






1、下载安装spark和scala
关于配置,可以百度,网上很多
1.1 修改spark的conf里面的spark-env.sh文件
1.2 配置环境变量
2、编写spark的简单程序
package com.zdjt.spark;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Map;
public class WordCount {
public static void main(String[] args) {
// 创建SparkConf对象
SparkConf conf = new SparkConf()
.setAppName("WordCount")
.setMaster("spark://qf01:7077")
.set("spark.driver.host","192.168.47.130");
// 创建JavaSparkContext对象
JavaSparkContext sc = new JavaSparkContext(conf);
// 读取文本文件
JavaRDD<String> lines = sc.textFile("/flinkPro/word.txt");
// 计算单词出现次数
JavaRDD<String> words = lines.flatMap(line -> Arrays.asList(line.split(" ")).iterator());
JavaRDD<String> filteredWords = words.filter(word -> !word.isEmpty());
JavaPairRDD<String, Integer> wordCounts = filteredWords.mapToPair(word -> new Tuple2<>(word, 1))
.reduceByKey((x, y) -> x + y);
Map<String, Integer> wordCountsMap = wordCounts.collectAsMap();
// 输出结果
for (Map.Entry<String, Integer> entry : wordCountsMap.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
// 关闭JavaSparkContext对象
sc.close();
}
}
如果这行代码报错,说明你的包没有导入正确(也是废了好大劲才发现的)
JavaRDD<String> words = lines.flatMap(line -> Arrays.asList(line.split(" ")).iterator());
3、运行
进入bin目录执行
./spark-submit --class com.xxx.spark.WordCount --master spark://xxx.xxx.xxx.xxx:7077 /root/hadoop-1.0-SNAPSHOT.jar
其中:xxx.xxx.xxx.xxx是你的虚拟机ip(也就是你web页面的ip)
/root/hadoop-1.0-SNAPSHOT.jar 为你上传到hdfs上面的jar路径
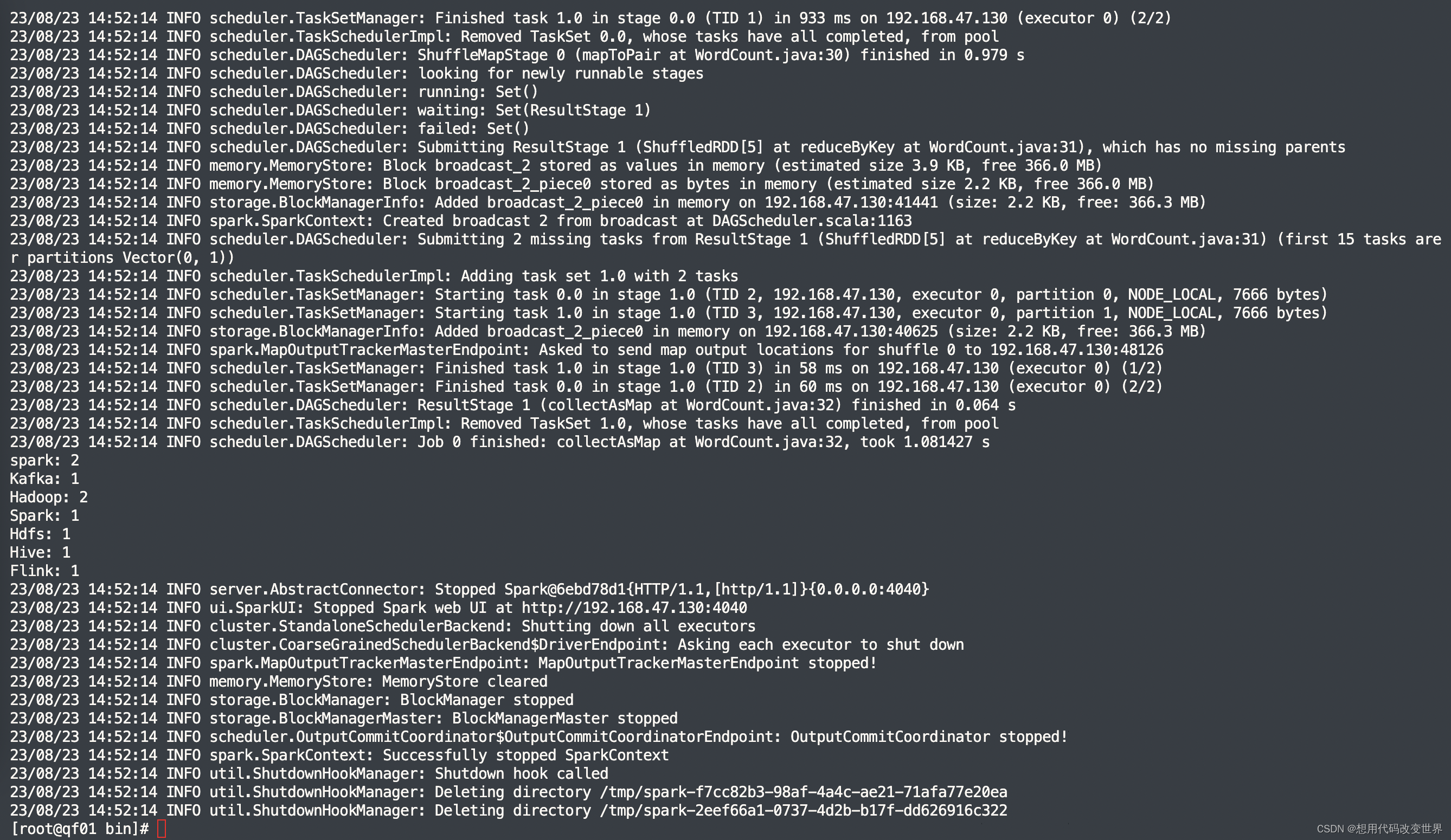
4、执行结果















 6709
6709











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









