






 本文探讨了一种针对1300万数据的题库分库分表架构方案,比较了两种切分方法的优缺点,重点介绍了Mycat作为数据库中间件在兼容旧功能、数据整合和性能优化中的作用。文章还讨论了适用场景和注意事项,如数据冗余、表分组和Join操作的最佳实践。
本文探讨了一种针对1300万数据的题库分库分表架构方案,比较了两种切分方法的优缺点,重点介绍了Mycat作为数据库中间件在兼容旧功能、数据整合和性能优化中的作用。文章还讨论了适用场景和注意事项,如数据冗余、表分组和Join操作的最佳实践。
题库分库分表架构方案
作者:大呜 原文网址:找不到了,尴尬的声明
方案项目背景
现在题库架构下,针对新购买的1300W多道数据进行整合,不影响现有功能。由于数据量偏多,需要进行数据的切分
目标场景
兼容旧的功能
对1300多W数据进行分库分表
需要对旧的数据进行整合
老师端选题组卷 可以根据 学段、学科、知识点、难度、题型 来筛选
学生端根据老师端所选题目获取对应的题目
对3年内以后扩展的增量数据预留数量空间
数据样例
| 学段 | 数据量 |
|---|---|
| 小学 | 1285336 |
| 初中 | 6655780 |
| 高中 | 6144072 |
| 学段学科 | 数据量 |
|---|---|
| 初中数学 | 1869524 |
| 初中化学 | 1356224 |
| 初中英语 | 288440 |
切分方案一
切分为3个库,分别是小学、初中、高中 数据占比如上
每个库切分10个表 根据 学科+首级知识点)%10
每个库一个总表
缺点:例:用到不同知识点时,需要多表获取数据
优点:数据分布较为平均
切分方案二 采用)
切分为3个库,分别是小学、初中、高中 数据占比如上
每个库切分10个表(全部10个学科)根据 学科区分,例:数学表、物理表
每个库一个总表
缺点:数据不大平均,数据量多的例数学有186W多、英语28W多
优点:当有用到组卷等需要筛选多知识点题目时,不必多表查询
数据id自增区间划分
小学 1-2亿
中学 2-3亿
高中 3亿起
关联关系图
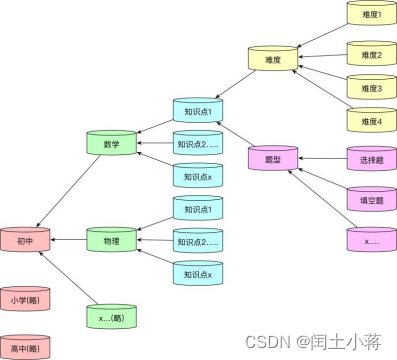
根据知识点获取题目流程

自增id
对原有的id区间段不做处理
对切分后的id自增段进行规划
兼容旧功能
解决的问题
新旧数据有重复的知识点、题目
新旧数据的结构不一样
对旧的题库功能代码的修改
两套题库合并主键冲突问题
兼容旧功能 方案一 个人推荐)
有操作的旧的数据洗入新的结构,旧的数据只为兼容原有的功能数据,不做显示。
优点:
不必变化数据结构,最新的购买的数据结构较为清晰。易维护扩展,因为目前旧的数据已经整合了两套数据
缺点:
需要修改全部旧有的功能代码(针对新的数据结构)
兼容旧功能 方案二
把新购买的数据整合进老的数据结构,同时保存三批数据,需要处置所有表的主键冲突、三批各表数据去重
优点:
旧有代码只修改数据结构切分的局部,不必全部修改功能代码
缺点:
数据较乱,三套不同的数据同时存在数据库
需要处置新的结构整合进旧的数据结构,同时需要处置主键冲突,
代码上需要处置对应的数据
问题点
测试环境和正式环境图片寄存在那里?100多G上传cdn需要几十天时间,有4000多W张,目前cdn不支持打包上传
解决方案:购买单独服务器,主备,寄存图片
测试db正式db1300多w目前占用100G左右,需要寄存空间
解决方案:测试环境新加硬盘,新加db实例端口3307正式环境db寄存在图片服务器
代码设计模式
采用适配器模式(原先的代码结构不变)
类图
调研内容中间件MYCA T未使用)
什么是MYCA T
一个彻底开源的面向企业应用开发的大数据库集群
支持事务、ACID可以替代MySQL加强版数据库
一个可以视为MySQL集群的企业级数据库,用来替代昂贵的Oracl集群
一个融合内存缓存技术、NoSQL技术、HDFS大数据的新型SQLServer
结合保守数据库和新型分布式数据仓库的新一代企业级数据库产品
一个新颖的数据库中间件产品
MYCA T特性
==支持库内分表(1.6==
==支持单库内部任意join支持跨库2表join甚至基于caltlet多表join==
支持全局序列号,解决分布式下的主键生成问题。
==分片规则丰富==插件化开发,易于扩展。
基于Nio实现,有效管理线程,解决高并发问题。
==支持通过全局表,ER关系的分片战略,实现了高效的多表join查询==
支持分布式事务(弱xa
支持SQL黑名单、sql注入攻击拦截
==支持MySQLOraclDB2SQLServerPostgreSQL等DB罕见SQL语法==
==遵守Mysql原生协议==跨语言,跨平台,跨数据库的通用中间件代理。
==基于心跳的自动故障切换,支持读写分离,支持MySQL主从,==以及galeracluster集群。
可以大幅降低开发难度,提升开发速度
具体看 mycat官网
Mycat注意事项
全局表一致性检测 1.6版本开始支持(一致性的定时检测)
分片 join尽量防止使用 Leftjoin或 Rightjoin,而用 Innerjoin
Mycat原理
应用要面对很多个数据库的时候,这个时候就需要对数据库层做一个抽象,来管理这些数据库,而最上面的应用只需要面对一个数据库层的笼统或者说数据库中间件就好了这就是Mycat核心作用。
分片分析、路由分析、读写分离分析、缓存分析等,然后将此SQL发往后端的真实数据库,并将返回的结果做适当的处置,最终再返回给用户。
Mycat应用场景
读写分离,配置简单
分表分库,对于超越1000万的表进行分片,最大支持1000亿的单表分片
报表系统,借助于Mycat分表能力,处置大规模报表的统计
文章整理
应用场景 那些适合,那些不适合 https://www.cnblogs.com/barry…
使用说明 https://juejin.im/post/59c325…
总表使用mysqlMERGE引擎(不考虑)
合并的表使用的必需是MyISA M引擎
表的结构必需一致,包括索引、字段类型、引擎和字符集
对于增删改查,直接操作总表即可。
数据切分原则
能不切分尽量不要切分。
如果要切分一定要选择合适的切分规则,提前规划好。
数据切分尽量通过数据冗余或表分组(TablGroup来降低跨库 Join可能。
由于数据库中间件对数据 Join实现的优劣难以掌握,而且实现高性能难度极大,业务读取尽量少使用多表 Join
尽可能的比拟均匀分布数据到各个节点上
该业务字段是最频繁的或者最重要的查询条件。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









