






Elasticsearch在进行数据装载时遇见的问题及解决方案
1.业务场景及基本技术方案
在客户画像项目上,需要用到ES进行客户标签筛选查询。标签源数据存储在hive中,项目初期大约有亿级客户、不到1000个标签。
数据量大,使用Java编写sql读取hive数据导入ES或者采用ES-Hadoop 建立映射表导入ES效率都过于低下,
故选择MapReduce直接读取hive存储在hdfs上的源文件,批量导入ES。系统逻辑关系如下图
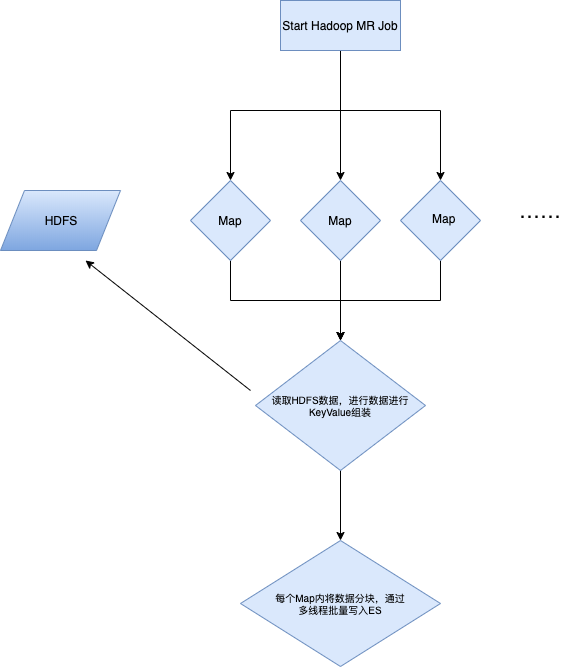
2.导入过程中遇到的问题
1.初期投产经过ES参数、JVM调优之后,,导入1亿+、近1000列数据耗时1.5个小时
2.随着业务发展,标签数据逐渐增长到了1600+列,此时发现,ES对于列数的扩张支持并不是线性的,而是指数性增长。在1600+列时,写入时间已经拉长到了16个小时,此时业务基本无法使用。
3.针对问题的排查思路
在写入ES过程通过
curl ip:port/_cat/thread_pool?v
观察发现,在整个写入过程中,大部分时间ES集群处理请求并不均衡,多数节点空闲,只有少数几个节点在正常工作。但写入完成后,通过curl ip:port/_cat/shards/{indexName}发现每个shard数据分布相差不大。同时写入过程中,所有机器CPU、IO、内存、GC压力并不大。
通过hotThread命令以及jstack查看线程日志发现,此时大量耗时请求卡在Lucene updateIndex方法,但是程序只有insert请求,并没有发送update请求。通过排查ES Java客户端源码发现,在ES Java sdk中ES有两个超时参数,一个为Http超时时间,一个为客户端超时时间。若客户端超时时间大于Http超时时间,且此次写入请求没有及时响应,那么ES客户端会自动触发重试操作。但这次请求可能已经在Queue中排队等候处理,若再次发送,则触发了ES的update操作。
通过修改超时时间,此时写入程序优化到了8小时。但仍不满足业务需求,此时需要对上文中,描述ES只能满足数据请求最终一致性,不能保证实时一致性的问题进行修改。
在ES中,一次写入请求的完整流程为:客户端发送给任意服务器,服务器通过 hash(docID/routing)%shards count 算出这部分数据应该分发在哪个机器上,将这批写入请求发送给这台机器。
通过 hash(docId/routing)%shards count=shardId这个公式,我们只要知道ShardId,就可以动态指定routing值,从而达到数据制定分配的目的。所以我们在写入过程中,每次发送curl ip:port/_cat/thread_pool?v 请求动态去获取ES机器的写入队列忙碌情况,找到压力最小的机器。将这批数据的routing值任意指向这台机器上shard,并且将请求直接发送给这台机器。就可以达到数据请求指定分发给压力最小的机器的目的,从而达到负载均衡性(和Least Connections思想一致)。
在调整过负载策略后,2000+列、近2亿行,2.5-3个小时即可将数据完全写入。
4.ES服务器的参数调整和程序优化明细
ES服务器资源为内存128G,32C,12台物理机,每台挂载10块盘
ES服务器集群单独拿出两台机器用于部署4个master节点,其余10台机器做Data节点,所有请求指向data节点,禁止客户端直连master
yarn集群为32C,每个map分配4G内存
- ES服务器参数调整
#bulk的写入线程数,可控制CPU使用率
thread_pool.bulk.size: 12
#数据在节点间传输最大带宽
indices.recovery.max_bytes_per_sec: 200mb
#bulk线程队列
thread_pool.bulk.queue_size: 1000
#索引写入buffer的内存占比
indices.memory.index_buffer_size: 20%
JVM设置:
-Xms64g -Xmx64g #JVM内存设置
-XX:+UseG1GC
-XX:MaxGCPauseMillis=150
#事务日志刷新到磁盘的机制;依据sync_interval参数(默认5秒)控制写入磁盘
index.translog.durability: async
#事务日志缓冲区大小,可控制内存、CPU使用率
index.translog.flush_threshold_size: 2048mb
#写入完成后,改为1
index.number_of_replicas: 0
#写入完成后,改为1s
index.refresh_interval: 300s
#和硬盘个数保持一致;60
index.number_of_shards: 60
- 程序调整
1.
对HDFS上的小文件进行合并,降低Map数
2.
#设置最小Map数据量,作用是降低Map数
OrcInputFormat.setMinInputSplitSize(job,1024*1024*10L);
3.
降低每次读取HDFS数据的条数,采用多次小批量读取的方式。
4.
对程序所有使用到的List、Map进行预扩容,对程序中对容器调用get、size等方法只调用一次,赋值给变量,用空间换取时间。
对所有Tmp变量都使用WeakReference,帮助GC进行回收,尽可能减少FullGC次数。















 1301
1301











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









