







之前是在linux云服务器上的hadoop本地模式实现了wordcount案例:linux云服务器实现wordcount案例
这次改用hadoop的集群模式实现此案例。
- 首先需要确保已完成了Pseudo-Distributed Operation伪分布式搭建,如果没有完成,可参考linux云服务器实现hadoop的Pseudo-Distributed Operation伪分布式搭建
搭建完成,并执行sbin/start-dfs.sh后,通过jps命令可查看已存在如下进程
31254 DataNode
32007 Jps
31481 SecondaryNameNode
31119 NameNode
- 登录可视化界面http://localhost:9870/,直观查看HDFS的web界面,或者通过命令查看HDFS上的所有文件
hdfs dfs -ls -R /
在没有上传文件的情况下,应该是啥也没有的,这时候我们就可以先创建文件夹hdfs dfs -mkdir -p /sample/wordcount,并将本地的wc.input文件上传至HDFS
hdfs dfs -moveFromLocal /root/software/Hadoop/hadoop-3.3.1/sample/wordcount/wc.input /sample/wordcount
其内容就只是一些文本,随便写些啥都行
hadoop yarn
hadoop mapreduce
atguigu
atguigu
- 此时可以执行命令,生成
wc.output结果文件
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /sample/wordcount/wc.input /sample/wordcount/wc.output
-
在web界面就可以看到如下内容
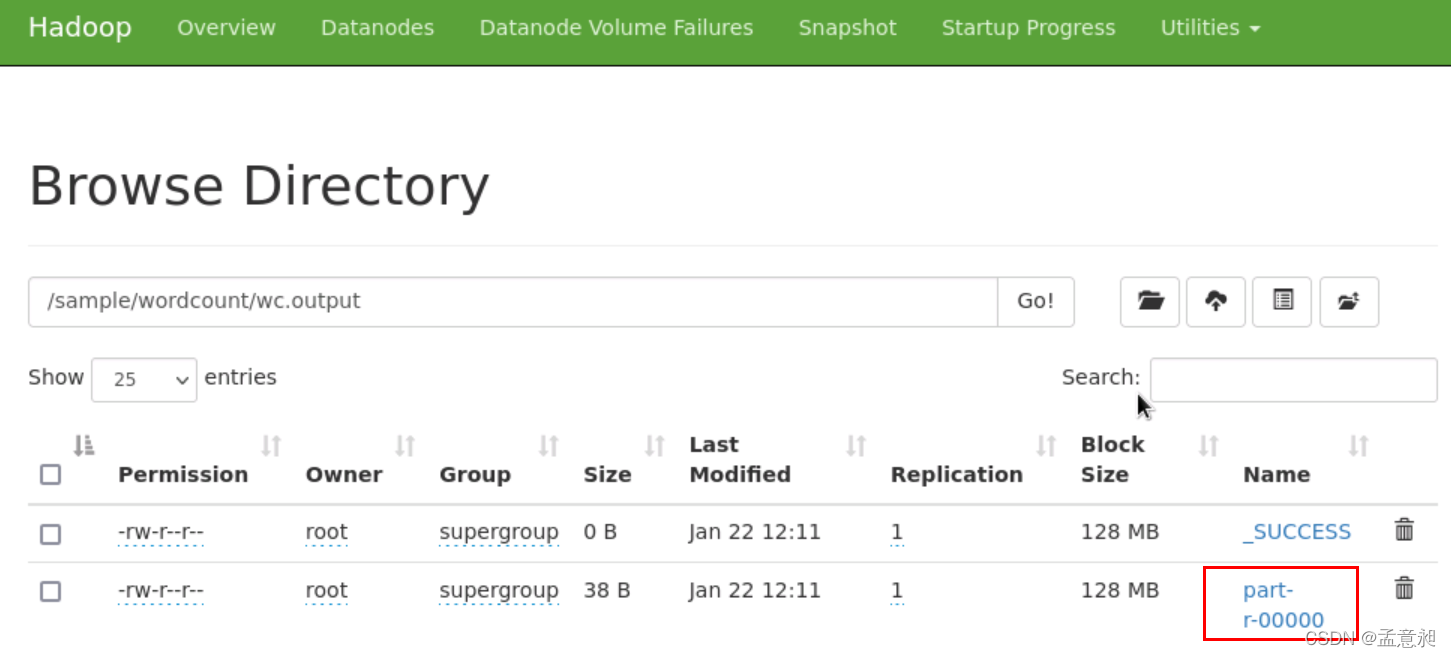
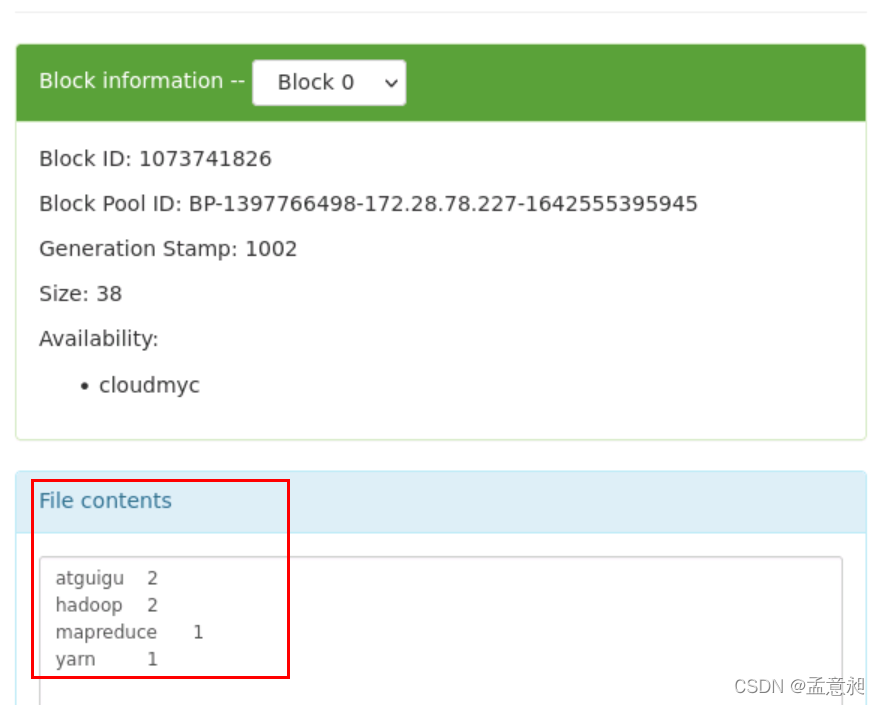
就已经看到对wc.input执行命令后的结果数据,此结果即表示在输入文件夹wcinput内,atguigu和hadoop字符出现的次数为2,mapreduce和yarn出现的次数为1 -
其实到第4步就已经完成了此案例,在操作web界面的时候,可能会出现权限问题,所以单独列一下解决方法,笔者曾出现过截图报错

解决方式是对指定文件夹赋权
hdfs dfs -chmod -R -777 /sample















 2120
2120











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











