







week 1
聚类和分类
监督学习和非监督学习
------------------------------------------------------------
1. 术语
1.1 类别 (class)
为标签枚举的一组目标值中的一个。例如,在检测垃圾邮件的二元分类模型中,两种类别分别是“垃圾邮件”和“非垃圾邮件”。在识别狗品种的多类别分类模型中,类别可以是“贵宾犬”、“小猎犬”、“哈巴犬”等等。
1.1.1. 介绍:
分类有如下几种说法,但表达的意思是相同的。
1. 分类(classification):分类任务就是通过学习得到一个目标函数f,把每个属性集x映射到一个预先定义的类标号y中。
2. 分类是根据一些给定的已知类别标号的样本,训练某种学习机器(即得到某种目标函数),使它能够对未知类别的样本进行分类。这属于supervised learning(监督学习)。
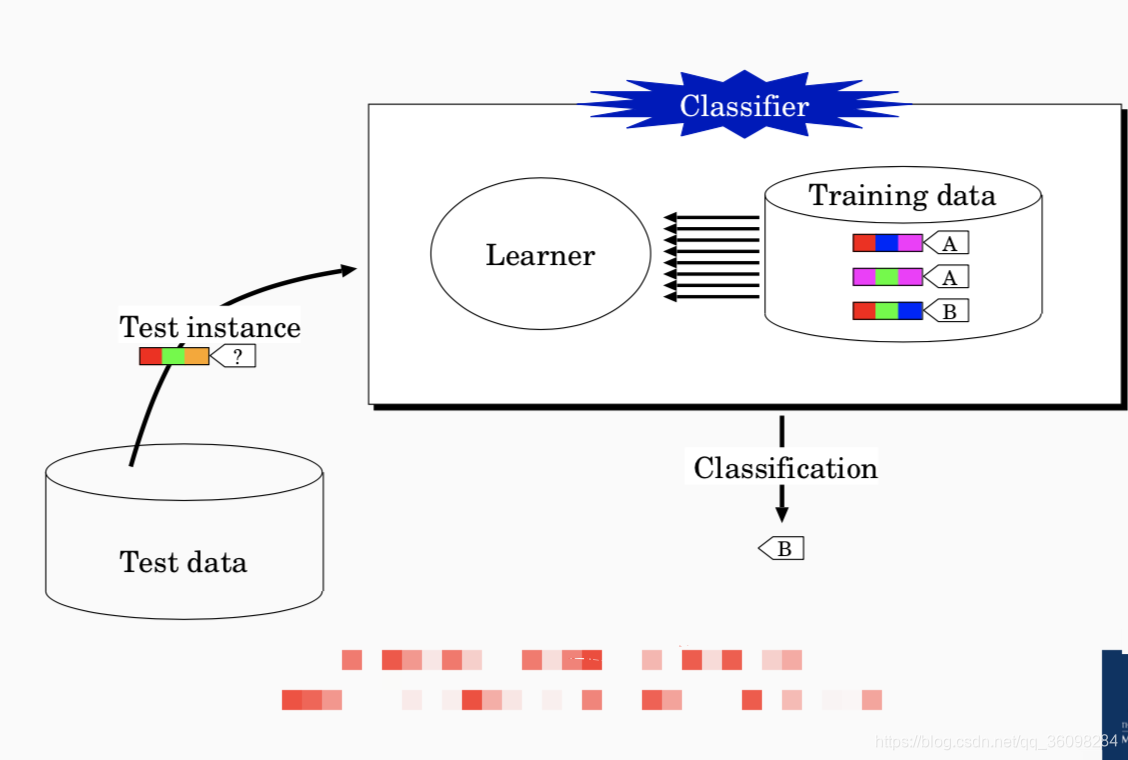
3. 分类:通过学习来得到样本属性与类标号之间的关系。
用自己的话来说,就是我们根据已知的一些样本(包括属性与类标号)来得到分类模型(即得到样本属性与类标号之间的函数)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









