






如有需要,请关注微信公众号“笔名二十七画生”!
首先,介绍一下基本概念:
多模态查询目标检测是一种目标检测方法,其中系统使用多种模态的信息(文本描述与视觉信息等)来理解和检测目标。
具体来说,多模态查询目标检测的过程通常包括以下几个步骤:
1.文本描述输入:系统接收与图像相关联的文本描述,这可以是关于图像中包含的物体或场景的自然语言描述。
2.视觉信息输入: 系统同时接收与图像相关的视觉示例,即图像本身。这提供了视觉信息,有助于模型理解图像内容。
3.模态融合:文本描述和视觉示例的信息被融合在一起,以更全面地理解目标。这可以通过各种方式进行,例如将文本嵌入与视觉特征结合起来。
4.目标检测:经过融合的信息用于进行目标检测,即确定图像中存在的对象、它们的位置和类别。
MQ-Det文章摘要
MQ-Det将视觉查询整合到现有的仅基于语言查询的检测器中。提出了一个即插即用的门控可缩放感知器模块(GCP模块),用于在冻结的检测器上增强类别文本与按类别的视觉信息。为解决冻结检测器带来的学习惯性问题,提出了一种以视觉为条件的掩码语言预测策略。实验结果表明,多模态查询在开放世界检测方面取得了显著的提升。

论文地址:
https://arxiv.org/pdf/2305.18980.pdf
代码地址:
https://github.com/YifanXu74/MQ-Det
实验条件:
8块NVIDIA V100 GPUs.(单卡16或者32GB)
MQ-Det前世今生
随着大规模视觉语言预训练模型的蓬勃发展 [25, 48, 24, 29, 27, 44, 20],目标检测最近引入了一种新的时尚范式,通过查询文本来定位所需的对象。由于预训练模型在大规模数据上的泛化 [26, 13, 36, 43, 22, 18, 37, 31, 35],这种文本查询范式在通向开放集目标检测的漫长道路上取得了稳步进展。
与之前的固定类别集(通常由有限数量表示)相比,前述的文本查询具有代表广泛概念的优点,但也存在固有的不足之处,即描述细粒度不足 [4, 9, 32]。例如,类同音词(例如,“bat”可以是一块木头或一种动物)导致查询模糊不清。同时,如图1所示,在对细粒度的鱼类物种进行检测时,通常很难使用有限的文本来描述具有特定图案的鱼。经验上,解决描述细粒度不足问题的一个简单解决方案是设计额外的文本描述,但存在三个明显的障碍:1)全面描述视觉细节很难 [52],为大量类别构建文本描述是一项繁重的工作。2)查询文本越长,预训练模型的理解难度越大,3)带来更多的计算开销。在实验证明,最先进的文本查询检测器GLIP [25]在水族馆数据集 [23](一个细粒度鱼类物种检测数据集)上仅将平均精度(AP)从17.7%提高到18.4%,即使对一些类别进行额外手动设计文本描述。
MQ-Det匠心独运
1.方法概述。
如下图所示,将即插即用的门控类可扩展感知器(GCPs)插入到文本编码器层中,并使用掩码语言预测策略进行训练。按类别的注意力掩码应用,使得每个类别的文本查询仅关注相应的视觉查询。
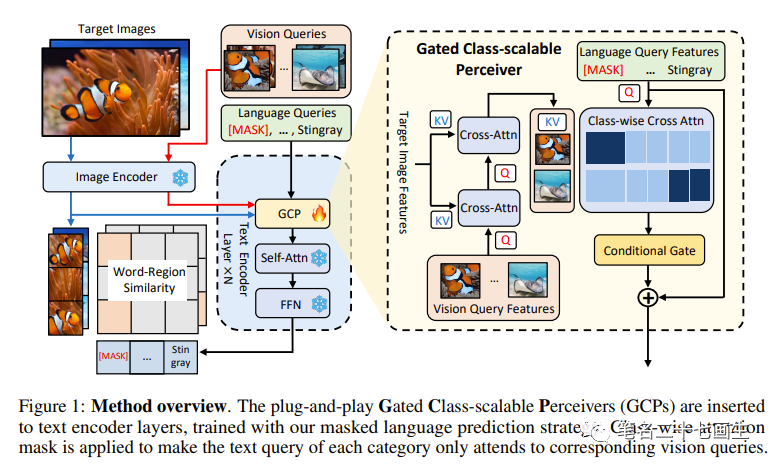
语言查询的检测模型。在CLIP的基础上,并行公式已经成为现有视觉语言检测基础模型的主流架构。以基线模型GLIP 为例,如图1左侧所示,它包括并行的文本编码器 ΦT (·) 和图像编码器 ΦI (·) 用于特征提取,并通过将每个视觉区域与文本提示中的类别内容进行基准/对齐来重新构建检测任务。由于像GLIP这样的检测模型仅通过语言查询中的类别内容识别对象,将其表示为语言查询的检测模型。
2.架构设计。
如下图所示,用于查询丰富的架构设计,为了清晰起见,仅呈现分类分支。(a)仅使用语言指令调整;(b)仅接受视觉输入。(c)MQ-Det结合语言指令和视觉输入查询。
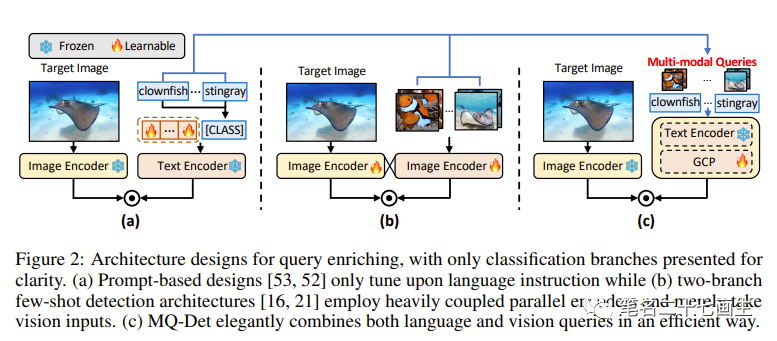
作者认为多模态查询检测模型的架构应遵循三个原则:
(1)类别可扩展:引入的视觉查询适用于任意类别,而不是适应于一个封闭的类别集。
(2)语义互补:视觉查询与粗糙的文本查询充分交错,提供支持区分各种粒度类别的细粒度视觉细节。
(3)保持泛化性:引入视觉查询到基础模型中累积了丰富的细节,同时仍保持泛化能力。
因此,作者通过将文本置于我们提出的图1中所示的门控类可扩展感知器(GCP)生成的相应视觉表示上来增强每个类别查询的语义。具体而言,在残差方式下将GCP模块插入到冻结的预训练文本编码器块之间,并仅从头开始训练这些模块。在GCP模块中,文本编码器块中的每个类别标记独立地与相应的视觉查询进行交叉关注,以获得丰富的细节(原则1,2)。然后,GCP模块对交错的类别标记进行门控,以保持冻结的文本编码器在初始化时保持完整,从而提高稳定性和泛化性能(原则3)。
MQ-Det卓越性能
Finetuning-free:
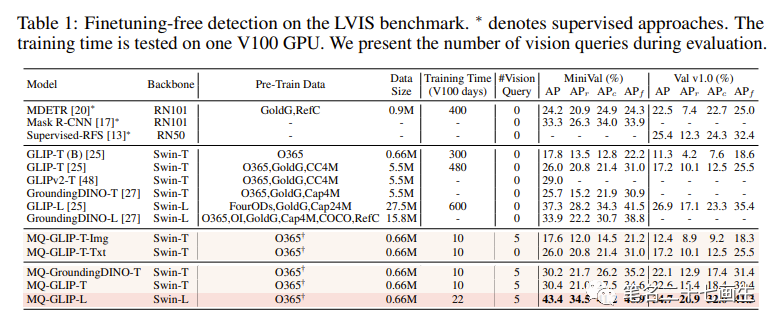
相比传统零样本(zero-shot)评估仅利用类别文本进行测试,MQ-Det提出了一种更贴近实际的评估策略:finetuning-free。其定义为:在不进行任何下游微调的条件下,用户可以利用类别文本、图像示例、或者两者结合来进行目标检测。
在finetuning-free的设定下,MQ-Det对每个类别选用了5个视觉示例,同时结合类别文本进行目标检测,而现有的其他模型不支持视觉查询,只能用纯文本描述进行目标检测。下表展示了在LVIS MiniVal和LVIS v1.0上的检测结果。可以发现,多模态查询的引入大幅度提升了开放世界目标检测能力。
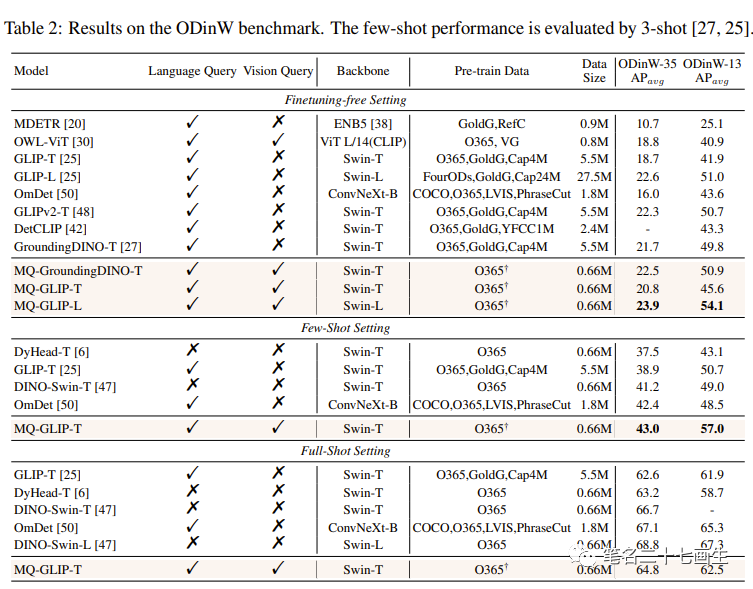
Few-shot评估
MQ-Det未来展望
作为基于实际应用的研究领域之一,目标检测注重算法落地。尽管以往的纯文本查询目标检测模型展现出了良好的泛化性,但是在实际的开放世界检测中文本很难涵盖细粒度的信息,而图像中丰富细信息粒度完美地补全这一环。至此我们能够发现,文本泛而不精,图像精而不泛,如果能够有效地结合两者,即多模态查询,将会推动开放世界目标检测进一步向前迈进。MQ-Det是一种高效的预训练架构和策略设计,使得视觉语言(VL)检测基础模型能够接受以图像交错的文本作为输入查询。在模块化预训练之后,MQ-Det在已建立的基准和35个下游任务的零微调和少样本设置上显示出显著性能提升。MQ-Det结果表明,利用语言和视觉的互补性是朝着开放世界目标检测的重要一步。
参考文献:
【1】Xu Y, Zhang M, Fu C, et al. Multi-modal Queried Object Detection in the Wild[J]. arXiv preprint arXiv:2305.18980, 2023.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









