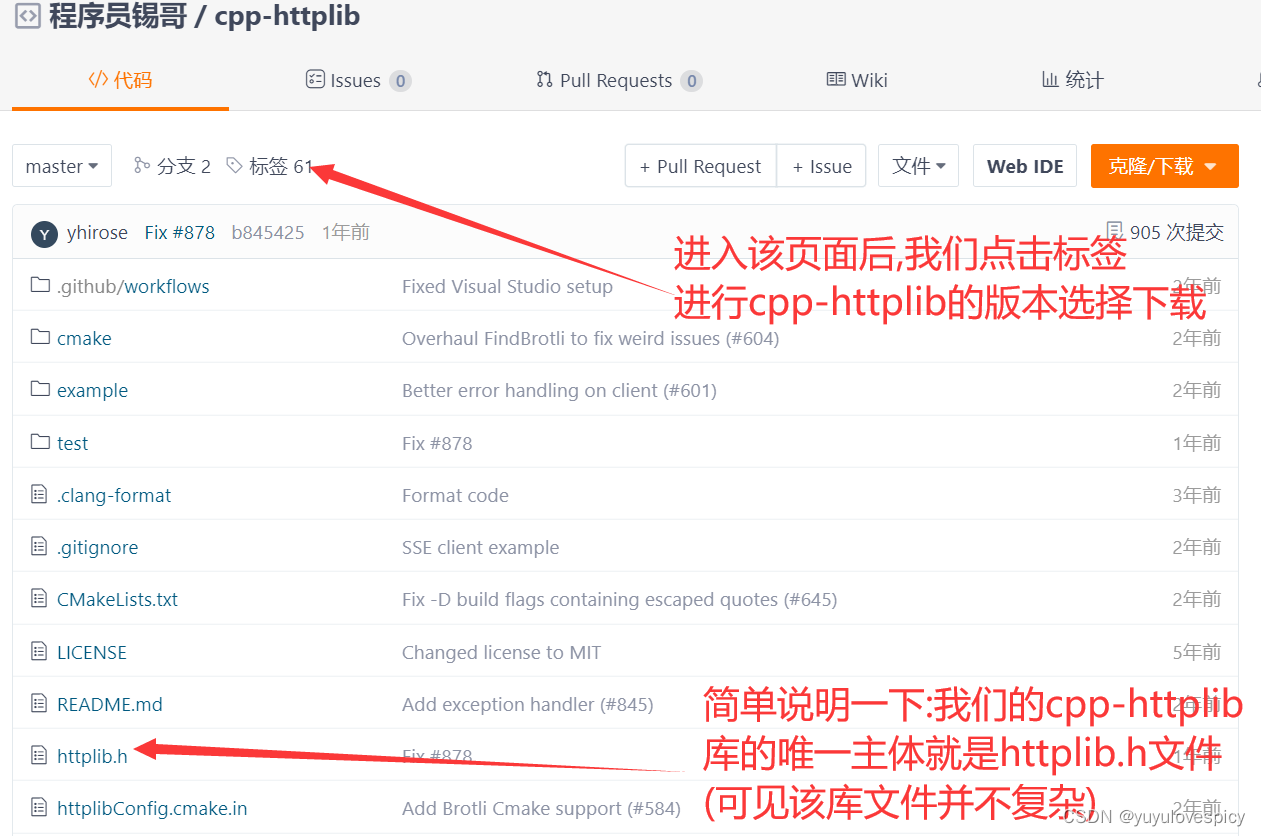

将下载好的库文件上传入云服务器中 (依托lrzsz工具 , 没有可以sudo yum install -y lrzsz)
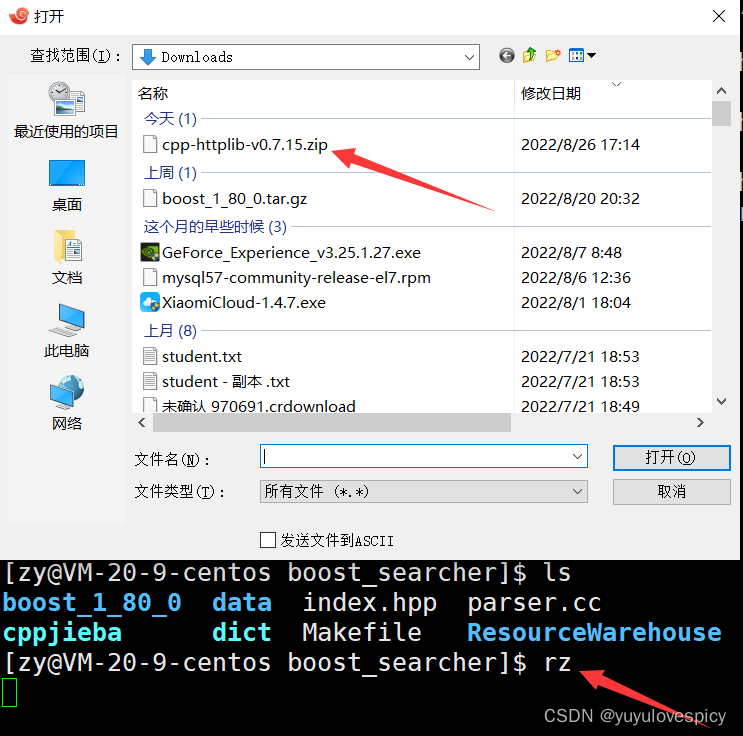
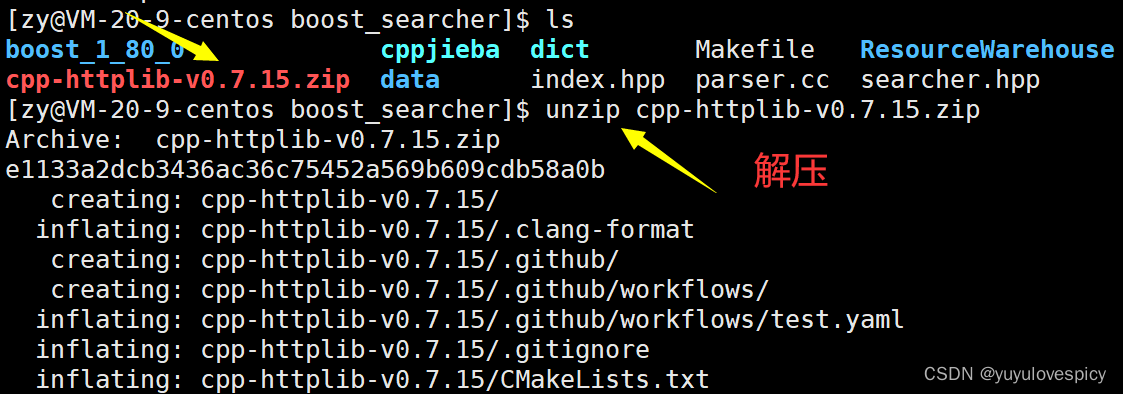
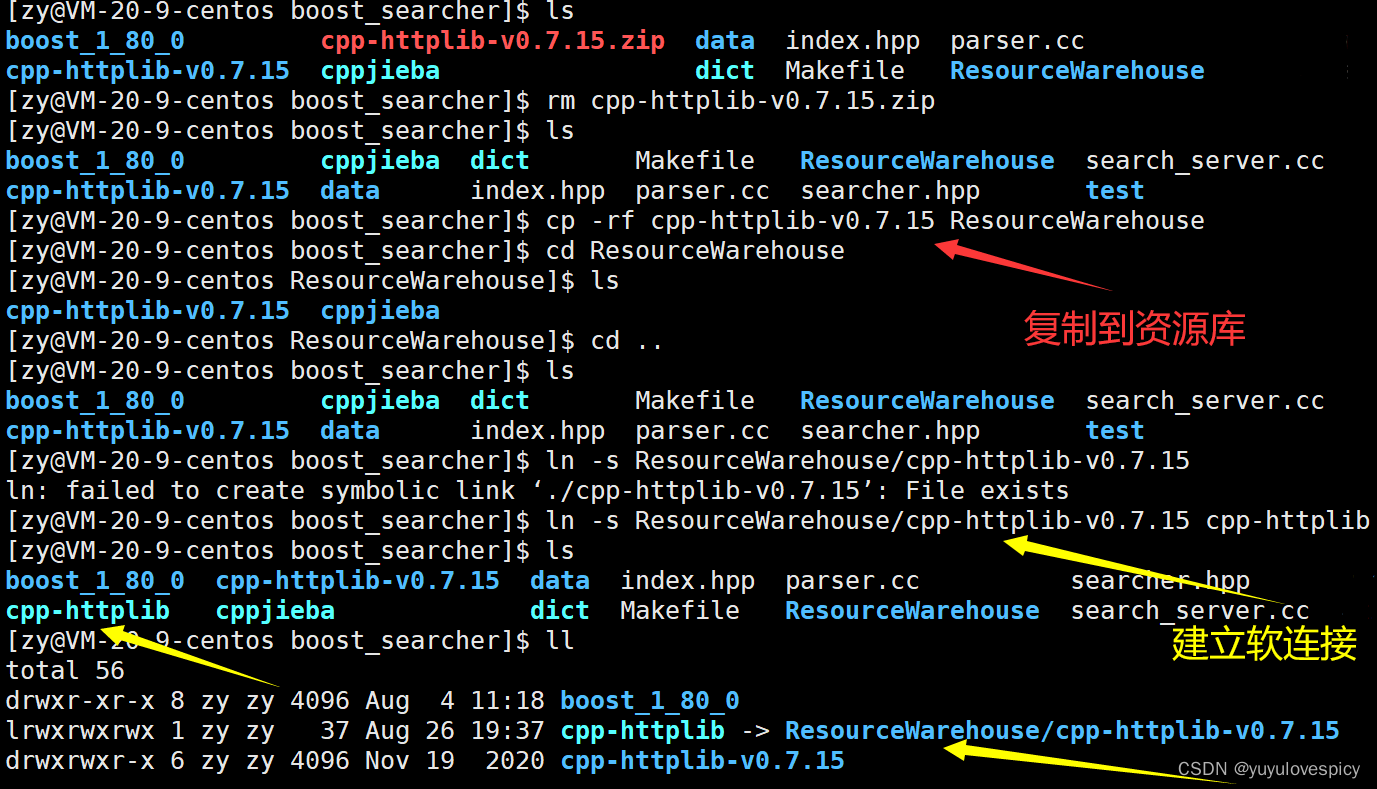
我们就有了对cpp-httplib库资源的链接
PS:这里注意,我们cpp-httplib的实现是运用到了原生线程库的,所以我们在编译的时候,需要链接线程库-lpthread
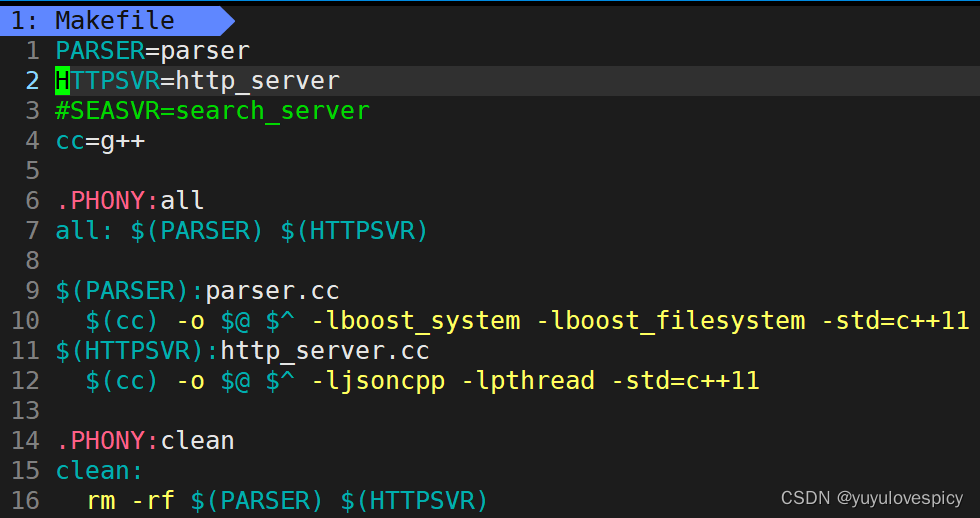
8.2.3使用cpp-httplib库
友情提示: #include "cpp-httplib/httplib.h"
使用测试:
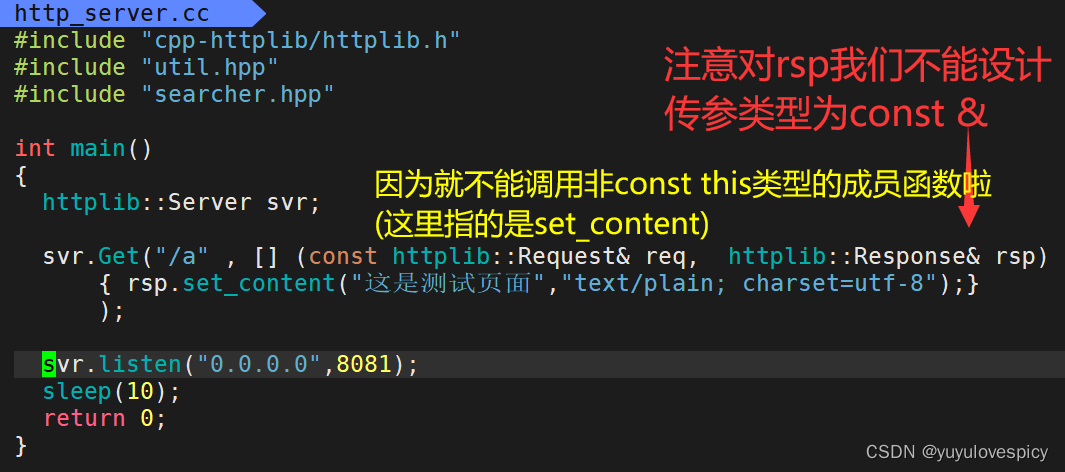
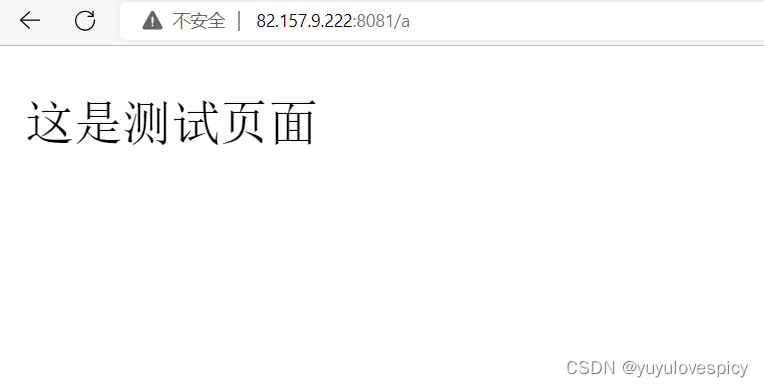
8.3编写搜索服务端http_server.cc
PS:设置服务端的web根目录wwwroot/index.html,web根目录就是直接访问该IP: Port端口时默认显示的网页。web根目录这里我们在后续实现前端的网页HTML时再进行演示。
http_server代码结构:
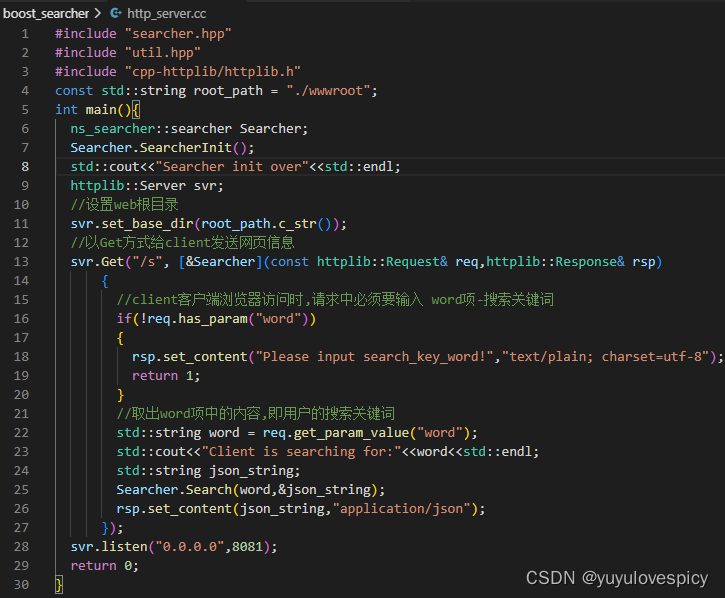
http_server搜索端测试:
9.前端部分代码实现
9.1前端基础说明
我们boost搜索引擎的主要代码(后端)已经完成,我们接下来简单介绍一下前端。
了解前端三大件:html , css , javascript(js)
html:是网页的骨骼 --- 负责网页结构
css: 网页的皮肉 --- 负责网页的美观
js:网页的灵魂 --- 负责动态效果,以及前后端交互
前端学习网站推荐:http://www.w3school.com.cn
9.2编写前端代码工具选择及其安装
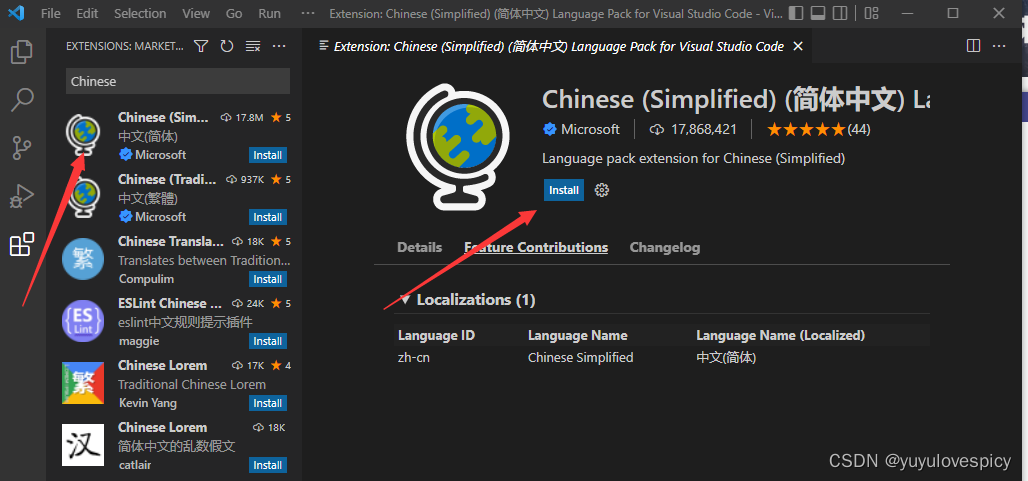
我们使用Vscode连接云服务器进行前端代码的编写 , 下面我们安装Vscode并进行连接。
#1.进入Vscode官方网站进行下载。
#2.下载相关插件
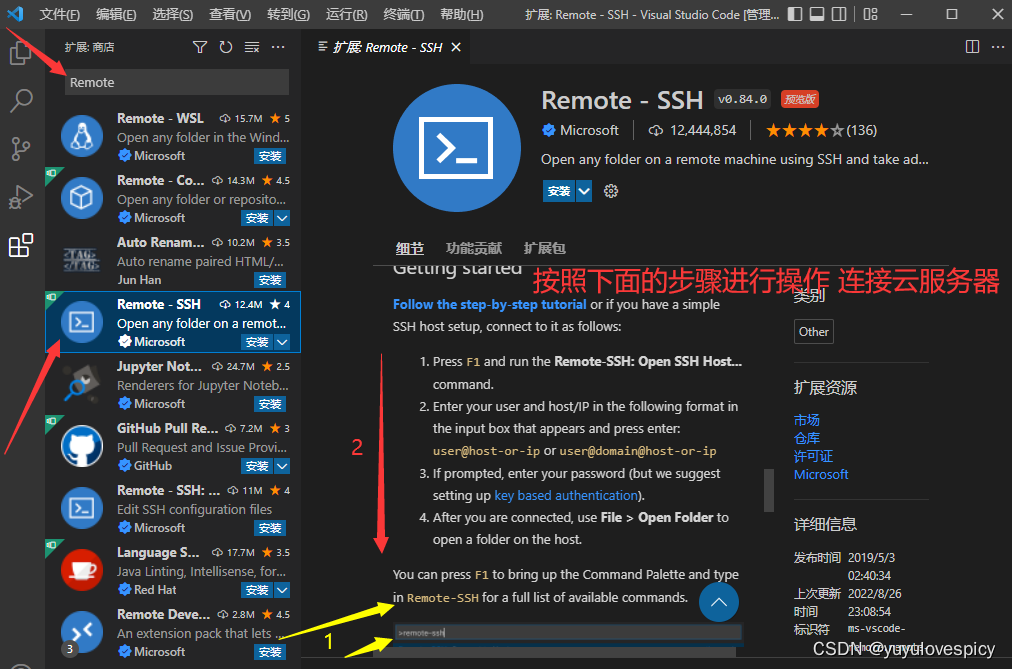
示例:
【1】安装好Remote - SSH之后 ,按F1打开输入对话框。
【2】输入remote-ssh
【3】ssh user_name@82.157.9.22
之后就会点击下图示主机进行连接主机 , 再打开文件夹即可找到自己的工作目录。
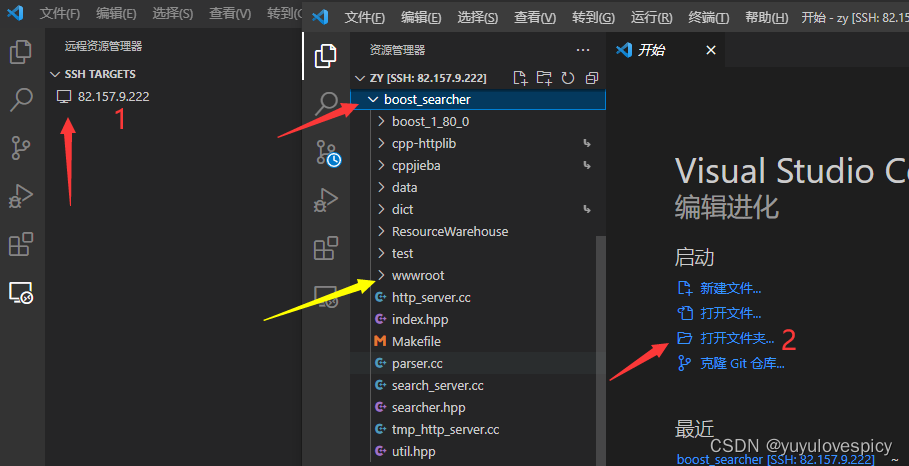
9.3 Html网页结构书写
9.3.1搜索引擎网页基本结构设计

9.3.2HTML网页代码基本实现
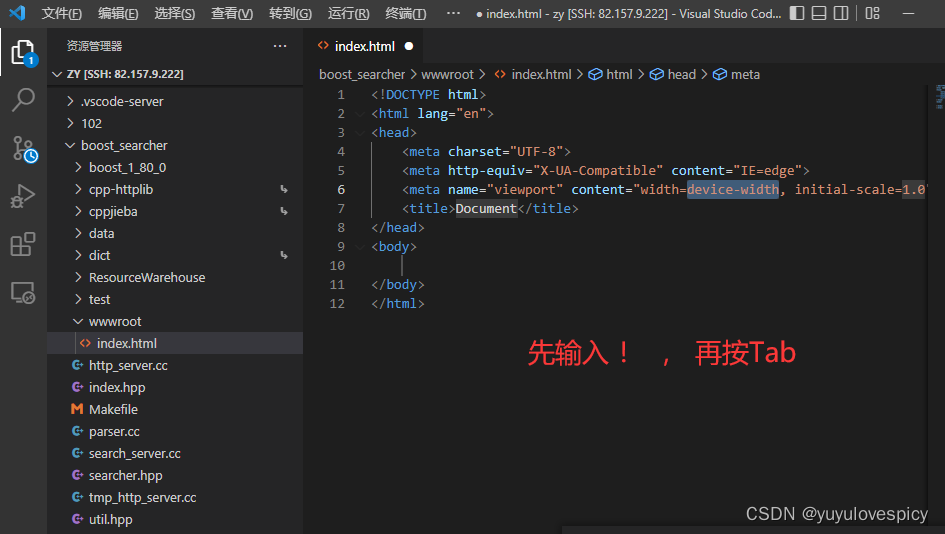
进入wwwroot/index.html进行代码书写
下面我们先介绍一下快捷键:
!+ Tab :会自动设计出html网页代码基本结构
h1 + Tab :会自动设计出h1标签
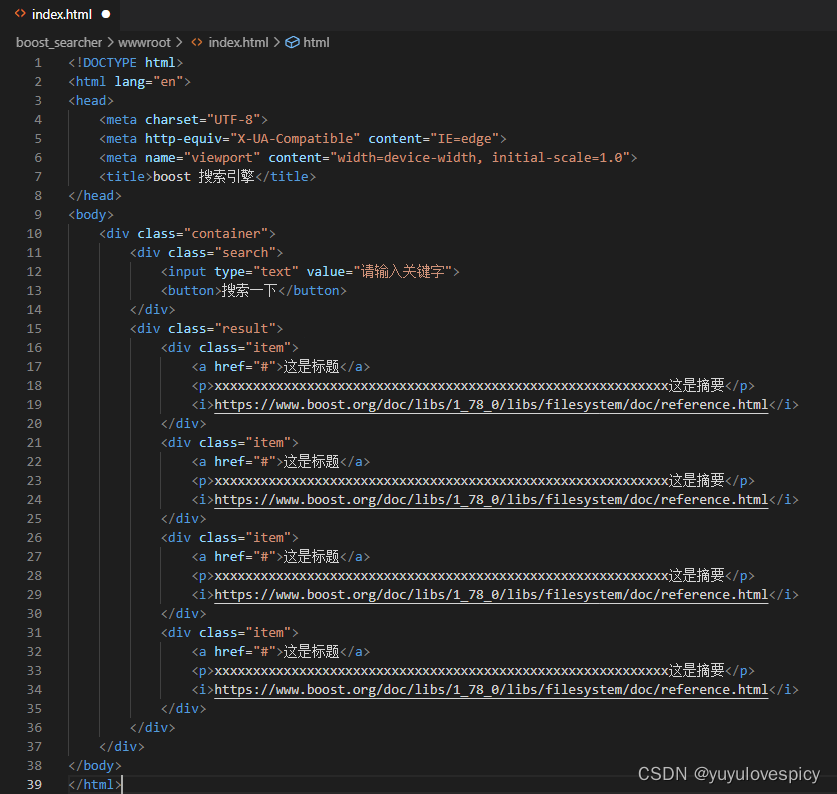
我们按照9.3.1搜索引擎根目录网页基本结构设计 ,设计如下的HTML文件。
代码展示:
web根目录:wwwroot/index.hmtl 网页测试:

9.4 CSS网页样式设置
对网页进行样式设置 (给骨骼加上皮肉)
设置样式的本质: 找到想设置的标签, 设置它的属性。
1. 选择特定的标签: 类选择器, 标签选择器, 符合选择器
9.4.1对网页进行总体样式设置
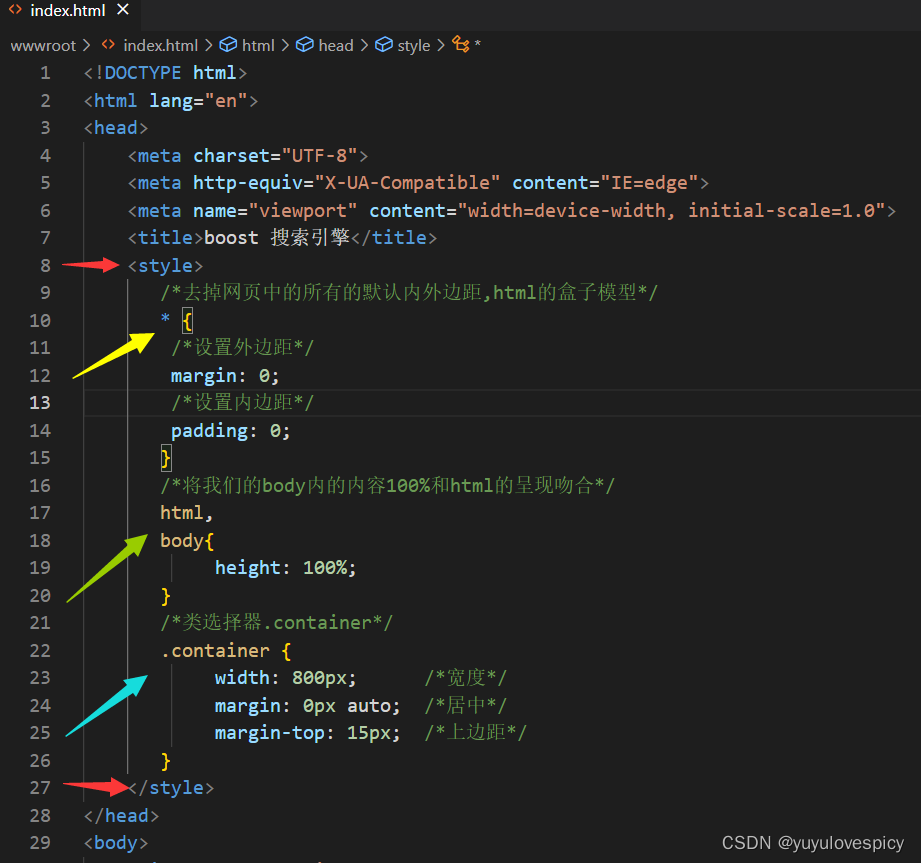
web根目录:wwwroot/index.hmtl 网页测试:
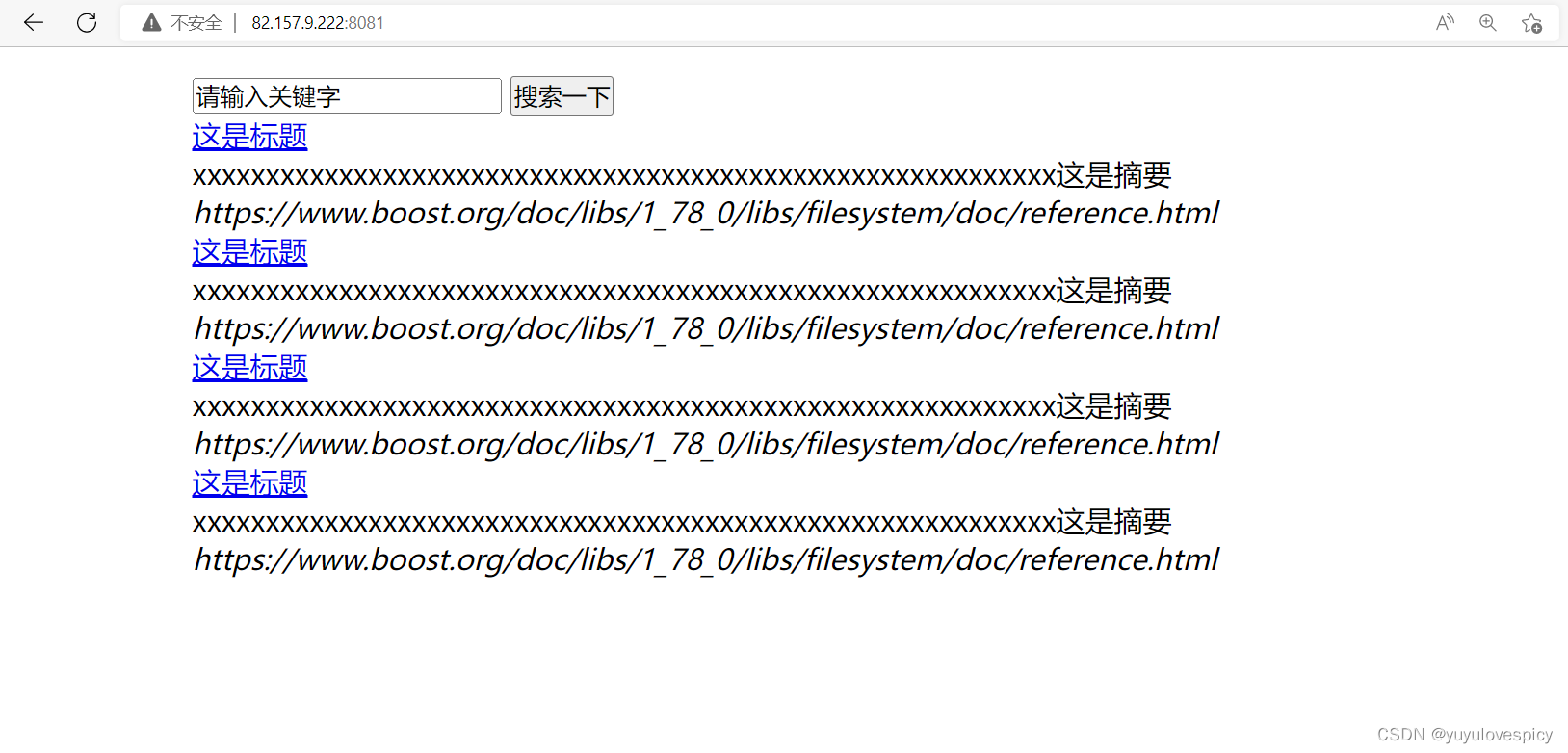
9.4.2对标题进行样式设置
web根目录:wwwroot/index.hmtl 网页测试:
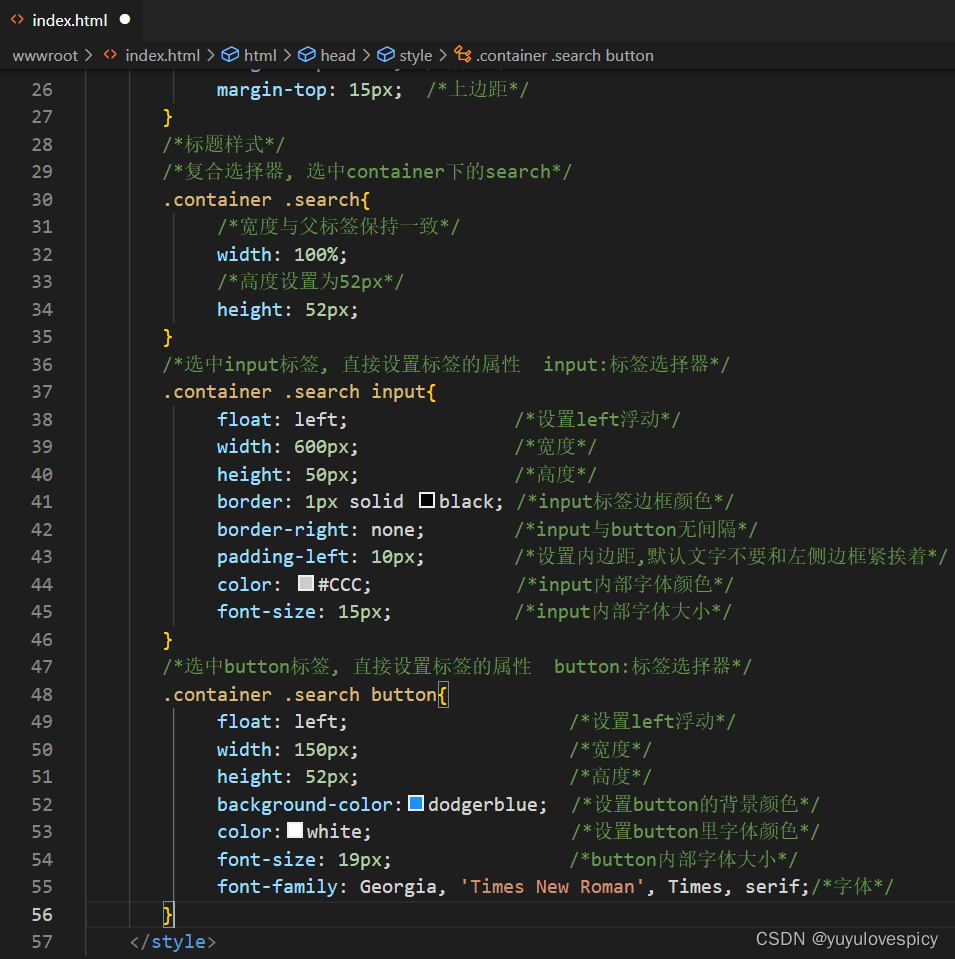
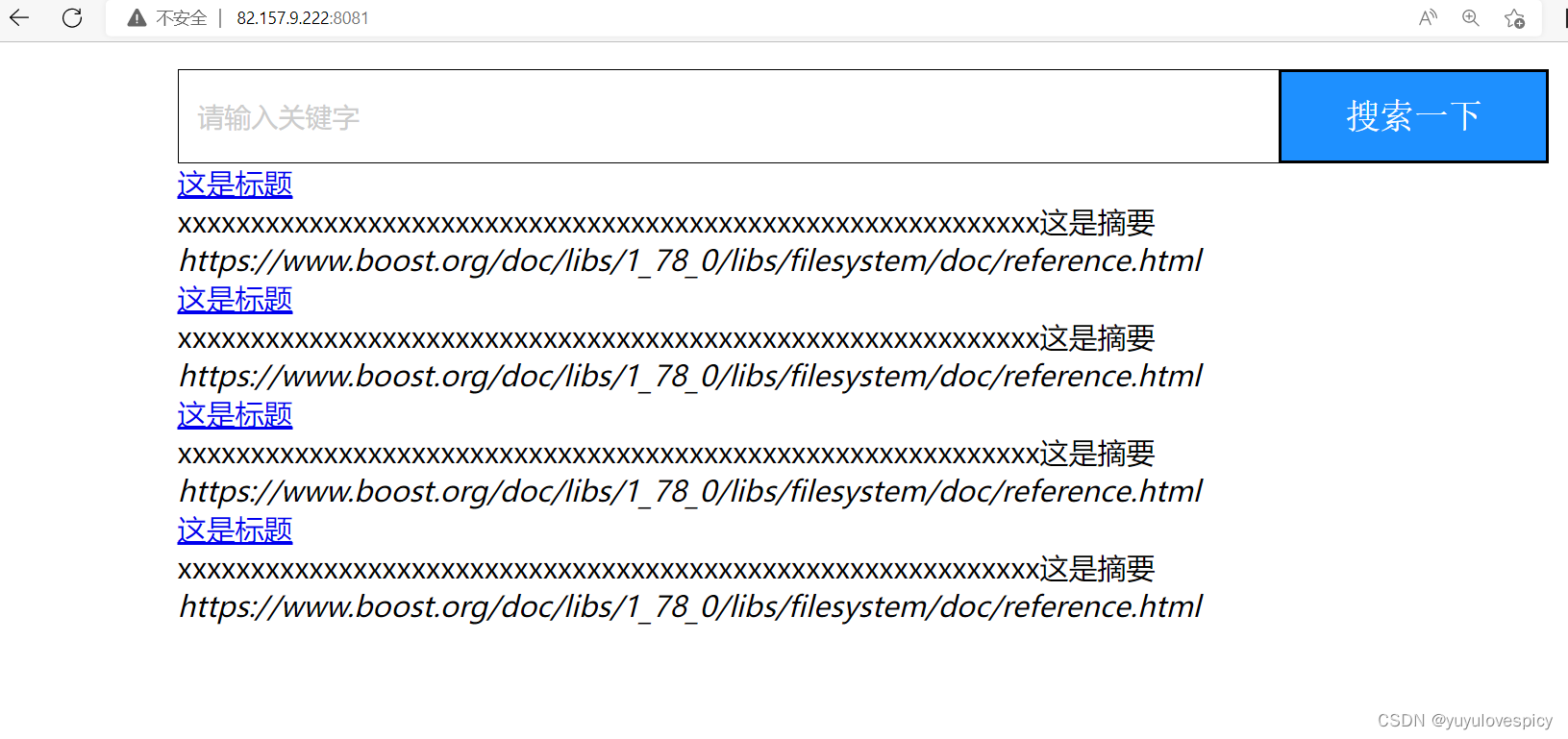 9.4.3对搜索内容进行样式设置
9.4.3对搜索内容进行样式设置
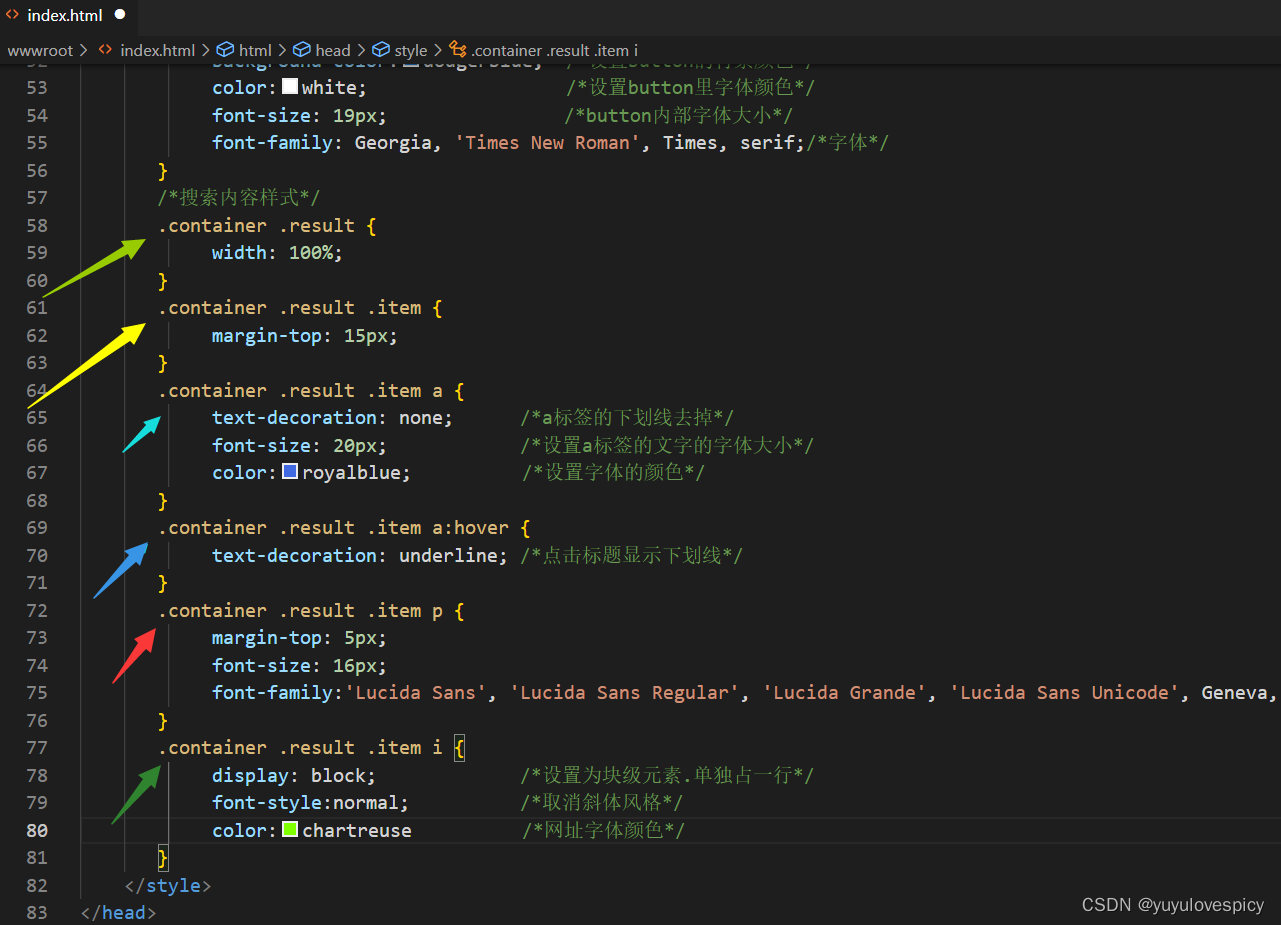
web根目录:wwwroot/index.hmtl 网页测试:
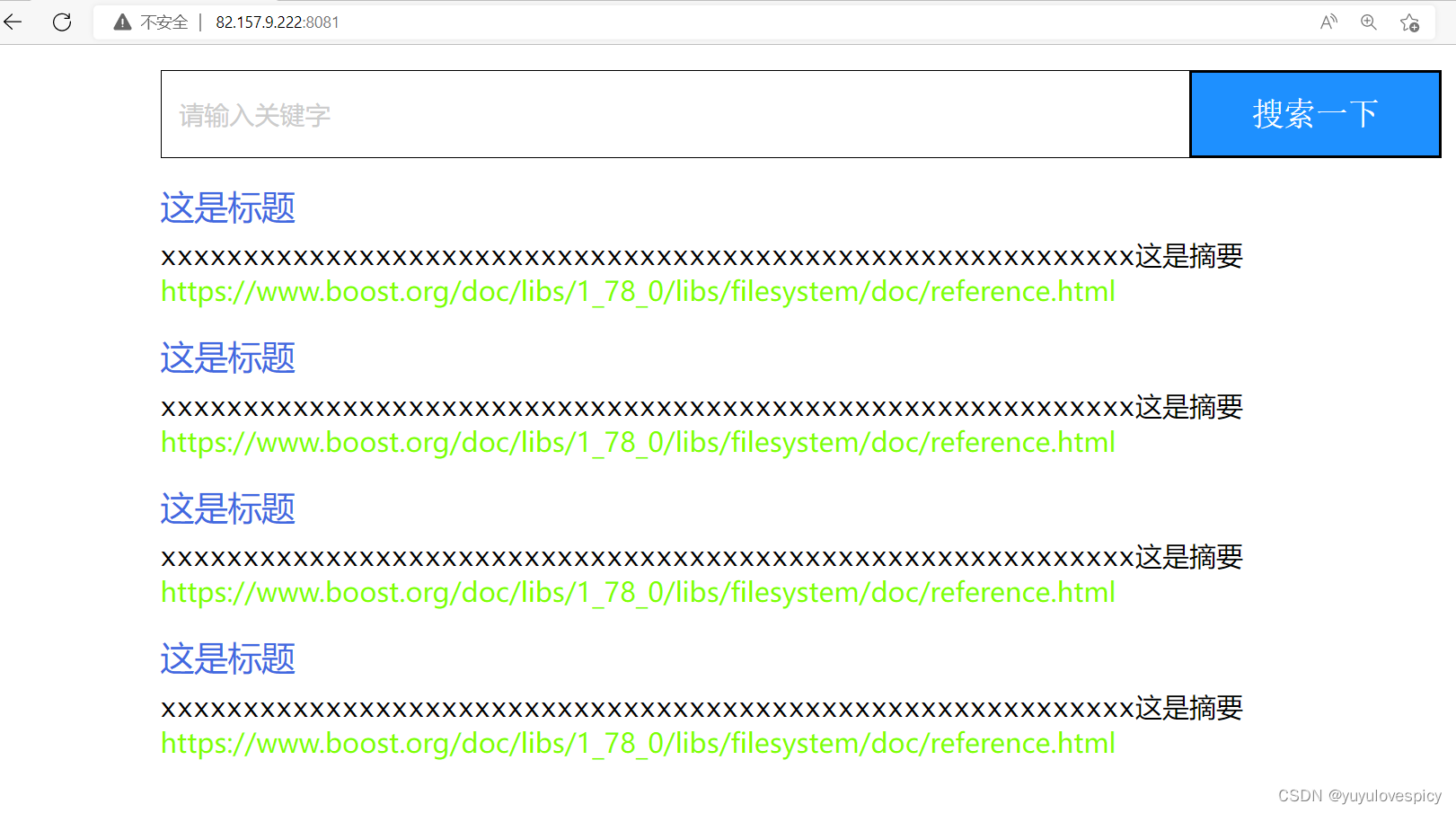
9.5 Js前后端交互
9.5.1网页Search()搜索函数初测试
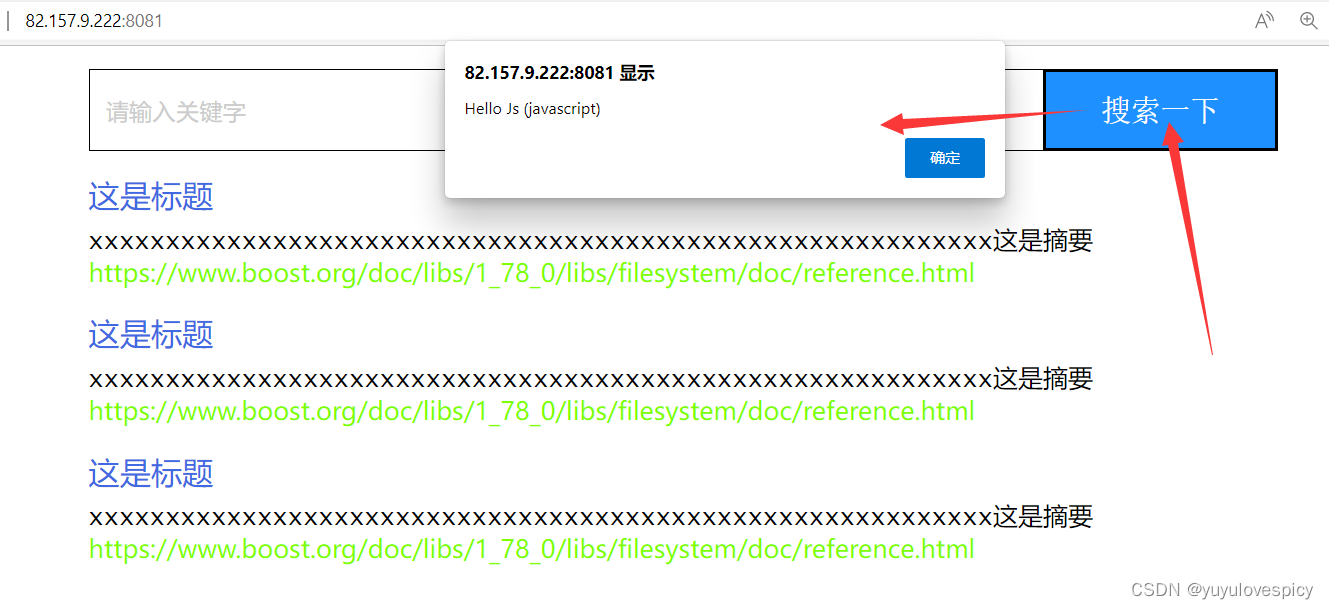
点击搜索一下按钮,我们可以进行搜索功能。
即我们需要添加点击按钮button时,会发生搜索Search()事件,执行Search()函数
初测试代码结构:
初测试结果:
9.5.2引入JQuery库
我们使用JQuery库 (就像C++语言之于C++标准库的关系)
来进行前后端交互,Js代码部分的书写。
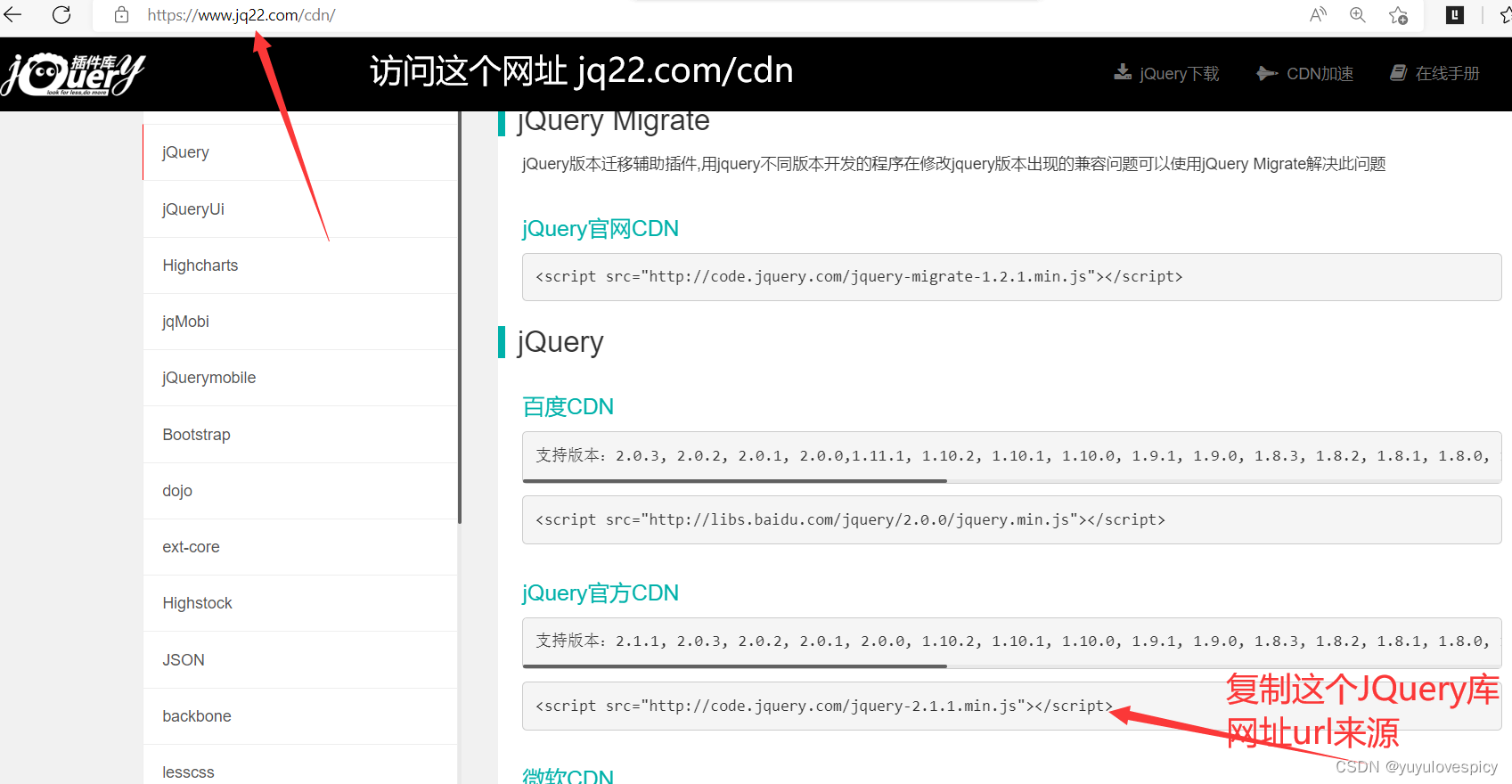
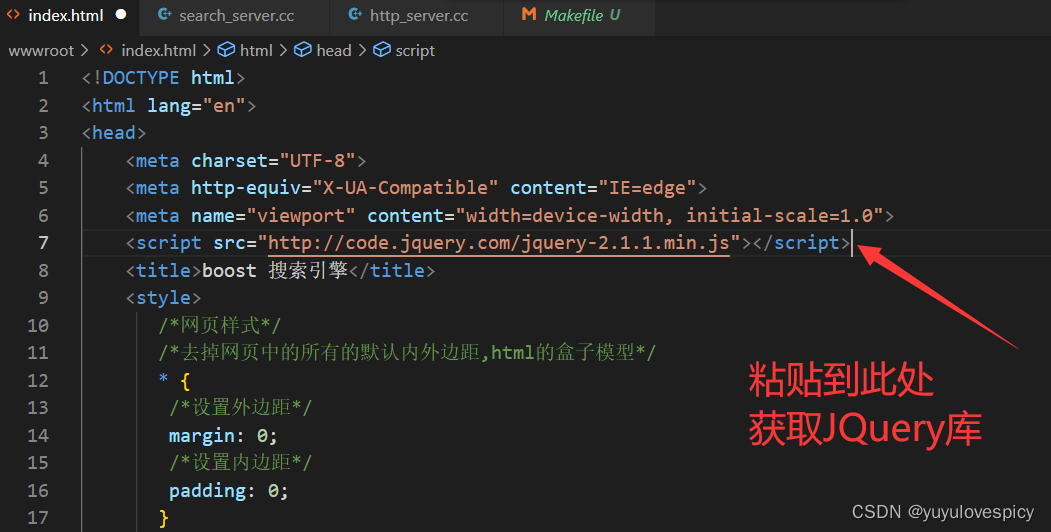
下面利用JQuery进行前后端交互搜索服务模块的编写。
9.5.3网页Search()搜索函数书写
#1.获取搜索原生结果data

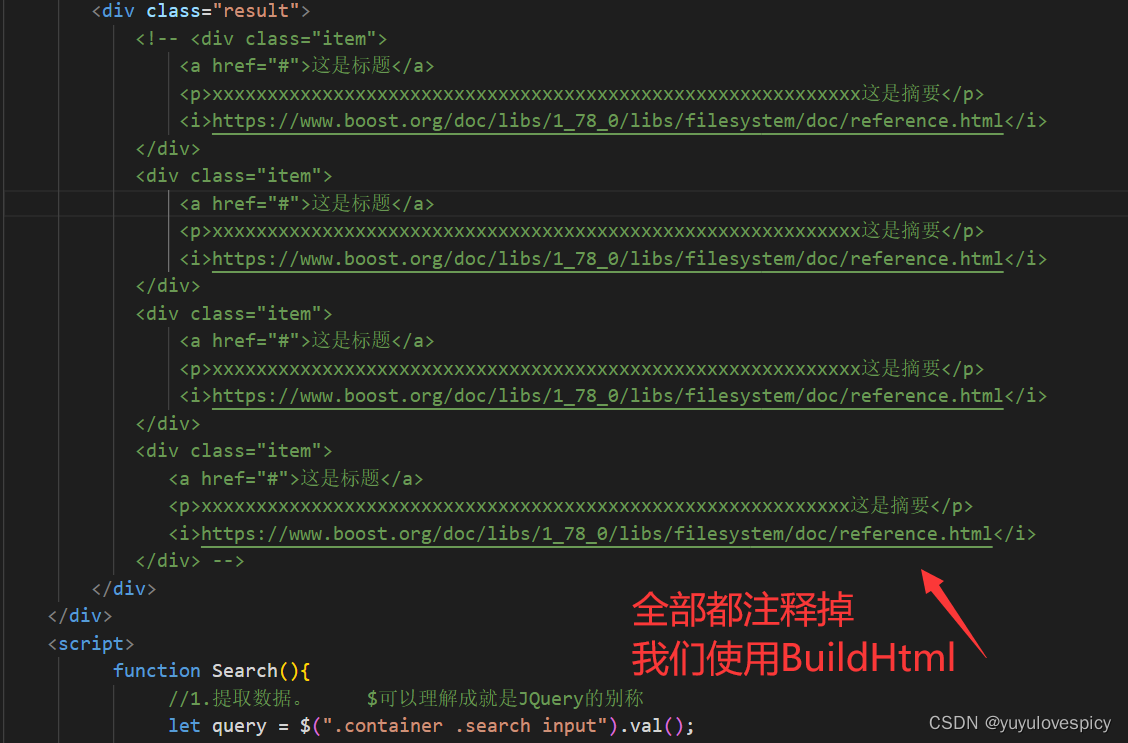
#2.根据搜索结果,建立搜索结果网页。
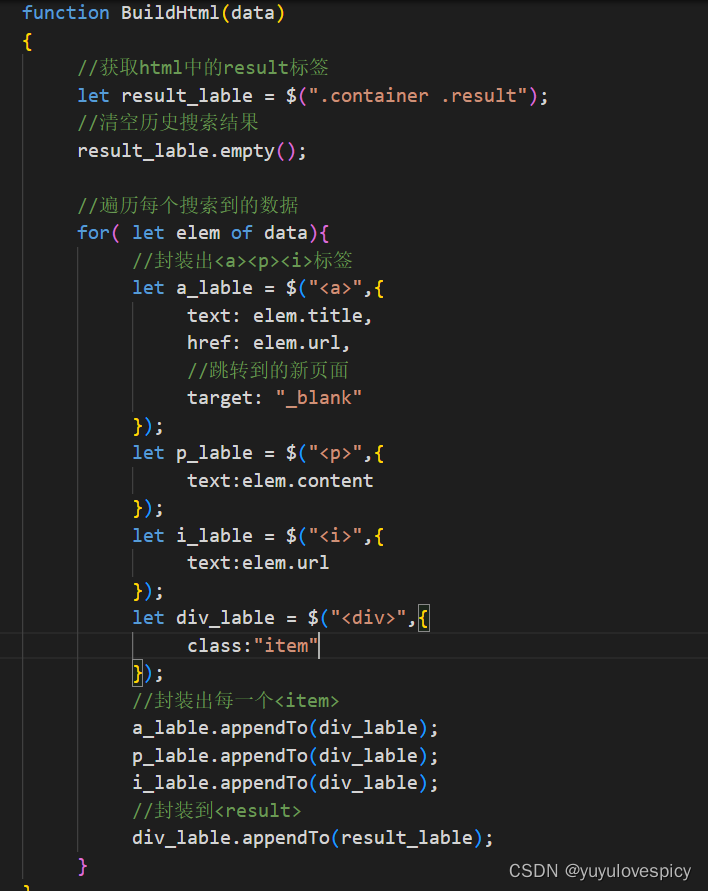
搜索功能测试:

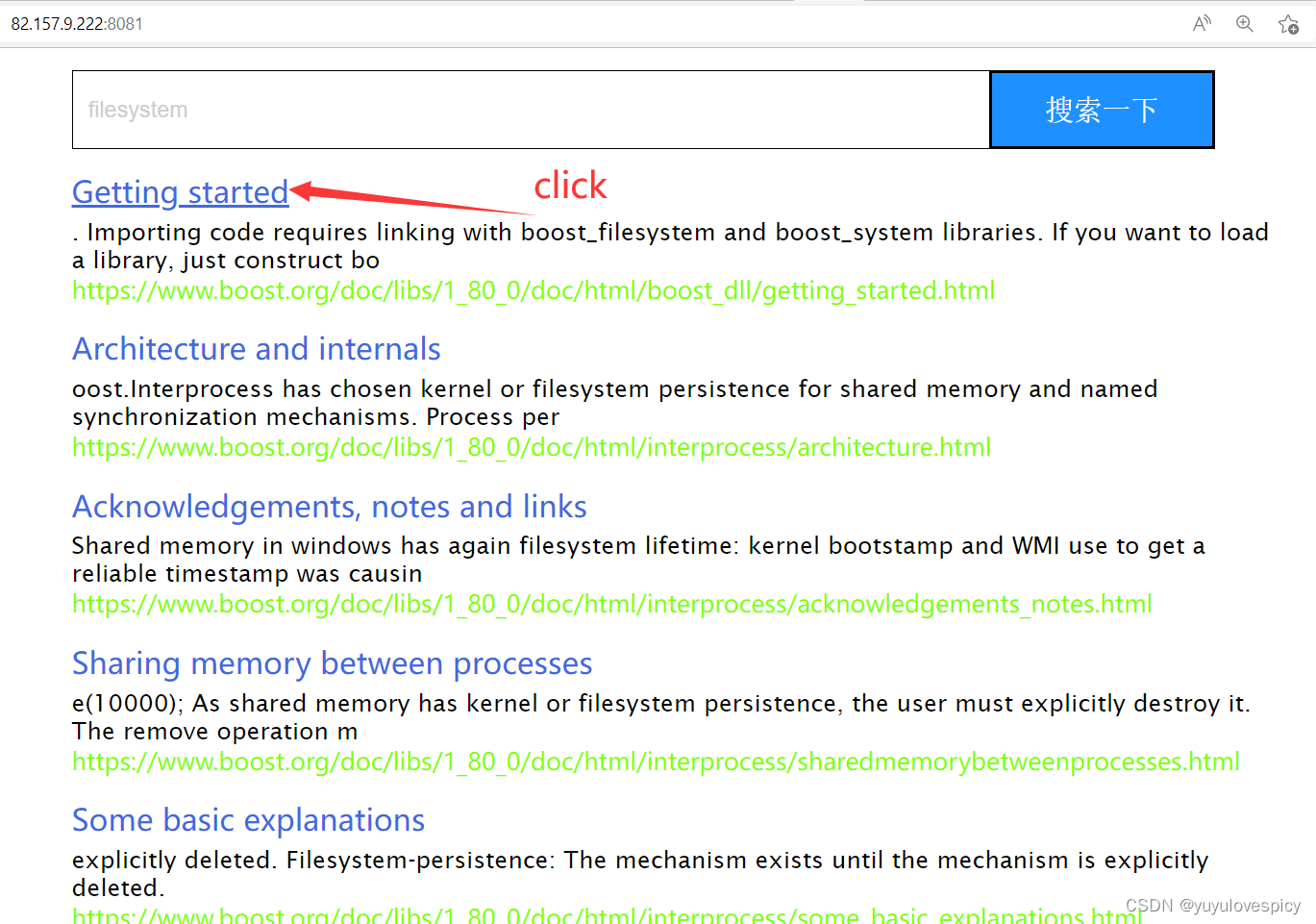
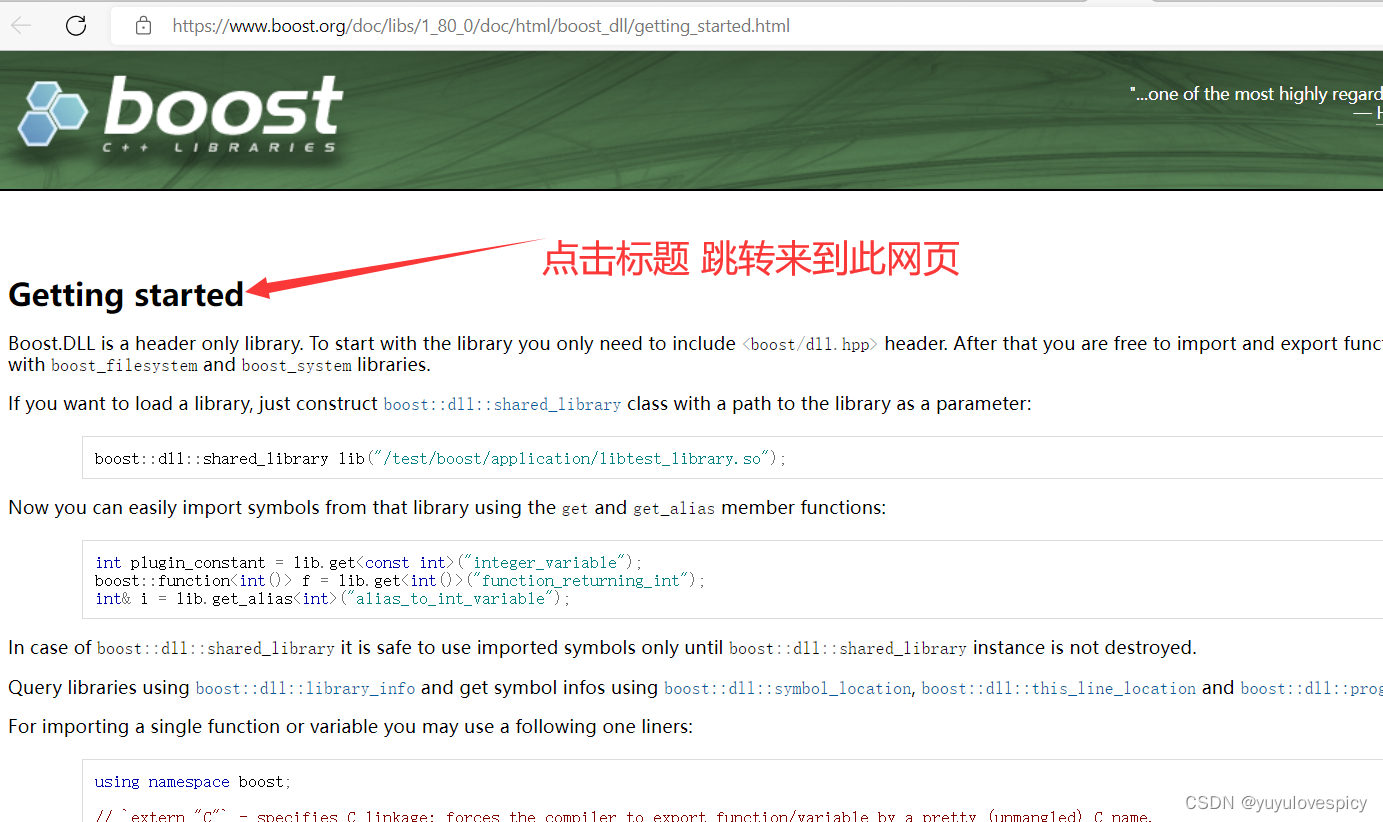
10.小细节完善
现在我们的代码已经基本成型了, 下面我们对小地方进行修改。
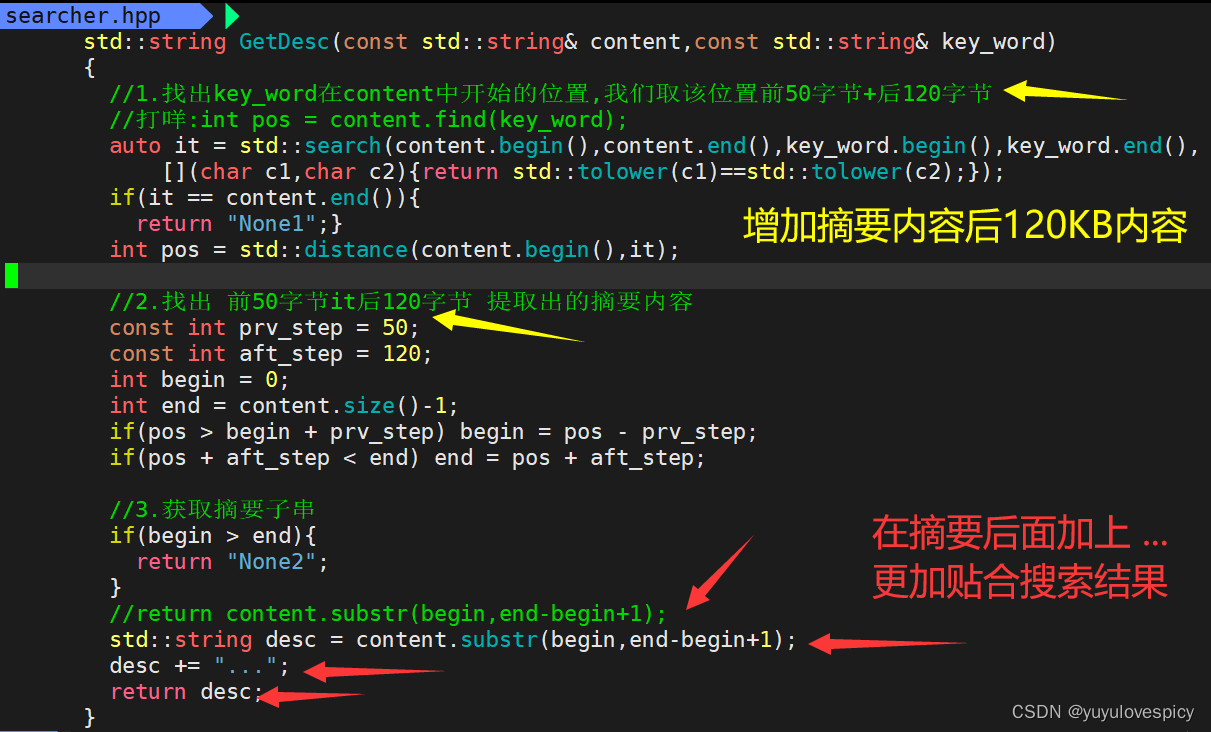
10.1摘要完善
在我们的搜索结果展示上, 增加摘要内容,将摘要内容后面加 ... , 提示摘要部分。
修改代码:
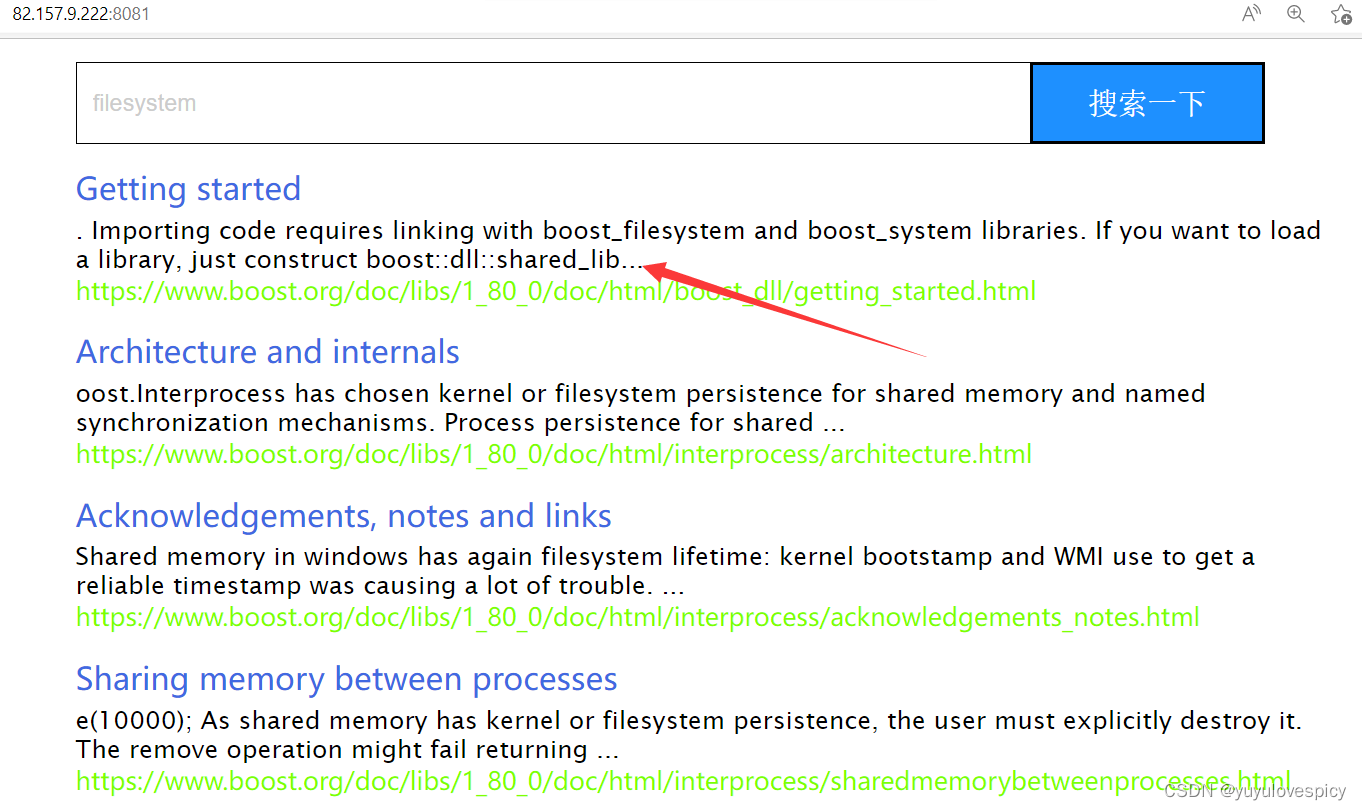
10.2去重完善
前情提要:之前在写searcher.hpp时,我们对搜索词query进行jieba分词后,由于分出的是多个词段,所以在进行倒排索引之后,我们会查到重复的文档信息,我们当时是用set去重,这样的确可以起到去重的目的,但是事实上不能体现权重这一属性。
举个例子: 一个query搜索关键词,我们将其分词成4个词段,这四个词段都能倒排搜索到同一个文档信息,那这个文档信息的优先级事实上应该是高的,我们之前无脑对搜索到的文档信息进行去重是不合理的。我们应该根据去重的数量,对有重复的文档信息word_info进行权重_weight
的增加。
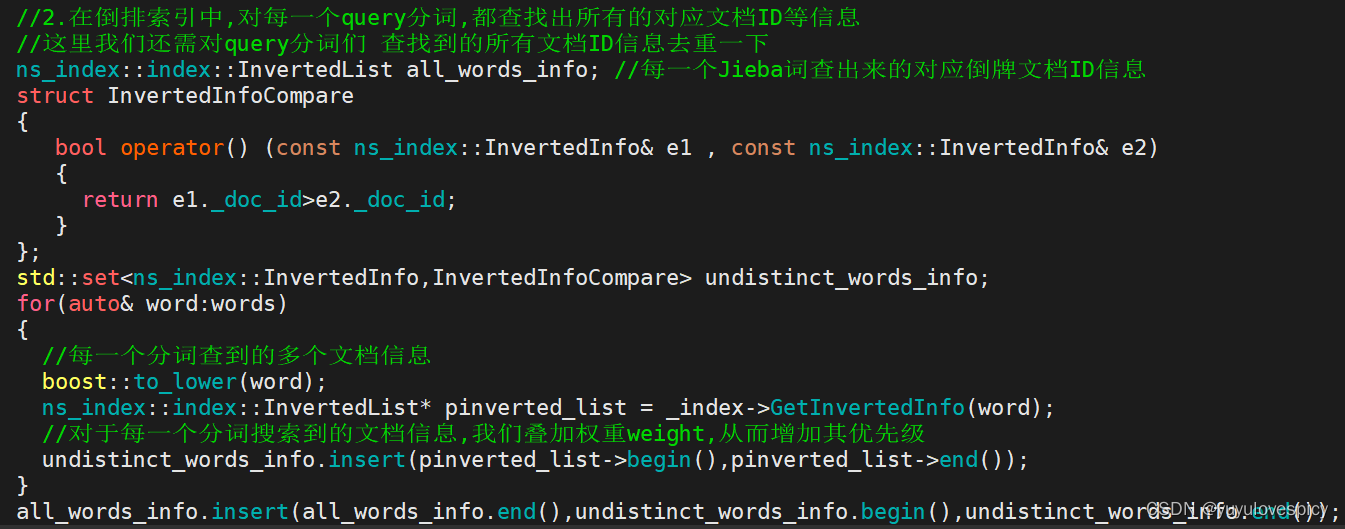
下面用之前的代码进行伪代码的修改:
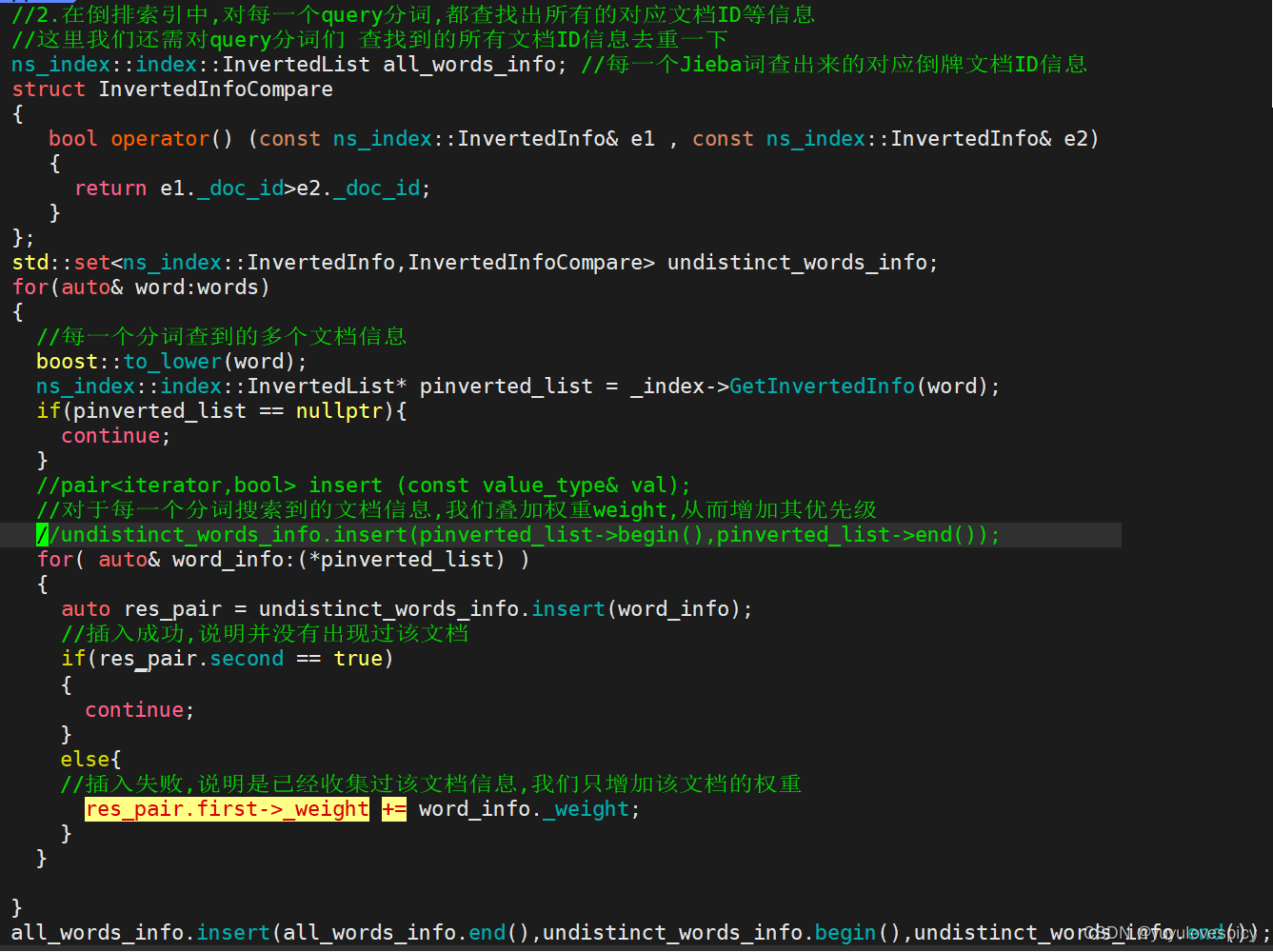
看上图代码,而当我们使用set进行修改时,并不能达到我们的预期(因为set的key并不可以修改),所以我们改用map容器,即可完成去重以及权重叠加两个工作。
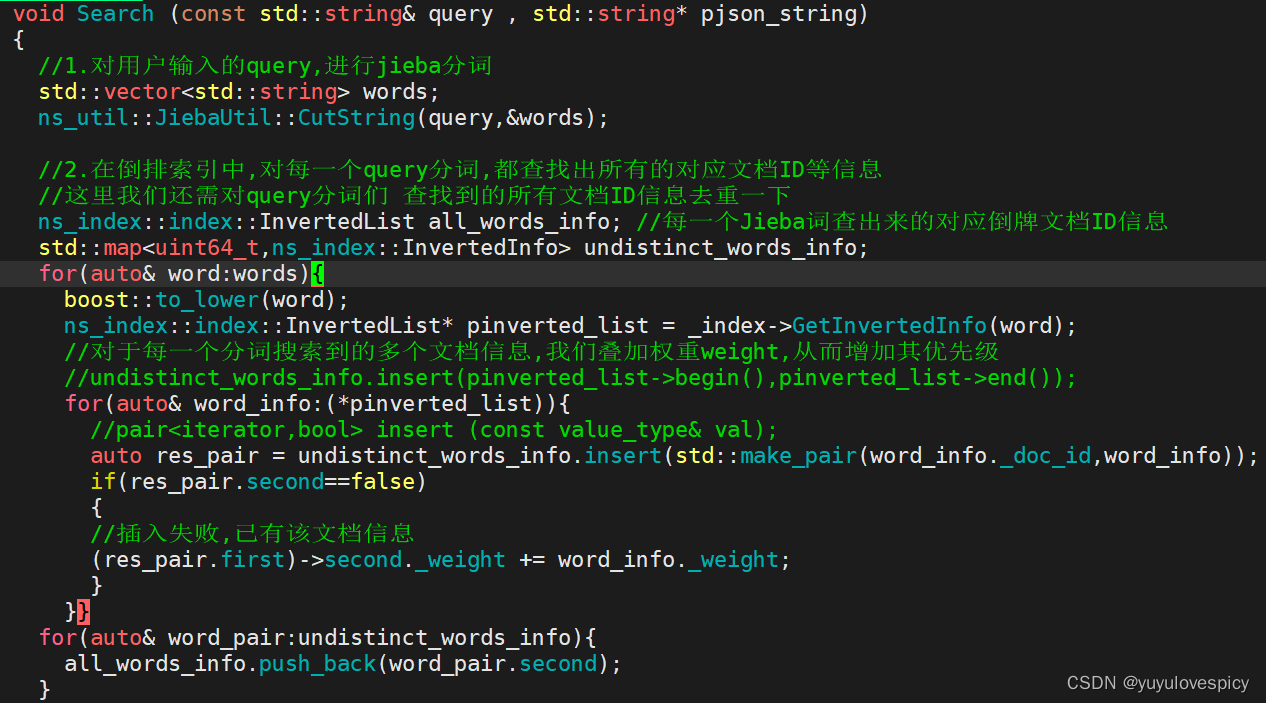
测试结果:
可见搜索结果发生了变化,且更加贴合我们的搜索结果预期。
11.添加日志与部署到Linux中
打日志,说人话就是在服务端打印提示信息: 哪个文件中的哪一行,执行发生了什么。
11.1建立日志库/接口
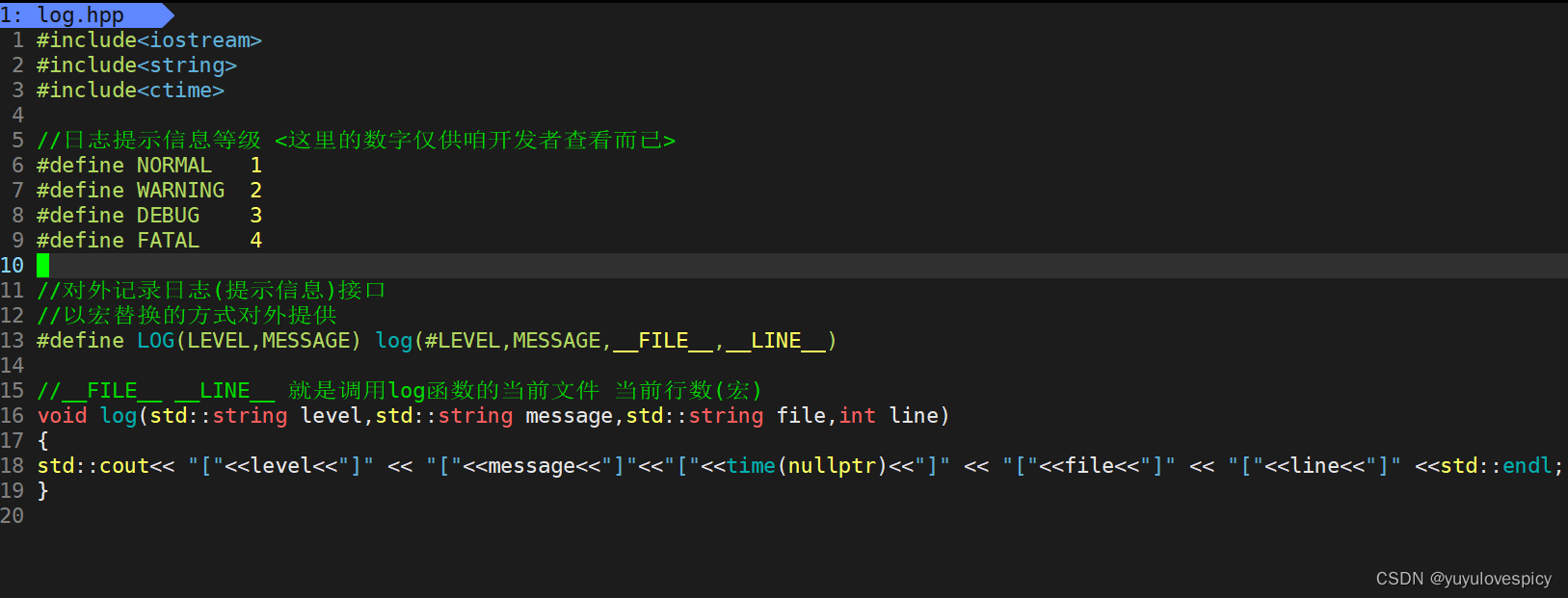
语法提示 : #LEVEL #后面的宏: 对之不进行宏替换,而是自动将其作为一个字符串
举个例子: LOG(WARNING,"这里有xxx警告") ->
在预处理阶段处理成: log( "WARNING" , "这里有xxx警告" , "调用log的文件名" , "调用行数")
最后打印出来的信息: [WARNING][这里有xxx警告][searcher.hpp][50]
11.2进行日志部署
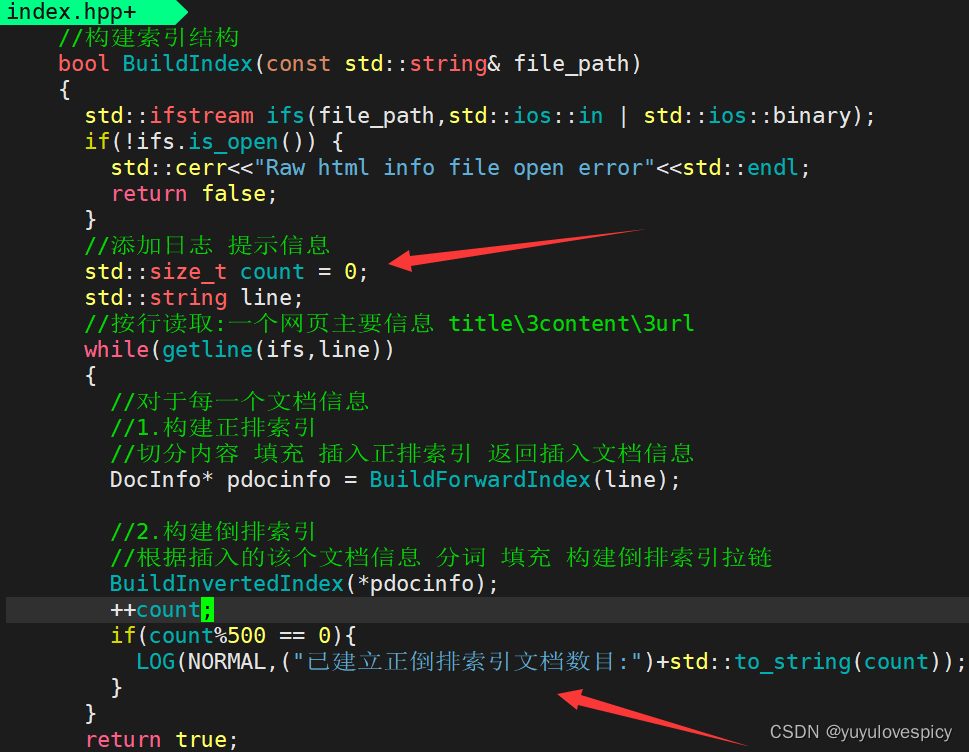
11.2.1在index.hpp中进行日志部署
在index.hpp中进行日志即提示信息的部署:
友情提示: #include "log.hpp"
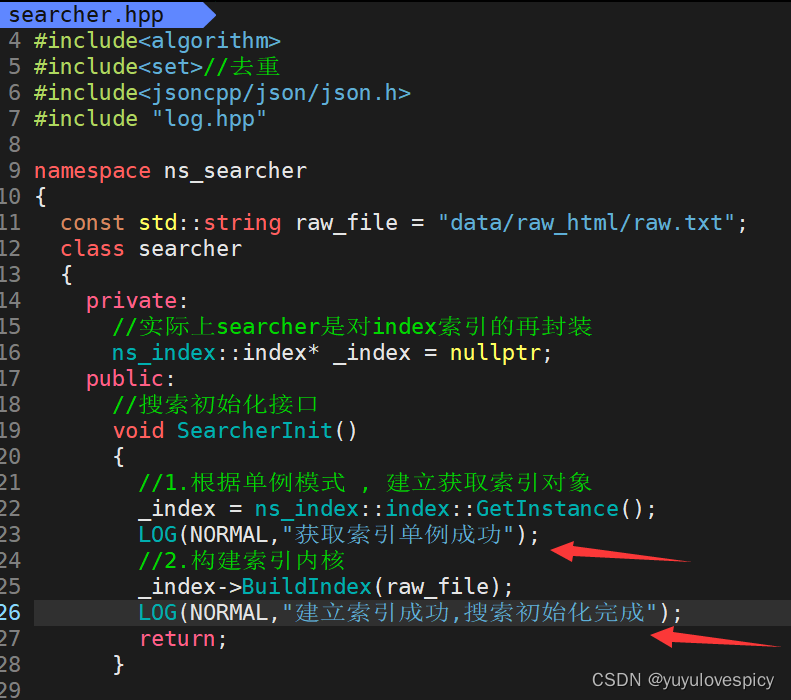
11.2.2在searcher.hpp中进行日志部署
11.2.3在http_server.cc中进行日志部署
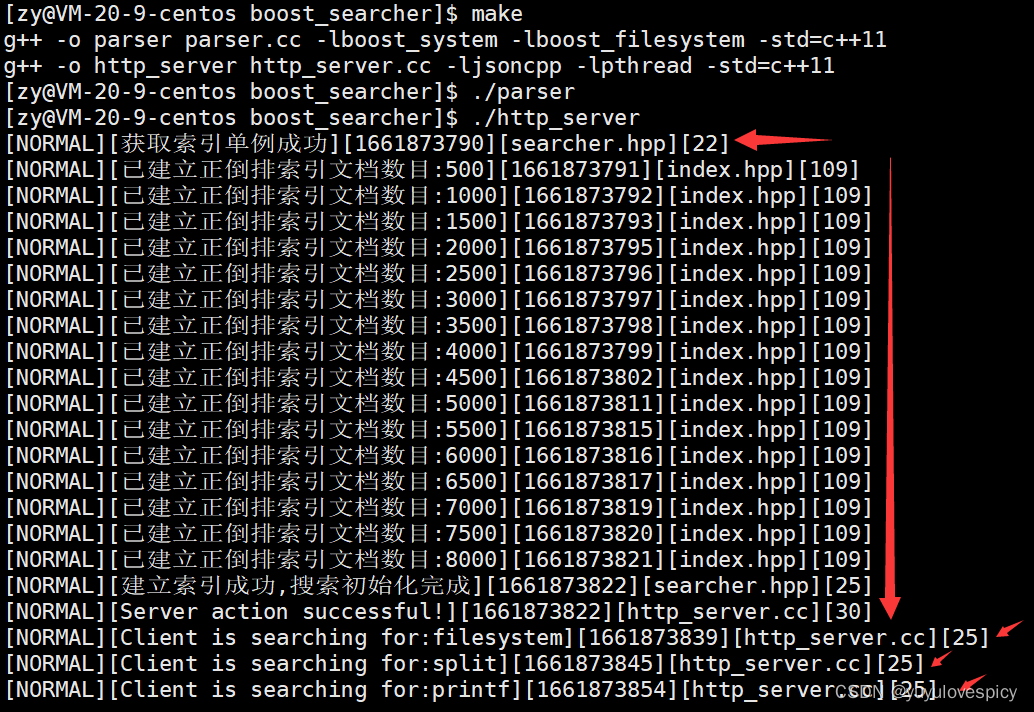
11.2.4日志打印测试
11.3后台部署服务
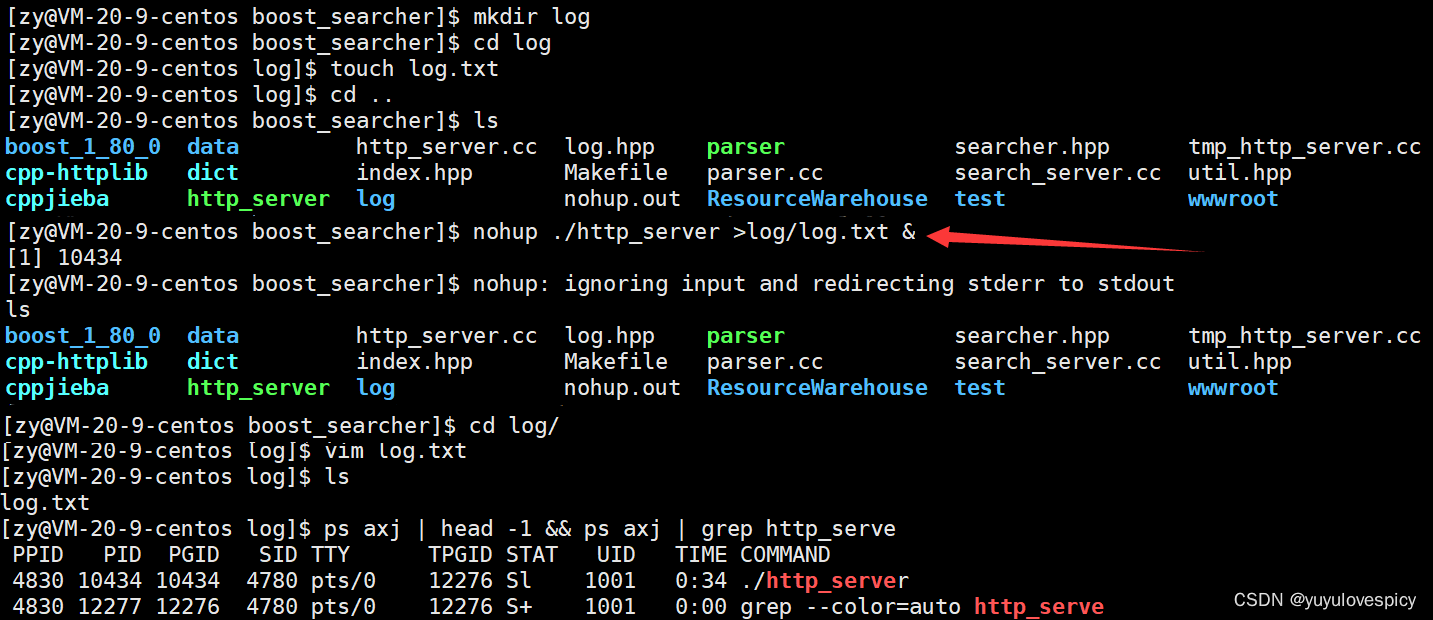
11.3.1介绍nohup指令
nohup的执行:
nohup指令: 将服务进程以守护进程的方式执行 , 使关闭XShell之后仍可以访问该服务。
例如 nohup ./http_server
如果让程序在后台执行, 可以在末尾加上 & , 程序就会隐身 , 不会显示在终端。
例如 nohup ./http_server &
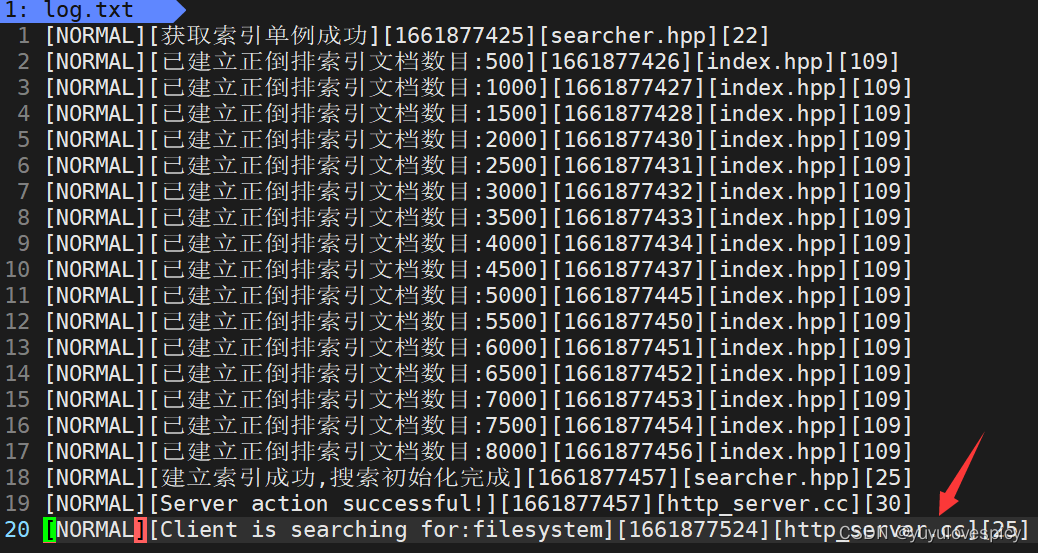
nohup形成的文件:
执行完上述的nohup指令之后,将会形成一个nohup.out存储日志信息文件,可以cat查看该文件
11.3.2使用nohup指令进行服务,日志部署
实现基本的 自动服务+更新日志 的部署
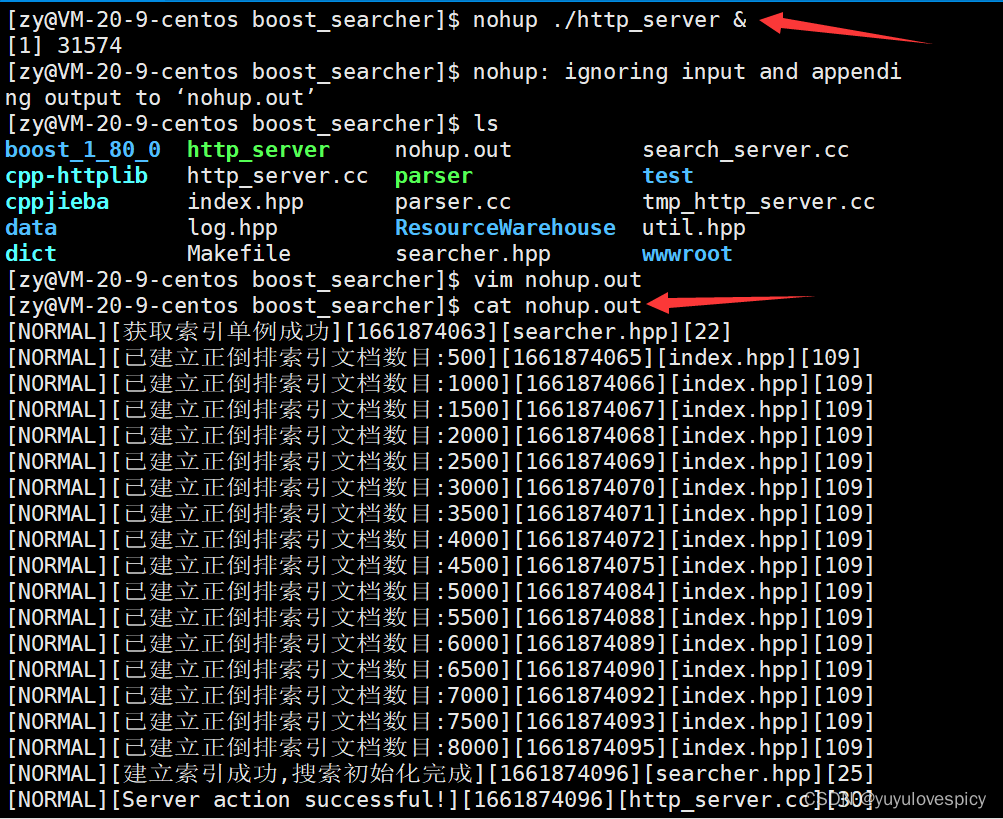
使用nohup指令后,我们的http_server就可以一直在后台执行了,即使我们关闭了XShell!!!
而且日志信息也会自动同步更新到nohup.out中。 (如下验证)
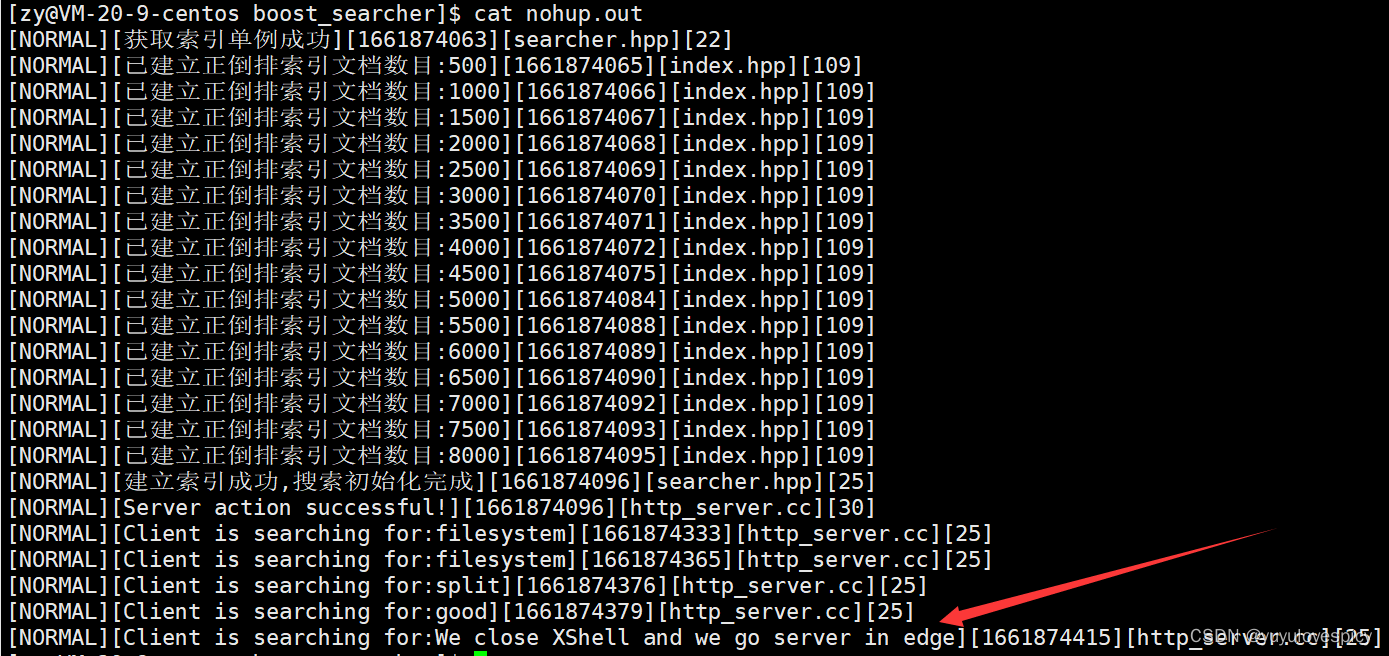
事实上,我们也可以存一个专门的日志文件夹,进行日志信息的存储。
而这之前我们要删除上一条对于日志 服务的部署。
这个较为简单:
ps axj | head -1 && ps axj | grep http_server //找到相应服务的PID。
kill -9 SERVER_PID //对该服务发送信号,结束服务。

再实现 自动服务+更新日志 的部署
总之,我们就完成了 自动服务+自动更新日志 的部署!!!
12.结项总结
至此,我们就完成了boost搜索引擎项目,我们可以随时访问该服务网址,进行在boost准标准库相应接口的站内搜索。
这里我们再总结一下该项目的可扩展点
1.我们受限于云服务器配置,没有做boost库的整站搜索,而只是做了1.8.0版本下的doc/html/*下的文件搜索。
2.我们在搜索引擎中,对于权重的设置先后显示顺序,我们其实可以叠加一些算法,比如可以设置竞价排名,热点统计,额外增加某些文档的权重。
3.我们可以利用数据库,设置用户登录注册,引入对MySQL的使用。
PS:欢迎大家及时指正此项目的不足,有任何问题可以随时联系我。
欢迎大家的支持!!!















 2841
2841











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









