







目录
聚类评估:轮廓系数(Silhouette Coefficient )
一、聚类算法原理
对于"监督学习"(supervised learning),其训练样本是带有标记信息的,并且监督学习的目的是:对带有标记的数据集进行模型学习,从而便于对新的样本进行分类。而在“无监督学习”(unsupervised learning)中,训练样本的标记信息是未知的,目标是通过对无标记训练样本的学习来揭示数据的内在性质及规律,为进一步的数据分析提供基础。对于无监督学习,应用最广的便是"聚类"(clustering)。
二、K-MEANS算法
2.1 K-MEANS算法基本介绍
kmeans算法又名k均值算法。其算法思想大致为:先从样本集中随机选取 kk 个样本作为簇中心,并计算所有样本与这 kk 个“簇中心”的距离,对于每一个样本,将其划分到与其距离最近的“簇中心”所在的簇中,对于新的簇计算各个簇的新的“簇中心”。
根据以上描述,我们大致可以猜测到实现kmeans算法的主要三点:
(1)簇个数 kk 的选择
(2)各个样本点到“簇中心”的距离
(3)根据新划分的簇,更新“簇中心”
基本概念:
要得到簇的个数,需要指定K值
距离的度量:常用欧几里得距离和余弦相似度(先标准化)
优化目标:
2.2 K-MEANS算法过程
工作流程:
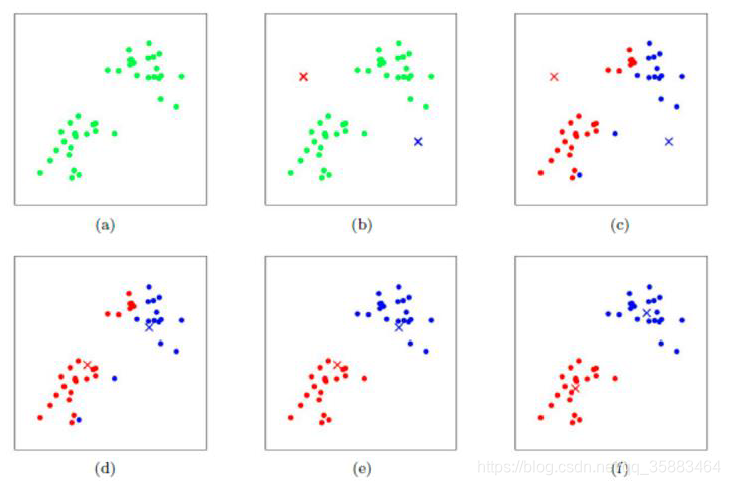

优势:
简单,快速,适合常规数据集
劣势:
复杂度与样本呈线性关系
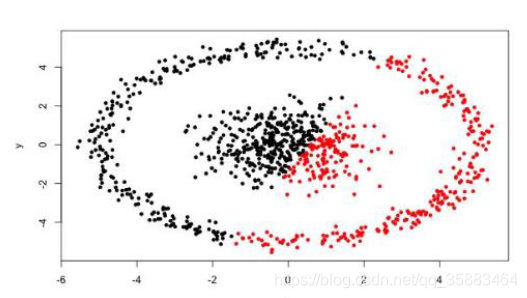
很难发现任意形状的簇
例如:
三、DBSCAN算法定义
DBSCAN(Density-Based
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









