







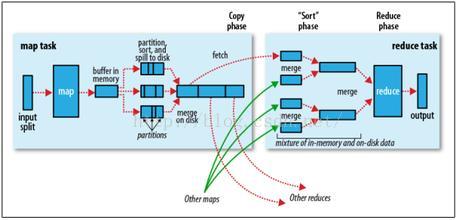
1、Map阶段。
split-----map----partition sort and spill to disk------combine。
1)split的目的是应一个原始文件分成多个文件,分别交由不同的map节点处理,文件块大小由block size、max size、min size,在hadoop1版本的计算方式是spiltSize = max(minsize,max(blockSize,goalSize));在hadoop2版本中的计算方式为spiltSize = max(minsize,max(blockSize,maxSize)),其中 maxSize = mapred.max.split.size 默认最大值整数值,minSize = mapred.min.split.size 默认0,goalSize是根据文件总大小totalSize和MapTask个数n计算得到,即goalSize=totalSize/n。
总结:新版本确定文件块大小时不再考虑maptask任务的个数,而有配置中的mapred.max.split.size代替。
2)map
3)partition sort and spill to disk
每个map任务计算的结果首先写到内存中,当超过阈值(默认100M)时将启动一个线程将数据内容溢写到磁盘上,在溢写的过程中需要指定每个map输出的键值对对应的reduce编号,即分区,默认的分区算法是使用map的key对象的hashcode模reduce个数,该方式不能保证负载均衡,重写Partition类的getPartition方法可自定义分区方式,除分区外,该过程还要经历排序过程,默认的排序是按ascii码排序,可实现WritableComparable接口的compare方法。
4)combine。
每个map任务执行过程中有可能会溢写生成多个文件,而map任务结束后需要交结果传到reduce任务节点,为提高效率需在网络传输文件前将多个小文件合并成大文件,combine是map节点本地reduce过程。
2、Reduce阶段
merge----sort----reduce-----output
在正式执行Reduce过程前,需要做一些预处理,首先将不同map节点传输过来的文件合并,然后排序,排序同map阶段。















 1693
1693

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









