







CXL 介绍
Systematic CXL Memory Characterization and Performance Analysis at Scale
针对CXL内存的性能进行分析,本文使用了4个CXL设备、5个CPU平台,对265个工作负载进行分析。(1)在基准测试方面:不同CXL设备性能表现不同,相比与本地内存和NUMA尾延迟更高、稳定性不足,在混合读写下CXL带宽更高。(2)在应用层:多数负载可以容忍CXL内存的延迟,性能下降不明显, 但对带宽受限应用下降明显,CXL与NUMA组合尾延迟更高。(3)提出精确定位CXL瓶颈的方法(Spa),通过9个CPU性能计数器,对比同一工作负载在本地DRAM和CXL内存上运行情况,分析额外停顿周期数量和位置,定位性能瓶颈(CXL读写、缓存、CPU核心)。
Exploring and Evaluating Real-world CXL: Use Cases and System Adoption
针对真实CXL硬件在各种环境下实际使用的性能进行测试,得到以下结论:(1)CXL相比于本地内存增加2.2-2.8倍延迟。CXL带宽更容易饱和,低于本地内存(LDRAM),接近远程内存(RDRAM),同时访问DRAM和CXL可以有效增加带宽。混合负载下,CXL的带宽和延迟接近RDRAM。(2)在HPC工作负载中,使用CXL内存时,应用程序级交织会降低性能,数据对象级交织可以与以LDRAM为中心的页面分配性能相当或更好。(3)在LLM工作负载中,CXL可以扩展内存容量,提高系统吞吐量。但GPU访问CXL内存时,由于数据路径导致延迟更长。卸载到CPU的计算可以从额外的CXL带宽中受益。(4)通过分层内存使用CXL内存具有巨大潜力。动态页面迁移和静态页面交织集成不好。动态页面迁移可能会降低性能,静态页面放置策略,如对象级交织,可以带来更好的性能。
Rethinking Hash Tables: Challenges and Opportunities with Compute Express Link (CXL)
总结将哈希表移植到CXL内存的一些挑战,如高访问延迟,粗粒度访问(64B),锁开销高,一致性开销。提出一些简单解决思路:存储更多元数据减少CXL内存访问,利用缓冲区实现批量修改,设计无锁结构,设计无日志结构。
A CXL-Powered Database System: Opportunities and Challenges
本文提出了将CXL用于数据库系统的思路,用于解决以下4个问题。(1)缓冲池管理:构建混合缓冲池,动态数据页面分配,细粒度内存共享实现多写一致性。(2)内存管理:弹性混合缓冲池,优化远近内存分配,冷热数据分层。(3)快速数据恢复:双重检查点机制,同步共享内存中的脏页,使用CXL和持久内存强制提交。(4)索引优化:B+树节点内存分配,数据修改时内存分配,数据结果修改时使用CXL管理冲突。
Exploring Performance and Cost Optimization with ASIC-Based CXL Memory
EuroSys 2024 Paper 阅读笔记
针对CXL硬件的测试,测试不同软件在CXL硬件上的性能变化。本文在ASIC CXL 1.1存储器上进行评估,测试不同类型应用的性能表现。(1)CXL 1.1性能特征。带宽争用:延迟在中低带宽利用率下相对稳定,随着带宽接近高水平,延迟呈指数级增加,这主要是由于内存控制器中的排队延迟。与本地主存相比,ASIC CXL的访问延迟为2.5倍,实现了73.6%的PCIe带宽。(2)内存容量受限应用,如键值存储、大数据分析、弹性计算。CXL提供的额外内存容量可以改善受主存容量限制的应用程序。通过智能调度策略,如热页升级,可以使性能几乎与完全在MMEM上运行接近,但对数据局部性差的应用效果有限。(3)内存带宽受限应用,如LLM推理。发现即使部分(30%)本地内存的容量和带宽没有得到充分利用,将一些工作负载转移到CXL内存也可以显著提高性能。因为使用CXL内存可以减少DDR通道上的带宽争用,降低总体内存访问延迟,从而提高应用程序性能。
An Introduction to the Compute Express LinkTM (CXLTM) Interconnect
arXiv Paper
对CXL技术进行介绍,包括CXL 1.0、CXL 2.0、CXL 3.0,对各规范的提升做介绍。整理了现有的CXL实现方法,延迟测试结果,对未来发展进行展望。
How Flexible is CXL’s Memory Protection? Replacing a sledgehammer with a scalpel
CXL提供的是粗力度的内存共享,没有提供细粒度的内存保护功能,作者提出用针对特定领域优化的去中心化能力系统来优化CXL的安全性。
CXL (Compute Express Link) Technology
Journal of Computer and Communications 2023 Paper 阅读笔记
对CXL的一些基础知识进行整理,包括一些对CXL的问题、CXL协议、完整性和数据加密(IDE)、数据速率。
提出一些使用CXL的看法:(1)SSD是块设备(而不是随机访问负载存储设备),不需要CXL控制器。(2)应用程序应该不知道正在使用什么内存,也不知道不同的延迟。操作系统/内核应该负责为应用程序分配正确的内存类型。(3)可以创建一个malloc函数,该函数可以指定它是否可以使用延迟更高的内存池,并由操作系统相应地为其提供服务。可以将现有的类似NUMA的方法应用于CXL。
CXL and the Return of Scale-Up Database Engines
对CXL在数据库领域的使用前景的分析,利用CXL带来的新功能,可以更好的实现内存扩展、分离式内存、近数据处理。文中提出了许多CXL带来的新问题,有待后续进行优化。
Compute Express Link(CXL): An Open Interconnect for Cloud Infrastructure
对CXL技术的介绍,CXL用于解决三个挑战:缓存一致性、内存带宽不足、资源滞留或未充分利用。介绍三代CXL规范的主要创新点:(1)CXL 1.0支持单个节点上直接连接主机处理器和CXL设备,提出三种CXL协议和三种CXL设备;(2)CXL 2.0支持跨节点切换和资源池,利用交换机,支持跨多个域(节点)的设备池、扇出交换机、对持久内存的支持、安全性。(3)CXL 3.0支持织物拓扑的可组合系统,加快传输速率和带宽,提出无序I/O(UIO)支持织物拓扑,提出反向无效(BI)支持主机以非缓存的方式访问其他主机管理的设备内存,支持多级交换机,引入节点间一致共享内存。
CXL 实现
Breaking Barriers: Expanding GPU Memory with Sub-Two Digit Nanosecond Latency CXL Controller
HotStorage 2024 Paper 泛读笔记
本文针对扩展GPU内存的问题,提出基于CXL的扩展方案。定制化设计了CXL控制器,运行GPU通过该控制器连接DRAM/SSD,实现约80ns的往返延迟。提出推测读取(在CXL控制器检测目标地址实现预取,监控流量避免预取引起过多负载)和确定性存储(当写密集或CXL内存成为瓶颈,在GPU内存临时存储数据随后写入CXL内存)策略。
Streamlining CXL Adoption for Hyperscale Efficiency
本文针对将CXL应用于超大规模的需求,介绍了一种CXL集成解决方案,与现有OCP超大规模CXL分层内存扩展器规范相符。引入了一种节能、可扩展、硬件加速、无损压缩内存CXL层。通过在缓存线粒度上实现专有的(解)压缩算法,以及开源LZ4算法的双硬件加速器实现,在纳秒内提供2-3倍的CXL内存压缩,为最终客户提供20-25%的TCO降低,同时不需要额外的物理插槽。
Memory Sharing with CXL: Hardware and Software Design Approaches
基于CXL设备支持内存共享,分为基于软件和基于硬件两种方式。基于软件需要多层间协议的支持和实现,或通过OpenSHMEM实现。基于硬件则利用硬件内的驱动程序支持共享内存访问、重映射、访问粒度等。
Demystifying CXL Memory with Genuine CXL-Ready Systems and Devices
使用CXL模拟器和真实CXL硬件,比较其性能。发现不同CXL控制器的设计会显著影响延迟的带宽,使用模拟器相对来说延迟更高带宽更小;使用CXL内存时使用页面迁移策略,需要考虑迁移带来的开销,否则会带来负优化;使用CXL内存会增加延迟,对𝜇s级延迟敏感的内存密集型应用,会显著增加p99延迟,对𝑚s级延迟敏感的复杂应用,增加的延迟可忽略不计;使用CXL内存会增加总带宽,但数据分布不合理时,带宽反而下降,需要有效的设计算法来优化吞吐和带宽。
A Novel Architecture of CXL Protocol Data Link Layer for Low Latency Memory Access
ICM 2023 Paper
本文提出CXL内存协议控制器的简单实现,提供了数据链路层架构,最大限度地减少数据路径中的延迟,并遵循CXL规范2.0。体系结构包含传输和接收链,确保了在两个CXL组件之间使用CXL协议可靠地传输数据包。整个体系结构使用HDL进行设计,在不同协议场景进行验证。
Direct Access, High-Performance Memory Disaggregation with DirectCXL
ATC 2022 Paper
基于硬件实现了CXL协议,将CXL 2.0引入实际系统并分析支持CXL的分解内存设计。
Memory Pooling With CXL
IEEE Micro 2023 Paper
DirectCXL的完整版,设计基于CXL的内存池,由于传统基于页面或基于对象的内存池。分析了基于CXL各步骤的实现,通过CXL连接主机和内存,运行时的软件堆栈,硬件实现方法。通过CXL优化减少了访问内存池时的网络开销、复制开销、利用CPU cache优化访问。在各种实验下均有良好的性能。
未来会基于CXL 3.0继续扩展,添加多缓存设备,反向无效窥探,利用多头逻辑设备和动态容量设备支持数据共享和内存动态扩展,结构扩展到更多互联设备。
按照这个实验的结果,L1 cache延迟4ns,L2 cache延迟96ns,本地内存240ns,CXL 1.312us,RDMA 8.108us。CXL比RDMA快8.3倍。
SMT: Software-Defined Memory Tiering for Heterogeneous Computing Systems With CXL Memory Expander
IEEE Micro 2023 Paper
提出基于CXL的内存扩展方案。构建了MXP原型,使用CXL控制器增强系统内存容量和带宽。开发了软件套件SMDK,用于在具有MXP的异构内存系统上执行内存分层、管理和智能分配。https://github.com/OpenMPDK/SMDK ,代码的wiki里介绍了一些细节。
文章里没讲具体的实现细节,就大概介绍了一下架构和各种功能,看不懂咋实现的。
按照这个实验的结果,本地内存100-140ns,CXL 420-600ns。但表格里写的平均是145ns,QoS 99.9%以上才和实验结果差不多425ns-567ns。顺序读或写带宽26GB/s,随机读写一起40GB/s,用的PCIe 5.0,理论上双通道时可达到64 GB/s。
Compute Express Link (CXL): Enabling Heterogeneous Data-Centric Computing With Heterogeneous Memory Hierarchy
对CXL协议的实现,涵盖了CXL 1.0和CXL 2.0的协议和实现方面,使用64.0-GT/s脉冲幅度调制4级电平(PAM-4)信令,将带宽增加一倍。
CXL模拟器
DRackSim: Simulating CXL-enabled Large-Scale Disaggregated Memory Systems
针对分离式内存系统,本文提出了一个模拟器DRackSim,模拟多个计算节点、内存池、本地/全局内存管理和CXL网络互连。(1)使用Intel的PIN工具生成指令,模拟无序执行的多核x86流水线和计算节点的多级缓存结构。(2)基于队列模拟CXL,以缓存行和页面粒度处理远程内存访问。(3)集成DRAMSim2进行本地和远程内存的模拟。(4)引入一个全局内存管理器,负责远程地址空间的分配和管理。
emucxl: an emulation framework for CXL-based disaggregated memory applications
本文提出了CXL模拟器,利用2个socket的物理服务器作为底层硬件,利用双节点虚拟机映射两个socket上的CPU和DRAM,其中一个映射CPU+DRAM作为本地内存,另一个只映射DRAM作为CXL远程内存。在硬件基础上设计了一套用户空间API,用于分配和释放内存。随后设计了两个简单的程序测试模拟器的效果。https://github.com/cloudarxiv/emucxl
局限性:只能模拟单个节点和一个CX扩展内存,使用场景有限。根据实验结果看本地和远程内存延迟差距约65-85ms,API的开销可能较高。
CXLMemSim: A pure software simulated CXL.mem for performance characterization
arXiv Paper
构建模拟器实现CXL.mem,只写了各简单的介绍,没有详细细节。模拟器先在现有软件上执行程序,并跟踪内存操作,将应用程序周期性中断插入三种延迟。https://github.com/SlugLab/CXLMemSim
局限性:目前开来模拟时间还是很长,对于系统调用的模拟时间提升34-141倍,不知道模拟的准不准
CXL 应用
SmartQuant: CXL-based AI Model Store in Support of Runtime Configurable Weight Quantization
针对如何利用CXL和低精度权重来优化内存访问速度和能源效率。本文提出SmartQuant,利用CXL内存存储AI模型权重,结合权重重要性降低访问数据量。包括2个技术:(1)位平面级内存放置,将模型权重不连续存储,而是按位存储,从而允许选择性的读取部分权重,降低读取数据量。(2)内存逻辑空间膨胀,将不同精度的权重逻辑上暴露给主机,便于主机使用,通过CXL控制器读取相应数据并构建不同精度权重。
Tiresias: Optimizing NUMA Performance with CXL Memory and Locality-Aware Process Scheduling
针对基于CXL的扩展内存使用,优化其上运行的工作负载性能。本文提出Tiresias,一种基于反馈的控制器,对延迟敏感(LC)和尽力而为(BE)应用分别调度。包括3个技术:(1)工作负载感知和内存带宽管理。定期通过load/store指令测试延迟,检测高延迟负载(BE),采用页表无效来限制带宽使用。(2)利用CXL内存缓解内存带宽争用。针对BE负载,对内存地址采样,将使用频率低的页面迁移到CXL内存。(3)页面和进程调度。将页面放置在分配后首先读/写此页面的处理器上。若进程必须跨NUMA访问,则将进程调度到对应CPU上。
Telepathic Datacenters: Fast RPCs using Shared CXL Memory
针对远程过程调用(RPC)的优化,现有方法需要昂贵的序列化和压缩才能通信。本文提出RPCool,利用CXL共享内存功能的RPC框架。包括以下技术:(1)通过传递指向共享内存数据结构的指针来通信。(2)限制发送方对RPC参数的访问,避免并发访问数据。(3)通过沙盒指定指针范围,检查无效或野指针。(4)将跨机架通信回退到基于RDMA的通信,并提供统一RPC接口。(5)利用租约机制感知应用程序故障,防止数据丢失或内存泄漏。
An LPDDR-based CXL-PNM Platform for TCO-efficient Inference of Transformer-based Large Language Models
针对提升大型语言模型(LLM)训练和推理所需内容容量和带宽的问题,模型并行等方法受限于低互联带宽,近内存处理(PNM)受限于扩展性和性能不足。本文提出CXL-PNM,基于CXL的PNM平台,优化GPU的容量和带宽,主要包括3个技术:(1)基于LPDDR5X的CXL内存架构,比DDR5和GDDR6有更高容量和带宽。(2)与推理集成的控制器,提供更高容量(硬件堆叠),可扩展性(多设备并行),并发(硬件仲裁管理),地址冲突(CXL内存映射避免冲突)。(3)完整软件栈,支持python程序简单转换。
Enabling Efficient Large Recommendation Model Training with Near CXL Memory Processing
针对推荐模型对内存需求过高的问题,利用CXL和近内存处理可以有效缓解推荐模型的嵌入层训练。本文提出了ReCXL,结合CXL和近内存计算(NMP)优化推荐模型训练。包括3个技术:(1)统一NMP架构,在CXL内存中集成了NMP单元,在前向和反向传播中减少传输数据量。(2)无依赖预取,在硬件空闲时提前预取下一批次数据。(3)细粒度调度,优化嵌入向量更新顺序,减少等待时间。
CLAY: CXL-based Scalable NDP Architecture Accelerating Embedding Layers
针对深度神经网络的嵌入层训练,解决训练过程中容量和性能的问题。现有方法基于双列直插式内存模块(DIMM)的近数据处理(NDP)架构,难以扩展容量,且受限于硬件架构无法完全并行。本文提出CLAY,基于CXL的NDP架构,包括4个技术:(1)将多个DRAM模块与专用的向量处理单元(Vector PU)互连,以减少DRAM模块之间的数据传输开销。(2)细粒度内存地址映射,将嵌入向量分片存储在多个DRAM集群中,来缓解负载不平衡。(3)基于CXL设计网格互联,在每个PU执行局部归约,多个PU交换中间结果,并行完成全局归约。(4)数据包复制方案,减少主机和CLAY集群间通信所需的指令带宽。
Bandwidth Expansion via CXL: A Pathway to Accelerating In-Memory Analytical Processing
针对将CXL用于数据库管理系统(DBMS)的效果,现有方法均将CXL用于扩展内存容量,但忽略了增加带宽的优势。本文测试了将DRAM和CXL内存交错使用的场景。在顺序和随机读写下,DRAM和CXL内存比在3:2时可以最大程度发挥带宽,甚至高于纯DRAM,提升1.61倍。在其他场景下,DRAM和CXL内存交错使用带宽也有提升,但受限于其他因素提升效果有限但依旧有提升。
RomeFS: A CXL-SSD Aware File System Exploiting Synergy of Memory-Block Dual Paths
针对CXL-SSD硬件下的文件系统,CXL-SSD提供CXL.mem和CXL.io双模接口,分别连接内存区和SSD区,但现有文件系统无法适应这种新架构。本文提出RomeFS,协同利用CXL.mem和CXL.io数据路径来处理文件操作,包括3个技术:(1)双路径数据布局,将元数据存储在CXL.mem数据区,将文件数据存储在CXL.mem和CXL.io数据区,运行时协同使用两个数据路径对文件数据进行双路径访问。(2)混合并行文件索引,定位两条数据路径上的文件数据。设计了写时合并(MOW)和按块数据日志回写(LWB)机制,以减轻文件数据碎片。(3)元数据日志记录和协同双路径事务写入,以低开销确保写入原子性和崩溃一致性。
ICGMM: CXL-enabled Memory Expansion with Intelligent Caching Using Gaussian Mixture Model
针对CXL连接主机和SSD架构下的缓存设计,本文提出ICGMM,使用高斯混合模型(GMM)的硬件缓存方案。(1)利用二维GMM分析内存访问的空间和时间分布,决定缓存和驱逐。(2)将GMM实现到FPGA中,采用数据流架构,使各模块并行运行,同时将计算和SSD访问重叠减少等待。
A Programming Model for Disaggregated Memory over CXL
针对CXL架构下的编程模型设计,本文提出了CXL0,用于CXL架构下并发程序的编程。 首先提出了一系列高级抽象和操作语义,包括存储、加载、刷新、传播、崩溃。随后将FliT转换(单机环境将线性化算法转换为支持崩溃的持久化线性算法)适配到CXL环境中,提供三种转换:MStore:每个存储在完成时持久化,不需要刷新;RStore和RFlush:使用RStore进行存储,通过RFlush将存储值刷新到远程内存;LStore和RFlush:使用LStore进行存储,通过RFlush将数据刷新到远程内存。
LMB: Augmenting PCIe Devices with CXL-Linked Memory Buffer
针对扩展设备内存的问题,本文提出基于CXL的链接内存缓冲区(LMB),实现CXL内存扩展器,包括地址映射、访问控制、内存管理、API接口等。对于CXL设备(GPU),直接通过CXL.mem或UIO访问,对于PCIe设备(SSD),由主机转换为CXL.mem请求在访问。
CXL Shared Memory Programming: Barely Distributed and Almost Persistent
针对CXL共享内存引入的数据故障和进程故障,本文提出处理模型。(1)数据故障,使用复制(交换机复制减少CPU开销)或纠删码(数据分组处理)。(2)进程故障,使用日志记录(读密集采用撤销日志,写密集采用重做日志,数据依赖采用恢复日志)和检查点(全流程持久化,记录缓存和寄存器状态)。(3)故障联合处理,将日志/纠删码与日志相结合,检查点与日志相结合。
OMB-CXL: A Micro-Benchmark Suite for Evaluating MPI Communication Utilizing Compute Express Link Memory Devices
利用CXL优化消息传递接口(MPI)通信,使用共享CXL内存,避免网络通信。并将CXL优化的MPI实现到OSU Micro Benchmark(OMB)中,评估点对点通信中,缓冲区在本地内存或CXL内存时的通信效果。基于QUMU模拟测试。
Yggdrasil: Reducing Network I/O Tax with (CXL-Based) Distributed Shared Memory
ICPP 2024 Paper 泛读笔记
针对网络I/O通信的优化,传统通信受限于数据封装、内存复制开销、上下文切换开销。本文利用基于CXL的共享内存(DSM)实现通信,设计用户空间套接字Yggdrasil。包括4个技术:(1)透明的动态快/慢数据路径导航。在CXL DSM和linux套接字间自动切换。(2)去中心化的CXL内存管理。利用CAS指令控制多个物理主机对共享内存的并发访问。(3)基于无锁队列的QoS感知动态数据轮询。根据端到端延迟,定期轮询共享内存中的特定数据位,以检测数据的到达。(4)语义感知内存页面迁移。当检测到大量冗余内存复制操作时,透明地将数据缓冲区的内存页迁移到CXL内存。
A Three-Tier Buffer Manager Integrating CXL Device Memory for Database Systems
针对数据库管理系统的优化,结合本地内存,CXL内存,固态硬盘。本文提出三层缓冲区管理器,利用虚拟内存转换支持本地内存和CXL内存的统一管理,利用概率页面迁移策略将页面在不同层间迁移,利用近似LRU策略实现页面驱逐。
An Examination of CXL Memory Use Cases for In-Memory Database Management Systems using SAP HANA
Proceedings of the VLDB Endowment 2024 Paper 泛读笔记
本文针对内存数据库管理系统,通过CXL内存缓解内存有限、重启时间长的问题。针对CXL扩展内存空间问题,需要考虑数据结构和内存访问模式,顺序访问影响较小,随机访问性能下降明显。针对重启时间长问题,通过共享CXL内存,可以重用表数据,显著减少了服务器重启时间。
HydraRPC: RPC in the CXL Era
本文提出基于CXL优化RPC,现有基于消息传递的RPC面临:网络开销高,数据复制开销,可扩展性差。本文提出利用CXL HDM(主机管理设备内存)进行数据传输的HydraRPC。包括4个技术:(1)利用多机间共享的CXL HDM来避免昂贵的网络开销、内存复制和(反)序列化。(2)采用不可缓存的共享来绕过CPU缓存,而不是通用的load/store内存访问指令。(3)基于轮询的优化,使用SSE3的功率降低指令,降低CPU利用率。(4)滑动窗口协议,防止访问拥塞。
NOMAD: Non-Exclusive Memory Tiering via Transactional Page Migration
针对使用基于CXL的内存时,分层内存的页管理策略。现有方法将页从容量层迁移到性能层时,受限于同步处理页面错误的开销,迁移过程中性能显著下降。本文提出非独占内存分层,允许性能层的部分页在容量层有副本,以减轻内存抖动。提出了事务性页面迁移(TPM),在迁移过程中页面可以访问。在不从容量层取消页面映射的情况下启动页面内容复制,以便程序仍然可以访问迁移页面。将页面复制到性能层上的新页面后,检查该页面是否被修改。如果修改,则页面迁移无效,并稍后重试;如果成功,将新页面将映射到页表中,旧页面取消映射,成为新页面的影子副本。页面降级时,如何页面不脏并且其副本存在于容量层,只需重新映射页面,实现平稳的性能转换。进一步实现NOMAD,针对分层内存的页面管理框架,集成了非独占内存分层和事务性页面迁移,防止由于影子页面导致的内存不足(OOM)。将页面迁移从程序执行的关键路径中删除,并使迁移完全异步。
Managing Memory Tiers with CXL in Virtualized Environments
针对利用CXL进行内存分层,基于软件会消耗过多CPU且只能在页面粒度迁移,基于硬件受限于组合间内存争用和租户内LLC争用。本文提出软硬件结合的CXL分层系统 Memstrata,基于Intel®扁平内存模式进行软件层优化,在各种负载下提供了类似于本地DRAM的性能,能够将内存容量扩展1.5倍。使用两个技术:(1)识别冲突缓存行的页面,采用页面着色将其分配给同一个租户来消除租户间争用。(2)使用四个指标:L3缺失延迟、L2缺失延迟、TLB未命中延迟、L2 MPKI(每千条指令的本地内存缺失次数),利用随机森林进行分类。根据未命中率在租户间动态分配专用的本地内存页,以提高对内存延迟最敏感的租户的性能。
Salus: Efficient Security Support for CXL-Expanded GPU Memory
针对使用CXL内存扩展GPU内存时,为了实现安全产生的相关流量。本文提出了一种新的安全模型,包括三个技术:(1)统一存储器的安全元数据,将安全元数据与数据的物理位置解耦,消除了在数据重新定位过程中的重新加密。(2)重组加密计数器块,在次要计数器之间共享主要计数器,从而减少流量,同时压缩访问频率较低的的计数器块。(3)在CXL到GPU映射中以位掩码格式跟踪脏信息,显著减少元数据访问和写回相关的流量。
Rethinking Design Paradigm of Graph Processing System with a CXL-like Memory Semantic Fabric
如何在图处理系统中利用CXL优化性能。本文基于对共享内存模型的分析,设计了降低访问频率和将计算与RMA重叠的方法。随后在FPGA上实现了CXL-oF,并与现有图处理系统结合,实现性能提升。
Rcmp: Reconstructing RDMA-Based Memory Disaggregation via CXL
针对RDMA和CXL结合的内存分解。本文提出基于RDMA和CXL的内存池Rcmp,通过CXL提高了基于RDMA的系统的性能,并利用RDMA克服了CXL的距离限制。包括4个创新点:(1)基于全局页面的内存空间管理,支持细粒度的数据访问,避免IO放大。(2)使用不同缓存区结构避免通信阻塞,机架内访问使用环形缓存区,机架间访问使用双层缓冲区,第一级存储已完成的访问避免阻塞,第二级使用环形缓存区,执行完时将请求添加到第一级缓冲区。(3)使用热页识别和交换策略,以及具有同步机制的CXL内存缓冲区,以减少跨机架RDMA通信。(4)设计了RDMA感知的RPC框架来加速跨机架RDMA传输。
Polaris: Enhancing CXL-based Memory Expanders with Memory-side Prefetching
针对CXL内存的预取,本文提出Polaris,将硬件预取器集成到CXL内存控制器芯片中。在CXL中增加额外缓存区,将预取数据存入缓存区中,预取命中时降低CXL内存访问延迟。支持将预取结果主动推送到CPU的LLC,进一步降低延迟。
优势:(1)在硬件修改,兼容现有数据中心服务器;(2)避免预取污染CPU缓存,具有更大预取范围;(3)利用设备端DRAM带宽进行预取;(4)可以利用硬件性能实现更高预取精度。
Database Kernels: Seamless Integration of Database Systems and Fast Storage via CXL
CIDR 2024 Paper 泛读笔记
针对利用CXL技术充分利用闪存设备。本文提出CXL闪存耦合方式,在设备中实现数据库系统的部分,称为数据库内核(DBK)。DBK利用CXL技术将地址空间导出到数据库系统,不是在Flash中实现1:1映射,而是针对该区域的I/O触发设备内部的计算,类似于近数据处理(NDP)。
Low-overhead General-purpose Near-Data Processing in CXL Memory Expanders
arXiv Paper 泛读笔记
针对CXL内存的近数据方法,如何实现不使用特殊单元,同时保持低延迟。本文提出了低开销的CXL存储器通用NDP架构,称为M2NDP,包括内存映射函数(M2func)和内存映射μ线程(M2μthr)。(1)M2func是主机处理器和NDP控制器之间的低开销通信机制。利用CXL.mem进行主机设备通信,将NDP管理命令封装到预先确定的地址,避免使用CXL.io/PCIe的高延迟开销。在CXL输入端口增加数据包过滤器,若请求的内存地址与预先分配的内存范围相匹配则触发NDP管理功能。(2)M2μthr使用轻量级μ线程,使用体系结构的寄存器子集作为执行单元,NDP单元使用细粒度多线程执行多个μ线程以隐藏DRAM访问延迟。每个μ线程与特定内存位置直接关联,即μ线程是内存映射的,可以避免初始地址计算代码。(3)NDP单元基于RISC-V ISA,以利用SIMD单元,并利用DRAM BW,同时支持标量运算。
Toward CXL-Native Memory Tiering via Device-Side Profiling
针对CXL内存的使用,现有方法进行内存分层时,受限于低分辨率和高开销内存访问分析技术。本文提出NeoMem,软硬件协同的CXL内存分层解决方案。硬件使用设备侧内存访问分析单元NeoProf,容易分析对CXL内存的LLC缺失,并提供页面热度、内存带宽利用率、读/写比率、访问频率分布等。在操作系统方面,利用NeoProf信息实施了高级内存分层策略,以实现高效的热页面升级。
Logical Memory Pools: Flexible and Local Disaggregated Memory
利用CXL实现分离式内存,本文提出逻辑内存池,在每个服务器中分割出部分本地内存来创建内存池,而不是使用与服务器分离的物理内存池。在逻辑上将每个服务器的内存划分为私有和共享区域,其中所有共享区域的并集构成了分离式内存。
局限性:但这种方法丢失了CXL扩展内存的优势。
Exploiting CXL-based Memory for Distributed Deep Learning
基于CXL内存扩展内存时,如何优化DL模型训练,本文提出DeepMemoryDL框架,通过资源收集+负载分析+数据预取,优化模型训练时间,避免数据读取导致的I/O停滞。核心是数据预取,并没有利用很多CXL的特性。
GPU Graph Processing on CXL-Based Microsecond-Latency External Memory
本文使用基于CXL的外部存储器对GPU图遍历进行了分析和评估。考虑到图处理工作负载的性质,大约32B的地址对齐,以及接近几百字节的数据传输,可以实现最佳运行时间。转化为对外部存储器的要求,即几百MIOPS的随机读取性能和几微秒的延迟,表明具有较长延迟的CXL存储器(包括配备了低延迟闪存的CXL)可以用作外部存储器,以实现与主机DRAM相当的性能。
Lightweight Frequency-Based Tiering for CXL Memory Systems
针对利用本地内存和CXL内存的分层系统,如何同时提升数据放置准确率;减少内存和运行时间开销。本文提出FreqTier,用于CXL内存的基于频率的分层系统。提出三个创新点:(1)采用了基于频率的分层,使用高性能硬件计数器以页粒度跟踪内存访问。(2)使用计数布隆滤波器(CBF)(一种概率数据结构)跟踪页面访问频率。(3)采用动态方法,根据应用程序内存访问行为调整分层操作的强度,调整页面迁移和访问采样频率。
Improving key-value cache performance with heterogeneous memory tiering: A case study of CXL-based memory expansion
利用CXL扩展内存,满足超出DRAM的带宽或容量需求。本文开发了一个CXL 2.0内存扩展解决方案,包括:(1)E3.S CXL内存原型;(2)HMSDK,提出新的NUMA内存分配策略,根据用户定义的内存分配比率在NUMA节点之间交错分配内存页。(3)透明分层和数据分层两种内存系统架构,透明分层中DRAM和CXL内存作为统一的内存层共存,数据分层中将DRAM和CXL内存区分为单独的内存层,根据数据类型,将元数据、索引数据存在DRAM中,键值数据存在两种内存中。并将其应用于Meta的缓存系统。
CXL-Enabled Enhanced Memory Functions
介绍了增强内存功能(EMF)的概念,提供了如何在智能内存控制器(IMC)中实现两个用例(访问热图和内存回滚)的EMF。本质来说是利用近数据处理的思路,在CXL设备端通过IMC获取更多数据,例如访问跟踪、缓存行状态,并响应来自主机的请求,实现更高的性能。
提出了EMF设计思路,利用以下一个或多个属性来实现其功能:(1) 接近内存介质本身。(2) 能够在数据平面上插入内存读/写命令。(3) 主机处理器缓存层次结构外部。(4) 独立于主机ISA限制。(5) 与虚拟内存子系统分离。(6) 能够与主机处理器复合体进行交互,以保持数据一致性。
Dynamic Capacity Service for Improving CXL Pooled Memory Efficiency
针对CXL扩展池内存,从软件和硬件方面实现了动态容量服务(DCS),根据主机的需求动态地从池中分配或释放内存。DCS硬件引擎支持动态容量分配和释放,包括:内存管理单元(MMU)、邮箱、内存段表、内存保护单元(MPU)、安全擦除器。DCS软件框架支持用户使用CXL池内存,包括:CXL池内存检测和管理、DCS引擎驱动程序、支持DCS的Kubernetes。并实现了用于传输请求的API,支持三个命令:获取内存段状态、设置内存段分配、设置内存段释放。最终基于FPGA实现了DCS原型,可以适用于不同孽畜大小的节点组成内存池,并提高系统内存利用率。
Cache in Hand: Expander-Driven CXL Prefetcher for Next Generation CXL-SSDs
针对CXL-SSD的预取,现有方法面临硬件逻辑大小限制和不同CXL层延迟不同。本文提出ExPAND,一种扩展器驱动的CXL预取器,将预取卸载到CXL SSD。包括两个关键技术:(1)使用用于地址预测的异构机器学习算法管理跨各种扩展器访问的数据预取,利用CXL.mem的反向失效(BI)确保数据一致。(2)在枚举和设备发现过程中识别底层CXL网络拓扑和设备延迟,技术每个CXL-SSD的精确端到端延迟,并写入每个设备的PCIe配置空间。因此,预取算法可以确定获取数据的最佳时机,减少了SSD后端介质施加的长延迟。
Apta: Fault-tolerant object-granular CXL disaggregated memory for accelerating FaaS
针对云环境的FaaS,如何通过基于CXL的分离式内存进行优化。直接使用CXL会面临部分故障引起的不可用。本文提出Apta,基于CXL的对象粒度内存接口,用于维护FaaS对象。关键创新是新的容错一致性协议,包括两个部分:(1)惰性失效,将无效项移出写入的关键路径,这样当缓存共享程序的服务器出现故障时,写入程序就不会被无限期地阻止。但会导致缓存不一致。(2)一致性感知调度,对FaaS调度器进行了更改,使其只能在无未决失效的服务器上调度功能,从而实现强大的一致性和可用性。
A Case Against CXL Memory Pooling
针对在数据中心或云中利用CXL扩展内存池的可行性,本文分析结果是目前不可行,使用CXL内存池面临三个问题:成本、复杂性和实用性。(1)CXL池的成本将超过减少RAM所节省的成本。因为使用CXL池有大量的基础设施成本,如与以太网完全并行的网络基础架构。(2)CXL的延迟远远高于主内存,要获得良好的性能,需要重写软件以显式管理CXL内存,将块复制到本地DRAM中,增加了软件的复杂性。(3)CXL内存池化的动机是针对被搁置的内存,即由于没有更多的计算资源来支持虚拟机而无法分配给虚拟机的内存,现在可以被其他服务器集中使用。但现代服务器相对于大多数虚拟机来说都很大,几乎没有内存搁浅。
Accelerating Performance of GPU-based Workloads Using CXL
针对基于GPU的HPC工作负载,其通常受到板载系统存储器的数量以及共享存储器资源(例如主存储器)和互连(例如PCIe)的争用的限制。本文提出了一种高效的内存分配方法,结合了多GPU系统的每个插槽上的内存需求进行内存分配。
局限性:整体来看方法比较简单,就是根据各种资源剩余数量和需求量进行分配。实验也是基于模拟,在访问过程增加CXL惩罚,实验不太准。
Evaluating Emerging CXL-enabled Memory Pooling for HPC Systems
用仿真器和模拟器评估CXL对HPC应用和图应用的性能影响,将CXL用于内存容量扩展和带宽扩展。
结果显示,在仿真的CXL内存池系统上,CXL内存池占75%的内存使用情况下,七个HPC应用中有五个在仿真CXL系统上几乎没有性能降级。在仿真的高带宽CXL系统上,OpenFOAM和Hypre等带宽敏感性最高的应用程序也保持了性能,突显了CXL启用的内存系统在可扩展、成本效益高带宽系统方面的潜力。对于共享内存服务器上的干扰需要通过系统级的协调来解决,基于对每个作业动态使用情况的理解,以减轻性能降级。
Transactional Indexes on (RDMA or CXL-based) Disaggregated Memory with Repairable Transaction
在分离式内存场景下,如何保证客户端操作的事务性,即故障原子性和隔离性,避免客户端崩溃导致索引数据的损坏。作者提出在事务进行前先记录redo log,如果发生故障则通过redo log来恢复;通过租约锁识别客户端故障,后续客户端如果发现租约锁过期则认为发生故障,并主动通过redo log恢复;保证修复操作时幂等的,实现协调修复操作。
CXL over Ethernet: A Novel FPGA-based Memory Disaggregation Design in Data Centers
优化分离式内存的访问。利用CXL和RDMA结合的方法,用CXL支持本机内存加载/存储访问;利用RDMA进行跨机架的访问,并通过封装以太网帧减少DMA复制和地址转换;通过缓存远程内存数据和拥塞控制算法减少延迟。
SDM: Sharing-enabled Disaggregated Memory System with Cache Coherent Compute Express Link
利用CXL优化分离式内存,利用CXL特性优化多处理器间的缓存一致性协议(MESI协议)。通过支持共享的控制流(SHA-CF)促进多主机间的共享,本质还是基于嗅探的MESI协议,利用CXL反向失效进行优化;利用CXL.io管理节点资源,不影响CXL.cache和CXL.mem传输;提出推测访问,就是乐观的执行仿存,若权限检查失败在回滚。
局限性:总体来看比较简单,利用CXL的特性来优化MESI协议;实验基于Intel PIN tool构建了模拟器,但没有具体细节,只对比了基础的基于嗅探的MESI协议,没有对比更好的缓存一致性算法。
Computational CXL-Memory Solution for Accelerating Memory-Intensive Applications
IEEE Computer Architecture Letters 2023 Paper 泛读笔记
通过CXL利用分离式内存加速应用计算。在CXL内存设计了计算核心,减少通过CXL传输的数据量;通过交织内存通道,利用MAC运算器隐藏累加器延迟,充分利用内部带宽。
CXL-ANNS: Software-Hardware Collaborative Memory Disaggregation and Computation for Billion-Scale Approximate Nearest Neighbor Search
ATC 2023 Paper
针对十亿规模近似最近邻居搜索(ANNS)问题,通过CXL缓解内存压力。
针对算法细节优化,基于关系感知进行图缓存,利用领域专用加速器(DSA)、EP端计算减少传输开销,调整算法执行顺序隐藏CXL内存池的延迟,对算法执行过程放松依赖进行调度。总体基于CXL实现十亿规模ANNS取得良好性能。
Overcoming the Memory Wall with CXL-Enabled SSDs
ATC 2023 Paper
针对计算资源和存储资源增长速度不匹配导致内存墙问题,本文提出基于CXL的闪存作为内存。
开发了一种新的工具来收集应用程序的物理内存跟踪,同时收集LLC未命中或驱逐引起的内存访问和页故障导致的页表更新,将二者组合成物理内存跟踪。https://github.com/spypaul/MQSim_CXL
克服了闪存的三个挑战:粒度不匹配、微秒级延迟、持久性有限。通过在闪存前添加DRAM作为缓存,设计未命中状态保持寄存器(MSHR)减少缓存未命中时的流量,设计简单的预取策略进行预取,使68–91%的请求延迟小于1微秒,估计寿命至少为3.1年。
局限性:文章所探讨的CXL闪存的设计没有考虑闪存的内部任务,如垃圾收集和损耗均衡,所考虑的主机系统可能无法完全反映CXL引入的新系统特性。只使用了MQSim模拟器。
Hello Bytes, Bye Blocks: PCIe Storage Meets Compute Express Link for Memory Expansion (CXL-SSD)
HotStorage 2022 Paper
提出了使用CXL-SSD扩展内存的思路,与上一篇思路相近。但没有做更细节的优化,只是简单用硬件实现了CXL-SSD,性能不佳。主要讨论了CXL-SSD的CXL互连和可扩展性潜力。讨论了主机向设备提供提示时的设计思路,通过在CXL消息中添加注释,将不同用户场景通知CXL-SSD,用于缓存预取或汇总数据批量写入。
A Case for CXL-Centric Server Processors
arXiv Paper
针对使用CXL接口替换DDR接口,从而极大增加带宽。
提出使用基于CXL的内存替代基于DDR内存,将内存请求分布在4倍以上的内存通道上,CXL减少了对内存总线的排队影响。由于排队延迟在有负载的内存系统中占主导地位,因此这种减少远远弥补了CXL引入的接口延迟开销。提出了分对称的CXL接口优化,读写接口不设计成1:1,根据读写需求设计,但PCIe标准目前不允许这样做。
局限性:设计过于简单,也没有很多具体场景的优化,实验基于模拟器做的比较简单,没有实际模拟CXL。
TPP: Transparent Page Placement for CXL-Enabled Tiered-Memory
ASPLOS 2023 Paper
对于内存扩展的场景,如何灵活使用本地内存和较慢的CXL内存,目标是将热页面留在本地内存,冷页面卸载到CXL内存。
文章构建Chameleon,轻量级的用户空间工具,用于分析应用程序的内存访问行为,如页面温度、不同类型页面的温度、不同页面类型使用情况。
根据分析结果设计TPP,内核空间下的透明的页放置策略,使用轻量级回收机制将冷页降级到CXL内存,将分配和回收逻辑解耦增加本地内存空闲页空间,基于LRU的页提升机制将热页提升到本地内存,基于页面感知的分配将不同类型页初始分配到不同内存层。
主要使用NUMA架构进行模拟,两个节点,一个有CPU和内存,另一个只有内存。也部署了基于FPGA支持CXL 1.1的硬件但延迟较高。实验结果本地内存利用率更高,吞吐量更高。
Pond: CXL-Based Memory Pooling Systems for Cloud Platforms
ASPLOS 2023 Paper
对生产云集群中观察发现内存滞留和未接触内存,可以通过内存池+CXL内存缓解,用内存池避免内存滞留,将未接触内存分配到廉价的远程内存节省DRA成本。
本文提出Pond,满足云提供商要求的全栈内存池,由硬件、系统软件和分布式系统层组成,用于管理池/CXL内存。提出4个技术:用8-16个套接字之间的池大小即可实现池的大部分优势;通过ML模型预测工作负载的延迟敏感程度、未接触内存大小,根据结果分配内存位置;将未接触内存分配到慢速内存节点不会影响工作负载性能;通过监控系统避免ML预测错误导致的性能下降。
套着CXL壳的云存储下内存分层技术,对云上工作负载分析,发现有节省内存的空间,于是对工作负载要使用的内存做预测,根据预测结果分开申请内存。
Design Tradeoffs in CXL-Based Memory Pools for Public Cloud Platforms
IEEE Micro 2023 Paper
在Pond基础上继续研究,Pond提出要使用更大的CXL内存池(50%),来节省DRAM的成本,本文分析发现使用CXL池会引入其他基础设施开销,反而使用较小的内存池(25%)综合来看节省更多成本。提出使用CXL多头设备(MHD)进行池的连接,相比于CXL交换机可以进一步减少传输延迟。
整体来看论文内容偏简单,绝大多数篇幅都是重述了Pond中的发现,最后分析了一下使用CXL内存池引入其他成本。
BEACON: Scalable Near-Data-Processing Accelerators for Genome Analysis near Memory Pool with the CXL Support
MICRO 2022 Paper
对生物领域的基因组分析问题优化,其中许多应用是内存绑定的,现有方法在通信带宽上和内存扩展方面有瓶颈,作者想设计基于CXL的设计,利用内存池中丰富的内存和CXL提供的高通信带宽。
提出BEACON,优化内存访问和通信。通过添加PE进行计算,添加内存控制器和地址转换器优化内存访问,添加总线控制器和数据打包器优化通信,添加原子引擎优化内存访问,通过数据迁移方法利用数据局部性优化内存访问,针对特定算法设计多芯片合并优化通信。相比与现有方法提升了大量性能但也提升了少量能耗
多数是基于硬件的修改,在CXl架构下针对基因组分析添加硬件解决内存访问和通信的问题。或许可以将这些硬件功能通过软件实现用于其他问题的优化。
Design and Analysis of CXL Performance Models for Tightly-Coupled Heterogeneous Computing
ExHET@PPoPP 2022 Paper
尝试使用CXL优化紧耦合的异构计算,本文用FPGA和GPU的通信作为例子,程序先通过FPGA计算,随后将计算结果传入GPU继续计算。
感觉没有真正实现,只是通过数学公式直接计算,模拟CXL惩罚参数为60%-90%的结果。大多数模拟太理想化了,也没有针对问题做细节上的优化,整体偏简单。只能算是个尝试,用CXL有优化异构计算的空间,但文章没有做很细节的实现。
Failure Tolerant Training With Persistent Memory Disaggregation Over CXL
IEEE Micro 2023 Paper
针对大规模推荐系统,通过CXL实现低开销容错性。使用type-2设备,将PMEM和GPU连接到CXL系统中,通过硬件间相互cache减少数据移动的开销(将整体一次性移动改为了多次小移动,会不会反而增加传输数据量,可能最后结果只有10,但中间计算结果有20)。通过批处理感知调整记录检查点时间,利用PMEM空闲时间记录检查点。将推荐训练的顺序放松,重新调度避免RAW开销,减少检查点记录。
整体思路创新性挺好,实验时因为没有硬件用GPU上计算时间替代CXL系统下的计算时间。第一个优化点利用CXL设备间相互cache,协议里没具体写可以这样实现,属于是自己猜测的功能。
Partial Failure Resilient Memory Management System for (CXL-based) Distributed Shared Memory
SOSP 2023 Paper
分布式共享内存,因为使用CXL技术,可能存在部分故障。例如两个计算节点引用相同内存,其中部分计算节点故障时不影响其他计算节点。基于重做日志无法精确定位故障位置;使用锁无法满足部分故障,获取锁的部分可能发生故障。
本文基于引用计数的内存管理方法,避免不同计算节点间故障后无法恢复的问题,实现CXL系统下的故障恢复。https://github.com/madsys-dev/sosp-paper19-ae
CXL Memory as Persistent Memory for Disaggregated HPC: A Practical Approach
arXiv Paper
将CXL内存用于高性能计算领域,作者展示了从传统PM编程模型可以轻易过度到CXL上,使用CXL可以表现出和PM近似的能力,优势是有更高的带宽。
Enabling CXL Memory Expansion for In-Memory Database Management Systems
DaMoN 2022 Paper
直接用CXL type 3扩展IMDBMS内存,将CXL内存设备仅用于主存储器。增量存储器和操作数据存储在主机DRAM中。当顺序访问主存储器时,预取方案可以有效地隐藏CXL设备的较长延迟。
Performance Evaluation on CXL-enabled Hybrid Memory Pool
NAS 2022 Paper
使用NUMA架构模拟CXL架构,使用SSD作为分层内存的第二层,测试典型工作负载的性能。就是NUMA架构,跟CXL没啥关系。
CXL架构
-
硬件保证了主机和分配的CXL device间的一致性;主机也可以访问其他主机的CXL device,但不保证cache一致性,可以通过禁用缓存或软件负责一致性的方法来访问;主机和主机间通过GIM相互访问,也不支持cache一致性,GIM延迟暂时不知道,假设和主机访问CXL device的延迟相同。
-
多头CXL.mem设备(MHD)连接到多个主机,可以同时将相同的物理内存区域映射到其所有HPA中。
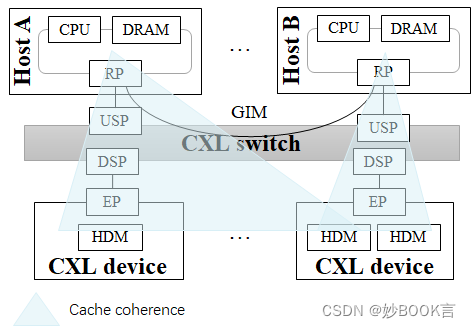
各层级延迟情况




















 2165
2165

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











