






内存排布
在深度学习中有两种内存排布方式,NCHW 和 NHWC。早期的caffe,tensorflow是以NHWC为主,因为他们开始主要支持的基于CPU的运算。后面的torch的内存模型以NCHW为主,因为在GPU上运算,NCHW更快

- NHWC,又称为“channel last”,在单线程下面比较适合CPU,排布方式为“RRRRRRGGGGGGBBBBBB”。在CPU的实现上,可以采用SSE或者AVX优化,pack 4或者8个字节进行运算。由于这种内存排布局部性更好,Cache Missing的情况更少。但是缺点也很明显,不利于做sum reduction。
- NHWC,C在外层,内存排列方式为“RGBRGBRGB”。对于GPU而言,尤其是多线程下面做reduction是非常耗时的操作,NCHW其实更利于GPU做并行化计算,而且CUDA默认的内存模型就是NCHW。
来自于 「Tensorflow」 官方文档:
Most TensorFlow operations used by a CNN support both NHWC and NCHW data format. On GPU, NCHW is faster. But on CPU, NHWC is sometimes faster.
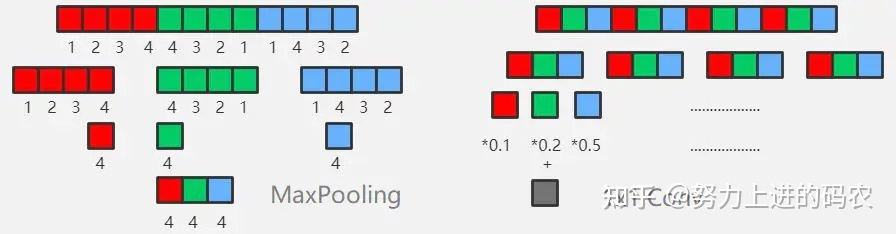
但是现代 英伟达显卡已经支持处理(包括reduction)局部block的数据,在这种情况下,使用NHWC是更快的。
由于NCHW,需要把所有通道的数据都读取到,才能运算,所以在计算时需要的存储更多。这个特性适合GPU运算,正好利用了GPU内存带宽较大并且并行性强的特点,其访存与计算的控制逻辑相对简单;而NHWC,每读取三个像素,都能获得一个彩色像素的值,即可对该彩色像素进行计算,这更适合多核CPU运算,CPU的内存带宽相对较小,每个像素计算的时延较低。「但是如果采用多线程编程实现,个人觉得NCHW更容易实现,效率更高。如果是纯单核做推断的话,采用NHWC更好。」

矩阵乘法与高性能数值计算
Basic Linear Algebra Subprograms (BLAS)
很多调包侠朋友很惊讶,矩阵乘法有啥好聊,随便都能实现。
float temp = 0;
timer.start();
for(int j = 0; j < rozmer; j++)
{
for (int k = 0; k < rozmer; k++)
{
temp = 0;
for (int m = 0; m < rozmer; m++)
{
temp = temp + matice1[j][m] * matice2[m][k];
}
matice3[j][k] = temp;
}
}
timer.stop();
但是实际上,用1024x1024矩阵算一下马上得出差别。这里大家惊讶发现被卡脖子的matlab计算性能居然和CUDA版本的运算速度差不多。
1024x1024 2048x2048 4096x4096
--------- --------- ---------
CUDA C (ms) 43.11 391.05 3407.99
C++ (ms) 6137.10 64369.29 551390.93
C# (ms) 10509.00 300684.00 2527250.00
Java (ms) 9149.90 92562.28 838357.94
MATLAB (ms) 75.01 423.10 3133.90
实际上,在matlab中,我们要计算两个矩阵 A 和 B 的乘积,我们会在命令行或者m-file里面写 A * B。这么一个简单的语句是如何转化为实际的计算过程的呢? 首先,matlab的解释器会分析这个语句的语法,从而知道你要做的是计算 A 和 B 的乘积。但是,matlab 其实只是个外包装,并不是自己进行这个计算的,而是把计算过程委托给一个核心的C语言计算函数叫做dgemm (Double precision GEneric Matrix Multiplication),然后dgemm进行实际的计算,最后matlab对dgemm输出的结果重新打包返回。
除了dgemm还有sgemm,cgemm,zgemm,dsymm (双精度对称矩阵乘法),zhemm(双精度复数 埃米特矩阵乘法)
SGEMM and DGEMM Combined Matrix Computations
C ← αAB+βC C ← αABT+βC
C ← αATB+βC C ← αATBT+βC
CGEMM and ZGEMM Combined Matrix Computations
C ← αAB+βC C ← αABT+βC C ← αABH+βC
C ← αATB+βC C ← αATBT+βC C ← αATBH+βC
C ← αAHB+βC C ← αAHBT+βC C ← αAHBH+βC
Data Types
A, B, C, α, β Subroutine
Short-precision real SGEMM
Long-precision real DGEMM
Short-precision complex CGEMM
Long-precision complex ZGEMM
dgemm其实是BLAS Level 3中最重要的函数 (常用BLAS/LAPACK 或者 MKL的朋友对这个函数肯定不陌生)。BLAS 全称 Basic Linear Algebra Subprograms,它是在1979年被提出的来用于支持建立一个叫做LAPACK的矩阵代数的运算库。到了今天,BLAS函数已经成为矩阵和向量运算的事实上的“国际标准”接口。BLAS的函数分为三个Level,
Level – 1是向量和向量之间的运算,比如点积 (ddot), 加法和数乘 (daxpy), 绝对值的和 (dasum), 等等; Level – 2 是向量和矩阵的乘法运算,最重要的函数是一般的矩阵向量乘法(dgemv) Level – 3 是矩阵和矩阵的乘法运算,最重要的函数是一般的矩阵乘法 (dgemm)
另外还有一套同样著名的标准运算接口,叫做LAPACK(Linear Algebra PACKage),它是基于BLAS的基础上建立的线性代数运算库,提供一些更复杂的功能,比如LU, QR, SVD分解,或者求解特征值和特征向量,又或者求解线性方程组以及最小二乘法等问题。
其实 BLAS 可以理解为只是一套函数接口,在遵循接口的情况下,不同的库可以有不同的实现。很多著名的软硬件厂商都分别实现了针对自己产品专门优化过的BLAS实现。最著名的实现有下面一些:
ATLAS: 这是一套开源的实现。很多开源的数值软件都使用ATLAS优化的BLAS; Intel MKL:这是Intel针对它的CPU系列开发的核心数学运算库,提供了完整的BLAS和LAPACK实现,除此以外,还有很多功能; AMD ACML: 作为Intel的长期对手,自然也不甘人后; Sun Performance Library: 主要针对Sun的SPARC架构;
另外,Apple, HP, NEC都有各自的BLAS实现。各大芯片厂商其实都不遗余力地提高自己的BLAS实现的性能——因为,前面提到的那个著名函数dgemm的运算速度是衡量一个CPU数值运算性能的非常重要的指标。一般来说,一台新的机器通过matlab算几次10001000或者20002000的随机矩阵乘法(前面提到,matlab也是调用核心的dgemm做这个事情),这样就大体知道这台机子的数值性能了。
那么既然在不同平台都支持了BLAS,为何不直接使用呢,其实是不方便使用,但是matlab封装了这些底层实现。譬如dgemm的C接口是这样的。总共14个参数。
void cblas_dgemm(const enum CBLAS_ORDER Order,
const enum CBLAS_TRANSPOSE TransA,
const enum CBLAS_TRANSPOSE TransB,
const int M,
const int N,
const int K,
const double alpha,
const double *A,
const int lda,
const double *B,
const int ldb,
const double beta,
double *C,
const int ldc);
加速矩阵乘法
我们都知道矩阵乘法的运算规则,其实很简单——一个10行内的的三重循环就能实现。为什么那么多大公司还要年复一年的研究怎么算矩阵乘法(还有别的更简单的数值运算过程)呢?因为,算对很容易,算得快却非常艰难。通常来说,会使用这么一些技术:
- 分解小矩阵块,每个小块都用特殊优化过的算法计算; - 把循环解开,减省内重循环中用于更新循环变量的开销。对于矩阵乘法这样的高密度数值运算,内重循环中每次循环哪怕减少一个指令周期,对整体性能都是很大的提高; - 对高速缓存(Cache)的调度进行改进,提高命中率; - 充分利用指令流水线,使得数据的读取,计算,写入这些接续操作在流水线内同时进行; - 使SIMD指令集(通常是SSE, SSE2, SSE3等)。SIMD全称是Single Instruction Multiple Data,就是一条指令在单周期内处理多组数据,在新的CPU中都支持这些指令。
SIMD对于向量运算的加速有重要意义。举个例子,在SSE2有指令能在单周期同时对一组128位浮点数(两个double,或者四个float)进行加减乘除或者开平方运算,可以想见,充分利用这些指令能对计算速度成倍提高。对于不同的CPU,不同的架构,不同大小的矩阵,对这些技术的运用也不尽相同,因此最终形成的实现算法非常非常复杂——资料显示,现代CPU上高度优化的矩阵乘法实现不是10行以内的for-loop,而是超过10万行!其中包含了大量和CPU和Cache密切相关的东西。
归纳起来,高速矩阵运算的全过程包含三个层次:
- 上层封装好的接口: 比如matlab里面的A * B;
- 中间层的 BLAS/LAPACK 的 C 函数,像dgemm,它们通过非常复杂并且硬件相关的技术来提高速度。
- 这些C函数会调用CPU中的指令进行运算,其中SIMD(SSEx)等汇编指令集对于运算速度的提高有着关键意义。
提高基本运算的速度显然不是我们的任务,Intel和AMD的工程师会管这个事情。如果能用matlab,matlab已经把这个包装好了。「如果你是那种对性能特别有追求的人,那么你可以到Intel或者AMD的网站获取最新版的MKL或者ACML,安裝到你的机器上,然后设置BLAS_VERSION环境变量就能让matlab使用最新的高性能库了。」
其它的常用数值软件,比如Mathematica, numpy, Octave, R都提供了方法链接不同的BLAS实现。对性能关键的数值运算程序,在选用支持库时,能否接入高性能BLAS实现是一个重要的标准。如果两个库都使用同一种BLAS实现,那么它们的计算性能应该是差不多的(除了在封装层的overhead略有差别)。而接口封装的质量当然也是重要的考虑,这直接关系到它的易用性。
当加速矩阵乘法本身就是一个具体的研究方向,对于深度学习研究者,要知道会用BLAS的接口来加速我们模型运算,尤其是类似「Attention或者Conv」这种需要大量矩阵运算的算子。下一节我们开始讲卷积操作,stay tuned!















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









