







今天做不成的事,明天也不会做好。
各位同学大家好,今天给大家分享一下用Mycat进行数据库的读写分离,本篇文章是基于上一篇的mysql主从复制。Linux上实现Mysql的主从复制(为Mycat读写分离作准备)
在上一篇文章中,我们在两个服务器使用同版本的操作系统和mysql:
服务器1:centos7.3,mysql5.6
服务器2:centos7.3,mysql5.6
接下来,我们来看一下实现读写分离的方法和优缺点。
1.读写分离的思路
1.1 原理
顾名思义,读写分离基本的原理是让主数据库处理事务性增、改、删操作,而从数据库处理查询操作。数据库复制被用来把事务性操作导致的变更同步到集群中的从数据库。
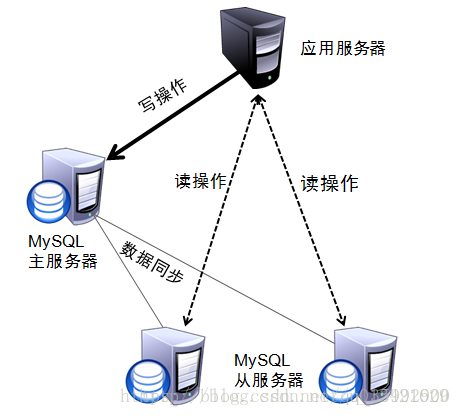
1.2 实现方式
实现方式有很多,但是不外乎分为内部配置和使用中间件,下面列举几个常用的方法:
1.配置多个数据源,根据业务需求访问不同的数据,指定对应的策略:增加,删除,修改操作访问对应数据,查询访问对应数据,不同数据库做好的数据一致性的处理。由于此方法相对易懂,简单,不做过多介绍。
2.动态切换数据源,根据配置的文件,业务动态切换访问的数据库:此方案通过Spring的AOP,AspactJ来实现动态织入,通过编程继承实现Spring中的AbstractRoutingDataSource,来实现数据库访问的动态切换,不仅可以方便扩展,不影响现有程序,而且对于此功能的增删也比较容易。
3.通过mycat来实现读写分离:使用mycat提供的读写分离功能,mycat连接多个数据库,数据源只需要连接mycat,对于开发人员而言他还是连接了一个数据库(实际是mysql的mycat中间件),而且也不需要根据不同业务来选择不同的库,这样就不会有多余的代码产生。
每个方法都有优缺点,我们选择对程序代码改动最小(只改数据源)的方法三,讲解mycat的配置和使用。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 649
649











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









