









 本文提出一种轻量级(frame-based)人脸表情识别(FER)模型,结合CNN与GRU,有效利用时间信息,提升跨域性能。模型在CK+与Oulu-CASIA数据集上表现优异,同时提出光照增强方案解决过拟合问题。
本文提出一种轻量级(frame-based)人脸表情识别(FER)模型,结合CNN与GRU,有效利用时间信息,提升跨域性能。模型在CK+与Oulu-CASIA数据集上表现优异,同时提出光照增强方案解决过拟合问题。
FER方法有两种,一是image-based方法;二是sequence-based方法,分别对应于静态图像数据集(eg:FER2013)和视频序列数据集(eg:CK+、Oulu-CASIA)。
论文概述
该论文来自2018年CVPR:
1.提出一种轻量型(compact)frame-based人脸表情识别模型,在性能不逊色state-of-the-art方法的同时参数量更少;
2.提出frame-to-sequence方法,通过门控循环单元(GRU)来使用时间信息;
3.收集三个不同场景的数据集,用来评估跨域性能;
4.提出光照增强方案以解决通过混合数据训练深度网络的过拟合问题,提高模型鲁棒性
模型介绍
frame-basedFER框架总体结构如下:
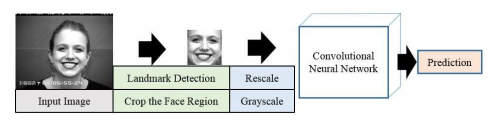
由此可见,整体框架分为两个部分:人脸预处理和CNN分类模型。其中,人脸预处理使用IntraFace检测出的人脸特征点裁剪人脸区域;CNN分类模型结构如下:

模型由两层卷积层(每层卷积层由两个卷积层构成)和两个全连接层构成,卷积核大小均为5X5,输入图片大小为96X96。
模型设计原因:
1.简单网络(plain model)能够在FRR任务中取得不错效果;
2.使用大卷积核(5X5)保证神经元拥有更大感受野;感受野相关内容参见:我的博客
3.大幅减少全连接层神经元数量,使得网络参数量大幅减少(实验结果证明只要合理设计感受野,人脸表情特征可以通过轻量型网络进行学习)。
frame-to-sequence方法:CNNs+RNNs
图片序列人脸表情数据集通常从中性表情开始,逐渐过渡到峰值表情。
将frame-basedFER预训练模型当作一个特征提取器(feature extractor),然后使用特征提取器得到图片序列对应概率分布,将一系列概率分布作为门控循环神经网络的输入,frame-to-sequence模型由一个GRU(128)和一个softmax层组成。
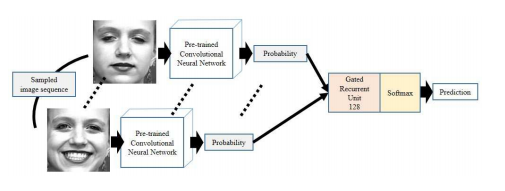
优点:
1.适用于不同场景,泛化能力强;
2.不容易过拟合,训练frame-based模型,可以将图片进行数据增强,这是sequence-base方法无法做到的;
3.使用时间(temporal)信息,提高识别准确率。
数据集介绍:
1.CK+(the Extended Cohn-Kanade database):由327个带标签的图片序列(7种表情)构成;
2.Oulu-CASIA:由480张带标签的图片序列(6种表情)构成。
训练细节:
权重初始化:xavier;学习率:0.001;momentum:0.9;optimizer:ADAM;10折交叉验证。
实验结果:
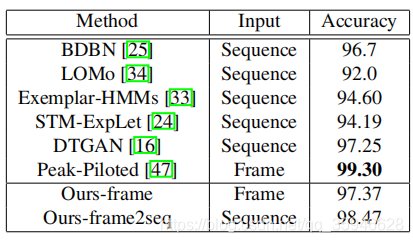
1.CK+数据集效果对比:
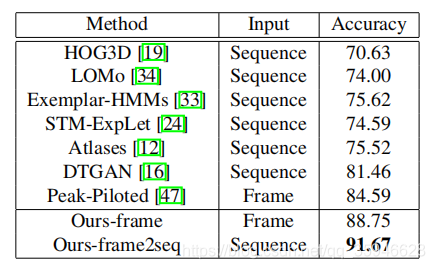
2.Oulu-CASIA数据集效果对比:

















01-02
 3827
3827
3827
08-28
3342
3342
08-27
1777
1777
03-13
765
765
12-09
2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









