







文章目录
提示: (1)论文地址 :https://arxiv.org/abs/2406.09414 (2)本人打包好预训练模型可运行代码 :0415Depth-Anything-V2-main.zip 链接: https://pan.baidu.com/s/1Gmc1L67UYX2-624X-3RDYA?pwd=9x3m 提取码: 9x3m
1. 文章背景:解决现有基准的局限性
传统的单目深度估计基准,如NYU-D和KITTI,已经在研究中得到了广泛应用。然而,这些基准存在一些显著的局限性。
- 首先,它们的标注存在噪声问题,尤其是在镜面反射和细小结构的深度标注上。
- 其次,现有的基准主要聚焦于特定场景(例如,NYU-D仅包含室内房间,KITTI主要包含街道场景),因此无法全面测试模型在各种环境下的表现。
- 最后,大多数基准图像分辨率较低,这对于现代相机和高分辨率图像的深度估计来说并不理想。
为了应对这些挑战,《Depth Anything V2》提出了一个新的评估基准——DA-2K,旨在为单目深度估计提供更精确、更全面的测试标准。
2. Depth Anything V2模型流程图
文章提出的解决方案很简单:加入无标签的真实图像,作者使用了五个精确的合成数据集(595K图像)和八个大规模伪标签真实数据集(62M图像)进行训练。Depth Anything V2模型流程图如下所示,它包括三个步骤:
- 首先,基于DINOv2-G,在高质量合成图像上训练一个可靠的教师模型。
- 然后,为了减轻合成数据的分布偏移和有限多样性,使用教师模型在大规模无标签真实图像上生成伪深度标签。
- 最后,在伪标签图像上训练最终的学生模型,以实现稳健的泛化。

损失函数方面,使用两个损失项来对标注图像进行优化:一个尺度和偏移不变的损失L_ssi和一个梯度匹配损失L_gm,来自MiDaS,详细见Github:https://github.com/isl-org/MiDaS。
3. 提出DA-2K数据集:更精确、更多样化的深度评估基准
DA-2K 是《Depth Anything V2》文章的核心贡献之一,它解决了现有基准的几个关键问题:
-
精确的深度标注:与传统基准不同,DA-2K并不试图为每个像素提供密集的深度标注,而是通过标注稀疏的深度对(pixel pairs)来进行训练和评估。每对像素表示两个点在空间中的相对深度关系。通过这种方式,DA-2K能够避免传统方法中存在的标注噪声问题。
-
多样化的应用场景:为了确保评估的广泛性,DA-2K包含了多种不同的场景,涵盖了八个重要的应用场景,如室内环境、街道、自然景观等。这些场景不仅代表了不同的物理环境,还考虑到了不同的深度估计任务需求。通过使用自动化生成的关键词(如GPT-4生成的关键词),DA-2K收集了来自Flickr的多样化图像,以确保场景的多样性。
-
高分辨率图像:DA-2K的图像分辨率更高(1000×2000),更符合现代相机的需求,从而能够提供更精确的深度估计。
为了确保标注的准确性,DA-2K的所有深度标注都经过了三重检查。具体来说,文章中的标注流程包括以下几个步骤:
-
自动化和人工标注结合:首先,使用自动化工具(如SAM)预测物体的掩膜,并从中选取关键像素对。然后,模型会对这些像素对的相对深度进行投票。若投票结果存在不一致,则将该对提交给人工标注员进行确认。这种三重检查机制确保了标注的高精度。
-
场景多样性的保证:为了确保所选图像的多样性,研究团队使用GPT-4生成的关键词从Flickr中下载了大量的图像。这些图像涉及到不同的场景和情境,进一步增加了基准的广度和适用性。
尽管DA-2K具有许多优势,但文章明确指出,它并不是要取代现有的深度估计基准。传统的基准仍然在许多任务中发挥着重要作用,特别是在需要精确密集深度估计的场景重建任务中,DA-2K的稀疏深度标注无法完全满足需求。然而,DA-2K可以作为现有基准的有力补充,特别是在以下几个方面:
-
广泛的场景覆盖:DA-2K涵盖了多种不同的应用场景,可以作为一种快速验证工具,帮助用户选择最适合特定场景的社区模型。
-
先验验证工具:由于其精确的标注和广泛的场景覆盖,DA-2K可以作为模型选择的先验验证工具,帮助研究人员和工程师在特定应用场景中更好地评估和选择合适的模型。
-
未来多模态大语言模型的测试平台:DA-2K还具有潜力作为未来3D感知任务的测试平台,尤其是对多模态大语言模型(如GPT等)的测试。
4. 可执行代码模型试用
提示:云盘代码img文件夹已内置少量图像示例
精度对比
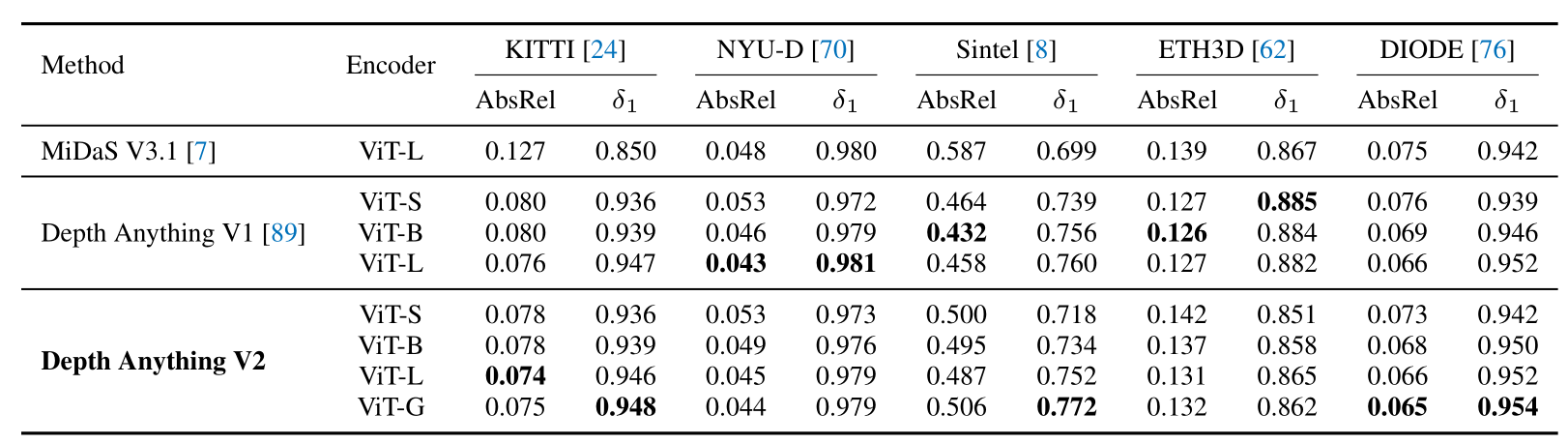
仅从指标来看(更好:AbsRel ↓,δ 1 ↑),Depth Anything V2优于MiDaS,但与V1相比差不多。然而,V2的重点和优势(例如,细粒度的细节、对复杂布局和透明物体的鲁棒性等)在这些基准上无法得到正确的反映。

在作者提出的DA-2K评估基准上的表现,该基准涵盖了八种具有代表性的场景。即使是最轻量级的模型,也优于所有其他社区模型。
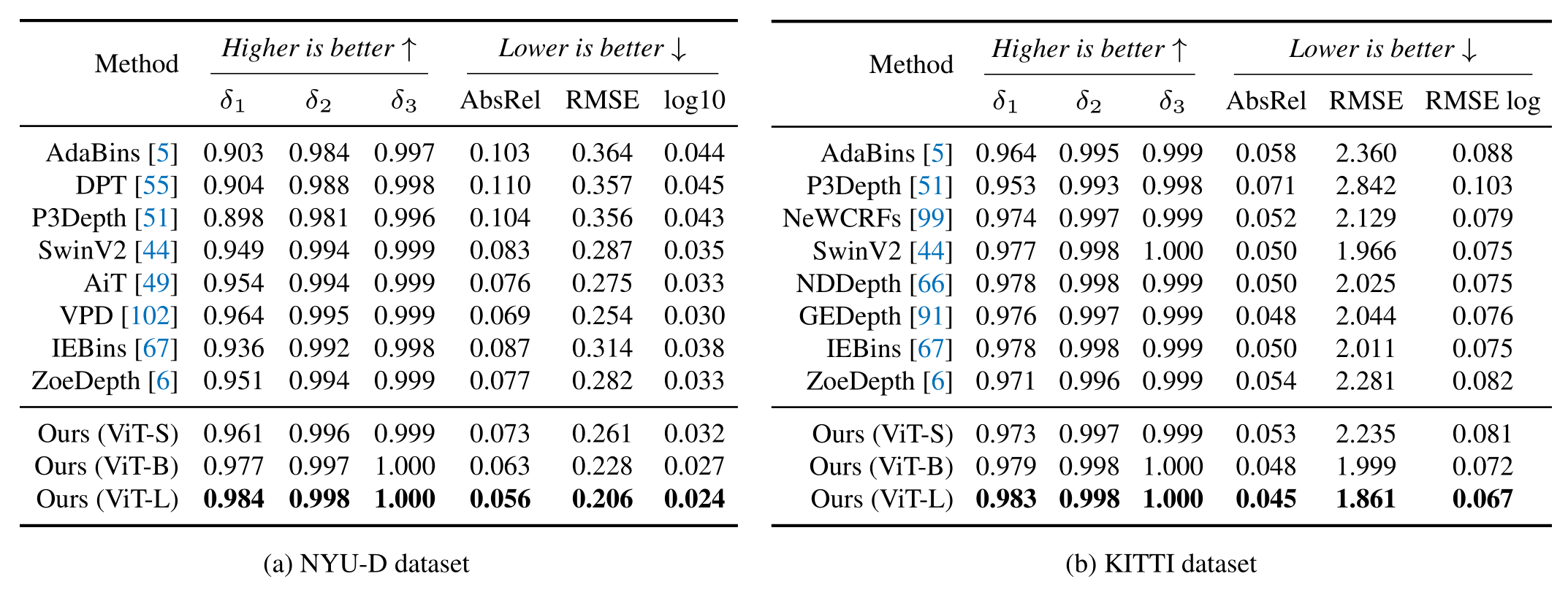
作者将预训练的Depth Anything V2编码器微调到领域内度量深度估计,即训练和测试图像共享相同的领域。所有对比方法使用的编码器大小接近ViT-L,精度对比结果如上。
预训练模型使用
运行run.py,调用预训练模型求解制定照片深度,核心参数包括:
| parser参数 | 说明 |
|---|---|
| –img-path | 支持三种输入:1)图片目录 2)单张图片 3)存储图片路径的文本文件 |
| –input-size | 默认使用518尺寸输入,增大尺寸可获得更精细结果 |
| –encoder | 模型参数量,vits 24.8M、vitb 97.5M、vitl 335.3M 、vitg 1.3B |
| –pred-only | 仅保存深度图,不保存原图 |
| –grayscale | 保存灰度深度图,不应用彩色映射 |
输出结果示例
Depth anything v2深度估计结果示例

grayscale=False

grayscale=True


















 3598
3598

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









