






今天介绍另外一个很容易踩坑的 SQL 例子,那就是隐式转换,隐式转换分为两种:隐式类型转换和隐式字符编码转换,下面将分别介绍这两种隐式转换对 SQL 执行效率的影响
隐式类型转换
假设有这样一张订单表
CREATE TABLE `t_order` (
`order_id` bigint(20) NOT NULL AUTO_INCREMENT,
`order_no` varchar(45) NOT NULL,
`amount` decimal(9,2) DEFAULT NULL,
`create_time` datetime DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`order_id`),
KEY `idx_order_no` (`order_no`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
现在需要根据订单号查询订单信息,如果你的 SQL 语句这样写
select * from t_order where order_no = 64267814;
从表结构来看,order_no 字段是有加索引的,但是 explain 的结果显示,这条 SQL 走的是全表扫描,并没有用到索引

这是因为,order_no 是 varchar 类型,而我们查询语句中的 where 条件,却是将 order_no 与整型进行对比,这里就涉及到一个问题,字符类型不能直接与整型进行对比,就需要做类型转换,需要将字符串转成整型,然后再进行对比,所以对于优化器来说,原本的 SQL 相当于
select * from t_order where cast(order_no as signed int) = 64267814;
可以看到,这条 SQL 实际上对索引字段做了函数操作,上一条推文有讲到,如果对索引字段做了函数操作,那么 MySQL 优化器会放弃走索引
函数操作对索引的影响,可以看我上一篇推文《SQL 优化(一):慎用 SQL 函数》
到这里你可能会有个疑问,为什么是字符串转整型,而不是整型转字符串呢?如果是整型转字符串,那 SQL 会变成下面这样,这不就会走索引了吗
select * from t_order where order_no = '64267814';
对于这个问题,我们有个简单的方法可以验证,执行select '10' > 9,看看 SQL 的执行结果
- 如果执行结果是 1,那么就是将字符串转为数字,做的是数字比较
- 如果执行结果是 0,那么就是将数字转为字符串,做的事字符串比较
在 MySQL 验证的结果如下:
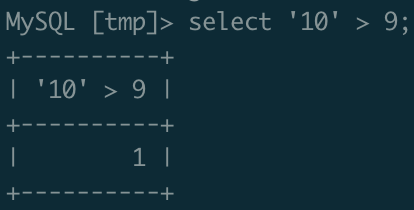
证明在 MySQL 中,如果将字符串跟数字做比较的话,是会将字符串转换成数字
隐式字符编码转换
相对于隐式类型转换,隐式字符编码转换则更隐蔽一点。假如有另外一张订单详情表,用于记录订单详情,表结构如下
CREATE TABLE `t_order_detail` (
`order_detail_id` bigint(20) NOT NULL AUTO_INCREMENT,
`order_no` varchar(45) NOT NULL,
`product_name` varchar(100) DEFAULT NULL,
`product_amount` decimal(9,2) DEFAULT NULL,
`create_time` datetime DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`order_detail_id`),
KEY `idx_order_no` (`order_no`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8
当我们想要查询某个订单的详情的时候,SQL 可能这样写
select od.*
from t_order o
inner join t_order_detail od on od.order_no = o.order_no
where o.order_no = '64267814';
执行计划如下

从执行计划可以看出,t_order 表用了 idx_order_no 索引,根据 where 条件中的 order_no 找到具体的记录,但是 t_order_detail 表并没有走索引,对 t_order_detail 表进行了全表扫描
这是因为,t_order 表跟 t_order_detail 表的字符编码不一样,t_order 表是 utf8mb4 编码,t_order_detail 表是 utf8 编码,两张表通过 order_no 关联的时候,要做字符编码转换,因为 utf8 不能直接与 utf8mb4 进行比较
因为 utf8mb4 是 utf8 的超集,所以 MySQL 内部在做类型转换的时候,会将 utf8 转换成 utf8mb4 再进行比较,这个很好理解,在做类型转换的时候,都是“按数据长度增长”的方向进行转换的,这样才能避免因为大数据集转换成小数据集导致数值失真。所以原本的 SQL 等同于
select od.*
from t_order o
inner join t_order_detail od on convert(od.order_no using utf8) = o.order_no
where o.order_no = '64267814';
知道了不走索引的原因后,我们对上面的 SQL 进行优化也很好优化,有下面两种优化方案
- 比较简单的方法是将 t_order_detail 表也改成 utf8mb4 编码
- 如果数据量比较大,或者暂时不能做 DDL 的话,可以将 SQL 修改成下面这种写法
select od.*
from t_order o
inner join t_order_detail od on od.order_no = convert(o.order_no using utf8)
where o.order_no = '64267814';
手动将 utf8mb4 的 t_order 表的 order_no 字段转换成 utf8 字符集,就避免了被驱动表 t_order_detail 上的字符编码转换,通过 explain 结果可以看到,这次两张表都走索引了

关注公众号:huangxy,一起学习,一起进步















 1911
1911











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









