






CycleGAN-VC3
源自文章《CycleGAN-VC3: Examining and Improving CycleGAN-VCs for Mel-spectrogram Conversion》,从题目到就可以看出,它是为 Mel-spectrogram而设计的。作者Takuhiro Kaneko ,来自NTT公司,发表于2020InterSpeech。
代码:Cyclegan_VC3
背景介绍
非平行语音转换(VC)是一种不使用平行语料库学习源语和目标语之间映射的技术。最近,循环一致对抗网络(CycleGAN)-VC和CycleGAN-vc2在这一问题上取得了令人满意的结果,并被广泛用作基准方法。然而,CycleGAN-VC/VC2对mel-谱图转换的有效性还不明确,它们通常用于梅尔倒谱转换,即使比较方法采用梅尔谱图作为转换目标。
为了解决这个问题,我们研究了CycleGAN-VC/VC2在mel-谱图转换中的适用性。通过初步实验,我们发现当CycleGAN-VC/VC2直接应用于melspectrogram时,它会破坏转换过程中应该保留的时频结构,如图1所示。
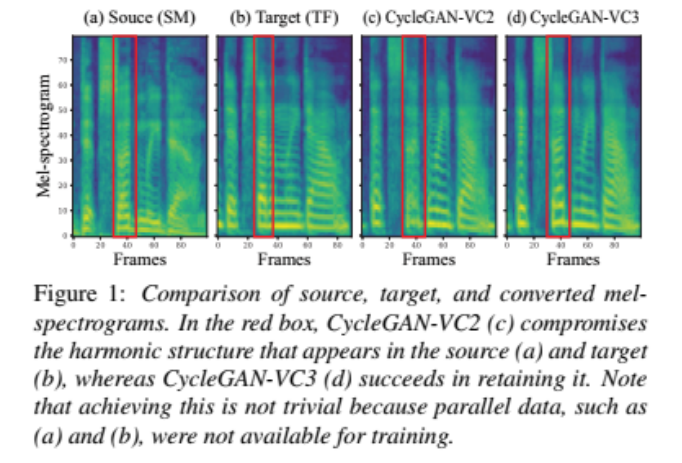
为了解决这个问题,我们提出了CycleGAN-VC3,它是对CycleGANVC2的改进,包含了时频自适应归一化(TFAN)。利用TFAN,我们可以调整转换特征的尺度和偏置,同时反映源梅尔谱图的时频结构。
我们使用2018年语音转换挑战(VCC 2018)数据集评估了CycleGAN-VC3在性别间和性别内非平行VC中的作用。自然度和相似度的主观评价表明,对于每个VC对,CycleGAN-VC3比两种类型的CycleGANVC2(一种应用于梅尔倒谱,另一种应用于梅尔谱)都取得了更好的或有竞争力的性能。
网络结构
TFAN:时频自适应归一化
我们设计了扩展实例归一化(IN)的TFAN,以调整转换特征的尺度和偏置,同时以时间和频率方式反映源信息(即x)。特别是,我们设计了用于2D-CNN的1D和2D时频特征的TFAN。
给定特征f, TFAN以类似于IN的通道方式对其进行归一化,然后使用cnn从x计算的尺度γ(x)和偏置β(x)以元素方式调制归一化特征。

其中f’是输出特征,μ(f)和σ(f)分别是f的通道平均和标准差。在In中,与x无关的尺度β和偏置γ以通道方式应用,而在TFAN中,从x计算的那些(即β(x)和γ(x))以元素方式应用。这些差异允许TFAN在以时间和频率方式反射x的同时,调整f的刻度和偏置。
TFAN_1D模块代码实现(以1D为例,2D的同理):
class TFAN_1D(nn.Module):
"""
as paper said, it has best performance when N=3, kernal_size in h is 5
"""
def __init__(self, norm_nc, ks=5, label_nc=128, N=3):
super().__init__()
self.param_free_norm = nn.InstanceNorm1d(norm_nc, affine=False)
self.repeat_N = N
# 中间嵌入空间的维数。为硬编码,即不可改变。
nhidden = 128
pw = ks // 2
self.mlp_shared = nn.Sequential(
nn.Conv1d(label_nc, nhidden, kernel_size=ks, padding=pw),
nn.ReLU()
)
self.mlp_gamma = nn.Conv1d(nhidden, norm_nc, kernel_size=ks, padding=pw)
self.mlp_beta = nn.Conv1d(nhidden, norm_nc, kernel_size=ks, padding=pw)
def forward(self, x, segmap):
# Part 1. 生成无参数的规范化激活
normalized = self.param_free_norm(x)
# Part 2. 根据语义图产生尺度和偏差
segmap = F.interpolate(segmap, size=x.size()[2:], mode='nearest')
# actv = self.mlp_shared(segmap)
temp = segmap
for i in range(self.repeat_N):
temp = self.mlp_shared(temp)
actv = temp
gamma = self.mlp_gamma(actv)
beta = self.mlp_beta(actv)
# apply scale and bias 应用尺度和偏差
out = normalized * (1 + gamma) + beta
return out
图2说明了TFAN的体系结构。
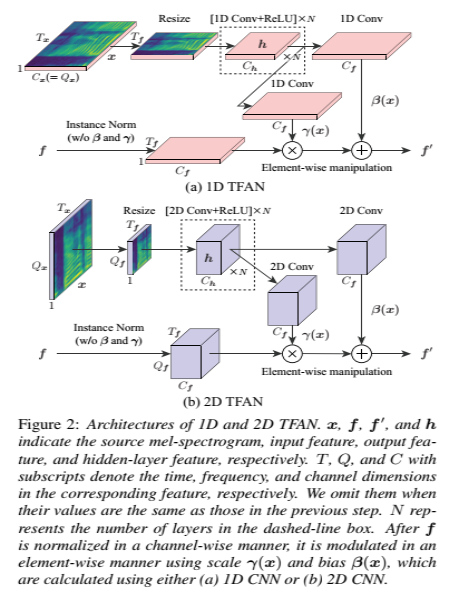
需要注意的是,TFAN的灵感来自于SPADE[27],后者最初是为语义图像合成而提出的。主要区别在于:
(1) SPADE是针对二维图像特征设计的,而TFAN是针对一维和二维时频特征设计的,
(2) SPADE在图2虚线框所示的组件中使用单层CNN。因为语义图像合成不需要剧烈的变化,而TFAN使用多层CNN来保证动态变化,
(3) SPADE基于批处理归一化[38],而TFAN基于in。
生成器代码:
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
# 2D Conv Layer
self.conv1 = nn.Conv2d(in_channels=1, # TODO 1 ?
out_channels=128,
kernel_size=(5, 15),
stride=(1, 1),
padding=(2, 7))
self.conv1_gates = nn.Conv2d(in_channels=1, # TODO 1 ?
out_channels=128,
kernel_size=(5, 15),
stride=1,
padding=(2, 7))
# 2D Downsample Layer
self.downSample1 = downSample_Generator(in_channels=128,
out_channels=256,
kernel_size=5,
stride=2,
padding=2)
self.downSample2 = downSample_Generator(in_channels=256,
out_channels=256,
kernel_size=5,
stride=2,
padding=2)
# 2D -> 1D Conv
# self.conv2dto1dLayer = nn.Sequential(nn.Conv1d(in_channels=2304,
# out_channels=256,
# kernel_size=1,
# stride=1,
# padding=0),
# nn.InstanceNorm1d(num_features=256,
# affine=True))
self.conv2dto1dLayer = nn.Conv1d(in_channels=2304,
out_channels=256,
kernel_size=1,
stride=1,
padding=0)
self.conv2dto1dLayer_tfan = TFAN_1D(256)
# Residual Blocks
self.residualLayer1 = ResidualLayer(in_channels=256,
out_channels=512,
kernel_size=3,
stride=1,
padding=1)
self.residualLayer2 = ResidualLayer(in_channels=256,
out_channels=512,
kernel_size=3,
stride=1,
padding=1)
self.residualLayer3 = ResidualLayer(in_channels=256,
out_channels=512,
kernel_size=3,
stride=1,
padding=1)
self.residualLayer4 = ResidualLayer(in_channels=256,
out_channels=512,
kernel_size=3,
stride=1,
padding=1)
self.residualLayer5 = ResidualLayer(in_channels=256,
out_channels=512,
kernel_size=3,
stride=1,
padding=1)
self.residualLayer6 = ResidualLayer(in_channels=256,
out_channels=512,
kernel_size=3,
stride=1,
padding=1)
# 1D -> 2D Conv
# self.conv1dto2dLayer = nn.Sequential(nn.Conv1d(in_channels=256,
# out_channels=2304,
# kernel_size=1,
# stride=1,
# padding=0),
# nn.InstanceNorm1d(num_features=2304,
# affine=True))
self.conv1dto2dLayer = nn.Conv1d(in_channels=256,
out_channels=2304,
kernel_size=1,
stride=1,
padding=0)
self.conv1dto2dLayer_tfan = TFAN_1D(2304)
# UpSample Layer
self.upSample1 = self.upSample(in_channels=256,
out_channels=1024,
kernel_size=5,
stride=1,
padding=2)
self.upSample1_tfan = TFAN_2D(1024 // 4)
self.glu = GLU()
self.upSample2 = self.upSample(in_channels=256,
out_channels=512,
kernel_size=5,
stride=1,
padding=2)
self.upSample2_tfan = TFAN_2D(512 // 4)
self.lastConvLayer = nn.Conv2d(in_channels=128,
out_channels=1,
kernel_size=(5, 15),
stride=(1, 1),
padding=(2, 7))
def downSample(self, in_channels, out_channels, kernel_size, stride, padding):
self.ConvLayer = nn.Sequential(nn.Conv1d(in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding),
nn.InstanceNorm1d(
num_features=out_channels,
affine=True),
GLU())
return self.ConvLayer
# def upSample(self, in_channels, out_channels, kernel_size, stride, padding):
# self.convLayer = nn.Sequential(nn.Conv2d(in_channels=in_channels,
# out_channels=out_channels,
# kernel_size=kernel_size,
# stride=stride,
# padding=padding),
# nn.PixelShuffle(upscale_factor=2),
# nn.InstanceNorm2d(
# num_features=out_channels // 4,
# affine=True),
# GLU())
# return self.convLayer
def upSample(self, in_channels, out_channels, kernel_size, stride, padding):
self.convLayer = nn.Sequential(nn.Conv2d(in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding),
nn.PixelShuffle(upscale_factor=2))
return self.convLayer
def forward(self, input):
# GLU
print("Generator forward input: ", input.shape)
input = input.unsqueeze(1)
print("Generator forward input: ", input.shape)
seg_1d = input # for TFAN module
conv1 = self.conv1(input) * torch.sigmoid(self.conv1_gates(input))
print("Generator forward conv1: ", conv1.shape)
# DownloadSample
downsample1 = self.downSample1(conv1)
print("Generator forward downsample1: ", downsample1.shape)
downsample2 = self.downSample2(downsample1)
print("Generator forward downsample2: ", downsample2.shape)
# 2D -> 1D
# reshape
reshape2dto1d = downsample2.view(downsample2.size(0), 2304, 1, -1)
reshape2dto1d = reshape2dto1d.squeeze(2)
# print("Generator forward reshape2dto1d: ", reshape2dto1d.shape)
conv2dto1d_layer = self.conv2dto1dLayer(reshape2dto1d)
# print("Generator forward conv2dto1d_layer: ", conv2dto1d_layer.shape)
conv2dto1d_layer = self.conv2dto1dLayer_tfan(conv2dto1d_layer, seg_1d)
residual_layer_1 = self.residualLayer1(conv2dto1d_layer)
residual_layer_2 = self.residualLayer2(residual_layer_1)
residual_layer_3 = self.residualLayer3(residual_layer_2)
residual_layer_4 = self.residualLayer4(residual_layer_3)
residual_layer_5 = self.residualLayer5(residual_layer_4)
residual_layer_6 = self.residualLayer6(residual_layer_5)
# print("Generator forward residual_layer_6: ", residual_layer_6.shape)
# 1D -> 2D
conv1dto2d_layer = self.conv1dto2dLayer(residual_layer_6)
# print("Generator forward conv1dto2d_layer: ", conv1dto2d_layer.shape)
conv1dto2d_layer = self.conv1dto2dLayer_tfan(conv1dto2d_layer, seg_1d)
# reshape
reshape1dto2d = conv1dto2d_layer.unsqueeze(2)
reshape1dto2d = reshape1dto2d.view(reshape1dto2d.size(0), 256, 9, -1)
# print("Generator forward reshape1dto2d: ", reshape1dto2d.shape)
seg_2d = reshape1dto2d
# UpSample
upsample_layer_1 = self.upSample1(reshape1dto2d)
# print("Generator forward upsample_layer_1: ", upsample_layer_1.shape)
upsample_layer_1 = self.upSample1_tfan(upsample_layer_1, seg_2d)
upsample_layer_1 = self.glu(upsample_layer_1)
upsample_layer_2 = self.upSample2(upsample_layer_1)
# print("Generator forward upsample_layer_2: ", upsample_layer_2.shape)
upsample_layer_2 = self.upSample2_tfan(upsample_layer_2, seg_2d)
upsample_layer_2 = self.glu(upsample_layer_2)
output = self.lastConvLayer(upsample_layer_2)
# print("Generator forward output: ", output.shape)
output = output.squeeze(1)
# print("Generator forward output: ", output.shape)
return output
判别器仍为PatchGAN
对比
在CycleGAN-VC3中,我们将TFAN置入CycleGAN-VC2生成器(即2-1-2d CNN(第2.2节))。IN在1D分别用1D TFAN和2D TFAN替换二维块和上采样块中的二维块,如图3所示。在TFAN中,我们将h(图2)中的通道数(即Ch)和内核大小分别设置为128和5。我们检查了不同N和调整TFAN插入位置的性能,并在第4.2节中展示了我们的发现。鉴别器与CycleGAN-VC2(即PatchGAN(第2.3节))中使用的鉴别器相同。

实验过程
实验条件
数据集: 我们在VCC 2018的Spoke(即非并行VC)任务上评估了CycleGAN-VCs[28],该任务包含美国专业英语使用者的录音。我们选择了一个考虑所有跨性别和性别内VC的说话者子集:VCC2SF3 (SF)、VCC2SM3 (SM)、VCC2TF1 (TF)和VCC2TM1 ™,其中S、T、F和M分别代表源、目标、女性和男性。采用2源2标组合进行评价。对于每个说话者,分别使用81句话(大约5分钟,这对于VC来说相对较低)和35句进行训练和评估。在训练集中,源话语和目标话语之间没有重叠;因此,这个问题必须在完全非并行情况中解决。录音被降采样到22.05 kHz。我们在实验中使用MelGAN[39]作为声码器,提取80维的对数梅尔谱图,其窗长为1024,帧移为256。
转换过程: 本研究的一个目的是研究使用CycleGAN-VCs进行mel-谱图转换的可行性。因此,我们使用CycleGAN-VCs进行mel-谱图转换,并使用预训练的MelGAN声码器合成波形[39],我们没有改变声码器的参数,这样我们就可以专注于mel谱图转换的评估;然而,对每个说话者进行微调是一种可能的改进方法。
网络架构: 随着声学特征由梅尔倒谱变为梅尔谱,特征维数由35增加到80。然而,CycleGAN-VCs的生成器是完全卷积的;因此,可以在不修改网络架构的情况下使用它们。在鉴别器方面,我们使用了与倒频谱转换相同的网络架构,只是在CycleGANVC2/VC3中,最后一层卷积的核大小在频率方向上增加了一倍(原始网络架构的详细信息见[21]中的图4)。
训练设置: 训练设置与CycleGAN-VC/VC2中用于倒频谱转换的设置相似[19,21]。对于预处理,我们使用训练数据的均值和方差对mel谱图进行归一化。我们使用最小二乘GAN[40]作为GAN目标。我们使用Adam优化器[41]训练网络进行500k次迭代,批大小为1。训练样本由随机裁剪的64帧(约0.75 s)组成,生成器的学习率设置为0.0002,鉴别器的学习率设置为0.0001,动量项β1和β2分别为0.5和0.999。λcyc和λid分别设置为10和5,并且Lid仅用于前10k次迭代。请注意,与原始CycleGAN-VC/VC2类似,我们没有使用额外的数据,模块或时间校准程序进行训练。

















 540
540

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









