







 本文介绍了一种名为BigKV的KV缓存系统,专为全闪存阵列设计,解决大型对象缓存的挑战,包括元数据开销、空间浪费和SSD故障。通过无视碰撞的哈希表、紧凑元数据和反应式容错机制,BigKV显著提高了缓存性能和可用性。
本文介绍了一种名为BigKV的KV缓存系统,专为全闪存阵列设计,解决大型对象缓存的挑战,包括元数据开销、空间浪费和SSD故障。通过无视碰撞的哈希表、紧凑元数据和反应式容错机制,BigKV显著提高了缓存性能和可用性。
问题
随着网络内容质量的提高,对缓存大型对象的需求不断增加。在生产内容交付网络(CDN)、图像和文档服务器中,大多数对象的大别为8KB–32KB(CDN服务器)、32KB–128KB(图像服务器)和1KB(文档服务器)。如果基于DRAM的键值(KV)缓存存储这些大型对象,则系统要么(i)无效,因为大型对象会迅速耗尽DRAM的容量[6],要么(ii)成本高昂,因为应该部署数百台服务器来创建分布式DRAM缓存池。因此,迫切需要建立一个专门为大型对象量身定制的KV缓存系统。
全闪存阵列(AFA)服务器包含许多SSD(高达84[12]),提供PB级的容量和数十GB/s的吞吐量[13]。但还没有如何在AFA上建立高效KV缓存的研究。
挑战
为了提高AFA的缓存命中率有几个挑战:
-
AFA 中可缓存的对象数量受到系统的DRAM的限制。典型的闪存KV缓存维护一个存储在DRAM中的哈希表,其中每个条目都保留一个用于索引KV对象的元数据,每个元数据的大小范围从8B到48B。考虑到AFA具有1PB的SSD和128GB的DRAM,对象的大小平均为32KB,因此最多只能使用AFA容量的一半来缓存对象。这必然会降低命中率,因为另一半的对象无法进行索引。只在DRAM中缓存热条目是可能的,但简单的哈希表缓存会导致额外的I/O。
-
AFA 空间的大部分都被已过期的对象占用。在缓存系统中,对象有一个指定生存期的 Time-To-Live(TTL),TTL 过期的对象必须是不可访问的,并且需要清理以回收空间。然而,在大量对象存储的 AFA 缓存中,主动回收 TTL 过期对象是昂贵的,因为需要扫描慢速的 SSD。而懒惰的替代方法只有在识别到它们时才删除过期的对象,这导致缓存容量的低效使用,进而导致高未命中率。
-
AFA 缓存不可避免地频繁发生 SSD 故障。为了在故障时提供缓存服务,通常使用基于奇偶校验的保护技术,例如 RAID。但 SSD 上的 RAID 对性能和容量都有害,因为它涉及额外的 I/O 来记录奇偶校验,并需要额外的空间来减少有效缓存容量 [3, 27, 43]。如果使用 RAID-6 对 8× SSD 进行分组,AFA 空间的 25% 必须用于存储奇偶校验块。
本文方法
我们提出了 BigKV,这是专门为在全闪存阵列(AFA)中缓存大型对象而设计的键值缓存。BigKV 的设计围绕缓存的独特属性:由于它包含数据的副本,因此对于缓存中有哪些数据的确切记录对于正确性来说并不是关键。通过忽略哈希碰撞、近似元数据信息,并允许因故障导致数据丢失,BigKV 显著提高了缓存命中率,并保留了系统中更多有用的对象。
-
设计了无视碰撞的两级哈希表,使用紧凑的每个对象 16B 元数据。BigKV 将整个哈希表存储在 SSD 中,将热门条目通过组相连缓存在 DRAM 中。容忍由于哈希碰撞而导致的数据丢失,这避免了碰撞处理所需的额外 I/O,从而极大提高了 I/O 吞吐量。当对象查找在 DRAM 缓存中未命中时,最多只需要两次 I/O,改善了尾延迟。
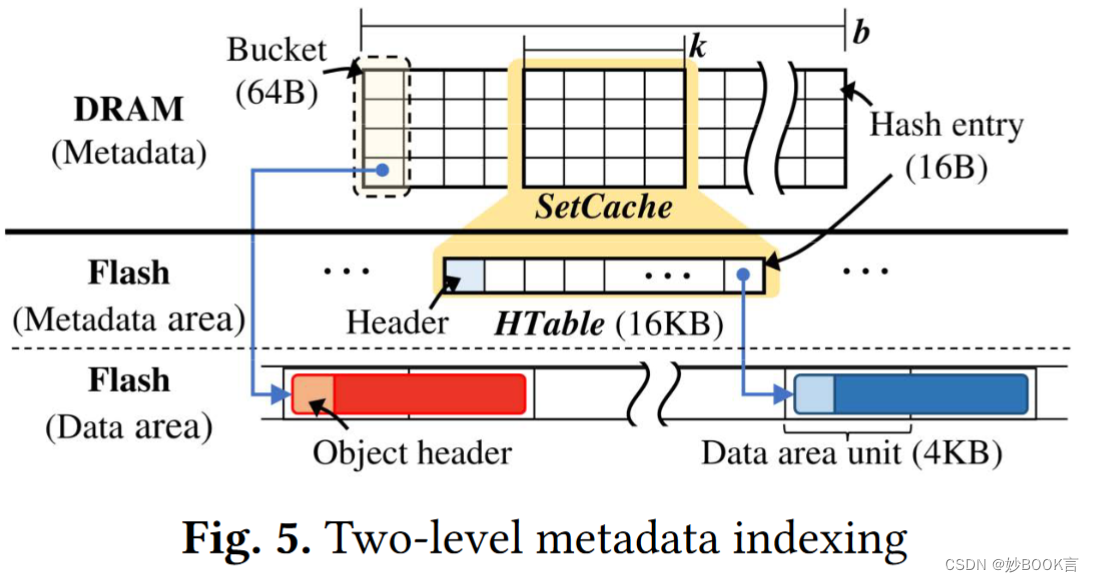
-
实现了近似 TTL 管理,将 TTL 相似的对象存储到同一空间。只使用 5 位表示 TTL,而精确的 TTL 需要 4B。这种粗粒度的分组允许 BigKV 快速、几乎零成本地识别过期对象,有效地利用缓存容量。
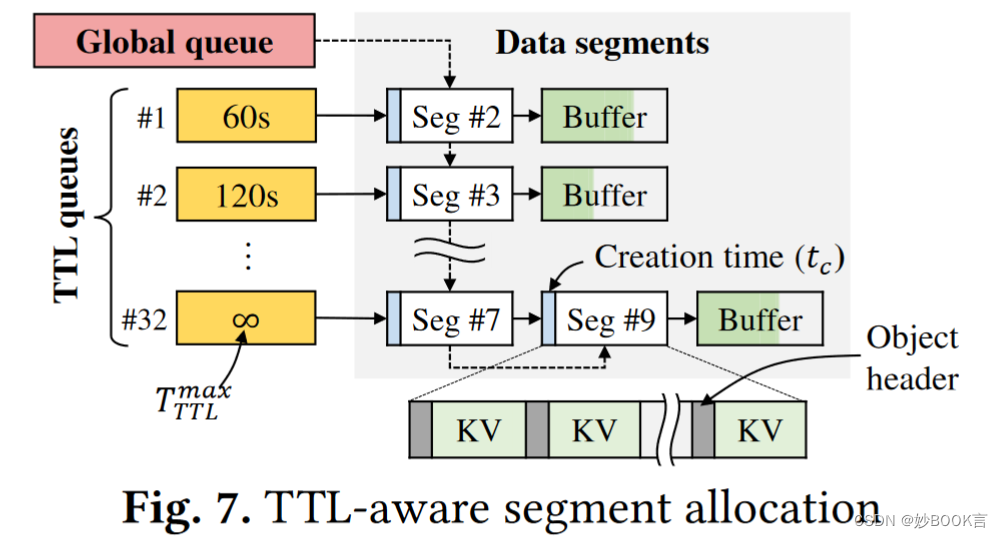
-
使用了反应式的容错机制,跨分片缓存空间处理故障,仅在故障显现时处理。BigKV 将分片与故障隔离来保持高可用性,而无需奇偶校验的开销。分片故障而导致的数据丢失是可以容忍的,总体而言,这有助于系统通过持续的正常运行和后台恢复来获益,而无需计算和写入奇偶数据的前期成本。
在真实的 AFA 上进行的实验证明我们的设计平均增加了 3.1 倍的吞吐量,并将平均延迟和尾延迟分别降低了 57% 和 81%。
实验
实验环境:AFA机器有两个Xeon Gold 6152 CPU(44核,运行频率2.1 GHz)和64GB DRAM。它可以容纳32×U.2 PCIe SSD。我们使用8×3.84TB NVMe SSD(三星的PM9A3[17]),每个SSD分别提供3.4GB/s和3.1GB/s的顺序读写吞吐量。为了快速评估,我们缩小AFA系统的规模,使用1TB SSD空间和128MB DRAM。此DRAM与SSD之比相当于具有1PB SSD空间和128GB DRAM的AFA(类似于NetApp的AFA产品[44])。
数据集:YCSB[10],Twitter跟踪[53,62]
实验对比:吞吐量、延迟、命中率
总结
针对AFA规模的KV缓存系统,用于大型对象。针对三个挑战:(1)庞大的元数据导致的高索引开销,(2)过期对象造成的空间浪费,(3)频繁的SSD故障导致的服务中断。为了解决这些问题并提高缓存命中率,提出三种技术:无视冲突的两级哈希表,使用紧凑的每个对象 16B 元数据,将整个哈希表存储在 SSD 中,将热门条目通过组相连缓存在 DRAM 中;近似TTL管理,将 TTL 相似的对象存储到同一空间,使用粗粒度分组快速识别过期对象;反应式容错机制,跨分片缓存空间处理故障,仅在故障显现时处理,将分片与故障隔离来保持高可用性,无需奇偶校验的开销。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











