







RDD运行原理
RDD设计背景
许多选代目前的MapReduce框架都是把中间结果写入到稳定存储 (比如磁盘)中带来了大量的数据复制、磁盘IO和序列化开销
RDD就是为了满足这种需求而出现的,它提供了一个抽象的数据架构,我们不必担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换处理,不同RDD之间的转换操作形成依赖关系,可以实现管道化,避免中间数据存储。
RDD概念
-
一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,每个RDD可分成多个分区,每个分区就是一个数据集片段,并且一个RDD的不同分区可以被保存到集群中不同的节点上,从而可以在集群中的不同节点上进行并行计算
-
RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,不能直接修改,只能基于稳定的物理存储中的数据集创建RDD,或者通过在其他RDD上执行确定的转换操作(如map、join和group by) 而创建得到新的RDD
-
RDD提供了一组丰富的操作以支持常见的数据运算,分为“动作”(Action)和“转换” (Transformation)两种类型
-
RDD提供的转换接口都非常简单,都是类似map、filter、groupBy、join等粗粒度的数据转换操作,而不是针对某个数据项的细粒度修改(不适合网页爬虫)
-
表面上RDD的功能很受限、不够强大,实际上RDD已经被实践证明可以高效地表达许多框架的编程模型(比如MapReduce、SQL、Pregel)
-
Spark提供了RDD的API,程序员可以通过调用API实现对RDD的各种操作
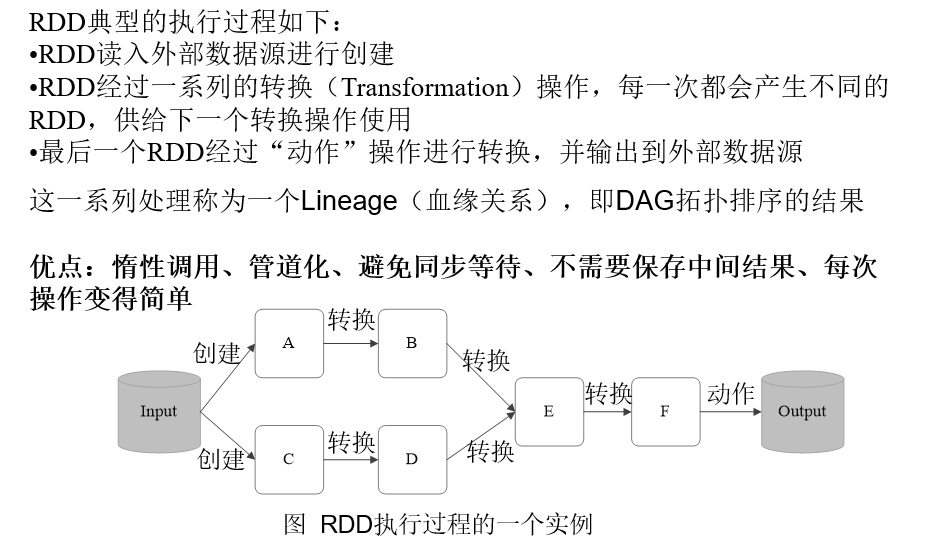
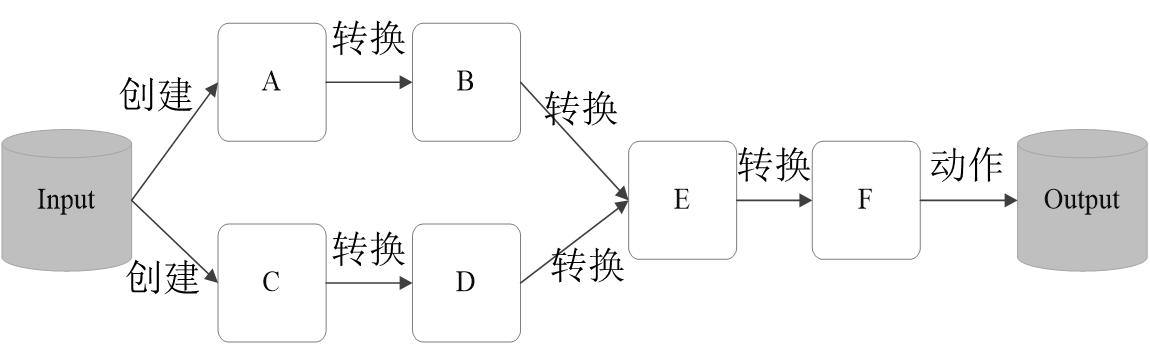
RDD运行过程
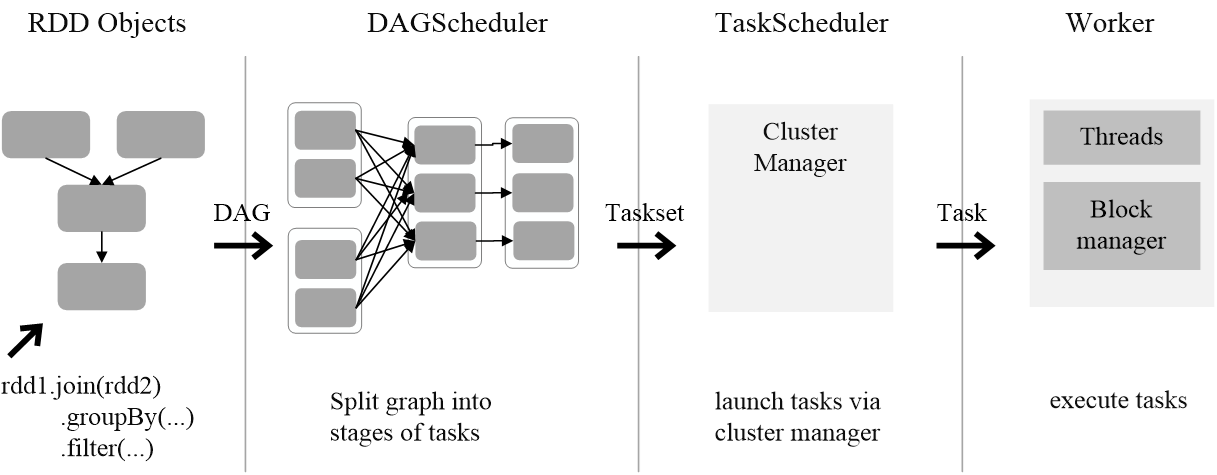
通过上述对RDD概念、依赖关系和Stage划分的介绍,结合之前介绍的Spark运行基本流程,再总结一下RDD在Spark架构中的运行过程:
(1)创建RDD对象;
(2)SparkContext负责计算RDD之间的依赖关系,构建DAG;
(3)DAGScheduler负责把DAG图分解成多个Stage,每个Stage中包含了多个Task,每个Task会被TaskScheduler分发给各个WorkerNode上的Executor去执行。
RDD编程基础
1. RDD创建
- 从文件系统中加载数据创建RDD
>>> lines = sc.textFile("file:///opt/spark/mycode/rdd/word.txt")
>>> lines.foreach(print)
Hadoop is good
Spark is fast
Spark is better

- 从分布式文件系统HDFS中加载数据
>>>lines = sc.textFile("hdfs://localhost:9000/user/hadoop/word.txt")
>>>lines = sc.textFile("/user/hadoop/word.txt")
>>>lines = sc.textFile("word.txt")
三条语句等价
- 通过并行集合(列表)创建RDD
可以调用SparkContext的parallelize方法,在Driver中一个已经存在的集合(列表)上创建。
>>>array = [1, 2, 3, 4, 5]
>>>rdd = sc.parallelize(array)
>>>rdd.foreach(print)
1
2
3
4
5

2. RDD操作
1. 转换操作
对于RDD而言,每一次转换操作都会产生不同的RDD,供给下一个“转换”使用。
转换得到的RDD是惰性求值的,也就是说,整个转换过程只是记录了转换的轨迹,并不会发生真正的计算,只有遇到行动操作时,才会发生真正的计算,开始从血缘关系源头开始,进行物理的转换操作。
常用的RDD转换操作API:
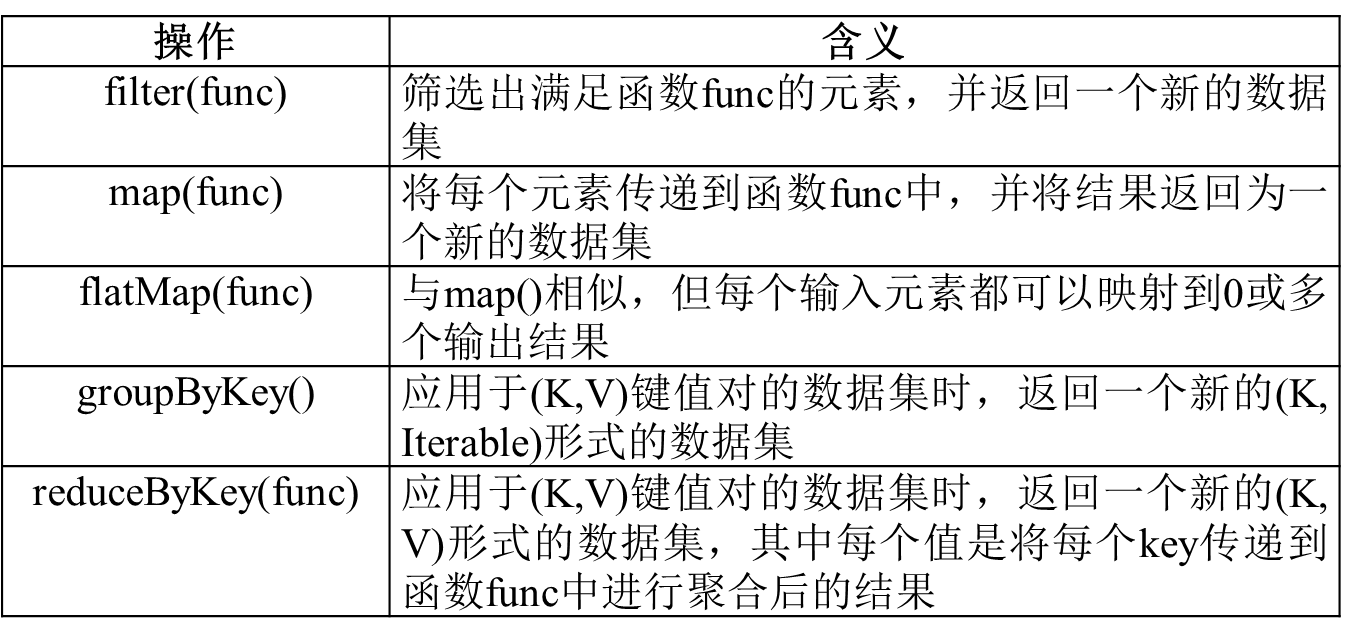
· filter(func):筛选出满足函数func的元素,并返回一个新的数据集
>>>lines = sc.textFile("file:///opt/spark/mycode/rdd/word.txt")
>>>linesWithSpark = lines.filter(lambda line: "Spark" in line)
>>>linesWithSpark.foreach(print)
Spark is better
Spark is fast

· map(func):将每个元素传递到函数func中,并将结果返回为一个新的RDD
>>>data = [1, 2, 3, 4, 5]
>>>rdd1 = sc.parallelize(data)
>>>rdd2 = rdd1.map(lambda x:x+10)
>>>rdd2.foreach(print)
11
13
12
14
15

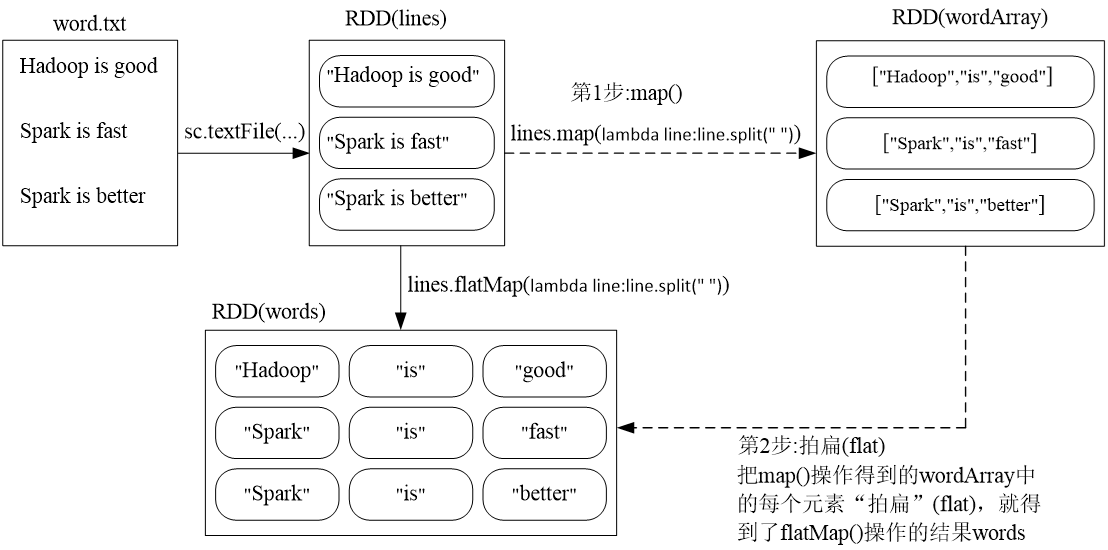
>>>lines = sc.textFile("file:///opt/spark/mycode/rdd/word.txt")
>>>words = lines.map(lambda line:line.split(" "))
>>>words.foreach(print)
['Hadoop', 'is', 'good']
['Spark', 'is', 'fast']
['Spark', 'is', 'better']

· flatMap(func):
>>>lines =sc.textFile("file:///opt/spark/mycode/rdd/word.txt")
>>>words = lines.flatMap(lambda line:line.split(" "))
>>>words.foreach(print)
Hadoop
is
good
Spark
is
fast
Spark
is
better
· groupByKey():应用于(K, V)键值对数据集时,返回一个新的(k, Iterable)形式的数据集
>>>words = sc.parallelize([("Hadoop",1), ("is",1), ("good", 1), ("Spark",1),\
...("is",1), ("fast",1), ("Spark",1), ("is",1), ("better",1)])
>>>words1 = words.groupByKey()
>>>words1.foreach(print)
('Hadoop', <pyspark.resultiterable.Resultlterable object at 0x7fb210552c88>)
('better', <pyspark.resultiterable.Resultlterable object at 0x7fb210552e80>)
('fast', <pyspark.resultiterable.Resultlterable object at 0x7fb210552c88>)
('good', <pyspark.resultiterable.Resultlterable object at 0x7fb210552c88>)
('Spark', <pysparkresultiterable.Resultlterable object at 0x7fb210552f98>)
('is', <pyspark.resultiterable.Resultlterable object at 0x7fb210552e10>)

· reduceByKey(func) 应用于(K, V)键值对的数据集时,返回一个新的(K, V)形式的数据集,其中的每个值是将每个Key传递到函数func中进行聚合后得到的结果
>>>words = sc.parallelize([("Hadoop",1),("is",1),("good",1),("Spark",1),\
...("is",1),("fast",1),("Spark",1),("is",1),("better",1)])
>>>words1 = words.reduceByKey(lambda a,b:a+b)
>>>words1.foreach(print)
('good', 1)
('Hadoop', 1)
('better', 1)
('Spark', 2)
('fast', 1)
('is', 3)

2. 行动操作
行动操作是真正触发计算的地方。Spark程序执行到行动操作时,才会执行真正的计算,从文件中加载数据,完成一次又-次转换操作,最终,完成行动操作得到结果。
常用的RDD行动操作API:
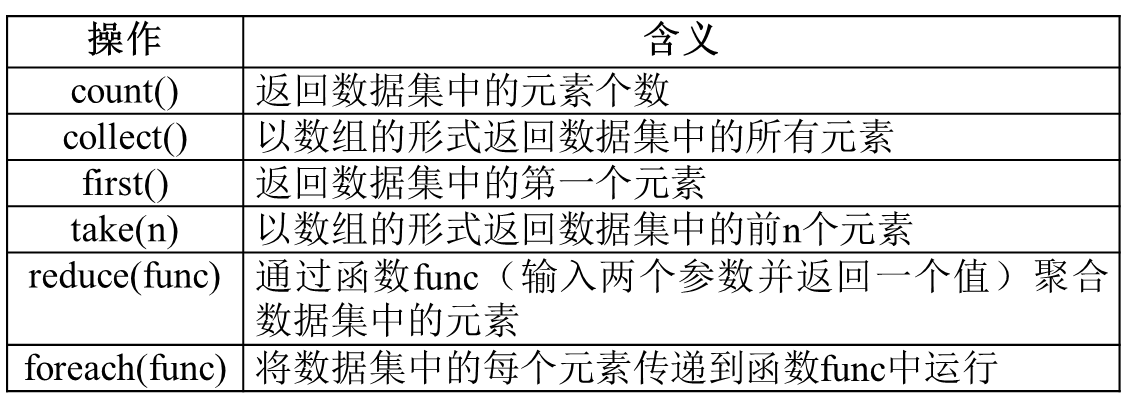
>>>rdd = sc.parallelize([1,2,3,4,5])
>>>rdd.count()
5
>>>rdd.first()
1
>>>rdd.take(3)
[1, 2, 3]
>>>rdd.reduce(lambda a,b:a+b)
15
>>>rdd.collect()
[1, 2, 3, 4, 5]
>>>rdd.foreach(lambda elem:print(elem))
1
2
3
4
5
3. 持久化
惰性机制:所谓的“惰性机制”是指,整个转换过程只是记录了转换的轨迹,并不会发生真正的计算,只有遇到行动操作时,才会触发“从头到尾”的真正的计算这里给出一段简单的语句来解释Spark的惰性机制
在Spark中,RDD采用惰性求值的机制,每次遇到行动操作,都会从头开始执行计算。每次调用行动操作,都会触发一次从头开始的计算。这对于迭代计算而言,代价是很大的,迭代计算经常需要多次重复使用同一组数据
下面就是多次计算同一个RDD的例子:
>>>list = ["Hadoop","Spark","Hive"]
>>>rdd = sc.parallelize(list)
>>>print(rdd.count()) //行动操作,触发一次真正从头到尾的计算
>>>print(','.join(rdd.collect())) //行动操作,触发一次真正从头到尾的计算
可以通过持久化(缓存)机制避免这种重复计算的开销
可以使用persist0)方法对一个RDD标记为持久化
之所以说“标记为持久化”,是因为出现persist)语句的地方,并不会马上计算生成RDD并把它持久化,而是要等到遇到第一个行动操作触发真正计算以后,才会把计算结果进行持久化
持久化后的RDD将会被保留在计算节点的内存中被后面的行动操作重复使用

针对上面的实例,增加持久化语句以后的执行过程如下:
>>>list =["Hadoop", "Spark", "Hive"]
>>>rdd = sc.parallelize(list)
>>>rdd.cache()#会调用persist(MEMORY ONLY),但是,语句执行到这里并不会缓存rdd,因为这时rdd还没有被计算生成
>>>print(rdd.count()) #第一次行动操作,触发一次真正从头到尾的计算,这时上面的rdd.cache()才会被执行,把这个rdd放到缓存中
3
>>> print(','.join(rdd.collect()))#第二次行动操作,不需要触发从头到尾的计算,只需要重复使用上面缓存中的rdd
Hadoop,Spark,Hive
4. 分区
RDD是弹性分布式数据集,通常RDD很大,会被分成很多个分区,分别保存在不同的节点上
- 分区的作用
(1) 增加并行度

(2) 减少通讯开销
有两个表:
UserData (Userld,Userlnfo)
Events (UserlD,LinkInfo)
UserData 和 Events 表进行连接操作,获得(UserlD,Userlnfo,Linklnfo)
未分区时对UserData和Events两个表进行连接操作:
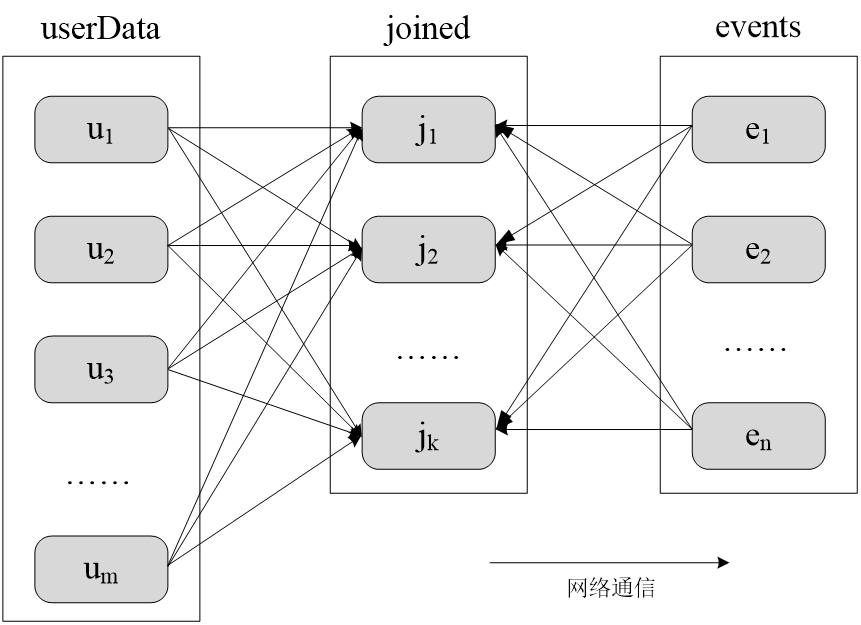
采用分区后对UserData和Events两个表进行连接操作:

- RDD分区原则
RDD分区的一个原则是使得分区的个数尽量等于集群中的CPU核心(core)数目
对于不同的Spark部署模式而言 (本地模式、Standalone模式、YARN模式、Mesos模式),都可以通过设置spark.default.parallelism这个参数的值,来配置默认的分区数目,一般而言:
(1)本地模式:默认为本地机器的CPU数目,若设置了local[N],则默认为N
(2)Apache Mesos:默认的分区数为8
(3)Standalone或YARN:在 “集群中所有CPU核心数目总和” 和 “2” 二者中取较大值作为默认值
- 设置分区的个数
(1) 创建RDD时手动指定分区个数
在调用textFile0和parallelize0方法的时候手动指定分区个数即可,语法格式如下:
sc.textFile(path,partitionNum)
>>>list =[1,2,3,4,5]
>>>rdd =sc.parallelize(list,2) #设置两个分区
(2) 使用reparititon方法重新设置分区个数
通过转换操作得到新 RDD 时,直接调用 repartition 方法即可。例如:
>>>data = sc.parallelize([1,2,3,4,5], 2)
>>>len(data.glom().collect()) #显示data这个RDD的分区数量
2
>>>data.glom().collect() #显示分区为2的情况
[[1, 2], [3, 4, 5]]
>>>rdd = data.repartition(1) #对data这个RDD进行重新分区
>>>len(rdd.glom().collect()) #显示rdd这个RDD的分区数量
1
>>>rdd.glom().collect()
[[1, 2, 3, 4, 5]] #显示分区为1的情况
- 自定义分区方法
Spark提供了自带的HashPartitioner(哈希分区)与RangePartitioner(区域分区),能够满足大多数应用场景的需求。与此同时,Spark也支持自定义分区方式,即通过提供一个自定义的分区函数来控制RDD的分区方式,从而利用领域知识进一步减少通信开销
>>>data = sc.parallelize(range(10), 5)
>>>data.glom().collect()
>>>[[0, 1], [2, 3], [4, 5], [6, 7], [8, 9]]
>>>rdd = data.map(lambda x:(x,1)).partitionBy(10,lambda x:0).map(lambda x:x[0])
>>>rdd.glom().collect() # 分到第一区
[[0, 1, 2, 3, 4, 5, 6, 7, 8, 9], [], [], [], [], [], [], [], [], []]
>>>rdd = data.map(lambda x:(x,1)).partitionBy(10,lambda x:2).map(lambda x:x[0])
>>>rdd.glom().collect() # 分到第三区
[[], [], [0, 1, 2, 3, 4, 5, 6, 7, 8, 9], [], [], [], [], [], [], []]
>>>rdd = data.map(lambda x:(x,1)).partitionBy(10,lambda x:x).map(lambda x:x[0])
>>>rdd.glom().collect() # 分到各自的key区
>>>[[0], [1], [2], [3], [4], [5], [6], [7], [8], [9]]
>>>rdd = data.map(lambda x:(x,1)).partitionBy(10,lambda x:(x+1)%10).map(lambda x:x[0])
>>>rdd.glom().collect() # 分到各自的(key+1)区(环式,舍去%效果一样)
>>>[[9], [0], [1], [2], [3], [4], [5], [6], [7], [8]]
3. 键值对RDD
1. 键值对RDD的创建
(1)第一种创建方式:从文件中加载
可以采用多种方式创建RDD,其中一种主要方式是使用 map() 函数来实现
>>>lines = sc.textFile("file:///opt/spark/mycode/pairrdd/word.txt")
>>>pairRDD = lines.flatMap(lambda line:line.split(" ")).map(lambda word:(word, 1))
>>>pairRDD.foreach(print)
('I', 1)
('love', 1)
('Hadoop', 1)
(2) 第二种创建方式:通过并行集合(列表)创建RDD
>>>list =["Hadoop", "Spark", "Hive", "Spark"]
>>>rdd = sc.parallelize(list)
>>>pairRDD =rdd.map(lambda word:(word,1))
>>>pairRDD.foreach(print)
('Hadoop', 1)
('Spark', 1)
('Hive', 1)
('Spark', 1)
2. 常用的键值对RDD转换操作
- reduceByKey(func)
- groupByKey()
- keys
- values
- sortByKey()
- mapValues(func)
- join
- combineByKey
· reduceByKey(func):使用func函数合并具有相同键的值
>>>pairRDD = sc.parallelize([("Hadoop",1),("Spark",1),("Hive",1),("Spark",1)])
>>>pairRDD.reduceByKey(lambda a,b:a+b).foreach(print)
('Spark', 2)
('Hive', 1)
('Hadoop', 1)
· groupByKey():对具有相同键的值进行分组
比如,对四个键值对(“spark”,1)、(“spark”,2)、(“hadoop”,3)和(“hadoop”,5)采用groupByKey()后得到的结果是: (“spark”,(1,2)) 和 (“hadoop”,(3,5))
>>>list =[("spark",1),("spark",2),("hadoop",3),("hadoop",5)]
>>>pairRDD = sc.parallelize(list)
>>>pairRDD.groupByKey()
PythonRDD[251] at RDD at PythonRDD.scala:53
>>>pairRDD.groupByKey().foreach(print)
('hadoop', <pyspark.resultiterable.Resultlterable object at0x7f2c1093ecf8>)
('spark',<pyspark.resultiterable.Resultlterable object at 0x7f2c1093ecf8>)
reduceByKey(func) 和 groupByKey
reduceByKey 用于对每个 key 对应的多个 value 进行 merge 操作,最重要的是它能够在本地先进行merge操作,并且merge操作可以通过函数自定义
groupByKey 也是对每个 key 进行操作,但只生成一个 sequence,groupByKey 本身不能自定义函数,需要先用groupByKey生成 RDD,然后才能对此 RDD 通过map进行自定义函数操作
>>>words =["one","two","two","three","three","three"]
>>>wordPairsRDD = sc.parallelize(words).map(lambda word:(word,1))
>>>wordCountsWithReduce = wordPairsRDD.reduceByKey(lambda a,b:a+b)
>>>wordCountsWithReduce.foreach(print)
('one', 1)
('two', 2)
('three', 3)
>>>wordCountsWithGroup = wordPairsRDD.groupByKey().map(lambda t:(t[0],sum(t[1])))
>>>wordCountsWithGroup.foreach(print)
('two', 2)
('three', 3)
('one', 1)
上面得到的 wordCountsWithReduce 和 wordCountsWithGroup 是完全一样的,但是,它们的内部运算过程是不同的
· keys:把Pair RDD中 key 返回形成一个新的RDD
>>>list = [("Hadoop",1),("Spark",1),("Hive",1),("Spark",1)]
>>>pairRDD = sc.parallelize(list)
>>>pairRDD.keys().foreach(print)
Hadoop
Spark
Hive
Spark
· valuse:把Pair RDD中 value 返回形成一个新的RDD
>>>list = [("Hadoop",1),("Spark",1),("Hive",1),("Spark",1)]
>>>pairRDD = sc.parallelize(list)
>>>pairRDD.valuse().foreach(print)
1
1
1
1
· sortByKey():返回一个根据键排序的RDD
>>>list = [("Hadoop",1),("Spark",1),("Hive",1),("Spark",1)]
>>>pairRDD = sc.parallelize(list)
>>>pairRDD.foreach(print)
('Hadoop', 1)
('Spark', 1)
('Hive', 1)
('Spark', 1)
>>>pairRDD.sortByKey().foreach(print)
('Hadoop', 1)
('Hive', 1)
('Spark', 1)
('Spark', 1)
sortByKey() 和 sortBy(func)
使用sortByKey():
>>>d1 = sc.parallelize([("c",8),("b",25),("c",17),("a",42),\
...("b",4),("d",9),("e",17),("c",2),("f",29),("g",21),("b",9)])
>>>d1.reduceByKey(lambda a,b:a+b).sortByKey(False).collect()
[('g', 21), ('f', 29), ('e', 17), ('d', 9), ('c', 27), ('b', 38), ('a', 42)]
使用sortBy(func):
>>>d1 = sc.parallelize([("c",8),("b",25),("c",17),("a",42),\
...("b",4),("d",9),("e",17),("c",2),("f",29),("g",21),("b",9)])
>>>d1.reduceByKey(lambda a,b:a+b).sortBy(lambda x:x,False).collect()
[('g', 21), ('f', 29), ('e', 17), ('d', 9), ('c', 27), ('b', 38), ('a', 42)]
>>>d1.reduceByKey(lambda a,b:a+b).sortBy(lambda x:x[0],False).collect()
[('g', 21), ('f', 29), ('e', 17), ('d', 9), ('c', 27), ('b', 38), ('a', 42)]
>>>d1.reduceByKey(lambda a,b:a+b).sortBy(lambda x:x[1],False).collect()
[('a', 42), ('b', 38), ('f', 29), ('c', 27), ('g', 21), ('e', 17), ('d', 9)]
· mapValues(func):对键值对RDD中的每个value都应用一个函数,但是,key不会发生变化
>>>list =[("Hadoop",1),("Spark",1),("Hive",1),("Spark",1)]
>>>pairRDD = sc.parallelize(list)
>>>pairRDD1 = pairRDD.mapValues(lambda x:x+1)
>>>pairRDD1.foreach(print)
('Hadoop', 2)
('Spark', 2)
('Hive', 2)
('Spark', 2)
mapValues(func) 和 map(func)
使用mapValues(func):
>>>rdd = sc.parallelize([("spark",2),("hadoop",6),("hadoop",4),("spark",6)])
>>>rdd.mapValues(lambda x:(x,1)).\
...reduceByKey(lambda x,y:(x[0]+y[0],x[1]+y[1])).\
...mapValues(lambda x:x[0]/x[1]).collect()
[('hadoop', 5.0), ('spark', 4.0)]
使用map(func):
>>>rdd = sc.parallelize([("spark",2),("hadoop",6),("hadoop",4),("spark",6)])
>>>rdd.map(lambda x:(x[0], (x[1],1))).\
...reduceByKey(lambda x,y:(x[0]+y[0],x[1]+y[1])).\
...map(lambda x:(x[0], (x[1][0]/x[1][1]))).collect()
[('hadoop', 5.0), ('spark', 4.0)]
· join:join就表示内连接。对于内连接,对于给定的两个输入数据集(K,V1)和(K,V2),只有在两个数据集中都存在的key才会被输出,最终得到一个(K,(V1,V2))类型的数据集。
>>>pairRDD1=sc.parallelize([("spark",1),("spark",2),("hadoop",3),("hadoop",5)])
>>>pairRDD2 =sc.parallelize([("spark","fast")])
>>>pairRDD3 = pairRDD1.join(pairRDD2)
>>>pairRDD3.foreach(print)
('spark', (1, 'fast'))
('spark', (2, 'fast'))
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









