







kafka的产生
Kafka是一个消息系统,原本开发自LinkedIn,用作LinkedIn的活动流(activity stream)和运营数据处理管道(pipeline)的基础。现在它已为多家不同类型的公司 作为多种类型的数据管道(data pipeline)和消息系统使用。
Kafka是一种分布式的,基于发布/订阅模式的消息系统。主要设计目标如下:
(1)以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间复杂度的访问性能
(2)高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条以上消息的传输
(3)支持Kafka Server间的消息分区,及分布式消费,同时保证每个Partition内的消息顺序传输
(4)同时支持离线数据处理和实时数据处理
(5)Scale out:支持在线水平扩展
架构设计
kafka拓扑结构
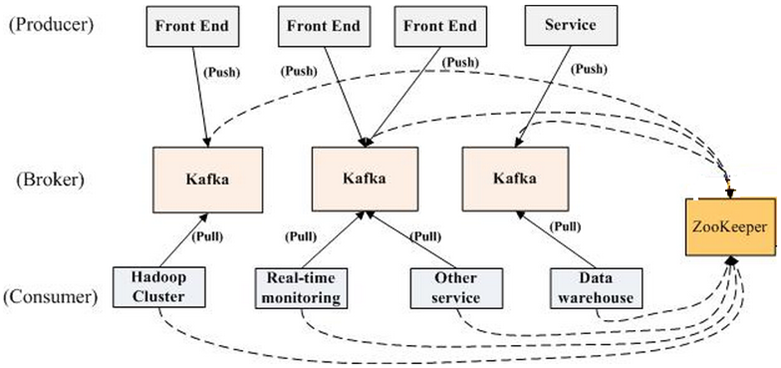
一个典型的Kafka集群中包含若干Producer(可以是web前端产生的Page View,或者是服务器日志,系统CPU、Memory等),若干broker(Kafka支持水平扩展,一般broker数量越多,集群吞吐率越高),若干Consumer Group,以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行rebalance。Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息。
分区Partition
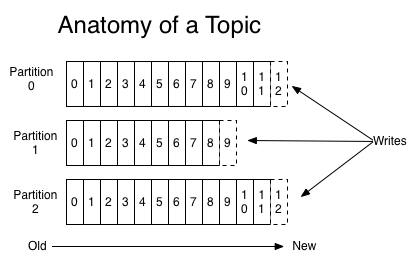
对于Consumer而言,它需要保存消费消息的offset,对于offset的保存和使用,由Consumer来控制;当Consumer正常消费消息时,offset将会线性的向前驱动,即消息将依次顺序被消费.事实上Consumer可以使用任意顺序消费消息,它只需要将offset重置为任意值。
Kafka集群几乎不需要维护任何Consumer和Producer状态信息,这些信息有Zookeeper保存,因此Producer和Consumer的客户端实现非常轻量级,它们可以随意离开,而不会对集群造成额外的影响。
将消息队列分区可以达到以下目的:首先这使得每个消息队列的数量不会太大,可以在单个服务上保存。另外每个分区可以单独发布和消费,为并发操作Topic提供了一种可能。
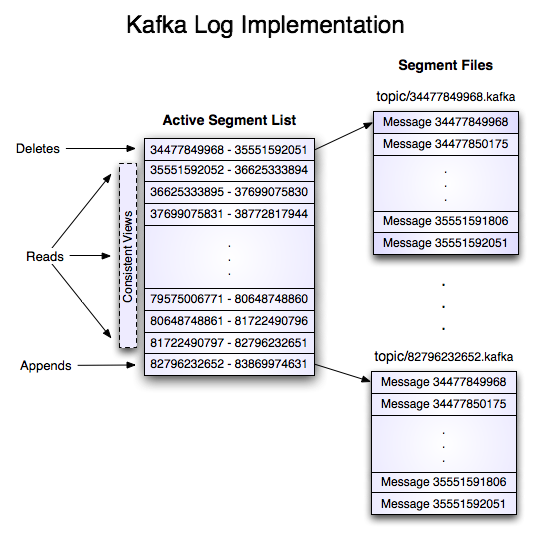
消息持久化
在对消息进行存储和缓存时,Kafka严重地依赖于文件系统。 大家普遍认为“磁盘很慢”,因而人们都对持久化结(persistent structure)构能够提供说得过去的性能抱有怀疑态度。实际上,同人们的期望值相比,磁盘可以说是既很慢又很快,这取决于磁盘的使用方式。设计的很好的磁盘结构往往可以和网络一样快。
消息由一个固定大小的消息头和一个变长不透明字节数字的有效载荷构成(opaque byte array payload)。消息头包含格式的版本信息和一个用于探测出坏数据和不完整数据的CRC32校验。让有效载荷保持不透明是个非常正确的决策:在用于序列化的代码库方面现在正在取得非常大的进展,任何特定的选择都不可能适用于所有的使用情况。
消息格式
具有两个分区的、名称为”my_topic”的话题的日志由两个目录组成(即:my_topic_0和my_topic_1),目录中存储的是内容为该话题的消息的数据文件。日志的文件格式是一系列的“日志项”;每条日志项包含一个表示消息长度的4字节整数N,其后接着保存的是N字节的消息。每条消息用一个64位的整数偏移量进行唯一性标示,该偏移量表示了该消息在那个分区中的那个话题下发送的所有消息组成的消息流中所处的字节位置。每条消息在磁盘上的格式如下文所示。
On-disk format of a message
| 字段 | 说明 |
|---|---|
| message length | 4 bytes (value: 1+4+n) |
| “magic” value | 1 byte |
| crc | 4 bytes |
| payload | n bytes |
生产者
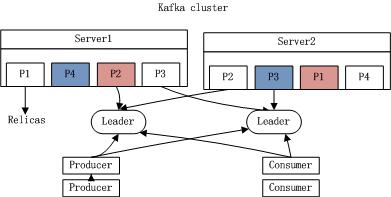
每个分区在Kafka集群的若干服务中都有副本,这样这些持有副本的服务可以共同处理数据和请求,副本数量是可以配置的。副本使Kafka具备了容错能力。
每个分区都会选择一个服务器作为leader,零或若干服务器作为followers,leader负责处理消息的读和写,followers则去复制leader。如果leader down了,follower中的一台则会自动成为leader。集群中的每个服务都会同时扮演两个角色:作为它所持有的一部分分区的leader,同时作为其他分区的follower,这样集群就会具有较好的负载均衡。
消费者
使用Consumer high level API时,同一Topic的一条消息只能被同一个Consumer Group内的一个Consumer消费,但多个Consumer Group可同时消费这一消息。
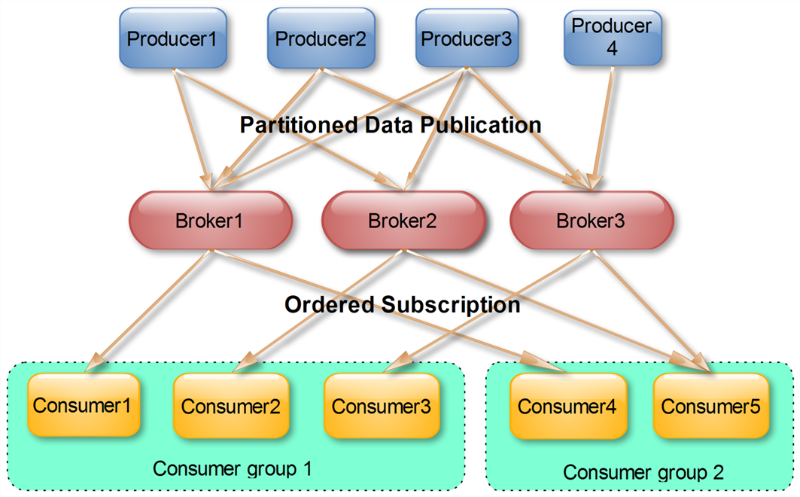
这是Kafka用来实现一个Topic消息的广播(发给所有的Consumer)和单播(发给某一个Consumer)的手段。一个Topic可以对应多个Consumer Group。如果需要实现广播,只要每个Consumer有一个独立的Group就可以了。要实现单播只要所有的Consumer在同一个Group里。
实际上,Kafka的设计理念之一就是同时提供离线处理和实时处理。根据这一特性,可以使用Storm或SparkStreaming这种实时流处理系统对消息进行实时在线处理,同时使用Hadoop这种批处理系统进行离线处理,还可以同时将数据实时备份到另一个数据中心,只需要保证这三个操作所使用的Consumer属于不同的Consumer Group即可。
Push模式 vs Pull模式
作为一个消息系统,Kafka遵循了传统的方式,选择由Producer向broker push消息并由Consumer从broker pull消息。一些logging-centric system,比如Facebook的Scribe和Cloudera的Flume,采用push模式。事实上,push模式和pull模式各有优劣。
push模式很难适应消费速率不同的消费者,因为消息发送速率是由broker决定的。push模式的目标是尽可能以最快速度传递消息,但是这样很容易造成Consumer来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而pull模式则可以根据Consumer的消费能力以适当的速率消费消息。
对于Kafka而言,pull模式更合适。pull模式可简化broker的设计,Consumer可自主控制消费消息的速率,同时Consumer可以自己控制消费方式——即可批量消费也可逐条消费,同时还能选择不同的提交方式从而实现不同的传输语义。
更多可参考:
1. http://www.oschina.net/translate/kafka-design?cmp&p=1#
2. http://www.infoq.com/cn/articles/apache-kafka/
3.http://www.infoq.com/cn/articles/kafka-analysis-part-1?utm_campaign=infoq_content&utm_source=infoq&utm_medium=feed&utm_term=global















 734
734

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









