









一、Kubernetes简介
1. Kubernetes简介
- 在Docker 作为高级容器引擎快速发展的同时,在Google内部,容器技术已经应用了很多年,Borg系统运行管理着成千上万的容器应用。
- Kubernetes项目来源于Borg,可以说是集结了Borg设计思想的精华,并且吸收了Borg系统中的经验和教训。
- Kubernetes对计算资源进行了更高层次的抽象,通过将容器进行细致的组合,将最终的应用服务交给用户。
- Kubernetes的好处:
- 隐藏资源管理和错误处理,用户仅需要关注应用的开发。
- 服务高可用、高可靠。
- 可将负载运行在由成千上万的机器联合而成的集群中。
2. kubernetes设计架构
- Kubernetes集群包含有节点代理kubelet和Master组件(APIs, scheduler, etc),一切都基于分布式的存储系统。

- Kubernetes主要由以下几个核心组件组成:
- etcd:保存了整个集群的状态
- apiserver:提供了资源操作的唯一入口,并提供认证、授权、访问控制、API注册和发现等机制
- controller manager:负责维护集群的状态,比如故障检测、自动扩展、滚动更新等
- scheduler:负责资源的调度,按照预定的调度策略将Pod调度到相应的机器上
- kubelet:负责维护容器的生命周期,同时也负责Volume(CVI)和网络(CNI)的管理
- Container runtime:负责镜像管理以及Pod和容器的真正运行(CRI)
- kube-proxy:负责为Service提供cluster内部的服务发现和负载均衡
- 除了核心组件,还有一些推荐的Add-ons:
- kube-dns:负责为整个集群提供DNS服务
- Ingress Controller:为服务提供外网入口
- Heapster:提供资源监控
- Dashboard:提供GUI
- Federation:提供跨可用区的集群
- Fluentd-elasticsearch:提供集群日志采集、存储与查询
- Kubernetes设计理念和功能其实就是一个类似Linux的分层架构

- 核心层:Kubernetes最核心的功能,对外提供API构建高层的应用,对内提供插件式应用执行环境
- 应用层:部署(无状态应用、有状态应用、批处理任务、集群应用等)和路由(服务发现、DNS解析等)
- 管理层:系统度量(如基础设施、容器和网络的度量),自动化(如自动扩展、动态Provision等)以及策略管理(RBAC、Quota、PSP、NetworkPolicy等)
- 接口层:kubectl命令行工具、客户端SDK以及集群联邦
- 生态系统:在接口层之上的庞大容器集群管理调度的生态系统,可以划分为两个范畴
- Kubernetes外部:日志、监控、配置管理、CI、CD、Workflow、FaaS、OTS应用、ChatOps等
- Kubernetes内部:CRI、CNI、CVI、镜像仓库、Cloud Provider、集群自身的配置和管理等
二、Kubernetes部署
关闭节点的selinux和iptables防火墙
所有节点(server1、2、3)部署docker引擎
yum install -y docker-ce

注意:这是我自己搭建的docker-ce仓库,直接将上图红圈中的软件包放到了docker仓库中构建的,如果是阿里云或清华镜像,可能会提示缺少该依赖,需要自己去网上下载(可在阿里云搜索下载的)。
vim /etc/sysctl.d/k8s.conf

sysctl --system
启动docker
systemctl enable --now docker.service

官网:https://kubernetes.io/docs/setup/production-environment/container-runtimes/#docker
vim /etc/docker/daemon.json 1 {
2 "exec-opts": ["native.cgroupdriver=systemd"],
3 "log-driver": "json-file",
4 "log-opts": {
5 "max-size": "100m"
6 },
7 "storage-driver": "overlay2",
8 "storage-opts": [
9 "overlay2.override_kernel_check=true"
10 ]
11 }
mkdir -p /etc/systemd/system/docker.service.d
systemctl daemon-reload
systemctl restart docker
禁用swap分区:
swapoff -avim /etc/fstab ##注释掉/etc/fstab文件中的swap定义
安装部署软件kubeadm(所有节点安装):
vim /etc/yum.repos.d/k8s.repo[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=0yum install -y kubelet kubeadm kubectl
systemctl enable --now kubelet

主节点从外网拉取镜像,上传到私有harbor仓库
主节点(server1):
查看默认配置信息
kubeadm config print init-defaults
默认从k8s.gcr.io上下载组件镜像,需要翻墙才可以,所以需要修改镜像仓库:
列出所需镜像
kubeadm config images list --image-repository registry.aliyuncs.com/google_containers
拉取镜像
kbeadm config images pull --image-repository registry.aliyuncs.com/google_containersu

报错,因为我的k8s是最新的1.18.4,而远程仓库没更新,所以报错
指定安装1.18.3 --kubernetes-version指定k8s安装版本
kubeadm config images pull \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.18.3

将镜像上传到harbor仓库,如何创建私有仓库可以看我上一篇文章
在harbor主机将证书传给server1
scp reg.harbor.com.crt 192.168.1.101:/etc/docker/certs.d/reg.harbor.com/ca.crt
然后再server1进行认证
docker login reg.harbor.com
将刚才我们从外网拉取的镜像上传到私有harbor仓库
for i in `docker images | grep registry | awk '{ print $1":"$2 }' | awk -F '/' '{ print $3 }'`;do
> docker tag registry.aliyuncs.com/google_containers/$i reg.harbor.com/library/$i;
> docker push reg.harbor.com/library/$i
> done

登陆harbor仓库查看

在server1删除阿里云仓库镜像,只保留私有仓库镜像
for i in `docker images | grep registry.aliyuncs.com | awk '{ print $1":"$2 }'`; do docker rmi $i; done
初始化集群
使用flannel网络组件时必须添加--pod-network-cidr=10.244.0.0/16
kubeadm init --pod-network-cidr=10.244.0.0/16 --image-repository reg.harbor.com/library

提示虚拟机是单核的,可以通过添加--ignore-preflight-errors=参数解决
kubeadm init --pod-network-cidr=10.244.0.0/16 --image-repository reg.harbor.com/library --ignore-preflight-errors=NumCPU
报错,找不到版本1.18.4,默认是找软件版本,和我们实际版本不一致,指定版本 --kubernetes-version v1.18.3
kubeadm init --pod-network-cidr=10.244.0.0/16 --image-repository reg.harbor.com/library --kubernetes-version v1.18.3 --ignore-preflight-errors=NumCPU


配置kubectl:
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/configkubectl get node ##配置完成后查看节点
kubectl get all
上面我使用的是root用户,实际环境可以创建普通用户,然后通过sudo授权,关键在于/etc/kubernetes/admin.conf文件
节点扩容:

kubeadm join 192.168.1.101:6443 --token 0m1udt.sae7k0ubqkz7pww4 \
--discovery-token-ca-cert-hash sha256:26340cffec9e7db18af86ca5238a8132ee81229f412a86fcb0f82e8ec627e562 上图是我们初始化成功时最后系统打印的信息,将红框部分内容在其他节点运行(server2,server3)


注意,这里的token会过期(默认24小时)过期后其他节点要加入时需要生成新的token
kubeadm token create

配置kubectl命令补齐功能:
echo "source <(kubectl completion bash)" >> ~/.bashrc
source ~/.bashrc
可以查看下状态,如果node节点notready可以查看日志,这是我参考别人的文章https://www.cnblogs.com/lph970417/p/11805934.html
其次因为我忘记做harbor解析,导致之后的pod状态一致不对,去查看server2、3节点发现拉取镜像失败,因为没做解析以及https的自签名证书问题
安装flannel网络组件
https://github.com/coreos/flannel
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml ###肯能会因为网络问题失败,多执行几次,我执行了十几次才成功
• 其他网络组件:
• https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/create-
cluster-kubeadm/#pod-network
Master查看状态:
kubectl get cs
kubectl get nodes
kubectl get pod -n kube-system 
kubectl命令指南:
• https://kubernetes.io/docs/reference/generated/kubectl/kubectl-commands
三、Pod管理
- Pod是可以创建和管理Kubernetes计算的最小可部署单元,一个Pod代表着集群中运行的一个进程,每个pod都有一个唯一的ip。
- 一个pod类似一个豌豆荚,包含一个或多个容器(通常是docker),多个容器间共享IPC、Network和UTC namespace。
kubectl命令: https://kubernetes.io/docs/reference/generated/kubectl/kubectl-commands
准备:
拉取nginx镜像,上传到私有harbor仓库
docker pull hub.c.163.com/library/nginx:latest
docker tag hub.c.163.com/library/nginx reg.harbor.com/library/nginx
docker push reg.harbor.com/library/nginx

删除镜像
docker rmi hub.c.163.com/library/nginx

创建Pod应用
kubectl run nginx --image=nginx --replicas=2 --record
本来这里是server3也会创建pod应用的,但因为replicas参数已经被弃用,所以不会生效,最终只是再server3创建pod应用后面我们可以通过资源清单的方式批量部署pod应用
• 集群内部任意节点可以访问Pod,但集群外部无法直接访问。
删除Pod
kubectl delete pod nginx
service是一个抽象概念,定义了一个服务的多个pod逻辑合集和访问pod的策略,一般把service称为微服务。
创建service
kubectl expose pod nginx --port=80 --target-port=80


• 此时pod客户端可以通过service的名称访问后端Pod
• ClusterIP: 默认类型,自动分配一个仅集群内部可以访问的虚拟IP
使用NodePort类型暴露端口,让外部客户端访问Pod
kubectl edit svc nginx //修改service的type为NodePort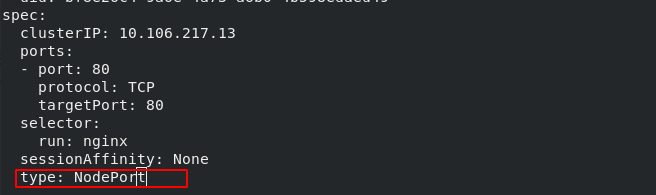

kubectl expose deployment nginx --port=80 --target-port=80 --type=NodePort //也可以在创建service时指定类型
• NodePort: 在ClusterIP基础上为Service在每台机器上绑定一个端口,这样就可以通过 NodeIP:NodePort 来访问该服务
更新pod镜像
kubectl set image deployment nginx nginx=nginx:1.16.0 --record
回滚
kubectl rollout history deployment nginx ##查看历史版本kubectl rollout undo deployment nginx --to-revision=1 ##回滚版本
四、资源清单
格式如下:
kubectl explain pod ##查询帮助文档





自主式Pod资源清单
vim demo.yaml
kubectl create -f demo.yaml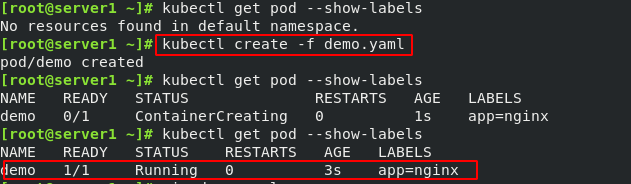
标签:
kubectl get pod --show-labels ##查看标签
kubectl get pod -l app ##过滤包含app的标签
kubectl get pod -L app
kubectl label pod demo version=v1 ##打标签
kubectl label pod demo app=demo-nginx --overwrite ##更改标签

节点标签选择器
kubectl label nodes server3 disktype=nvme-ssd
kubectl get nodes -l disktype

在yaml文件中增加标签选择器

kubectl delete -f demo.yml
kubectl create -f demo.yaml
kubectl get pod -o wide
kubectl label nodes server2 disktype=hdd
![]()
vim demo.yaml 

五、Pod生命周期

Pod 可以包含多个容器,应用运行在这些容器里面,同时 Pod 也可以有一个或多个先于应用容器启动的 Init 容器。
Init 容器与普通的容器非常像,除了如下几点:
- 它们总是运行到完成。
- Init 容器不支持 Readiness,因为它们必须在 Pod 就绪之前运行完成。
- 每个 Init 容器必须运行成功,下一个才能够运行。
如果 Pod 的 Init 容器失败,Kubernetes 会不断地重启该 Pod,直到 Init 容器成功为止。然而,如果 Pod 对应的 restartPolicy 值为 Never,它不会重新启动。
Init 容器能做什么?
- Init 容器可以包含一些安装过程中应用容器中不存在的实用工具或个性化代码。
- Init 容器可以安全地运行这些工具,避免这些工具导致应用镜像的安全性降低。
- 应用镜像的创建者和部署者可以各自独立工作,而没有必要联合构建一个单独的应用镜像。
- Init 容器能以不同于Pod内应用容器的文件系统视图运行。因此,Init容器可具有访问 Secrets 的权限,而应用容器不能够访问。
- 由于 Init 容器必须在应用容器启动之前运行完成,因此 Init 容器提供了一种机制来阻塞或延迟应用容器的启动,直到满足了一组先决条件。一旦前置条件满足,Pod内的所有的应用容器会并行启动。
准备:
下载busybox镜像推送到私有harbor仓库

编辑yaml文件

kubectl create -f demo2.yaml
kubectl get -f demo2.yaml 
kubectl describe -f demo2.yaml 
kubectl create -f myservice.yaml 
这里应该是running,发现还没有初始化,查看具体情况
kubectl describe -f demo2.yaml  这里提示是我的server2网络配置有问题,删除server2的cni0网卡,重建
这里提示是我的server2网络配置有问题,删除server2的cni0网卡,重建
ifconfig cni0 down
ip link delete cni0
ifconfig cni0 upkubectl get -f demo2.yaml

初始化完成
探针是由 kubelet 对容器执行的定期诊断:
- ExecAction: 在容器内执行指定命令。如果命令退出时返回码为 0 则认为诊断成功。
- TCPSocketAction: 对指定端口上的容器的 IP 地址进行 TCP 检查。如果端口打开,则诊断被认为是成功的。
- HTTPGetAction: 对指定的端口和路径上的容器的 IP 地址执行 HTTP Get请求。如果响应的状态码大于等于200 且小于 400,则诊断被认为是成功的。
每次探测都将获得以下三种结果之一:
- 成功:容器通过了诊断。
- 失败:容器未通过诊断。
- 未知:诊断失败,因此不会采取任何行动。
Kubelet 可以选择是否执行在容器上运行的三种探针执行和做出反应:
- livenessProbe:指示容器是否正在运行。如果存活探测失败,则 kubelet 会杀死容器,并且容器将受到其 重启策略 的影响。如果容器不提供存活探针,则默认状态为 Success。
- readinessProbe:指示容器是否准备好服务请求。如果就绪探测失败,端点控制器将从与 Pod 匹配的所有 Service 的端点中删除该 Pod 的 IP 地址。初始延迟之前的就绪状态默认为 Failure。如果容器不提供就绪探针,则默认状态为 Success。
- startupProbe: 指示容器中的应用是否已经启动。如果提供了启动探测(startup probe),则禁用所有其他探测,直到它成功为止。如果启动探测失败,kubelet 将杀死容器,容器服从其重启策略进行重启。如果容器没有提供启动探测,则默认状态为成功Success。
重启策略
- PodSpec 中有一个 restartPolicy 字段,可能的值为 Always、OnFailure 和Never。默认为 Always。
Pod 的生命
- 一般Pod 不会消失,直到人为销毁他们,这可能是一个人或控制器。
- 建议创建适当的控制器来创建 Pod,而不是直接自己创建 Pod。因为单独的Pod 在机器故障的情况下没有办法自动复原,而控制器却可以。
- 三种可用的控制器:
- 使用 Job 运行预期会终止的 Pod,例如批量计算。Job 仅适用于重启策略为OnFailure 或 Never 的 Pod。
- 对预期不会终止的 Pod 使用 ReplicationController、ReplicaSet 和Deployment ,例如 Web 服务器。 ReplicationController 仅适用于具有restartPolicy 为 Always 的 Pod。
- 提供特定于机器的系统服务,使用 DaemonSet 为每台机器运行一个 Pod 。
readiness实例
liveness实例

六、控制器
Pod 的分类:
- 自主式 Pod:Pod 退出后不会被创建
- 控制器管理的 Pod:在控制器的生命周期里,始终要维持 Pod 的副本数目
控制器类型:
- Replication Controller和ReplicaSet
- Deployment
- DaemonSet
- StatefulSet
- Job
- CronJob
- HPA全称Horizontal Pod Autoscaler
Replication Controller和ReplicaSet
- ReplicaSet 是下一代的 Replication Controller,官方推荐使用ReplicaSet。
- ReplicaSet 和 Replication Controller 的唯一区别是选择器的支持,ReplicaSet 支持新的基于集合的选择器需求。
- ReplicaSet 确保任何时间都有指定数量的 Pod 副本在运行。
- 虽然 ReplicaSets 可以独立使用,但今天它主要被Deployments 用作协调 Pod 创建、删除和更新的机制。
Deployment
- Deployment 为 Pod 和 ReplicaSet 提供了一个申明式的定义方法。
- 典型的应用场景:
- 用来创建Pod和ReplicaSet
- 滚动更新和回滚
- 扩容和缩容
- 暂停与恢复
DaemonSet
- DaemonSet 确保全部(或者某些)节点上运行一个 Pod 的副本。当有节点加入集群时, 也会为他们新增一个 Pod 。当有节点从集群移除时,这些Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod。
- DaemonSet 的典型用法:
- 在每个节点上运行集群存储 DaemonSet,例如 glusterd、ceph。
- 在每个节点上运行日志收集 DaemonSet,例如 fluentd、logstash。
- 在每个节点上运行监控 DaemonSet,例如 Prometheus Node Exporter、zabbix agent等
- 一个简单的用法是在所有的节点上都启动一个 DaemonSet,将被作为每种类型的 daemon 使用。
- 一个稍微复杂的用法是单独对每种 daemon 类型使用多个 DaemonSet,但具有不同的标志, 并且对不同硬件类型具有不同的内存、CPU 要求。
StatefulSet
- StatefulSet 是用来管理有状态应用的工作负载 API 对象。实例之间有不对等关系,以及实例对外部数据有依赖关系的应用,称为“有状态应用”
- StatefulSet 用来管理 Deployment 和扩展一组 Pod,并且能为这些 Pod 提供*序号和唯一性保证*。
- StatefulSets 对于需要满足以下一个或多个需求的应用程序很有价值:
- 稳定的、唯一的网络标识符。
- 稳定的、持久的存储。
- 有序的、优雅的部署和缩放。
- 有序的、自动的滚动更新。
Job
- 执行批处理任务,仅执行一次任务,保证任务的一个或多个Pod成功结束。
CronJob
- Cron Job 创建基于时间调度的 Jobs。
- 一个 CronJob 对象就像 crontab (cron table) 文件中的一行,它用 Cron 格式进行编写,并周期性地在给定的调度时间执行 Job。
HPA
- 根据资源利用率自动调整service中Pod数量,实现Pod水平自动缩放。
ReplicaSet控制器



Deployment控制器



缩容
kubectl scale deployment deployment-nginx --replicas=2 --record
更新
kubectl set image deployment deployment-nginx nginx=nginx:v1 --record![]()
查看历史版本
kubectl rollout history deployment
回滚
kubectl rollout undo deployment deployment-nginx --to-revision=1

回滚状态
kubectl rollout status deployment deployment-nginx
![]()

DaemonSet控制器



Job控制器

cronjob

kubectl create -f cronjob-test.yaml kubectl get cronjobs.batch
kubectl get pod
kubectl logs cronjob-example-1593150780-vg4lj
七、service
- Service可以看作是一组提供相同服务的Pod对外的访问接口。借助Service,应用可以方便地实现服务发现和负载均衡。
- service默认只支持4层负载均衡能力,没有7层功能。(可以通过Ingress实现)
- service的类型:
- ClusterIP:默认值,k8s系统给service自动分配的虚拟IP,只能在集群内部访问。
- NodePort:将Service通过指定的Node上的端口暴露给外部,访问任意一个
- NodeIP:nodePort都将路由到ClusterIP。
- LoadBalancer:在 NodePort 的基础上,借助 cloud provider 创建一个外部的负载均衡器,并将请求转发到 <NodeIP>:NodePort,此模式只能在云服务器上使用。
- ExternalName:将服务通过 DNS CNAME 记录方式转发到指定的域名(通过spec.externlName 设定)。
- Service 是由 kube-proxy 组件,加上 iptables 来共同实现的.
- kube-proxy 通过 iptables 处理 Service 的过程,需要在宿主机上设置相当多的iptables 规则,如果宿主机有大量的Pod,不断刷新iptables规则,会消耗大量的CPU资源。
- IPVS模式的service,可以使K8s集群支持更多量级的Pod。
开启kube-proxy的ipvs模式:
所有节点安装
yum install -y ipvsadm
修改IPVS模式
kubectl edit cm kube-proxy -n kube-system
![]()
更新kube-proxy pod
kubectl get pod -n kube-system |grep kube-proxy | awk '{system("kubectl delete pod "$1" -n kube-system")}'
IPVS模式下,kube-proxy会在service创建后,在宿主机上添加一个虚拟网卡: kube-ipvs0,并分配service IP。
ifconfig kube-ipvs0 
kube-proxy通过linux的IPVS模块,以rr轮询方式调度service中的Pod。

Flannel vxlan模式跨主机通信原理

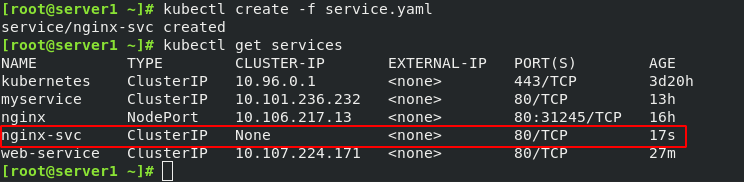
创建service:(ClusterIP方式)
vim service-test.yaml

kubectl create -f service-test.yaml
kubectl describe service web-service

Kubernetes 提供了一个 DNS 插件 Service
kubectl get services kube-dns --namespace=kube-system 
kubectl run test --image=busyboxplus -it

Headless Service “无头服务”
- Headless Service不需要分配一个VIP,而是直接以DNS记录的方式解析出被代理Pod的IP地址。
- 域名格式:$(servicename).$(namespace).svc.cluster.local
Headless Service 示例:

yum install -y bind-utils-9.9.4-72.el7.x86_64

dig -t A nginx-svc.default.svc.cluster.local @10.96.0.10

Pod滚动更新后,依然可以解析:
kubectl delete pod --all
dig -t A nginx-svc.default.svc.cluster.local @10.96.0.10

创建service:(NodePort方式)
vim service-example.yaml
kubectl create -f service-test.yaml
kubectl get services my-nginx

从外部访问 Service 的第二种方式,适用于公有云上的 Kubernetes 服务。这时候,你可以指定一个 LoadBalancer 类型的Service
vim lb-service.yaml
在service提交后,Kubernetes就会调用 CloudProvider 在公有云上为你创建一个负载均衡服务,并且把被代理的 Pod 的 IP地址配置给负载均衡服务做后端。


从外部访问的第三种方式叫做ExternalName
vim ex-service.yaml
kubectl create -f ex-service.yaml
dig -t A my-service.default.svc.cluster.local @10.96.0.10

service允许为其分配一个公有IP
vim ex-service.yaml
kubectl create -f ex-service.yaml
kubectl get services ex-service


ingress-nginx

- 一种全局的、为了代理不同后端 Service 而设置的负载均衡服务,就是 Kubernetes 里的Ingress 服务。
- Ingress由两部分组成:Ingress controller和Ingress服务。
- Ingress Controller 会根据你定义的 Ingress 对象,提供对应的代理能力。业界常用的各种反向代理项目,比如 Nginx、HAProxy、Envoy、Traefik 等,都已经为Kubernetes 专门维护了对应的 Ingress Controller。
官网: https://kubernetes.github.io/ingress-nginx/
应用ingress controller定义文件
kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/nginx-0.30.0/deploy/static/mandatory.yaml
应用ingress-service定义文件
kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/nginx-0.30.0/deploy/static/provider/baremetal/service-nodeport.yaml![]()
kubectl -n ingress-nginx get pod
kubectl -n ingress-nginx get services

创建ingress服务:
vim ingress.yaml
kubectl apply -f ingress.yaml
kubectl get ingresses.
用DaemonSet结合nodeselector来部署ingress-controller到特定的node上,然后使用HostNetwork直接把该pod与宿主机node的网络打通,直接使用宿主机的80/433端口就能访问服务。
- 优点是整个请求链路最简单,性能相对NodePort模式更好。
- 缺点是由于直接利用宿主机节点的网络和端口,一个node只能部署一个ingress-controller pod。
- 比较适合大并发的生产环境使用。

修改ingress controller部署文件
vim mandatory.yaml ##我已经将需要的镜像下载上传到harbor仓库,所以这里使用harbor仓库
设置ingress controller节点的标签
kubectl label nodes server6 type=ingress
![]()
应用更新配置
kubectl -n ingress-nginx delete deployments.apps nginx-ingress-controller ![]()
kubectl apply -f mandatory.yaml
Ingress TLS 配置
openssl req -x509 -sha256 -nodes -days 365 -newkey rsa:2048 -keyout tls.key -out tls.crt -subj "/CN=nginxsvc/O=nginxsvc"
kubectl create secret tls tls-secret --key tls.key --cert tls.crt
vim ingress-https.yaml
Ingress 认证配置
yum install -y httpd-toolshtpasswd -c auth huayu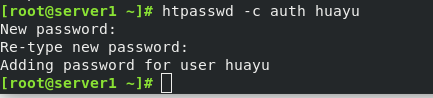
kubectl create secret generic basic-auth --from-file=auth
![]()

vim ingress-auth.yaml
kubectl create -f ingress-auth.yaml![]()
Ingress地址重写
vim ingress-rewrite.yaml
kubectl apply -f ingress-rewrite.yaml 
![]()

annotations参数
















 366
366











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









