







 博客围绕好大夫网站爬取的数据展开清洗工作。先明确数据清洗规则,包括服务类型归类、去除缺省部分、格式化数据等。运用Python和Excel等工具,依次完成去除缺省数据、调整服务价格、格式化数据等步骤,强调多工具混用及合理规划步骤可提高效率。
博客围绕好大夫网站爬取的数据展开清洗工作。先明确数据清洗规则,包括服务类型归类、去除缺省部分、格式化数据等。运用Python和Excel等工具,依次完成去除缺省数据、调整服务价格、格式化数据等步骤,强调多工具混用及合理规划步骤可提高效率。
1.前言
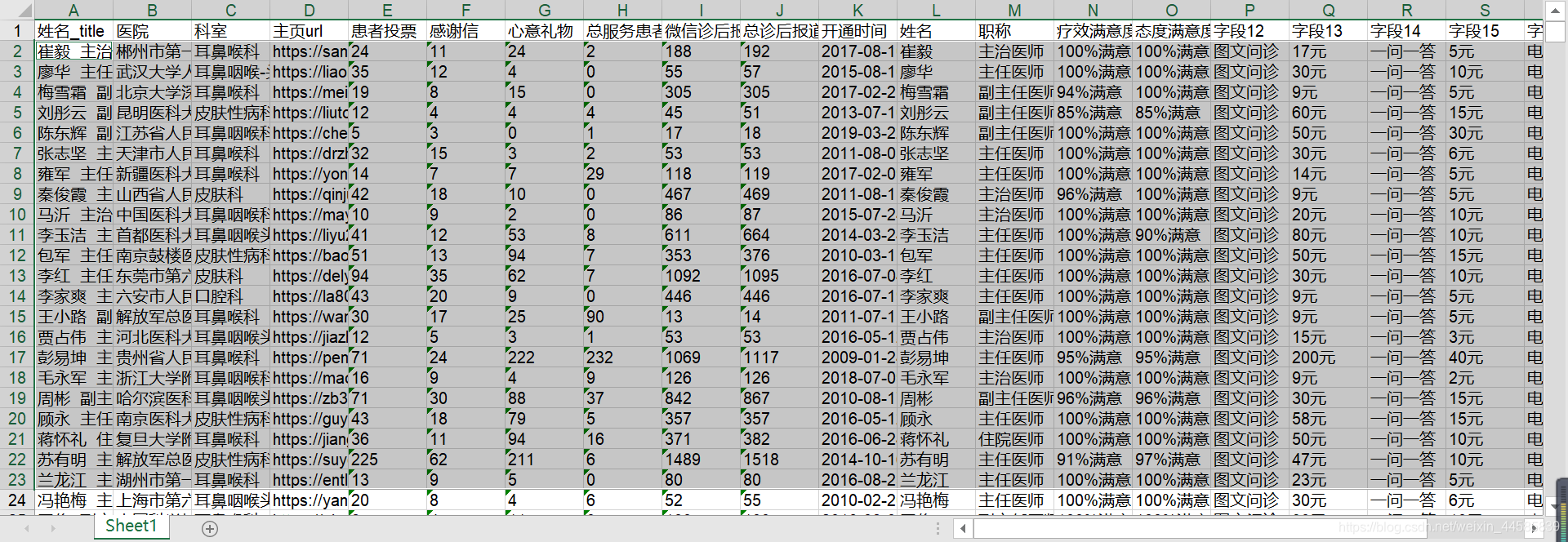
通过对好大夫网站内容的爬取,我们已经收集到好大夫的相关数据,并将其存入excel表中。之所以先存入excel表中,是因为有很多是非结构化数据,需要进行数据清理后在进行保存,excel中有很多的功能能够帮助进行数据清理,下图是获取的数据示例,一共获得20多万条数据。接下来进行数据清洗工作。
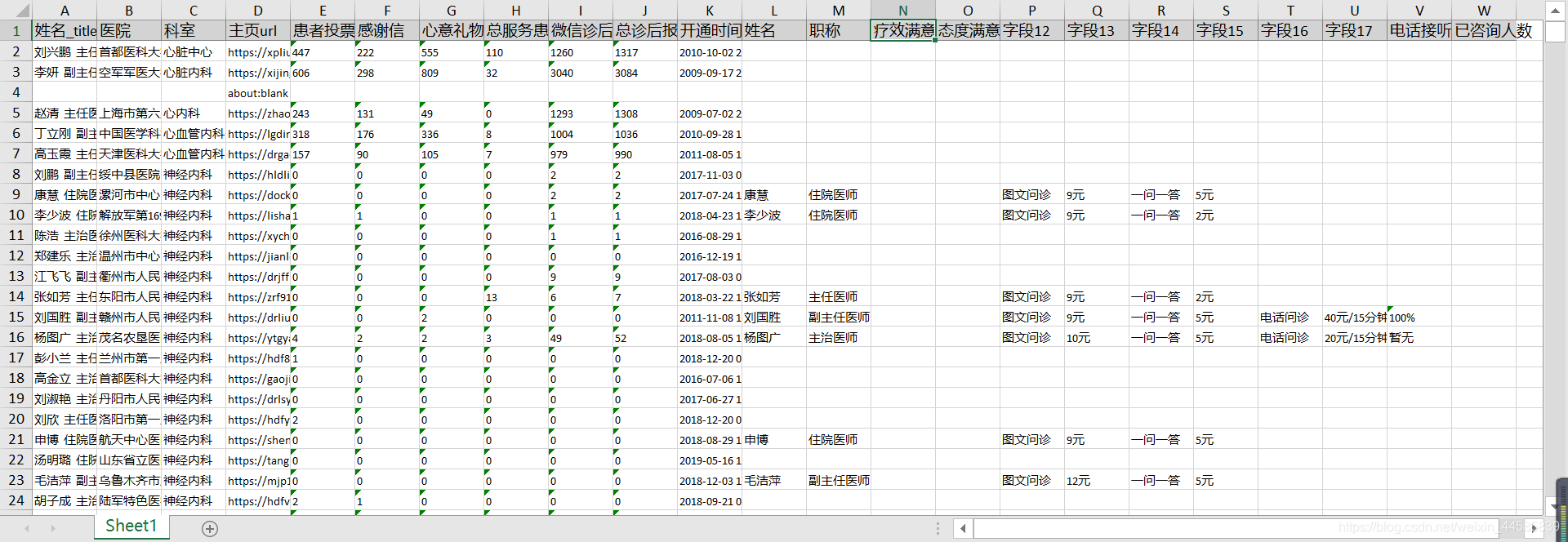
2.数据清洗规则
爬虫爬取的内容为:
- 姓名_title
- 医院
- 科室
- 医生主页url
- 患者投票
- 感谢信
- 心意礼物
- 总服务患者
- 微信诊后报道患者
- 总诊后报道患者
- 开通时间
- 姓名
- 职称
- 疗效满意度
- 态度满意度
- 价格类型1
- 价格类型1价格
- 价格类型2
- 价格类型2价格
- 价格类型3
- 价格类型3价格
- 电话接听率
- 已咨询患者数
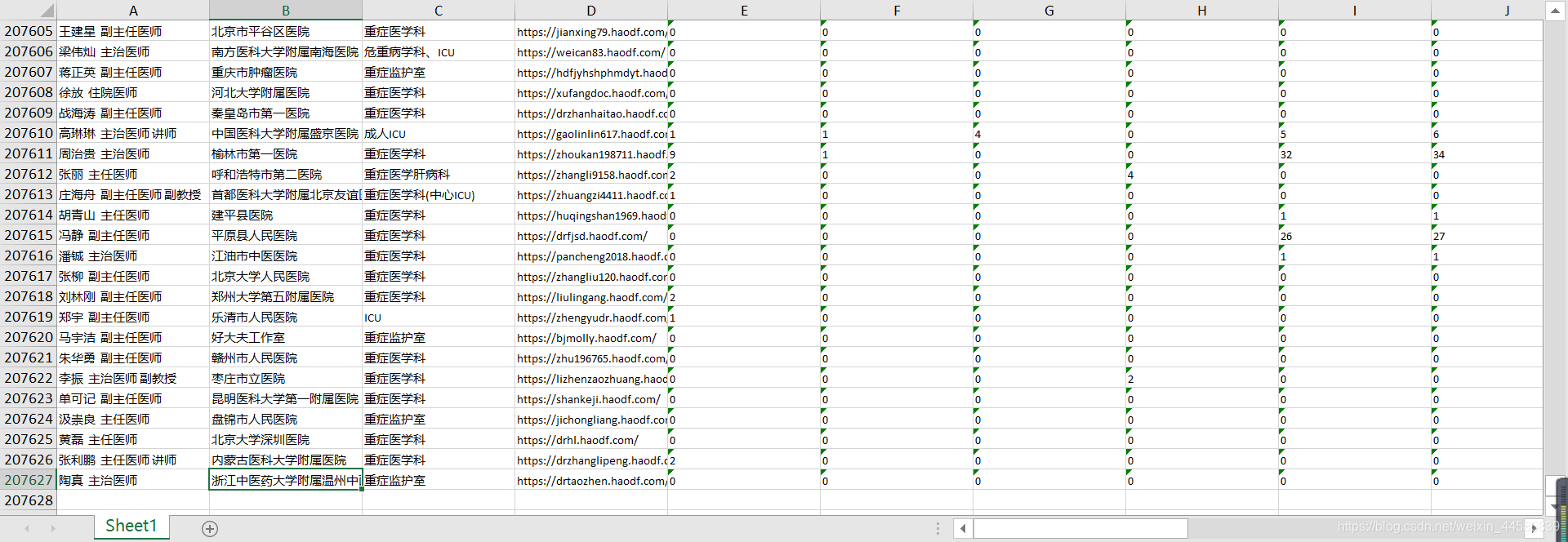
由于爬虫技术问题,再爬价格是并没有区分类型进行归类,因此顺序是乱序的,大致情况如图
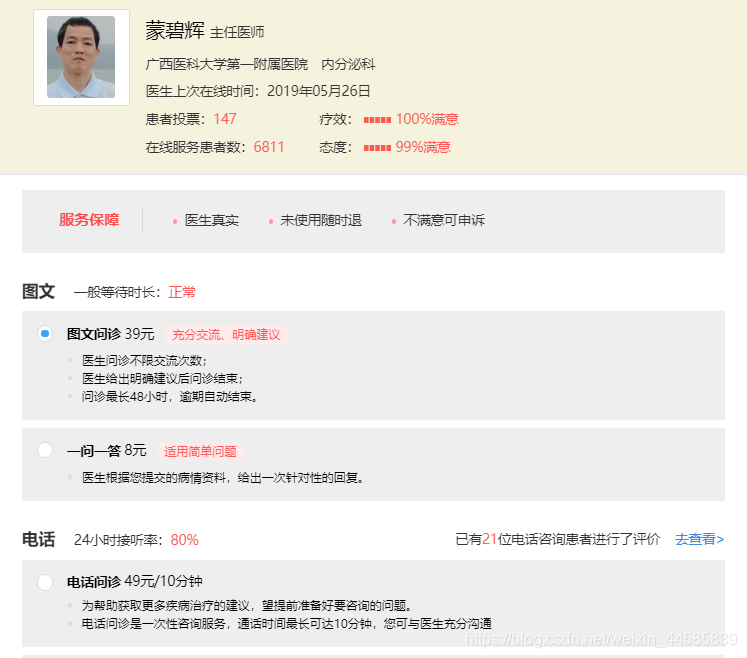
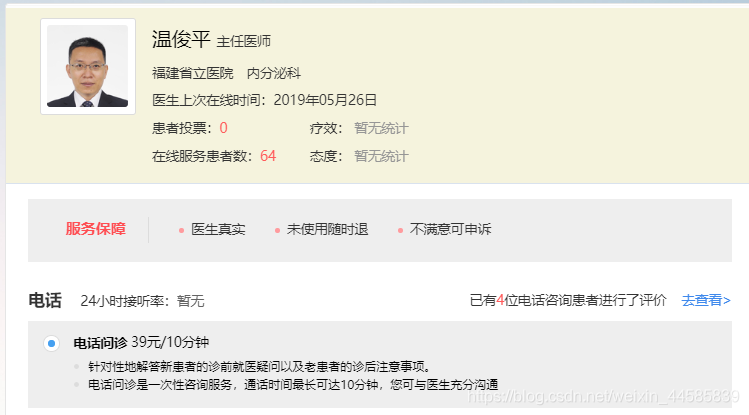
因此,数据清洗任务主要有:
- 对三种类型服务进行归类,分别将价格123对应图文问诊、一问一答、电话问诊
- 删除16 18 20 行,并将17 19 21行对应的title改为对应的服务类型
- 选择合适的记录:如咨询人数或者满意度为空则不适用这条数据
- 格式化数据:1.包括一些数据列由string类型转为int数据类型;2.疗效满意度、态度满意度、电话接听率转为[0,1]数据类型;3.图文问诊、一问一答价格转化为int数据类型,并将电话问诊转化为每小时价格的int数据类型;4.通过开通时间计算开通天数(以2019/05/20为标准点)
3.step1去除缺省部分
这一部分主要针对不符合要求的信息进行筛选,标准是如果已有咨询人数不存在,认定该医生为不活跃医生,则清除这行数据。方法是:使用python对咨询人数进行检索,如为空,清楚该行数据,然后使用excel定位空行并删除。
import xlrd
import xlwt
from xlutils.copy import copy
import os
url = r"C:\Users\lenovo\Desktop\好大夫全部网页数据挖掘.xls"
def dataClear(work_url):
read_workbook = xlrd.open_workbook(work_url)
write_workbook = copy(read_workbook)
sheet_read = read_workbook.sheet_by_index(0)
sheet_write = write_workbook.get_sheet(0)
# 行和列
nrows = sheet_read.nrows
ncols = sheet_read.ncols
for row in range(nrows):
if ((sheet_read.cell(row, 19).value == '' or
sheet_read.cell(row, 13).value == '') or
sheet_read.cell(row, 14).value == ''):
for i in range(ncols):
sheet_write.write(row, i, '')
# 保存
os.remove(work_url)
write_workbook.save(work_url)
if __name__ == '__main__':
dataClear(url)
运行结束的excel表如下:
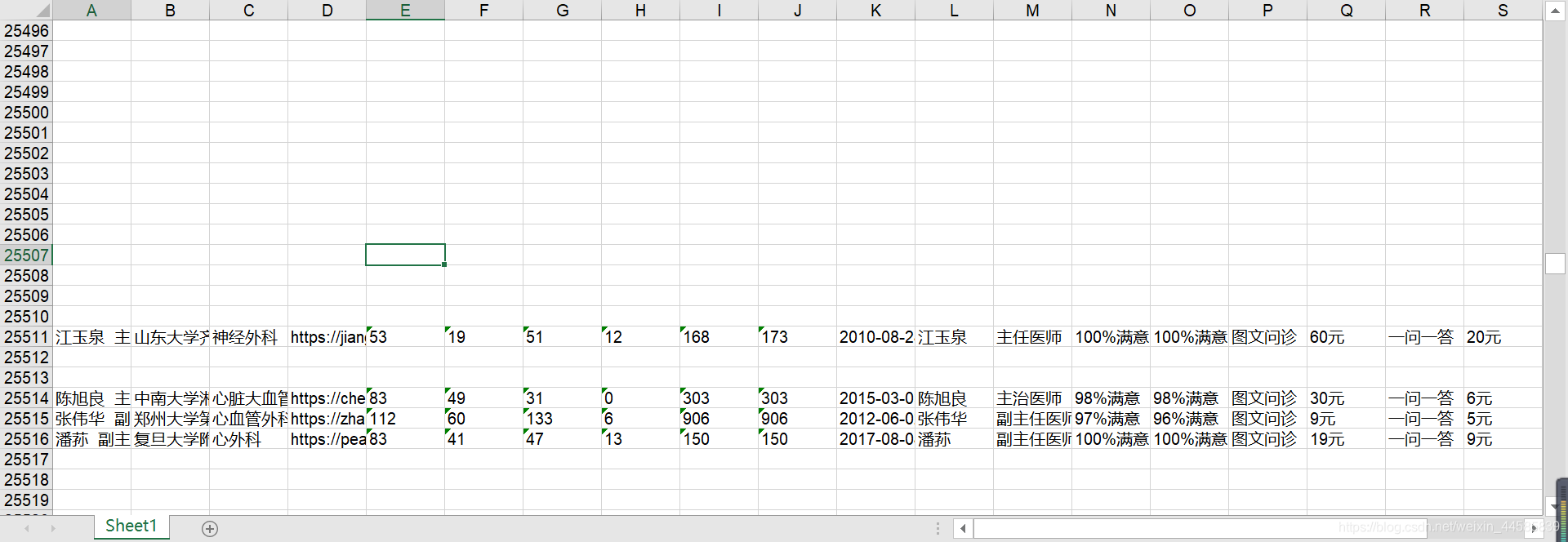
接着再excel表中使用F5定位条件,找到空值进行删除

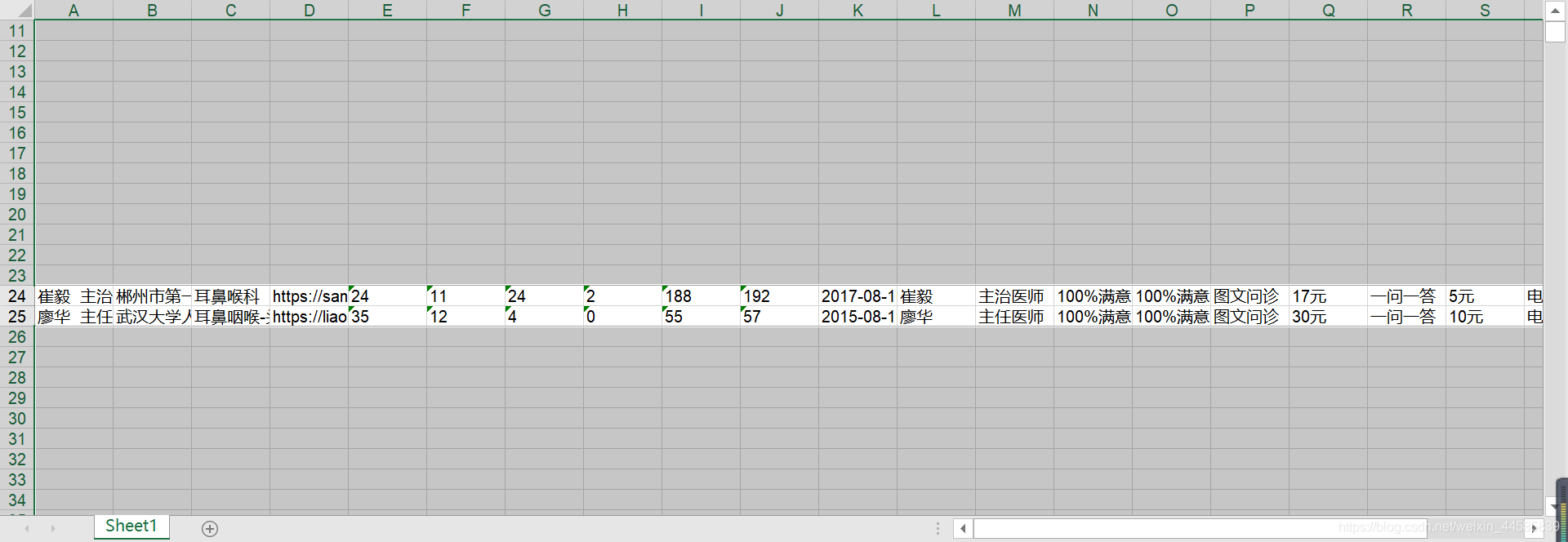
4.step2调整服务类型价格
import xlrd
import xlwt
from xlutils.copy import copy
import os
url = r"C:\Users\lenovo\Desktop\好大夫全部网页数据挖掘.xls"
defult_num = 0
def dataClear(work_url):
read_workbook = xlrd.open_workbook(work_url)
write_workbook = copy(read_workbook)
sheet_read = read_workbook.sheet_by_index(0)
sheet_write = write_workbook.get_sheet(0)
# 行和列
nrows = sheet_read.nrows
ncols = sheet_read.ncols
# 修改excel对应列的title为对应服务价格的名称
sheet_write.write(0, 16, '图文问诊价格')
sheet_write.write(0, 18, '一问一答价格')
sheet_write.write(0, 20, '电话问诊价格')
# 从excel第二行开始遍历,三种服务出现的顺序为图文问诊、一问一答、电话问诊
# 可能出现类型不存在的情况,但只要出现顺序一定符合
for row in range(1, nrows):
if sheet_read.cell(row, 15).value == '一问一答':
type = sheet_read.cell(row, 15).value
price = sheet_read.cell(row,16).value
sheet_write.write(row, 15, '')
sheet_write.write(row, 16, defult_num)
sheet_write.write(row, 17, type)
sheet_write.write(row, 18, price)
elif sheet_read.cell(row, 15).value == '电话问诊':
type = sheet_read.cell(row, 15).value
price = sheet_read.cell(row, 16).value
sheet_write.write(row, 15, '')
sheet_write.write(row, 16, defult_num)
sheet_write.write(row, 18, defult_num)
sheet_write.write(row, 19, type)
sheet_write.write(row, 20, price)
if sheet_read.cell(row, 17).value == '电话问诊':
type = sheet_read.cell(row, 17).value
price = sheet_read.cell(row, 18).value
sheet_write.write(row, 17, '')
sheet_write.write(row, 18, defult_num)
sheet_write.write(row, 19, type)
sheet_write.write(row, 20, price)
# 保存
os.remove(work_url)
write_workbook.save(work_url)
if __name__ == '__main__':
dataClear(url)
运行代码前后的数据对比图:
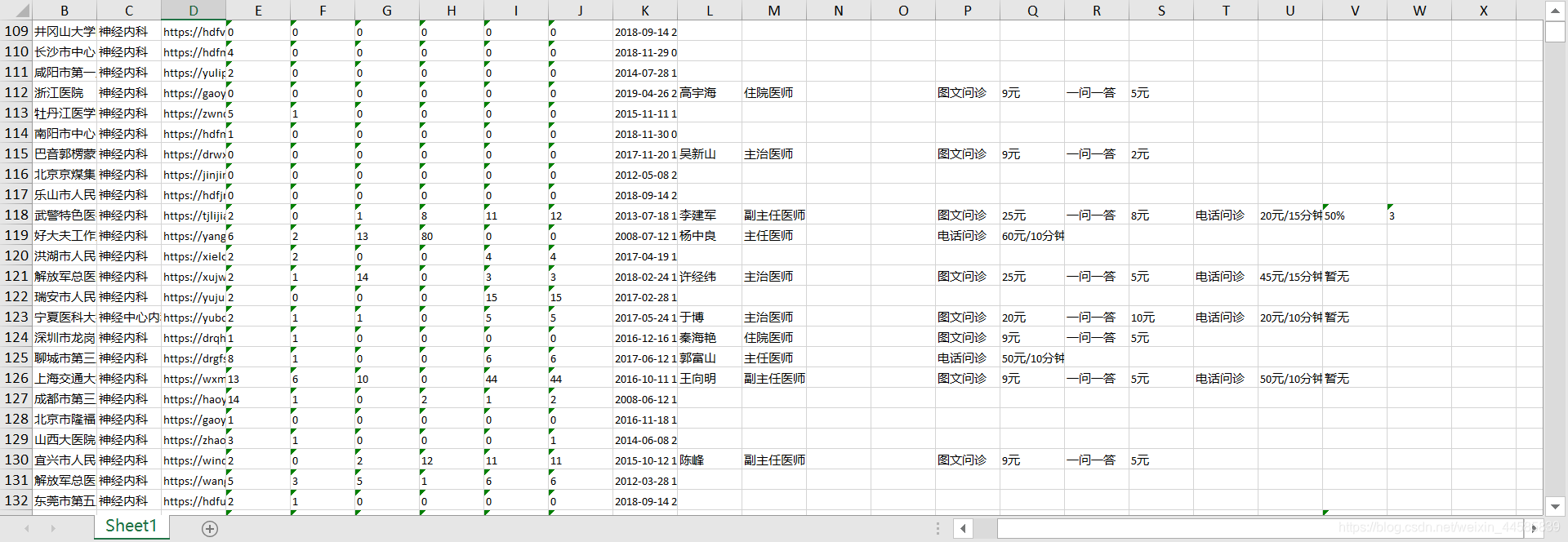
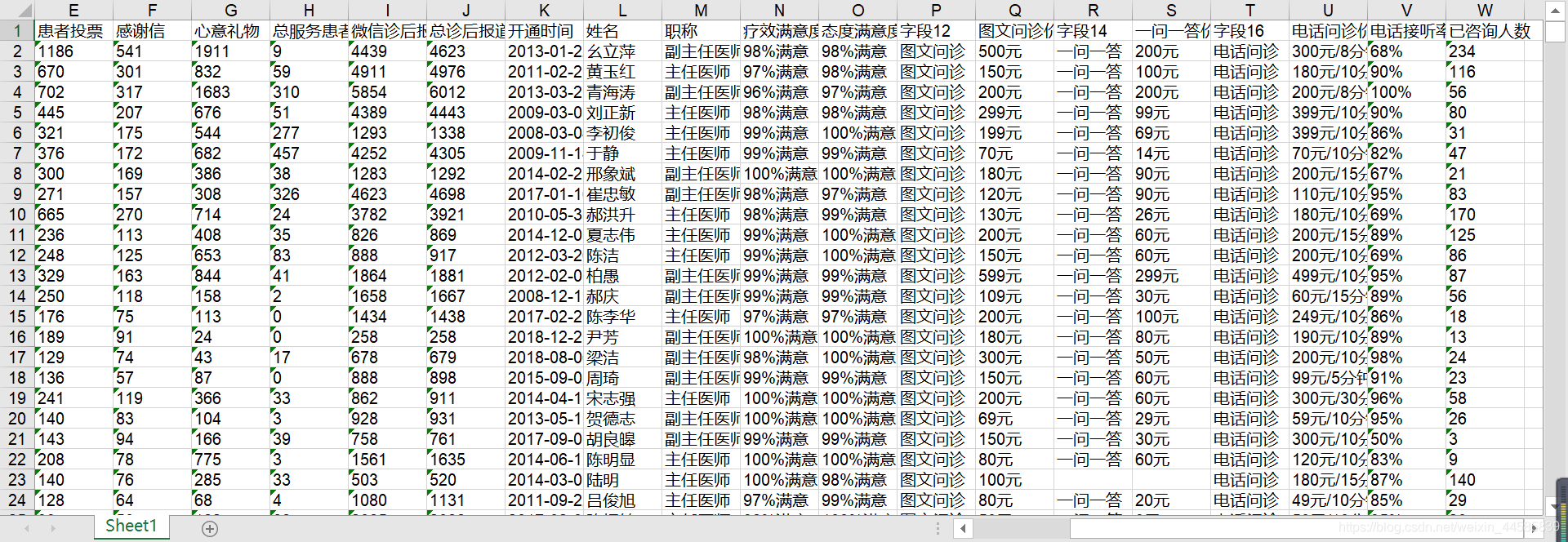
5.step3格式化数据
1)将str数据类型转化为int
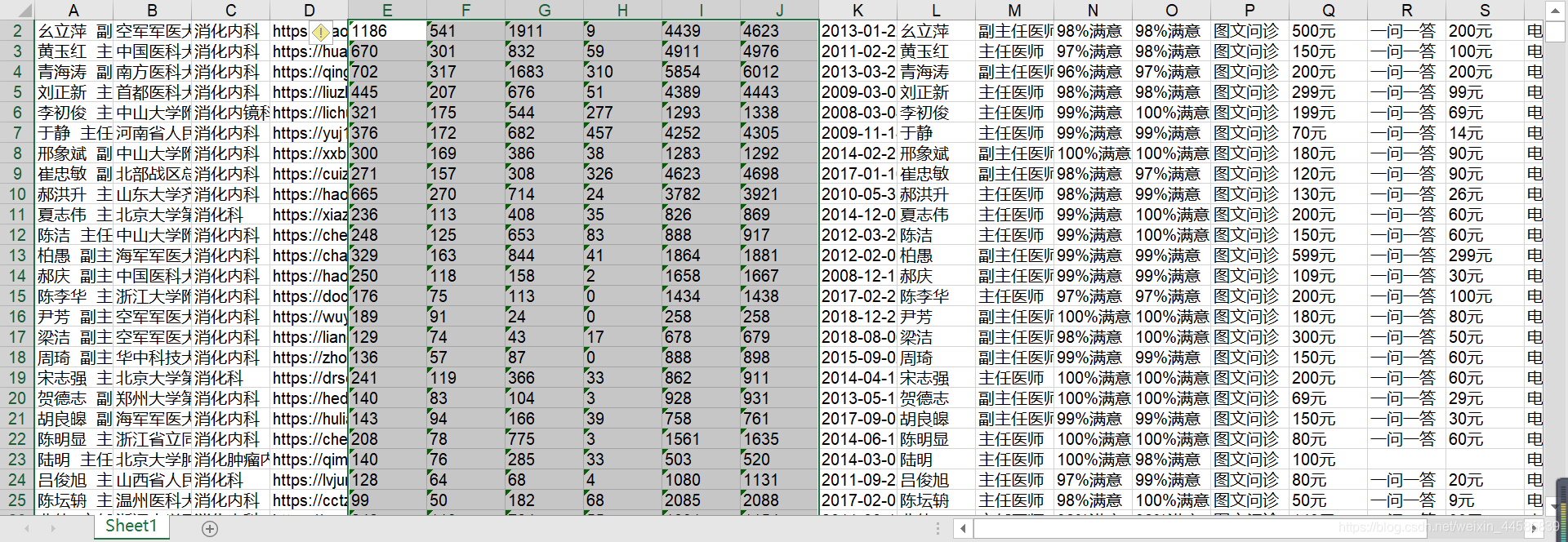
也可以使用python进行转换:
import xlrd
import xlwt
from xlutils.copy import copy
import os
url = r"C:\Users\lenovo\Desktop\实验.xls"
def dataClear(work_url):
read_workbook = xlrd.open_workbook(work_url)
write_workbook = copy(read_workbook)
sheet_read = read_workbook.sheet_by_index(0)
sheet_write = write_workbook.get_sheet(0)
# 行和列
nrows = sheet_read.nrows
ncols = sheet_read.ncols
StrToIntList = [4, 5, 6, 7, 8, 9, 19]
for row in range(1, nrows):
for i in StrToIntList:
value = sheet_read.cell(row, i).value
sheet_write.write(row, i, int(value))
# 保存
os.remove(work_url)
write_workbook.save(work_url)
if __name__ == '__main__':
dataClear(url)
2).疗效满意度和态度满意度调整为百分比形式
相关代码为(也可以直接使用excel进行操作):
import xlrd
import xlwt
from xlutils.copy import copy
import os
url = r"C:\Users\lenovo\Desktop\实验.xls"
def dataClear(work_url):
read_workbook = xlrd.open_workbook(work_url)
write_workbook = copy(read_workbook)
sheet_read = read_workbook.sheet_by_index(0)
sheet_write = write_workbook.get_sheet(0)
# 行和列
nrows = sheet_read.nrows
ncols = sheet_read.ncols
ChangeTo01 = [13, 14, 18]
for row in range(1, nrows):
for i in ChangeTo01:
value = sheet_read.cell(row, i).value
if (i==13 or i==14):
value = value.replace('满意', '')
value = int(value)
sheet_write.write(row, i, value/100)
# 保存
os.remove(work_url)
write_workbook.save(work_url)
if __name__ == '__main__':
dataClear(url)
处理结果:

3)价格类型12整数化
这里可以直接使用excel的替换功能进行操作,处理结果为:
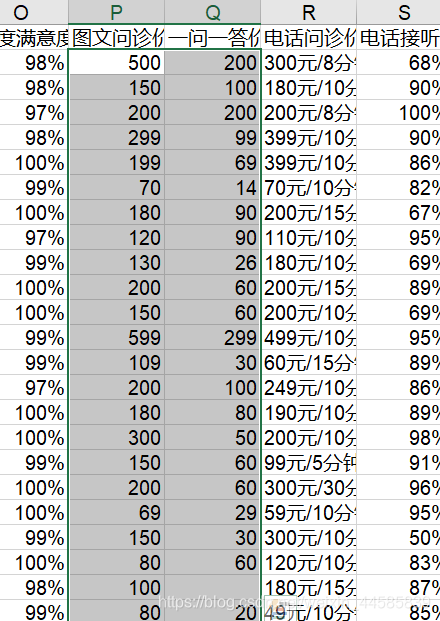
4)电话问诊转化为每小时服务价格
此处比较复杂,使用代码进行修改:
import xlrd
import xlwt
from xlutils.copy import copy
import os
url = r"C:\Users\lenovo\Desktop\好大夫全部网页数据挖掘.xls"
def dataClear(work_url):
read_workbook = xlrd.open_workbook(work_url)
write_workbook = copy(read_workbook)
sheet_read = read_workbook.sheet_by_index(0)
sheet_write = write_workbook.get_sheet(0)
# 行和列
nrows = sheet_read.nrows
ncols = sheet_read.ncols
sheet_write.write(0, 17, '电话问诊每小时价格')
for row in range(1, nrows):
value = sheet_read.cell(row, 17).value
value = value.replace('元', '元元元元') # 防止价格宽度不一,先增长区分度
str1 = value[:5]
str2 = value[5:]
money = (''.join([x for x in str1 if x.isdigit()]))
min = (''.join([x for x in str2 if x.isdigit()]))
result = int(money)/int(min)*60
sheet_write.write(row, 17, result)
# 保存
os.remove(work_url)
write_workbook.save(work_url)
if __name__ == '__main__':
dataClear(url)
完成后的效果为:
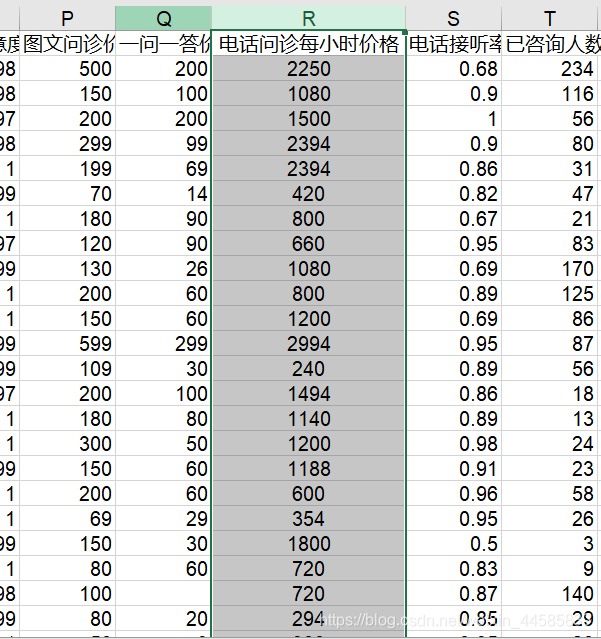
5)通过开通时间计算开通天数
我们收集到的开通时间形式如下图,保存数据类型为str,因此我们可以利用python将其改成year/month/day,然后通过excel中日期相减功能得到开通天数。

修改开通时间列的代码为:
import xlrd
import xlwt
from xlutils.copy import copy
import os
url = r"C:\Users\lenovo\Desktop\好大夫全部网页数据挖掘.xls"
def dataClear(work_url):
read_workbook = xlrd.open_workbook(work_url)
write_workbook = copy(read_workbook)
sheet_read = read_workbook.sheet_by_index(0)
sheet_write = write_workbook.get_sheet(0)
# 行和列
nrows = sheet_read.nrows
ncols = sheet_read.ncols
sheet_write.write(0, 17, '电话问诊每小时价格')
for row in range(1, nrows):
value = sheet_read.cell(row, 10).value
year = value[:4]
month = value[5:7]
day = value[8:10]
sheet_write.write(row, 10, year+'/'+month+'/'+day)
# 保存
os.remove(work_url)
write_workbook.save(work_url)
if __name__ == '__main__':
dataClear(url)
处理结果为:
进一步通过excel的相关功能:
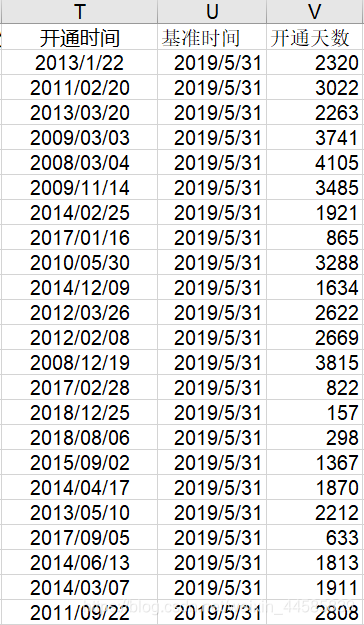
至此我们完成了数据清洗工作。
6.总结
- 进行数据清洗工作时,多种工具混合使用能在很大程度上提高效率。
- 数据清洗的代码片段不应追求一次清洗完成,在清洗过程需要主翼抛出的exception,例如在电话问诊单位小时价格上,如出现缺省情况,使用int进行数据转换就会抛出错误。
- 数据清洗的步骤很重要,确定好清洗步骤能节省很多时间,例如先出去意义不大的数据项。

















 2562
2562

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









