







The Perceptron
注意:本文主要介绍preceptron(没有隐藏层)的工作原理,和具体的实例(具体的数据如何进行权重的迭代更新的),但是没有代码实现。preceptron一般是二分类,这里同样提到了当分类结果是3种时,如何进行权重的迭代更新。本文主要介绍的是原理,如果想看具体更新权重的计算过程的实例(有数字计算的),可以查看我的另一个文章:https://blog.csdn.net/qq_36098284/article/details/105933793
1. Netural network
The Perceptron is a minimal neural network (neural networks are composed of neurons )

这里只是简单的提到netural network,下一节会详细的提到具有隐藏层的netrual network的工作过程。
2. Perceptron
2.1 介绍
简单描述一下每个神经元的基本工作原理和基本名词:
我们原理和例子一起进行描述:
背景:假设这个神经元是想预测一个人在某一门考试的期末成绩,我们假设根据这个人的学习时间,额外学习时间,出勤率,作业完成程度4个因素来判定。那么这4个因素就是已知的。
1. input:Input是一些x值(就是指上面的学习时间,额外学习时间,出勤率,作业完成程度)这四个因素,也就是说对于这个模型,x的值就是x1/x2/x3/x4)。但是在计算的时候,有一个x0,这里默认是1
2. weight:针对每个不同的x值,均有不同的权重(权重可以理解成,每种影响因素的重要性)。但是要注意,这里的θ不是4个,而是5个,因为有一个x0的权重。
3. 激活函数:有了input和weight后,把他们分别相乘在相加就得到一个结果,就是我们预测的值y.这里用f(x;θ,b) 表示激活函数。
4. Test的时候,就是输入x然后计算后,得到y。训练的时候,就是输入x和y训练权重。
5. learning rate:学习率用来根据输出结果和预测结果的对比的结果进行权重的重新计算需要用到的一个参数。
6. 因为是监督学习,我们还需要每个train data 的label
下面是一个神经元的图解:
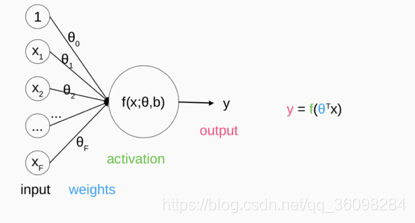
下面是Perceptron的图解:
和上面的区别,就是激活函数那里,限制了输出结果y只能是两个值:-1/1

对perceptron模型的说明:

几点要注意的事:
- Perceptron只能用来0/1分类,也就是二分类。Class的结果用-1/1表示。
- Perceptron是监督分类算法,也就是需要从input-label来学习。学习的内容其实就是修改参数(weight权重),以获得最优的性能。
- 比较predicted的结果和true结果,minimize the number of mis-classifications 在数学上不可行。因此,这里选择minimize预测结果和真实结果的gap
- 我们这里计算得到的结果可能是任意的值,但是我们只要结果是-1/1两个值就可以(有的文章要0/1)。因此需要对得到的结果进行处理,也就是上面的第二条。
- 上面第二条函数的解释是:当计算的结果超过某一个边界值(decision boundary),我们就说他是f()=1,否则就是-1.这个函数我们成为step function。但是边界值的选择不是随意的。
根据预测结果和真实结果的对比,如果结果不一致就迭代的更新权重值。

例子:详细的描述一个模型训练和计算的过程:

已知:训练数据(features+label)/ 学习率/初始权重(全部是0,下面有提到)/step function
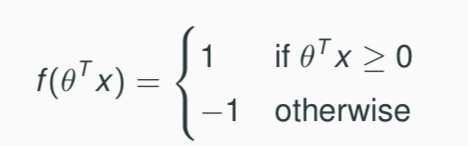
下面进行第一次的计算:
step 1. 计算X1:<x1,x2>,分别用他们的x值和对应的权重相乘

step 2.得到计算结果y,并得到分类结果(计算出的结果不是该instance的分类结果)
可以观察到第三条数据<0,0>时,计算结果是1,但是分类结果是-1.
为什么计算的结果是1,但分类结构是-1呢?
因为我们规定了边界值是0,也就是当计算出的结果比0大的时候,我们的分类结果是1,而其他的时候,分类结果都是-1.(step function)
step 3. 预测结果和真实结果想比较,如果一样就继续计算下一条数据,如果不相同就要更新权重,然后在计算下一条数据:
可以看到1和2都是一样的,但是3不一样,所以更新了权重。用新的权重计算的第四条4.

可以看到X3的预测结果是1,而真实结果是-1,根据权重的更新公式(上面已经提到了),权重需要跟新成-2.
(下面会再一次提到权重是如何计算的)
4. 第4条数据计算完成后。我们需要计算迭代的从第一条数据开始重新计算,也就是反复进行上面的第一步,直到准确率为1时。

下面在解释一下权重的更新计算:
注意,为什么X1计算完后,权重由(-2,0,0)变成(0.2.2)
因为权重的计算公式(θ ← θ + η ( y i − yˆ i ) x i )
对于θ = -2 + 2 =0 ;
θ1 = 0 + 1 * (2 ) * 1 = 2 ;
θ2同理。
因为有权重的更新,因此需要需要计算第三次。下面为第三次计算的结果,可以发现预测结果都和真实结果一样,因此不需要在计算第四次。

3. 下面是权重更新的公式
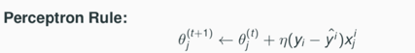
- 因此,我们要做的就是每次出错时都添加和减去权重的变化值。
- 权重的变化值:学习率 * (lable的真实值- 预测值) * input(这个权重下的x)
4. Multi-Class Perceptron
上面提到的都是分类结果只有1/-1两种时,下面讨论的是如果分类结果有3种或者多种时,如何进行训练。
4.1 introduction
下面是计算的4步:

4.2 例子:
一共有3个lable,三个神经元的初始weight已知。
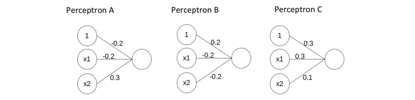
a) Training: For training example xtrain = (0,1), with class B, calculate the updated weights of each perceptron after processing x. Use learning rate η = 0.1.
step1: create 权重,这个题目已知
step2: 根据权重和xtrain = (0,1),计算在每个分类结果下预测值,

Step3: 选取预测值中最大的作为预测label(这里c时0.4,因此预测的结果是c)

Step4: 比较二者结果,如果不相同就更新权重(真实是b,因此需要更新weight)。更新的方法和上面的相同,只需要注意更新哪个神经元就可以了。


更新之后的权重是:
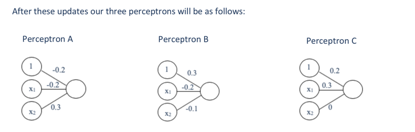
b) Testing: Using the new weights from part (a), given test example xtest = (1, 1) with true class C, give the class prediction of the group of three perceptrons. Is the prediction correct? Should we change the weights?

利用更新之后的weight,在对模型记性计算,观察,c类的结果是0.5,最大,那么输出的结果就是c。和真实的结果相同,就不需要再次进行计算了。














 701
701











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









