







video :https://www.youtube.com/watch?v=my207WNoeyA&list=PLZbbT5o_s2xoWNVdDudn51XM8lOuZ_Njv&index=2
concept
- one agent/entity :decision maker
- have an environment/situation
- do one action
- get a state and a reward(positive and negative )
- policy
Problem
- reward (稀疏), 可能需要很多actions,走到最后才能发现rewaird是什么. 而如何区分这个reward是和某一个关键action还是某一些,还是最后一个有关?
- solve the optimal policy
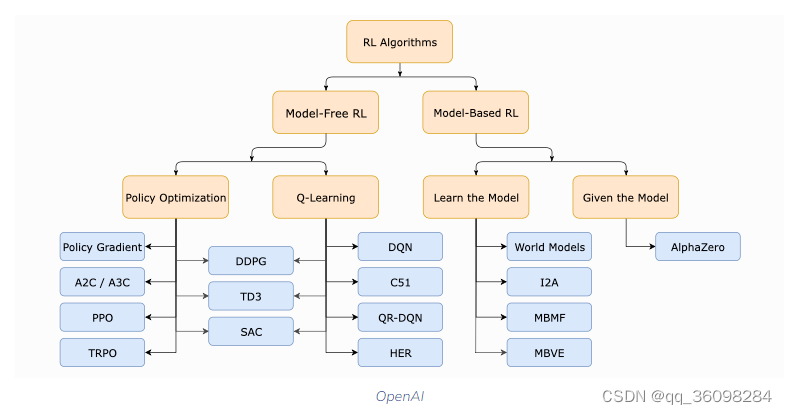
MDP (Markov Decision Processes)
Q-Learning
1. 马尔可夫决策过程
MDP (Markov Decision Processes)
Markov Decision Process or MDP, is used to formalize the reinforcement learning problems. If the environment is completely observable, then its dynamic can be modeled as a Markov Process. In MDP, the agent constantly interacts with the environment and performs actions; at each action, the environment responds and generates a new state.
MDP is used to describe the environment for the RL, and almost all the RL problem can be formalized using MDP.
MDP contains a tuple of four elements (S, A, Pa, Ra):
- A set of finite States S
- A set of finite Actions A
- Rewards received after transitioning from state S to state S', due to action a.
- Probability Pa.
Markov Property:
It says that "If the agent is present in the current state S1, performs an action a1 and move to the state s2, then the state transition from s1 to s2 only depends on the current state and future action and states do not depend on past actions, rewards, or states."
Or, in other words, as per Markov Property, the current state transition does not depend on any past action or state. Hence, MDP is an RL problem that satisfies the Markov property. Such as in a Chess game, the players only focus on the current state and do not need to remember past actions or states.
The aim of this process is to maximize its cumulative rewards
Expected Return R = R1 + R2+...+ Rt(the final step)
奖励是代理在环境中的某些状态下执行某些操作时收到的数值。根据代理的动作,数值可以是正数或负数。
在强化学习中,我们关心的是最大化累积奖励(代理从环境中获得的所有奖励),而不是代理从当前状态获得的奖励(也称为即时奖励)。代理从环境中获得的奖励总和称为回报。
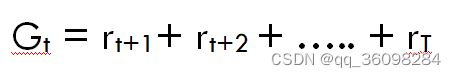
Discount return r means discount future rewards and will determine the present value of future rewards
折扣系数(ɤ):它决定了对当前奖励和未来奖励的重视程度。这基本上可以帮助我们避免将无穷大作为连续任务的奖励。它的值介于 0 和 1 之间。值0意味着更重视即时奖励,值1意味着更重视未来奖励。在实践中,折扣因子 0 永远不会学习,因为它只考虑即时奖励,而折扣因子 1 将继续用于可能导致无穷大的未来奖励。所以,折扣因子的最佳值介于 0.2 到 0.8 之间。
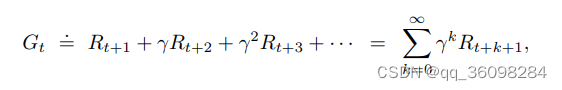
让我们用一个例子来理解它,假设你住在一个你面临缺水的地方,那么如果有人来找你说他会给你 100 升水!(请假设!)接下来的 15 小时一些参数(ɤ)。让我们看看两种可能性:(假设这是方程1,因为我们稍后将使用这个方程来推导贝尔曼方程)
一个折扣因子 ( ɤ) 0.8 :
这意味着我们应该等到第 15 个小时,因为减少不是很明显,所以仍然值得坚持到最后。这意味着我们也对未来的奖励感兴趣。所以,如果折扣因子接近 1,那么我们将努力结束,因为奖励非常重要。
其次,贴现因子 ( ɤ) 为 0.2:
这意味着我们对早期奖励更感兴趣,因为奖励在小时内变得非常低。所以,我们可能不想等到结束(直到第 15 小时),因为这将毫无价值。所以,如果折扣因素接近归零然后立即奖励比未来更重要。


How probable is it for an agent to select any action from a given state?
-- Policies :策略是将给定状态映射到从该状态中选择每个可能动作的概率的函数
可以是一个状态转换图,上面有不同状态之间的有向连接,以及转换的可能性,因此可以清楚的看出每个状态之间转换的可能.
How good is any given action or any given state for an agent?
-- Value Function : state-value function + action-value function
价值函数是状态或状态-动作对的函数,用于估计智能体处于给定状态的好坏程度,或智能体在给定状态下执行给定动作的好坏程度。
Optimal Policy
A policy that is better than or at least the same as all other policies is called the optimal policy
1. Optimal State-Value Function
2. Optimal Action-Value Function
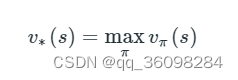
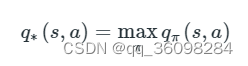
Bellman Optimality Equation
V(s) = max [R(s,a) + γV(s`)]
Where,
V(s)= value calculated at a particular point.
R(s,a) = Reward at a particular state s by performing an action.
γ = Discount factor
V(s`) = The value at the previous state.















 669
669











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









