







 本文详细介绍了如何使用Python的Scrapy框架爬取豆瓣Top250电影列表的详细信息,并将数据导出为xlsx和json文件。内容包括创建Scrapy项目、设置爬虫参数、定义爬取函数以及数据存储的管道处理。爬取的字段包括电影链接、名称、原名、导演、主演等17项信息。同时,代码中加入了防止IP被封的延时策略,并提供了测试环境和效果。请注意,爬虫使用前需遵守相关法律法规和网站规则。
本文详细介绍了如何使用Python的Scrapy框架爬取豆瓣Top250电影列表的详细信息,并将数据导出为xlsx和json文件。内容包括创建Scrapy项目、设置爬虫参数、定义爬取函数以及数据存储的管道处理。爬取的字段包括电影链接、名称、原名、导演、主演等17项信息。同时,代码中加入了防止IP被封的延时策略,并提供了测试环境和效果。请注意,爬虫使用前需遵守相关法律法规和网站规则。
Python使用scrapy爬取豆瓣TOP250详情页并导出xlsx和json文件
一、使用说明
- 在按照指定路径完成文件内容替换后,运行main.py文件即可,自动导出xlsx和json文件。
- 用于获取电影详情页链接的目标URL:https://movie.douban.com/top250;若URL被修改,需要人工替换。
- 爬取的数据共250条,各影片包含以下17个项目:详情链接、中文名称、原名、别名列表、播放状态、导演列表、编剧列表、主演列表、官方网站、上映时间、制片国、语言、片长、类型、评论人数、评分、中心主题。官方网站项可能有误。
- 本代码仅用于开源学习,若使用于商业或非法用途,所引发的一切责任均与本人无关。(爬取任何目标前请熟读爬虫守则)
- 由于访问次数过多,加入了time.sleep(self.step_time)语句,如果只需爬取一遍,可注释该语句,也可自行写入代理IP。默认请求等待时间为5s,需要至少22分钟完成爬取,频率太高会被封IP。
二、创建scrapy项目
1.创建空项目
使用pycharm进入命令行窗口,进入工作区,在工作区要创建项目的位置输入以下命令,针对本项目代码,命令不可更改。
#创建项目目录
scrapy startproject douban_details
#进入项目主文件夹
cd douban_details
cd douban_details
cd spiders
#创建爬虫主文件
scrapy genspider douban_details_spider movie.douban.com

项目结构
其中,main.py需要手动创建,导出的文件在运行后会自动生成,无需手动。
2.替换代码
douban_details_spider.py
参数说明
- name:爬虫名称,自动生成;
- allowed_domains:目标网站,自动生成;
- start_urls:目标URL,自动生成;
- step_time:请求步长,限制请求频率,防止IP被封;
- page_number:当前所在页面位置,1-10;
函数说明
- parse(self, response):目录页面爬取;
- get_details(self,response):详情页爬取;
完整代码
import scrapy
from ..items import DoubanDetailsItem
from scrapy import Request
import time
class DoubanDetailsSpiderSpider(scrapy.Spider):
name = 'douban_details_spider'
allowed_domains = ['movie.douban.com']
start_urls = ["https://movie.douban.com/top250"]
step_time=5
page_number=0
def parse(self, response):
node_list = response.xpath('//div[@class="info"]')
for msg in node_list:
# 详情链接
details_url = msg.xpath('./div[@class="hd"]/a/@href').extract()
# 中文名称
name_chinese = msg.xpath('./div[@class="hd"]/a/span[1]/text()').extract()
# 原名
name = msg.xpath('./div[@class="hd"]/a/span[2]/text()').extract()
name=str(name).replace("\\xa0","").replace("/","")
# 别名列表
name_other_list = msg.xpath('./div[@class="hd"]/a/span[3]/text()').extract()
name_other_list=str(name_other_list).replace("\\xa0","").replace("/","")
# 播放状态
player_type = msg.xpath('./div[@class="hd"]/span[@class="playable"]/text()').extract()
player_type=str(player_type)[3:-3]
# 评论人数
number_evaluate = msg.xpath('./div[@class="bd"]/div[@class="star"]/span[4]/text()').extract()
number_evaluate=str(number_evaluate)[2:-5]
# 评分
score = msg.xpath('./div[@class="bd"]/div[@class="star"]/span[@property="v:average"]/text()').extract()
# 中心主题
purpose = msg.xpath('./div[@class="bd"]/p[@class="quote"]/span[@class="inq"]/text()').extract()
# 使用管道保存
# 管道可以对键值自动去重
item_pipe = DoubanDetailsItem()
item_pipe["details_url"] = details_url
item_pipe["name_chinese"] = name_chinese
item_pipe["name"] = name
item_pipe["name_other_list"] = name_other_list
item_pipe["player_type"] = player_type
item_pipe["number_evaluate"] = number_evaluate
item_pipe["score"] = score
item_pipe["purpose"] = purpose
time.sleep(self.step_time)
yield Request(details_url[0],callback=self.get_details,meta={"info":item_pipe})
# 有序内容获取方法
self.page_number += 1
print(self.page_number)
# 爬取其他页面
if (self.page_number < 10):
time.sleep(3)
page_url = 'https://movie.douban.com/top250?start={}&filter='.format(self.page_number * 25)
yield scrapy.Request(page_url, callback=self.parse)
# 获取详情页数据
def get_details(self,response):
item_pipe=DoubanDetailsItem()
info=response.meta["info"]
item_pipe.update(info)
response=response.xpath('//div[@id="info"]')
# 编剧列表
writer_list=response.xpath('./span[2]/span[@class="attrs"]/a/text()').extract()
# 导演列表
director_list=response.xpath('./span[1]/span[@class="attrs"]/a/text()').extract()
# 主演列表
star_list=response.xpath('string(./span[@class="actor"]/span[@class="attrs"])').extract()
# 官方网站
official_url=response.xpath('./a[@rel="nofollow" and @target="_blank"]/@href').extract()
# 上映时间
release_data=response.xpath('./span[@property="v:initialReleaseDate"]/text()').extract()
# 制片国
area=str(response.extract())
area=area[area.index("制片国"):area.index("语言")].strip()
area=area[area.index("</span>")+7:area.index("<br>")].strip()
# 语言
languages=str(response.extract())
languages=languages[languages.index("语言"):languages.index("上映")].strip()
languages=languages[languages.index("</span>")+7:languages.index("<br>")].strip()
# 片长
times=response.xpath('./span[@property="v:runtime"]/text()').extract()
# 类型
film_type=response.xpath('./span[@property="v:genre"]/text()').extract()
item_pipe["writer_list"]=writer_list
item_pipe["director_list"]=director_list
item_pipe["star_list"]=star_list
item_pipe["official_url"]=official_url
item_pipe["release_data"]=release_data
item_pipe["area"]=area
item_pipe["languages"]=languages
item_pipe["times"]=times
item_pipe["film_type"]=film_type
yield item_pipe
items.py
完整代码
import scrapy
class DoubanDetailsItem(scrapy.Item):
details_url = scrapy.Field()
name_chinese = scrapy.Field()
name = scrapy.Field()
name_other_list = scrapy.Field()
player_type = scrapy.Field()
director_list = scrapy.Field()
writer_list = scrapy.Field()
star_list = scrapy.Field()
official_url = scrapy.Field()
release_data = scrapy.Field()
area = scrapy.Field()
languages = scrapy.Field()
times = scrapy.Field()
film_type = scrapy.Field()
number_evaluate = scrapy.Field()
score = scrapy.Field()
purpose = scrapy.Field()
main.py
完整代码
from scrapy.cmdline import execute
import sys
import os
sys.path.append(os.path.dirname(os.path.abspath(__file__)))#到服务器保证路径一致
execute(["scrapy","crawl","douban_details_spider"])#填写项目名称
pipelines.py
参数说明
- self.item_list:项目列表;
- self.data_excel:excel临时数据列表;
函数声明
- open_spider(self,spider):启动预处理;
- process_item(self, item, spider):中间数据写入;
- close_spider(self,spider):文件关闭;
完整代码
from itemadapter import ItemAdapter
import json
import pandas as pd
import numpy as np
class DoubanDetailsPipeline(object):
def open_spider(self,spider):
self.item_list = ["详情链接","中文名称","原名","别名列表","播放状态",
"评论人数","评分","中心主题","编剧列表","导演列表","主演列表",
"官方网站","上映时间","制片国","语言","片长","类型"]
# 导出txt
self.f_txt=open('douban_details.txt','w+',encoding='utf-8')
# 导出excel
self.f_excel = pd.ExcelWriter("douban_details.xlsx")
self.data_excel=[]
# 导出json
self.f_json=open('douban_details.json','w+',encoding='utf-8')
self.f_json.write("[")
def process_item(self, item, spider):
# 导出txt
json_data=json.dumps(dict(item),ensure_ascii=False)+"\n"
self.f_txt.write(json_data)
# 导出excel
li_temp = np.array(list(dict(item).values()))
li_data = []
for i in range(len(li_temp)):
li_data.append(str(li_temp[i]).replace("[","").replace("]","").strip('"').strip("'").replace("', '",","))
self.data_excel.append(li_data)
# 导出json
self.f_json.write(json_data+",")
return item
def close_spider(self,spider):
# 导出txt
self.f_txt.close()
# 导出excel
self.data_df = pd.DataFrame(self.data_excel)
self.data_df.columns = self.item_list
self.data_df.index = np.arange(1, len(self.data_df) + 1)
self.data_df.to_excel(self.f_excel, float_format='%.5f')
self.f_excel.save()
# 导出json
self.f_json.seek(self.f_json.tell()-1,0)# 解决退格问题
self.f_json.write("]")
self.f_json.close()
settings.py
完整代码
from fake_useragent import UserAgent
BOT_NAME = 'douban_details'
SPIDER_MODULES = ['douban_details.spiders']
NEWSPIDER_MODULE = 'douban_details.spiders'
USER_AGENT = UserAgent().random
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'douban_details.pipelines.DoubanDetailsPipeline': 300,
}
三、测试
1.测试环境
- Windows10 pycharm2017.3
- Anaconda3
2.测试效果

json
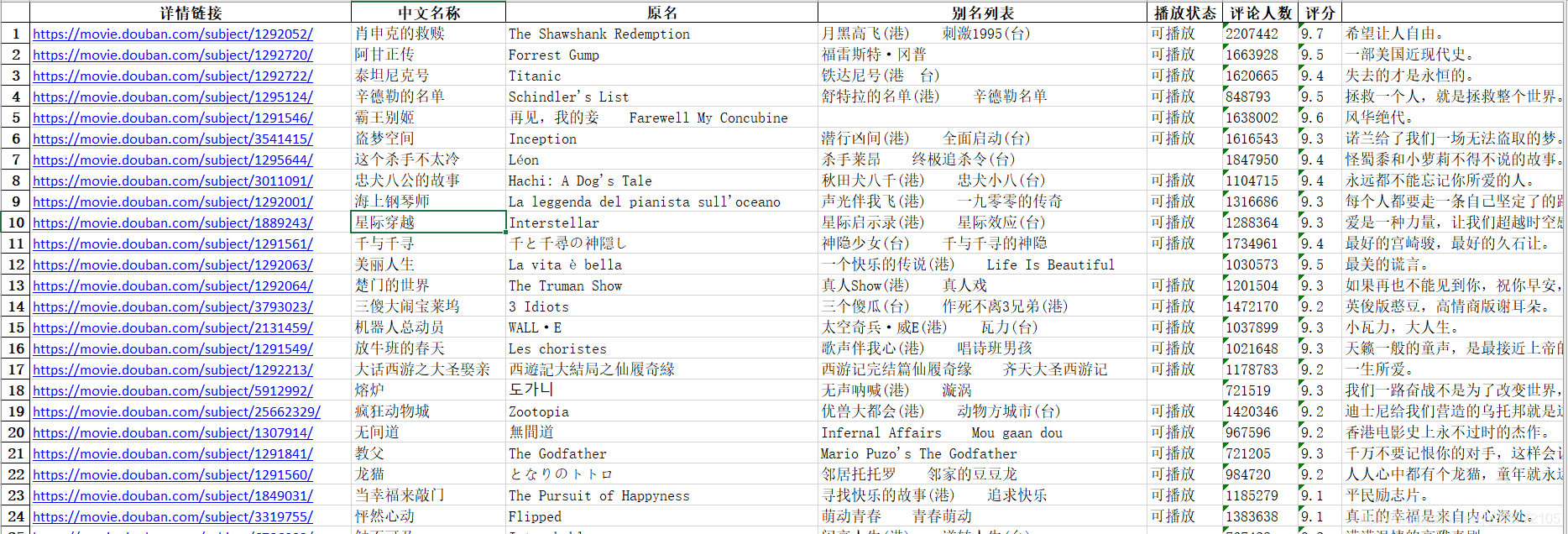
excel
四、转载说明
- 本文内容完全原创,代码完成时间2020.12.8。
- 若要转载本文,请在转载文章末尾附上本文链接:https://blog.csdn.net/qq_35772105/article/details/110766530
- 本文douban_details_spider.py文件唯一MD5:1D1621989CDBD8E94D0EF7086B747A87。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











