









论文《Deep Dual-resolution Networks for Real-time and Accurate Semantic Segmentation of Road Scenes》原理解析及代码复现。
用自己的数据训练yolov11目标检测
实时语义分割之BiSeNetv2(2020)结构原理解析及建筑物提取实践
实时语义分割之Deep Dual-resolution Networks(DDRNet2021)原理解析及建筑物提取实践
SegFormer 模型解析:结合 Transformer 的高效分割框架原理及滑坡语义分割实战
概要
提示: (1)论文地址 https://arxiv.org/pdf/2101.06085 (2)本人打包好数据可运行代码 DDRNet.zip 链接: https://pan.baidu.com/s/17wrkGX03LqUDxDw6XzooYA?pwd=m2my 提取码: m2my
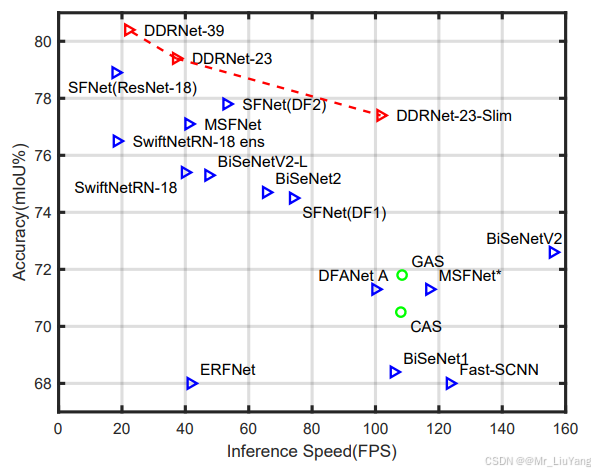
在自动驾驶领域,实时语义分割需要在保持高精度的同时实现实时推理速度(通常要求>30 FPS)。DDRNet(Deep Dual-resolution Networks)通过创新的双分支架构设计,在Cityscapes数据集上以1024×2048分辨率达到80.4% mIoU和37.7 FPS的优异表现114。相比传统方法,其核心突破体现在:
- 深度聚合金字塔池化(DAPPM):通过多级池化核(5×5到17×17)的级联融合,在低分辨率特征图上实现更大感受野,相比传统PSPNet的PPM模块参数量减少30%1。
- 双分辨率并行架构(Bilateral Fusion):通过高分辨率分支(保留空间细节)和低分辨率分支(提取语义信息)的协同工作,解决了传统编码器-解码器结构中细节丢失与计算量大的矛盾114。
- 轻量化设计:通过通道压缩和残差瓶颈结构(RBB),DDRNet-23-slim版本仅需5.7M参数即可达到76.2% mIoU14。
理论知识
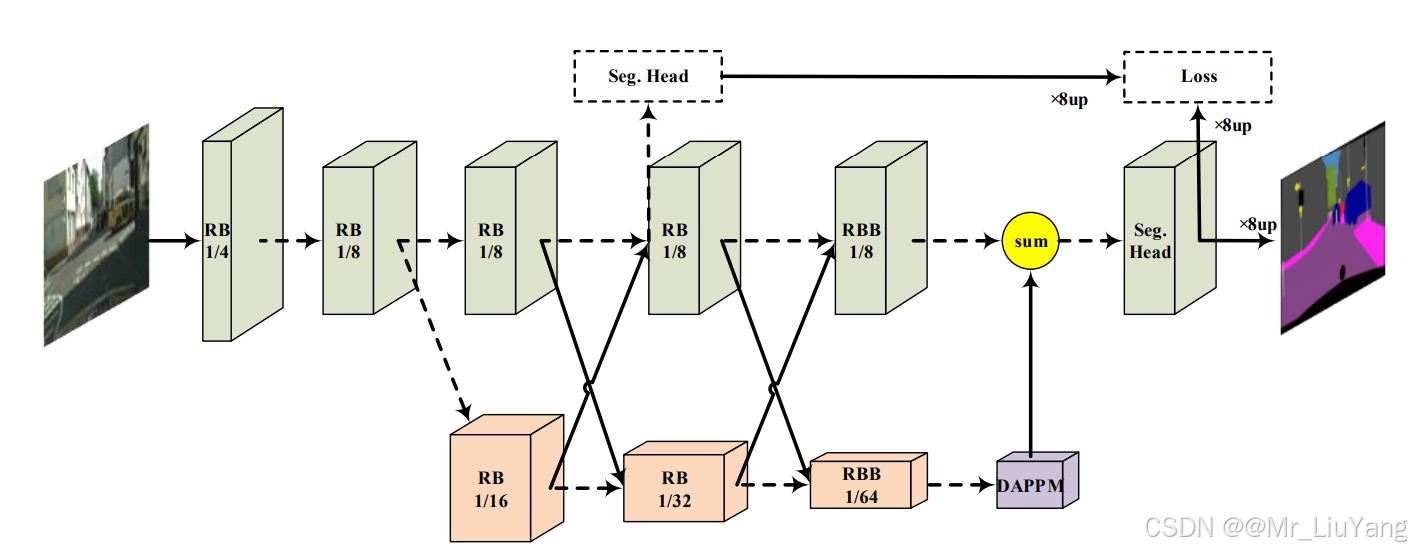
整体架构流程
class DDRNet(nn.Module):
def __init__(self, num_class=1, n_channel=3, arch_type='DDRNet-23-slim', ...):
self.conv1 = ConvBNAct(n_channel, init_channel, 3, 2) # 初始下采样
self.conv2 = Stage2(...) # 低分辨率分支构建
self.conv3 = Stage3(...) # 通道扩展
self.conv4 = Stage4(...) # 双分支初始化
self.conv5 = Stage5(...) # 深层特征融合
self.seg_head = SegHead(...) # 分割头
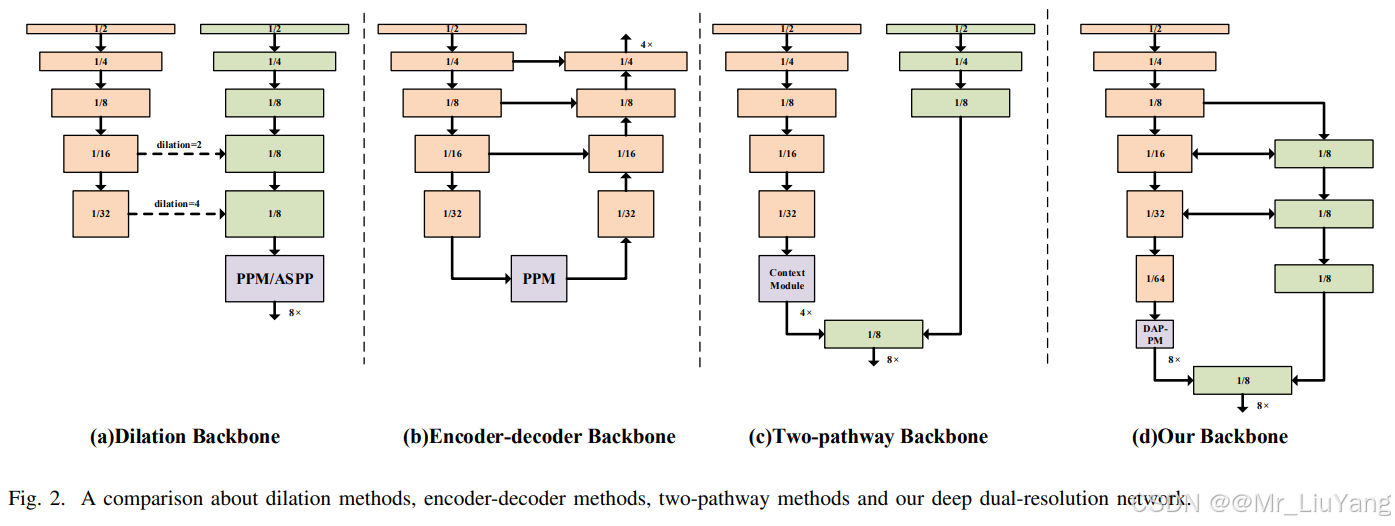
网络采用渐进式下采样策略,如下图d,从Stage4开始分为双分支:
- 高分辨率分支:保持1/8输入分辨率,使用常规残差块(RB)保留细节。
- 低分辨率分支:通过步长2卷积逐步下采样至1/32,使用瓶颈残差块(RBB)提取语义。
关键模块解析
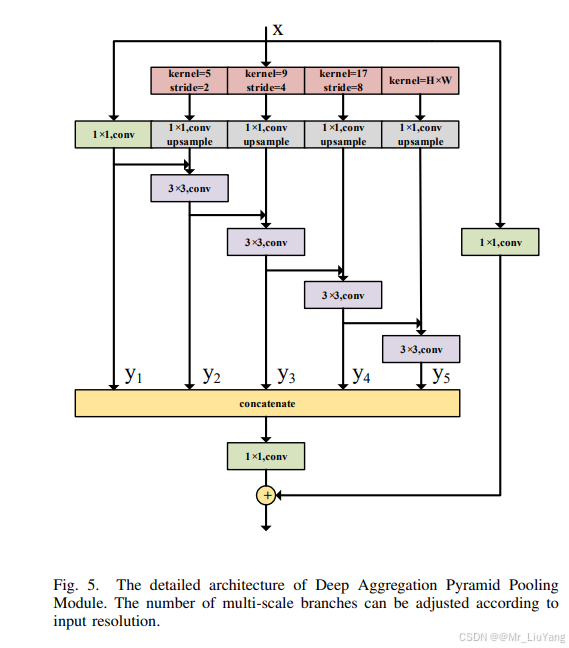
深度聚合金字塔池化(DAPPM)
class DAPPM(nn.Module):
def __init__(self, in_channels, out_channels, act_type='relu'):
...
self.conv0 = ...
self.conv1 = ...
self.pool2 = ...
self.conv2 = ...
self.pool3 = ...
self.conv3 = ...
self.pool4 = ...
self.conv4 = ...
self.pool5 = self._build_pool_layers(in_channels, hid_channels, -1, -1)
self.conv5 = ConvBNAct(hid_channels, hid_channels, 3, act_type=act_type)
...
def _build_pool_layers(self, ...):
# 构建多尺度池化层:5x5/9x9/17x17/全局平均池化
...
layers.append(nn.AvgPool2d(kernel_size, stride, padding))
def forward(self, x):
# 多级特征聚合
y1 = self.conv1(x)
y2 = self.pool2(x) -> conv2 -> 与y1融合
...
return conv_last(cat([y1,y2,y3,y4,y5])) + y0
1、每一层ConvBNAct(卷积、批标准化和激活函数组合)都包含以下几个部分:
- 卷积操作(Conv): 卷积层用于从输入图像中提取空间特征。
- 批量归一化(Batch Normalization, BN): 用于对每一层的输出进行标准化,减少内协方差偏移,加速训练过程,提升训练的稳定性。
- 激活函数(Act): 激活函数用来增加非线性能力,常见的激活函数包括 ReLU、LeakyReLU、Sigmoid 等。在该实现中,激活函数可以通过 act_type 参数灵活设置。
2、 _build_pool_layers(自适应池化和普通池化)函数用于构建不同尺度的池化层,并通过1x1卷积进一步处理池化结果。具体包括:
- AvgPool2d:通过平均池化层来下采样特征图,不同的池化核和步长可以捕捉到不同的尺度信息。
- AdaptiveAvgPool2d:自适应平均池化层将输入特征图的空间尺寸缩放到指定大小,通常用于全局信息的提取,生成固定大小的输出特征图。
3、forward(前向传播)实现了模块的前向传播流程,其主要步骤包括:
- 多尺度特征提取:
(1) conv1 对输入特征进行初步的转换,生成特征 y1。
(2) 通过不同尺度的池化操作(pool2, pool3, pool4, pool5),分别提取不同尺寸的上下文信息。池化后,通过插值将其恢复到原始输入的尺寸。
(3) 每个池化层后的卷积层(conv2, conv3, conv4, conv5)进一步处理池化得到的特征图。 - 特征融合与输出:
(1)将 y1, y2, y3, y4, y5 五个特征图按通道维度拼接(torch.cat),然后通过 conv_last 进行最终的卷积操作,得到融合后的特征。
(2)最后,y0 被加到融合后的特征图中,以保留输入特征图的细节信息。
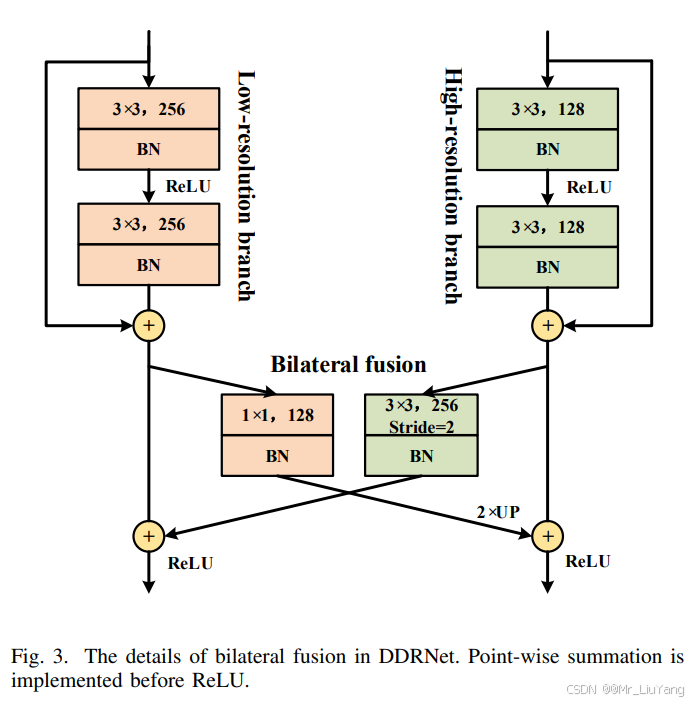
双边融合(Bilateral Fusion)
class BilateralFusion(nn.Module):
def forward(self, x_low, x_high):
fuse_low = self.conv_low(x_low)
fuse_high = self.conv_high(x_high)
# 高->低融合:高分辨率特征下采样后与低分辨率相加
x_low = self.act(x_low + fuse_high)
# 低->高融合:低分辨率特征上采样后与高分辨率相加
fuse_low = F.interpolate(fuse_low, size, mode='bilinear', align_corners=True)
x_high = self.act(x_high + fuse_low)
该模块实现了跨分辨率特征交换:
-
High-to-Low:通过3×3卷积下采样高分辨率特征,补充低分辨率分支的细节信息。
-
Low-to-High:通过1×1卷积压缩通道后双线性上采样,增强高分辨率分支的语义。
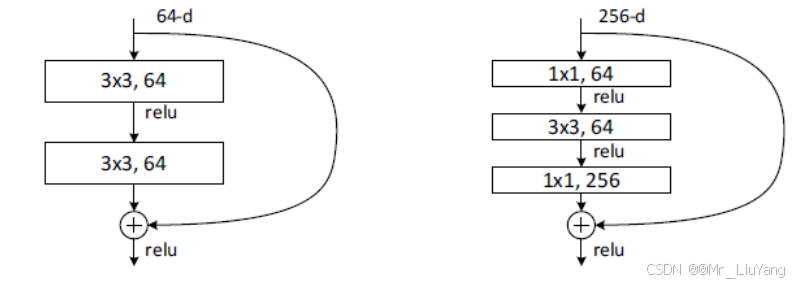
残差瓶颈结构(RBB)
class RBB(nn.Module):
def __init__(self, in_channels, out_channels, stride=1, act_type='relu'):
super().__init__()
self.downsample = (stride > 1) or (in_channels != out_channels)
self.conv1 = ConvBNAct(in_channels, in_channels, 1, act_type=act_type)
self.conv2 = ConvBNAct(in_channels, in_channels, 3, stride, act_type=act_type)
self.conv3 = ConvBNAct(in_channels, out_channels, 1, act_type='none')
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.conv2(out)
out = self.conv3(out)
if self.downsample:
identity = self.conv_down(x)
out += identity
一种基于残差网络的瓶颈块结构,通过在 3x3 卷积之前使用 1x1 卷积降低通道数,瓶颈设计(即使用 1x1 卷积进行通道数调整)能够有效减少计算量。下图左图为正常残差结构,右图为RBB结构,先降低通道数再卷积再回到原始通道数。
模型实践
训练数据准备
提示:云盘代码已内置少量高分二号卫星影像建筑物数据集
训练数据分为原始影像和标签(二值化,0和255),均位于Sample文件夹内,本示例数据为512*512,数据相对路径为:
Sample\Build\train\ IMG_T1
------------------\ IMG_LABEL
-------------\val \ IMG_T1
------------------\IMG_LABEL
模型训练
运行dp0_train.py,模型开始训练,核心参数包括:
| parser参数 | 说明 |
|---|---|
| num_epochs | 训练批次 |
| learning_rate | 初始学习率 |
| batch_size | 单次样本数量 |
| dataset | 数据集名字 |
| crop_height | 训练时影像重采样尺度 |
数据结构CDDataset_Seg定义在utils文件夹dataset.py中,注意读取后进行了数据增强(随机翻转),灰度化,尺寸调整,标签归一化、 one-hot 编码,以及维度和数据类型的转换,最终得到适用于 PyTorch 模型训练的张量。
# 读取训练图片和标签图片
image_t1 = cv2.imread(image_t1_path,-1)
#image_t2 = cv2.imread(image_t2_path)
label = cv2.imread(label_path)
# 随机进行数据增强,为2时不做处理
if self.data_augment:
flipCode = random.choice([-1, 0, 1, 2])
if flipCode != 2:
# image_t1 = normalized(image_t1, 'tif')
image_t1 = self.augment(image_t1, flipCode)
#image_t2 = self.augment(image_t2, flipCode)
label = self.augment(label, flipCode)
label = cv2.cvtColor(label, cv2.COLOR_BGR2GRAY)
image_t1 = cv2.resize(image_t1, (self.img_h, self.img_w))
#image_t2 = cv2.resize(image_t2, (Config.img_h, Config.img_w))
label = cv2.resize(label, (self.img_h, self.img_w))
label = label/255
label = label.astype('uint8')
label = onehot(label, 2)
label = label.transpose(2, 0, 1)
label = torch.FloatTensor(label)
训练过程如下图所示,模型保存至checkpoints数据集同名文件夹内。
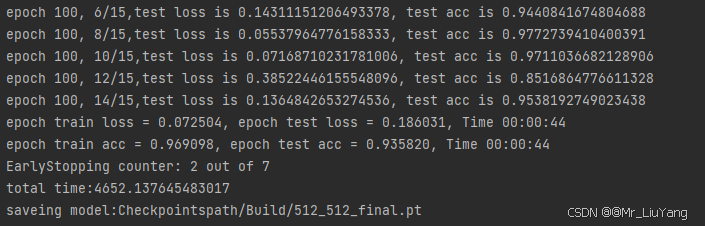
影像测试
运行dp0_AllPre.py,核心参数包括:
| parser参数 | 说明 |
|---|---|
| Checkpointspath | 预训练模型位置名称 |
| Dataset | 批量化预测数据文件夹 |
| Outputpath | 输出数据文件夹 |
数据加载方式:
pre_dataset = CDDataset_Pre(data_path=pre_imgpath1,
transform=transforms.Compose([
transforms.ToTensor()]))
pre_dataloader = torch.utils.data.DataLoader(dataset=pre_dataset,
batch_size=1,
shuffle=False,
pin_memory=True,
num_workers=0)
需要注意,预测定义的数据结构CDDataset_Pre与训练时CDDataset_Seg有区别,没有resize等,后续使用自己的数据训练时注意调整。
结果示例





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









