







数据结构
追加型数据库和哈希索引
数据库最简单的形式,是追加型的方式:
- 写入数据直接追加到文件尾部,
O(1)复杂度 - 读取数据从文件头遍历,获取最新的数据
这种数据库,没有删除操作,所有的数据都是追加性质的,这也是日志形式的数据库。
为了改善查询效率,我们需要给追加型数据库创建索引,一般来说是Hash索引。
最基础的Hash索引:
- 每个键值都有一个唯一的Hash值
- Hash值对应一个偏移量,用于映射数据在文件中的偏移位置
- 内存够大的情况下,Hash表存储到内存中,先查询Hash表,如果Key存在,则根据获取到的偏移量读取Key
Hash会减慢写入性能,因为写的时候,还需要更新Hash表。
上述方案面临几个问题:
- 如果及其故障,那么内存中的数据会丢失,重启后需要重新建立索引,耗时较长。
- 内存可能不够用
- 追加的方式,会有空间浪费的现象,旧的数据用不到了
针对上述3个主要问题,我们给出如下的解决方案:
- 针对磁盘空间浪费or用尽的情况,我们把文件分段存储,按照固定的size分段。这样,可以启动异步线程去合并&压缩这些文件块,同时更新有关的索引。
- 针对机器故障的问题,我们把内存定期写一个磁盘的快照,比如每出现一个新的block,就把旧的所有的block的索引写入快照,这样当重启之类的,我们只需要加载快照,然后重新给新的block建立索引即可。合并&压缩过程中,旧的block是『冻结』的块,即仍然可以提供读写请求;合并完成之后,再切换到新的block中
- 内存不够用,可以考虑建立二级索引等
操作记录也可以追加到日志中,这种情况是防止日志文件损坏导致数据无法回复。
Bitcask数据库是典型的应用。
SSTables && LSM Tree
SSTable的定义:
- 文件块中的键按照顺序排列
- 每个文件块中的键只能在合并的块中出现一次
SSTable的优点:
-
合并算法更加高效,归并有序段的思路即可完成压缩&合并
-
节省内存索引空间,不需要给每个键建立索引,只要给部分键值创建索引即可,因为可以区间查询。比如,Hash Horrible只要建立这两个单词的索引,那么在这两个单词之间的数据,可以定位到Hash之后,顺序查找即可。缺点是,查找时间稍微增加,存在遍历的过程。 — 注:Q: 为什么不用二分查找?A: 因为块的size不是严格固定的,二分查找不容易确定记录的起始&停止的位置
-
如果读请求需要查询一个范围内部的多个KV,那么可以把有关的记录执行压缩,内存索引直接指向对应的文件头;可以节省磁盘空间&减少IO带宽。
构建SSTable & LSM-Tree
构造SSTable:
- 写入数据时,把数据放入内存的有序结构中,比如AVL树、跳表等
- 当内存的有序结构到达一定size后,把该结构刷新到磁盘中。write disk的有序结构冻结,只提供读的服务;有新的写入请求的时,直接创建新的有序结构即可
- 读请求发生的过程:先找内存,然后是最新的block,之后是次新的block,依次类推。
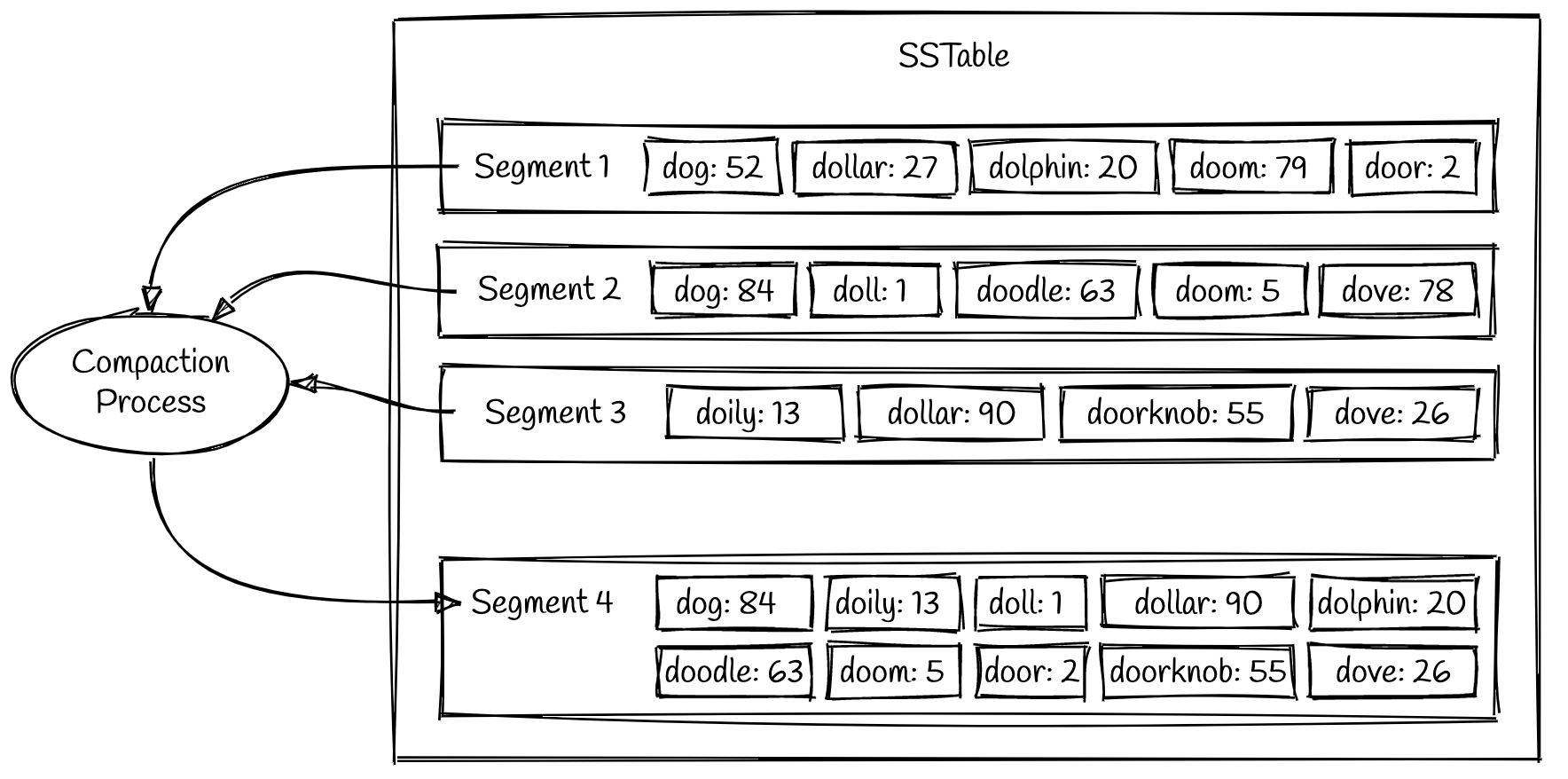
- 后台线程(进程)周期性压缩&合并block,丢弃已经覆盖or删除的值
LSMT查询的速度比较慢,可以使用bloom filter执行性能优化。
同样,可以利用追加操作日志的方式,防止机器崩溃导致的内存数据丢失。
LSM相对于BTree优势:写入速度快,基于追加的方式
劣势:compaction过程会影响读写的速率,因为compaction也占用磁盘IO
LSM-Tree就是根据上述结构构建的:
- 创建流程:
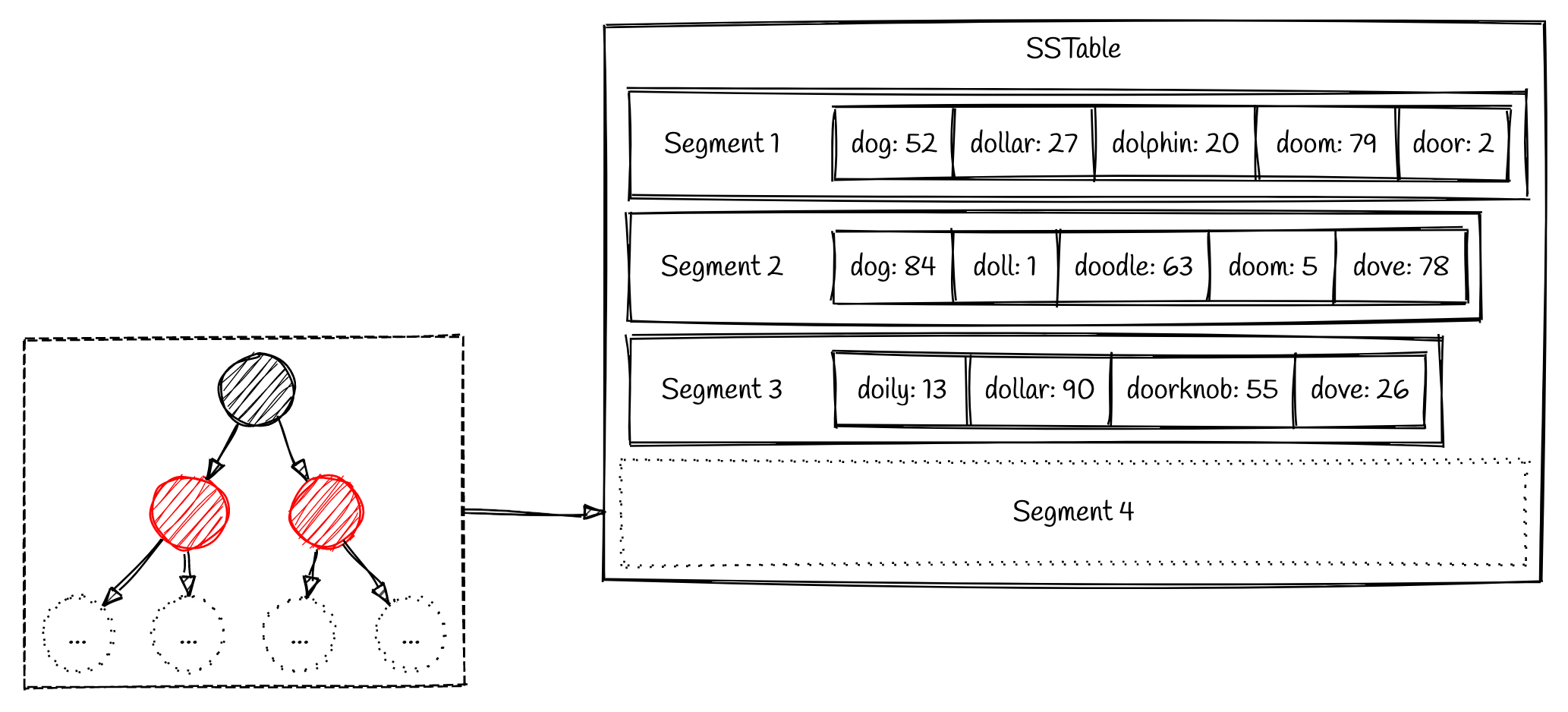
- 读取数据,这里是前面提到的,区间范围的Key在一个块中:
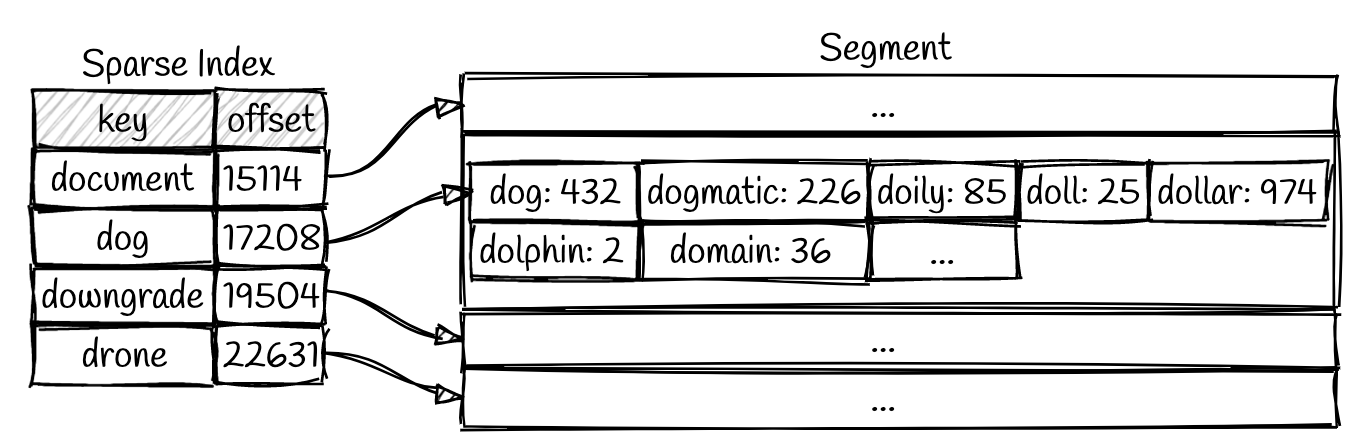
- 压缩操作,相当于是归并,在后台执行。压缩的过程,基本思想在前一小节提到了
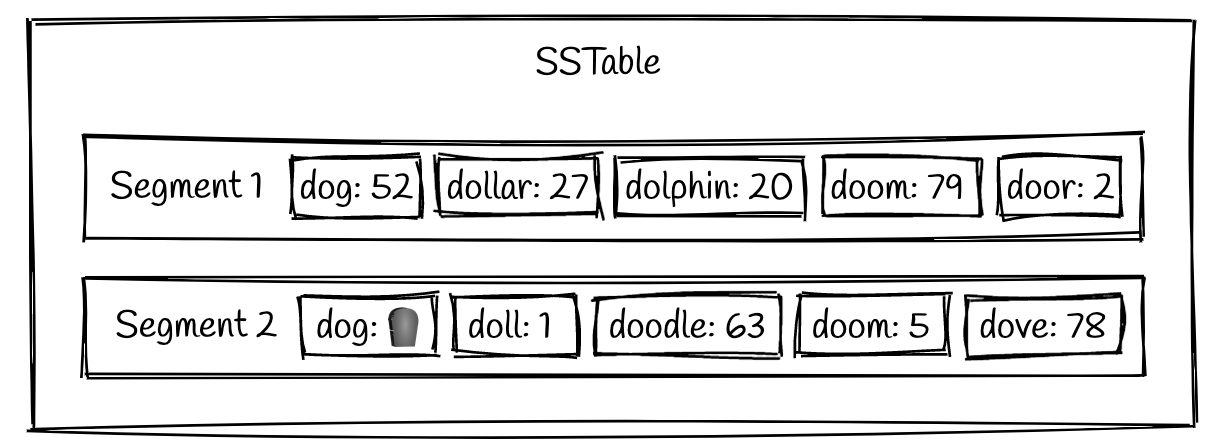
- 删除操作,标记数据为已删除的,但是不会立刻执行,只有后台compaction的时候,才会执行:
事务处理与分析处理
OLTP: Online traction process,在线事物处理,比如读写等。
OLAP: Online analysis process,在线分析处理,比如统计数据等。
OLTP对IO要求较高,OLAP可能涉及到大量的计算等,批量或者流处理等。
列式存储
与列式存储对应的是行存储。行存储,即传统SQL中所说的数据表。
为什么使用列存储?
假设有一个业务表,该业务对应的特性有几百个甚至更多。如果我们要获取某一行或者几行的数据,则需要把几百列的数据都加载到内存中。当然,我们有数据库的表的规范化,不过规范化会让业务更加难以理解。
同样的,这么多属性列,必然会有大量的重复数据,比如说,主键是用的id,某一列是用户的年龄,而且我们有数以亿计的用户,那么年龄必然存在大量的重复数据。
如果面向列存储,那么我们只需要指定需要的列和对应的数据位置,就可以直接加载对应的数据,而不必把所有的列都加载到内存。同时,当列中有大量的重复数据时,我们可以对列执行压缩,节约大量的空间。因此,列存储非常利于空间压缩&加速查询。
列存储的排序
单纯对列执行排序是没有意义的,列式存储的排序本身也是面向行的。可以指定某个列作为主键,然后执行有关的排序。排序可以极大地优化压缩率。
列存储的写入
行存储的写入分为两种情况:
- 不存在的行,直接按照规则插入即可
- 存在的行,原地更新
列式存储最困难的地方在于:不能原地更新数据,或者在列中间插入数据,尤其是压缩过的列,更不可能。
因此,列式存储采用LSMT的方式写入,定期执行compaction操作。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









