






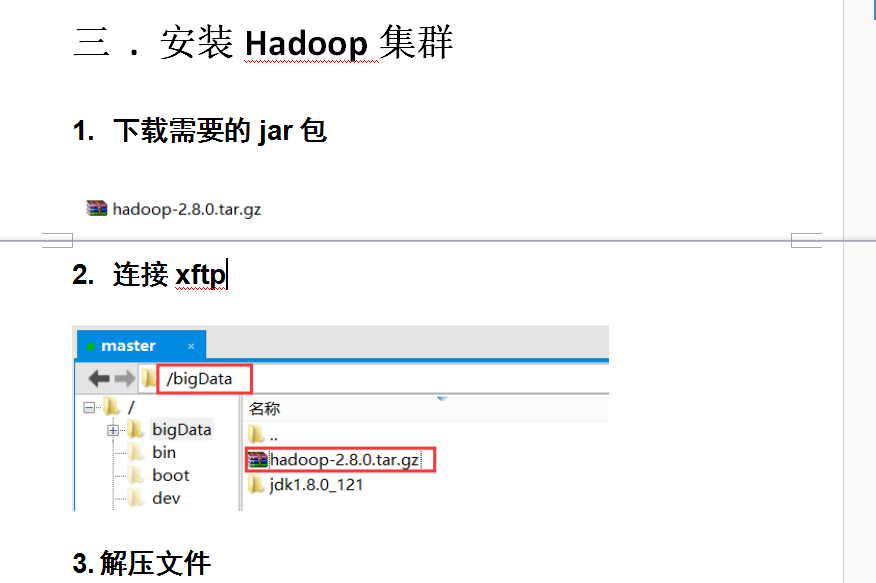
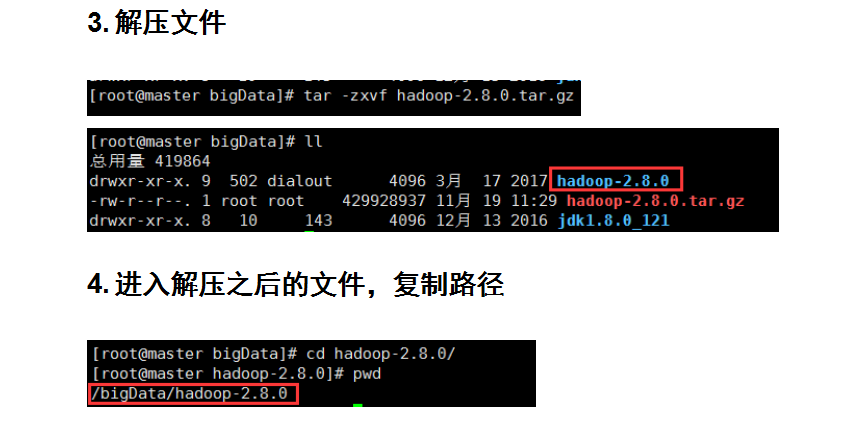
配置Hadoop集群
配置环境变量 /etc/profile
export HADOOP_HOME=/bigData/hadoop-2.8.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

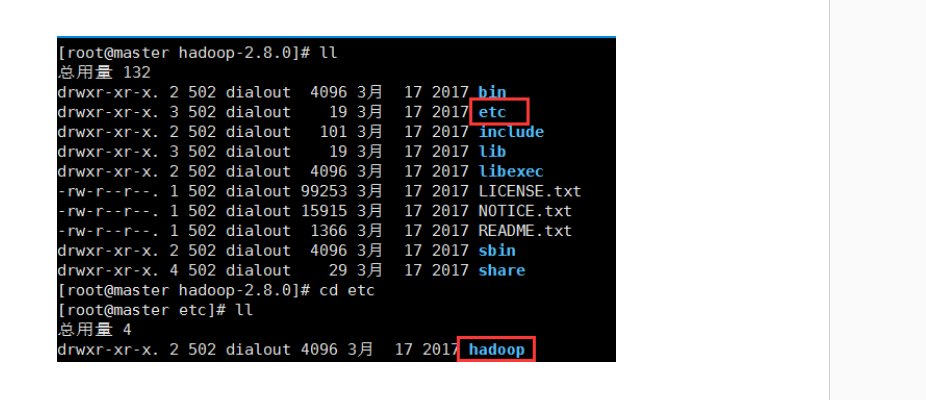
8.配置hadoop-env.sh文件
1> vim hadoop-env.sh
2> 在文件中加入
export JAVA_HOME=/bigData/jdk1.8.0_121
9.配置yarn-env.sh文件
1> vim yarn-env.sh
2> 在文件中加入
export JAVA_HOME=/bigData/jdk1.8.0_121
10. 配置slaves文件
1> vim slaves
2> 删除原有的localhost
3> 在文件中加入
slave1
slave2
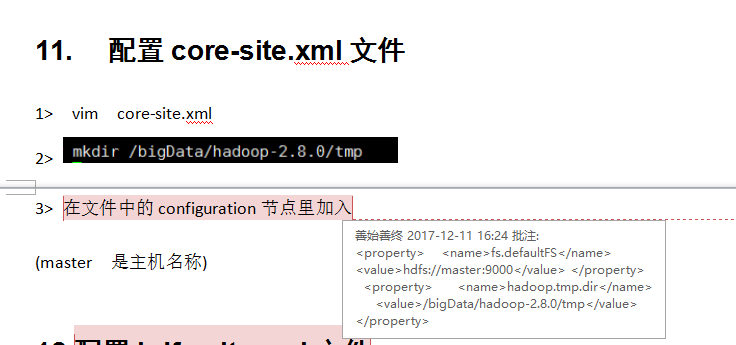
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/bigData/hadoop-2.8.0/tmp</value>
</property>
配置hdfs-site.xml文件
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/bigData/hadoop-2.8.0/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/bigData/hadoop-2.8.0/hdfs/data</value>
</property>
14.配置mapred-site.xml文件
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
14.配置mapred-site.xml文件
1> mapred-site.xml.template 是存在的
mapred-site.xml不存在
注意:先要copy一份
cp mapred-site.xml.template mapred-site.xml
然后编辑 vim mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
15. 把配置好的hadoop文件复制到其他的子机器中
scp -r /bigData/hadoop-2.8.0 root@slave1:/bigData/
scp -r /bigData/hadoop-2.8.0 root@slave2:/bigData/
16. 把配置好的/etc/profile文件复制到其他的子机器中
进行测试 hadoop version
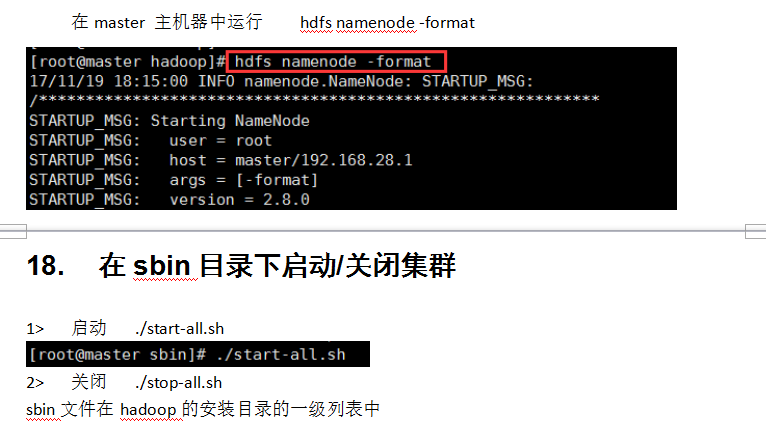
17. 格式化节点
在master 主机器中运行 hdfs namenode -format
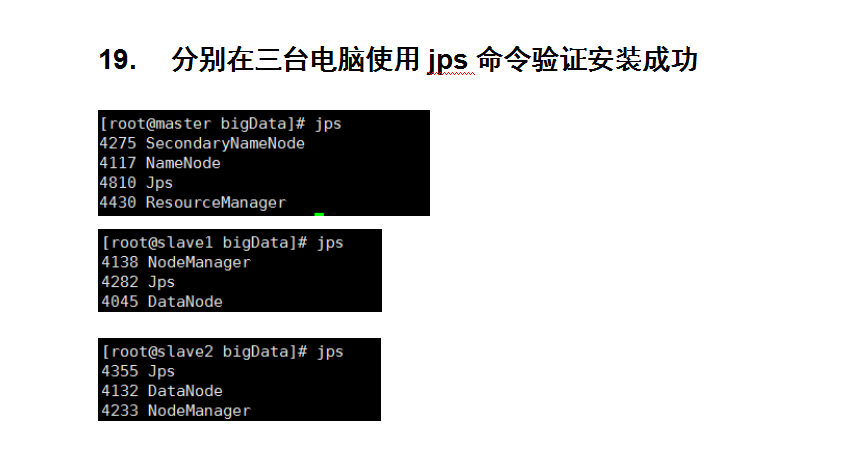
启动
出现上面 的情况 就说明你已经成功了
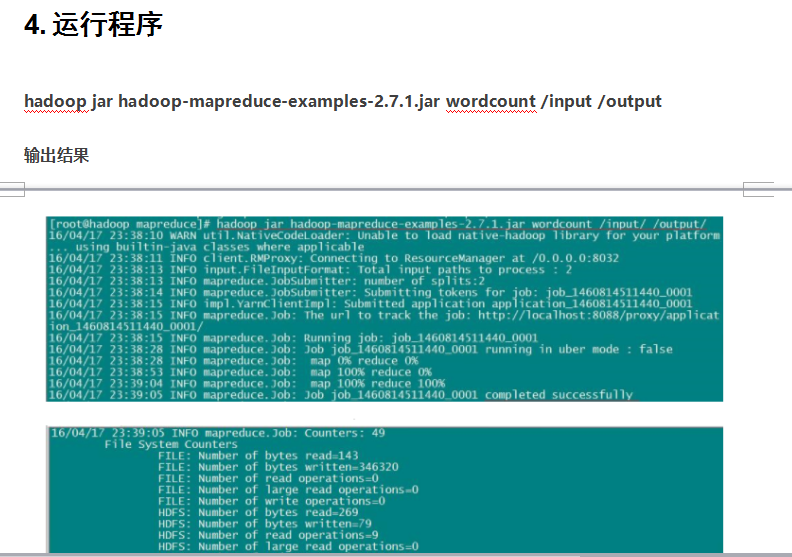
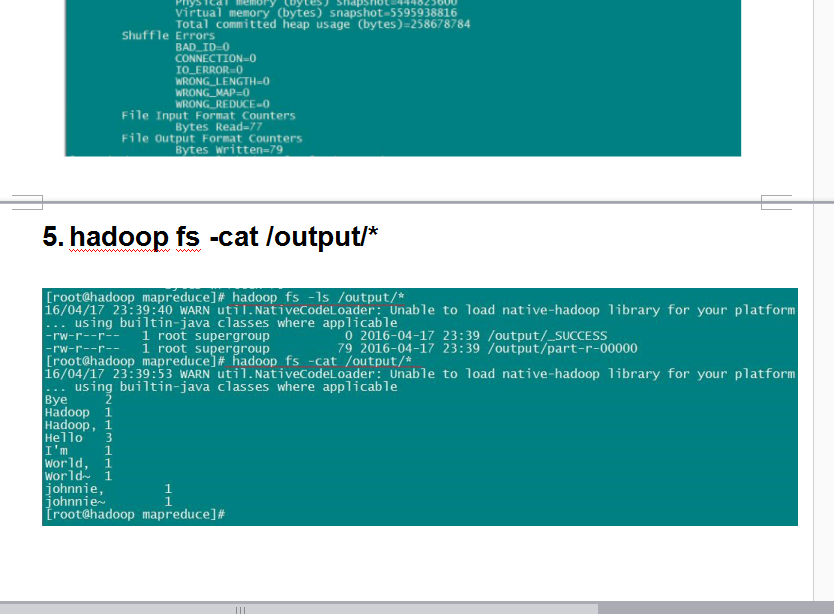
我们接下来 来实现wordcount案例
这个jps可能是假的 例如我们在 master 里面的hdfs目录下面只有一个name文件夹 也可以出现 NameNode节点 但是 里面没东西就是假的 骗你的
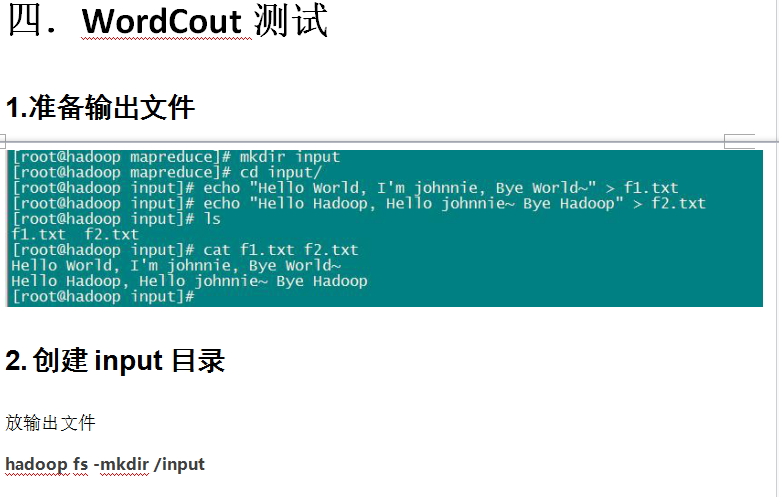
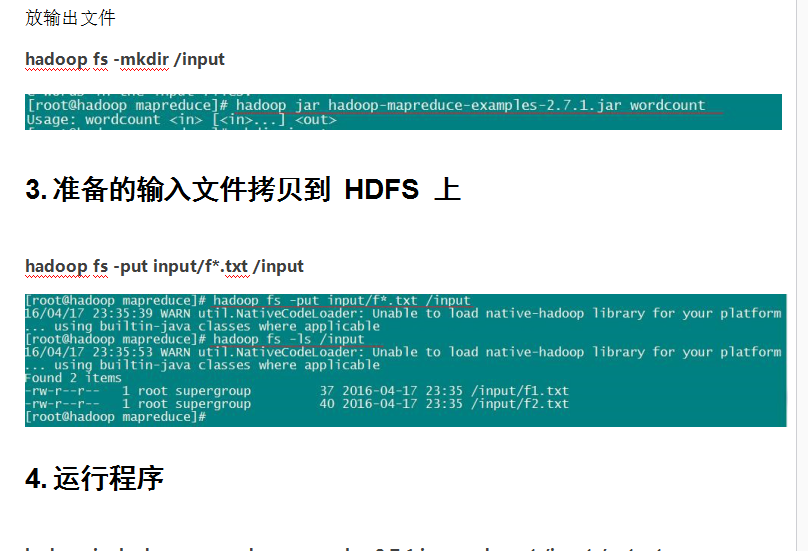
所以我们要wordcount测试















 273
273

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









