







RDD是Spark中最基本的数据抽象。虽然Spark2.x中建议使用效率更高的DataSet代替RDD,但还是有必要学习一下RDD的相关知识。
本文第一部分简单介绍RDD的一些基本概念,第二部分则介绍RDD的常用操作并给出例子。
另外,本文介绍的操作不涉及到键值对RDD的操作,然而键值对RDD是许多操作所需要的常见数据类型,这部分内容会在下一篇笔记中补充。
文章目录
1. RDD简介
1.1 RDD是什么?
RDD(Resilient Distributed Dataset),弹性分布式数据集,是Spark中最基本的数据抽象。
- 每个RDD被分为多个分区Partition,这些分区运行在不同的节点上
- RDD允许用户显式地将工作集缓存在内存中,极大地提升效率
- RDD拥有Lineage(血统、谱系)信息,存储着父RDD等信息,当数据丢失时可以恢复,即具备容错性
- RDD拥有每个分区Partition的优先位置,可以通过“移动计算”减少网络通信开销
简单来说,Spark将用户的数据以RDD形式(实际上只存了数据的位置信息)分布式地保存并进行运算,且这种形式具有高容错性、位置感知、高效率的优点。
更详细的RDD内部结构可参考Spark之深入理解RDD结构。
1.2 RDD的两种操作
RDD支持两种类型的操作——转化操作(Transformation)与行动操作(Action)。
- 转化操作是指由一个RDD生成一个新的RDD,如filter操作,会筛选出符合条件的数据得到一个子RDD
- 行动操作是指对RDD计算出一个结果,把结果返回给程序或存储在外部存储系统(如HDFS)中
Spark对RDD的计算策略是惰性计算,即只有在遇到Action操作时才会真正计算,否则只是记录下不同的RDD之间的依赖关系(即lineage)。
举个例子来说明惰性计算的优势——
假设我们要把文件中包含Python的行筛选出来,并利用first操作获取第一个结果。如果Spark在我们运行时就把文件中所有的行都读取并存储起来,就会消耗很多存储空间,而我们马上就要筛选掉其中的很多数据。相反,一旦Spark了解完整的转化操作链,它就可以只计算求结果时真正需要的数据。事实上,在调用first操作时,Spark只需要扫描文件直到找到第一个匹配的行,而不需要读取整个文件。
通过转化操作,可以从已有的RDD中派生出新的RDD,Spark 会使用谱系图(lineage graph) 来记录这些不同RDD之间的依赖关系。Spark需要用这些信息来按需计算每个RDD,也可以依靠谱系图在持久化的RDD丢失部分数据时恢复所丢失的数据。
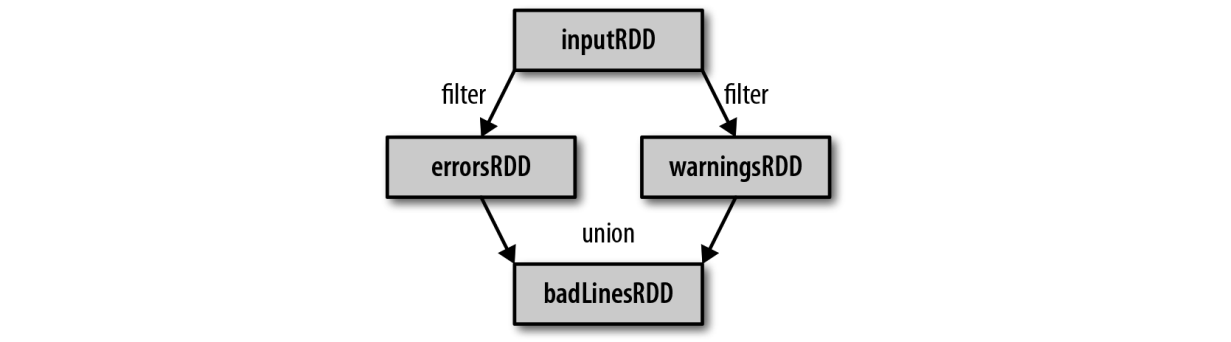
1.3 RDD的宽依赖、窄依赖
RDD的Transformation操作会生成新的RDD,父RDD和子RDD之间的依赖关系可分为宽依赖和窄依赖。
- 窄依赖,指父RDD的每个分区只被子RDD的一个分区所使用,子RDD分区通常对应常数个父RDD分区
- 宽依赖,指父RDD的每个分区都可能被多个子RDD分区所使用,子RDD分区通常对应所有的父RDD分区
如下图中的map操作和union操作为窄依赖,groupBy操作为宽依赖,而join操作对B为窄依赖,对F为宽依赖。
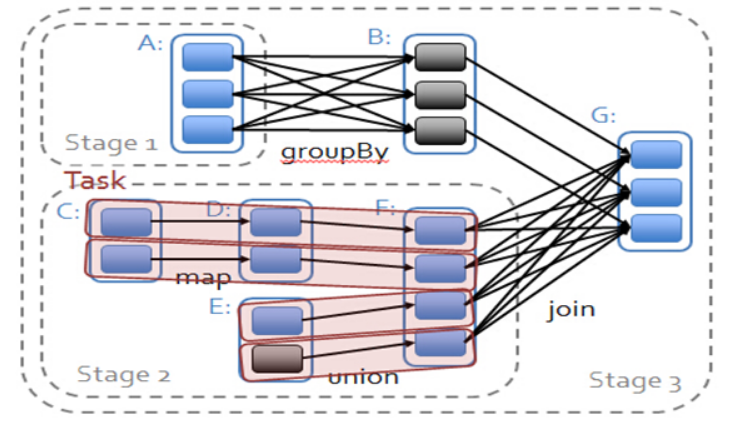
DAG Scheduler划分Stage的方法:从后往前推,遇到宽依赖则划分为新的stage,遇到窄依赖就加入当前stage。
以上图为例,从后往前,遇到A-B之间的宽依赖,将A划分为Stage1;遇到F-G之间的宽依赖,将F划分为Stage2,从F往前,均为窄依赖,故将C、D、E均加入Stage2。剩余部分为获取最后结果G的部分,划分为Stage3。
划分Stage后,每个Stage的Task数量由当前Stage最后的RDD分区数决定,如上图的Stage2最后的RDD为F,分区数为4,所以有4个Task,以TaskSet的形式交给Task Scheduler。
- Stage1和Stage2称为ShuffleMapStage,相当于Hadoop中的Map阶段,生成的任务称为ShuffleMapTask
- Stage3称为ResultStage,获取最后结果,相当于Hadoop中的Reduce阶段,生成的任务称为ResultTask
2. RDD操作实例
2.1 创建RDD
有两种方式创建RDD,从外部数据集读入或在驱动器程序中对集合进行并行化。
- 从外部数据集读入

- 在驱动器程序中对集合进行并行化

2.2 Transformation操作
尝试常用的转化操作,更详细的可以查阅手册或其他资料。
filter操作,传入一个判定函数,保留判定结果为1的数据,如获取包含Spark的句子

map,传入一个映射函数,对每个元素做某种映射,返回映射后的RDD,如将所有句子变为大写

flatMap,传入的函数对每个元素进行运算并返回一个迭代器,输出的RDD由所有迭代器内的元素组成(而不是迭代器组成的RDD),如获取整个RDD的所有单词

- 伪集合操作,包括
union、intersection、subtract、cartesian操作,允许有重复(可以使用distinct操作去重,但是开销很大,因为是宽依赖,需要shuffle)。示例如下:

2.3 Action操作
尝试常用的行动操作,更详细的可以查阅手册或其他资料。
collect,返回RDD的所有元素,如下:

count,对当前RDD进行计数;countByValue则返回一个字典,对每个取值进行计数,如下:

take,获取当前RDD中指定个数的元素

reduce,提供一个函数(如sum),并行归约整个RDD的数据,如下:

fold,类似reduce,但需要提供一个初值,如sum初值为0,multiply初值为1,如下:

aggregate,提供初值、初值与元素之间的操作函数、不同分区结果之间的操作函数,如下,每个分区用初值(0,0)跟其元素做求和与计数,所有分区都得到求和与计数结果后,根据第二个函数合并,相当于先用map将所有元素映射为(**, 1)的形式,再用reduce求和

2.3 persist操作
persist用于将RDD持久化,可以缓存在内存或磁盘中,根据参数StorageLevel决定,默认是只在内存中。
对应的,有unpersist用于取消RDD持久化。
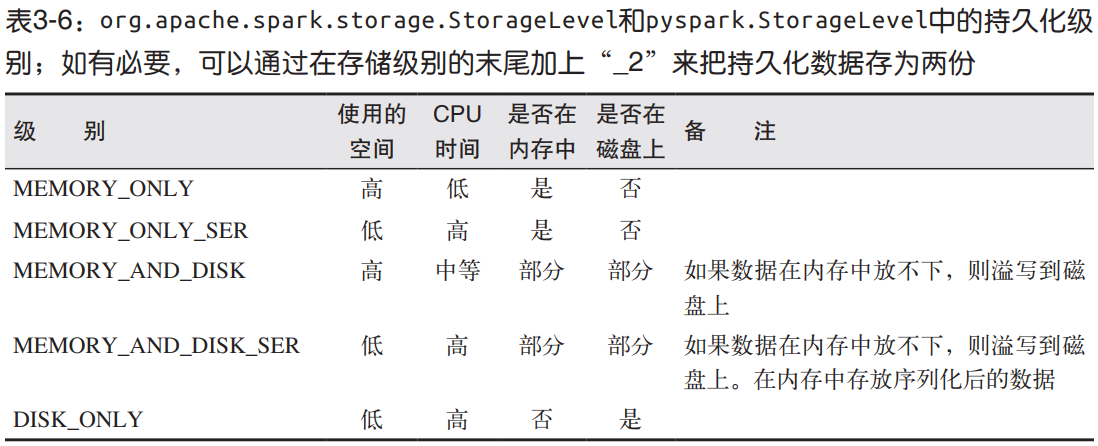
如果要缓存的数据太多, 内存中放不下, Spark 会自动利用最近最少使用(LRU)的缓存策略把最老的分区从内存中移除。 但是对于使用内存与磁盘的缓存级别的分区来说,被移除的分区都会写入磁盘。不必担心你的作业因为缓存了太多数据而被打断。不过,缓存不必要的数据会导致有用的数据被移出内存,带来更多重算的时间开销。
Reference
- 《Spark快速大数据分析》
- Spark学习之路 (三)Spark之RDD
- Spark之深入理解RDD结构















 2223
2223











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









