






MATLAB基础
一、基本数据类型
1.1 数组
-
数组创建
-
创建空数组
>> A=[] A = [] -
创建一维行向量
>> B=[1 2 3 4 5] B = 1 2 3 4 5 -
创建一维列向量
>> C=[1;2;3;4;5] C = 1 2 3 4 5 -
创建全1数组
>> D=ones(1,5) %1行5列 D = 1 1 1 1 1 -
创建全0数组
>> E=zeros(1,5) %1行5列 E = 0 0 0 0 0 -
创建平均数组(
linspace函数)>> x=linspace(0,2*pi,6) x = 0 1.2566 2.5133 3.7699 5.0265 6.2832 %linspace(a,b,n)其中,a表示第一个元素,b表示最后一个元素,n表示元素总数(若省略则默认为100) -
创建递增数组
>> a=1:12 a = 1 2 3 4 5 6 7 8 9 10 11 12
-
-
数组访问
对于数组
A=[1 2 3 4 5]:-
访问数组第1个元素
>> a1=A(1) a1 = 1 -
访问数组第1、2、3个元素
>> a2=A(1:3) a2 = 1 2 3 -
访问数组第3个到最后一个元素
>> a3=A(3:end) a3 = 3 4 5 -
访问数组第1个及第5个元素
>> a5=A([1 5]) a5 = 1 5 -
数组反向输出
>> a4=A(end:-1:1) a4 = 5 4 3 2 1
-
-
数组修改
对于数组
A=[1 2 3 4 5]-
修改单个值
>> A(3)=5 1 2 5 4 5 -
修改多个值
>> A([1 4])=[1 1] 1 2 5 1 5
-
1.2 矩阵
-
矩阵创建
-
创建已知矩阵
>> A=[1 2 3;4 5 6;7 8 9] %3行3列 A = 1 2 3 4 5 6 7 8 9 -
创建全0矩阵
>> B=zeros(3:3) B = 0 0 0 0 0 0 0 0 0 -
创建全1矩阵
>> C=ones(2:2) C = 1 1 1 1 -
创建单位矩阵(只有对角线为1的矩阵)
>> D=eye(4) D = 1 0 0 0 0 1 0 0 0 0 1 0 0 0 0 1 -
创建随机矩阵
>> E=rand(3:3) E = 0.8147 0.9134 0.2785 0.9058 0.6324 0.5469 0.1270 0.0975 0.9575
-
-
矩阵访问
对于矩阵
H=eye(5)1 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 1-
获取矩阵尺寸
>> size(H) ans = 5 5 -
访问单个元素
>> H(2,5) ans = 0 -
访问第2行所有元素
>> H(2,:) ans = 0 1 0 0 0 -
访问第5列所有元素
>> H(:,5) ans = 0 0 0 0 1 -
查找符合条件的元素
>> a=find(H>0) %查找矩阵H中大于0的元素,返回他们的角标,以列向量的形式 H(a) %访问上述角标 a = 1 7 13 19 25 ans = 1 1 1 1 1 -
矩阵变换维度(用
reshape函数实现)>> a=1:12 b=reshape(a,3,4) a = 1 2 3 4 5 6 7 8 9 10 11 12 b = 1 4 7 10 2 5 8 11 3 6 9 12 %reshape(matrix,a,b)将matrix矩阵调整为a行b列矩阵,从上到下,先读左边第一列,也先排左边第一列
-
-
矩阵运算
-
矩阵乘积(用
*表示),即行乘列再累加>> a*b a = 1 2 3 4 b = 4 3 2 1 a*b = 8 5 20 13 -
矩阵中的元素相乘(用
.*表示),即对应位置元素相乘>> a.*b a = 1 2 3 4 b = 4 3 2 1 a.*b = 4 6 6 4
-
二、MATLAB绘图
2.1 基础功能
-
横坐标生成
一般使用数组中提到的
linspace函数生成连续的等间隔的数组作为标准的横坐标linspace(a,b,n) %其中,a表示第一个元素,b表示最后一个元素,n表示元素总数(若省略则默认为100) -
纵坐标生成
一般使用现成的表达式,或实时捕获到的电信号,是一个数组,数组大小与横坐标相同
-
新建画布(
figure语句)使用
figure语句新建画布窗口-
直接使用,将会新建一个空画布
figure -
输入数字参数,将会指定这个画布的序号
figure(5) %指定该画布为第5块画布,其余直接使用figure新建的画布按照1,2,3,4,6,7...的顺序分配 -
输入其他属性名,则会通过关键词对画布属性进行设置
figure('Name', 'MyFigure', 'Color', 'white', 'Position', [100, 100, 800, 600])上述代码将创建一个名为
MyFigure的新图形窗口,背景色为白色,位置为[100, 100],宽度为800,高度为600
-
-
绘制图像
-
单个图像
plot(t,f) %以t为横坐标,f为纵坐标,绘制二维折线图 -
多个图像
涉及到在一个
figure窗口内的多个图像,则需要通过subplot()函数进行图像位置的划分subplot(m, n, p)m和n是子图网格的行数和列数,表示将图形窗口分割成 m 行 n 列的子图。p是子图的位置,表示在网格中的第 p 个子图。
【补充】:
plot(X, Y): 绘制 2D 折线图,X 和 Y 分别是横坐标和纵坐标的数据。scatter(X, Y): 绘制散点图,X 和 Y 分别是散点的横坐标和纵坐标。bar(X, Y): 绘制柱状图,X 是柱子的位置,Y 是柱子的高度。stem(X, Y):绘制离散图(火柴棒图),X 和 Y 分别是横坐标和纵坐标的数据。
-
2.2 图像装饰
-
添加标题 / 坐标轴标签
plot(x, y) xlabel('x') % 添加 x 轴标签 ylabel('sin(x)') % 添加 y 轴标签 title('Plot of sin(x)') % 添加标题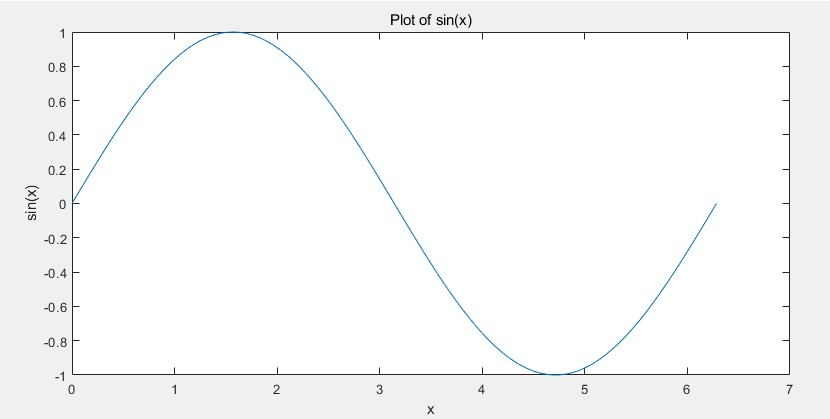
-
图例
图例存在的意义是在图中指出的某个函数的名字叫什么
使用
legend()函数进行赋值,输入参数为多个字符串,将按照plot的先后顺序依次分配给所绘制的各个函数图像plot(x, y1) hold on plot(x, y2) legend('sin(x)', 'cos(x)') % 添加图例因此
legend函数的参数数目必须与plot函数出现的次数相同,才能不重不漏地为所有函数提供图例【拓展】
图例也可以通过输入多个属性名称对其赋值,例如:
legend('label1', 'label2', 'Location', 'best','EdgeColor', 'r', 'Color', 'w','FontSize', 12, 'FontWeight', 'bold')上述代码设置了两个图例,自动选择最合适的位置出现,红色边框,白色底色,12号字体加粗
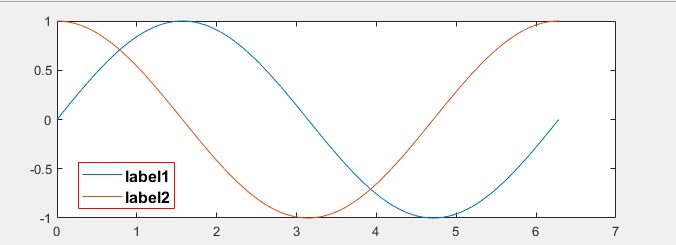
-
图像所用线条
该属性在
plot函数中配置,包括三种:-
颜色
Color:-
'r':红色 -
'g':绿色 -
'b':蓝色 -
'k':黑色 -
'm':品红色 -
'c':青色 -
'y':黄色 -
RGB 值:例如
[0.5, 0, 0.5]表示紫色
-
-
线型
LineStyle:-
'-':实线 -
'--':虚线 -
':':点线 -
'-.':点划线 -
'o':小圆圈,绘制散点图 -
'*':星星,绘制散点图
-
-
线宽
LineWidth:- 整数值,例如
2、3,表示线条的宽度
- 整数值,例如
【例如】:
plot(x, y, 'Color', 'r', 'LineStyle', '--', 'LineWidth', 2) % 使用参数名称同时指定颜色、线型和线宽上述代码指定了曲线为红色虚线,线宽为2
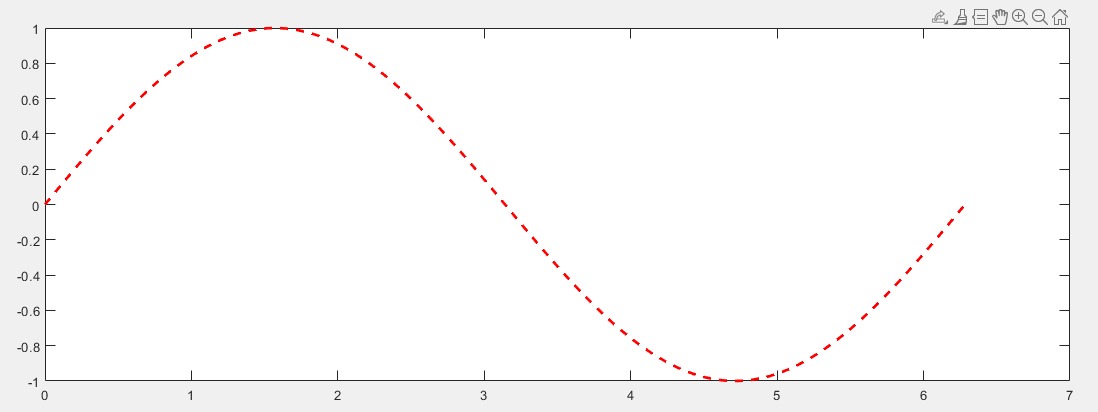
【补充】:
颜色
Color与线型LineStyle组合使用可以省略关键字,例如:plot(x, y1, 'r-') % 红实线 -
-
添加网格线
使用
grid on函数plot(x, y) grid on % 添加网格线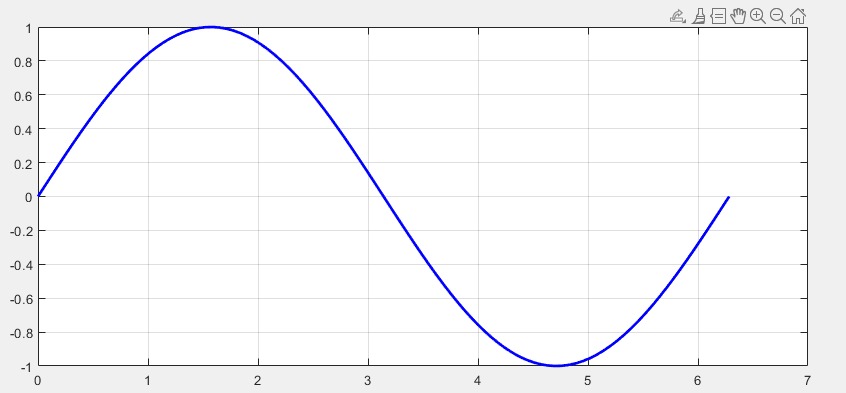
-
调整坐标轴范围
使用
xlim函数,参数为x的取值范围,ylim同理。若不修改则默认为最佳适配范围plot(x, y) xlim([0, 20]) %图像中x的取值范围为0-20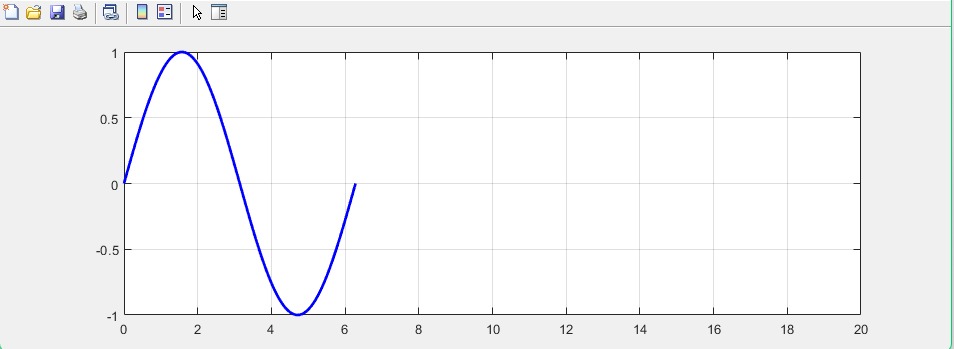
-
调整坐标轴刻度
使用
xticks函数,参数为坐标轴刻度取值,yticks同理。若不修改则默认为最佳适配刻度plot(x, y) yticks([0,0.2,0.6]) %纵轴只显示 0 0.2 0.6 这三个刻度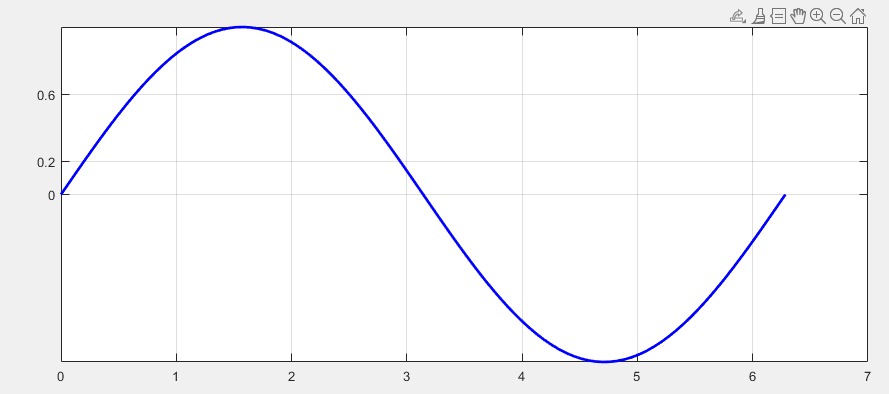
2.3 字体属性汇总
-
字体:
- 属性名:
FontName或FontFamily - 可选值:字符串,表示字体名称
- 英文字体:如
'Arial'、'Helvetica'、'Times New Roman'、'Courier'等。 - 中文字体:
- 宋体:
'SimSun' - 黑体:
'SimHei' - 微软雅黑:
'Microsoft YaHei' - 楷体:
'KaiTi' - 隶书:
'LiSu' - 幼圆:
'YouYuan'
- 宋体:
- 英文字体:如
- 属性名:
-
字体大小
-
属性名:
FontSize -
可选值:整数或小数,表示字体大小,例如
12或1.5。
-
-
字体粗细
-
属性名:
FontWeight -
可选值:
'normal'、'bold'、'light'等,分别表示普通、粗体、轻体。
-
-
字体倾斜
-
属性名:
FontAngle或FontItalic -
可选值:
'normal'、'italic',分别表示不倾斜和斜体。
-
-
字体颜色
-
属性名:
Color -
可选值:颜色字符串,如
'k'(黑色)、'r'(红色)、'g'(绿色)、'b'(蓝色)、'm'(品红色)、'c'(青色)、'y'(黄色)等,或者 RGB 值,如[0.5, 0, 0.5]表示紫色。
-
2.4 图形化操作
如果上述代码觉得操作复杂,下面来推荐一种 MATLAB 自带的图形化图像处理:
首先随便画一个函数图像,例如:
t=linspace(0,2*pi,20); %在0-2π之间均匀取20个点
s=sin(t);
c=cos(t);
figure
plot(t,s);
hold on %在上图的基础上再画一个图
plot(t,c);
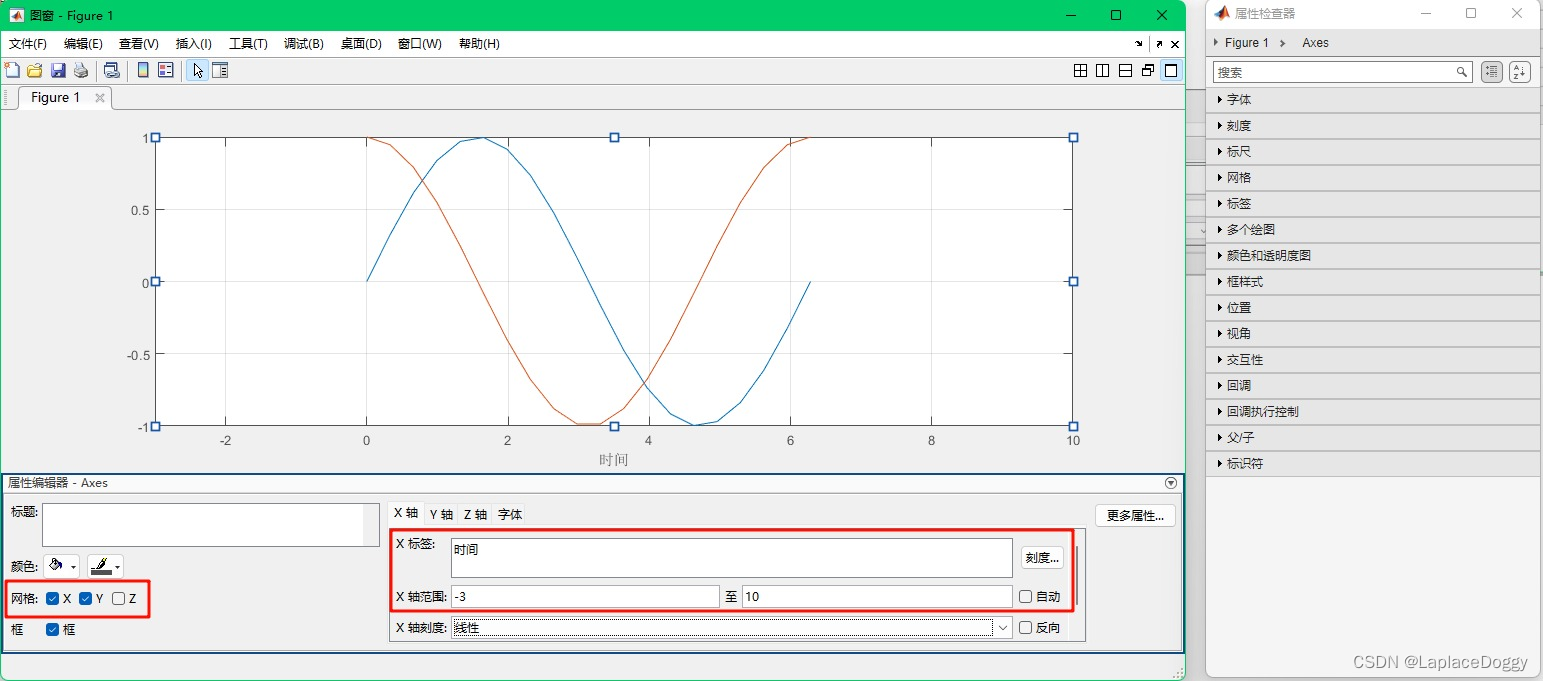
运行代码,在Figure窗口左上角点击查看>>属性编辑器
就会得到下面这个界面,点击“更多属性”可以打开属性检查器,修改更多属性:
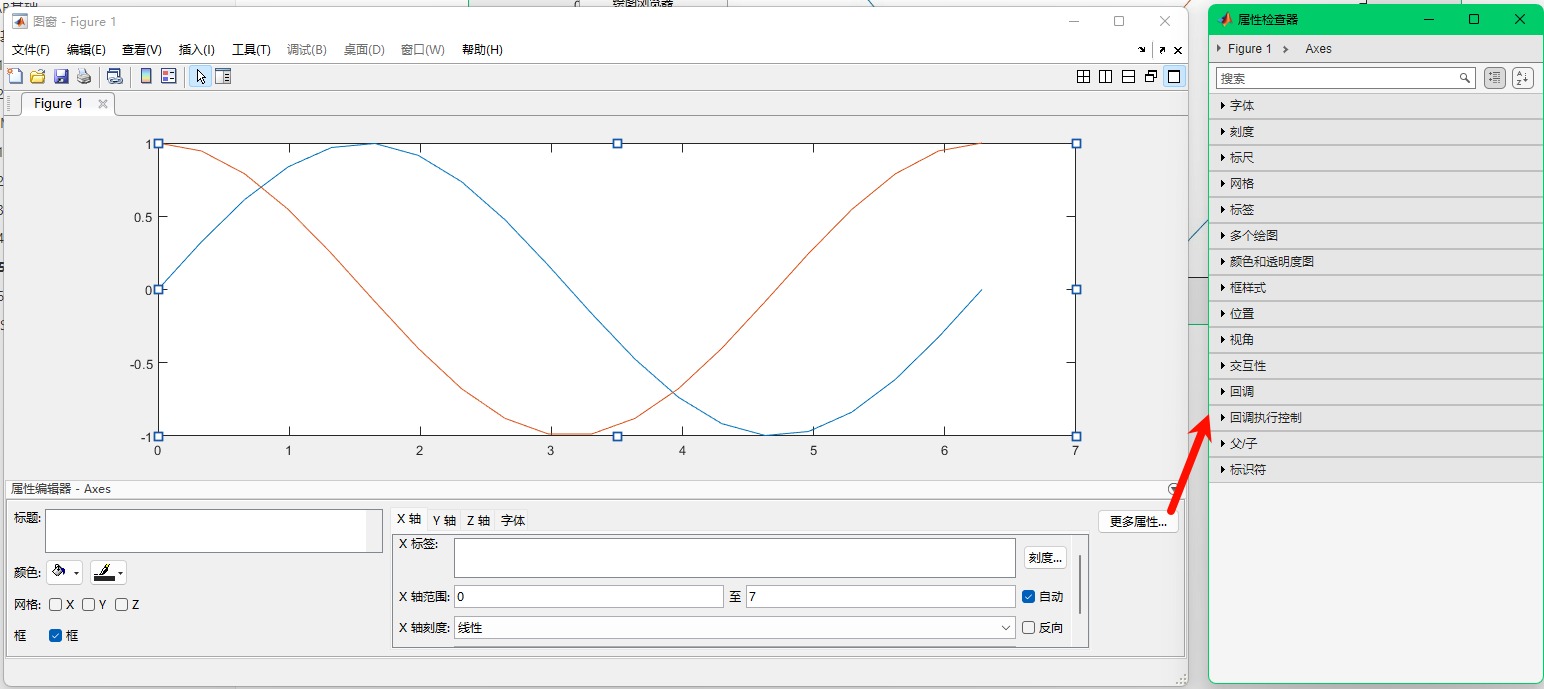
在这个界面里我可以随意地对图像进行操作,任何用代码可以实现的操作在这里都可以实现,比如:
- 加网格,加标签,调整x轴范围
-
设置图例
点击左上角这个小按钮可以插入图例,默认命名为:data1、data2、data3…
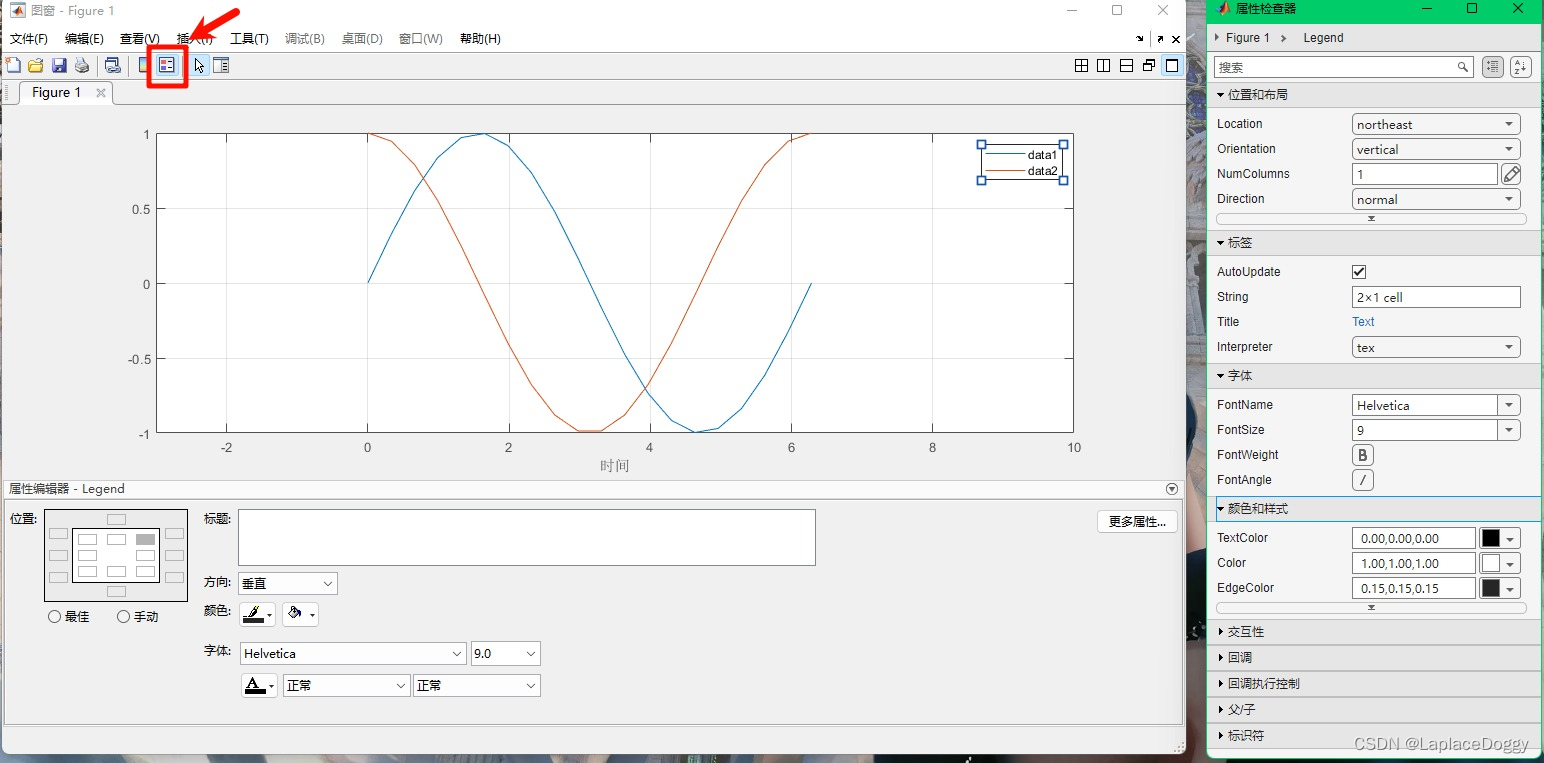
右边的属性栏可以调整位置,设置排列方式,修改字体字号,修改颜色…
-
修改线条
单击你要操作的曲线,在右边的属性检查器中可以进行修改参数
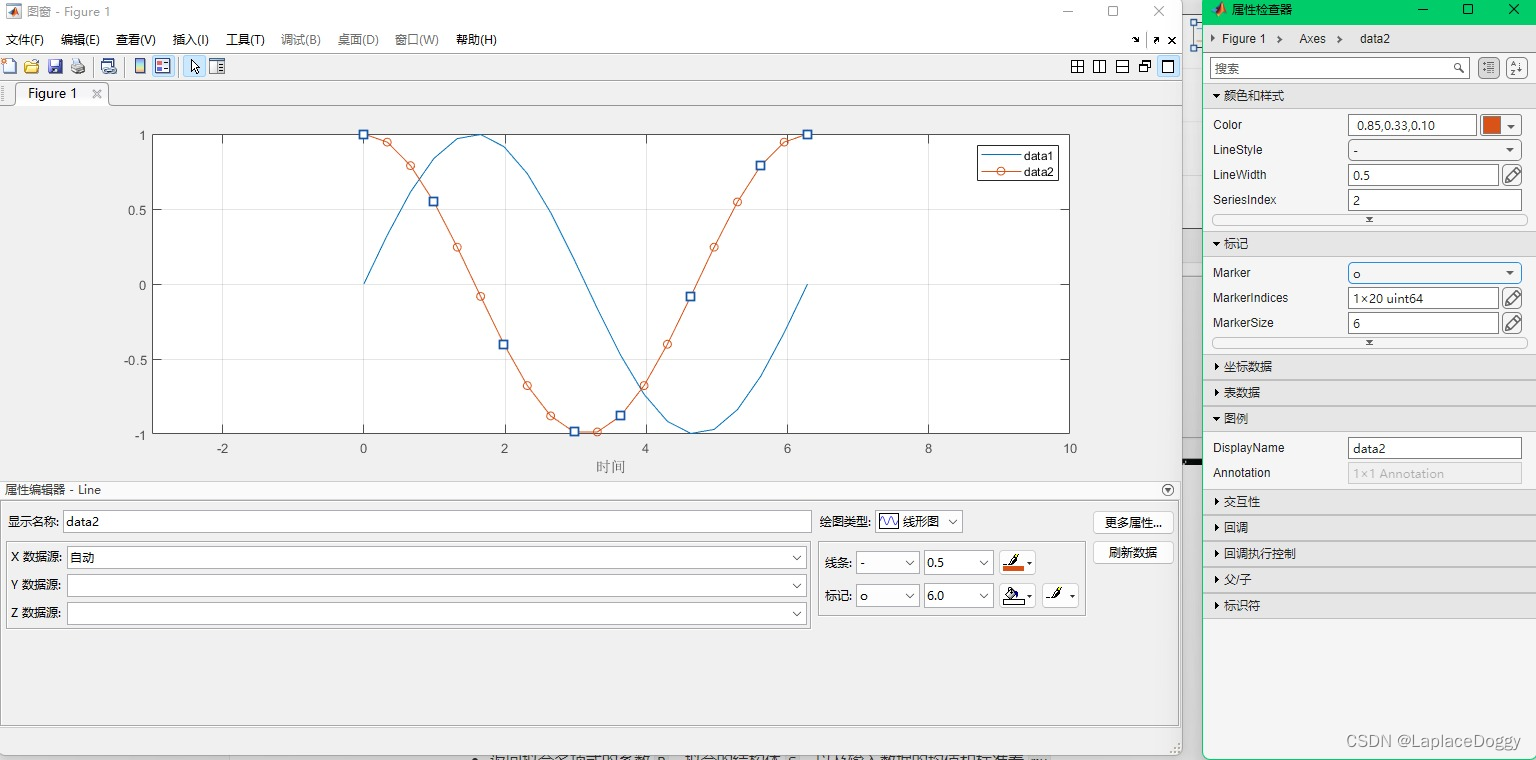
【注意】:
这种方法得到的图像不是通过代码修改的,一旦关掉就不能再找回了,修改完记得保存!!!
2.5 多项式拟合
常用polyfit()函数进行拟合
原理:最小二乘法
语法:[P, S] = polyfit(X, Y, m)
P:拟合多项式的系数数组,由高次到低次排列,长度为m+1S:拟合的结构体,包括:S.R:拟合的残差,即每个数据点的观测值与拟合值之间的差值,是一个大小为(m+1)*(m+1)的矩阵S.df:拟合自由度,即拟合的参数个数。S.normr:残差的范数,即拟合残差的欧几里得范数。
X:自变量数据,一个包含输入数据点的数组。Y:因变量数据,一个包含对应输出数据点的数组。m:拟合多项式的阶数,即最终生成多项式的最高次数。
此外,还需要一个辅助函数polyval(),直接计算多项式在这些自变量值处的函数值
语法:y = polyval(p, x)
p:一个包含多项式的系数的向量,例如 [ a n , a n − 1 , . . . , a 1 , a 0 a_n,a_{n-1},...,a_1,a_0 an,an−1,...,a1,a0 ] ,这里 a n a_n an 到 a 0 a_0 a0 分别是多项式的最高次项到常数项的系数。x:一个包含自变量值的向量或者标量,表示要计算多项式函数值的自变量值。
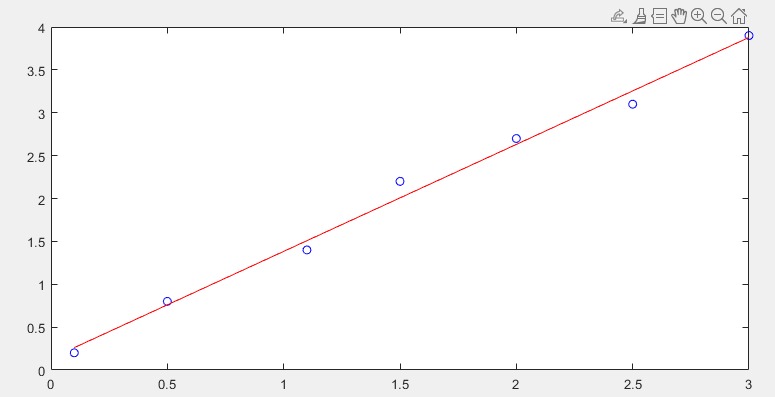
代码示例如下:
%原始数据
xData = [0.1, 0.5, 1.1, 1.5, 2.0, 2.5, 3.0];
yData = [0.2, 0.8, 1.5, 2.0, 2.5, 3.2, 3.8];
%开始拟合
degree = 1;
[P,S]= polyfit(xData, yData, degree);
%绘制原始数据
figure
plot(xData, yData, 'bo');
hold on
%绘制拟合曲线图
xFit = linspace(min(xData), max(xData), 100); % 生成拟合曲线上的 x 值
yFit = polyval(P, xFit); % 计算拟合曲线上的 y 值
plot(xFit,yFit,'r-');
效果如下:
【拓展1】如果想将P所拟合的函数表达式输出,可以用:
fitExpression = 'y =';
for i = 1:length(P)
if P(i) ~= 0
if i == 1
fitExpression = strcat(fitExpression, num2str(P(i)), '*x^', num2str(length(P)-i));
else
if P(i) > 0
fitExpression = strcat(fitExpression, ' + ', num2str(P(i)), '*x^', num2str(length(P)-i));
else
fitExpression = strcat(fitExpression, ' - ', num2str(abs(P(i))), '*x^', num2str(length(P)-i));
end
end
end
end
disp(fitExpression);
输出结果为:
y =1.2201*x^1 +0.13501*x^0
【拓展2】如果将P的系数矩阵输出,则可以看作是频谱图(该图的多项式阶数degree取5)
Xpin=1:length(P);
Ypin=P(end:-1:1); %P的系数是从高到底,因此这里需要反向
stem(Xpin,Ypin);
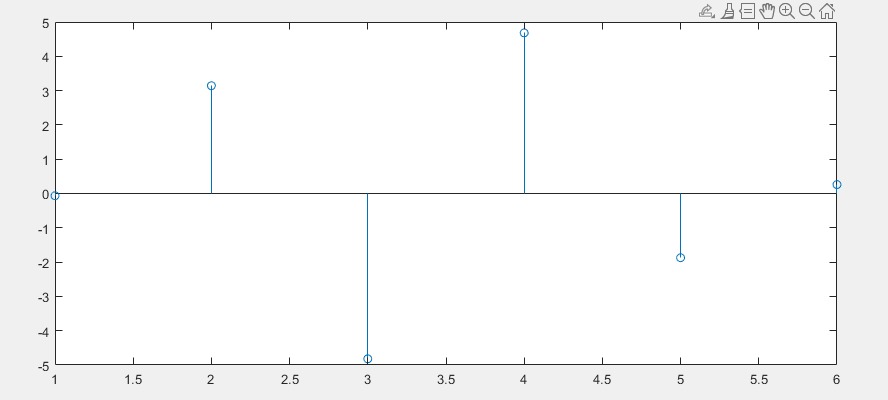
2.6 其他拟合
-
lsqcurvefit函数是 MATLAB 中用于拟合 任意 非线性模型的函数
原理:最小二乘法
语法:
x = lsqcurvefit(fun, x0, xdata, ydata)-
fun:是一个函数句柄,表示要拟合的非线性模型函数,例如模型 y = a ∗ e b x y=a*e^{bx} y=a∗ebx 的代码表示如下:function y = myModel(params, x) % params 是未知参数数组,数组中的每个元素都是未知参数,x 是自变量数组 y = params(1) * exp(params(2) * x); end -
x0:是对于fun代表的非线性模型函数中未知参量的猜测值,例如模型 y = a ∗ e b x y=a*e^{bx} y=a∗ebx 有两个未知数 a a a 和 b b b ,因此:x0 = [1, 0.5]; -
xdata:是一个包含自变量数据的向量,表示给定的自变量数据点。 -
ydata:是一个包含因变量数据的向量,表示给定的因变量数据点。
代码示例如下:
% 原始数据 xData = [0.1, 0.5, 1.1, 1.5, 2.0, 2.5, 3.0]; yData = [0.2, 0.8, 1.5, 2.0, 2.5, 3.2, 3.8]; % 开始拟合 x0 = [1, 0.5]; params = lsqcurvefit(@myModel, x0, xData, yData); %绘制原始数据 figure; plot(xData, yData, 'bo'); hold on; %绘制拟合数据 xFit = linspace(min(xData), max(xData), 100); yFit = myModel(params, xFit); %计算标准拟合数据 plot(xFit, yFit, 'r-');效果如下:
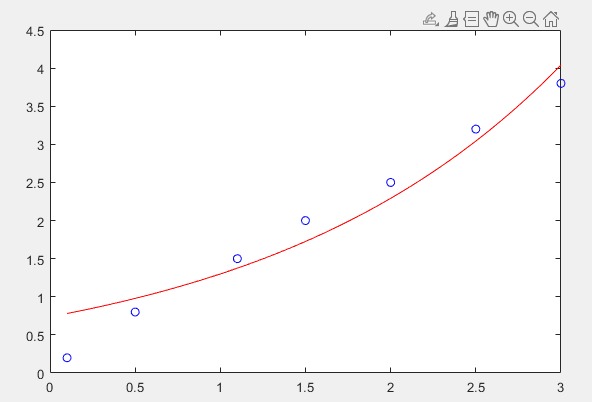
【注意】
lsqcurvefit函数需要手动输入一个猜测值,猜测值可能会对最终模型产生微小影响,问题不大,随便猜一个就行,但不能没有 -
-
fittype函数
fittype函数需要下载Curve Fitting Toolbox工具包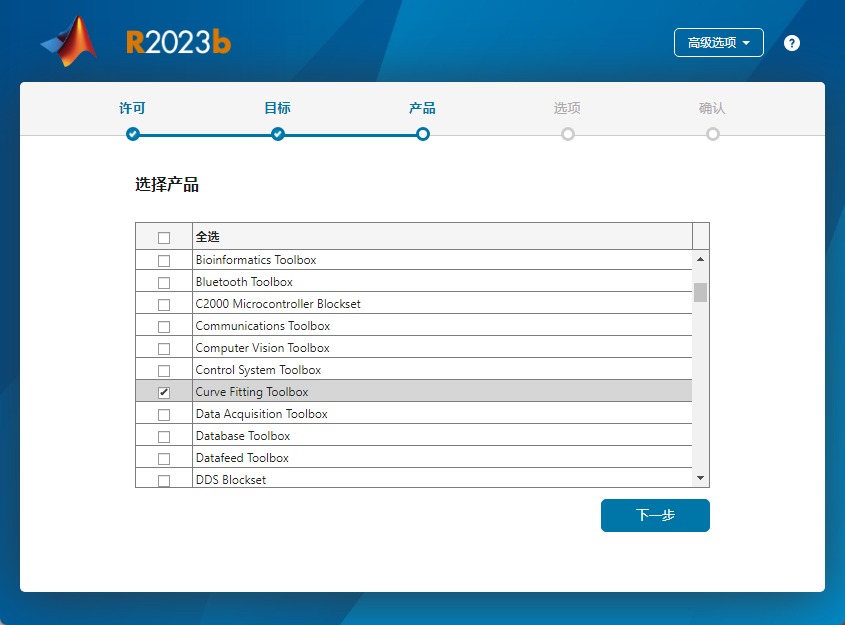
对于已知的两个等长数组
x和y,要得到两者的拟合函数关系,可以通过如下步骤:语法:
fittype('expression')参数:
'expression'是一个字符串,表示拟合函数的表达式,如'a * x^2 + b * x + c'代码示例如下:
% 示例数据 xData = [0.1, 0.5, 1.1, 1.5, 2.0, 2.5, 3.0]; yData = [0.2, 0.8, 1.5, 2.0, 2.5, 3.2, 3.8]; % 创建二次多项式拟合类型对象 ft = fittype('a * x^2 + b * x + c'); % 使用 fit 函数拟合数据 fittedModel = fit(xData', yData', ft); %传入列向量,因此要转置 %上面这一行代码中可以提供猜测起点,如 fittedModel = fit(xData', yData', ft, 'StartPoint', [1,1,1]); % 绘制数据点和拟合曲线 figure plot(fittedModel, xData, yData);模型的样子是什么呢,打印一下康康:
>> disp(fittedModel) 常规模型: fittedModel(x) = a * x^2 + b * x + c 系数(置信边界为 95%): a = -0.009914 (-0.08421, 0.06438) b = 1.251 (1.014, 1.488) c = 0.1209 (-0.03395, 0.2758) -
对比一下上述两个模型
% 原始数据 xData = [0.1, 0.5, 1.1, 1.5, 2.0, 2.5, 3.0]; yData = [0.2, 0.8, 1.5, 2.0, 2.5, 3.2, 3.8]; %法一处理 x0 = [1, 0.5]; params = lsqcurvefit(@myModel, x0, xData, yData); %法二处理 ft = fittype('a * exp(b*x)'); fittedModel = fit(xData', yData', ft); %法一的图 figure subplot(1,2,1) plot(xData, yData, 'bo'); hold on; %法二的图 xFit = linspace(min(xData), max(xData), 100); yFit = myModel(params, xFit); plot(xFit, yFit, 'k-'); legend("data","拟合曲线") subplot(1,2,2) plot(fittedModel, xData, yData);所得图像如下:
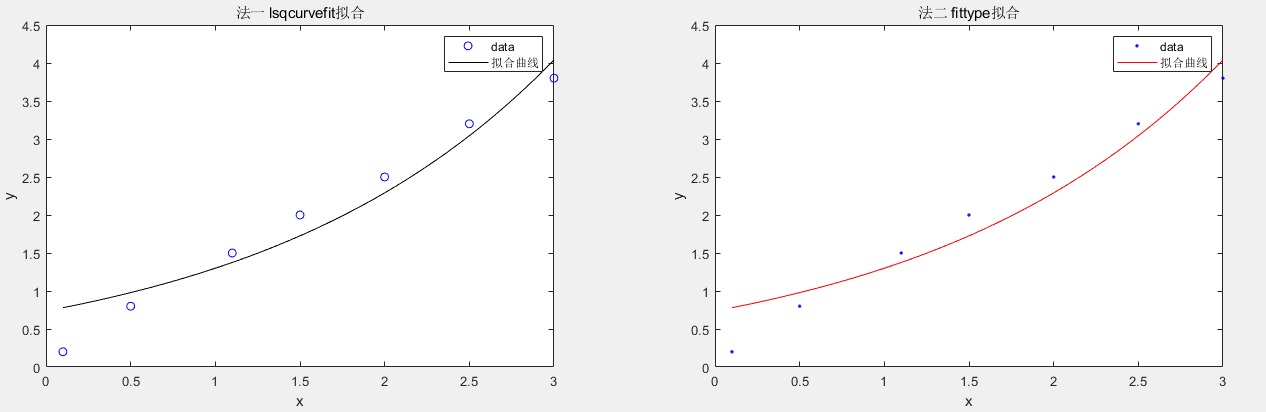
模型参数如何呢?
>> disp("法一lsqcurvefit模型中的参数为:") disp(fittedModel) disp("法二fittype模型中params的参数为:") disp(params) 法一lsqcurvefit模型中的参数为: 常规模型: fittedModel(x) = a * exp(b*x) 系数(置信边界为 95%): a = 0.7372 (0.3647, 1.11) b = 0.5671 (0.3658, 0.7683) 法二fittype模型中params的参数为: 0.7372 0.5671可以看出拟合程度极其相似



未完待续…
小狗都会好起来的!
三、Simulink仿真
3.1 阶跃函数的延时
加入元件的步骤:
Step1:打开“库浏览器”
Step2:搜索需要的元件
Step3:将元件拖动到右侧画布中
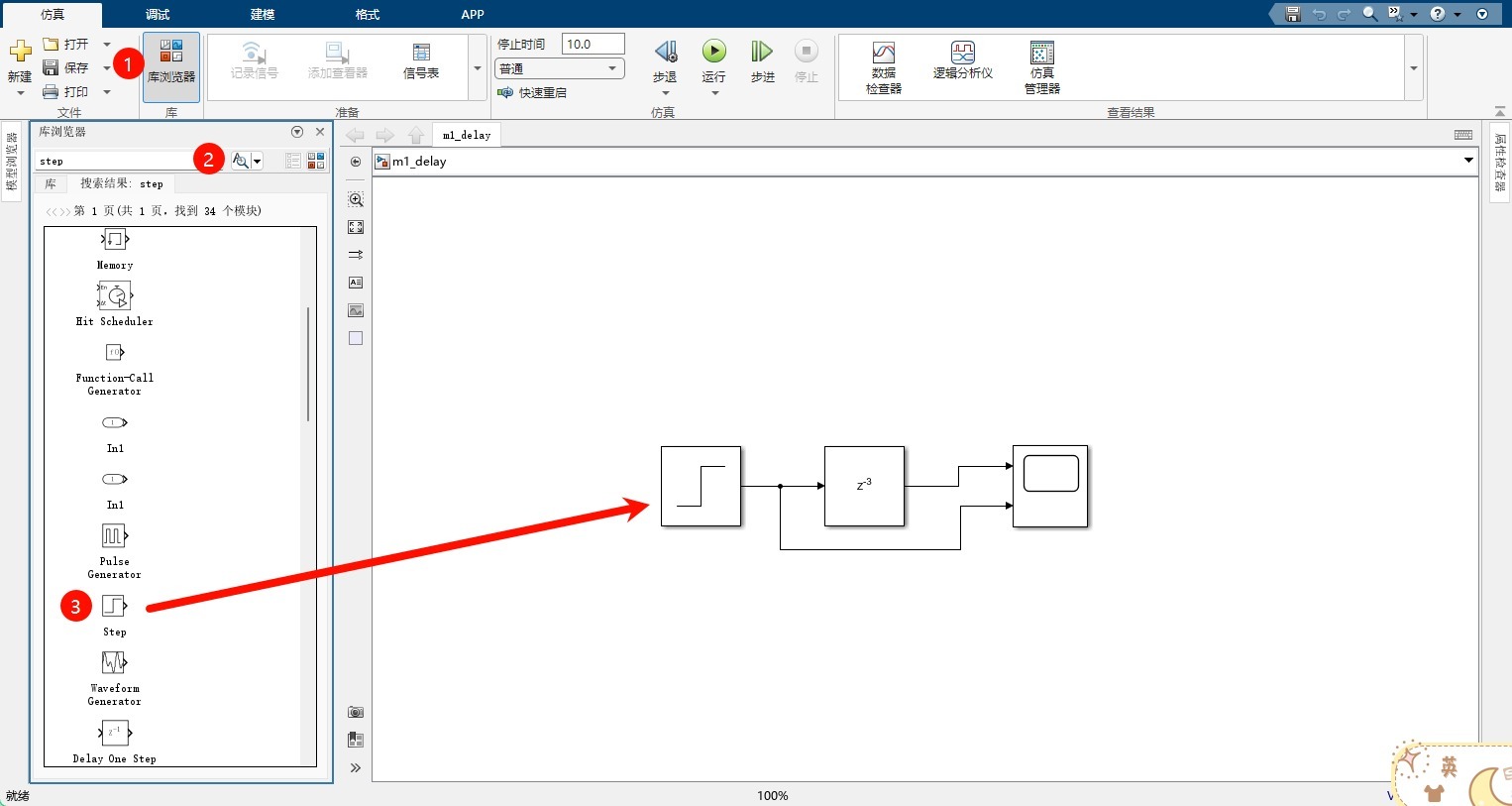
拖动好后,双击元件修改属性,下图是Step元件和Delay元件:

下图是Time Scope元件,可以在配置属性中更改输入端口数目和布局,使得同时展示两个图像:
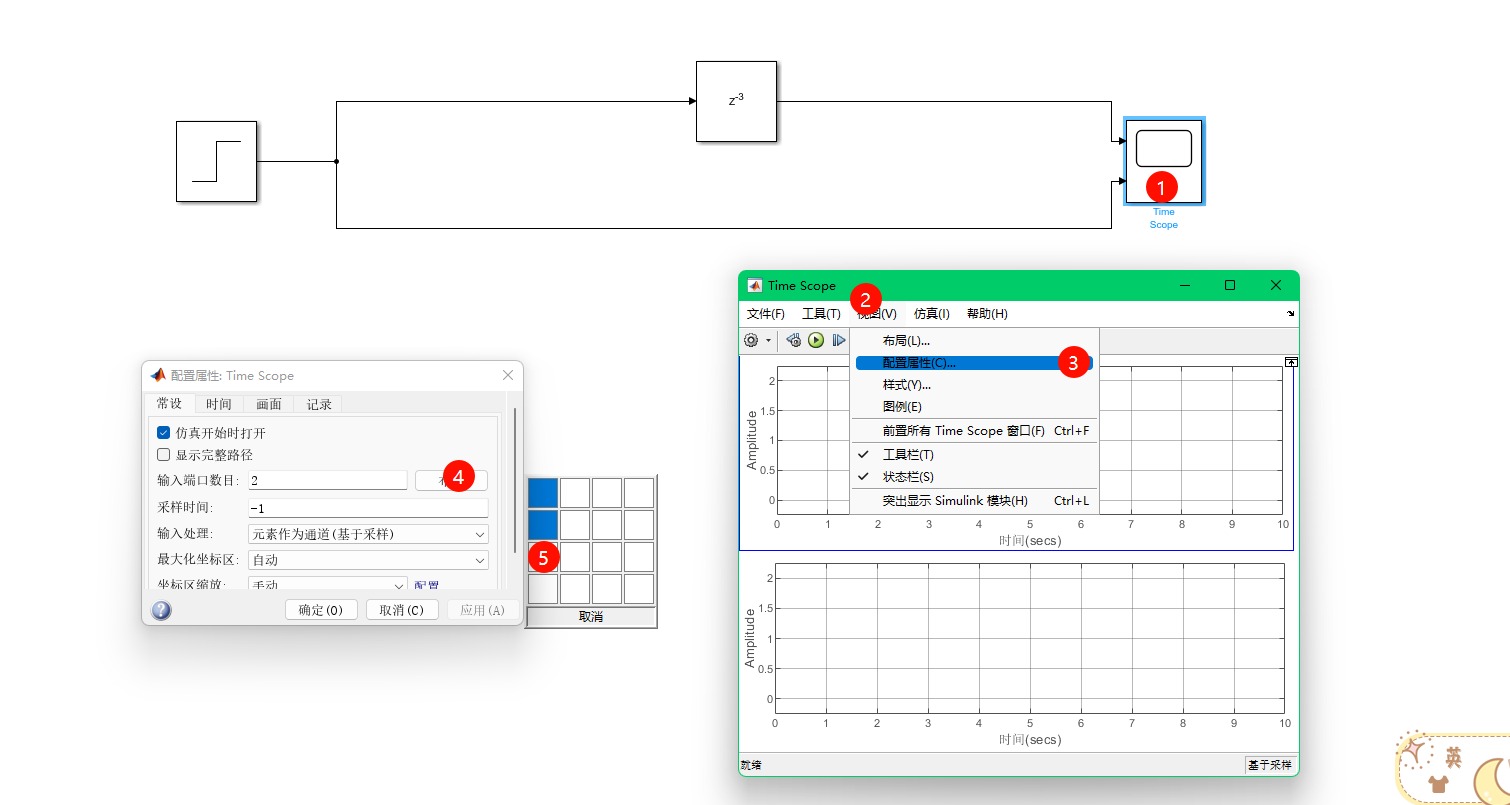
在“样式”窗口中修改曲线的各项参数
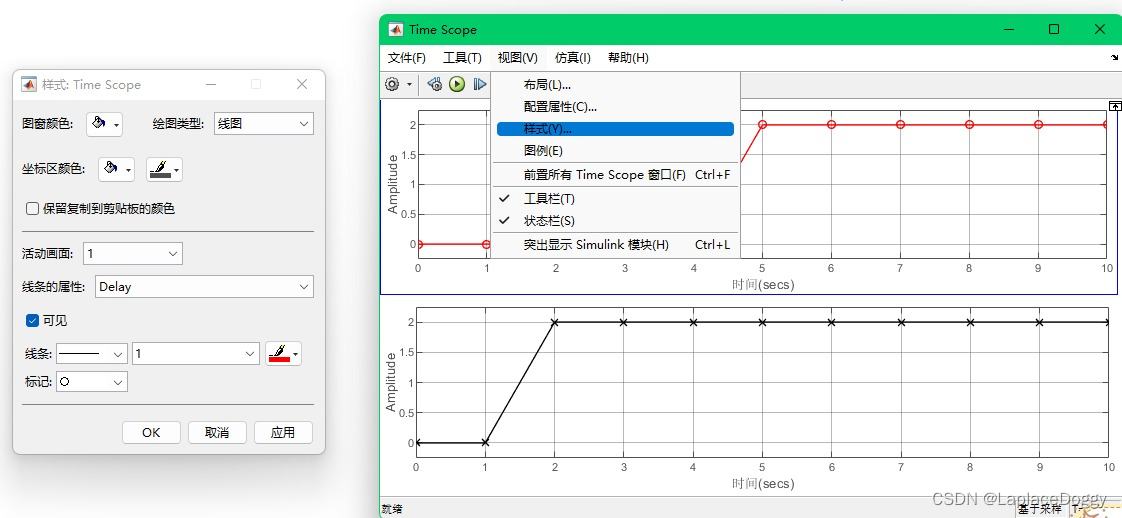
可以观察到阶跃函数在延时前后的图像,图中是折线而非直角的原因是,Step元件中采样时间设置的是1秒,也就是说每秒取1个点,只在整数点的部分有值。如果将采样时间取小一点,才可以看到真实的阶跃函数:
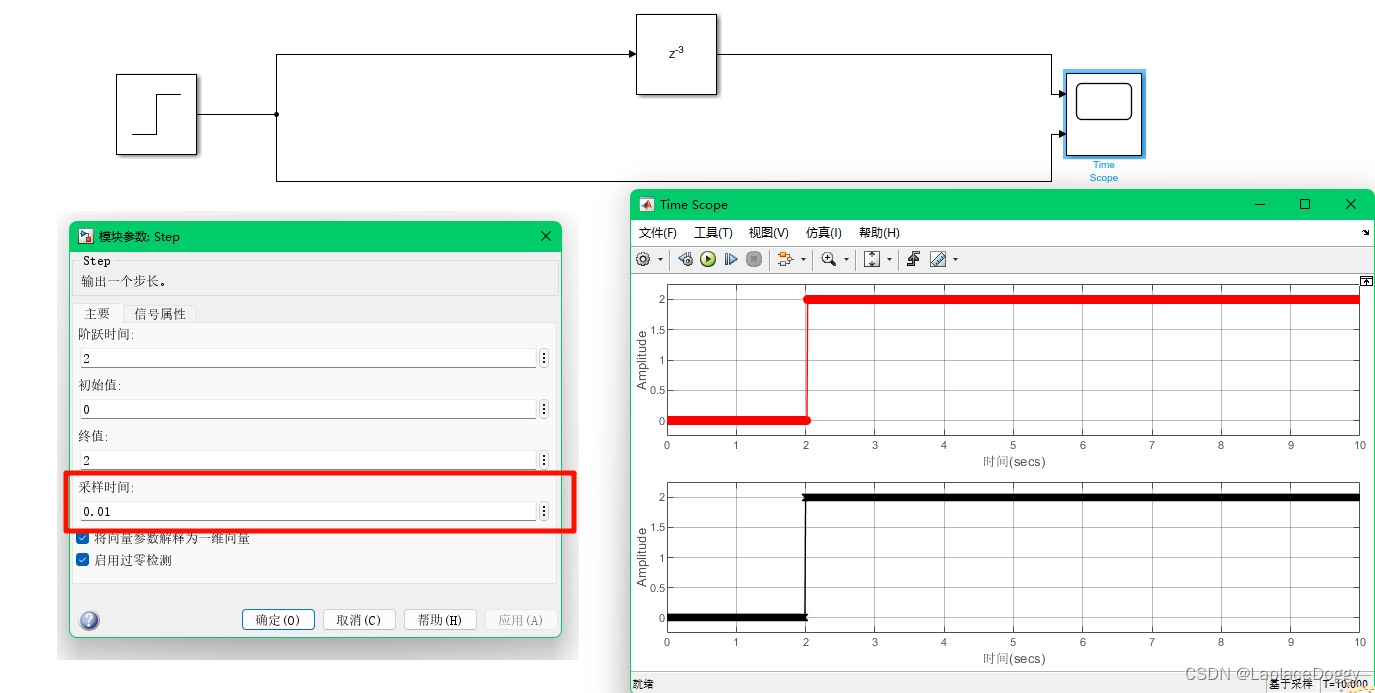
但是如果只调整采样时间,会发现最终Time Scope元件的输出并没有延时,这是因为Delay元件中设置的延时长度是3,单位是“采样时间”,采样时间现在设置为0.01s,因此只延时了0.03s,如果想延时3s,则需将Delay元件中的延时长度设置为300:
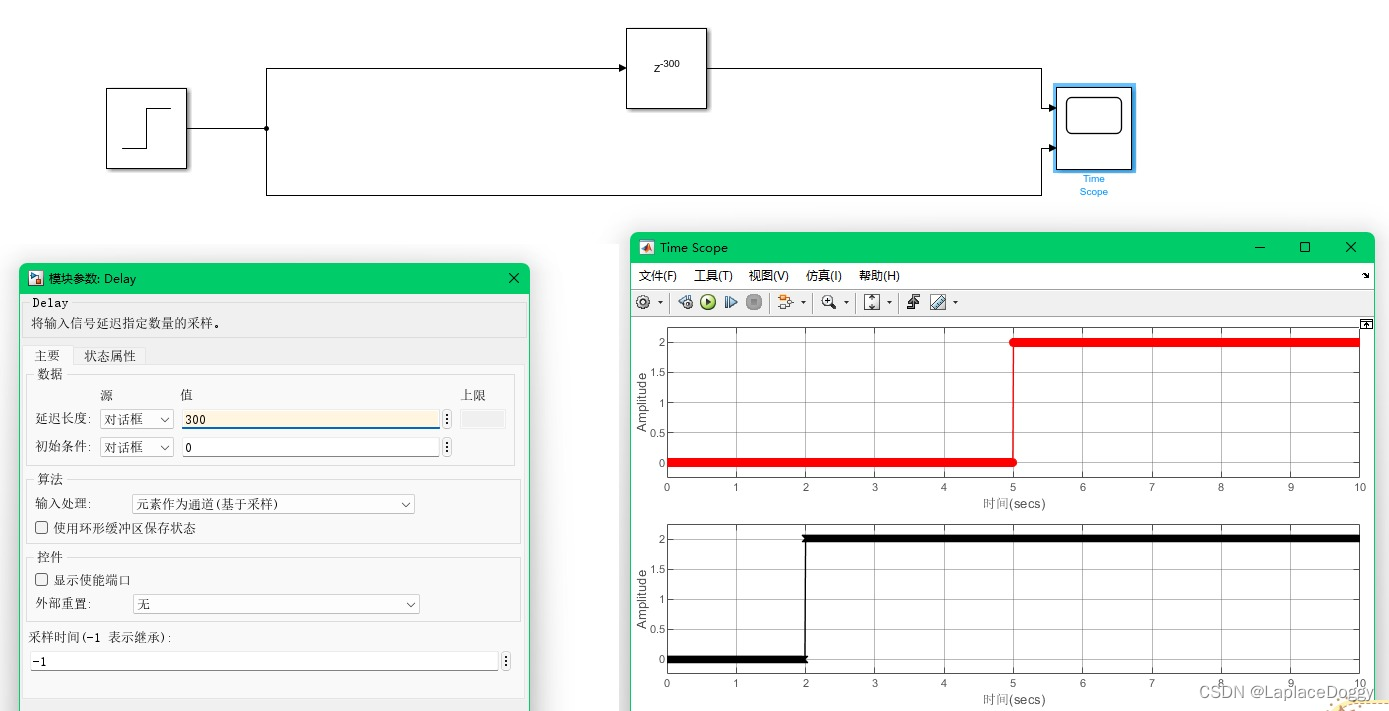
3.2 输入变量
右击空白处点击“模型属性”选项,在回调函数窗口中编写函数:
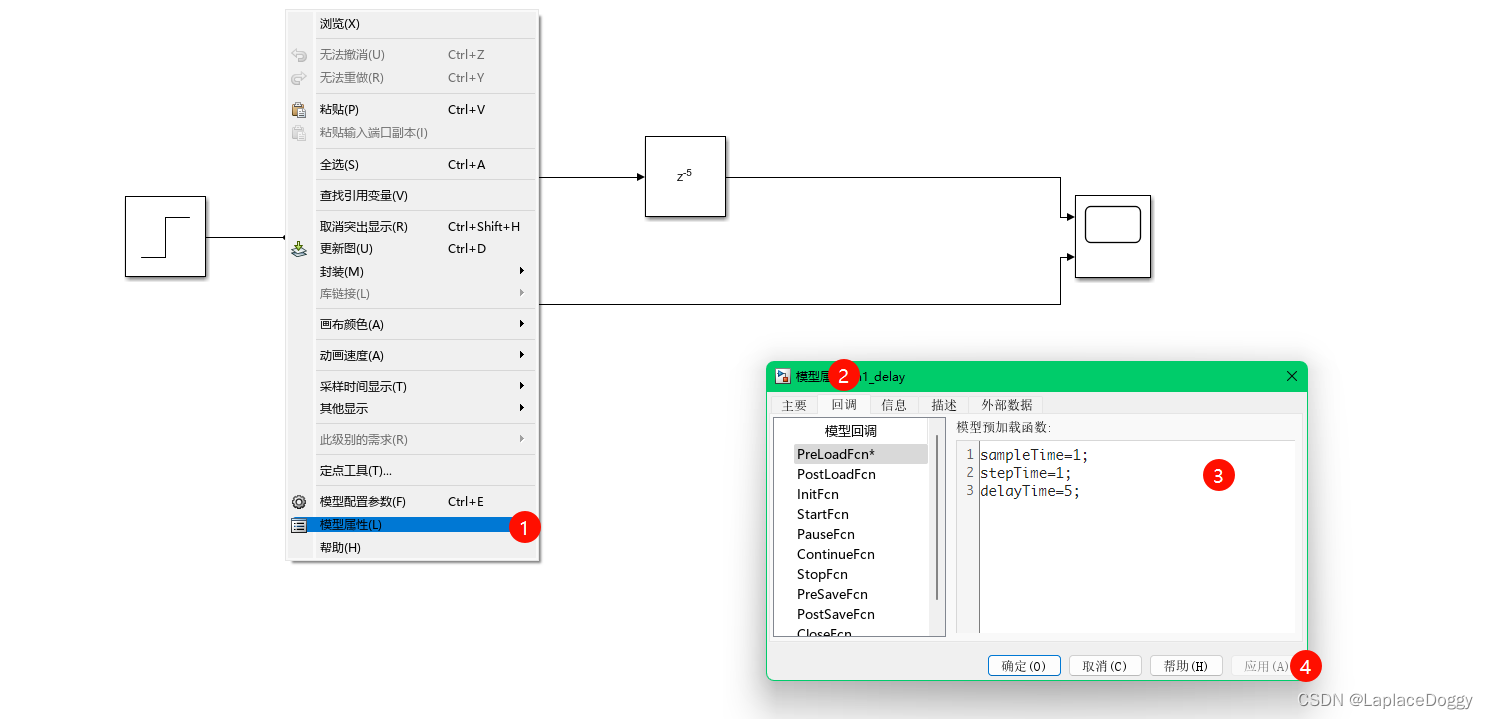
上述代码编写完毕后,会在 MATLAB 的工作区同步显示变量:
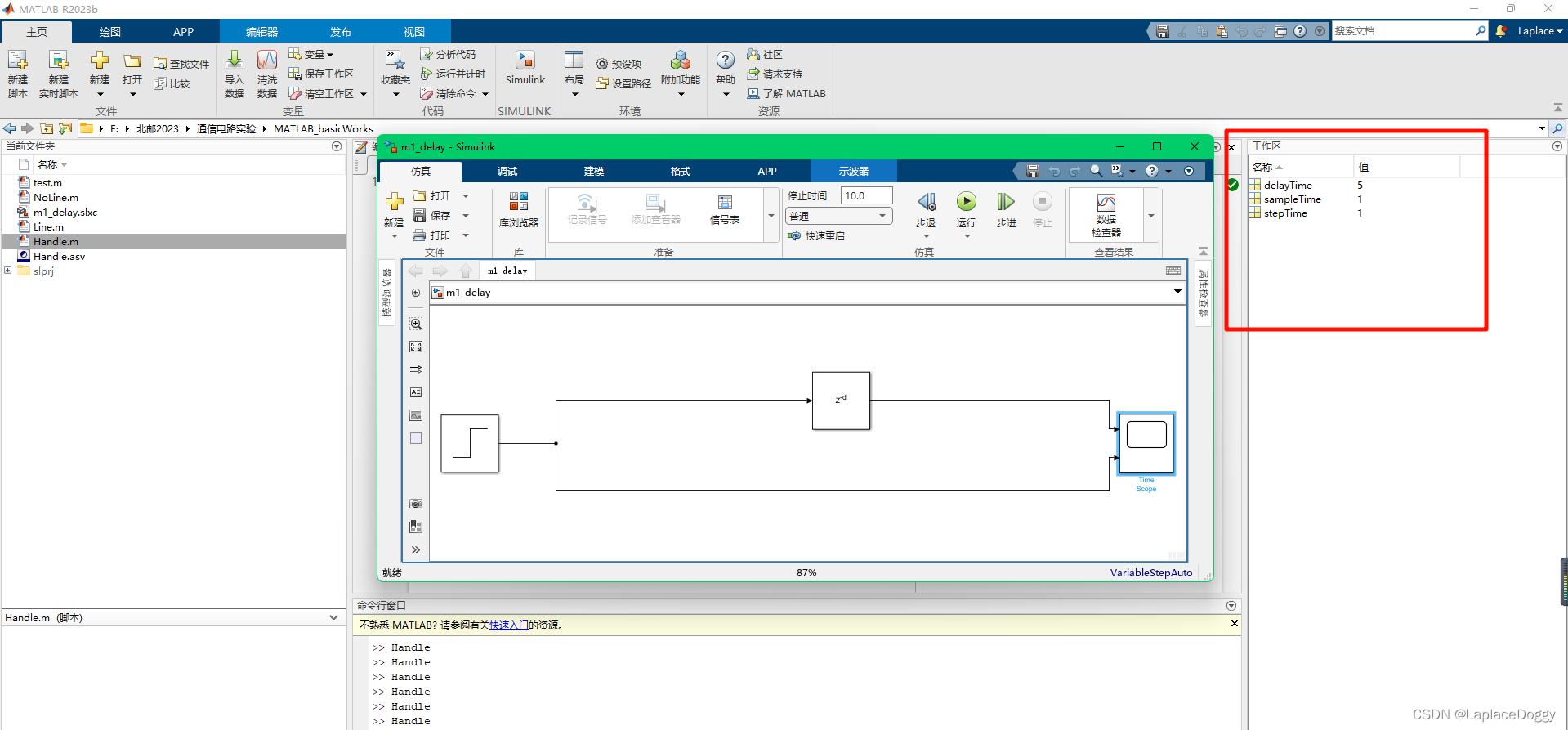
然后在 Simulink 工作区将Step和Delay两个元件对应参数修改为变量名:
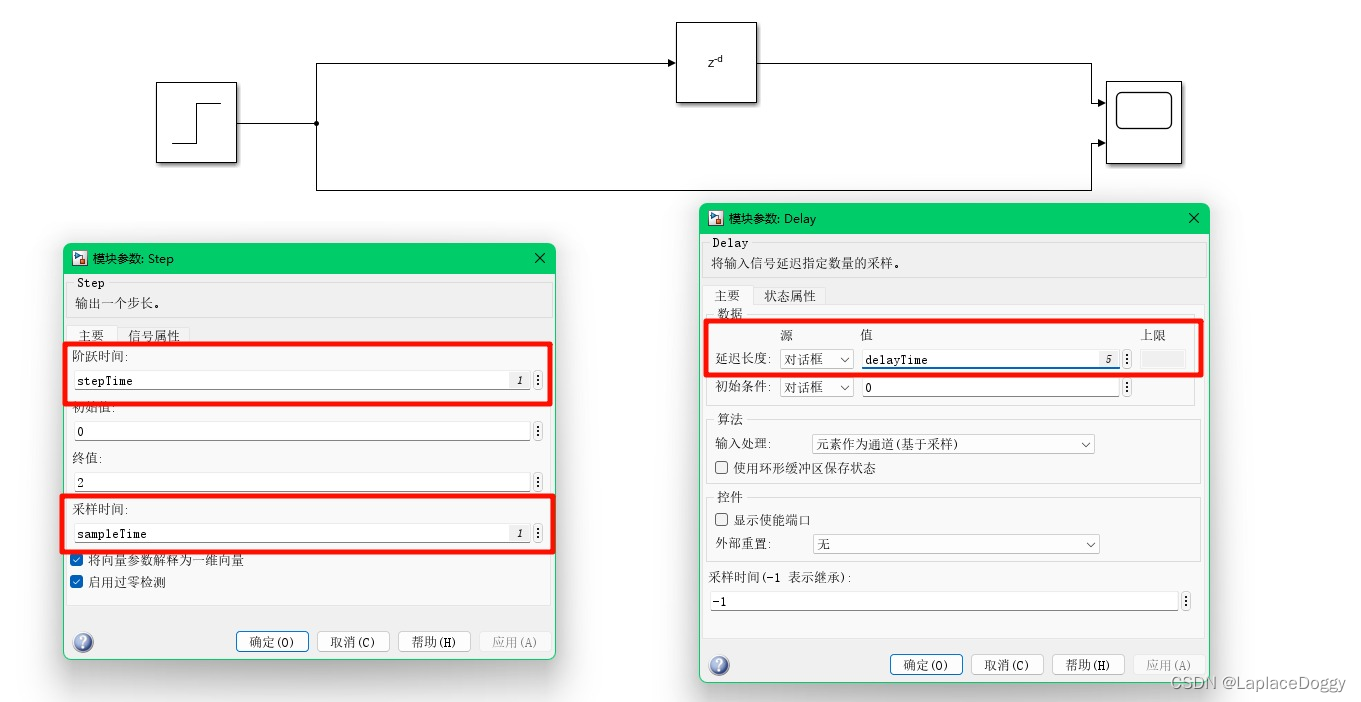
3.3 输出变量
添加To Workspace元件,将其变量名称修改为想要的变量名,保存格式选数组更直观:
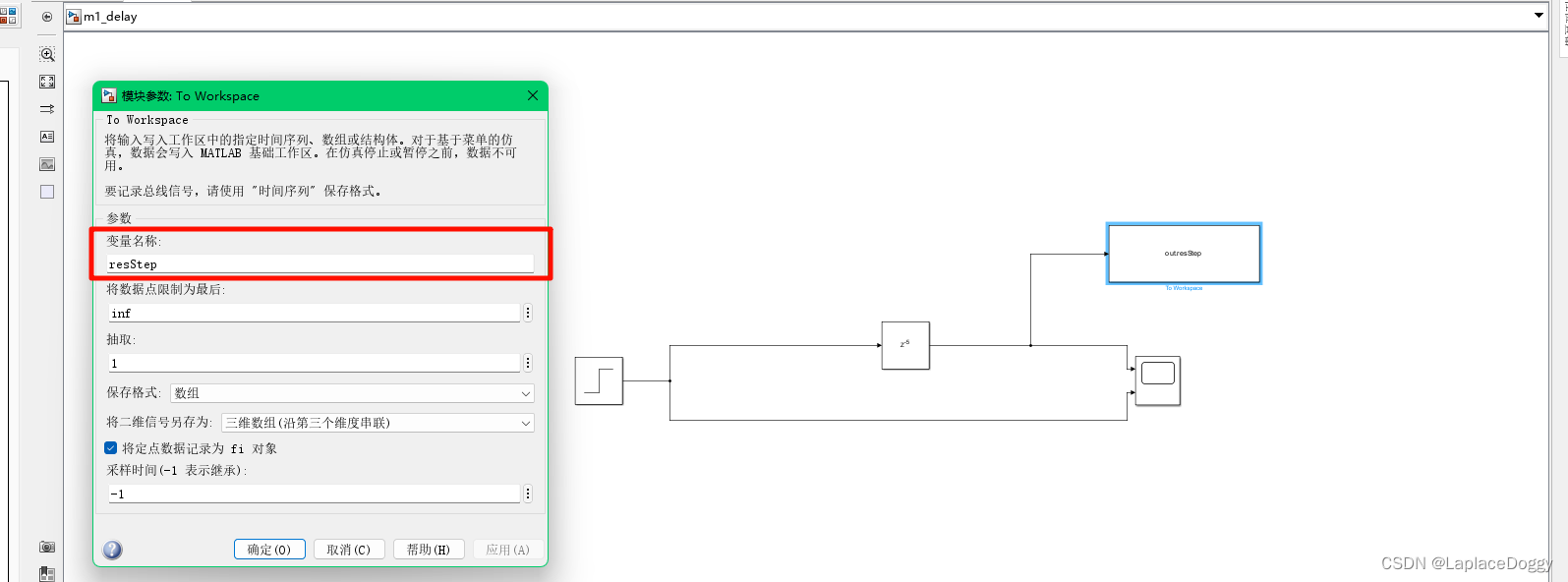
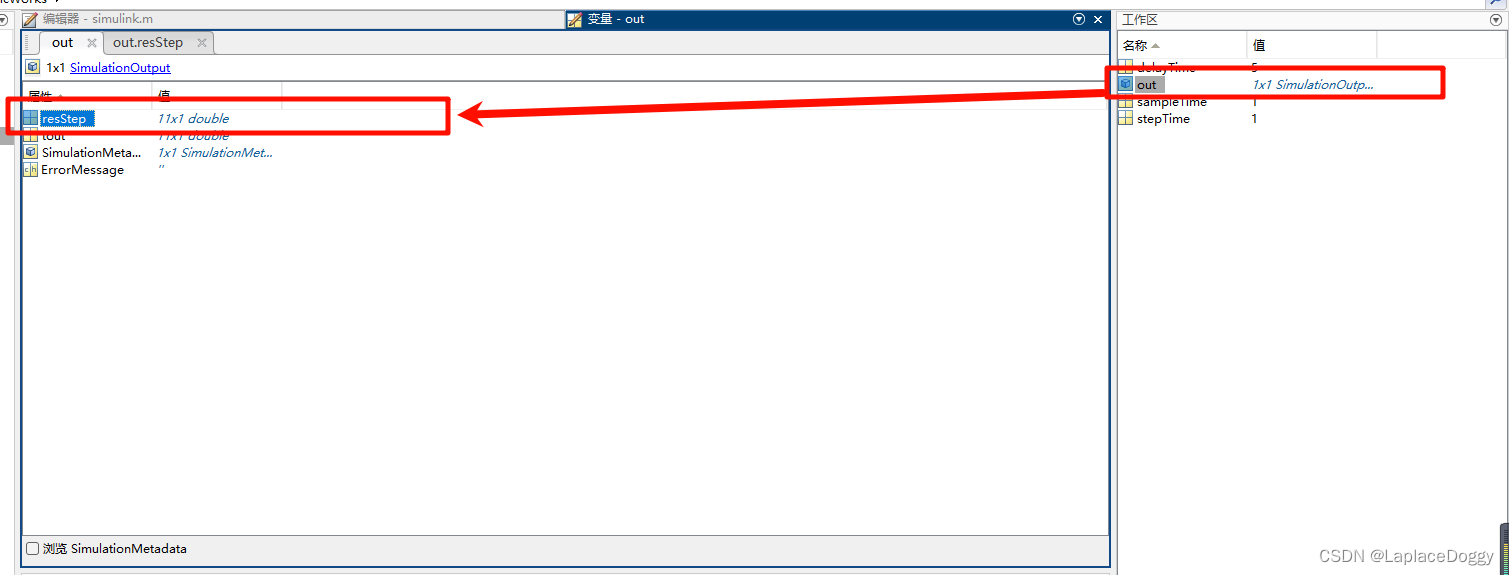
这个时候会在 MATLAB 工作区中多出现一个文件out,其中包含多个变量,其中一个就是刚才定义的resStep
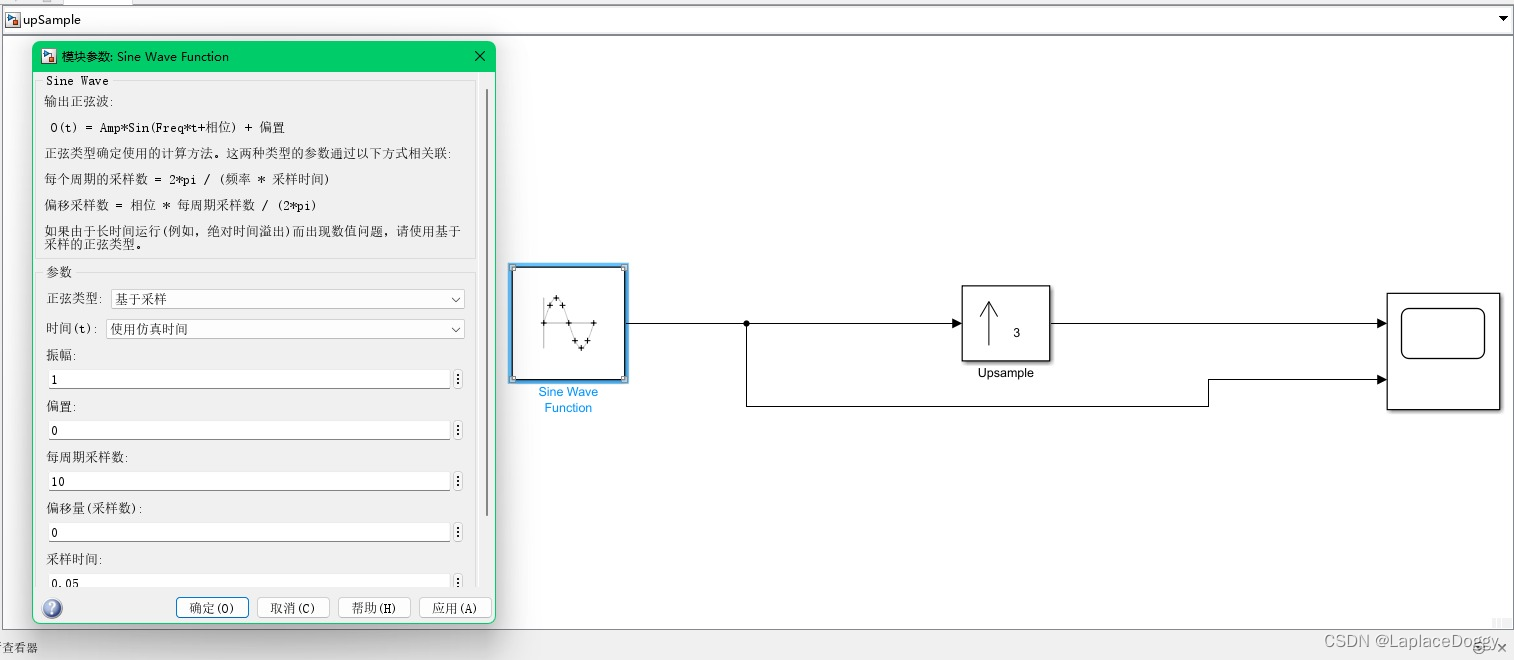
3.4 上采样
使用Sine Wave Function元件产生正弦波,Upsample元件做上采样
时间记得选使用仿真时间,并手动设置采样时间
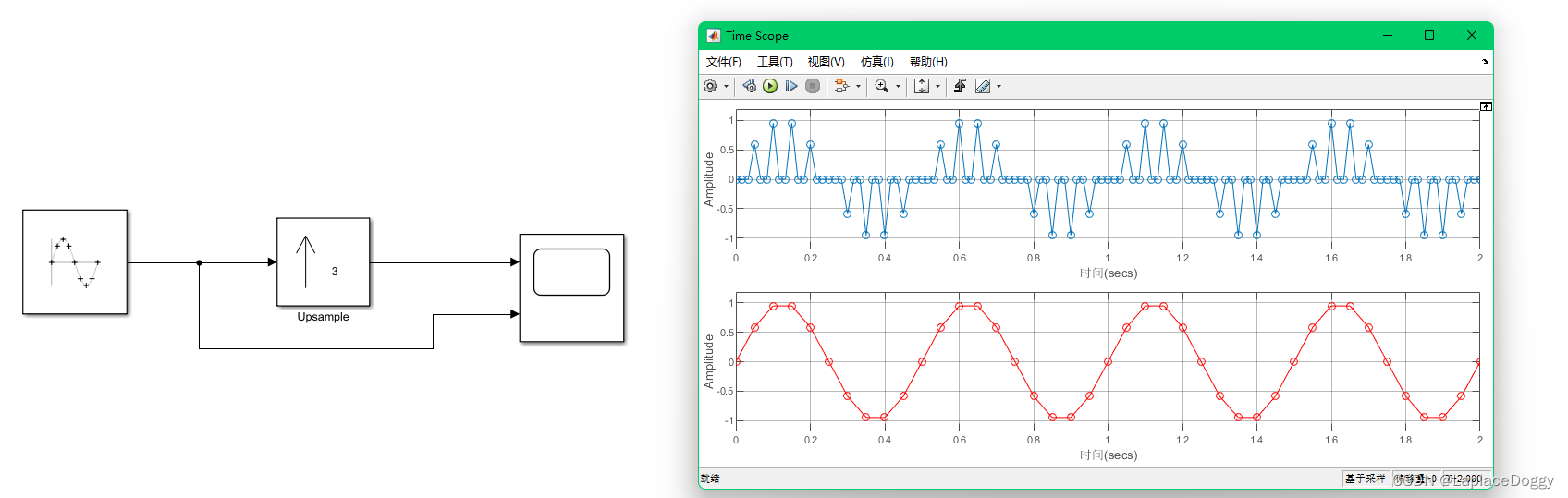
示波器输出如下:
四、5G信号同步
本章节来源于北京邮电大学信息与通信工程学院王鲁晗老师《通信电路实验》课程,欢迎大家报考北京邮电大学!
前言:对于一个典型的通信系统而言,其工作流程如下:
在接收机的设计中,对于5G信号而言,信号的同步是做到解调出正确信息的关键,本章节将主要介绍对于一段已经录制好的5G空口信号如何处理得到其中传递的关键信息

4.1 OFDM技术概览
(1)OFDM符号
在数字调制的过程中,会用到诸如ASK、FSK、PSK等一系列调制技术,其中包含对输入的复信号进行时移、乘积等操作,因此对于输入的三角函数信号我们需要将其转换为复数信号进行后续操作。
以QPSK为例,每个符号对应2bit数据,可将其映射到复数序列:
Q
P
S
K
符号映射
{
00
−
−
e
j
π
4
01
−
−
e
j
3
π
4
10
−
−
e
j
5
π
4
11
−
−
e
j
7
π
4
QPSK符号映射 \begin{cases} 00--e^{j\frac{\pi}{4}} \\ 01--e^{j\frac{3\pi}{4}}\\ 10--e^{j\frac{5\pi}{4}} \\ 11--e^{j\frac{7\pi}{4}} \end{cases}
QPSK符号映射⎩
⎨
⎧00−−ej4π01−−ej43π10−−ej45π11−−ej47π
对于一个输入的复基带信号
A
(
t
)
=
I
(
t
)
+
j
⋅
Q
(
t
)
A(t)=I(t)+j·Q(t)
A(t)=I(t)+j⋅Q(t) ,通过复载波
e
j
2
π
f
t
e^{j2\pi ft}
ej2πft 进行调制,得到QAM信号:
s
(
t
)
=
[
I
(
t
)
+
j
⋅
Q
(
t
)
]
e
j
2
π
i
f
t
=
A
(
t
)
e
j
2
π
f
t
s(t)=[I(t)+j·Q(t)]e^{j2\pi ift}=A(t)e^{j2\pi ft}
s(t)=[I(t)+j⋅Q(t)]ej2πift=A(t)ej2πft
要传输多个QAM信号,则选取不同载波进行调制,如
e
j
2
π
f
1
t
e^{j2\pi f_1t}
ej2πf1t,
e
j
2
π
f
2
t
e^{j2\pi f_2t}
ej2πf2t,
e
j
2
π
f
3
t
e^{j2\pi f_3t}
ej2πf3t…以此类推
选取等间隔的子载波,间隔 Δ f = 2 π N \Delta f=\frac{2\pi}{N} Δf=N2π ,其中 ( N + 1 ) (N+1) (N+1) 为子载波数目,也就是将 0 − 2 π 0-2\pi 0−2π 分成了 ( N + 1 ) (N+1) (N+1) 个子载波,任意两个子载波都相互正交:
e j 2 π ( f + 0 ⋅ Δ f ) t e^{j2\pi(f+0·\Delta f)t } ej2π(f+0⋅Δf)t, e j 2 π ( f + 1 ⋅ Δ f ) t e^{j2\pi(f+1·\Delta f)t } ej2π(f+1⋅Δf)t, e j 2 π ( f + 2 ⋅ Δ f ) t e^{j2\pi(f+2·\Delta f)t } ej2π(f+2⋅Δf)t,…, e j 2 π ( f + N ⋅ Δ f ) t e^{j2\pi(f+N·\Delta f)t } ej2π(f+N⋅Δf)t
【为什么是正交的呢?】这是因为它们的频率分量相差一个整数倍的变化量(Δf),这导致它们的周期性在整数倍频率上对齐,从而使得它们在整数个周期内完全重叠,形成正交关系。可以通过理论推导内积为0证明如下:
∫ 0 T e j 2 π ( f + m Δ f ) t ⋅ e − j 2 π ( f + n Δ f ) t d t \int_{0}^{T}e^{j2\pi (f+m\Delta f)t}·e^{-j2\pi (f+n\Delta f)t}dt ∫0Tej2π(f+mΔf)t⋅e−j2π(f+nΔf)tdt
= ∫ 0 T e j 2 π ( f − f + m Δ f − n Δ f ) t d t =\int_{0}^{T}e^{j2\pi (f-f+m\Delta f-n\Delta f)t}dt =∫0Tej2π(f−f+mΔf−nΔf)tdt
= ∫ 0 T e j 2 π ( m − n ) Δ f t d t =\int_{0}^{T}e^{j2\pi (m-n)\Delta ft}dt =∫0Tej2π(m−n)Δftdt
在周期T内,积分结果为0
OFDM信号利用上述N个子载波进行传输,将待传输的QAM信号A(t)进行串并转换得到:

将串并转换得到的信号
A
0
A_0
A0,
A
1
A_1
A1,…,
A
N
A_N
AN 通过子载波传输:
s
o
f
d
m
=
A
0
(
t
)
e
j
2
π
(
f
+
0
⋅
Δ
f
)
t
+
A
1
(
t
)
e
j
2
π
(
f
+
1
⋅
Δ
f
)
t
+
.
.
.
+
A
N
(
t
)
e
j
2
π
(
f
+
N
⋅
Δ
f
)
t
s_{ofdm}=A_0(t)e^{j2\pi(f+0·\Delta f)t}+A_1(t)e^{j2\pi(f+1·\Delta f)t}+...+A_N(t)e^{j2\pi(f+N·\Delta f)t }
sofdm=A0(t)ej2π(f+0⋅Δf)t+A1(t)ej2π(f+1⋅Δf)t+...+AN(t)ej2π(f+N⋅Δf)t
上式称为一个OFDM符号,在“时频资源网格”中表示为:

每一行是一个时域单元,每一列是一个OFDM符号,橙色块表示第一个OFDM符号的第一个子载波。
此外,OFDM符号在频谱中表示为:

上图中共有4个子载波,任意两个子载波之间是正交的,即两两之间不会相互干扰,但随之会带来两个问题:
这两个问题来自知乎前沿通信: OFDM符号介绍 - 知乎 (zhihu.com)
-
子载波漂移
OFDM能很好的充分利用给定频率,但这个特点也带来了一个缺点,为了有效地工作,在满足正交条件下,子载波之间的间隔应该保持精确。如果子载波之间的间隔没有得到准确的维护,就会四处漂移。当每个子载波单独绘制时,不会看到太大的差异,但当所有这些子载波被归纳在一起时,就会注意到差异,如图:

实际上没有这样一个不存在频率漂移的环境。因此,当设计OFDM时,首先必须确定系统能够承受子载波频率漂移引起的信号失真的频率间隔。
-
抗干扰能力
对于两个相邻的OFDM符号在频域上可以表示为:

在理想情况下,这个信号没有问题,但是如果第一个符号稍微延迟一点会发生什么呢?在这种情况下,第一个符号的结束部分将溢出到下一个符号时间,并干扰下一个符号,如下所示:

这种不同符号之间的干扰称为符号间干扰(ISI:Inter Symbol Interference),有什么办法可以解决这个问题?你可能想防止信号延迟。但这是不可能的,因为无法控制无线信道本身(物理介质本身)。所以唯一的办法就是设计系统来处理这种情况。一个简单的解决方案是在符号之间设置一些时间间隔,这样即使一个符号被延迟,也不会溢出到下一个符号中,即:

有了这个Gap,系统在一定程度上可以容忍时延和码间干扰问题,但存在实际问题,“在这个Gap里放什么?”。什么都不放(比如关掉变速器)好吗?如果在间隙期间完全关闭信号,则会导致放大器出现问题。为了减少这个问题,我们从末端复制一部分信号并粘贴到这个Gap中。这个在开头加上前缀的复制部分称为“循环前缀
Cyclic Prefix”。
一般选择原始符号的结束部分来生成循环前缀,这有助于找到符号边界(符号的起点和终点)


于是构成了完整的OFDM符号(添加了CP)
【拓展】OFDM符号的长度
首先说一下4G的LTE标准下,一般子载波间隔为15kHz,带宽为20MHz。
则理论子载波数目 = 带宽 / 子载波间隔 = 20 MHz / 15 kHz ≈1333个,但是利用率过高会导致误差,因此规定只取其中1200个作为子载波
每个子载波带宽为15kHz,即有效带宽=15k Hz* 1200 = 18MHz(20M是因为有2M的过渡带宽)
为了FFT点数的需要,选择既包含1200个子载波,又要是2的n次方的正整数,所以一般一个OFDM符号包含2048个采样点
依次类推,15M带宽对应1024点,10M带宽对应1024点,5M带宽对应512点
由此引出5G NR标准,一般子载波间隔为30kHz,40MHz带宽
则理论子载波数目 = 带宽 / 子载波间隔 = 40 MHz / 30 kHz ≈1333个,但是5G NR协议中规定了最大子载波数目:

在30kHz,40MHz的情况下,子载波数目 N R B N_{RB} NRB的最大值为106, 106 ∗ 12 = 1272 106*12=1272 106∗12=1272,即协议中规定了只使用1272个子载波,选择2048采样点,多余的采样点用于保护间隔。
因此一个原始的不加CP前缀的OFDM符号的长度一般为2048点
(2)5G NR帧结构
5G NR的每一帧(frame)包含10个子帧(subframe),每个子帧包含多个时隙(slot),每个时隙一般包含14个OFDM符号(symbol)
首先来看第一句话:5G NR的每一帧(frame)包含10个子帧(subframe)

再来看第二句话:每个子帧包含多个时隙(slot)
在LTE系统中只有一种类型的子载波间隔,也就是15kHz;然而在NR系统中,有5种可选的子载波间隔,包括15kHz、30kHz、60kHz、120kHz、240kHz:

不同子载波间隔具有不同的时隙数,时隙数为 2 μ 2^{\mu} 2μ 个,例如子载波间隔为30kHz则所需时隙数为2
最后来看第三句话:每个时隙一般包含14个OFDM符号(symnol)
在每个时隙所包含的14个OFDM符号中,每个OFDM符号的CP长度是不一样的,可以由以下公式给出:

以子载波间隔为30kHz举例,一个时隙有14个OFDM符号,每个符号的CP长度如下:
| 160 | 144 | 144 | 144 | 144 | 144 | 144 | 160 | 144 | 144 | 144 | 144 | 144 | 144 |
|---|
所以一个时隙下CP总长度为160+144+144+…+144+144=2048
【综上】在系统带宽40MHz,子载波间隔为30kHz的情况下,计算每一帧的采样点数为:
OFDM符号的数目为: 1 ( f r a m e ) ∗ 10 ( s u b f r a m e ) ∗ 2 ( s l o t ) ∗ 14 ( s y m b o l ) = 280 ( s y m b o l ) 1(frame)*10(subframe)*2(slot)*14(symbol)=280(symbol) 1(frame)∗10(subframe)∗2(slot)∗14(symbol)=280(symbol)
原始OFDM长度为: 280 ( s y m b o l ) ∗ 2048 ( b i t ) = 573440 ( b i t ) 280(symbol)*2048(bit)=573440(bit) 280(symbol)∗2048(bit)=573440(bit)
CP长度为: 1 ( f r a m e ) ∗ 10 ( s u b f r a m e ) ∗ 2 ( s l o t ) ∗ 2048 ( b i t ) = 40960 ( b i t ) 1(frame)*10(subframe)*2(slot)*2048(bit)=40960(bit) 1(frame)∗10(subframe)∗2(slot)∗2048(bit)=40960(bit)
总长度为: 573440 ( b i t ) + 40960 ( b i t ) = 614400 ( b i t ) 573440(bit)+40960(bit)=614400(bit) 573440(bit)+40960(bit)=614400(bit)
记住614400这个数字,4.2章节会再次出现
4.2 信号读取
据大模型Gemini说,OAI 官方文档 《OAI Software Architecture Specification》 中的 第 6.2.2 节 规定了数据存储格式:
一个采样点占用4个字节(32bit),一个采样点其实是一个复数,其中实部占用2个字节,虚部占用2个字节

例如,我的5G空口信号(二进制文件)共有1帧数据,每帧包含614400个采样点,每个采样点包含4个字节,则占用内存大小为:
1
∗
614400
∗
4
=
2457600
b
y
t
e
1*614400*4=2457600 byte
1∗614400∗4=2457600byte

在代码中二进制表示为:
| I0(16bit) | Q0(16bit) | I1(16bit) | Q1(16bit) | I2(16bit) | Q2(16bit) | … |
|---|
那一共就存储了
2457600
(
b
y
t
e
)
÷
2
(
b
y
t
e
)
=
1228800
2457600(byte)\div2(byte)=1228800
2457600(byte)÷2(byte)=1228800 个实数,即下述IQ_data_array_int16数组的长度为1228800
fid = fopen(file_name,'r');
IQ_data_array_int16 = fread(fid,inf,'int16'); % 以int16类型将数据读入IQ_data_arry_int16中。
将获取到的数组实虚分离,奇数位为实数,偶数位为偶数:
Rx_temp_real = IQ_data_array_int16(1:2:length(IQ_data_array_int16));
Rx_temp_imag = IQ_data_array_int16(2:2:length(IQ_data_array_int16));
%转换为复数序列
Rx_data = Rx_temp_real+Rx_temp_imag*1i;
【注意】上述是基于理想采样,每一帧都包含数据信息,在实际传输过程中存在很多全0的冗余帧,这些帧不携带信息,需要删除,示例代码如下:
frame_length = 614400; % 以样点计,每帧长度包含多少复数【这是当前5G配置所决定的】
frame_length_in_bytes = frame_length*2; % 以实数计,每帧长度包含多少实数
total_frame = floor(length(IQ_data_array_int16)/frame_length_in_bytes); %计算有多少帧数据,即总实数/每帧包含的实数
N_frm = 0;
IQ_data_remove_starting_zeros = [];
frm_index = [];
for frm = 1:total_frame
frame = IQ_data_array_int16((frm-1)*frame_length_in_bytes+1:frm*frame_length_in_bytes);
if all(frame == 0)
else
N_frm = N_frm+1;
IQ_data_remove_starting_zeros((N_frm-1)*frame_length_in_bytes+1:N_frm*frame_length_in_bytes) = frame;
frm_index = [frm_index,frm];
end
end
原理是计算帧数后遍历每一帧,利用all()函数判断该帧是否全为0,若不全为0则将其添加进入新数组IQ_data_remove_starting_zeros
最后将其封装为函数process_data(file_name),完整代码如下:
function [Rx_data] = process_data(file_name)
%打开数据文件,32bit为一个数,包括实部和虚部(各16bit)
fid = fopen(file_name,'r');
IQ_data_array_int16 = fread(fid,inf,'int16'); % 以int16类型将数据读入IQ_data_arry_int16中。
% IQ_data_array的格式为: | I0(16bit) | Q0(16bit)| I1(16bit) | Q1(16bit)| I2(16bit) | Q2(16bit)|
frame_length = 614400; % 以样点计,每帧长度。这是当前5G配置所决定的。
frame_length_in_bytes = frame_length*2; % 以int16计,每帧长度
total_frame = floor(length(IQ_data_array_int16)/frame_length_in_bytes); %计算有多少帧数据
N_frm = 0;
IQ_data_remove_starting_zeros = [];
frm_index = [];
for frm = 1:total_frame
frame = IQ_data_array_int16((frm-1)*frame_length_in_bytes+1:frm*frame_length_in_bytes);
if all(frame == 0)
else
N_frm = N_frm+1;
IQ_data_remove_starting_zeros((N_frm-1)*frame_length_in_bytes+1:N_frm*frame_length_in_bytes) = frame;
frm_index = [frm_index,frm];
end
end
Rx_temp_real = IQ_data_remove_starting_zeros(1:2:length(IQ_data_remove_starting_zeros));
Rx_temp_imag = IQ_data_remove_starting_zeros(2:2:length(IQ_data_remove_starting_zeros));
%转换为复数序列
Rx_data = Rx_temp_real+Rx_temp_imag*1i;
fclose(fid);
end
4.3 PSS主信号同步
通过上述信号读取操作,可以获得一串比特流信号0100110…,但是这串比特流信号应该从哪里开始读取成为了新问题,我们选择的方法是在有效载荷之前为其添加一串同步序列:
本章的两个核心问题为: 使用什么样的序列呢? 如何来找到这个同步序列?

-
这里要引入一个概念:自相关函数。
自相关函数是描述信号在不同时刻之间的相关程度,相当于对信号本身做 “互相关”,表示同一序列不同时刻的相关程度。利用一些序列的良好的自相关和互相关特性可以将其应用于信号同步中。
m序列是由线性反馈的移位寄存器产生周期最长的序列,其具有很好的自相关性和互相关 性,5G NR中PSS同步信号使用的就是长度为127的m序列
因此,通过m序列进行同步序列的设计:
同步信号包括 主同步信号( PSS )和辅同步信号 ( SSS )。
NR设计了3个PSS序列,PSS序列的ID为 N i d ( 2 ) ∈ { 0 , 1 , 2 } N_{id}^{(2)}\in \{0,1,2\} Nid(2)∈{0,1,2},
每个PSS序列对应336个SSS序列,SSS序列的ID为 N i d ( 1 ) ∈ { 0 , 1 , 2...335 } N_{id}^{(1)}\in \{0,1,2...335\} Nid(1)∈{0,1,2...335}。
每个NR物理小区标识由PSS序列ID和SSS序列ID的组合共同确定,即 N I D ( c e l l ) = 3 ∗ N i d ( 1 ) + N i d ( 2 ) N_{ID}^{(cell)}=3*N_{id}^{(1)}+N_{id}^{(2)} NID(cell)=3∗Nid(1)+Nid(2)
于是,NR共支持1008个PCID,相比之下,4G的LTE的PCID数只有504个,NR可以提供更大的小区部署灵活性
PSS序列的同步主要分为两步:
-
在频域摆放PSS序列
这里再引入一个概念:NR同步广播块(synchronization signal/physical broadcast channel block,SS/PBCH block),一个SS/PBCH块在时域上占用4个OFDM符号,在频域上占用20个物理资源块(physical resource block,PRB),由 PSS、SSS 和 PBCH 三部分组成,如下图所示:
NR系统在下行同步过程中,PSS、SSS和PBCH必须同时发送, 即组成SS/PBCH块,在不至于引起混淆的情况下,也简称为NR同步信号块(synchronization signal block,SSB)。

观察可得几个要素:
- PSS、SSS和PBCH采用TDM(时分复用)的方式,一次性传输4个OFDM符号
- 一个SSB占用4个OFDM符号,其中PSS和SSS各占一个符号,PBCH占用两个符号,顺序为PSS-PBCH-SSS-PBCH。
- 一个SSB的带宽为20个PRB,其中PSS和SSS的带宽为12个PRB, PBCH的带宽为20个PRB。
- PBCH还占用了SSS所在OFDM符号的部分PRB
- PSS/SSS的中心频率和PBCH的中心频率对齐
上述是一个SSB,那么SSB在整个通信系统中的什么位置呢?

联系一下之前的知识点,每个时隙包含14个OFDM符号,SSB必须在特定位置才能传输,而不是随便挑一个OFDM符号就可以传输:

这个图里面分一下工:
- PSS和SSS: 用于辅助接收设备进行时间和频率同步。
- PBCH: 用于传输系统信息块,其中包括主要的系统配置信息,如系统带宽、小区ID等。
- PDCCH: 是传输控制信息的通道,用于指示接收设备如何解码PDSCH(Physical Downlink Shared Channel)上的数据,以及其他控制指令。
下面开始看真正的一个OFDM符号的2048个bit的位置:

每个小格是1个RB,1个RB代表12个RE,也就是代表12个子载波
但是,MATLAB里面的FFT变换之后低频和高频是如图所示的关系,故PSS位于OFDM 符号的两端,单独拿出来看:

所以真正的PSS序列的摆放方式应该是:
PSS序列的1-64位应该摆放在OFDM符号的1985位-2048位
PSS序列的65-127位应该摆放在OFDM符号的1-64位
用代码实现如下:
k_pss = 1984; N_symbol = 2048; % 下面生成一个PSS序列 pss_sequence = nrPSS(0); % 这里的参数可以选0,1,2,分别代表三个不同的PSS序列 % 生成长度为2048的OFDM信号 ofdm = zeros(N_symbol, 1); % 创建OFDM信号的初始空序列 ofdm(1985:end) = pss_sequence(1:64); % 序列最前后为PSS ofdm(1:63) = pss_sequence(65:end); -
将PSS分别与接收到的时域信号做相关,寻找最高峰
将设计好的OFDM信号与接收到的5G空口信号作互相关,最高峰出现在最匹配的地方,凭此定位我们所读接收的5G空口信号中PSS序列的位置
% 进行IFFT变换到时域与信号做互相关 time_domain_signal = ifft(ofdm, N_symbol); correlation_result = abs(xcorr(Rx_data, time_domain_signal));
因为共有三种PSS序列,接收端无法得知使用哪个PSS序列进行同步,所以需要通过for循环遍历这三种PSS序列,得到最精准的那一个:(PSS.m)
Rx_data = process_data('frame_20_231.dat');
N_symbol = 2048;
k_pss = 1984;
for i = 0:1:2
% 生成PSS序列摆放到频域上正确的位置
pss_sequence = nrPSS(i);
% 生成长度为2048的OFDM信号
ofdm = zeros(N_symbol, 1); % 创建OFDM信号的初始空序列
ofdm = fftshift(ofdm,N_symbol); % 做2048点FFT转换为频域
ofdm(k_pss+1:end) = pss_sequence(1:64); % 序列最前后为PSS
ofdm(1:63) = pss_sequence(65:end);
% 进行IFFT变换到时域与信号做互相关
time_domain_signal = ifft(ofdm, N_symbol);
correlation_result = abs(xcorr(Rx_data, time_domain_signal));
% 绘制相关图
subplot(1,3,i+1)
plot(correlation_result(614401:end));
title(['PSS 互相关,NiD2为', num2str(i)]);
xlabel('样本编号');
ylabel('相关值');
end
所绘制的图像如下:

目测即可发现与PSS(1)序列与读取到的5G空口信号的互相关性最显著,在421457处取得最大相关性,因此PSS序列选择PSS(1),也就是说 N i d ( 2 ) N_{id}^{(2)} Nid(2)的值为1,峰值索引为421457
4.4 SSS辅信号同步
最初提到,每个NR物理小区标识由PSS序列ID和SSS序列ID的组合共同确定,即 N I D ( c e l l ) = 3 ∗ N i d ( 1 ) + N i d ( 2 ) N_{ID}^{(cell)}=3*N_{id}^{(1)}+N_{id}^{(2)} NID(cell)=3∗Nid(1)+Nid(2) ,目前通过PSS同步得到了 N i d ( 2 ) N_{id}^{(2)} Nid(2)的值,还需要通过SSS同步得到 N i d ( 1 ) N_{id}^{(1)} Nid(1) 的值才能得到最终的小区 N I D ( c e l l ) N_{ID}^{(cell)} NID(cell) ,依旧分为两步:在频域放置SSS同步序列,作互相关寻找最高峰
-
在频域摆放SSS序列
由SSB的内部关系可知,PSS序列的起始位置与SSS序列的起始位置刚好差了2个OFDM符号:

因此由于前面已经得到了PSS相关峰的位置421457,因此SSS的位置应为421457+2*OFDM符号的长度(1个OFDM符号长度为2048+144)
与前面PSS的分布类似,SSS序列的分布也是分裂的,将分裂的SSS序列拼接在一起变成长度为127的序列:

SSS序列的1-64位应该摆放在OFDM符号的1985位-2048位
SSS序列的65-127位应该摆放在OFDM符号的1-64位
代码实现如下:
%确定symbol3的位置 Pss_peak = 421457; start = Pss_peak+2192*2; Symbol3 = Rx_data(start:start+2047); %得到SSS序列 SSS_1 = fft(Symbol3,2048); SSS_2(1:64) = SSS_1(1985:end); SSS_2(65:127)=SSS_1(1:63); -
互相关寻找最高峰,寻找最大值
将设计好的OFDM信号与接收到的5G空口信号作互相关,最高峰出现在最匹配的地方,凭此定位我们所读接收的5G空口信号中SSS序列的位置
for i = 0:1:335 % 生成SSS序列 sss_sequence = nrSSS(3*i+1); % 进行互相关 correlation_result = abs(xcorr(SSS_2,sss_sequence)); %找出最大值的小区号 if (max(correlation_result)>max_data) max_num = i; max_data = max(correlation_result); end end
完整代码如下(SSS.m):
Rx_data = process_data('frame_20_231.dat');
%确定symbol3的位置
Pss_peak = 421457;
start = Pss_peak+2192*2;
Symbol3 = Rx_data(start:start+2047);
%得到SSS序列
SSS_1 = fft(Symbol3,2048);
SSS_2(1:64) = SSS_1(1985:end);
SSS_2(65:127)=SSS_1(1:63);
max_data = 0;
max_num = 0;
for i = 0:1:335
% 生成SSS序列
sss_sequence = nrSSS(3*i+1);
% 进行互相关
correlation_result = abs(xcorr(SSS_2,sss_sequence));
%找出最大值的小区号
if (max(correlation_result)>max_data)
max_num = i;
max_data = max(correlation_result);
end
end
disp(max_num)
disp(max_data)
sss_sequence = nrSSS(301);
% 进行互相关
correlation_result = abs(xcorr(SSS_2,sss_sequence));
plot(correlation_result);
xlim([1, 255]);
输出与图像如下:

运行代码输出的i值为100,由上图可以看出,即 N i d ( 1 ) N_{id}^{(1)} Nid(1) 取100时的相关性最强,取其作为 N i d ( 1 ) N_{id}^{(1)} Nid(1)的最终取值,则 N I D ( c e l l ) = 3 ∗ N i d ( 1 ) + N i d ( 2 ) = 300 + 1 = 301 N_{ID}^{(cell)}=3*N_{id}^{(1)}+N_{id}^{(2)}=300+1=301 NID(cell)=3∗Nid(1)+Nid(2)=300+1=301
4.5 PBCH信道估计
在通信过程中,真正传递的信息存储在PBCH部分,终端在接入NR系统时,首先检测PSS 和SSS 以获得下行时频同步以及物理小区标识,然后对PBCH进行解 码,PBCH中包含MIB和其他与SSB传输时间有关的信息,MIB中携带终端接入NR系统所需要的最小系统信息的一部分。
但是PBCH信号在通过信道传输过程中会产生不可预测的波动,因此,为了更好地对PBCH进行解调,一般会向PBCH中添加解调参考信号DM-RS,通过DM-RS信号模拟信道,计算出在信号传输过程中的损耗,将此模拟信道的内容补偿给合并后的PBCH信号,即可恢复最初传输的PBCH信号。
(1)获取PBCH序列
与PSS和SSS同理,在摆放PBCH的过程中也需要考虑MATLAB中的矩阵特点:

PSS有结论:
PSS序列的1-64位应该摆放在OFDM符号的1985位-2048位
PSS序列的65-127位应该摆放在OFDM符号的1-64位
-
以PBCH的第一部分(OFDM symbol2)为例,则有:
PBCH序列的1-120位应该来源于OFDM符号的1929-2048位
PBCH序列的121-240位应该来源于OFDM符号的1-120位
加起来长度一共是240位,刚好对应于前面讲到的SSS带宽为20个RB,每个RB包含12个RE,每个RE是一个子载波,共计240个子载波
-
对于PBCH的第二部分(OFDM symbol3),则有:
PBCH序列的241-288位来源于OFDM符号的1929-1976位
PBCH序列的289-336位来源于OFDM符号的73-120位
加起来长度是96位,刚好对应OFDM symbol3中PBCH占据了最开始的4个RB和最后的4个RB,共8个RB,即96个RE
-
对于PBCH的第三部分,与第一部分排列相同:
PBCH序列的337-456位应该来源于OFDM符号的1929-2048位
PBCH序列的457-576位应该来源于OFDM符号的1-120位
通过上述操作拼凑好了PBCH序列的总共576位,代码实现如下:
k = 1984; %PSS序列的起始位置
k1 = k-56; %SSB的起始位置
N_symbol = 2048; %OFDM符号长度
N_cp = 144; %OFDM的CP长度
% 计算符号序列的索引
symbol2_index = pss_peak + (N_symbol + N_cp);
symbol3_index = pss_peak + (N_symbol + N_cp) * 2;
symbol4_index = pss_peak + (N_symbol + N_cp) * 3;
% 提取符号序列 s2, s3, s4
symbol234 = [Rx_data_frm(symbol2_index:symbol2_index+N_symbol).', ...
Rx_data_frm(symbol3_index:symbol3_index+N_symbol).', ...
Rx_data_frm(symbol4_index:symbol4_index+N_symbol).'];
% 变换到频域
fft_symbol234 = fft(symbol234, 2048);
% 根据OFDM符号结构来构建PBCH
PBCH(1:240) = [fft_symbol234(k1+1:end,1);fft_symbol234(1:240-N_symbol+k1,1)];
PBCH(241:288) = fft_symbol234(k1+1:k1+48,2);
PBCH(289:336) = fft_symbol234(240-2048+k1-48+1:240-2048+k1,2);
PBCH(337:576) = [fft_symbol234(k1+1:2048,3); fft_symbol234(1:240-N_symbol+k1,3)];
(2)提取PBCH中的DMRS序列
那么首先来介绍一下DM-RS信号:
DMRS(DeModulation Reference Signal)是解调参考信号,在数据传输过程中,用于上下行数据解调。
简而言之,DMRS是一种特殊的参考信号,是发送端事先设计好的已知信号,发送端和接收端都能够知道它的结构和位置,通常在无线通信系统中用于信道估计目的。此外,DMRS信号在频域上与数据信号正交,这意味着它与数据信号之间相互独立,可以独立估计其信道响应。
在使用时,首先提取到发送端的DMRS信号,通过dmrs模拟信道对DMRS信号造成的影响,最终接收端收到的信道响应信号h。对结果进行分段线性插值操作得到H,获得的估计值可以用于补偿接收到的信号,消除信道引起的失真和衰落,从而提高信号恢复的准确性和可靠性。
在NR系统中,有两种DMRS设计,分别是前置DMRS和附加DMRS,可参见:NR DMRS信号介绍 (baidu.com)
PBCH的DM-RS 在SS/PBCH块的1、2、3号OFDM符号上均匀间隔放置,每4个子载波上放置一个,一个 RB上有3个DM-RS。
PBCH的DM-RS的位置还与频域偏移有关,频域偏移由 PCID确定,表示为 v = N I D ( c e l l ) m o d 4 v=N_{ID}^{(cell)}mod4 v=NID(cell)mod4,有4种可能的偏移值,如下图:

通过4.4章中求得小区编号 N I D ( c e l l ) = 301 N_{ID}^{(cell)}=301 NID(cell)=301 ,则 v = 301 m o d 4 = 1 v=301mod4=1 v=301mod4=1,因此DM-RS出现的位置在 2 , 6 , 8 , 12... 2,6,8,12... 2,6,8,12...
通过代码实现:
data_index = [];
dmrs_index = [];
for i = 1:576
if mod(i,4)~=2
data_index = [data_index,i]; %把i放到PBCH数据数组
else
dmrs_index = [dmrs_index,i]; %把i放到DMRS数组
end
end
打印一下dmrs_index和data_index:
>> disp(dmrs_index)
disp(data_index)
2 6 10 14 18 22 26 30 34 38 42 46 50 54 % DMRS数组
1 3 4 5 7 8 9 11 12 13 15 16 17 19 % PBCH数据数组
将PBCH序列中dmrs_index对应的数字取出即得到DM-RS信号
PBCH_dmrs = PBCH(dmrs_index);
(3)信道均衡
通过(2)我得到了实际读取5G空口信号中所传递PBCH信息中的DM-RS信号,这个信号是经历了信道干扰的。之前提到DM-RS序列是一个收发双方都已知的信号,也就是说收端其实已知DM-RS信号的标准形式,将标准形式与我所拼凑得到的真实的DM-RS信号进行比对,就可以得到信道对我的DM-RS信号产生了什么影响,那么信道对其他所传输的PBCH信号一定也会出现相同的影响,只需对这个影响做反向补偿就可以接收到真实的未受信道干扰的PBCH数据。
那么接收端是如何得知DM-RS信号的标准格式的呢?
DM-RS仅与 N I D ( c e l l ) N_{ID}^{(cell)} NID(cell)和 SSB index有关, N I D ( c e l l ) N_{ID}^{(cell)} NID(cell)即小区ID,是在4.4经过SSS辅信号同步得到的301,SSB index是指所传输内容这一帧中的第几个SSB,由于本实验中每一帧只有一个SSB,因此SSB index为0
有了上述两个数据即可以生成标准的DM-RS信号;
NiD = 301;
ssb_index = 0;
dmrs = nrPBCHDMRS(NiD,ssb_index);
下面以标准DSRM信号dmrs为分母,读取的真实DMRS信号PBCH_dmrs为分子,即PBCH_dmrs中的每个元素除以dmrs中的对应元素,得到系数矩阵h:
h = PBCH_dmrs ./ dmrs;
对h进行线性插值,使其样点数增多,可以均衡其他PBCH数据:
H = interp1(dmrs_index', h, data_index', 'linear', 'extrap'); % 分段线性插值
对PBCH信号的每个点作均衡,同时都除以这个计算得到的系数矩阵:
PBCH_data_eq = PBCH(data_index) ./ H;
画图感受一下均衡前后的星座图变化:
scatterplot(PBCH(data_index));
title('QPSK 星座图(均衡前)');
scatterplot(PBCH_data_eq);
title('QPSK 星座图(均衡后)');

可见,均衡前各个相位均有分量,均衡补偿后体现出QPSK特有的四相位分布
4.6 PBCH解调
这一部分是最终课程的大作业,每个人所分配的5G空口信号都不同,得到的最终答案也不同,很开放性,没有一个严格的评判标准也没有老师的讲解,所以我也不确定我的理解是否正确…欢迎大家批评指正
在PBCH信息的传递过程中,经常用到信道编码BCH(Bose-Chaudhuri-Hocquenghem),所传递的信息中包含校验位,BCH解码是纠正误差的过程。
接收到码字后,将其与生成多项式做模2除法。如果余数为0,则说明没有错误;否则,余数所对应的位置上的比特翻转,即可得到正确的信息比特流。
与BCH编码技术有关的内容过多,这里就不展开说啦,经过解码后即可提取到PBCH所传递的MIB数据:
% 解码PBCH比特
pbchBits = nrPBCHDecode(data_eq.', NiD, 0);
% 参数设置
Lmax = 8; % SSB Burst 最大长度
polarListLength = 8;
% BCH解码
[~, crcBCH, trblk, sfn4lsb, nHalfFrame, msbidxoffset] = ...
nrBCHDecode(pbchBits, polarListLength, Lmax, NiD);
% 从解码结果中提取MIB(Master Information Block)
mib32 = [trblk; sfn4lsb; 0; 0; 0; 0];
t1 = reshape(mib32, 4, [])';
t2 = bi2de(t1, 'left-msb');
message = dec2hex(t2); % 32bit信息,用十六进制表示
% 显示解码结果
disp("message: " + message');
最终得到的message解码结果为:
message: 35060680
这是一个16进制数,对应32bit,这32bit携带的什么信息呢?
| 来源 | 参数 | 比特数 | 说明 |
|---|---|---|---|
| MIB | systemFrameNumber(MSB) | 6 | SFN的 6 个最高有效位 |
| subCarrierSpacingCommon | 1 | 初始接入、寻呼和广播系统消息 SIB1、Msg2、Msg4 的子载波间隔,取值为60kHz或120kHz | |
| ssb-SubcarrierOffset | 4 | SSB 子载波偏移 k S S B k_{SSB} kSSB | |
| dmrs-TypeA-Position | 1 | PDSCH SIB1的第一个DM-RS在时隙内开始的符号位置 | |
| pdcch-ConfigSIB1 | 8 | 决定公共 CORESET、公共搜索空间和必要 PDCCH 参数的配置 | |
| cellBarred | 1 | 指示小区是否禁止 UE 接入 | |
| intraFreqReselection | 1 | 控制对同频小区的小区重选 | |
| spare | 1 | 保留位 | |
| 其他 | messageClassExtension | 1 | 消息扩展备用 |
| 物理层 | LSB | 4 | SFN的4个最低有效位 |
| 半帧指示位 | 1 | 半帧指示位 | |
| MSB | 3 | SS/PBCH 块索引的3个最高有效位 | |
| 合计 | 32 | 来自MIB的24位+来自物理层的8位 |
对应上述表格,结合解调PBCH得到的32bit数据,绘制一张译码表如下:
注:(3506 0680) = (0011 0101 0000 0110 0000 0000 0100 0000)
| 参数 | 比特数 | 解调数据 | 说明 |
|---|---|---|---|
| systemFrameNumber(MSB) | 6 | 0011 01 | SFN的前6位为:001101 |
| subCarrierSpacingCommon | 1 | 0 | SIB1、Msg2、Msg4 的子载波间隔为60kHz |
| ssb-SubcarrierOffset | 4 | 1000 | 从公共资源块(CRB) N C R B S S B N_{CRB}^{SSB} NCRBSSB的第0个子载波到SSB的第0个子载波之间,偏移了8个子载波数量 |
| dmrs-TypeA-Position | 1 | 0 | 一个时隙内的OFDM符号为2,即第3个OFDM符号 |
| pdcch-ConfigSIB1 | 8 | 0110 0000 | 参数配置 |
| cellBarred | 1 | 0 | 小区不禁止 UE 接入 |
| intraFreqReselection | 1 | 0 | cellBarred为0,则该位无效 |
| spare | 1 | 0 | 保留位 |
| messageClassExtension | 1 | 0 | 消息扩展备用,未使用 |
| LSB | 4 | 0100 | SFN的后4位为:0100 |
| 半帧指示位 | 1 | 0 | 半帧指示位 |
| MSB | 3 | 000 | SS/PBCH 块索引的3个最高有效位 |
因此可以破译出的关键信息如下:
10 位系统帧号SNF为 00 1101 0100
其余破译出的信息都在上述表格中对应呈现

















 2483
2483

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









