







引言
《算法导论》在本章将向我们介绍一个算法设计和分析框架,在后续的章节也将在这个框架的基础上来分许算法。
名词解释:
(1):伪代码
伪代码就是以最清晰、最简洁的表示方法来说明算法,而忽略数据抽象、模块性和错误处理的问题
(2):循环不变式
每次循环从数组A中取出第j个元素插入有序数列A[1…..j-1],然后递增j,这样A[1,j-1]的有序性始终保持,这就是所谓循环不变式。(可用于证明算法的正确性)
(3):运行时间
指程序执行的操作数或步数。
关于循环不变式,须证明以下三个性质
(1):初始化:循环第一次迭代之前,循环不变式为真
(2):保持:如果循环在某次迭前,它为真,那么下次迭代之前,它仍为真
(3):终止:在循环终止时,循环不变式提供了一个有助于证明算法正确性的性质。
上述的三个证明,类似数学的数学归纳法:
初始化为基本情况
保持为归纳步,
终止性不同于我们的归纳法,归纳法是无限的,但是它有终止条件
伪代码的一些约定(参考博客)
插入排序
(1)思路:
在一个数组中,把未排好序的第一个元素取出来,作为一个关键字,插入到已经排好序的数列中,插入到恰当的位置,使得插入该关键字后的数列依旧是有序的。
(2)伪代码:
for j=2 to A.length
key=A[j]
//insert A[j] into the sorted sequence A[1...j-1]
i=j-1
while i>0 && A[i]>key
A[i+1]=A[i]
i=i-1
A[i+1]=key 证明插入排序的,三个性质的成立
(1)初始化:当子数组只有一个元素时,循环不变式一定成立
(2)保持: 每次插入一个数后得到仍然是一个有序的数列,循环不变式成立
(3)终止:数组是有长度的,循环一定会终止
分析算法
RAM模型:描述串行算法所用资源及其代价的模型。(请参考)
分析插入排序算法:
计算具有n个输入值上的INSERTION-SORT的运行时间T(n);
T(n)=c1n+c2(n-1)+c4(n-1)+c5(∑tj)+c6(∑(tj-1))+c7(∑(tj-1))+c8(n-1)
最好情况就是:输入的数组已经是有序的了,所以tj=1;
所以:T(n)=c1n+c2(n-1)+c4(n-1)+c5(n-1)+c8(n-1)
所以:T(n)=an+c,它为n的线性函数
最坏的情况就是:输入数组是逆序的,此时tj=j
所以有:∑tj=(n(n+1)/2)-1;
∑(tj-1)=n(n-1)/2
所以:T(n)=c1n+c2(n-1)+c4(n-1)+c5((n(n+1)/2)-1)+c6(n(n-1)/2)+c7(n(n-1)/2)+c8(n-1)
所以:它是n的二次函数
上面我们分析了插入算法的最好和最坏情况,但是在余下的章节中,我们将集中于最坏情况的运行时间,理由如下
(1):它给出了任何输入的运行时间的上限,
(2):对某些算法,最坏情况经常出现
(3):平均情况经常和最坏情况大致一样差。
分治算法
分治算法的思路就是:把原问题分解为几个规模较小但类似原问题的子问题,递归地求解这些子问题,然后再合并这些子问题解做为原问题的解。
分治模式在每层递归都要进行三个步骤
(1):把原问题划分为多个子问题(原问题小规模时的实例。)。
(2):解决这些子问题。
(3):合并子问题的解。
以归并排序举例
(1)分解:把待排序的n个序列,分为两个数量相等的子序列
(2)解决:使用归并排序递归的排序两个子序列
(3)合并:把两个已经排好序的子序列合并。
当待排序的子序列只有一个元素时,开始“递归回升”
归并排序代码
#include<iostream>
#include<ctime>
#include<cstdlib>
using namespace std;
void print(int * num, int n)
{
for (int i = 0; i < n; i++)
cout << num[i] << " ";
cout << endl;
}
void Merge_array(int * num,int * b,int low,int mid,int heigh)
{
int i = low;
int j = mid + 1;
int k = 0;
while (i<=mid&& j<=heigh)
{
/*
这里充当的排序的作用,
*/
while (i <= mid && num[i] <= num[j])
b[k++] = num[i++];
while (j <= heigh && num[i] >= num[j])
b[k++] = num[j++];
}
/*
把残余的数据添加到临时数组中
*/
while (j <= heigh)
b[k++] = num[j++];
while (i <= mid)
b[k++] = num[i++];
/*
把排好序的数组重新添加回原来的数据,这样这段数据就是有序的了;
*/
for (i = 0; i < k; i++)
num[low + i] = b[i];
}
void MergeSort(int * num,int *b,int first,int last)
{
if (first < last)
{
int mid = first + ((last - first) >> 1); //利用分治的思想,再利用右移实现除于2的功能
MergeSort(num, b, first, mid);
MergeSort(num, b, mid + 1, last);
Merge_array(num, b, first, mid, last);
}
}
int main()
{
int n,i;
cout << "请输入数据规模:";
cin >> n;
srand((int)time(NULL)); //每次执行种子不同,生成不同的随机数
int * num;
int * b ;
num = new int[n];
b = new int[n];
for (i = 0; i < n; i++)
num[i] = rand();
MergeSort(num, b, 0, n - 1);
print(num,n);
delete[] num;
delete[]b;
system("pause");
return 0;
}分析分治算法
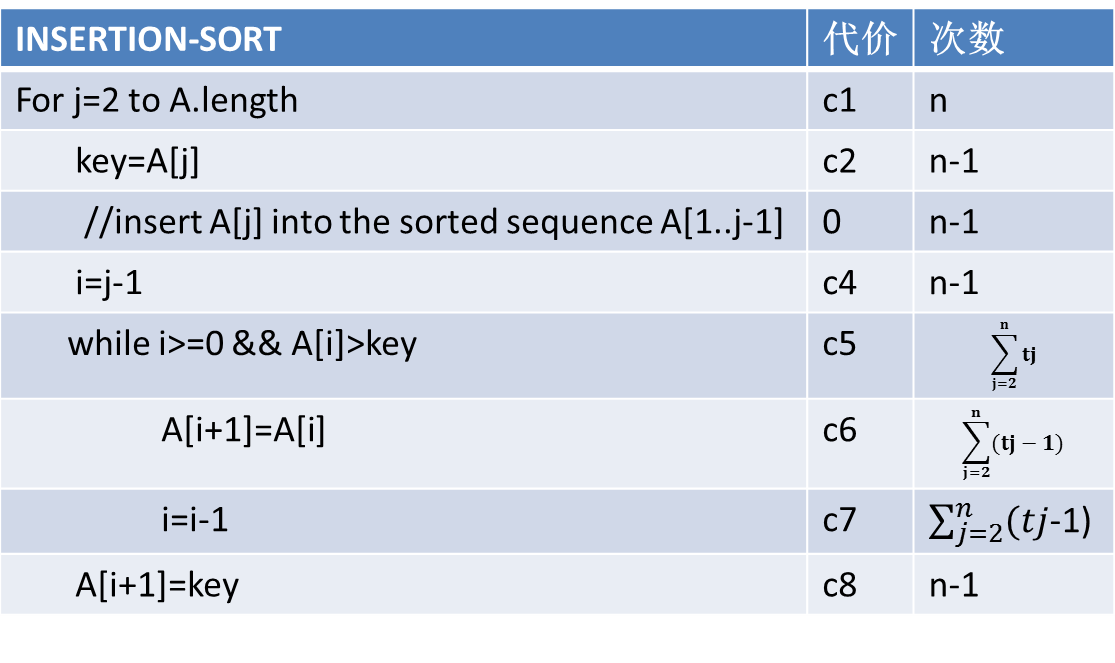
当一个算法中包含了对自身的递归调用时,我们往往是用递归式或递归方程来描述其运行时间。分治算法的运行时间来自基本模式的三个步骤:
(1):当规模足够小的时候,我们可以直接对其求解,需要的时间也为一个常量,我们记为O(1)。
(2):我们把原问题分为a个小问题,每个问题的规模是原问题的1/b,所以为了求解一个规模为n/b的小问题,需要的时间为T(n
/b),所以a个小问题需要的时间为:aT(n/b);
(3):除去了递归解决问题的时间,剩下的就是分解问题时间:D(n),以及合并解的时间:C(n)
因此递归式为:
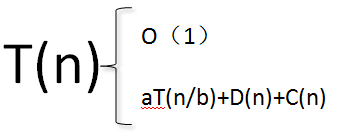
就按照上述的递归是分析归并算法:
首先我们是假设数组的大小为2的幂,来简化问题的分析,在这个假设下,每个步骤产生的规模刚好为n/2的两个子序列,即a=b=2;
(1)当n=1时,T(n)=O(1);
(2)当n>1时,
分解:分解只是计算数组的中间位置,故D(n)=O(1);
解决:递归求解两个规模均为n/2的子问题,贡献的时间为:2T(n/2)
合并:我们是要把两个n/2的规模的子数组合并为n大小的数组,故需要时间为O(n)。
当我们把合并和分解时间相加时,将得到的是一个一次函数,所以其运行时间为O(n);
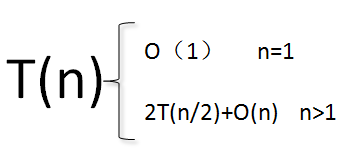
在第四章我们将通过“主定理”,可以证明T(n)=O(nlog(n)),其中log是以2为底的对数。其实我们可以通过另外一种方式得到这个结论,就是通过构建一个满二叉树的方式。

我们通过把每个分解步骤通过一个二叉树的形式展现,我们通过二叉树的性质可以知道这个二叉树的深度为:log(n)+1,其中log为以2为底对数,然后每层又贡献多了时间为:cn,所以总代价为cnlog(n)+cn,然后我们忽略低阶和常量c,就可以得到O(log(n)),其中log均为以2为底的对数。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









