







二.优化
1.不丢失数据ack=-1(是生产端的设置)
当Producer向Leader发送消息时,可以通过ack的值来设置可靠性级别。
1)1(默认)
意味着ISR中的Leader已成功收到消息并且Producer得到Leader收到消息的确认。如果ISR中的副本数还没有来得及拉取数据就宕机了,则会丢失数据。
2)0
意味着Producer无需等待来自Broker的确认而继续发送下一批消息,此时数据传输效率最高,但是数据可靠性最低。
3)-1(all)
Producer需要等待ISR中所有的Replicas都成功收到消息并得到它们收到消息的确认,在副本数为1的情况下,只有一个Leader,等同于ack=1,这种情况下Leader挂了,会丢数据。在副本数>1的情况下,不会丢失数据,但数据有可能会重复。
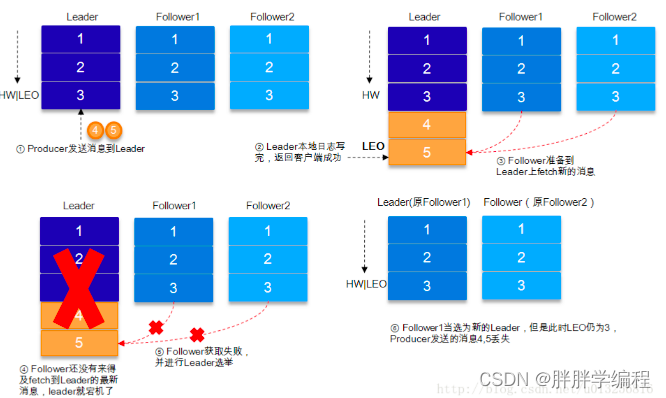
a)副本数>1的情况下,数据发送到Leader,ISR的Follower全部完成数据同步后,Leader挂掉,选举出新的Leader,数据不会丢失。
b)副本数>1的情况下,数据发送到Leader后,Follower1同步完成,Follower尚未同步,此时Leader挂掉,Producer端会返回异常,Producer端会重新发送数据,数据可能会重复。
3)设置方法
props.put("acks", "all");2.幂等(exactly once)(对生产端和消费端的设置)
1)什么是幂等
幂等性是指:无论执行多少次同样的计算。结果都是相同的,即一条命令,任意多次执行所产生的影响均与一次执行的影响相同。
2)Producer的幂等
[1]说明
幂等保证Producer在一个Partition内消息精准一次。
1)最多一次(at most once):消息可能会丢失,但绝对不会重复。
2)至少一次(at least once):消息不会丢失,但有可能会重复。
3)精准一次(exactly once):消息不会丢失,也不会重复。
[2]设置方法:props.put("enable.idempotence",true)
[3]kafka producer如何实现幂等
它在底层设计框架引入了ProducerID和SequenceNumber。
ProducerID:在每个新的Producer初始化时,会分配唯一的ProducerID。
SequenceNumber:对每个ProducerID,Producer发送数据的每个Topic的Partition都对应一个从0开始单调递增SequenceNumber值,通过该值进行唯一处理。
3)消费者的幂等
有唯一的id,如在mysql就是主键,在埋点中可以设置一个唯一id。
3.数据丢失与重复
0)说明
消费消息是两个环节:
【1】生产者发送消息到Broker,此时要确保消息发送到了Broker
【2】消费者消费消息,可以使用两种方式:自动提交offset和手动提交offset
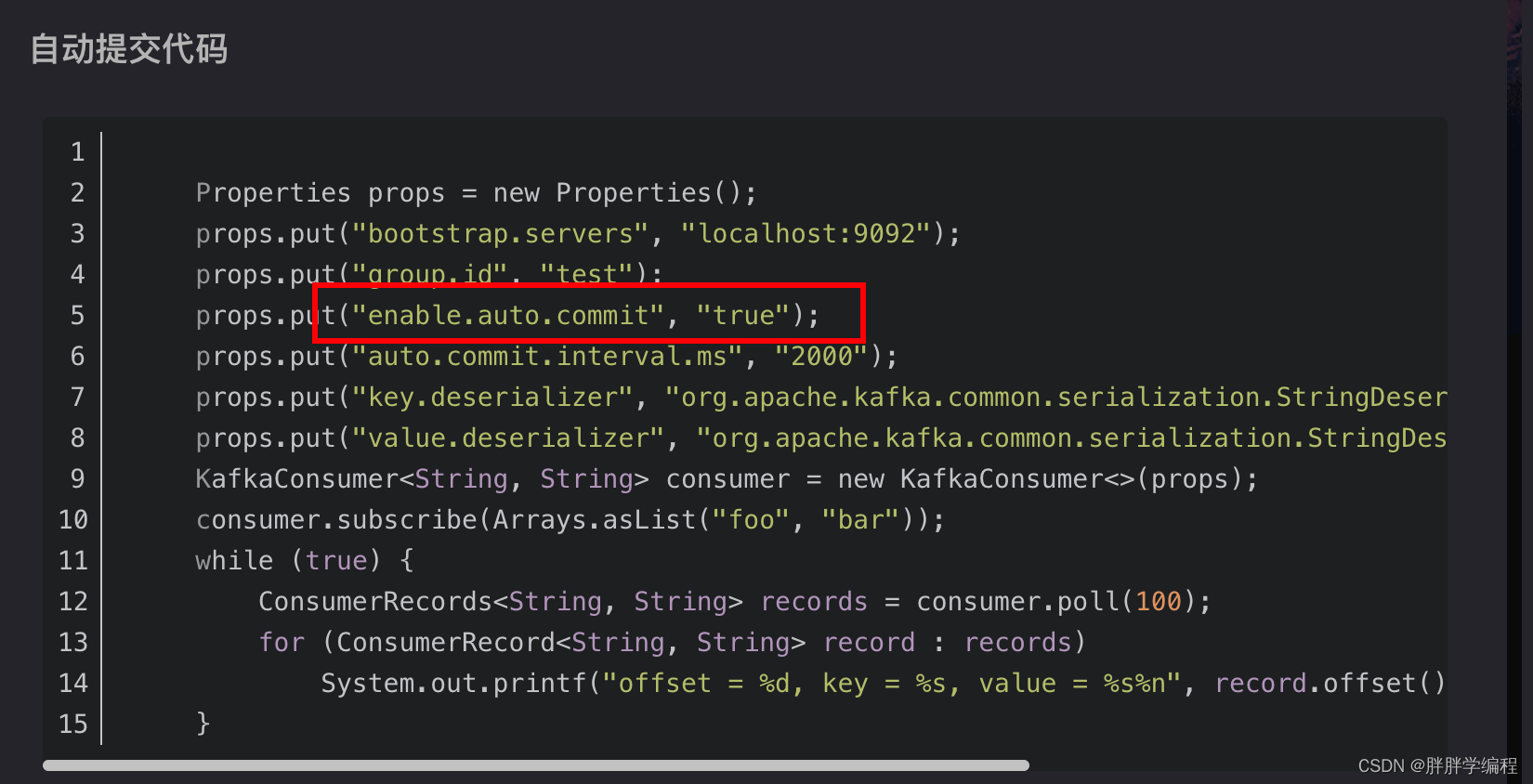

自动提交可能会造成消费未处理进程中断,导致丢失数据。所以要数据不丢的话就使用手动提交。
消费的消息是批处理的方式,在的代码中是1S处理一次,这种处理方式是实时的。
还可以离线定时处理,比如一小时处理一次,这种方式偏移量是由系统自己创建的topic里维护的偏移量,老版本是在zookeeper中维护的偏移量。
1)重复
【1】生产端
a)fume将数据发送到kafka,flume已经发送,但是但是offset没提交,flume就挂掉了。
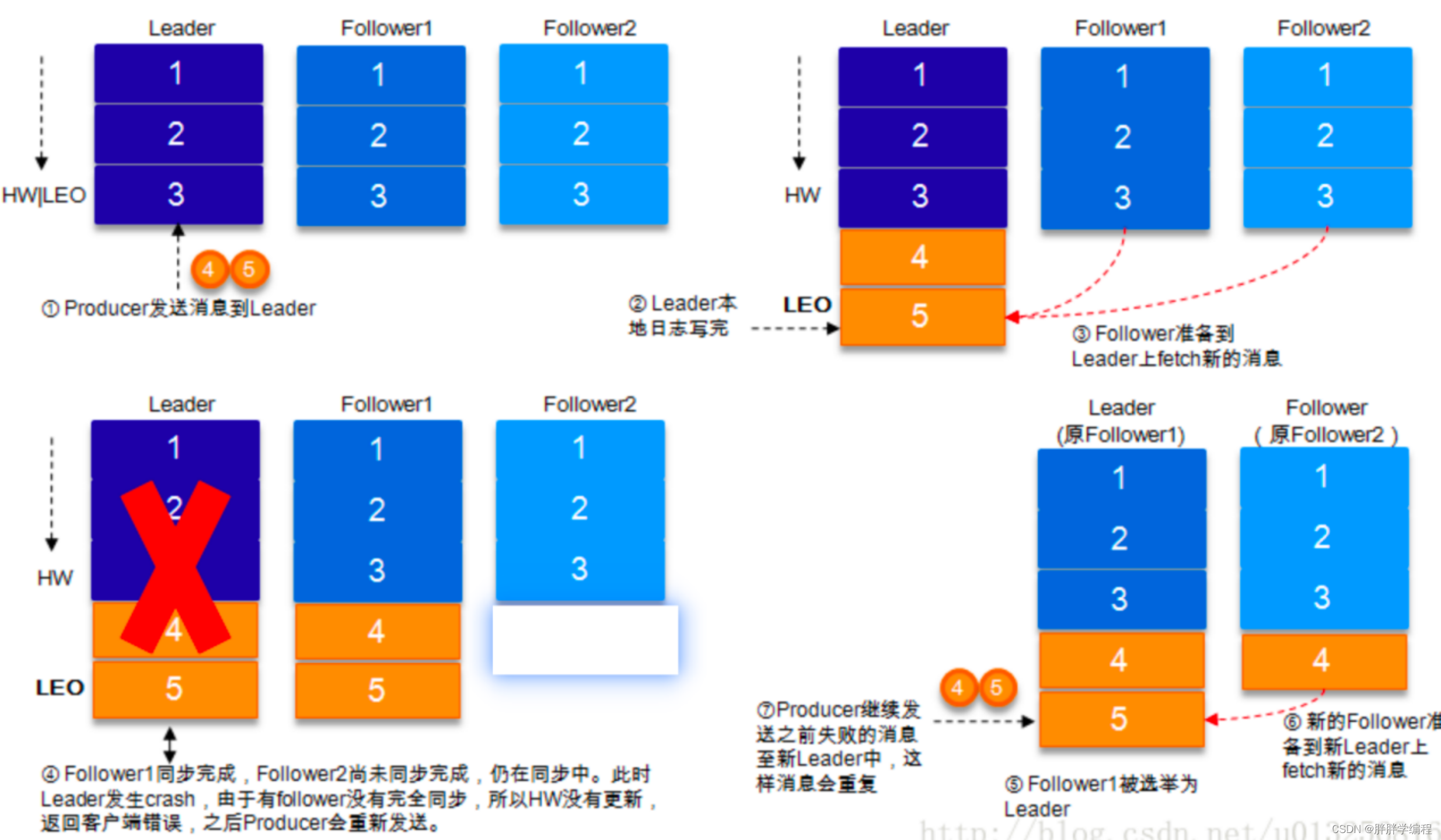
b)kafka消费消息,ack=-1时,Leader挂掉,和上面图的情况相同。比如:通常会遇到消费者的数据处理很耗时,导致超过了kafka的session timeout时间(默认30s),那么该Partition重新选择新的Leader,此时会有一定几率offset没提交,会导致重平衡后数据重复。(大多数情况)。
解决方案:
幂等+ack=-1+事务(不成功可以回滚)、下游处理,如hive dwd
【2】消费端
设置为手动提交,消费者在消费了消息后,消费者挂了,还未提交offset。
解决方案:在dwd层清洗、有唯一的id,如在mysql就是主键,在埋点中可以设置一个唯一id。这样的话就算是聚合值也不怕。
2)丢失
原因:在消费Kafka数据时,设置offset为自动定时提交,数据还在内存中未处理,此时刚好把线程kill掉,那么offset已经提交,但是数据未处理,导致这部分内存中的数据丢失。
解决方案:改为手动提交。
4.kafka参数优化
1)Broker参数配置(server.properties)
1.日志的保留策略设置
log.retention.hours=72 #保留3天,也可以缩短
2.replica副本
default.replication.factor=1 #设置副本1个
3.网络通信延时
replica.socket.timeout.ms=30000 #当集群之间的网络不稳定时,调大参数
replica.log.time.max.ms=600000 #follower落后leader 10min,会踢出ISR集合.
#如果网络不好,或者kafka压力较大,会出现节点从ISR到OSR再到ISR,然后会频繁复制副本,
#导致集群压力更大,此时可以调大该参数.2)Producer(producer.properties)
compression.type=none
#可选: gzip snappy lz4
#默认发送不进行压缩,推荐配置一种合适的压缩算法,可以大幅度的减缓网络压力和
#Broker的存储压力.3)kafka内存调整(kafka-server-start.sh)
export KAFKA_HEAP_OPTS="-Xms4g -Xmx4g"kafka对于消息体大小默认为每条消息最大为1M,但生产中,常常出现一条消息大于1M,如果不对kafka进行配置,则会出现生产者无法将消息推送到kafka或者消费者无法去消费kafka里面的数据,这时我们就要对kafka进行以下配置:server.properties
replica.fetch.max.bytes: 1048576
#broker可复制消息的最大字节数,默认为1M
messgae.max.bytes: 1000012
#kafka会接收单个消息size的最大限制,默认为1M左右
#注意:message.max.bytes必须小于等于replica.fetch.max.bytes
#否则就会导致replica之间数据同步失败5.kafka过期数据清理
保证数据没有被引用(没人消费它)
日志清理保存的策略只有delete和compact两种
log.cleanyp.policy=delete
#启用删除策略
log.cleanup.policy=compact
#启用压缩策略1)delete(直接删除过期数据)
2)compact
将数据压缩,只保留每个key最后一个版本的数据。
在实时计算下,一些数据可能经过了一天的聚合,要重复算需要花费很多时间,此时使用压缩策略,可以直接从kafka中读取。
6按时间消费数据
Map<TopicPartition, OffsetAndTimestamp> startOffsetMap =
KafkaUtil.fetchOffsetsWithTimestamp(topic, sTime, kafkaProp);7.kafka消费者角度考虑是拉取数据还是推送数据
拉取数据
8.kafka中的数据是有序的吗
单分区:分区内有序
多分区:各分区内有序,分区间无序
9.kafka消息数据积压、kafka消费能力不足怎么处理?
1)如果是kafka消费能力不足,则可以考虑增加Topic的分区数,并且同时提升消费者组的消费者数量,消费者数=分区数(两者缺一不可)。
2)如果是下游的数据处理不及时,提高每批次拉取的数量,批次拉取数据过少(拉取数据/处理时间<生产速度),使处理的数据小于生产的数据,也会造成数据积压。















 725
725











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









