






 文章详细探讨了Clickhouse的MergeTree表引擎如何处理DataPart和Compaction,以及ReplacigMergeTree的数据一致性问题。介绍了OPTIMIZEStatement和SelectFinalStatement两种解决方案,并针对特定业务场景进行了性能优化分析。
文章详细探讨了Clickhouse的MergeTree表引擎如何处理DataPart和Compaction,以及ReplacigMergeTree的数据一致性问题。介绍了OPTIMIZEStatement和SelectFinalStatement两种解决方案,并针对特定业务场景进行了性能优化分析。
前言
Clickhouse优秀的性能背后MergeTree系列的表引擎是功不可没的。MergeTree存储结构的设计思想其实和LSM-TREE是类似的。都是优化随机写磁盘的性能。LSM-TREE数据结构对于数据是采用顺序写的模式。所以对于之前数据的删除或者更新, 也是采用追加新数据的模式来做的。那么如何保证数据的有效性,这里就需要引入一个Compaction的机制来处理(Merge on write)。让新的数据块和老的数据块进行合再提供给外部使用。 那么Clickhouse是如何做的呢。
MergeTree DataPart说明
ClickHouse 每次在写入数据的时候都会生成一个新的数据目录,并且一旦写入以后就不会修改变成(Immutable)的状态,类似于LSM-TREE的Immutable Memory Table。 我们把每一个数据目录称作为Data Part。 这时我们可以看到一个问题,如果当每次写入数据量很少的时候,底层会产生很多的Data Part目录。例如极端场景下,每次写入数据都只有一行。那Clickhouse也会为这一行数据创建出来一个Data Part目录。这样当查询的时候读放大的问题会更加严重。所以Clickhouse官方建议再每一次写入的时候尽量通过Batch的方式批量写入。
即使通过Batch的方式进行写入,底层也还会创建很多的Data Part目录,只是会相对好一些。但是读放大的问题还是没有解决。所以Clickhouse社区还引入后异步Compaction的机制,让这些Data Part目录进行Merge操作。逐渐的降低读放大的问题。
但是我们发现,让我们写入数据的时候,如果没有进行Compaction的时候,这时我们的数据一致性可能是有问题的。
MergeTree系列表引擎数据一致性问题
通过上面Data Part的Compaction机制可知,可能会存在数据不一致的问题。 这里我举个例子。
- 创建表语句
CREATE TABLE t_final
(
`x` Int32,
`y` Int32
)
ENGINE = ReplacingMergeTree
ORDER BY x;
-- 插入数据语句
insert into t_final values(1, 10);
insert into t_final values(1, 20);
-- 读取数据
select * from t_final;
Query id: 1046322e-8276-4aee-b421-1e07a046cbec
┌─x─┬──y─┐
│ 1 │ 20 │
└───┴────┘
┌─x─┬──y─┐
│ 1 │ 10 │
└───┴────┘
2 rows in set. Elapsed: 0.002 sec.这里我描述下ReplacingMergeTree表引擎的含义。这个表引擎的含义是如果排序键相同的情况下,并且不带version字段的情况下,使用最后插入的数据。所以这里应该显示的数据理论上应该是x=1, y=20。因为y=20是最后插入的。但是我们通过Clickhouse的执行结果可以看到,他把两行数据都输出出来了。这样就不符合预期结果了。
出现这种问题的原因是,我们在插入x=1, y=10的时候,底层产生了一个Data Part 1的数据目录。 我们再次插入的时候x=1, y=20的时候,底层产生了一个Data Part 2的数据目录。但是这时候Data Part 1和Data Part 2还没有进行Compaction。所以这两行数据在同一时刻都是起作用的。所以输出了两行数据。 这样就造成了数据一致性的问题。
那么对于这种数据一致性的问题,Clickhouse社区提供了两种解决方案。
- 使用OPTIMIZE Statement语法,强制让底层的Data Part进行Compaction操作,这是一个同步操作。当Compaction操作结束后,再进行查询操作来保证数据的一致性。
- 使用Select Final Statement语法,当我们再做Select查询的时候,添加Final关键字。让把所有的Data Part目录读取上来后,进行Compaction操作,计算完的数据再提供给上层计算。
OPTIMIZE Statement方案
- 优势在于,如果后续没有插入的操作了,可以一直保持数据的一致性。
- 劣势在于,如果后续有新的数据操作,还要重新执行OPTIMIZE Statement。OPTIMIZE Statement的执行性能通常比较慢,特别是对于大表。通常使用这种方案的都是定时在集群低峰值的时候执行。
Select Final Statement方案
- 优势在于,通过SQL的方式更加灵活。如果之前执行过Optimize操作。并且插入新数据也不频繁,就可以使用这种方案,从而不用Optimize这种非常重的操作。
- 劣势在于,如果底层的Compaction操作没有执行,每一次的查询都需要Compaction从而影响Select查询的性能。
Select Final实现方式
我们从社区关于Final的实现方式来看下,看看是如何保证数据一致性的。这里通过Clickhouse的执行效果来看下Final的实现,看下社区关于Final的解决方案。
Clickhouse 关于Final 提供了2个特性。
1.do_not_merge_across_partitions_select_final, Clickhouse 这个特性的含义是说,对于不同分区间的主键不会进行merge处理,并且不同分区并发读数据。
举个例子
CREATE TABLE t_final_not_merge_across_partitions
(
`p` Int32,
`x` Int32,
`v` Int32
)
ENGINE = ReplacingMergeTree(v)
PARTITION BY p
ORDER BY x;
INSERT INTO t_final_not_merge_across_partitions VALUES (1,1,1);
INSERT INTO t_final_not_merge_across_partitions VALUES (2,1,1);
INSERT INTO t_final_not_merge_across_partitions VALUES (3,1,1);
INSERT INTO t_final_not_merge_across_partitions VALUES (3,1,2);
SELECT *
FROM t_final_not_merge_across_partitions
FINAL
SETTINGS do_not_merge_across_partitions_select_final = 1;
Query id: d77c2a67-e852-44c0-a5d2-165fcfa9d849
┌─p─┬─x─┬─v─┐
│ 2 │ 1 │ 1 │
└───┴───┴───┘
┌─p─┬─x─┬─v─┐
│ 1 │ 1 │ 1 │
└───┴───┴───┘
┌─p─┬─x─┬─v─┐
│ 3 │ 1 │ 2 │
└───┴───┴───┘
3 rows in set. Elapsed: 0.002 sec.通过上面的执行结果,我们可以看到,即使排序键相同,但是如果处于不同分区的情况下,数据不会进行Merge处理。这个优化降低了分区和分区之间数据Merge的复杂性,从而提升性能。我们看下如果放开分区间Merge的情况是什么效果。
SELECT *
FROM t_final_not_merge_across_partitions
FINAL;
Query id: 89144d06-362e-407f-b984-ff4bcd94b47d
┌─p─┬─x─┬─v─┐
│ 3 │ 1 │ 2 │
└───┴───┴───┘
1 rows in set. Elapsed: 0.002 sec.通过结果可以看到分区键如果也进行Merge的情况和只Merge分区里的数据,执行结果是不一样的,所以要根据自己的业务进行选择。
2. max_final_threads,Clickhouse这个特性的含义是说,select final的时候使用多少个线程。如果并发读取线程(max_threads)比max_final_threads大的情况下,使用max_final_threads线程的个数。降低资源的使用。
我们可以看下Select Final大致的物理执行计划
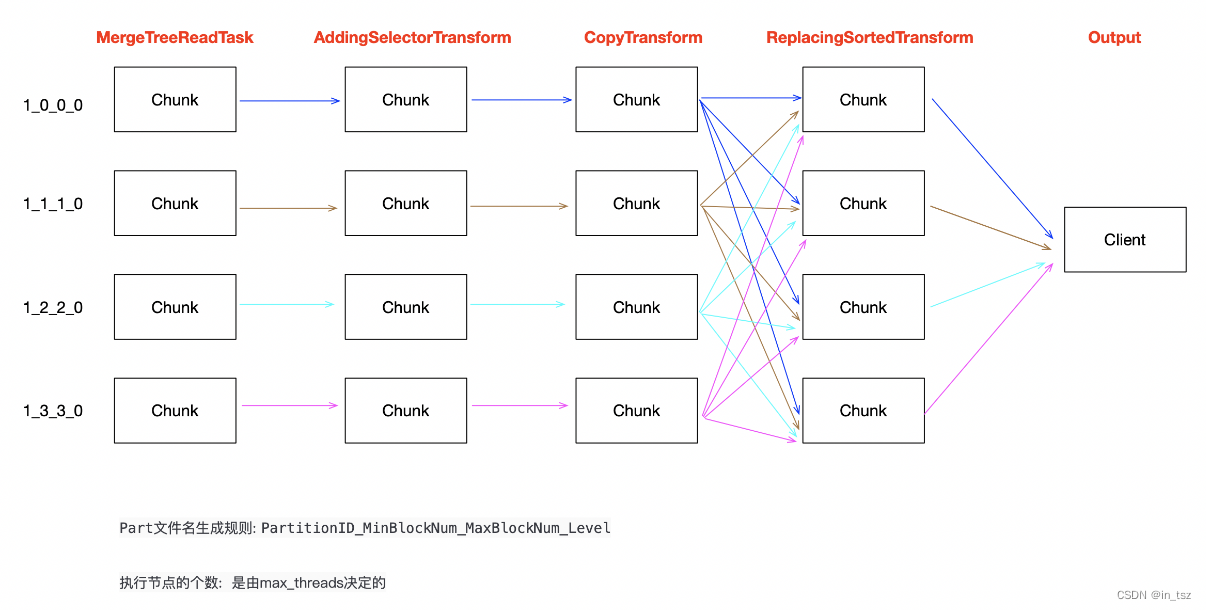
Select Final执行过程大致可以描述为:
- 如果使用do_not_merge_across_partitions_select_final特性,则根据max_threads和底层part的个数来划分每一个线程处理的数据量。如果part的个数没有max_threads大的情况下。降低线程的使用个数。
- 如果part比较多,并且part内部数据量比较少的情况下,并且不merge交叉分区的场景下,可以加大并发进行读取。
- 如果底层数据扫描是多线程的,那么我们如何保证相同的数据是落在一起的。所以官方采用的是,每一笔数据都进行一下hash计算然后对应到某一个chunk的槽位上面,然后把这个chunk发送给所有的ReplacingSortTransform工作线程。每一个工作线程读取对应chunk槽位上面的数据。这个所有的工作线程都可以并发读取数据,并进行Merge计算了。
- Merge还使用SortHeap算法进行处理。
- 最后数据Union起来,发送出去。
Select Final 性能优化
业务场景一、分区之间不包含相同的主键
可以根据自己业务的场景选择使用do_not_merge_across_partitions_select_final配置来提升性能。如果业务场景下各个分区中不包含相同的排序键则可以使用这个参数进行优化。并且排序键可以设计成(PARTITION Key, Order By key)下面举个例子看下性能能提升多少。
-- 创建表语句
CREATE TABLE t_final_pref
(
`p` int,
`key` int
)
ENGINE = ReplacingMergeTree
PARTITION BY p
ORDER BY (p, key)
-- 插入语句(表1千万的数据量,包含1000个分区, 分区内部不包含相同的排序键)
insert into t_final_pref select mod(number, 1000), number from numbers(10000000);
-- 使用标准的final执行
SELECT count(*) FROM t_final_pref FINAL
Query id: d155aa8d-87fa-4f0f-b0de-f94f69d0b13a
┌──count()─┐
│ 10000000 │
└──────────┘
1 rows in set. Elapsed: 5.826 sec. Processed 10.00 million rows, 80.00 MB (1.72 million rows/s., 13.73 MB/s.)
-- 使用不Merge不同的partition分区内的排序键配置
SELECT count(*) FROM t_final_pref FINAL
SETTINGS do_not_merge_across_partitions_select_final = 1
Query id: 6028d23e-8ac6-4e9b-810c-4c8c1e18bd06
┌──count()─┐
│ 10000000 │
└──────────┘
1 rows in set. Elapsed: 0.837 sec. Processed 10.00 million rows, 80.00 MB (11.95 million rows/s., 95.58 MB/s.)通过上面的测试可以看到,带do_not_merge_across_partitions_select_final配置参数比不带do_not_merge_across_partitions_select_final性能大约提升了6倍。效果还是非常明显的,所以如果业务能保证自己分区内是不包含相同主键的情况下,使用这种优化策略提升还是非常明显的。
业务场景二、分区之间包含相同的主键,通过version字段使用高版本的数据
这里我们可以通过Clickhouse的聚合函数来实现。举个例子
-- 创建表语句
CREATE TABLE t_final_version_pref
(
`p` int,
`key` int,
`version` int
)
ENGINE = ReplacingMergeTree(version)
PARTITION BY p
ORDER BY (p, key)
-- 插入语句,分2批插入,每一批插入500万数据,第一次插入版本为0,第二插入版本为1,最终使用版本为1的数据
insert into t_final_version_pref select mod(number, 1000), number, 0 from numbers(5000000);
insert into t_final_version_pref select mod(number, 1000), number, 1 from numbers(5000000);
-- 使用标准的final执行
SELECT count(*)
FROM t_final_version_pref
FINAL
Query id: fd17cd4c-7e68-472b-9091-1e3caa8462be
┌─count()─┐
│ 5000000 │
└─────────┘
1 rows in set. Elapsed: 2.832 sec. Processed 10.00 million rows, 120.00 MB (1.38 million rows/s., 16.59 MB/s.)
- 使用聚合参数进行优化
SELECT count(*)
FROM
(
SELECT argMax(key, version)
FROM t_final_version_pref
GROUP BY key
)
Query id: 8be3a137-823b-46cf-b8e2-6f57eb289601
┌─count()─┐
│ 5000000 │
└─────────┘
1 rows in set. Elapsed: 1.512 sec. Processed 10.00 million rows, 80.00 MB (6.61 million rows/s., 52.91 MB/s.)通过上面的例子可以看到使用聚合优化比不使用聚合优化性能大约提升了1倍。这里需要注意下Clickhouse里面聚合的处理是相对比较耗内存的,所以使用聚合优化会占用更多的内存。可能会报内存不足。所以需要根据自己的实际情况进行选择。
总结
本文通过SQL任务的执行计划和性能测试对比的方式分析Clickhouse对于select Final功能是如何保证数据一致性及如何针对性进行相关优化。工作中有被人问到什么加Final和不加Final性能差距会比较大。 希望本文能给大家解个惑。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









