







文章目录
数据结构
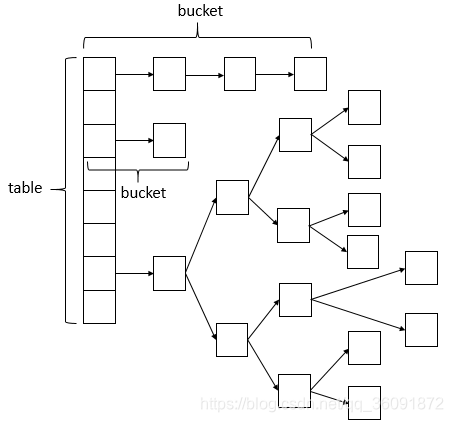
ConcurrentHashMap相比HashMap而言,是多线程安全的,利用 CAS + synchronized 来保证并发更新的安全 ,其底层数据结构与HashMap的数据结构(数组+链表+红黑树)相同,数据结构如下:
即:
Node:保存key,value及key的hash值的数据结构。 其中value和next都用volatile修饰,保证并发的可见性。
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
...//省略部分代码
public final int hashCode() { return key.hashCode() ^ val.hashCode(); }
public final V setValue(V value) {
throw new UnsupportedOperationException();
}
public final boolean equals(Object o) {
Object k, v, u; Map.Entry<?,?> e;
return ((o instanceof Map.Entry) &&
(k = (e = (Map.Entry<?,?>)o).getKey()) != null &&
(v = e.getValue()) != null &&
(k == key || k.equals(key)) &&
(v == (u = val) || v.equals(u)));
}
...//省略部分代码
}
ForwardingNode:一个特殊的Node节点,hash值为-1,其中存储nextTable的引用。
只有table发生扩容的时候,ForwardingNode才会发挥作用,作为一个占位符放在table中表示当前节点为null或则已经被移动。
static final class ForwardingNode<K,V> extends Node<K,V> {
final Node<K,V>[] nextTable;
ForwardingNode(Node<K,V>[] tab) {
super(MOVED, null, null, null);
this.nextTable = tab;
}
...//省略部分代码
}
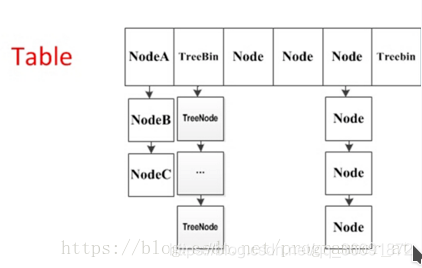
TreeNode
static final class TreeNode<K,V> extends Node<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
TreeNode(int hash, K key, V val, Node<K,V> next,
TreeNode<K,V> parent) {
super(hash, key, val, next);
this.parent = parent;
}
...//省略部分代码
}
TreeBin
static final class TreeBin<K,V> extends Node<K,V> {
TreeNode<K,V> root;
volatile TreeNode<K,V> first;
volatile Thread waiter;
volatile int lockState;
// values for lockState
static final int WRITER = 1; // set while holding write lock
static final int WAITER = 2; // set when waiting for write lock
static final int READER = 4; // increment value for setting read lock
...//省略部分代码
}
重要成员变量
/**用来控制table的初始化和扩容操作,
为负数时
-1 代表table正在初始化
-N 表示有N-1个线程正在进行扩容操作
其余情况:
1、如果table未初始化,表示table需要初始化的大小。
2、如果table初始化完成,表示table的容量,默认是table大小的0.75倍,居然用这个公式算0.75(n - (n >>> 2))。
*/
private transient volatile int sizeCtl;
//负载因子,默认为0.75
private static final float LOAD_FACTOR = 0.75f;
// 默认为null,初始化发生在第一次插入操作,默认大小为16的数组,用来存储Node节点数据,扩容时大小总是2的幂次方。
transient volatile Node<K,V>[] table;
//默认为null,扩容时新生成的数组,其大小为原数组的两倍。
private transient volatile Node<K,V>[] nextTable;
static final int MOVED = -1; // hash for forwarding nodes
static final int TREEBIN = -2; // hash for roots of trees
实例初始化
//table的初始化操作会延缓到第一次put操作再进行,并且初始化只会执行一次。默认的table大小为16.
public ConcurrentHashMap() {
}
//初始化时会根据参数调整table大小,确保table的大小总是2的幂次方
public ConcurrentHashMap(int initialCapacity) {
if (initialCapacity < 0)
throw new IllegalArgumentException();
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
this.sizeCtl = cap;
}
...//省略其他构造函数
put操作
过程
假设table已经初始化完成,put操作采用CAS+synchronized实现并发插入或更新操作:
- 当前bucket为空时,使用CAS操作,将Node放入对应的bucket中。
- 出现hash冲突,则采用synchronized关键字。倘若当前hash对应的节点是链表的头节点,遍历链表,若找到对应的node节点,则修改node节点的val,否则在链表末尾添加node节点;倘若当前节点是红黑树的根节点,在树结构上遍历元素,更新或增加节点。
- 倘若当前map正在扩容f.hash == MOVED, 则跟其他线程一起进行扩容
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {// 当前bucket为空
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))// 比较并且交换值,如tab的第i项为空则用新生成的node替换
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)//检测到桶结点是 ForwardingNode 类型,协助扩容当前Map在扩容
tab = helpTransfer(tab, f);
else {// hash冲突
V oldVal = null;
synchronized (f) {// 加锁同步
if (tabAt(tab, i) == f) {// 找到table表下标为i的节点
if (fh >= 0) {// 该table表中该结点的hash值大于0
binCount = 1;// binCount赋值为1
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) { // 结点的hash值相等并且key也相等
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
// 保存当前结点
Node<K,V> pred = e;
if ((e = e.next) == null) {// 当前结点的下一个结点为空,即为最后一个结点
pred.next = new Node<K,V>(hash, key,
value, null); // 新生一个结点并且赋值给next域
break;
}
}
}
else if (f instanceof TreeBin) {// // 结点为红黑树结点类型
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
//binCount != 0 说明向链表或者红黑树中添加或修改一个节点成功
//binCount == 0 说明 put 操作将一个新节点添加成为某个桶的首节点
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)//如果binCount大于等于转化为红黑树的阈值,进行转化
treeifyBin(tab, i);
//oldVal != null 说明此次操作是修改操作
//直接返回旧值即可,无需做下面的扩容边界检查
if (oldVal != null)
return oldVal;
break;
}
}
}
//CAS 式更新baseCount,并判断是否需要扩容
addCount(1L, binCount); // 增加binCount的数量
//程序走到这一步说明此次 put 操作是一个添加操作,否则早就 return 返回了
return null;
}
说明:put函数底层调用了putVal进行数据的插入,对于putVal函数的流程大体如下。
-
判断存储的key、value是否为空,若为空,则抛出异常,否则,进入步骤2
-
计算key的hash值,随后进入无限循环,该无限循环可以确保成功插入数据,若table表为空或者长度为0,则初始化table表,否则,进入步骤3
-
根据key的hash值取出table表中的结点元素,若取出的结点为空(该桶为空),则使用CAS将key、value、hash值生成的结点放入桶中。否则,进入步骤4
-
若该结点的的hash值为MOVED,则对该桶中的结点进行转移,否则,进入步骤5
-
对桶中的第一个结点(即table表中的结点)进行加锁,对该桶进行遍历,桶中的结点的hash值与key值与给定的hash值和key值相等,则根据标识选择是否进行更新操作(用给定的value值替换该结点的value值),若遍历完桶仍没有找到hash值与key值和指定的hash值与key值相等的结点,则直接新生一个结点并赋值为之前最后一个结点的下一个结点。进入步骤
-
若binCount值达到红黑树转化的阈值,则将桶中的结构转化为红黑树存储,最后,增加binCount的值。
在putVal函数中会涉及到如下几个函数:initTable、tabAt、casTabAt、helpTransfer、putTreeVal、treeifyBin、addCount函数。
initTable函数
initTable函数(对于table的大小,会根据sizeCtl的值进行设置,如果没有设置szieCtl的值,那么默认生成的table大小为16,否则,会根据sizeCtl的大小设置table大小。)
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
//如果一个线程发现sizeCtl<0,意味着另外的线程执行CAS操作成功,当前线程只需要让出cpu时间片
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {// 比较sizeCtl的值与sc是否相等,相等则用-1替换
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2); // sc为n * 3/4 ,即阈值为n*0.75
}
} finally {
sizeCtl = sc; // 设置sizeCtl的值,
}
break;
}
}
return tab;
}
spread函数
static final int HASH_BITS = 0x7fffffff; // usable bits of normal node hash
static final int spread(int h) {
return (h ^ (h >>> 16)) & HASH_BITS;
}
tabAt函数
此函数返回table数组中下标为i的结点,可以看到是通过Unsafe对象通过反射获取的,getObjectVolatile的第二项参数为下标为i的偏移地址。
采用Unsafe.getObjectVolatie()来获取,而不是直接用table[index]的原因跟ConcurrentHashMap的弱一致性有关。在java内存模型中,我们已经知道每个线程都有一个工作内存,里面存储着table的副本,虽然table是volatile修饰的,但不能保证线程每次都拿到table中的最新元素,Unsafe.getObjectVolatile可以直接获取指定内存的数据,保证了每次拿到数据都是最新的。
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}
casTabAt函数
此函数用于比较table数组下标为i的结点是否为c,若为c,则用v交换操作。否则,不进行交换操作。
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
Node<K,V> c, Node<K,V> v) {
return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
helpTransfer函数
此函数用于在扩容时将table表中的结点转移到nextTable中。
final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) {
Node<K,V>[] nextTab; int sc;
if (tab != null && (f instanceof ForwardingNode) &&
(nextTab = ((ForwardingNode<K,V>)f).nextTable) != null) { // table表不为空并且结点类型是ForwardingNode类型,并且结点的nextTable不为空
int rs = resizeStamp(tab.length);
while (nextTab == nextTable && table == tab &&
(sc = sizeCtl) < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) {
transfer(tab, nextTab);// 将table的结点转移到nextTab中
break;
}
}
return nextTab;
}
return table;
}
其他函数
putTreeVal函数,此函数用于将指定的hash、key、value值添加到红黑树中,若已经添加了,则返回null,否则返回该结点。
treeifyBin函数,此函数用于将桶中的数据结构转化为红黑树,其中,值得注意的是,当table的长度未达到阈值时,会进行一次扩容操作,该操作会使得触发treeifyBin操作的某个桶中的所有元素进行一次重新分配,这样可以避免某个桶中的结点数量太大。
addCount函数,此函数主要完成binCount的值加1的操作。
table扩容
什么时候会触发扩容?
- 如果新增节点之后,所在的链表的元素个数大于等于8,则会调用treeifyBin把链表转换为红黑树。在转换结构时,若tab的长度小于MIN_TREEIFY_CAPACITY,默认值为64,则会将数组长度扩大到原来的两倍,并触发transfer,重新调整节点位置。(只有当tab.length >= 64, ConcurrentHashMap才会使用红黑树。)
- 新增节点后,addCount统计tab中的节点个数大于阈值(sizeCtl),会触发transfer,重新调整节点位置。
treeifyBin
private final void treeifyBin(Node<K,V>[] tab, int index) {
Node<K,V> b; int n, sc;
if (tab != null) {
if ((n = tab.length) < MIN_TREEIFY_CAPACITY)
tryPresize(n << 1);
else if ((b = tabAt(tab, index)) != null && b.hash >= 0) {//只有当tab.length >= 64, ConcurrentHashMap才会使用红黑树。
...
}
}
}
addCount
private final void addCount(long x, int check) {
CounterCell[] as; long b, s;
// 利用CAS更新baseCount
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
CounterCell a; long v; int m;
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
fullAddCount(x, uncontended); // 多线程修改baseCount时,竞争失败的线程会执行fullAddCount(x, uncontended),把x的值插入到counterCell类中
return;
}
if (check <= 1)
return;
s = sumCount();
}
if (check >= 0) {
Node<K,V>[] tab, nt; int n, sc;
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
if (sc < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0) // 其他线程在初始化,break;
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) // 其他线程正在扩容,协助扩容
transfer(tab, nt);
}
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null); // 仅当前线程在扩容
s = sumCount();
}
}
}
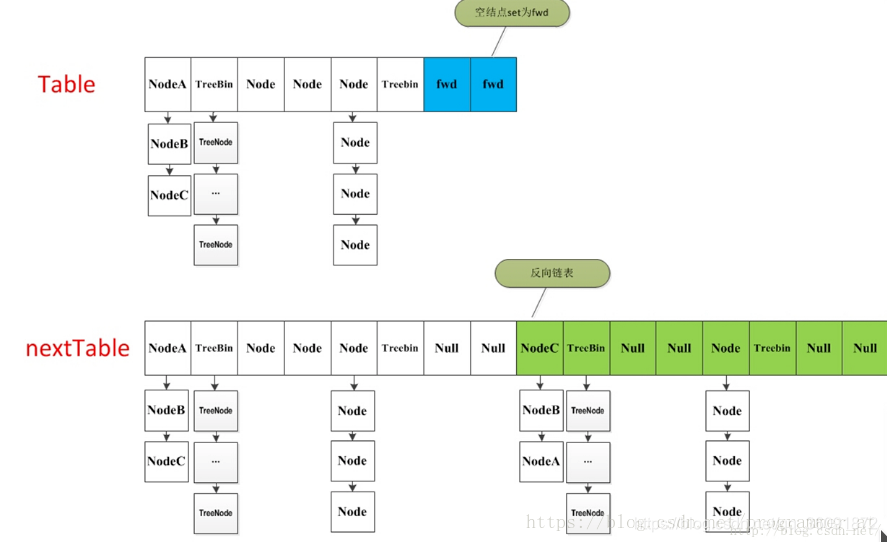
transfer
当table的元素数量达到容量阈值sizeCtl,需要对table进行扩容:
- 构建一个nextTable,大小为table两倍
- 把table的数据复制到nextTable中。
在扩容过程中,依然支持并发更新操作;也支持并发插入。
首先,每个线程进来会先领取自己的任务区间,然后开始 --i 来遍历自己的任务区间,对每个桶进行处理。如果遇到桶的头结点是空的,那么使用 ForwardingNode 标识该桶已经被处理完成了。如果遇到已经处理完成的桶,直接跳过进行下一个桶的处理。如果是正常的桶,对桶首节点加锁,正常的迁移即可,迁移结束后依然会将原表的该位置标识位已经处理。
当 i < 0,说明本线程处理速度够快的,整张表的最后一部分已经被它处理完了,现在需要看看是否还有其他线程在自己的区间段还在迁移中。
get操作
根据key的hash值来计算在哪个桶中,再遍历桶,查找元素,若找到则返回该结点,否则,返回null。
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {// 表不为空并且表的长度大于0并且key所在的桶不为空
if ((eh = e.hash) == h) {// 表中的元素的hash值与key的hash值相等
if ((ek = e.key) == key || (ek != null && key.equals(ek)))// 桶中第一个元素与目标对象键相等
return e.val;
}
else if (eh < 0)// 结点hash值小于0
return (p = e.find(h, key)) != null ? p.val : null;// 在桶(链表/红黑树)中查找
while ((e = e.next) != null) {// 对于结点hash值大于0的情况
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
统计size
ConcurrentHashMap的元素个数等于baseCounter和数组里每个CounterCell的值之和,这样做的原因是,当多个线程同时执行CAS修改baseCount值,失败的线程会将值放到CounterCell中。所以统计元素个数时,要把baseCount和counterCells数组都考虑。
private transient volatile long baseCount;
private transient volatile CounterCell[] counterCells;
public int size() {
long n = sumCount();
return ((n < 0L) ? 0 :
(n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :
(int)n);
}
final long sumCount() {
CounterCell[] as = counterCells; CounterCell a;
long sum = baseCount;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
@sun.misc.Contended static final class CounterCell {
volatile long value;
CounterCell(long x) { value = x; }
}
ConcurrentHashMap为什么高效?
Hashtable低效主要是因为所有访问Hashtable的线程都争夺一把锁。如果容器有很多把锁,每一把锁控制容器中的一部分数据,那么当多个线程访问容器里的不同部分的数据时,线程之前就不会存在锁的竞争,这样就可以有效的提高并发的访问效率。这也正是ConcurrentHashMap使用的分段锁技术。将ConcurrentHashMap容器的数据分段存储,每一段数据分配一个Segment(锁),当线程占用其中一个Segment时,其他线程可正常访问其他段数据。
删除元素
public V remove(Object key) {
return replaceNode(key, null, null);
}
final V replaceNode(Object key, V value, Object cv) {
int hash = spread(key.hashCode());
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0 ||
(f = tabAt(tab, i = (n - 1) & hash)) == null)
break;// 桶位为空,跳过
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);// 协助扩容
else {
V oldVal = null;
boolean validated = false;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
validated = true;
for (Node<K,V> e = f, pred = null;;) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
V ev = e.val;
if (cv == null || cv == ev ||
(ev != null && cv.equals(ev))) {
oldVal = ev;
if (value != null)
e.val = value;
else if (pred != null)// 非链表头节点,直接删除该节点
pred.next = e.next;
else// 更新链表头节点
setTabAt(tab, i, e.next);
}
break;
}
pred = e;
if ((e = e.next) == null)
break;
}
}
else if (f instanceof TreeBin) {
validated = true;
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> r, p;
if ((r = t.root) != null &&
(p = r.findTreeNode(hash, key, null)) != null) {
V pv = p.val;
if (cv == null || cv == pv ||
(pv != null && cv.equals(pv))) {
oldVal = pv;
if (value != null)
p.val = value;
else if (t.removeTreeNode(p))
setTabAt(tab, i, untreeify(t.first));
}
}
}
}
}
if (validated) {
if (oldVal != null) {
if (value == null)
addCount(-1L, -1);
return oldVal;
}
break;
}
}
}
return null;
}
参考:
https://blog.csdn.net/programmer_at/article/details/79715177
http://www.importnew.com/28263.html














 1390
1390











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









