







不好意思,由于种种原因让各位爷久等了。

在第一节,(第一节很快就会审核通过)我们使⽤urllib来抓取⻚⾯源代码,urllib是python内置的⼀个模块,但是使用起来并不方便。因此也就不是我们常⽤的爬⾍⼯具。这里就引出了我们今天的主角——⼀个第三⽅模块requests。这个模块⽐urllib简单, 并且处理各种请求都⽐较⽅便。
话不多说,第一步,安装第三方模块。
1.安装requests
pip是python安装第三方模块最简单有效的方法,但是它并不能在脚本文件中运行,而是在终端中运行。在所有程序中搜索命令提示符(windows)或打开终端(linux),以管理员身份运行。
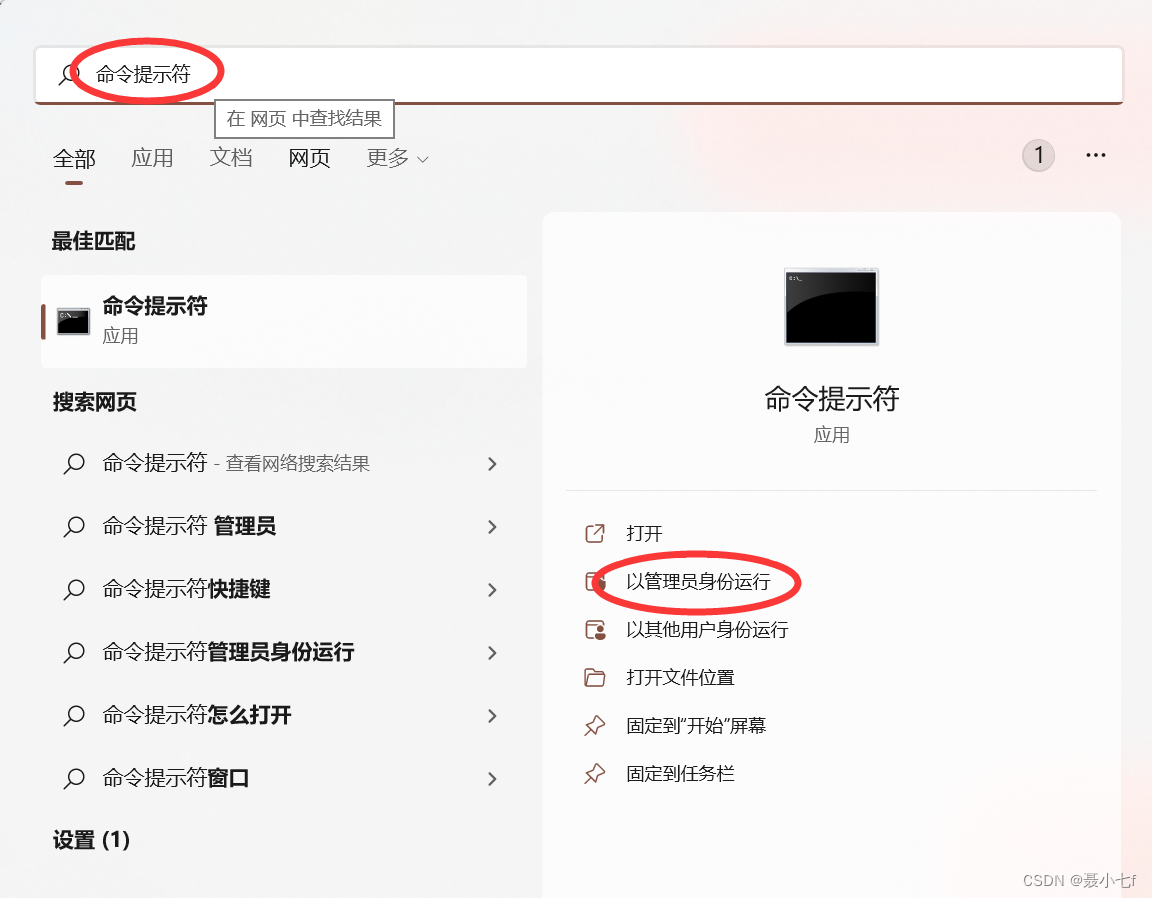
在里面输入
pip install requests如果安装速度慢的话可以改⽤国内的源进⾏下载安装。推荐使用清华源,国内其他源我也给大家安排好了,喜欢哪个用哪个。
#临时改成国内源
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple requests
#如果不想每次用 pip 都加上 -i https://.....,可以把国内源设为默认
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
# 阿里源
https://mirrors.aliyun.com/pypi/simple/
# 腾讯源
http://mirrors.cloud.tencent.com/pypi/simple
# 豆瓣源
http://pypi.douban.com/simple/2.小试牛刀
import requests
star = input("输入一个你喜欢的明星:")
url = f'https://cn.bing.com/search?q={star}'
dic = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36"
} # 处理一个小小的反爬
resp = requests.get(url, headers=dic)
# print(resp)
# print(resp.text)
with open("bing.html", mode="w", encoding="utf-8") as f:
f.write(resp.text)结果如下:

有的爷说不爽,咱们再来点硬菜
3.杀鸡用牛刀
import requests
url = "https://fanyi.baidu.com/sug"
s = input("请输入你要翻译的英文单词:")
dat = {
"kw": s
}
# 发送post请求, 发送的数据必须放在字典中, 通过data参数进行传递
resp = requests.post(url, data=dat)
# 将服务器返回的内容直接处理成json()
print(resp.json()) 4.总结
requests模块包括get, post两种⽅式的请求,分别对应咱们在第二节提到的两种渲染方式,在post请求时,最重要的是找到url,其次是加密方式。下节课我们来学bs4。















 814
814











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









