







本文大部分内容转载于STD源码剖析并结合个人理解。
VC6 malloc:

cookie是记录分配内存的大小,当使用容器,所有分配的内存一样大就可以去掉;
上图表示当我们申请一个12个字节大小的内存时,实际分配给我们的是0x40的大小。目的是去除冗余的部分
VC6.0标准分配器
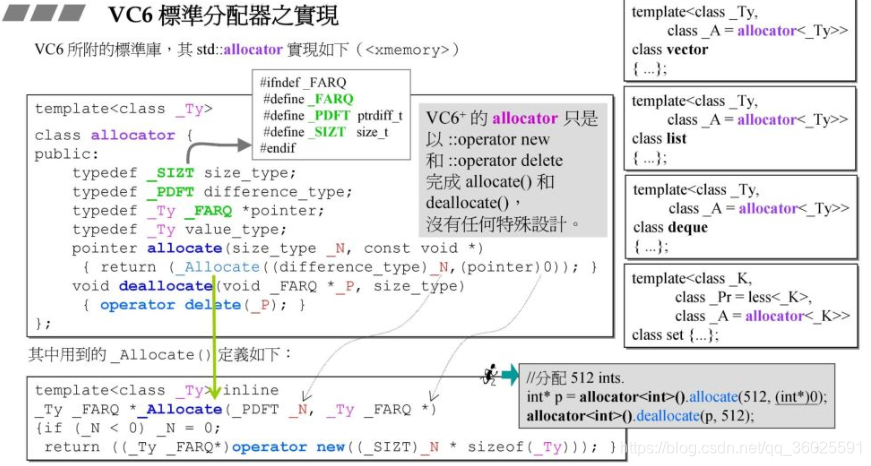
VC6.0的allocate()函数只是对malloc的二次封装,并没有做什么很特殊的操作,它是以类型字节长度为单位分配内存的,上图就分配了512个int类型空间。
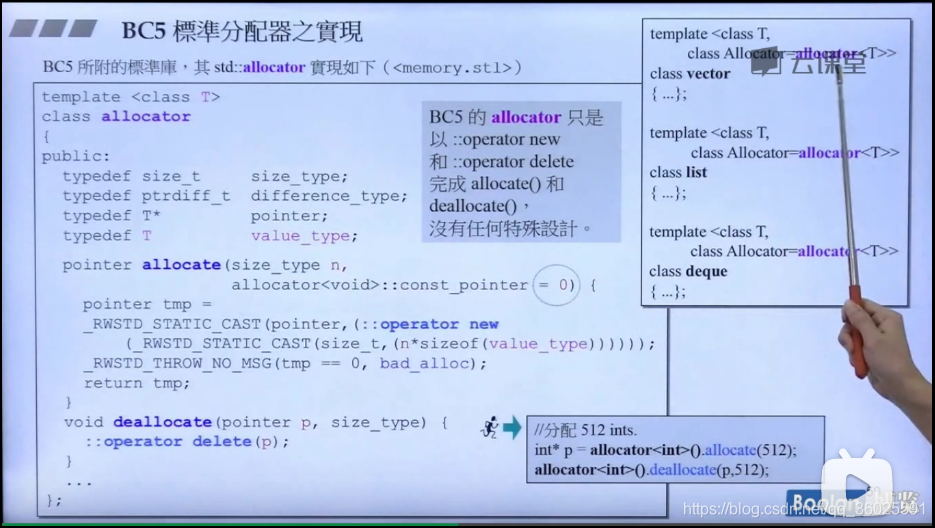
BC5标准分配器
G2.9标准分配器

GCC 2.9版本的allocator如上图所示,同样这里的allocator同前面提到的几个标准分配器一样.
而G2.9容器使用的分配器,不是std::allocator,而是std::alloc.
对于前面提到的malloc设计,如果想要优化,可以减少malloc次数,同时减少cookie.而去除cookie的先决条件是你的cookie大小一致。容器里面的元素是一样的大小,这就满足了先决条件!
分配器的客户不是给你应用程序用,而是给容器用。
G4.9标准分配器
g4.9的__pool_alloc是我们在容器中使用的分配器,而普通的allocator,则是通过operator new 与operator delete调用malloca与free.其实没有什么特殊设计.

测试一下:
采用__gnu_cxx::pool_alloc< double> 分配内存,可以发现容器使用__pool_alloc后,连续地址相差8字节,而一个double类型变量的大小也是8个字节,说明这连续几块内存之间是不带cookie的(即使这几块内存在物理上也是不连续的).而后面那个则相差更多(相差32字节,携带了cookie).
#include <iostream>
#include <vector>
#include <ext/pool_allocator.h>
using namespace std;
template<typename Alloc>
void cookie_test(Alloc alloc, size_t n)
{
typename Alloc::value_type *p1, *p2, *p3; //需有 typename
p1 = alloc.allocate(n); //allocate() and deallocate() 是 non-static, 需以 object 呼叫之.
p2 = alloc.allocate(n);
p3 = alloc.allocate(n);
cout << "p1= " << p1 << '\t' << "p2= " << p2 << '\t' << "p3= " << p3 << '\n';
alloc.deallocate(p1,sizeof(typename Alloc::value_type)); //需有 typename
alloc.deallocate(p2,sizeof(typename Alloc::value_type)); //有些 allocator 對於 2nd argument 的值無所謂
alloc.deallocate(p3,sizeof(typename Alloc::value_type));
}
int main(void)
{
cout << sizeof(__gnu_cxx::__pool_alloc<double>) << endl;
vector<int, __gnu_cxx::__pool_alloc<double> > vecPool;
cookie_test(__gnu_cxx::__pool_alloc<double>(), 1);
cout << "----------------------" << endl;
cout << sizeof(std::allocator<double>) << endl;
vector<int, std::allocator<double> > vecPool2;
cookie_test(std::allocator<double>(), 1);
return 0;
}
输出为:
1
p1= 0x1121c40 p2= 0x1121c48 p3= 0x1121c50
----------------------
1
p1= 0x1121d90 p2= 0x1121db0 p3= 0x1121dd0
2.1 G2.9运作模式
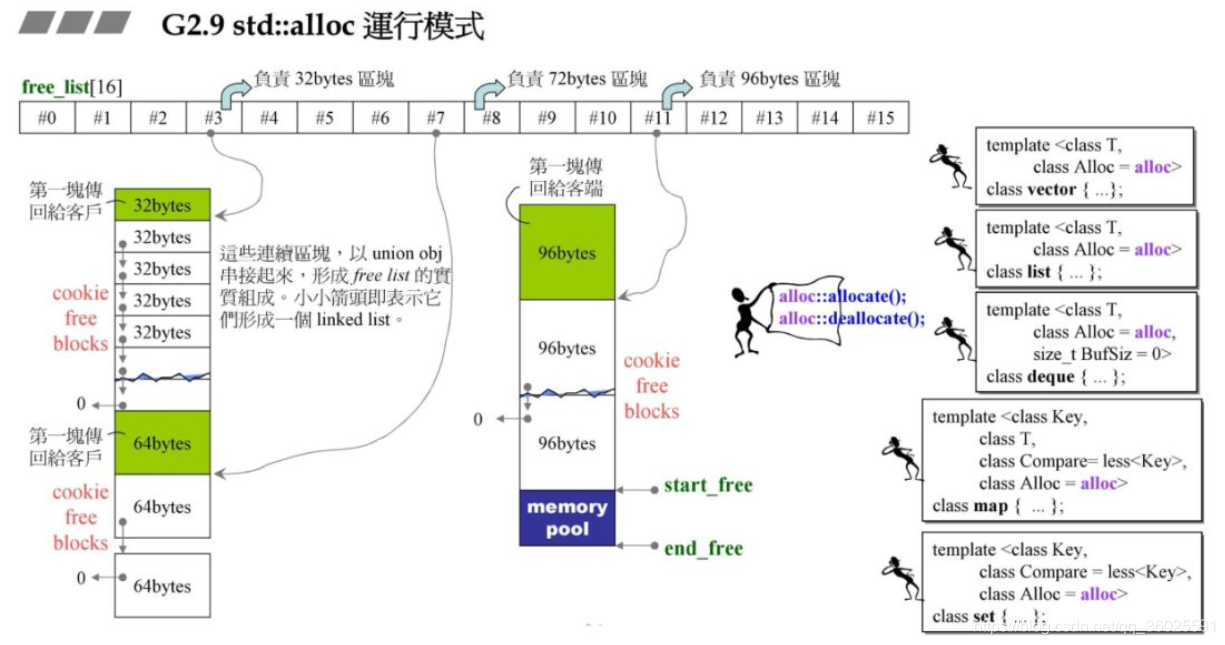
G2.9 std::alloc运作模式使用一个16个携带指针头的数组来管理内存链表,而我们上一章只是用了一条链表。数组不同的元素管理不同的区块,每个元素之间相差8字节,例如#3号元素负责管理32bytes为一小块的链表。
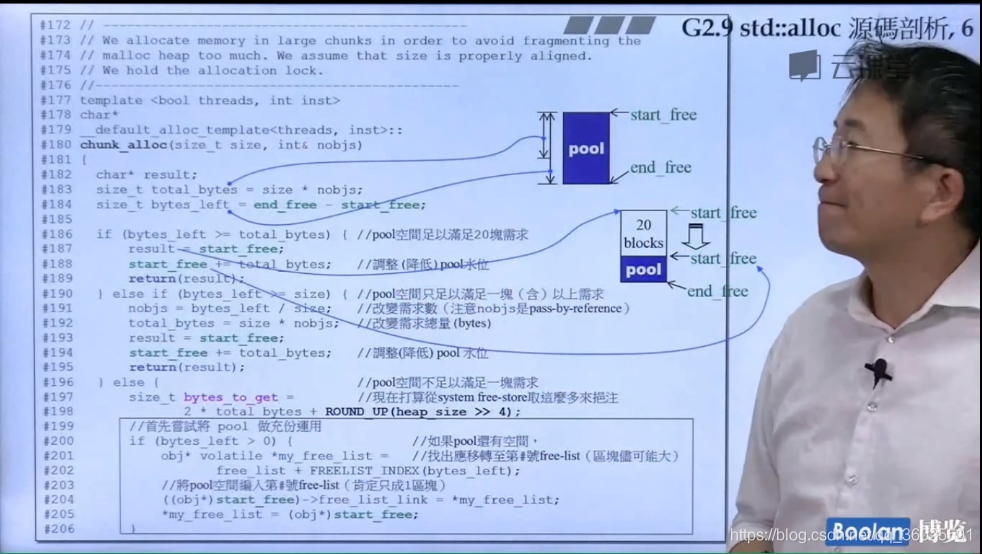
图中pool就是战备池(start_free与end_free中间部分),所以总是把分配的东西放到战备池中,再从战备池挖适当的空间到链表来。这样构思,代码写起来特别漂亮。
假设现在用户需要32字节的内存,std::allloc先申请一块区间,为32202大小,用一条链表管理,然后让数组的#3链表指针管理这条链表。接着讲该以32为一个单元的链表的中的一个单元(32字节)分给用户。(对应图中绿色部分).
为什么是32202?
前面3220空间是分配给用户的,但是后面的3220空间是预留的,如图所示,如果这时用户需要一个64字节的空间,那么剩下的3220空间将变成6410,然后将其中64字节分配给用户,而不用再一次地构建链表和申请空间。其中20是开发团队设计的一个值.
如果该链表组维护的链表最大的一个小块为128byte,但是用户申请内存块超过了128byte,那么std::alloc将调用malloc给用户分配空间,然后该块将带上cookie头和尾。
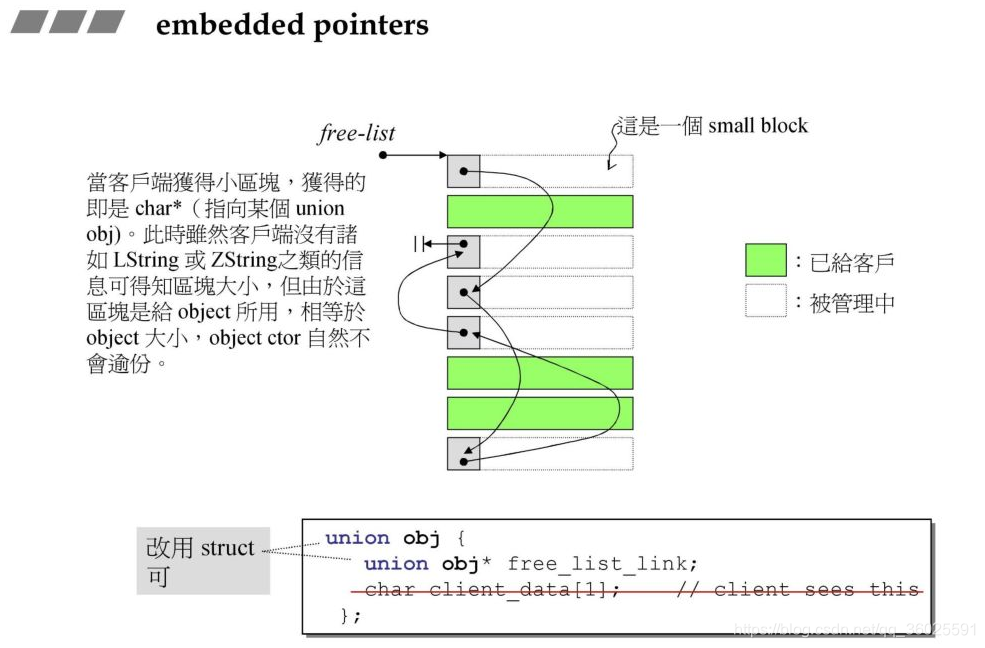
前面一节提到内存管理的核心设计:嵌入式指针.在真正的商业级的内存分配器中,一般都会使用嵌入式指针,将每一个小块的前四个字节用作指针连接下一块可用的内存块。这样不需要多分配额外空间,就可以完成任务.
2.2 std::alloc运行过程

32字节对应#3指针所指向的链表,此时由于战备池为空,故向战备池中充值32202+RoundUp(0>>4=1280),从中切出一块返回给客户,剩余19块,累计申请量有1280字节,战备池有640字节.
RoundUp(累计申请量/16),这是由开发团队设计的,思想应该是越往后面希望通过molloc的内存越大一些。上面这张图计算时的累计申请量为0(这个概念一直没懂,听了两遍才明白)

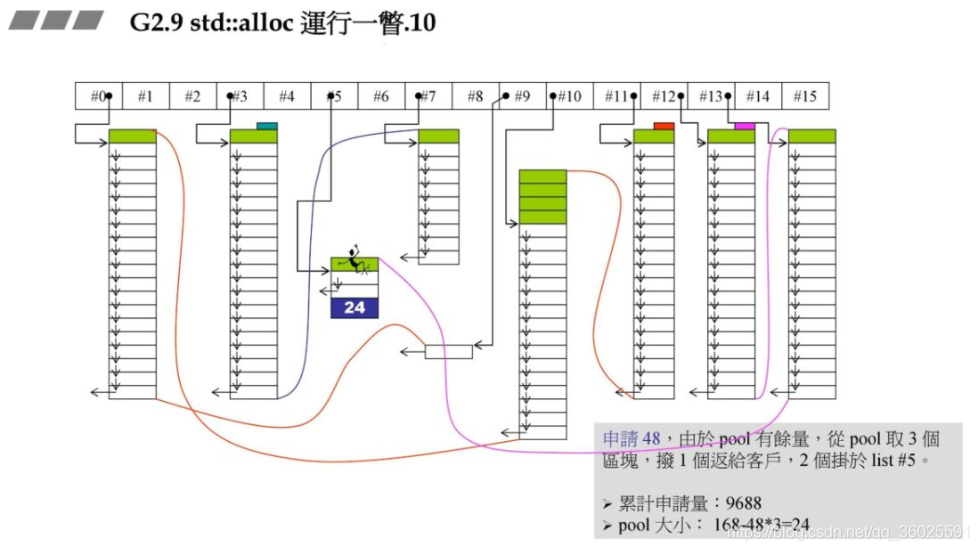
上次的战备池有640字节,下次的分配就会从战备池中取,这次申请64字节,对应到#7链表指针,此时使用战备池中的字节做区块,可以得到10个,从中切出一块返回给用户,剩余9,此时累计申请量:1280,战备池大小此时为0.
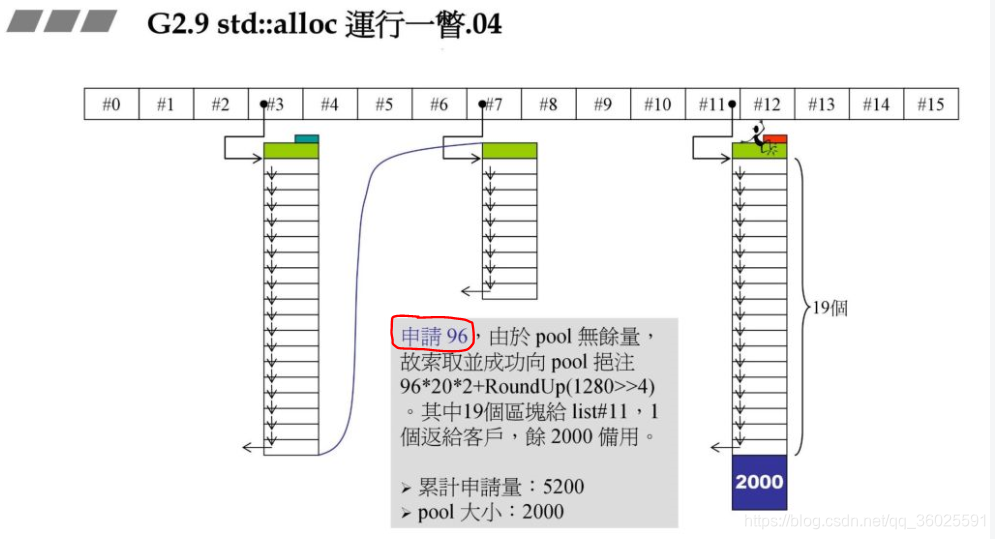
由于战备池中没有余量,此时向战备池中注入96202+RoundUp(1280>>4).其余原理同上.
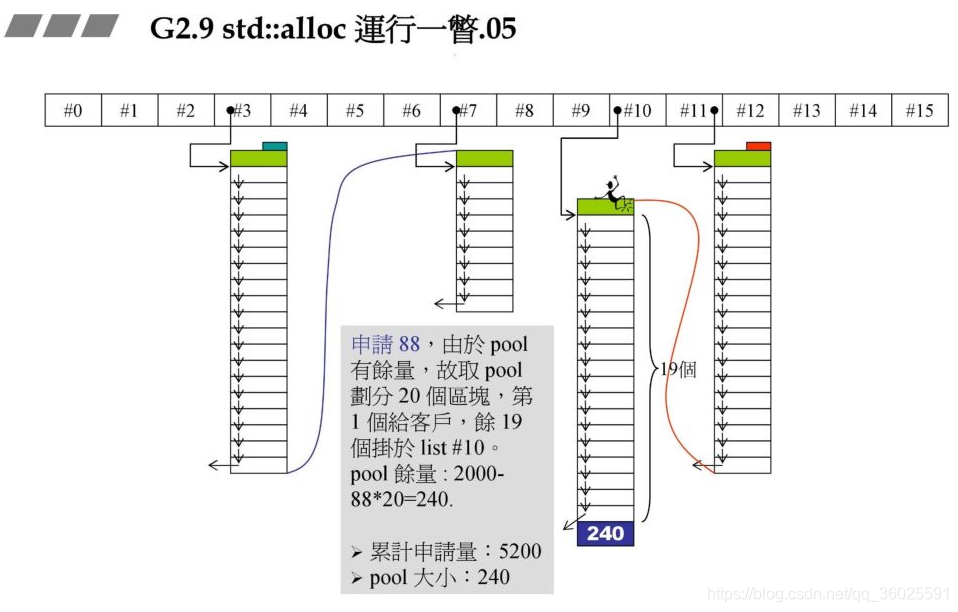
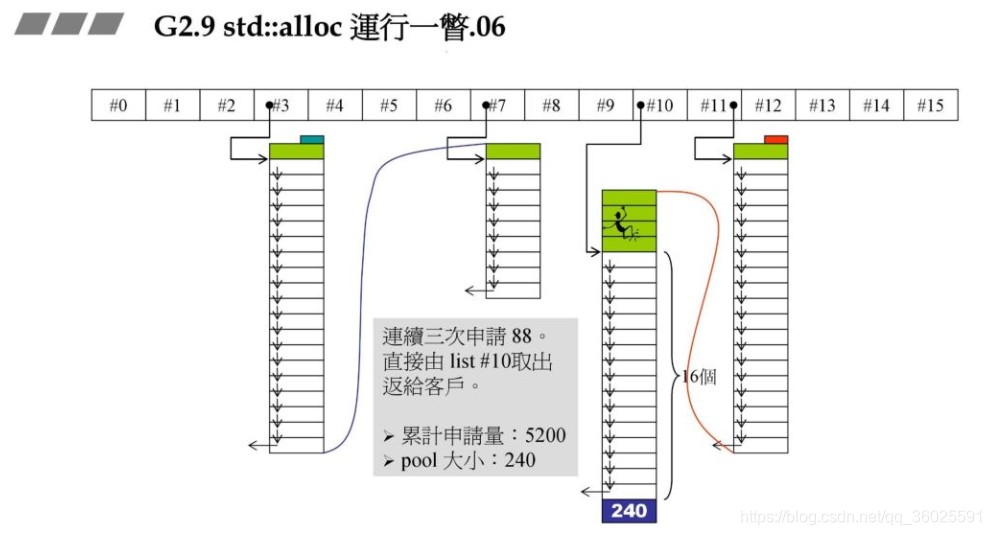
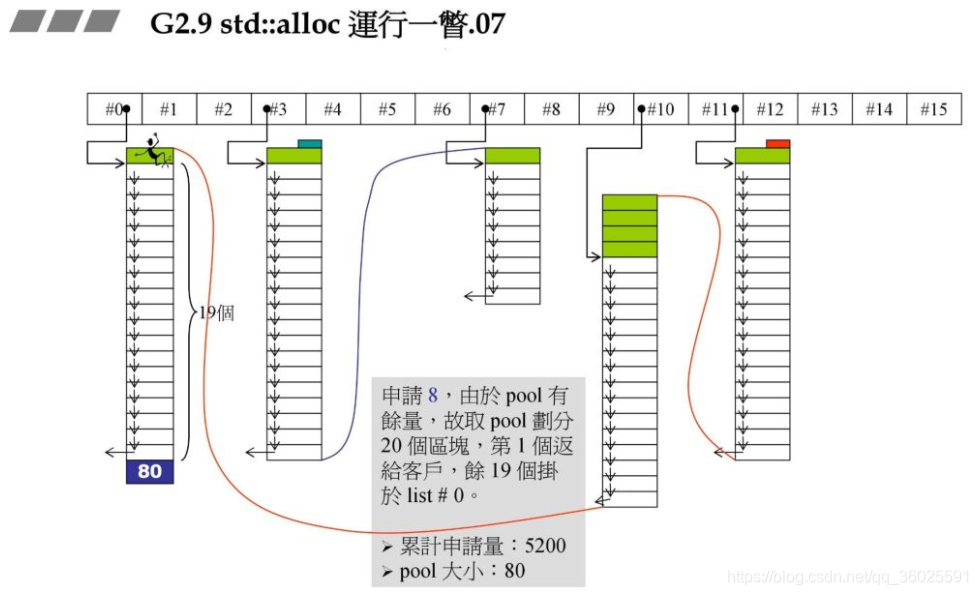

战备池不够了,碎片状态如何处理:
在前面的战备池中还有24字节,此时需要72字节,战备池中1个区块都不能够满足,因此要先解决24区字节碎片,再重新往#8中充值.
碎片处理,24字节对应的是#2,那么把刚才的24字节块拉到#2即可.
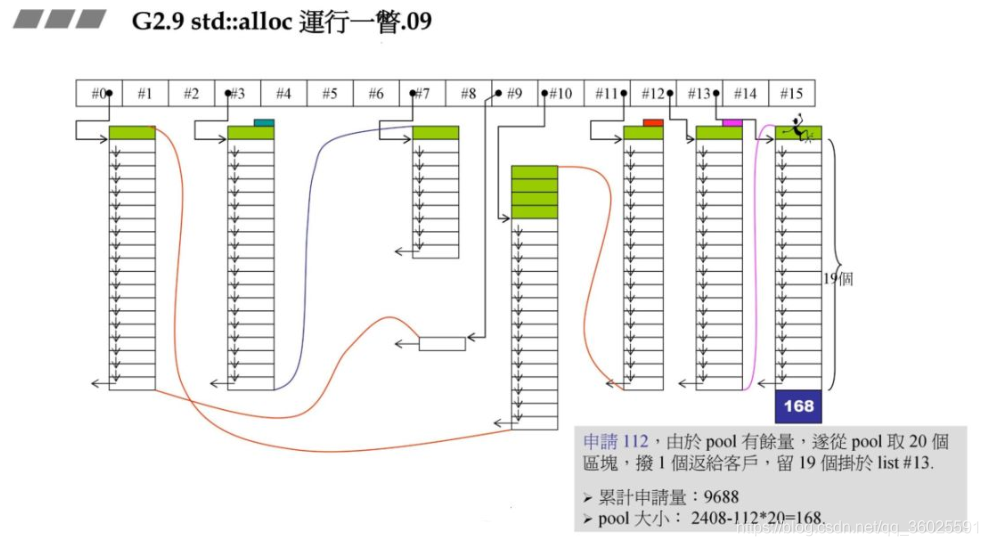
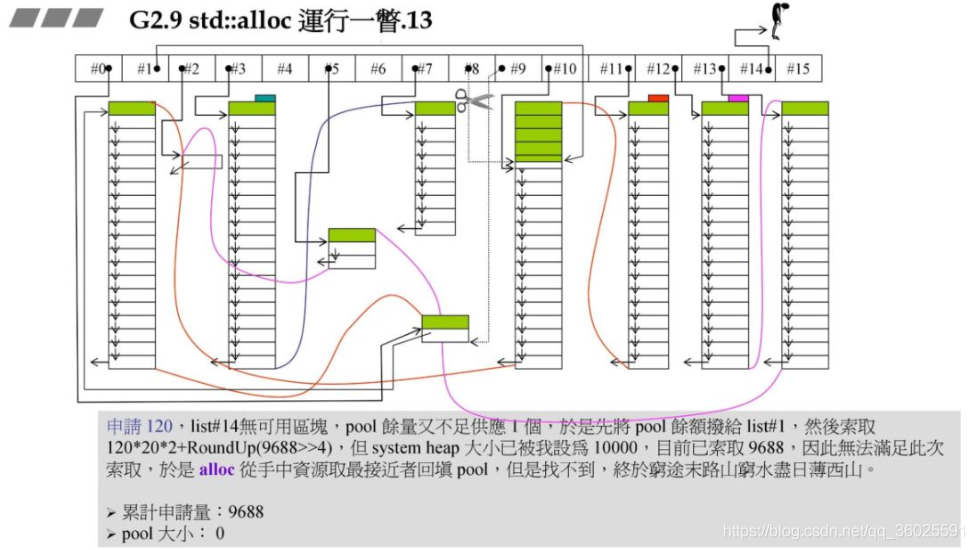
此时要重新往#8中充值,同时此时假设系统的heap大小为10000,此时分配的72202+RoundUp(9688>>4再加上之前的累计申请量,更新后就超过了10000,资源不够了,那此时就需要从后面最近的链表元素借.在上一个图中我们发现#9满足,此时80-72=8,也就是战备池为8.切除了72返回给用户.
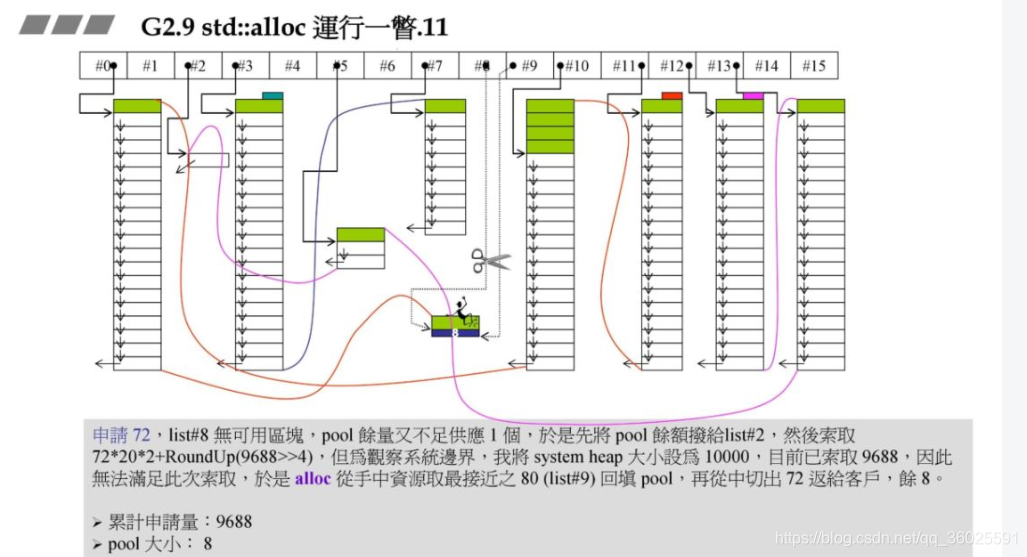
再申请72字节原理结合了碎片处理与上面的资源限制处理:
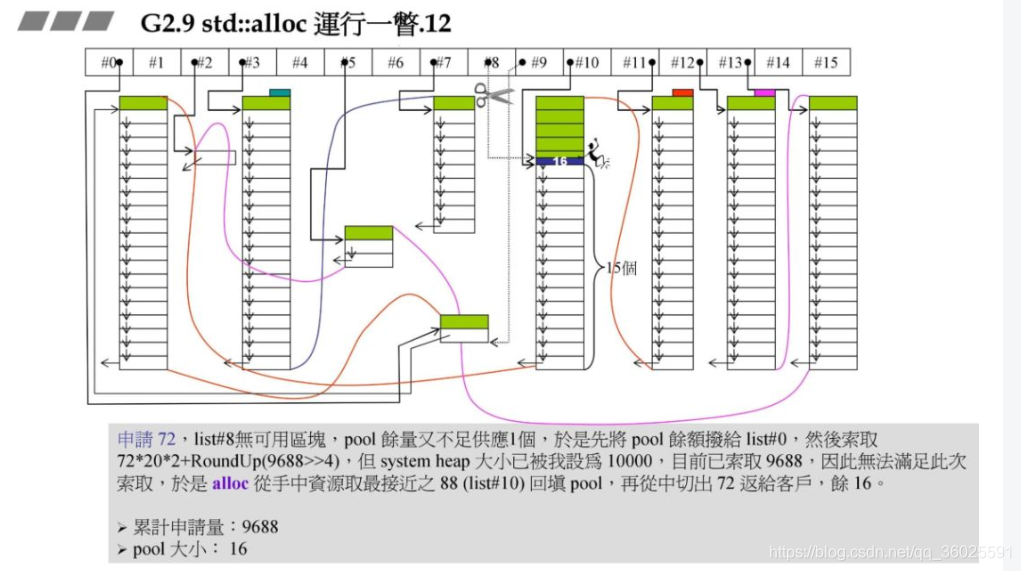
此时申请120字节,对应#14,根据上述原理,此时已经山穷水尽!
3.std::allloc源码剖析
在G2.9中有std::alloc的第一级分配器与第二级分配器,在G4.9中只有前面的第二级分配器。
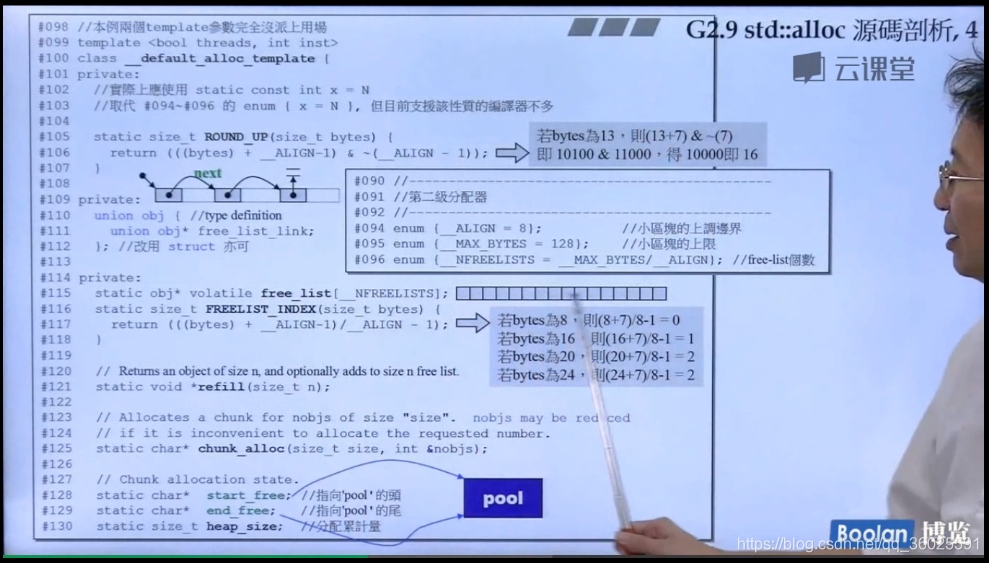
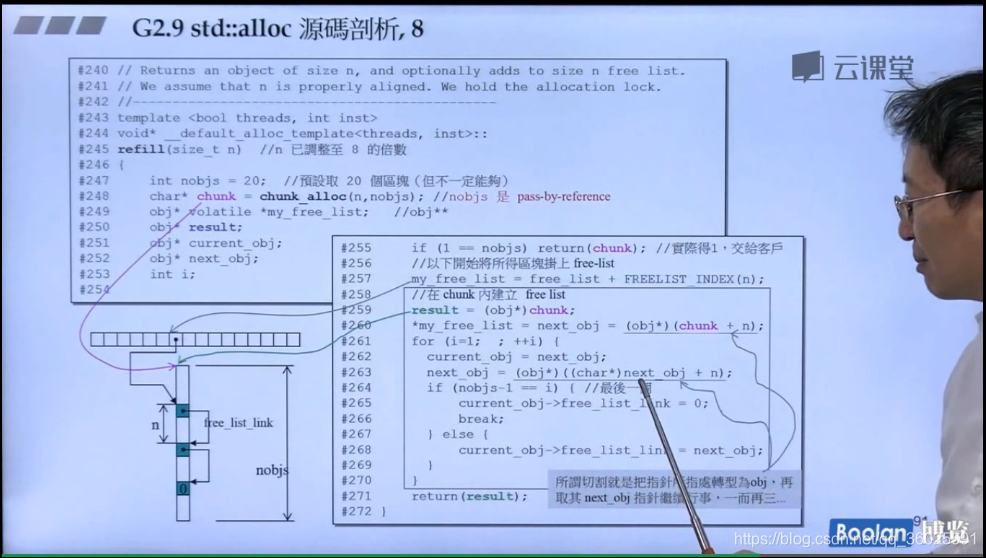
上面是G2.9的源码,其中分配器为__default_alloc_template,一开始默认使用的分配器,在该类中定义了ROUND_UP函数,用来将申请内存数量做8字节对齐。
定义了union free_list_link,嵌入式指针,在上一章中我们构建的一个小的分配器中也定义了该联合体,作用类似,该联合体只有一个成员,因此可以使用struct代替。
free_list是一个有16个obj*元素的数组,在前面讲过,GCC 2.9的分配器用一个16字节数组管理16条链表,free_list便是该管理数组。
start_free和end_free分别指向该内存池的头和尾。中间管理的就是战备池!
对应G4.9源码:
class __pool_alloc_base
{
protected:
enum { _S_align = 8 };
enum { _S_max_bytes = 128 };
enum { _S_free_list_size = (size_t)_S_max_bytes / (size_t)_S_align };
union _Obj
{
union _Obj* _M_free_list_link;
char _M_client_data[1]; // The client sees this.
};
static _Obj* volatile _S_free_list[_S_free_list_size];
// Chunk allocation state.
static char* _S_start_free;
static char* _S_end_free;
static size_t _S_heap_size;
size_t
_M_round_up(size_t __bytes)
{ return ((__bytes + (size_t)_S_align - 1) & ~((size_t)_S_align - 1)); }
_GLIBCXX_CONST _Obj* volatile*
_M_get_free_list(size_t __bytes) throw ();
// Returns an object of size __n, and optionally adds to size __n
// free list.
void*
_M_refill(size_t __n);
// Allocates a chunk for nobjs of size size. nobjs may be reduced
// if it is inconvenient to allocate the requested number.
char*
_M_allocate_chunk(size_t __n, int& __nobjs);
};
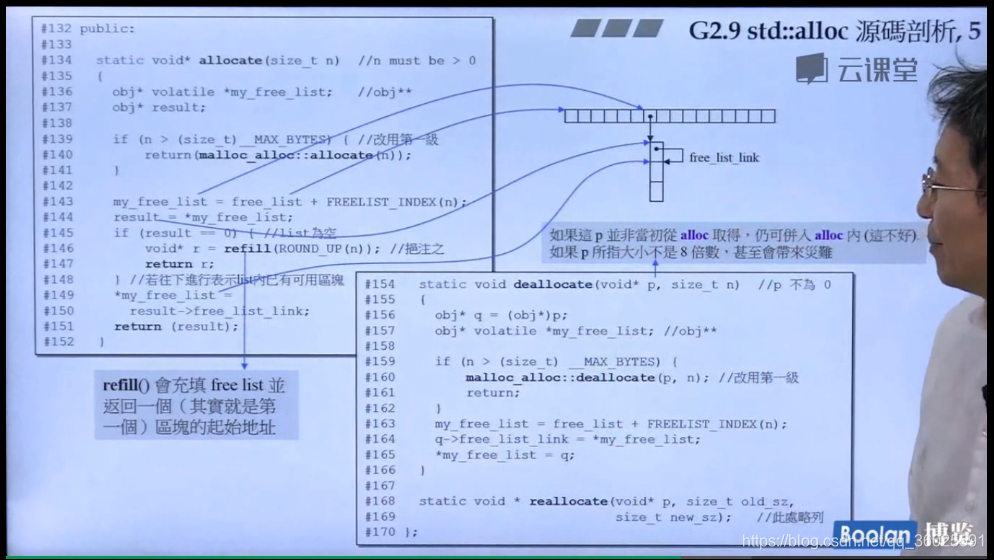
分配过程每次分配一大块内存,存到一个 free list 中,下次 client 若再有相同大小的内存要求,就直接从这个 free list 中划出,内存释放时,则直接回收到对应的 free list 中。
为了管理的方便,实际分配的大小都被调整为 8 的倍数,所以有 16 个 free lists,分别为 8, 16, 24, 32, 40, 48, 56, 64, 72, 80, 88, 96, 104, 112, 120, 128 bytes。例如需要 20 bytes,将会被自动调整为 24 bytes。如果超过了128字节,则需要通过malloc进行分配.
为了节省内存使用,使用 union 结构,这个设计很巧妙,每一个元素(内存区域对象)即可以当作下一个元素的指针,例如后面代码中的 result -> _M_free_list_link,也可以当作该元素的值,例如 *__my_free_list。整个 free lists 的结构便是一串使用后者的元素构成的节点,每个节点的值是使用前者构成的单向链表的首地址















 784
784











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









