







春雨医生问答实例爬虫
好久不更博~
九月中旬过去了 不管怎样 我比赛也都结束了 是时候丰富自己一波了 我说了今搞出来爬虫的 gan起来
那么首先是html文档的获取
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return " "接下来不管我们怎样解析这个html文档结构 解析完了最重要的是我们获得我们想要的内容 最重要的是正则表达式
首先正则语法 正则语法
正则语法
最全正则
然后就是怎么应用啦
Python通过re模块提供对正则表达式的支持。使用re的一般步骤是先使用re.compile()函数,将正则表达式的字符串形式编译为Pattern实例,然后使用Pattern实例处理文本并获得匹配结果(一个Match实例),最后使用Match实例获得信息,进行其他的操作。
举一个简单的例子,在寻找一个字符串中所有的英文字符:
import re
pattern = re.compile('[a-zA-Z]')
result = pattern.findall('as3SiOPdj#@23awe')
print result
# ['a', 's', 'S', 'i', 'O', 'P', 'd', 'j', 'a', 'w', 'e']那么就爬一波春雨医生
我们观察一波网页源码
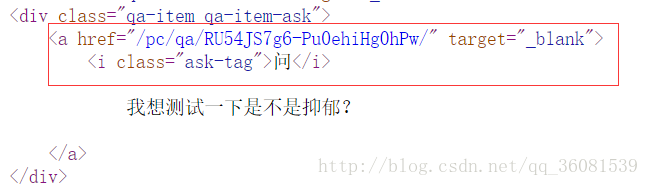

可以看到问答都在i标签中
所以 分别可以这样获取
重要的就是这里
QAQ
re_wen=re.compile(r'(?<=<i class="ask-tag">)[\s\S]*?(?=</a>)')
re_da=re.compile(r'(?<=<div class="qa-item qa-item-answer">)[\s\S]*?(?=</div>)')然后就没了
上代码
#coding:utf-8
import requests
from bs4 import BeautifulSoup
import bs4
import re
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return " "
def main():
depth = 10
start_url = 'http://www.chunyuyisheng.com/pc/search/qalist/?query=%E6%8A%91%E9%83%81 '
infoList = []
re_wen = re.compile(r'(?<=<i class="ask-tag">)[\s\S]*?(?=</a>)')
re_da = re.compile(r'(?<=<div class="qa-item qa-item-answer">)[\s\S]*?(?=</div>)')
for i in range(1, depth):
url = start_url + '&page=' + str(i)
html = getHTMLText(url)
result_a=re_wen.findall(html)
result_b=re_da.findall(html)
for i in range (len(result_a)):
result_a[i]=result_a[i].replace(" ","").replace(r"</i>",':').replace("\n",'').replace("\t",'')
for i in range(len(result_b)):
result_b[i] = result_b[i].replace('<i class="ask-tag answer-tag">', "--").replace("<span class='s-hl'>", '').replace("</span>", "").replace("\t", '').replace(" ","\n")
for i in range(len(result_b)):
print(str(i)+":"+result_a[i]+result_b[i])
main()

















 14万+
14万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









