







WaveNet
由伦敦人工智能公司DeepMind的研究人员于2016年9月的一篇论文[1]中提出,可以直接生成语音,而且语音效果媲美真人。WaveNet取代了对音频信号使用傅里叶变换的传统方法,它通过令神经网络找出要执行的转换来实现。因此,转换可以反向传播,原始音频数据可以通过一些技术来处理,例如膨胀卷积、8位量化等。
2018年,Google在其云端语音合成服务Google Cloud Text-to-Speech[3]中提供了基于WaveNet的语音合成API[4]。截至2019年,该产品提供了32种语言以及多种不同音色的语音合成服务,且基于WaveNet的合成结果在自然度上相比传统方法更接近人类语音[5]。
概述
在过往的语音生成任务,如文字转语音、语者转换等,模型往往会先生成声音特征参数或时频谱,再使用声码器或Griffin-Lim算法合成声音讯号。在Tacotron2[8]中,首次将WaveNet用作神经声码器来补足从时频谱或梅尔刻度时频谱重建声音讯号所缺失的资讯(如相位等)。研究人员发现使用神经声码器所重建的声音讯号,比起使用传统声码器或算法生成的声音更为自然。此后,除了大量被使用在语音生成研究中来提高声音品质外,神经声码器也逐渐被应用在许多产品当中[4]。
缺点:
- 生成速度十分缓慢,由于样本点是逐一生成,因此生成一秒的声音讯号可能就要花上数分钟的时间[9],使其在实际应用上受到限制。
- 模型以之前生成的样本点作为输入来生成下一个样本点,因此当生成较差的样本点时,错误可能会不断累积下去,影响声音讯号品质。
原理
wavenet论文及参考代码:
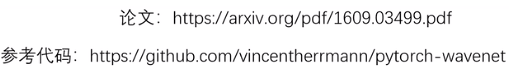
语音生成任务:
利用随机数据或者一段起始语音,生成后继的语音。
早期的语音生成,主要是RNN,利用前N-1特征帧,预测第N特征帧。
直到2016年,Google DeepMind团队提出的Wavenet,首次提出直接利用原始音频数据实现声音的生成,而不是用特征。
之前为什么一直是用特征呢?因为语音数据量大,但信息少。比如采样率为16KHz的语音,1秒语音就有16000个采样点,而RNN一般只能对长度小于100的点的序列建模。
WaveNet的主要思想:
利用前t-1个样本点,预测第t个样本点
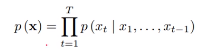
论文中使用的是CNN-1D的结构
普通的CNN感受野太少,如下图感受野就只有5.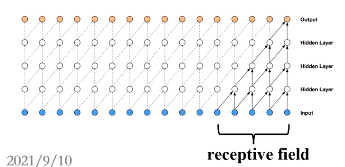
所以本文提出了因果卷积和膨胀卷积的概念。
-
普通卷积:t时刻的输出需要t,t-1,t+1三个时刻的输入。这并不适用于生成任务,因为t+1点正是需要生成的点。
-
因果卷积:t时刻的输出只由t和t-1时刻的输入。或t-i时刻。
-
膨胀卷积:不再是相邻的神经元,而是跳跃几个,比如膨胀系数=3,那就是t时刻的输出由t和t-3的输入决定。这样大大增加了感受野。
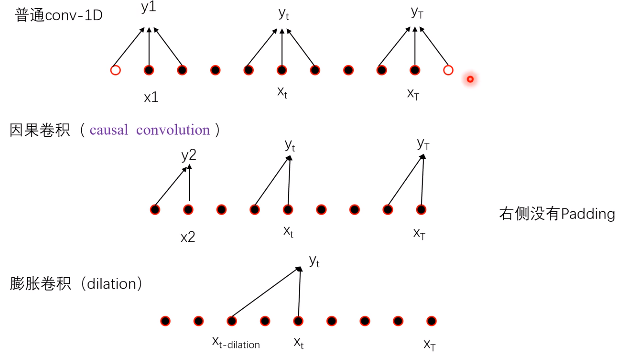
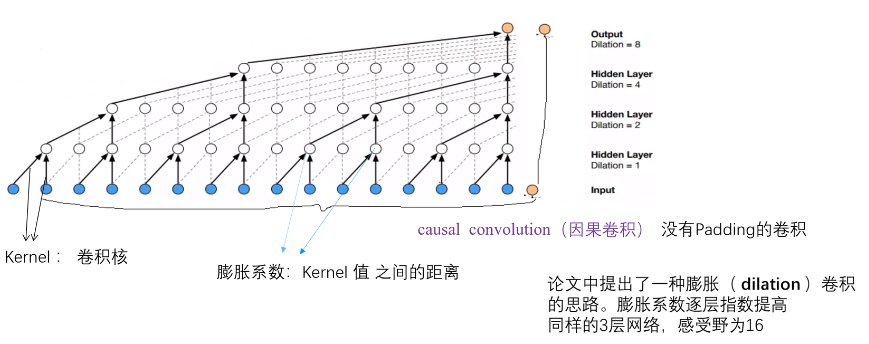
论文膨胀卷积网络如图:
论文中共用来10层,每层膨胀系数不同。
最后输出的黄色点1,就是由16个蓝色输入点决定,再把黄点1作为输入,与后面的15个蓝色点拼接,也是16点作为新的输入,预测黄点2…以此类推。
图中展示了3层隐藏层,整体感受野是16,所以实际网络10层的感受野就是1024。
还有其他网络结构共同构成:
因果膨胀卷积只是整体结构中的一小部分。因为有10层,怕引起梯度消失,所以还 需要引入残差连接和skip-out层。
一个block里每个layer的膨胀系数是指数增加[1, 2, 4, 8, 16],下一个block也是。
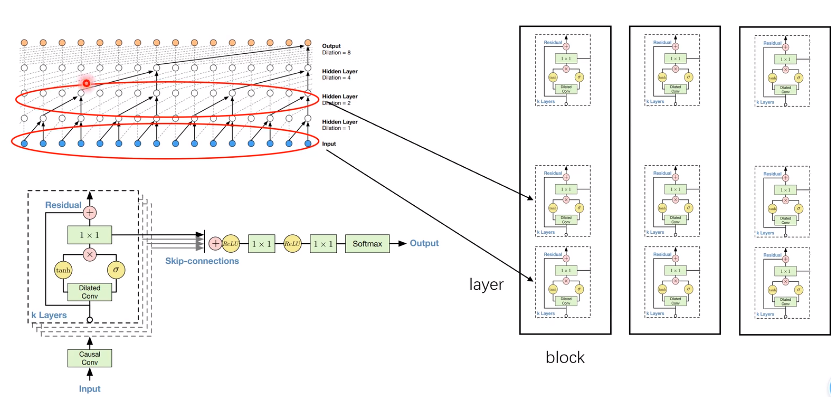
注意,每个层都有一个分支的输出,最后会合并到一起,再经过下面的Relu等。下图的这一部分。
网络具体的输入输出:
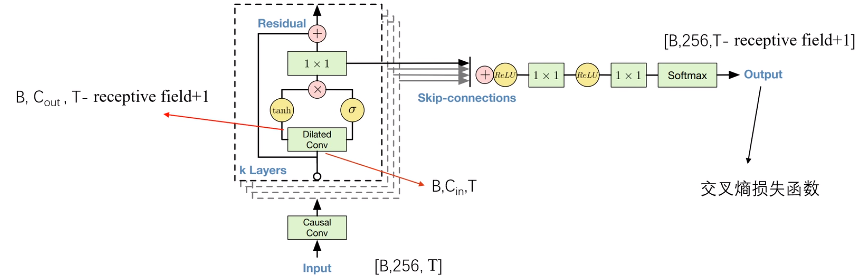
输入不是直接的原始音频采样点,也做了一些处理:
处理完后,每一个采样点都变成256维的onehot矢量。

输入数据长度可为感受野长度,比如输入1024点,1-1024输出预测的一点(记作1025号点),然后2-1025预测第1026,3-1026预测1027…
原理:
1.网络结构
与PixelCNNs类似,条件概率分布是通过若干卷积层进行建模的。网络中没有下采样层,模型的输出与输入具有相同的时间维度。
Wavenet模型是根据一个序列的前 t-1 个点预测第 t 个点的结果,每一个语音样本都依赖于之前时间步的所有样本,因此可以用来预测语音中的采样点数值。基本公式如下:

Wavenet模型主要成分是卷积网络,每个卷积层都对前一层进行卷积,卷积核越大,层数越多,时域上的感知能力越强,感知范围越大。在生成过程中,每生成一个点,把该点放到输入层最后一个点继续迭代生成即可。使用softmax层作为输出层。
由于语音的采样率高,时域上对感知范围要求大,我们采用了Dilated convolutions这种模型。Dilated convolutions加入了dilation这个概念,根据dilation大小选择连接的节点。比如dilation=1的时候,第二层只会使用第t,t - 2,t - 4…这些点。
使用最大对数似然方法对参数进行优化。由于对数似然易于处理,我们在验证数据集上对超参数进行优化,可以容易测定模型是否过拟合或者欠拟合。
2.Softmax Distributions
Wavenet在输出层使用了softmax,求取每个采样点的概率。由于16位的采样点就有65536种采样结果,所以我们使用 [公式] 对采样值进行转换。其公式如下:

转换后,65536个采样值会转换成256个值,而且实验证明该转换方法没有对原始音频造成明显损失。
3.Activate funtion:
激活函数使用了门单元

4. Residual and skip connections

如图,隐层中每一层的节点都会把该原来的值和通过激活函数的值相加后传递给下一层,其中1x1的卷积核用来实现降通道数的操作。然后每一个隐层的过激活函数后的结果相加做一系列操作后传给输出层。
5.Conditional wavenets
加条件特征主要是在激活函数处增加,分为两种形式,global condition 和 local condition。两者公式一致,但local的特征需要升采样.

升采样有两种方式,第一种是自己学习升采样的模型,可在模型中添加。另一种就是手动升采样,自己将特征复制多次。

















 1925
1925

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









